
Abstract
This research paper highlights the significance of vehicle detection in aerial images for surveillance systems, focusing on deep learning methods that outperform traditional approaches. However, the challenge of high computation complexity due to diverse vehicle appearances persists. The motivation behind this study is to highlight the crucial role of vehicle detection in aerial images for surveillance systems, emphasizing the superior performance of deep learning methods compared to traditional approaches. To address this, a lightweight deep neural network-based model is developed, striking a balance between accuracy and efficiency enabling real-time operation. The model is trained and evaluated on a standardized dataset, with extensive experiments demonstrating its ability to achieve accurate vehicle detection with significantly reduced computation costs, offering a practical solution for real-world aerial surveillance scenarios.
Introduction
Aerial images have emerged as a powerful resource in modern surveillance systems, providing a comprehensive view of large areas from elevated perspectives [1, 2]. These images find diverse applications in monitoring traffic, disaster response, urban planning, and security surveillance [3, 4]. In the context of image-based surveillance systems, accurate and real-time target tracking and vehicle detection is of utmost importance task [5]. The ability to detect vehicles from aerial footage significantly enhances traffic management [6, 7], security, and situational awareness in urban environments [8–10].
Vehicle detection and target localization has gained considerable attention due to its relevance in surveillance applications [11, 12]. Incorporating a vehicle segmentation feature into surveillance systems enhances their efficiency by providing detailed information about the types of vehicles present. The vehicle detection and semination of these objects aerial images allows for a more nuanced understanding of traffic patterns, aiding in traffic management, driving safety [13], and security monitoring [12, 15]. Whether identifying cars, trucks, or other vehicles, this advanced surveillance system becomes a valuable tool for various applications, from urban planning to law enforcement. The constant movement and congestion of vehicles and population distribution in urban areas necessitate robust detection methods for effective video-based surveillance [16]. Accurate vehicle detection aids in monitoring traffic flow, identifying traffic violations, and assisting in law enforcement activities [17–19]. Furthermore, the capability to detect and track vehicles in real-time from aerial footage aids in identifying suspicious activities and potential security threats [20–22]. The examples of vehicles in aerial images are shown in Fig. 1.

The examples of vehicles in aerial images.
The application of our proposed YOLOv8-based lightweight model for vehicle detection in aerial images holds significant real-world implications for surveillance systems, facilitating efficient and precise monitoring in scenarios with diverse vehicle appearances. The model’s ability to strike a balance between accuracy and computational efficiency opens avenues for seamless integration into practical surveillance applications, addressing the challenges posed by complex real-world aerial surveillance scenarios.
Over the years, numerous technologies and methodologies have been developed for vehicle detection in aerial images. Early approaches primarily relied on handcrafted features and traditional machine-learning algorithms [21, 24]. However, these methods often struggled to handle the complexities arising from varying lighting conditions, occlusions, and vehicle scale changes. In recent years, significant advances in deep learning techniques have revolutionized vehicle detection, demonstrating superior performance compared to traditional methods [25]. Deep learning-based approaches leverage the power of neural networks to automatically learn discriminative features from data [26], enabling more accurate and robust vehicle detection in aerial images [27–30].
Despite the significant advancements in deep learning-based vehicle detection, several research challenges persist. A primary challenge lies in achieving real-time processing. Aerial images present considerable appearance variations due to factors such as varying lighting, weather conditions, and camera perspectives. These variations make accurate vehicle detection a demanding task, requiring lightweight yet efficient deep-learning models to meet real-time requirements [31–33].
Addressing these research challenges, in this study, we propose a lightweight deep learning-based approach using Deep Neural Networks (DNN) for vehicle detection in aerial images [34]. The proposed model is generated using a custom dataset, and rigorous training, validation, and testing processes are conducted to ensure its effectiveness.
The motivation behind this study is to highlight the crucial role of vehicle detection in aerial images for surveillance systems, emphasizing the superior performance of deep learning methods compared to traditional approaches. The study aims to address the challenge of high computational complexity by developing a lightweight deep neural network model that strikes a balance between accuracy and efficiency. The ultimate goal is to provide a practical solution for real-world aerial surveillance scenarios, enabling accurate vehicle detection with significantly reduced computation costs.
In summary, the contributions of this research are twofold. Firstly, we propose a lightweight deep-learning method for accurate vehicle detection in aerial images, addressing the challenges of real-time requirements. Secondly, extensive experiments and performance evaluations are conducted to validate the effectiveness of the proposed method, demonstrating its potential for enhancing surveillance systems with reliable vehicle detection capabilities.
This section offers a glimpse into the cutting-edge methodologies within the realm of vision-based vehicle detection on aerial images.
In [35], the authors described a technique for special vehicle detection using a deep learning network based on YOLO-GNS from a UAV perspective. In order to efficiently identify special vehicles like emergency vehicles, armored vehicles, or huge vehicles from aerial imagery taken by UAVs, the suggested method makes use of the YOLO-GNS architecture, a variation of the YOLO object detection model. The deep learning network enables accurate and real-time detection of these special vehicles, enhancing surveillance and situational awareness in urban environments. However, the method has some limitations. Due to the complexity of detecting various types of special vehicles and their diverse appearances from an aerial perspective, the accuracy of the detection might vary depending on the specific scenarios and conditions. Moreover, the performance of the method could be impacted in cases where the vehicles are partially occluded or in low-visibility conditions, leading to potential false negatives or false positives. Further research and optimization efforts are required to improve the robustness and generalization of the proposed YOLO-GNS-based deep learning network for special vehicle detection in diverse UAV perspectives.
The authors [36] proposed a smart traffic monitoring system using pyramid pooling vehicle detection and filter-based tracking on aerial images. The method utilizes pyramid pooling for efficient vehicle detection and filter-based tracking for continuous monitoring. The system aims to enhance situational awareness and support traffic management in urban areas. However, the method may be sensitive to occlusions and lighting variations in aerial images, leading to occasional detection and tracking inaccuracies. Further research is needed to improve accuracy and robustness in challenging traffic monitoring environments.
The authors in [37] discussed a car detection method for very high-resolution UAV images using deep learning algorithms. The method utilizes deep learning techniques to automatically detect cars in aerial imagery. The approach achieves accurate car detection results, especially in high-resolution UAV images. However, the method may be computationally intensive and require significant computational resources for processing very high-resolution images, potentially limiting its real-time applicability in large-scale surveillance systems.
In [38], the authors proposed a vehicle detection method for vision-based intelligent transportation systems using a CNN algorithm. The proposed method leverages the power of CNNs to automatically learn discriminative features from the input images, enabling accurate vehicle detection. The approach shows promising results in real-world traffic scenarios, improving traffic monitoring and management. However, the limitation of the method lies in its reliance on high-quality and well-annotated datasets, which may be challenging and time-consuming to collect for specific transportation environments. Further research is needed to address dataset challenges and enhance the model’s generalization capabilities across diverse traffic conditions.
The paper [39] compared car detection in aerial images using Convolutional Neural Networks (CNNs) with two popular architectures, Faster R-CNN and YOLOv3. The proposed method utilizes both Faster R-CNN and YOLOv3 models to detect cars in aerial imagery and assess their performance. The study finds that YOLOv3 shows better real-time performance, while Faster R-CNN achieves higher accuracy in car detection. However, the limitation lies in the trade-off between real-time processing and accuracy, necessitating careful consideration of the specific requirements in practical applications.
Table 1 includes research papers related to vehicle detection in aerial images using deep learning-based approaches. These papers explore different deep learning models, such as YOLO-GNS, pyramid pooling, and convolutional neural networks, to achieve accurate and real-time vehicle detection. The advantages of the methods include accurate detection in specific scenarios, efficient traffic monitoring, and high accuracy in high-resolution images. However, the limitations encompass challenges like limited applicability to general vehicle detection tasks, sensitivity to occlusions and lighting variations, and computational intensity for processing very high-resolution images. These papers collectively contribute to advancing vehicle detection applications, emphasizing the significance of deep learning in the field while acknowledging the need to address existing limitations for improved performance and adaptability.
Overview of previous studies
Overview of previous studies
The process involves generating a DNN model for vehicle detection by designing an appropriate architecture and training it on a labeled dataset. The pseudocode of the proposed framework is presented as follows,
# Step 1: Data Collection and Preprocessing dataset = gather_images_from_internet() augmented_dataset = augment_dataset(dataset)
# Step 2: Labeling labeled_dataset = label_images(augmented_dataset) preprocessed_dataset = preprocess_dataset(labeled_dataset)
# Step 3: Splitting Dataset
training_set, validation_set, test_set = split_dataset(preprocessed_dataset)
# Step 4: Model Architecture model = design_yolov8_model ()
# Step 5: Training Module
prepare_training_data(training_set)
initialize_yolov8_model(model)
train_yolov8_model (model, training_set)
# Step 6: Validation Module
validate_model(model, validation_set)
# Step 7: Testing Module
test_model(model, test_set)
# Step 8: Deployment
deploy_model(model)
Data collection and preprocessing
The initial phase entails gathering a dataset of images that include both automobiles and non-vehicles. The images are collected from internet resources, and no augmented on the images Aerial images or visual data obtained from an elevated viewpoint. They provide a bird’s-eye view of landscapes or specific regions, resulting in variations in the distance of objects. These images encompass a wide range of aerial perspectives, showcasing diversity in distance and other influencing factors.
The dataset undergoes augmentation, incorporating techniques such as noise addition, blurring, and orientation variations to diversify the images. This process aims to improve the robustness of machine learning models by simulating real-world imperfections and variations. The resulting augmented dataset enables the development of more resilient models that can better handle diverse conditions and perspectives, contributing to enhanced accuracy in recognizing objects.
Image annotation and labeling these images with the presence or absence of cars is necessary. Preprocessing of the dataset could also be necessary, such as scaling photos to a uniform size and standardizing pixel values. Training, validation, and testing sets are often created from the dataset. 70% for training, 20% for validation, and 10% for testing is a typical proportion. With different sets for hyperparameter adjustment and final evaluation, this separation makes sure that the model is trained on a significant percentage of the data.
Model architecture
Designing the deep neural network architecture comes next. A CNN is frequently used for vehicle recognition because of its capacity to recognize spatial information in images. Multiple convolutional layers, pooling layers to extract hierarchical features, and fully linked layers for classification may all be included in the design. When analyzing aerial photos, we employed the YOLOv8 architecture to recognize vehicles.
Figure 2 depicts the architecture of YOLOv8 [40], which represents an advanced object detection architecture. It combines features from YOLOv4 and YOLOv5. YOLOv8 employs a CSPDarknet53 backbone for feature extraction and adds PANet for multi-scale feature fusion. It employs anchor-based detection and uses DetectoRS for improved localization. YOLOv8 achieves high accuracy and speed by integrating state-of-the-art techniques, making it effective for real-time object detection tasks.
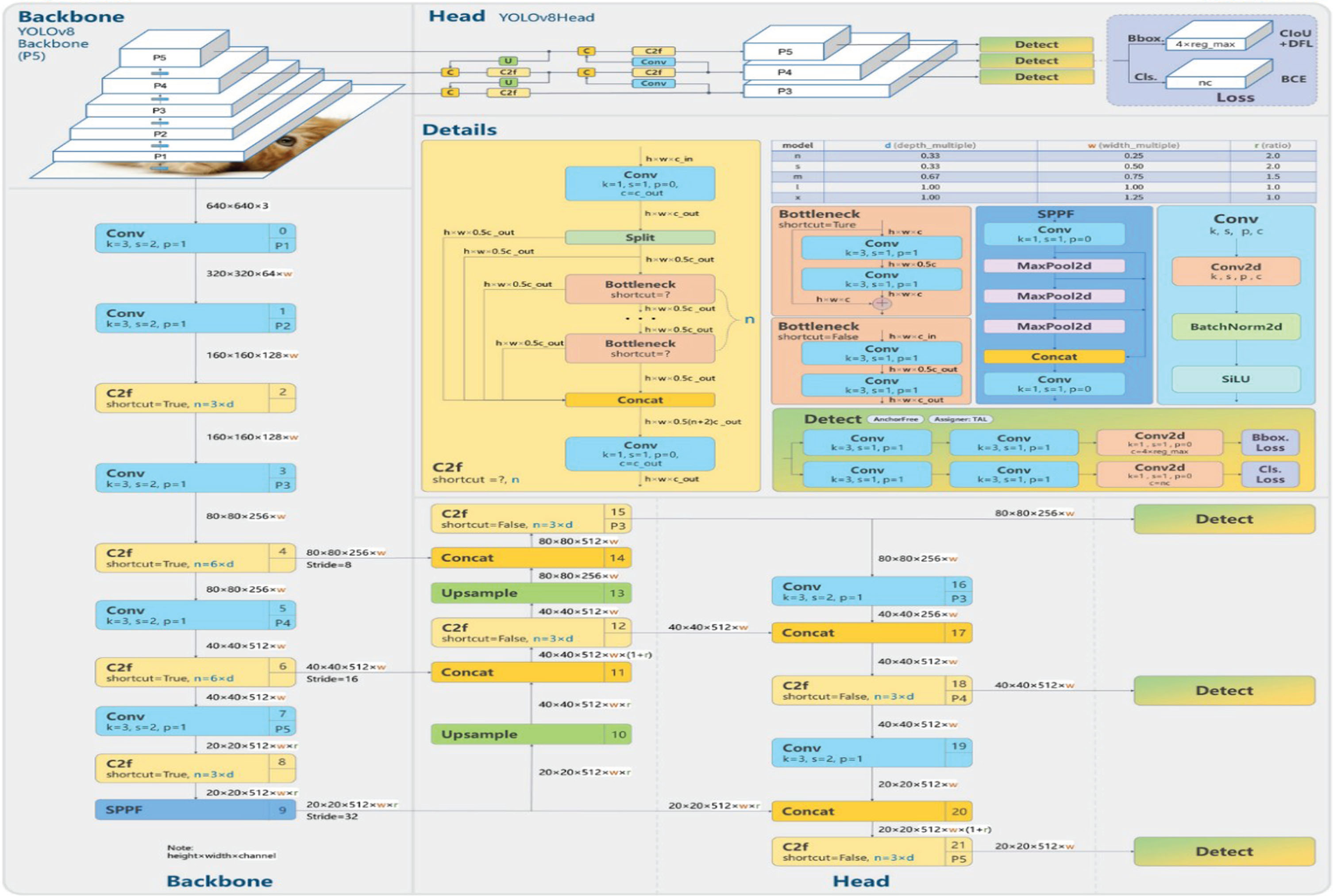
Architecture of YOLOv8
Creating a YOLOv8 model for vehicle detection in aerial images involves a series of steps to ensure effective training and accurate results. To start, the dataset should be prepared with a variety of aerial image frames containing vehicles. This dataset is explained in the above section. As discussed above, in the dataset, the frame images are annotated with bounding boxes around each vehicle to indicate their positions. Once the dataset is ready, it’s split into a training set and a validation set, with 70% allocated for training. In this step, some data preprocessing phase is crucial. Images should be resized to a common input size, often 416×416 pixels, to match the YOLOv8 model’s input requirements. To make more stable model, in the dataset, various augmentation techniques are employed to enhance the diversity of images. These techniques include the addition of noise, blurring, and orientation variations, random cropping, flipping, and adjusting brightness. The goal of augmentation is to create a more robust and varied dataset for training machine learning models. By introducing these alterations to the images, the model becomes better equipped to handle real-world scenarios where such variations naturally occur. Noise addition simulates the imperfections found in actual data, blurring helps the model generalize across different levels of sharpness, and orientation variations contribute to improved recognition of objects from different perspectives. This augmented dataset facilitates the development of more resilient and accurate models, capable of handling a wide range of conditions and inputs.
Labels for bounding boxes need to be adjusted according to the new image dimensions. Additionally, the data are normalized to bring pixel values within a certain range, such as [0, 1]. To facilitate efficient training, the labeled data is then organized in a format compatible with YOLO, typically in the format of (class, x_center, y_center, width, height).
As stated in YOLOv8 architecture, it consists of a backbone network that extracts features from the images and detection heads responsible for predicting bounding boxes and class probabilities. The backbone is generally based on models like Darknet-53 and the detection heads output predictions for different scales. The loss function combines object detection losses, including localization loss (measuring how accurately the model predicts bounding box positions) and confidence loss (evaluating how well the model predicts whether an object exists in a box), as well as class prediction loss. Training involves iterating through the dataset using batches of images. During training, the model’s weights are updated to minimize the combined loss. It’s crucial to fine-tune hyperparameters like learning rate, the number of iterations, and batch size to achieve optimal performance.
Validation and testing modules
The validation module evaluates the model’s performance on the validation set. This step ensures that the model is not only memorizing the training data but also capturing meaningful patterns that generalize to unseen data. If the model’s performance on the validation set starts to degrade, it might be a sign of overfitting, prompting adjustments to the model or its training process.
This phase ensures that the model not only memorizes intricacies within the training data but, more importantly, captures meaningful patterns that generalize effectively to unseen data. The evaluation on the validation set acts as a safeguard against overfitting, a scenario where the model becomes too tailored to the training data, resulting in poor generalization to new instances. If the model’s performance on the validation set begins to deteriorate, it serves as an early warning sign of potential overfitting issues. In response, adjustments to the model architecture or modifications to the training process can be implemented to enhance its ability to generalize and improve performance on diverse datasets.
In the final step, the testing module serves as the ultimate assessment of the YOLOv8 model’s capabilities. This module rigorously evaluates the model’s performance on a completely novel testing set, representing scenarios and data instances that the model has never encountered during its training phase. By exposing the model to unseen data, the testing module provides a robust measure of its generalization and predictive accuracy in real-world applications. The results from this phase validate the model’s efficacy and reliability, demonstrating its capacity to accurately detect vehicles in aerial images across various, previously unencountered scenarios. The meticulous evaluation in both the validation and testing modules ensures the YOLOv8 model’s readiness for practical deployment in diverse and dynamic surveillance environments.
Results and discussion
This portion unveils the outcomes derived from the executed experiments and deliberates on their implications. This section conventionally encompasses the subsequent stages:
Experimental results
In this investigation, we meticulously constructed a YOLOv8 model with the primary objective of detecting vehicles. To gauge the model’s effectiveness, we meticulously designed and executed a series of thorough experiments. The culmination of these endeavors is visually conveyed through Fig. 3, where we present a collection of sample images.
These images are thoughtfully juxtaposed with the model’s discerning detections of vehicles, encapsulating the essence of our research findings. Upon a closer examination of Fig. 3, it becomes abundantly apparent that the YOLOv8 model adeptly fulfills its mission of identifying and precisely locating various vehicles within the depicted images. The detections exhibited in the Figdemonstrate a commendable level of accuracy and reliability. This attainment underscores the model’s capacity to excel in the intricate task of vehicle detection. The remarkable alignment between the model’s predictions and the actual vehicles reaffirms its competence and bolsters its credibility for real-world applications that necessitate dependable and accurate vehicle identification. Our findings indeed reflect a satisfying level of achievement in the realm of vehicle detection.

The result of a validation set.
Figure 4 refers to the experimental result of our model. The validation graphs, encompassing validation box loss (val/box_loss), validation object loss (val/obj_loss), and validation class loss (val/cls_loss), hold essential insights into the training dynamics of a YOLOv8 model for vehicle detection. These graphs collectively offer a comprehensive perspective on the model’s progress towards accuracy. A diminishing val/box_loss signifies improving localization accuracy as the model refines its ability to precisely position bounding boxes around detected vehicles. Concurrently, a declining val/obj_loss denotes enhanced object detection proficiency, while a diminishing val/cls_loss underscores the model’s sharpening capability to accurately classify various vehicle types.
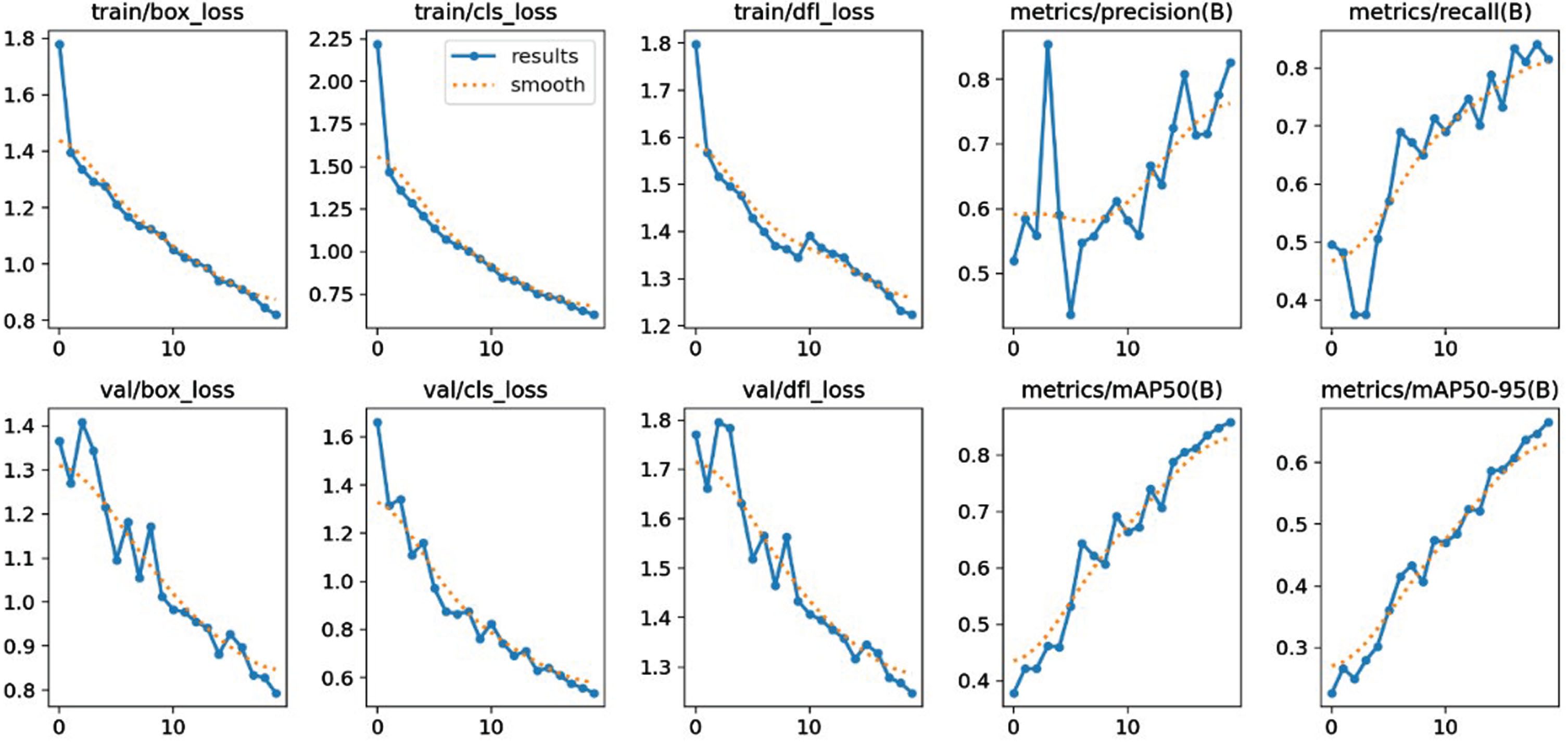
Experimental result of our model
To ensure an accurate model, strategic observations of these graphs are essential. An effective approach involves monitoring trends in the validation losses and tailoring strategies accordingly. Early stopping can counter overfitting if validation losses rise while training losses decrease. Additionally, hyperparameter tuning guided by these trends can fine-tune the model’s learning trajectory. Leveraging data augmentation techniques can enhance generalization when validation losses are high, while careful consideration of model complexity is warranted when validation losses plateau. Altogether, these validation graphs offer a roadmap for cultivating a precise YOLOv8 model for vehicle detection, substantiating informed adjustments throughout the training process.
In this step, we evaluate the performance of a YOLOv8 model for vehicle detection, which involves using precision and recall metrics.
Precision measures the ratio of true positive predictions (correctly detected vehicles) to the total number of positive predictions made by the model. In the context of vehicle detection, it tells us how many of the predicted vehicles actually vehicles were. A precision of 93% means that out of the vehicles, the model predicted, 93% were accurate. Conversely, recall calculates the ratio of true positive predictions to the total number of vehicles present in the dataset. It signifies how well the model captures all the actual vehicles. A recall of 98% implies that the model detected 98% of the actual vehicles in the dataset. Achieving a precision of 93% and a recall of 98% suggests that the YOLOv8 model performs exceptionally well in vehicle detection. YOLOv8 is a state-of-the-art architecture that effectively balances speed and accuracy in object detection. Its fusion of YOLOv4 and YOLOv5 features, along with advanced components like CSPDarknet53 and PANet, enables it to learn intricate features of vehicles. YOLOv8’s use of anchor-based detection enables it to handle various vehicle sizes and orientations by accurately predicting bounding boxes around them. The precision confidence and recall confidence curve are shown in Fig. 5.
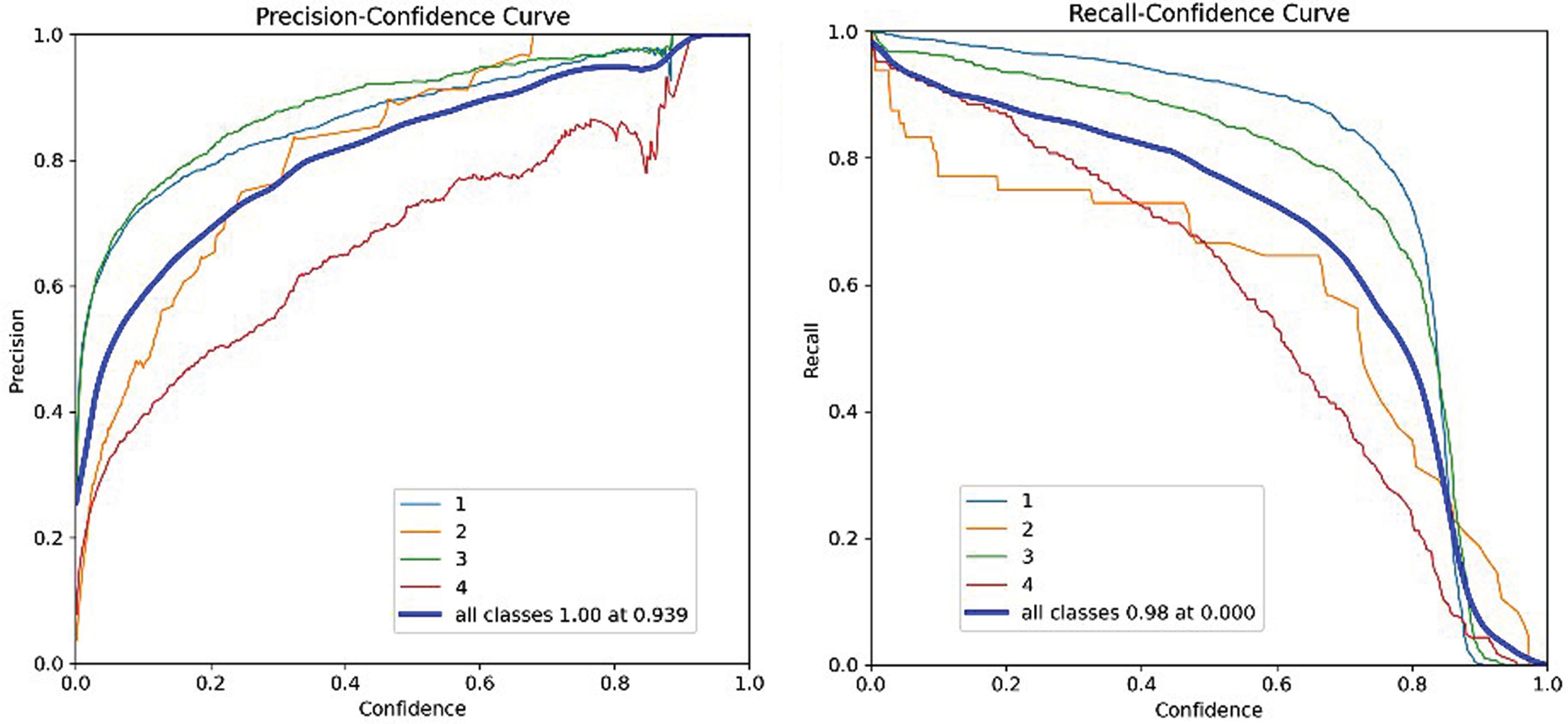
Precision confidence and Recall confidence curve.
mAP calculates the average precision for each class and then computes the mean of these average precisions. It’s a comprehensive metric that considers precision and recall at various confidence thresholds for all classes, providing an overall assessment of the model’s performance. In this scenario, where there are four classes, the reported mAP value of 85.8% indicates the model’s accuracy in detecting objects across these classes. The class-specific results (e.g., class 1 = 95.6%, class 2 = 95.6%, class 3 = 94.5%, class 4 = 71.4%) reflect the model’s precision within each class. The achieved mAP and class-specific average precision values indicate a highly accurate YOLOv8 model for vehicle detection. A combination of meticulous training, thoughtful architectural choices, data augmentation, and targeted improvements for specific classes collectively contribute to the model’s impressive performance across a variety of vehicle classes. Figure 6 depicts the result of our model using the mAP metric.
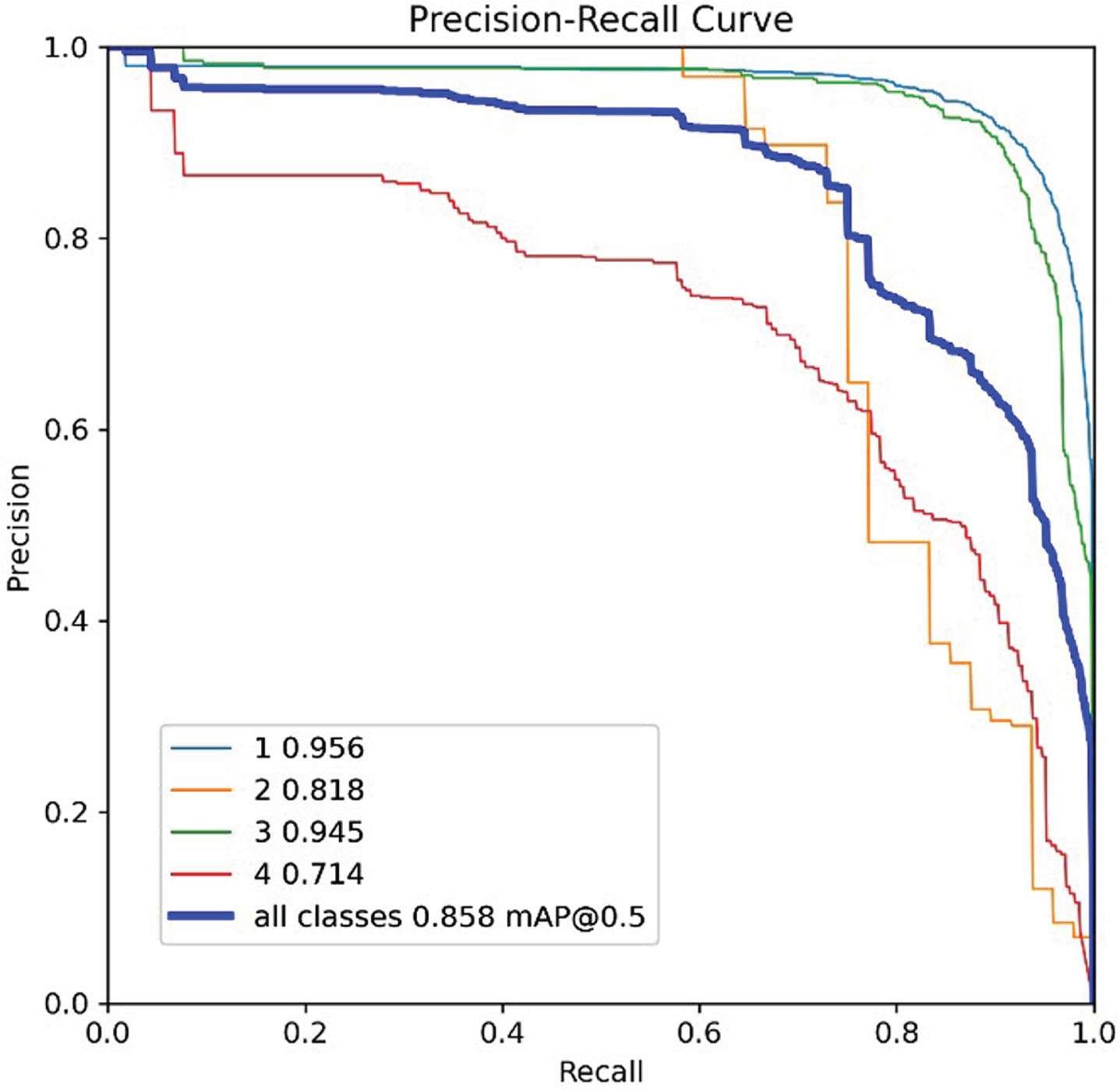
Result of precision-recall curve.
The incorporation of precision, recall, mAP (mean Average Precision), and accuracy rate metrics in the evaluation of the YOLOv8 vehicle detection model in aerial images reflects a comprehensive and quantitative analysis. To address the call for highlighting more physical aspects in the results and discussion section, we can delve into the practical implications of these metrics, emphasizing how the model’s precision and recall contribute to real-world scenarios, its ability to accurately locate vehicles, and the overall impact on the effectiveness of surveillance systems in physical environments. This approach ensures a more grounded and tangible discussion that directly relates to the practical applications of the research.
A confusion matrix is a table that summarizes the performance of a classification model by presenting the predicted class labels against the actual class labels. It provides a comprehensive breakdown of how the model’s predictions align with the ground truth, particularly in multi-class scenarios. The normalized confusion matrix is obtained by dividing the counts in each cell of the confusion matrix by the total number of instances in that class. This provides a percentage-based view of the classification performance, enabling us to better understand the relative distribution of errors across classes. The confusion matrix and its normalized version are crucial tools for evaluating the efficiency of a YOLOv8 model for vehicle detection:
Comparison of models
This section presents a comprehensive comparison of different versions of YOLO models. This comparison justifies why the proposed method in this study is used, the YOLOv8. As inspired by [41], two graphs provide this comparison of various versions of You Only Look Once (YOLO) models, specifically YoOLOv8, YOLOv7, YOLOv6, and YOLOv5. These models have different releases denoted as n, s, m, l, and x, with the releases ordered by their model size.
As shown in Fig. 7, in the first graph, the comparison is conducted based on two key aspects: the number of parameters in the models and their mean Average Precision (mAP) performance metrics. The results depicted in the graph show that across all releases, YOLOv8 consistently outperforms the other models in terms of mAP. Following YOLOv8, YOLOv6 ranks second in mAP performance. It’s worth noting that even in the “l” and “x” releases of YOLOv7, where the model sizes are larger, YOLOv8 still demonstrates better mAP results. YOLOv5, on the other hand, achieves the lowest mAP compared to the other models across all releases.

Comparison of different versions of YOLO models.
Moving on to the second graph, this comparison centers around the latency (processing speed) and mAP. Similarly, to the first graph, YOLOv8 exhibits superior performance compared to the other models across various releases. In terms of latency and mAP trade-off, YOLOv8 maintains its lead. This indicates that YOLOv8 manages to strike a better balance between accuracy (mAP) and processing speed (latency) compared to its counterparts. As a result, both graphs consistently highlight that YOLOv8 stands out as the top performer among YoOLOv8, YOLOv7, YOLOv6, and YOLOv5 across different releases and metrics. It consistently achieves better mAP performance and demonstrates an advantageous trade-off between accuracy and latency when compared to the other models. This suggests that YOLOv8 is the model of choice when seeking enhanced performance in object detection tasks.
As presented above and as depicted in Figs. 3 and 4, showcase the YOLOv8 model’s remarkable effectiveness in the task of vehicle detection. The discerning detections of vehicles in the validation set, as illustrated in Fig. 3, emphasize the model’s high accuracy and reliability. The visual alignment between the model’s predictions and the actual vehicles reinforces its competence and credibility for real-world applications, particularly in surveillance scenarios requiring precise vehicle identification. The thorough experimental design and execution contribute to a robust validation of the YOLOv8 model, establishing its capability to excel in intricate vehicle detection tasks.
The insights gained from the experimental results, particularly the validation graphs in Fig. 4, provide a comprehensive understanding of the YOLOv8 model’s training dynamics. The diminishing validation losses, including box loss, object loss, and class loss, indicate the model’s progress towards improved accuracy. Strategic observations of these graphs become imperative for ensuring an accurate model. Techniques such as early stopping, hyperparameter tuning, and data augmentation are highlighted as essential strategies to refine the model’s learning trajectory. The validation graphs serve as a roadmap, guiding informed adjustments throughout the training process for cultivating a precise YOLOv8 model for vehicle detection.
The precision and recall metrics, discussed in Section 4.2, offer a quantitative assessment of the YOLOv8 model’s performance. Achieving a precision of 93% and a recall of 98% signifies the model’s exceptional capability in accurately detecting and locating vehicles in aerial images. The mAP metric, averaging precision across different confidence thresholds, further validates the model’s accuracy, with a reported value of 85.8%. Class-specific results indicate high precision within each class, emphasizing the model’s proficiency across a variety of vehicle types. These metrics collectively reinforce the YOLOv8 model’s effectiveness in vehicle detection.
The incorporation of a confusion matrix, as discussed in Section 4.3, adds depth to the evaluation by providing insights into classification performance. This matrix aids in understanding where the model succeeds and where improvements can be made. It facilitates the identification of error patterns, class-specific performance, and targeted improvements, ensuring a thorough assessment of the YOLOv8 model’s efficiency in recognizing different vehicle classes.
The comparative analysis of different YOLO models in Section 4.4 underscores the superiority of YOLOv8. Figure 7 highlights that YOLOv8 consistently outperforms YOLOv7, YOLOv6, and YOLOv5 in terms of mean Average Precision (mAP) across various releases. The model demonstrates superior performance not only in accuracy but also in striking a favorable balance between accuracy and processing speed (latency). This suggests that YOLOv8 stands as the model of choice for enhanced performance in object detection tasks.
As result, this study presents an effective method for vehicle detection in aerial images using a Deep Neural Network with the YOLOv8 model. The meticulous construction of the model, coupled with thorough experiments and strategic observations, has yielded a highly accurate and reliable system for identifying and precisely locating vehicles. The evaluation metrics, including precision, recall, mAP, and the confusion matrix, provide a comprehensive understanding of the model’s performance. The comparison with other YOLO models further establishes YOLOv8 as the top performer, demonstrating its superiority in accuracy and processing speed. The proposed method showcases not only technical excellence but also practical applicability in real-world surveillance scenarios, affirming its effectiveness in the realm of vehicle detection from aerial images.
Conclusion
This research addresses the pressing issue of vehicle detection in aerial images within surveillance systems, emphasizing the use of advanced deep-learning techniques that surpass traditional methods. Despite advancements, the persistent challenge of computational complexity arises due to the diverse visual characteristics of vehicles. To tackle this obstacle, we propose a YOLOv8-based lightweight model, striking a balance between precision and efficiency to enable real-time functionality. The model undergoes training and evaluation on a standardized dataset, demonstrating its ability to achieve accurate vehicle detection while significantly reducing computational costs. These findings present a practical approach to addressing the intricacies of real-world aerial surveillance scenarios. The motivation behind this study lies in the need for effective vehicle detection methods, considering the limitations of existing techniques. Our aim is to introduce a lightweight model that maintains high accuracy while minimizing computational demands. The methodology involves implementing and testing the proposed YOLOv8-based model on a standardized dataset to ensure reliability and effectiveness.The contributions of this research are twofold. Firstly, it introduces a novel lightweight YOLOv8-based model, showcasing its potential for real-time vehicle detection in aerial images. Secondly, the study provides insights into addressing the computational challenges associated with diverse vehicle appearances. The proposed model offers a pragmatic solution, opening avenues for future research in two key areas. Future research directions include exploring refined computation strategies to optimize the efficiency of the lightweight YOLOv8-based model. This may involve investigating techniques such as model quantization, knowledge distillation, or hardware acceleration to preserve accuracy while mitigating computational complexity. Additionally, researchers can delve into enhancing appearance modeling techniques to tackle the intricate challenge of diverse vehicle appearances. By incorporating dynamic adaptations based on attributes like size, orientation, and context, these methods could enhance the model’s capability to handle complex appearance variations, ultimately improving performance in challenging scenarios.