
Abstract
Structure learning is the core of graph model Bayesian Network learning, and the current mainstream single search algorithm has problems such as poor learning effect, fuzzy initial network, and easy falling into local optimum. In this paper, we propose a heuristic learning algorithm HC-PSO combining the HC (Hill Climbing) algorithm and PSO (Particle Swarm Optimization) algorithm, which firstly uses HC algorithm to search for locally optimal network structures, takes these networks as the initial networks, then introduces mutation operator and crossover operator, and uses PSO algorithm for global search. Meanwhile, we use the DE (Differential Evolution) strategy to select the mutation operator and crossover operator. Finally, experiments are conducted in four different datasets to calculate BIC (Bayesian Information Criterion) and HD (Hamming Distance), and comparative analysis is made with other algorithms, the structure shows that the HC-PSO algorithm is superior in feasibility and accuracy.
Introduction
Bayesian Network (BN) is a classical probabilistic graphical model, which mainly describes the dependency relationship between random variables with versatility and effectiveness, and is widely used for the intelligent solution of uncertainty problems. BN is capable of transforming data directly into intuitive graphs for inference, and is popular in multiple fields such as risk management [1], medical diagnosis [2], and information fusion [3].
BN research is divided into two parts: structure learning and parameter learning, where structure learning is the basis and core of structural learning of BN. Generally speaking, structure learning methods are divided into three main categories: learning methods based on dependency analysis; methods based on scoring search; and hybrid methods. The first dependency-based learning method determines the BN structure by determining the existence of edges and the direction of the edges through dependency and conditional independence tests between two variables. The classical dependency-based analysis methods are Inferred Causation (IC) algorithm [4] and PC algorithm [5]. The second approach, which is based on scoring search, consists of two parts: the selection of the search strategy and the selection of the scoring function to find the structure that gets the highest score. The common scoring search algorithms are K2 algorithm [6] and Particle Swarm Optimization algorithm (PSO) [7]. The third hybrid algorithm combines the first two algorithms, reduces the search space by conditional independence test, and then uses a score-based approach for structure learning. The well-known hybrid learning methods are Max-Min Hill Climbing (MMHC) [8] and H2PC [9]. Many scholars propose some new structural learning methods, such as integer programming methods [10] and information theoretic methods [11].
In recent years, the PSO algorithm is a population-based optimization method that mainly solves various function optimization problems with fast convergence, and has been successfully applied to many research and application fields, including BN structure learning. However, the classical PSO algorithm is only applicable to continuous numerical variables, so the discrete particle swarm space has to be introduced in the structure learning process [12], and some scholars have proposed their own PSO-based structure learning methods, such as BNC-PSO [13], PC-PSO [14] and sPSO [15] etc.
In this paper, we propose the HC-PSO learning algorithm based on HC algorithm and PSO algorithm, introducing a spatial discretization method that is combined with DE (Differential Evolution) [16] to obtain the optimal solution by continuous iteration of particle swarm. In the following parts, we first review the scoring-search-based approach in structure learning for BN, then specifies the improved PSO algorithm for structure learning, and then gives the experimental setup and results, and the comparison with other common structure learning algorithms, and finally concludes this paper.
BN structure learning
Introduction of BN
BN is a directed acyclic graph that uses probability theory to deal with the uncertainty between variables. BN has two components, which are denoted by G =< V, E >, where V ={ υ1, υ2 … υ
p
} denotes the set of p nodes, representing random variables, and E = < e1, e2 … e
n
> denotes the set of directed edges from the parent node to the child node, representing the correlation between the two variables correlation. Using Pa (X
i
) to denote the parent node of node X
i
and according to the Markov property [17], the conditional probability theory formula is Equation (1)
where P (X i |Pa (X i )) denotes the conditional distribution of child node X i given the parent node Pa (X i ), reflecting the dependency relationship between the parent and child node. In addition, Bayesian networks can output a p × p adjacency matrix A. The parameter of A ij is 1 when a directed edge is pointing from X i to X j , A ij is 0 in other cases, for example, the standard network of CANCER [18] and its adjacency matrix are shown in Fig. 1.
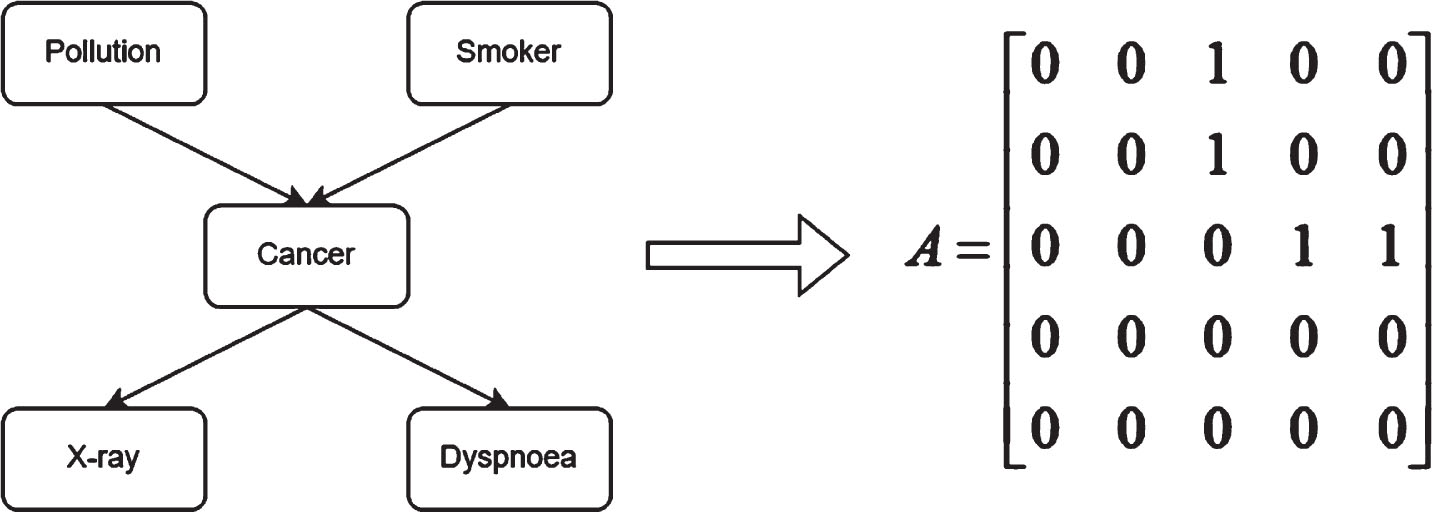
CANCER network and its adjacency matrix, A.
Given dataset D, finding the best BN for D is the final goal of structure learning. The method used in this paper is based on a scoring search, and this method requires two processes, which are the search process and the scoring function. The network is continuously changed during the search process, and the corresponding scoring function values are calculated to finally obtain the optimal structure.
Scoring function
The common scoring functions are Bayesian Dirichlet Equivalent (BDe) [19], Minimum Description Length (MDL) [20], and Bayesian Information Criterion (BIC) [21]. The BDe is a measure that maximizes the posterior distribution under the assumption of parameter distribution and relies heavily on the assumption of prior distribution; the MDL measure is based on the assumption that the number of laws in the data encoded by the model is proportional to the amount of data compression allowed by the model, and the computational effort increases exponentially when the number of nodes increases; the BIC is a measure that selects the optimal model among a limited set of models based on the likelihood function. When the sample size is large, the results of the three measures are convergent. The specific definition of the BIC function in this paper is Equation (2).
where, B G is a network structure, m ij denotes the number of samples when the parent nodes of X i take the jth combination, m ijk is the number of samples when the parent nodes of X i that is the kth value take the jth combination, r i denotes the number of values of X i , and q i denotes the number of combinations of its parent nodes.
Finding an optimal structure in the space is the np-hard problem [22], and greedy algorithms are generally used to improve the corresponding network structure by adding edges, subtracting edges, and reversing operations until it cannot be improved, such as the optimal tree algorithm. When there are many nodes, the greedy algorithm needs to traverse all the nodes, and the computational complexity will increase exponentially, so heuristic search algorithms are used, and common algorithms are Tabu Search (Tabu) [23], Genetic Algorithm (GA) [24] and Hill Climbing (HC) [25]. This paper uses the PSO algorithm, which uses a positive feedback mechanism and the search process converges continuously toward the optimal solution of the system. A method of particle swarm position and velocity update is also proposed to improve the efficiency of spatial convergence.
BN structure learning based HC-PSO algorithm
In this section, the standard PSO algorithm and the mutation and crossover operators used in updating the PSO algorithm are introduced, and then the HC-PSO algorithm based on BN structure learning is proposed.
Specific introduction of the PSO algorithm
The PSO algorithm was proposed by Kennedy and Eberhart in 1995 [26], which simulates the process of random search of a flock of birds. In PSO, the potential solution of each optimization problem is a bird in the search space, called a particle. Each particle has a velocity that determines the direction and distance of their “flight”. The particles search for the global optimal solution by following the current optimal particle
The PSO algorithm initializes a population of random particles (random solutions) and then updates the particle positions and velocities through iterations, while calculating the fitness function values for each particle to find the optimal solution. In each iteration, the particles update themselves by tracking two extremes: the optimal solution found by the particle itself, which is called the local optimum; and the optimal solution currently found by the whole population, which is the global optimum, and its update formula can be expressed by Equation (3):

The flow path of standard PSO.
The classical PSO algorithm is used to solve continuous optimization problems, while BN structure learning is a discrete optimization problem, so a discretization process is required, and in this paper, we choose the DE algorithm [27]. After the initialization of the population, the DE algorithm is updated by the differential variation strategy and crossover recombination strategy. The difference between any two individual vectors in the population is made, weighted, and then added with the third individual, which generates a new individual vector, and then crossed with the current vector using a certain probability to generate a new individual vector. Depending on the form of the difference vector, the variational crossover strategy is different, and the method used in this paper is shown in Equation (4):
N initial populations are generated based on the prior structure, and G represents the adjacency matrix of the BN structural output, they are defined as shown in Equation (5):
The target individuals are mutated according to Mov and the specific operation is shown in Equation (7):
g
best
is the optimal individual in the contemporary population. This mutation process produces meaningless gbest,j = –1 and gbest,j = -2, which are set to 0 and 1 accordingly and the variational operator process pseudo-code is
The crossover operator uses a uniform crossover strategy. H
i
and V
i
are individuals in the population, when the random probability value is less than crossover_rate, the corresponding nodes crossover, and the specific operation is Equation (8), and the process pseudo-code is
Priori structure
There are two methods to determine the prior structure in general: the expert knowledge-based method and the automatic learning-based method. The first one requires a lot of human resources. So in this paper, HC algorithm is chosen to determine a structural prior, which uses adjacent node constraint to expand the local search when the adjacent node scores are higher than the current node, the adjacent node will replace the current node, otherwise, it will return to the current node. The HC algorithm can obtain the current locally optimal network structure, which can reduce the initial search space and make the next operation space more efficient and converge faster.
Updating the BN structure
Using the above knowledge, The HC-PSO algorithm iteratively updates the initial local optimal structure obtained by the HC algorithm to obtain the global optimal structure. we summarize the specific flow of the HC-PSO algorithm as

The flow path of the HC-PSO.
Preparation for experiment
To verify the performance of the algorithms in this paper, the classical CANCER, ASIA [28], CHILD [29] and ALARM [30] networks are used as experimental datasets. Four training sets are randomly selected for each experiment, and the numbers of samples are 500, 1000, 1500, and 2000. Meanwhile, we compare the HC-PSO algorithm with other algorithms, namely HC, Tabu, MMHC and PC-PSO. All algorithms are implemented in the software RStudio, and the experiments are executed in a LAPTOP, its CPU is AMD Ryzen 5800H with Radeon Graphics 3.20 GHz and 16.00 GB memory.
Parameter setting
Before experimenting, we need to set the parameters, and the initial number of populations is set 50 and the maximum number of iterations MaxIt is set 100. In the particle update formula, the inertia weight ω indicates the effect of the particle’s previous velocity action trajectory, and the acceleration constants c1, c2 indicate the effects of the local optimal position and the global optimal position on the action trajectory. In the study [31], a larger c1 and smaller c2 strategy was proposed for the early part of the experiment, and the opposite for the later part of the experiment. This strategy accelerates the convergence rate without falling into the local optimum. Therefore, we calculate ω, c1 and c2 according to the following Equation (10), where ω0 = 0.9, ω1 = 0.35, c10= 0.84, c11= 0.5, c20= 0.38, c21= 0.81, and i denotes the number of current iterations:
The HD (Hamming Distance) [32], BIC (Bayesian Information Criterion) and It (the number of iterations) are used to evaluate the difference between the network structure learned by various algorithms and the standard structure. HD is used to measure the degree of difference between the network structure learned by the algorithm and the standard network structure. It is expressed as the sum of the number of RE (Redundant Edges), the number of ME (Missing Edges) and the number of IE (Inverted Edges), as show in Equation (11). And the smaller HD is, the closer the learned network is to the standard network.
The BIC is based on the likelihood function, and the larger the value, the better the fit of the learned network. The function expression of BIC is shown in Equation (1). The number of iterations, where the best structure was found (It).
Performance analysis of the HC-PSO
Four datasets are selected for the experiments, namely CANCER (5 nodes, 4 arcs), ASIA (8 nodes, 8 arcs), CHILD (20 nodes, 25 arcs), and ALARM (37 nodes, 46 arcs), with the numbers of samples being 500, 1000, 1500 and 2000 respectively. The PSO algorithm has randomness in the update operation, so we take the average of 100 experiments as the experimental results, as shown in Table 1, the data in parentheses indicate the standard network BIC scores. The BN (2000 samples) learned in all datasets using the HC-PSO algorithm is shown in Figs. 4–7.

The BN structure of CANCER network.
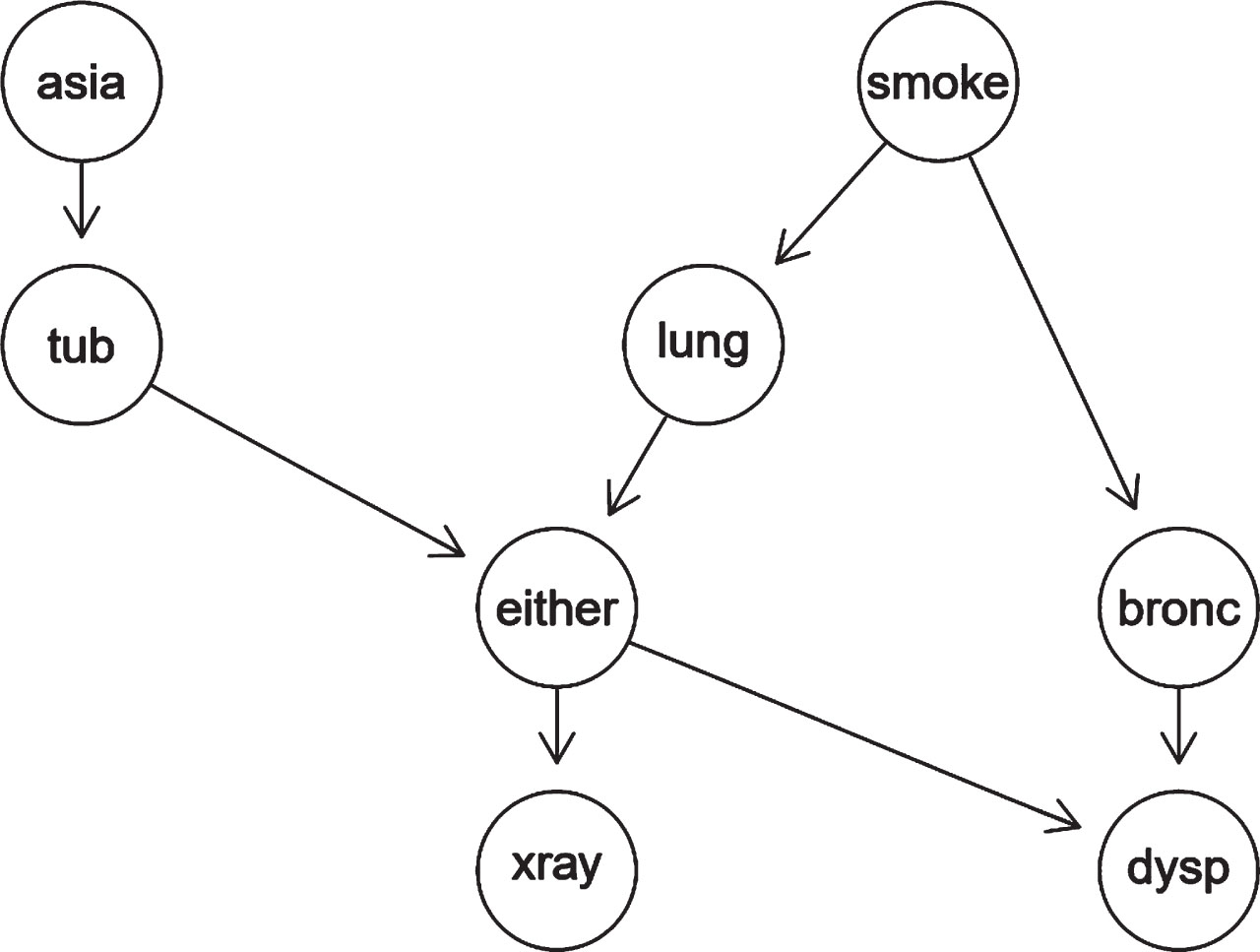
The BN structure of ASIA network.

The BN structure of CHILD network.

The BN structure of ALARM network.
Experiment results of HC-PSO with different sample sizes
From the experimental results in Table 1, we can see that the BIC learned by HC-PSO algorithm is similar to the standard score, and the HD is decreasing with the increase of sample sizes, which indicates that the accuracy of BN is getting better. It can also be seen from Table 1 that the accuracy of BN learned by HC-PSO is affected as the number of nodes and edges increases.
The algorithm in this paper is compared experimentally with HC, Tabu, MMHC and PC-PSO, the results of the experiments are shown in Tables 2–6. The HD (2000 samples) comparison results are shown in Fig. 8 and the iterations (500 samples) results.
Observing Tables 2–5, under the same sample size conditions, the results indicate that as the sample size increases, the HD of all algorithms decreases and the absolute value of BIC increases. The HD obtained by the HC-PSO algorithm is the smallest among these four algorithms, indicating that the accuracy of the HC-PSO algorithm is better. At the same time, with the addition of Fig. 8, it can be seen that the results of the HC algorithm and the HC-PSO algorithm are similar, indicating that the HC algorithm can learn a good initial structure, while the PSO algorithm plays a general role in iterative updates, but the final results are better than the MMHC algorithm and the PC-PSO algorithm. Table 6 and Fig. 9 show the fractional convergence of the algorithm on different networks, indicating that the HC-PSO algorithm converges and has a relatively good convergence speed. All in all, the HC-PSO proposed in this article outperforms other related algorithms in terms of performance indicators.

The HD of different algorithms.

The Iterations.
The learning results of different algorithms on CANCER network
The learning results of different algorithms on ASIA network
The learning results of different algorithms on CHILD network
The learning results of different algorithms on ALARM network
In this paper, the HC-PSO algorithm is proposed for the BN learned by the HC algorithm that can easily fall into the local optimal structure. The HC algorithm and the PSO algorithm are relatively simple in concept, both retain the memory of the search space, and can be implemented by a short code with relatively low computational cost. In addition, The DE algorithm strategy is used in the selection of mutation and crossover operators, which is a population-based adaptive global optimization algorithm with fast convergence and high robustness compared to GA [33]. Finally, in the experiments, the HC-PSO algorithm learns a little better than the other algorithms.
BN is an important method for solving uncertainty problems, and the HC-PSO algorithm provides a new research idea for BN structure learning. However, considering that the HC-PSO algorithm doesn’t have obvious advantages in the learning effect of multi-node data sets, further research should focus on integrating node priority into the algorithm. Meanwhile, further methods to evaluate the HC-PSO algorithm should be applied to real-world uncertainty problems. For example, learning the BN of relevant variables by the HC-PSO algorithm from medical dataset can make more accurate medical diagnosis.
The number of iterations on all of data sets (500 samples)
The number of iterations on all of data sets (500 samples)
Financial support came from National Natural Science Foundation of China (72374094) and Scientific Research Project of the General Administration of Customs(2022HK069).
Authors contribution statement
Wenlong Gao: Ideas; supervision; Funding acquisition; Review; Revision and Editing.
Mingqian Zhi: Creation of models; Data analysis and Writing.
Anping Liu: Creation of models; Data Curation; Parameter test.
Yongsong Ke: Data Curation; Parameter test.
Xiaolong Wang: Data Curation.
Yun Zhuo: Data Curation.
Yi Yang: Data Curation.
Ethics declarations
Ethical and informed consent for data used
This article does not contain any studies with human participants or animals performed by any of the authors. All data used are available openly.
Conflicts of interest
All the authors declared no conflict of interest.
Data availability and access
The data that support the findings of this study are openly available in Bayesian Network Repository at https://www.bnlearn.com/. The data contents are licensed under the Creative Commons Attribution-Share Alike License. And this study doesn’t violate any ethical standards.