
Abstract
Aiming at the shortcomings of the traditional butterfly optimization algorithm in solving the high-dimensional classification feature selection problem, which has low convergence and is prone to fall into local optimal solutions, a new hybrid butterfly optimization algorithm is proposed, i.e., HBOA-SCV (A novel hybrid butterfly optimization algorithm with sine cosine velocity). The algorithm is applied to solve a high-dimensional classification feature selection problem. Firstly, the algorithm’s global exploration and local exploitation ability can be dynamically balanced by introducing inertia weight coefficients w based on multiple learning strategies. Secondly, using the updated speed position formula of the sine-cosine acceleration strategy, individual butterflies’ autonomous search ability and convergence speed can be further improved. Finally, according to the fitness value of each butterfly individual, the moving step length and direction of the butterfly individual are automatically adjusted better to fit the actual search process of the butterfly individual, increase the search ability in the global range, and avoid the algorithm from falling into the local optimum. To verify the algorithm’s effectiveness, 18 high-dimensional classification numbers are selected to carry out simulation and comparison experiments between HBOA-SCV and traditional BOA algorithm, five improved BOA algorithms and other comparative algorithms for high-dimensional classification data successively. The experimental results show that the average fitness value and classification accuracy of the HBOA-SCV algorithm are better than the comparison algorithm, thus verifying the superiority of the HBOA-SCV algorithm.
Keywords
Introduction
In the past decades, the number of dataset features has increased dramatically with the rapid development of big data technologies [1, 2]. Many irrelevant and redundant features are contained in these high-dimensional datasets. Because irrelevant and redundant features can negatively affect the performance of classification learning algorithms [3]. Dealing with these irrelevant and redundant features poses a significant challenge to data dimensionality reduction techniques.
Data dimensionality reduction techniques [2] include two main categories: feature extraction and feature selection. Feature selection is due to the ability to remove irrelevant and redundant features while retaining relevant original features. Feature selection is due to the ability to remove irrelevant and redundant features while retaining relevant original features. Feature selection usually consists of research in two main categories: data level (filter-based methods) and algorithmic level (wrapper-based methods). Wrapper-based methods have attracted the attention of many researchers because they can usually find the best subset of features that express the original features [4–6].
Metaheuristic algorithms are the most efficient and reliable optimization techniques when solving high-dimensional problems. These algorithms have been widely used for performance improvement in real issues [7]. For example, Whale Optimization Algorithm(WOA) [8], Artificial ecosystem-based optimization(AEO) [9], Equilibrium Optimizer(EO) [10], Artificial gorilla troops optimizer(ATO) [11], Sand Cat swarm optimization(SCSO) [12], Exponential distribution optimizer(EDO) [13]. Recently, meta-heuristic algorithms have been successfully applied to coronavirus disease prediction [14], shop-floor scheduling [15], industrial manufacturing field [16], and photovoltaic model parameter estimation [17].
Due to the excellent performance of meta-heuristic algorithms, many researchers have used them (packing-based methods) to solve feature selection problems. For example, Wang et al. [18] proposed the BChOA algorithm, in which the ChOA algorithm first finds the optimal solution. Then, the optimal feature subset is obtained by binary conversion of the optimal solution through V-type and S-type conversion functions. Long [19] proposed VGHHO. First, the search process is guided by the introduction of velocity operator and inertia weights; second, the cosine function is used to nonlinearized the escape energy parameter E, which achieves a good transition from the exploration phase to the development phase; third, the global optimal solution is obtained by using the refractive opposites learning mechanism; and lastly, it is proved by experiments that the proposed algorithm outperforms other meta-heuristic algorithms.
This paper focuses on the Butterfly optimization algorithm (BOA) [20]. The BOA algorithm is simple to implement, has fewer parameters, and has novel ideas for high dimensional function optimization problems. Compared with other active optimization algorithms proposed in the last few years, the BOA algorithm performs better in finding the optimal solution. It is less affected by the change in dimensionality, which has a more significant research potential. However, it also suffers from the problems of slow convergence speed and poor optimization finding accuracy [21, 22].
Therefore, to solve the feature selection problem in high dimensional datasets, this paper proposes a new variant called A novel hybrid butterfly optimization algorithm with sine cosine velocity (HBOA-SCV). This approach finds the optimal subset of features, which improves the classification task’s accuracy and enhances the algorithm’s convergence performance. Finally, experimental validation is performed on 18 challenging classification datasets. The experimental results show that HBOA-SCV outperforms other packing FS techniques in terms of convergence performance and classification accuracy (Butterfly optimization algorithm(BOA) [20] BBOA [23], a modified BOA(PIL-BOA) [24], Enhanced Artificial Ecosystem-based Optimization(EAEO) [25],backtracking search algorithm driven by generalized mean position (GMPBSA) [26], Information-Exchanged Gaussian AOA with Quasi-Opposition learning (IEGQO-AOA) [27] adaptive opposition slime mould algorithm (AOSMA) [28],a time-varying number of leaders and followers binary Salp Swarm Algorithm (TVBSSA) [29], Artificial Bee Colony (ABC) algorithm [30],Slime mould algorithm(SMA) [31], bald eagle search optimization algorithm(BES) [32], Generalized normal distribution optimization(GNDO) [33], Aquila Optimizer (AO) [34]).
The main contributions of the research are summarized below: The HBOA-SCV algorithm preserves the framework of the basic GOA algorithm and only introduces new operators. By introducing the inertia weights w, the algorithm’s ability to regulate and control the global exploration and local mining. The search centre of gravity of the butterfly optimization algorithm is dynamically adjusted using a velocity-based position update equation. In this way, butterfly individuals can better avoid falling into local optimal solutions during the search process, thus improving the convergence performance of the algorithm. Enhancing population diversity using an adaptive butterfly individual position update equation strategy. By adaptively adjusting the step size and direction of an individual’s movement, the variety of the population can be increased, allowing the algorithm better to balance the processes of global exploration and local mining. The greedy mechanism is introduced so that the target position can lead and reduce the probability of the algorithm falling into a locally optimal solution. With this strategy, we can increase the ability to explore the global optimal solution and thus obtain better optimization results.
The rest of the paper is organized as follows. Section 2 summarizes and analyses the limitations of previous related studies. Section 3 is a brief description of the butterfly optimization algorithm and particle swarm algorithm. Section 4 the proposed new algorithm (HBOA-SCV), describes the implementation principle of HBOA-SCV. Section 5 describes in detail the steps of implementing the HBOA-SCV algorithm. Section 6 experimental design and result analysis. Finally, summary and future work outlook.
Related work
Feature selection is to select the most valuable features from the original high-dimensional data, preserving the physical characteristics of the original features. Recently, many feature selection algorithms have been proposed and applied to diagnosis, classification, pattern recognition, and data mining in the big data field [35–38]. Table 1 lists the recent feature selection algorithm studies.
Previous studies in the literature
Previous studies in the literature
Among the filtered feature selection algorithms, the WRRFS algorithm is proposed by Zhang [39]. The algorithm uses mutual information to calculate feature correlations and redundancy between features. Secondly, calculate the mean of the feature correlation terms and the parameter weights of the conditional feature correlation terms are dynamically adjusted using the standard deviation. Zhou et al. [5] proposed the CCMI algorithm, which improves classification accuracy by introducing the correlation coefficient and combining the correlation coefficient and mutual information to measure the relationship between features. Macedo et al. [40] proposed a DMIM algorithm that applies maximization to inter-feature and class-related redundancy to overcome the complementarity penalty between features and class labels. Experimental results demonstrate that the method can effectively extract the optimal subset of features.
Among the wrapper style feature selection algorithms, Grey Wolf Optimizer (GWO) [41] and its binary variant (BGWO) [42] have been widely used in feature selection work. Zhang [43] proposed a binary version of the local opposing learning golden sinegrey wolf optimization algorithm (OGGWO); firstly, the OGGWO algorithm uses local opposing learning mapping to initialize the positions of individual grey wolves to enrich population diversity and improve convergence speed. Secondly, mix the golden sine algorithm and the grey wolf optimization algorithm to control the direction and distance of α wolves by using the golden mean coefficient to improve the autonomous search ability of individual grey wolves and avoid the algorithm from falling into the local optimum. Finally, the updated grey wolf position is binary converted by pre-setting the threshold value to reduce the feature subsets size and improve the classification effect. Dhal et al. [44] proposed a hybrid two-stage multi-objective feature selection method based on Particle Swarm Optimization (PSO)[45] and Grey Wolf Optimization (GWO). The technique minimizes the classification error rate while reducing the number of selected features. Song et al. [46] proposed the SS-PSO algorithm, which combines collaborative feature clustering and an integrated agent-assisted PSO approach by partitioning the sample and feature space simultaneously. The algorithm effectively reduces the computational cost. Jiang et al. [47] proposed a grey wolf optimization algorithm based on group competition and a balancing mechanism. In this algorithm, the group competition mechanism changes the number of leading wolves from three to six. Secondly, a balancing tool of exploration and exploitation is designed to enhance the local optimal avoidance ability.
Wang et al. [18] proposed the BChOA algorithm, in which the ChOA algorithm first finds the optimal solution; then, the optimal feature subset is obtained by binary conversion of the optimal solution by the V-type and S-type conversion functions. Long et al. [23] proposed the BBOA algorithm. Firstly, dynamic inertia weights based on a Logistic model are introduced to modify the position update equation. Secondly, the convergence speed is improved by adversarial learning to enhance classification accuracy. Long et al. [24] proposed the PIL-BOA algorithm, which first designs an improved position update equation by introducing a globally optimal solution, effectively improving the utilization capability and solution accuracy. Secondly, a pinhole imaging learning strategy efficiently searches for unknown regions and avoids premature convergence. Bo et al. [48] proposed the GSOBL-ChOA algorithm, where the convergence rate is first accelerated by applying the OBL technique in the exploration phase. Finally, a greedy selection strategy is used to find the optimal solution. Eluri et al. [49] proposed the HBFS-GA algorithm. The algorithm incorporates the FSA algorithm into the GA algorithm. Then, eight conversion functions are used to map continuous values to binary values. The experimental results proved that the method is effective. Bacanin et al. [50] proposed the QRLAOA-FS algorithm. This algorithm improves classification performance and reduces feature dimensionality through firefly search and quasi-reflective learning mechanisms. Gad et al. [51] proposed the iBSSA algorithm, which firstly, improves the local exploration capability by using the local search algorithm; secondly, improves the global search capability by using the roaming agent approach; and lastly, obtains the optimal feature subset by binary conversion of the optimal solution by using the V-Type and S-transformationfunctions.
Although the metaheuristic algorithms mentioned above improve the search efficiency and increase the convergence speed, they still need to improve on the problems of imbalance between exploration and exploitation, poor quality of solution, and easy fall into local optimality. As we know from our study, enhancing local exploration and global search capability, increasing population diversity, and finding optimal solutions have become essential in studying meta-heuristic algorithms in the high-dimensional optimization process [52]. Therefore, this paper focuses on enhancing, improving, and optimizing the BOA algorithm’s global survey and local mining capabilities while applying it to high-dimensional classification feature selectionproblems.
Butterfly optimization algorithm
The butterfly optimization algorithm is a new swarm intelligence algorithm proposed by Arora et al. [20]. In the butterfly algorithm, butterflies can correct themselves to carry out their flight path based on the strength of the scent concentration. Since butterflies are affected by various factors during foraging, a fixed probability P is used to control the search pattern of butterflies. When greater than P, the butterfly can sense the scent from other butterflies in the air and fly towards the butterfly with the most aromatic scent to perform a global search pattern. When smaller than P, the butterfly cannot sense the smell from other butterflies in the air and flies randomly to the butterfly with the most aromatic scent, thus executing the local search mode.
Therefore, in the global search mode, the butterfly moves towards the optimal solution g* with the following formula:
In the local search mode, the formula is as follows:
Where
where I is the stimulus intensity. a is the power index of the dependent sensory modality. ct+1 is the sensory modality strength, which is calculated as follows:
1: Input:the population size N;the maximum iterations T
2: Random initialization of butterfly populations in the D dimensional search space
3: Initialization parameters P,c, and α
4:
5: Calculate the fitness value for each butterfly f (X i ) , i = 1, 2, ⋯ , N
6:
7:
8: Generate a random number rand in [0, 1]
9:
10: According to Equation (1), Update the position of
11:
12: According to Equation (2), Update the position of
13:
14:
15: Calculate the fitness value for each butterfly f (X i ) , i = 1, 2, ⋯ , N
16:
17: According to Equation (4), Update the values of c
18: t = t + 1
19:
20: Output:the best value X best
Kennedy et al. [45] proposed Particle swarm optimization (PSO). In PSO, each particle has its position and velocity. In each iteration, the particle gradually approaches the optimal solution based on the guidance of the individual historical optimal position and the global optimal position, as well as the velocity adjustment. This search process enables PSO to find the optimal solution in the search space efficiently. Its velocity and position are updated as follows:
From Equations (1) and (2), we can see that the two-stage position update strategy with fixed probability makes most butterfly individuals receive the global optimal position information more often. This will lead to the following two problems: In the middle and late iterations, butterfly individuals gather near the current optimal butterfly position, decreasing the diversity of the butterfly population. If the current optimal butterfly individuals fall into the local optimum, it is difficult for the aggregated butterfly population to jump out of the local extreme point. In the late iteration, the diversity of the population decreases, and even the overlap of multiple butterfly positions occurs, which leads to the BOA quickly falling into the local optimum, and the convergence accuracy is low. From the above, adopting a two-stage position update strategy is not conducive to maintaining the diversity of the population.
Based on the no free lunch theorem [53], no swarm intelligence algorithm can solve various optimization problems at the same time. Therefore, the HBOA-SCV algorithm is designed in this section. The algorithm does not change the structure of the BOA algorithm but improves it by introducing three modification strategies. These three modification strategies are explained in detail in the following subsections.
Introduction of inertia weights
In meta-heuristic algorithms, inertia weights can regulate and control the algorithm’s global survey and local mining capabilities. To address the shortcomings of the basic butterfly algorithm in terms of slow convergence speed for complex functions and low accuracy in finding the best. The PIL-BOA algorithm proposed by Long et al. [24] uses a single learning strategy to modify Equation (1) and (2). While there are many uncertainties in the natural butterfly foraging process, using a single method cannot reflect the natural process of butterfly foraging. Therefore, how to solve the inertia weights becomes a vital research direction Long et al. [23, 54]. Many kinds of literature have used multi-learning strategies as an improvement technique and achieved good results, such as APSO [55] and LOPSO[56], and the experimental results proved the effectiveness of the improvement strategies in the APSO and LOPSO algorithms. In this paper, the APSO and LOPSO algorithms are influenced by the multi-learning strategy approach to inertia weights, which is formulated as follows:
Where
From Equations (1)(2)(3)(4), the positions of individual butterflies during iterative updating are affected by the current position information of different individuals and the optimal position information of the group, and the positions of individual butterflies are adjusted by the exchange of information of the butterfly group. This mechanism makes the butterfly optimization algorithm unable to find the optimal solution effectively. Therefore, how to solve this problem is an important research direction for the position update equation [22, 58].
From Equation (5), b1 and b2 are used to adjust the individual optimal position (p
best
) and the group optimal position (g
best
), respectively. Therefore, these two parameters play an important role in finding the optimal solution quickly and accurately. Meng [59]argued that when b1 is larger than b2, the PSO algorithm has better global search capability. When b1 is smaller than b2, the PSO algorithm has better local search capability. Chen [60] suggest that the ideal state of the PSO algorithm is: the population can traverse the whole search space as much as possible in the early stage. In the later stage, it can search the specified region. Through the above description, this paper proposes a sine-cosine acceleration adjustment strategy to adjust the values of b1 and b2. When the number of iterations is increasing, the values of b1 and b2 will change dynamically. Among, b1 = cos(r6) , b2 = sin(r6). Therefore, the velocity position update formula of the sine-cosine acceleration strategy is:
The global exploration and local mining processes in the butterfly optimisation algorithm are contradictory, and their equilibrium is not easy to find [61]. From Equation (6), the new position mainly depends on the position of the last iteration and the current velocity. To better balance the global exploration process and local mining process, the quality of the individual is improved. Therefore, this paper combines Equation (6) and introduces the variable of dynamic weights to strengthen the butterfly individual position update formula in the process of butterfly individual position update:
In Equation (11),
In Equation (12), μ denotes the mean fitness value of individual butterflies.
Algorithmic implementation steps
The Improved Butterfly Optimization (HBOA-SCV) algorithm is shown in Algorithm 2 and Fig. 1 HBOA-SCV algorithm framework.From Algorithm 2, compared with the basic BOA algorithm, the HBOA-SCV algorithm has the following characteristics: The HBOA-SCV algorithm does not change the framework of the basic BOA algorithm and only accelerates the convergence of the BOA algorithm by introducing new operators. By introducing the inertia weights w, the algorithm’s ability to regulate and control the global exploration and local mining. Through the velocity-based position updating equation, the Dynamically adjusts the centre of gravity of the butterfly optimization algorithm search. Use the adaptive butterfly individual position update equation strategy, enhance the diversity of the population, and adaptively balance the global exploration process and the local mining process during the iteration process of the algorithm. Through the greedy mechanism, allow the target position to give full play to its guiding role, reduce the probability of the algorithm falling into the local optimum, and thus obtain the global optimal solution.
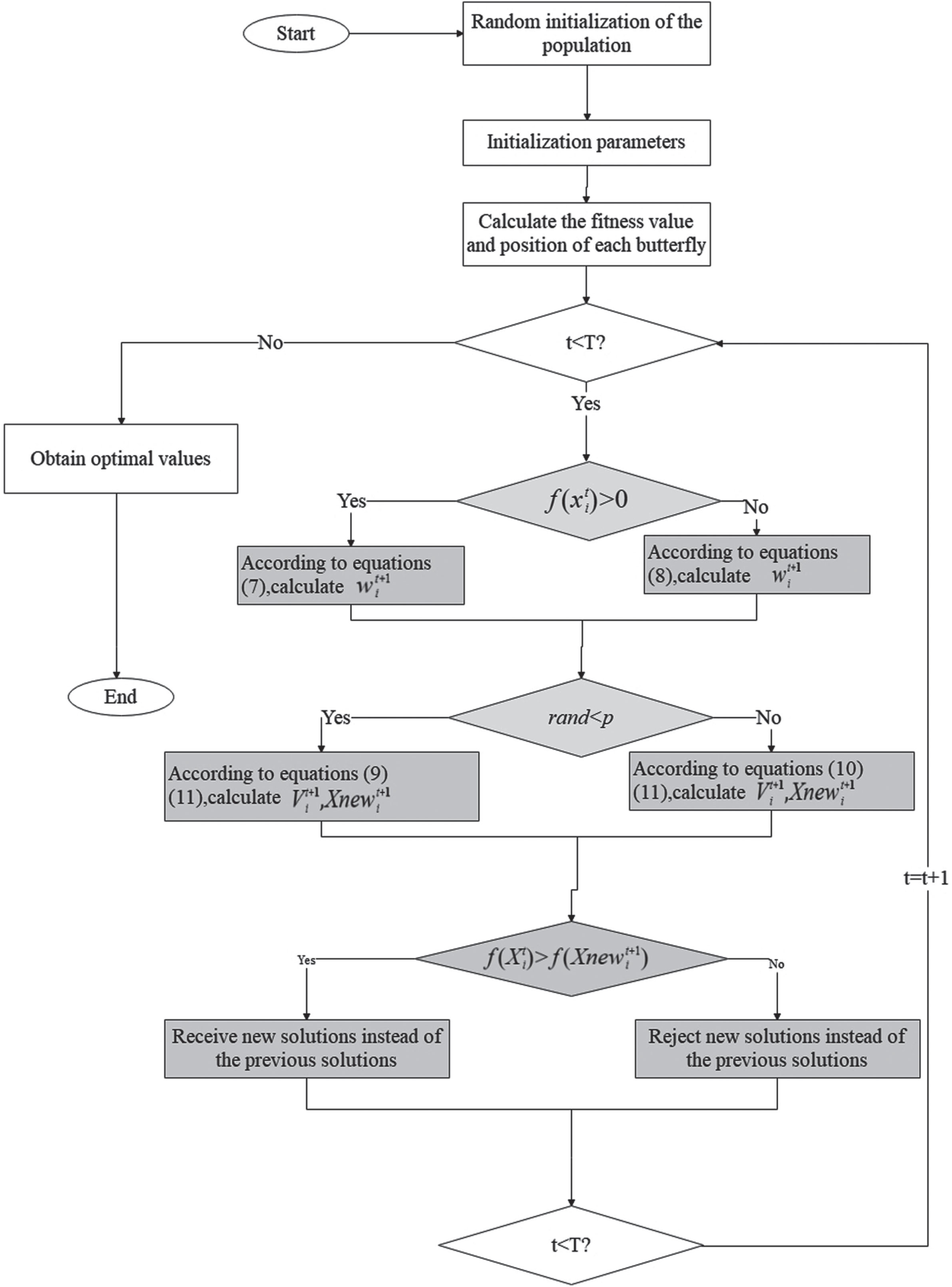
HBOA-SCV algorithmic framework.
1: Input:the population size N;the maximum iterations T
2: Random initialization of butterfly populations in the D dimensional search space
3: Initialization parameters P,c, and α
4: Initializetion the velocity matrix of the butterfly V i
5:
6: Calculate the fitness value for each butterfly f (X i ) , i = 1, 2, ⋯ , N
7:
8:
9: Generate a random number rand in [0, 1]
10:
11: According to Equation (7), Update the value of
12:
13: According to Equation (8), Update the value of
14:
15:
16:
17: According to Equation (9), Calculate the position of
18: According to Equation (11), Update the position of
19:
20: According to Equation (10), Calculate the position of
21: According to Equation (11), Update the position of
22:
23:
24:
25:
26:
27:
28:
29:
30: Calculate the fitness value for each butterfly f (X i ) , i = 1, 2, ⋯ , N
31:
32: According to Equation (4), Update the values of c
33: t = t + 1
34:
35: Output:the best value X best
Feature selection is a multi-objective optimization problem with two conflicting objectives: the minimum subset of features and higher classification accuracy. A solution is more desirable if fewer features are selected with higher classification accuracy. Therefore, the goal is to determine the balance between classification accuracy and the number of features. Thus, this paper uses linear weighting to combine the two objectives into a single objective function. In evaluating the butterfly optimization algorithm, the following fitness function is used to assess the solution vector:
To provide a comprehensive assessment of the performance of the HBOA-SCV algorithm, the following three different analyses were used in this experiment: First, we compare the HBOA-SCV algorithm with the original Butterfly optimization algorithm(BOA), BBOA, and PIL-BOA for performance comparison. By comparing their feature selection results on multiple categorical datasets, we evaluate the superiority of HBOA-SCV. Secondly, we compare HBOA-SCV with five recently proposed population-based meta-heuristic algorithms, including ABC, SMA, BES, GNDO, and AO. By performing feature selection on the same dataset and comparing their performance metrics, we evaluate the relative merits of HBOA-SCV. Finally, we also consider other hybrid methods recently reported in the related literature, including EAEO, GMPBSA, IEGQO-AOA, AOSMA, and TVBSSA, and validate the effectiveness of the proposed HBOA-SCV technique. By comparing the feature selection results of these hybrid methods on multiple categorical datasets, we can further validate the performance of HBOA-SCV. When analyzing the performance of comparative algorithms in experiments, it is expected to consider the mean and standard deviation values of classification accuracy, the mean value of fitness, the size of the feature selection dataset, the CPU running time, and the Wilcoxon rank-sum test used for statistical validation.
Standard test data set and experimental environment
To validate the effectiveness of the HBOA-SCV algorithm, in this paper, we have chosen to pass 18 widely known high-dimensional datasets with different difficulties (lung_discrete, COIL20, colon,warpAR10P, warpPIE10P, lung, lymphoma, 9_Tumor, TOX_171, Brain_ Tumor_1, Prostate_Tumor_1, Brain_Tumor_2, ALLAML, Carcinom,nci9,11_Tumor, Lung_Cancer, and SMK_CAN_187), a detailed description of these datasets is shown in Table 2. where these 18 datasets contain different sample number, feature number, and class number. The range of samples is from 50 to 3195, the content of features is from 10 to 12533, and the range of classes is from 2 to 11. These datasets are obtained from ASU (http://featureselection.asu.edu/ datasets.php) and the literature [60]. The experimental environment of this paper is an Intel-i7 processor using 16GB RAM, and the simulation software is Python 3.9.
Test data set
Test data set
For each dataset in Table 2, 70% of the samples were randomly selected as training data and 30% as test data. In terms of classification accuracy, KNN is selected as the classifier. To reduce the computational cost and maintain the search efficiency, the population size is uniformly set to 10. For each test dataset, the experiments are executed M times (its value is set to 30 times) to evaluate the feature selection performance of each algorithm. The maximum number of iterations (T) is 100, indicating the current iteration.α = 0.99,β = 0.01.
The pre-set parameters of each algorithm such as HBOA-SCV, BOA, BBOA, PIL-BOA, EAEO, GMPBSA, IEGQO-AOA, AOSMA, TVBSSA, SMA, ABC, BES, GNDO and AO are shown in Table 3.
Parameter settings for the comparison algorithm
Parameter settings for the comparison algorithm
Several metrics are often used when evaluating and interpreting the results of feature selection problems, such as average classification accuracy (ACA), standard deviation (SD), average optimal fitness value (OFV), number of selected features (NSF), etc. Among them, the fitness value is obtained by coordinating to ensure the balance between the number of features and classification accuracy [63].
Average Classification Accuracy: it represents the average of the classification accuracy of the selected feature set, where acc (i) is the i-th classification accuracy, which is calculated as follows.
Standard deviation of classification accuracy: It represents the change in classification accuracy obtained after running the algorithm and is calculated as follows.
To analyze the effect of the improved strategies in 3 on the performance of the algorithms, Table 3 was selected for the experiments. HBOA-SCV is compared with the BOA algorithm using only the inertial weighting strategy (denoted as WBOA), the BOA algorithm using only the position updating equation of velocity (characterized as VBOA), and the BOA algorithm using only the adaptive butterfly individual position updating equation (denoted as ABOA). The parameter settings for the algorithms are the same as in subsection 6.2.
The comparison results from Table 4 show that using only inertial weighting strategies or only adaptive butterfly individual position update equations is of limited help in improving the performance of the BOA algorithm. However, it is experimentally confirmed that the position update equation using velocity is an effective operator in the HBOA-SCV algorithm. The VBOA algorithm only significantly outperforms the HBOA-SCV algorithm regarding classification accuracy and average adaptation values on the lung, TOX-171, Brain_Tumor_1 and 11_Tumor datasets. By combining the results in Tables 4, 5, and 6, we can conclude that the HBOA-SCV algorithm can effectively improve the BOA algorithm, increase its global investigation and local mining ability, accelerate the convergence speed, get rid of the local optimum, and achieve higher classification accuracy and smaller optimal adaptation value.
Comparison of classification accuracy and average fitness value test results of four algorithms
Comparison of classification accuracy and average fitness value test results of four algorithms
Average classification accuracy and variance of the variant butterfly optimization algorithm
Optimal fitness values and number of selected features for the variant butterfly optimization algorithm
The HBOA-SCV algorithm is used to compare the performance of classification accuracy, standard deviation, fitness value, and selected feature subset with BOA, BBOA, and PIL-BOA in 18 classified datasets. The advantages and disadvantages of the performance of the four algorithms are compared and analyzed by analyzing the results of different performance measures of the four algorithms. To maintain the fairness of the experiments, the four algorithms use the same experimental parameters, and the detailed parameter settings are shown in Table 3. For each classification dataset, HBOA-SCV, BOA, BBOA, and PIL-BOA are run independently 30 times. The average classification accuracy (ACA), standard deviation (STD), standard deviation (STD), optimal fitness value (OFV), and number of selected features (NSF), the specific results are shown in Tables 5 and 6.
As seen from Table 5, HBOA-SCV is an effective algorithm that outperforms the other compared algorithms on all 17 classification datasets. He just on lymphoma HBOA-SCV and BOA algorithm show as good classification accuracy. This indicates that HBOA-SCV has a significant advantage over standard BOA, BBOA and PIL-BOA regarding classification accuracy. In terms of standard deviation, the average standard deviation of HBOA-SCV, BOA, BBOA and PIL-BOA are 1.72E-02, 1.80E-02, 2.19E-02 and 2.60E-02, respectively, which indicates that HBOA-SCV has better stability, which can improve the ability of BOA algorithms to explore globally and develop locally, and dynamically adjust the balance between them. Adjust the balance between them.
As can be seen from Table 6, in terms of fitness values, the average fitness values of HBOA-SCV, BOA, BBOA, and PIL-BOA are 9.07E-02,1.12E-01,1.37E-01 and 1.82E-01 respectively. The minimum fitness value is obtained for HBOA-SCV. Regarding the number of selected features, the average number of selected features of HBOA-SCV, BOA, BBOA, and PIL-BOA are 451.75,318.70,303.62, and 481.98, respectively. The experimental results show that the HBOA-SCV algorithm performs better than the PIL-BOA algorithm in terms of the subset of selected features. However, there is still a particular gap between it and the BOA and BBOA algorithms. There exists a specific hole. This means that the ability of the HBOA-SCV algorithm still needs to be further improved regarding the selected feature subset.
Comparison of HBOA-SCV with improved meta-heuristic algorithms
HBOA-SCV is compared with EAEO, GMPBSA, IEGQO-AOA, AOSMA, and TVBSSA for classification accuracy and optimal fitness values. The advantages and disadvantages of the performance of the six algorithms are compared and analyzed by analyzing the results of different performance measures of the six algorithms. To keep the experiment fair, all five algorithms use the optimal fitness function evaluation number of 1000 (population size N = 10, maximum iteration number T = 100); the detailed parameter settings are shown in Table 3. The specific results of the comparison are shown in Tables 7 and 8.
Average classification accuracy
Average classification accuracy
Optimal fitness values
From Table 7, it can be seen that in terms of classification accuracy, the HBOA-SCV algorithm on the different classification datasets of lung_discrete, colon,warpAR10P,warpPIE10P, lung, lymphoma, 9_Tumor, Brain_Tumor_1, Prostate_Tumor_1, Brain_Tumor _2, ALLAML, Carcinom,11_Tumor, SMK_CAN_187, nci9 classification accuracy is optimal on different classification datasets. The HBOA-SCV algorithm is not as good as the IEGQO-AOA algorithm in classification accuracy on COIL20, TOX_171, and Lung_Cancer datasets. The average accuracy of HBOA-SCV with EAEO, GMPBSA, IEGQO-AOA, AOSMA, and TVBSSA on 18 datasets is 90.90%, 87.44%,77.92%, 86.95%, 87.46%, and 82.12% respectively. The HBOA-SCV algorithm obtained the highest values. These indicate that HBOA-SCV has a significant advantage over other algorithms in classification performance.
As can be seen from Table 8, in terms of optimal fitness values, the average optimal fitness values of HBOA-SCV with EAEO, GMPBSA, IEGQO-AOA, AOSMA, and TVBSSA on the 18 datasets are 9.07E-02,1.26E-01,2.24E-01,1.31E-01,1.24E-01 and 1.80E-01 respectively. The HBOA-SCV algorithm obtains the optimal fitness values. The HBOA-SCV algorithm is optimal on all 17 high-dimensional datasets. The HBOA-SCV algorithm is not as good as the IEGQO-AOA algorithm regarding optimal fitness value on the TOX_171 dataset. Among the six algorithms, the feature selection method proposed by HBOA-SCV can improve the classification performance and enhance the convergence of the BOA algorithm.
HBOA-SCV is used to compare the classification accuracy and fitness value performance with SMA, ABC, BES, GNDO, and AO. The advantages and disadvantages of the performance of the six algorithms are compared and analyzed by analyzing the results of different performance measures of the six algorithms. All five algorithms use the optimal fitness function evaluation number of 1000 (population size N = 10, maximum iteration number T = 100). Parameter settings are shown in Table 3.
From Table 9, the HBOA-SCV algorithm outperforms the other compared algorithms on the 15 classification datasets, which indicates that it is completely superior in terms of classification accuracy. From Table 10, the HBOA-SCV algorithm outperforms the other comparative algorithms on lung_discrete, COIL20, colon, warpPIE10P, lymphoma, TOX_171, Brain_Tumor_1, Prostate_Tumor_1, ALLAML, Brain_Tumor_2, Carcinom,11_Tumor, Lung_Cancer, SMK_CAN_187, nci9 high-dimensional datasets outperform the other compared algorithms. The HBOA-SCV algorithm has some gap with the SMA, BES, and GNDO algorithms on the warpAR10P, lung, and 9_Tumor datasets respectively. In conclusion, among the six algorithms, HBOA-SCV has obvious advantages in convergence speed and accuracy and shows better performance on high-dimensional problems.
Average classification accuracy
Average classification accuracy
Optimal fitness values
Graphical illustrations can provide a more intuitive comparison of the robustness and stability of the HBOA-SCV algorithm relative to other algorithms. Figure 2 illustrates the gradual convergence curves in various datasets.
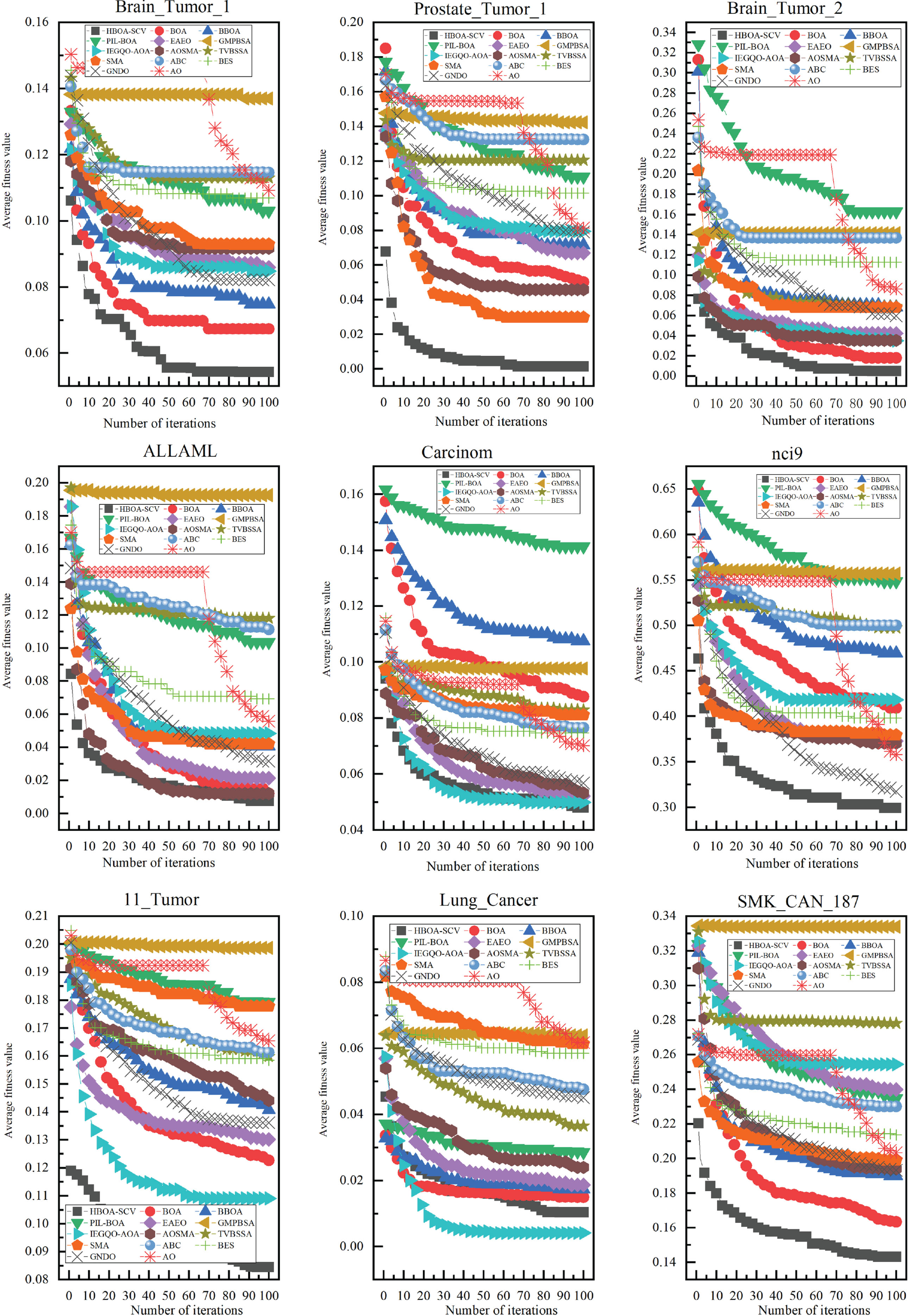
Convergence curves of different algorithms.
Since the HBOA-SCV algorithm worked similarly on the other test datasets, only 9 test datasets were selected for presentation.Where Brain_Tumor_1, Prostate_Tumor_1,Brain_Tumor_2, ALLAML, Carcinom, nci9 and 11_Tumor, etc., highlighting the performance advantages of HBOA-SCV over other algorithms. By comparing the shapes and trends of the curves, it is observed that HBOA-SCV approaches the optimal solution faster. For instance,On the Brain_Tumor_1 datasets, the HBOA-SCV algorithm reaches the optimal fitness value at the beginning of the iteration. These results demonstrate that the HBOA-SCV algorithm can rapidly find high-quality feature subsets within a limited number of iterations. The findings from Tables 5, 8, and 9 further support the claim that the HBOA-SCV algorithm excels in quickly finding optimal solutions in high-dimensional feature spaces. Overall, the HBOA-SCV algorithm exhibits superior feature selection performance across different datasets.
We use a histogram approach to compare the average classification accuracy properties of the HBOA-SCV algorithm with other algorithms. As can be seen in Figures 3 and Table 5 to 9. Since the HBOA-SCV algorithm worked similarly on the other test datasets, only 9 test datasets were selected for presentation.on the lung_discrete, colon, warpPIE10P, lymphoma datasets, the HBOA-SCV algorithm has the highest average classification accuracy. The IEGQO-AOA algorithm has the highest average classification accuracy on the COIL20 and TOX- 171. On the warpAR10P dataset, the average classification accuracy of the SMA algorithm is the highest. On the lung and 9_Tumor datasets, the average classification accuracy of the GNDO algorithm is the highest. Finally, from the results of Friedman’s ranking statistics test in Fig. 4, HBOA-SCV is ranked first, BOA is ranked second, followed by GNDO, IEGQO-AOA, EAEO, AOSMA, BBOA, SMA, BES, ABC, AO, TVBSSA, PIL-BOA and GMPBSA.
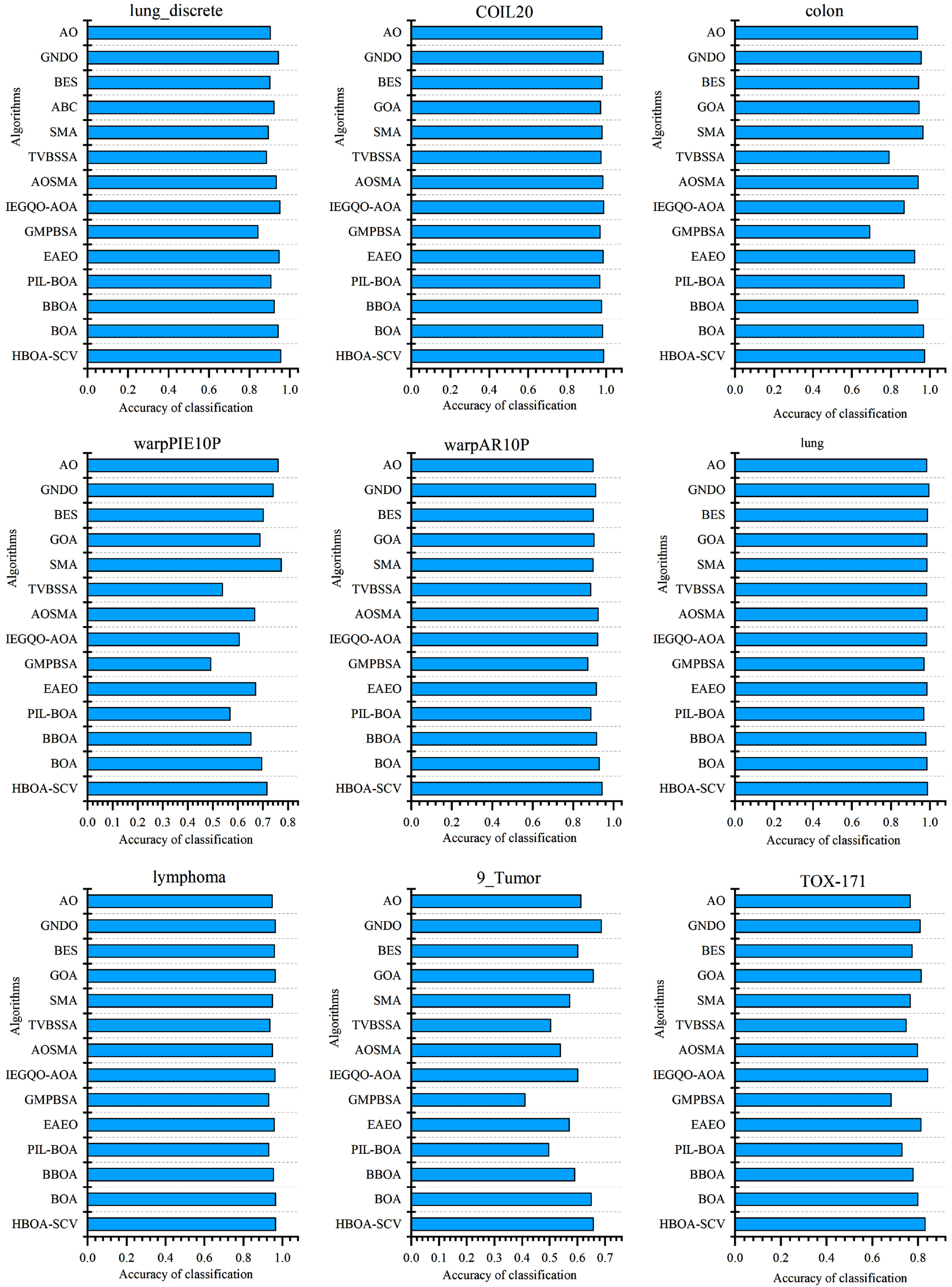
Classification Accuracy of different algorithms.
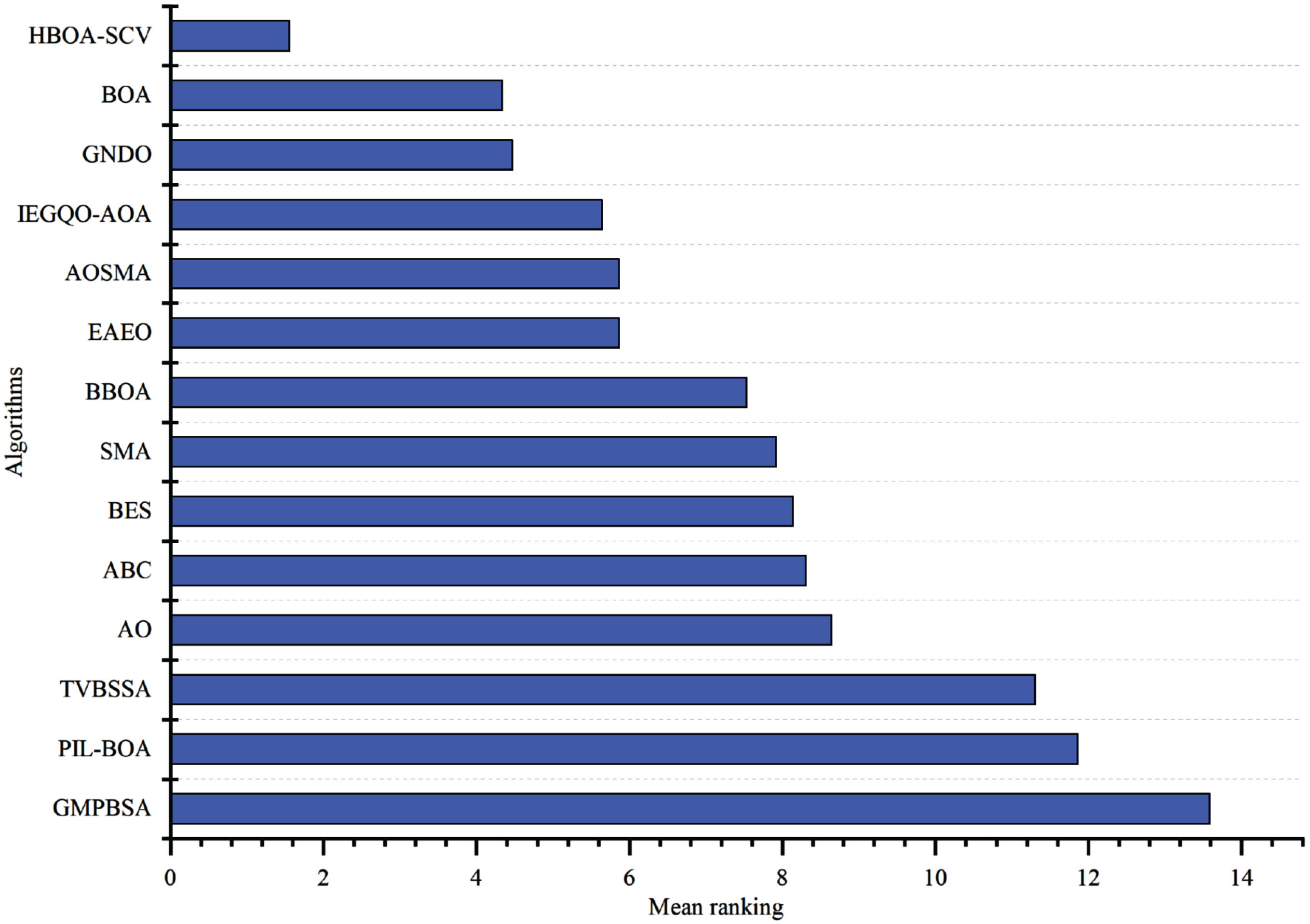
Friedman’s Ranking Test Result of different algorithms.
To analyze the stability performance of HBOA-SCV on high-dimensional datasets, Figure 5 gives the data distribution of 30 experiments on 18 test datasets.The boxplot in Fig. 5 show that HBOA-SCV performs optimally in terms of minimum, quartile (25th percentile), median, quartile (75th percentile), and maximum values and does not fluctuate drastically, resulting in better stability.
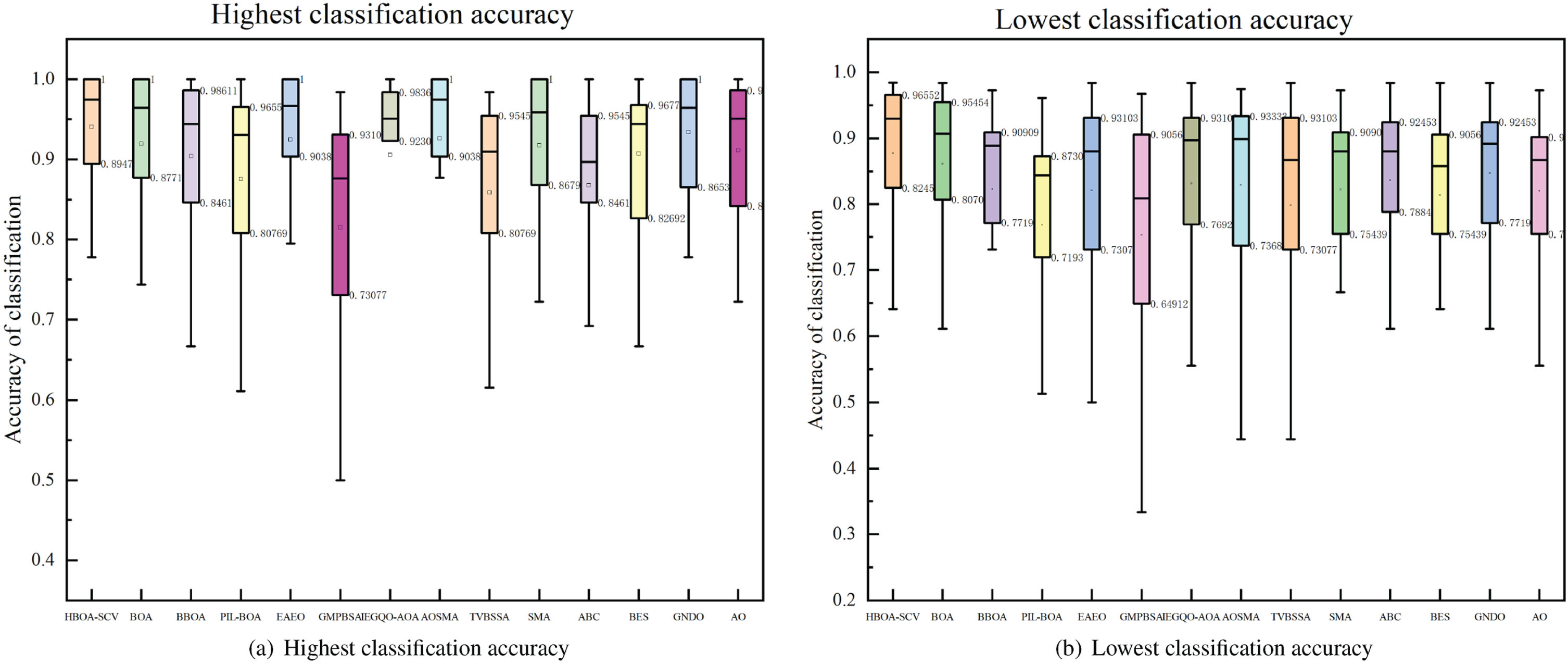
Algorithmic stability analysis
The computational complexity of introducing the inertial weighting mechanism and the adaptive butterfly velocity individual position updating equation strategy are respectively: O (N × T) , O (N × T × D), where T represents the maximum number of iterations, N represents the population size, and D represents the dimensionality of the feature set. Therefore, the proposed HBOA-SCV algorithm in this paper has the same computational complexity as the standard BOA algorithm. The proposed HBOA-SCV algorithm does not introduce additional computational processes. In introducing the inertia weighting mechanism, he only adds Equations (7), (8). In the velocity individual position update equation strategy, it just replaces Equations (1), 2) with Equations (9), (10), (11). Therefore, the proposed HBOA-SCV algorithm performs better than the original BOA algorithm without adding extra computational cost. The comparison algorithms’ running times are shown in Table 11. From Table 11, it can be seen that the running time of the HBOA-SCV algorithm is within the acceptable range.
Running time (/s) of different algorithms
Running time (/s) of different algorithms
To verify the fairness and stability of the HBOA-SCV algorithm. In this section, the Wilcoxon rank sum test is used to confirm whether there is a significant difference in the running results between the HBOA-SCV algorithm and other algorithms. Therefore, the results of each of the 14 algorithms tested independently 30 times on 18 test data are taken as samples; when p> 5 %, it indicates significant variability between the two algorithms being compared. When p< 5 %, it suggests that the optimality finding results of the two algorithms under comparison are the same. Meanwhile, HBOA-SCV is compared with BOA, BBOA, PIL-BOA, EAEO, GMPBSA, IEGQO-AOA, AOSMA, TVBSSA, SMA, ABC, BES, GNDO, and AO, which are denoted as P1, P2, P3, P4, P5, P6, P7, P8, P9, P10, P11, P12 and P13. Table 12 gives the values calculated in the rank sum test of HBOA-SCV with BOA, BBOA, PIL-BOA, EAEO, GMPBSA, IEGQO-AOA, AOSMA, TVBSSA, SMA, ABC, BES, GNDO, and AO for the twelve test data sets.
Wilcoxon rank-sum test of different algorithms
Wilcoxon rank-sum test of different algorithms
As can be seen from Table 12, most of the p-values are much less than 5%, indicating a significant difference between the HBOA-SCV algorithm and the other twelve algorithms. Among them, in the Carcinom dataset, the difference between the HBOA-SCV algorithm and IEGQO-AOA is slight. The Lung_Cancer dataset showed less variability between the HBOA-SCV algorithm and BOA.
The rapid growth of big data has led to increased high-dimensional features, many of which may need to be more relevant or relevant. Removing these redundant features is crucial in machine learning and data mining. Traditional feature selection algorithms often need help identifying and eliminating irrelevant or redundant features.
This research proposes a new hybrid butterfly optimization algorithm with sinusoidal cosine velocity (HBOA-SCV). Firstly, the algorithm introduces inertia weights w to dynamically adjust its global and local mining capabilities. Second, the velocity-position update formula of the sine-cosine acceleration strategy is used to dynamically adjust the centre of gravity in the butterfly optimization algorithm search. Thirdly, the adaptive butterfly individual position update equation strategy enhances population diversity and balances global exploration and local mining capabilities.
To evaluate the effectiveness of the HBOA-SCV algorithm, experiments are conducted on 18 high-dimensional datasets and compared with various other algorithms, including BOA, BBOA, PIL-BOA, EAEO, GMPBSA, IEGQO-AOA, AOSMA, TVBSSA, SMA, ABC, BES, GNDO, and AO algorithms. The experimental results demonstrate that the HBOA-SCV algorithm effectively balances global survey and local mining capabilities, exhibits faster convergence, possesses more vital ability to escape local optima, achieves higher classification accuracy, and has smaller optimal adaptation values. These findings validate the effectiveness of the proposed improvement strategy.Future research directions include: Optimizing the structure of the butterfly optimization algorithm. Integrating the strengths of other intelligent algorithms to enhance performance further. Reducing the dimensionality of selected feature subsets.
Furthermore, it is suggested to verify the effectiveness of the proposed method in a broader range of high-dimensional datasets.
Author contributions
Li Zhang wrote the manuscript, reviewed it, and approved the final version. Xiaobo Chen contributed by discussing the research direction and providing professional opinions and suggestions. She also studied and revised the paper, making significant contributions during the finalization process of the manuscript.
Funding
Key Open Project of Key Laboratory of Data Science and Intelligence Education (Hainan Normal University), Ministry of Education (No.DSIE202305). Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education (Jilin University) (No. 93K172023K08), Supported by “the Fundamental Research Funds for the Central Universities. JLU".
Conflict of interest
The authors declare that he has no competing interests.
Ethics approval and consent to participate
This study does not involve any ethical issues.
Data Availability
The experimental data set selects the world-famous data set (https://ckzixf.github.io/dataset.html, https://ckzixf.github.io/dataset.html and http://featureselection.asu.edu/datasets.php)