
Abstract
An improved genetic algorithm is proposed for the Job Shop Scheduling Problem with Minimum Total Weight Tardiness (JSSP/TWT). In the proposed improved genetic algorithm, a decoding method based on the Minimum Local Tardiness (MLT) rule of the job is proposed by using the commonly used chromosome coding method of job numbering, and a chromosome recombination operator based on the decoding of the MLT rule is added to the basic genetic algorithm flow. As a way to enhance the quality of the initialized population, a non-delay scheduling combined with heuristic rules for population initialization. and a PiMX (Precedence in Machine crossover) crossover operator based on the priority of processing on the machine is designed. Comparison experiments of simulation scheduling under different algorithm configurations are conducted for randomly generated larger scale JSSP/TWT. Statistical analysis of the experimental evidence indicates that the genetic algorithm based on the above three improvements exhibits significantly superior performance for JSSP/TWT solving: faster convergence and better scheduling solutions can be obtained.
Introduction
Job Shop Scheduling Problem (JSSP) is a classical combinatorial optimization problem that involves scheduling the order and timing of jobs on a given set of jobs and a set of available resources (e.g., machines) in order to minimize a particular objective function, such as completion time, lead time, or cost [28]. Traditional job shop scheduling studies have dealt with goals relating to completion time (e.g., maximum completion time, total completion time, flow time, etc.). However, on-time delivery is a crucial component of establishing customer satisfaction in contemporary manufacturing and operations management. Therefore, scheduling problems with due dates objectives have attracted more and more managers’ and researchers’ interest [20], and minimizing the total weighted tardiness of jobs is an important evaluation index for scheduling when the due date of all jobs cannot be satisfied. If all the jobs are divided into two categories according to the scheduling scheme: tardy jobs (completion time is greater than the due date) and no-tardy jobs (completion time is less than or equal to the due date), the total completion time of all the jobs is the sum of the total completion time of the tardy jobs and the total completion time of the non-tardy jobs. Since the due date of the job is usually regarded as a pre-set constant, it is obvious that the issue of minimizing the total completion time of all jobs is comparable to the problem of minimizing the total tardiness of all tardy jobs. That is, the challenge of reducing the total completion time of all jobs is equivalent to the merge problem of minimizing the total lead time of all jobs and minimizing the total completion time of jobs without tardiness. For non-tardy jobs, minimizing the completion time is of little practical significance and may result in more management and inventory costs, therefore, minimizing the total tardiness of all jobs is a more reasonable scheduling optimization objective for order-oriented and due date considering manufacturing systems [4].
In real manufacturing systems, the importance of jobs may different, and the completion of jobs with different weights has different impacts on production management and business benefits. For this reason, many scholars have considered the weights of jobs in the study of scheduling problems (literature cited). This paper describes a heuristic solution procedure for the job shop scheduling problem with minimizing the total weighted tardiness of jobs as objective (JSP/TWT). In this essay, for the Job Shop Scheduling Problem with Minimum Total Weight Tardiness (JSSP/TWT), we improve the fundamental genetic algorithm in relation to chromosome decoding, population initialization, and crossover operator, an effective improved genetic algorithm is proposed, and experimental simulated scheduling trials confirm the algorithm’s higher performance.
The remaining portion of the paper is organized as follows: Section 2 offers a critical analysis of the literature on earlier investigations of the issue.; section 3 presents the theoretical formulation of the JSSP/TWT problem; section 4 describes the specific improvement methods to improve the various aspects of the genetic algorithm; section 5 describes the simulation scheduling experiments, the experimental results, and the analysis of the data processing; and section 6 gives the key conclusions of the study and the outlook of future research work.
Literature review
Compared to the traditional JSSP problem, the JSSP/TWT problem is less in literature and more difficult to solve than the traditional JSP problem. According to the literature review, the earlier study of JSSP/TWT problem was given by Singer and Pinedo [17] (conducted by Singer and Pinedo), which proposed a branch-and-bound algorithm as well as a moving bottleneck method [16]. Before that time, only specific dispatching rules like the Apparent Tardiness Cost rule [23] have been available to build production schedules in the presence of job due dates. Singer and Pinedo’s various algorithms can handle JSPTWT instances of up to 10 jobs and machines on a nearly reliable basis. Wu S D et al. [25] proposed a decomposition technique that separates task processes into an ordered list of subsets has been presented. By employing a branch-and-bound approach, this decomposition locates and resolves the “critical subsets” of scheduling decisions. The effectiveness of this strategy in the deterministic scenario is demonstrated by computational tests, and it can successfully resolve the JSSP/TWT problem.; Kutanoglu E [7] examines how well this decomposition strategy performed when used to the weighted tardiness objective in the dynamic job shop scheduling problem. The study compares the performance of various algorithms to determine which heuristic method will best optimize the scheduling plan under the weighted tardiness objective; Asano M and Ohta [14] proposed another specific heuristic algorithm based on a search tree, a certain job shop schedule is solved at each node of the search tree to minimize the maximum delay affected by the fixed sub-schedule and generates successor nodes where the sub-schedule of the operation is fixed. Therefore, a schedule is obtained at each node, and the suboptimal solution is determined among the obtained schedules.; Mattfeld D C and Bierwirth C [6] utilized genetic algorithms for solving the job shop scheduling problem with tardiness objectives for job shop scheduling problems, a heuristic reduction of the search space can help the algorithm to find better solutions in a shorter computation time. Two ways of reducing a search space are investigated by considering short-term decisions made at the machine level and by long-term decisions made at the shop floor level; Essafi I et al. [11] combined a genetic algorithm with a local search algorithm to represent the job scheduling solution through chromosomes and used genetic operations for global search while using local seek to enhance the current solution; Zhou H et al. [10] combined a heuristic algorithm and a genetic hybrid framework algorithm (GA) to solve the job shop scheduling problem to minimize weighted tardiness. For each iteration, the genetic algorithm establishes the initial action for each machine and the heuristic determines the allocation of the remaining operations; Zhang R and Wu C [22] proposed a simulated annealing approach based on block characteristics that has the benefit of guaranteeing that the local modifications are made to the most important operations in the current solution and by performing straightforward computation that can omit some unimproved neighborhood moves.; Zhang R et al. [24] proposed a hybrid artificial bee colony algorithm that combines the artificial bee colony algorithm and a local search algorithm. The discrete local search has replaced the continuous neighborhood generation method of the onlooker bees, making the algorithm more effective at solving the JSSP/TWT problem.
Kuhpfahl J and Bierwirth C [13] proposed a class of heuristic algorithms for the JSSP/TWT problem known as the neighborhood search technique. A disjunction graph-based approach is developed to capture the general structure of JSPTWT neighborhoods. Existing and newly designed communities are formulated and analyzed. Compare the performance and search capabilities of operators (and their combinations) in computational research; Zhang R and Chong R [23] proposed a multi-objective genetic algorithm to address the dual-objective problem of lowering energy consumption and total weighted tardiness, which comprises two problem-specific local improvement techniques; Bierwirth C and Kuhpfahl J [3] proposed a heuristic algorithm with the goal of minimizing the total weighted tardiness, which builds on the meta-heuristic algorithm GRASP and is strengthened by the addition of a specific local search component. The algorithm is based on a cutting-edge parsing graph model that is capable of solving the scheduling through the dendrogram of the key tree scheme, which additionally combines a powerful neighborhood operator and a quick movement evaluation process based on; Wei H et al. [9] solved the multi-objective shop floor scheduling problem with non-processing energy consumption (NEC), completion time (Cmax), and total weighted tardiness (TWT) using the multi-objective genetic algorithm U-NSGA-III and the heuristic algorithm MME.
Table 1 summarizes the common methods used to solve the JSSP/TWT problem in the above literature. Most of the methods to solve the problem are heuristic methods and intelligent optimization algorithms. Among them, the common intelligent optimization algorithm to solve the JSSP/TWT problem is the genetic algorithm, which are the most used for their excellent generalizability, expandability, and adaptability. The basic expression of the solution in the genetic algorithm is the chromosome of the actual problem solution mapped in the genetic space, when solving the JSSP/TWT problem, the chromosome encoding methods are based on the encoding of the job number, based on the encoding of the machine number and based on the encoding of the work process and so on. Different encoding methods have some influence on the operator design of the algorithm and correspondingly have different decoding methods. In the studies related to genetic algorithms for solving JSS problems, there are fewer studies on encoding and decoding compared to the studies on improvement of operators, process modification and expansion. The reason for this is that, for the basic JSSP/TWT problem, decoding is usually regarded as a conventional inverse process of encoding, which aims at reflecting the solution in the genetic space into the real problem solution space to obtain a feasible, and often considered unique, solution to the real problem.
Table caption
Table caption
Genetic Algorithm (GA) was first proposed by John Holland [12] in the United States in the 1970 s. This algorithm was designed and proposed based on the evolution laws of organisms in nature. Genetic algorithm has a long history of development, but in recent years it is still one of the most effective intelligent optimization algorithms for solving shop scheduling problems. Chen N et al. [18] develop an elite genetic algorithm for solving a flexible job shop scheduling problem with uncertain processing time. This algorithm uses elite strategies and neighborhood search methods to search for promising individuals while ensuring population diversity. Tellache N E H and Kerbache L [19] present mixed integer linear programming models, lower bounds, and genetic algorithms for open shop problem. Tutumlu B and Saraç T [2] Proposed a Hybrid Genetic Algorithm to solve flexible job-shop scheduling problem, in the proposed HGA, the local search algorithm (LSA) to determine the sub-batch size has been included in the GA to improve efficiency. Liu Z [27] developed an improved genetic algorithm with a three-layer coding mechanism to solve flexible job shop batch scheduling problem, the three-layer coding mechanism includes the batch strategy, operation selection, and machine selection. In addition, an operation overlapping strategy is introduced to improve production efficiency and make production more resilient. Cui H [8] proposed an improved multi-population genetic algorithm to solve distributed heterogeneous hybrid flow shop scheduling problem.
Genetic algorithm has many advantages, such as fast search capabilities, strong robustness, and easy combination with other algorithms. The genetic algorithm based on the minimum local tardiness rule (MLTGA) has the advantages mentioned above, and has obvious advantages compared with other intelligent optimizations. The above is the reason why this paper chooses the genetic algorithm.
In this paper, based on the most commonly used coding based on job numbering, an improved genetic algorithm based on minimum local tardiness decoding of jobs is proposed. The improvement of the algorithm mainly lies in (1) proposing a population initialization method combining non-delay scheduling and heuristic rules. (2) A decoding method based on the minimum local tardiness (MLT) of the job is designed. (3) Based on this decoding method, a chromosome recombination operator is added to the basic genetic algorithm flow. (4) A PiMX (Precedence in Machine crossover) crossover operator in genetic algorithm is proposed to improve the genetic algorithm. Through simulation scheduling experiments on randomly generated larger-scale Job shop scheduling problems, the results show that the proposed improved genetic algorithm exhibits significantly superior performance under the total tardiness index.
The JSSP/TWT problem belongs to a class of shop scheduling problems for manufacturing systems. The proposed JSSP/TWT problem is described as: Given a manufacturing shop, the shop contains m machines, denoted as the set M = {M1, M2, ⋯ , M
k
, ⋯ , M
m
}; there are njobs to be machined, denoted as the set J = {J1, J2, ⋯ , J
i
, ⋯ , J
n
}. The machining of job J
i
contains n
i
processes, denoted as the set O
i
= {Oi1, Oi2, ⋯ , O
ij
, ⋯ , O
in
i
}. One machining machine is designated for each process, and the machining machines of O
ij
are denoted as M (O
ij
), M (O
ij
) ∈ M, and the machining of the jobs is not considered to be reentrant, i.e. M (O
ij
) ≠ M (Oij′). The machining man-hours, the start time, and the completion time for process O
ij
are denoted as p
ij
, s
ij
, and c
ij
, respectively. The set of all the processes is denoted as O = {O1, O2, ⋯ , O
i
, ⋯ , O
n
}. The scheduling objective is to optimally determine the start machining time of each process in such a way that a certain performance metric associated with the manufacturing process revenue is optimal. The problem also includes the following assumptions: The job can only be processed by one machine at the same time. Remembering that process O
ij
is immediately followed by process Oi(j+1), then si(j+1) ⩾ c
ij
; A machine can process only one job at the same moment.max {s
ij
, si′j′} ⩾ min {c
ij
, ci′j′} , ∀ M (O
ij
) = M (Oi′j′); The processing of all processes not be interrupted.c
ij
= s
ij
+ p
ij
, ∀ : i = 1, 2, ⋯ , n ∧ j = 1, 2, ⋯ , n
i
; All jobs arrive at zero moment; Various dynamic factors such as machine breakdowns, job insertion, changes in working hours, etc. are not taken into account.
The performance metric for scheduling the basic JSS problem is generally the duration to complete all the jobs, i.e., the maximum completion timeCmax. In this study, the total weighted tardiness is taken as the objective for optimal scheduling of jobs. The mathematical planning model of the problem is shown in Equation (1):
In the above equation, d i is the set due date of job J i , and w i is the weight of the job.

An example of chromosome encoding.
An example of a 4×3 job shop scheduling problem
Decoding algorithm based on minimum local tardiness
The most common coding method used to solve the JSSP/TWT problem using genetic algorithm is the coding based on the job number. Taking the JSSP/TWT problem with three machines, four jobs, each job containing three processes and processed by three different machines (hereafter referred to as the 4×3 JSSP/TWT problem) as an example, the four jobs are numbered “1”, “2”, “3”, “4”, “3”, “4”, and a legal chromosome coding is based on the number of jobs., “3” and “4", a legal chromosome code as shown in Fig. 1, three numbered “1” represents the three processes of job J1, from left to right are O11,O12 and O13, the rest are analogous. It can be seen, based on the job number of the chromosome code for each gene actually represents a process. Let the processing machine and processing time corresponding to the process on each gene of the chromosome be listed in Table 2. In this paper, the solution objective is the total weighted tardiness, the tardiness of the important job has a greater impact on the total weighted tardiness than the ordinary job, the job to be processed is divided into important jobs and conventional jobs, in order to better illustrate the process, the important jobs are set as the job 1 and the job 4, and the weight is 5.
For routine decoding of chromosomes, the steps are as follows: Let l denote the locus number and L be the total length of the chromosome; Let l = 1; Extract the gene at the l-th locus and analyze its actual corresponding process; In order to satisfy the previous five assumptions as the premise, according to the generation of activity scheduling, the process will be arranged in the corresponding processing machine, and determine its processing time interval; If l < L, makel : = l + 1, turn (2), otherwise, turn (6); Calculate the performance index and decode the end.
The Gantt chart of activity scheduling obtained from conventional decoding is shown in Fig. 2.
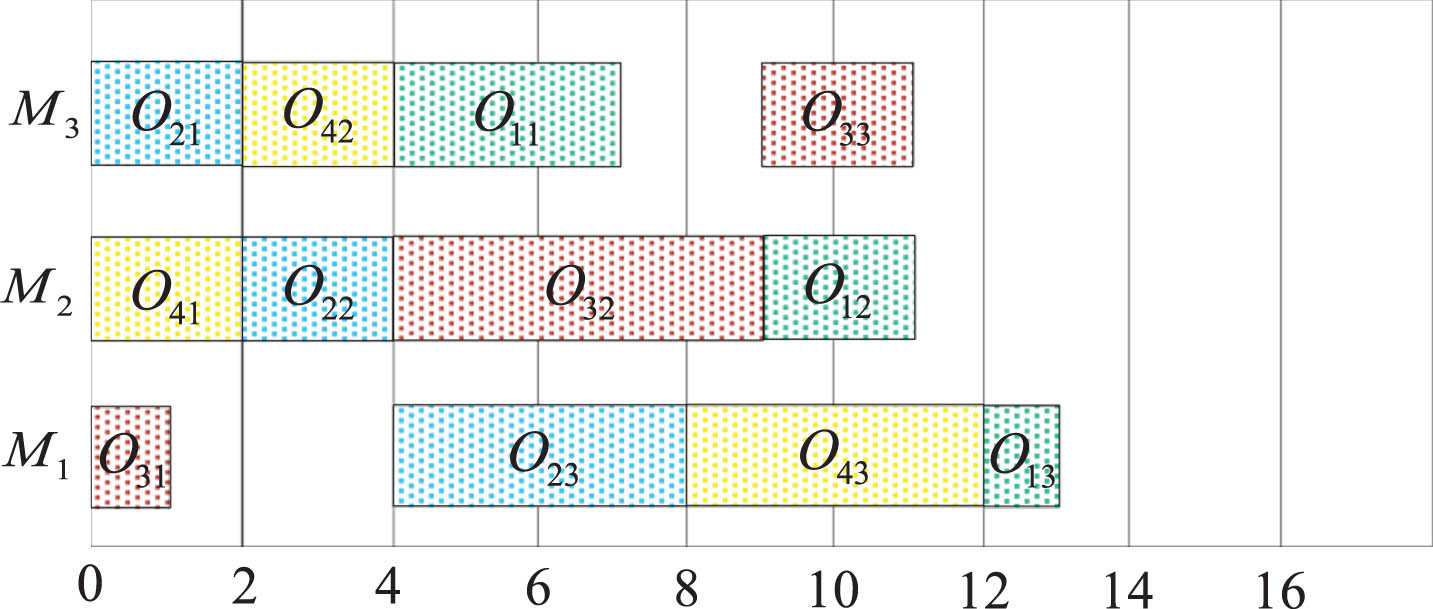
Gantt chart of scheduling scheme for regular decoding.
As can be seen from Fig. 2, the chromosome encoding of Fig. 1 generates a feasible activity scheduling scheme under conventional decoding, but the completion times of both job 1 and job 4 are later, which can lead to a larger total weighted tardiness. The main reason for this result is that the decoding of chromosomes based on job numbering is made possible by decoding from left to right, strictly following the order of genes. If the order of gene coding on the chromosome is followed in the decoding process, while examining the real-time local tardiness of regular and important jobs and changing the decoding order accordingly, better decoding results are expected to be obtained.
In this paper, we propose a local minimum lead time (MLT) scheduling rule and incorporate it into the decoding algorithm. Assuming that “O12 (M1)", “O21 (M2)", “O31 (M1)", “O43 (M1)” are the current pending processing processes of 4 jobs, and The corresponding chromosome gene order of the pending processing processes of these 4 jobs is “1234” (meaning that the first process to be decoded is), the specific steps of the MLT scheduling rule are: If job 1 is an important job, decode gene “1” directly. If job 1 is an ordinary job, it is necessary to compare job 1 with its important jobs processed on the same machine in the following cases: Job 1, job 3 and job 4 are ordinary jobs and job 2 is an important job. Since process O12 and process O21 are different processing machines, the gene “1” is decoded directly. Job 1 is an ordinary job, and either job 3 or job 4 is an important job. Since process O12 and process O31 and process O43 are the same processing machine, if job 3 is an important job, then calculate the tardiness and process 1 → 3 and process 3 → 1 in the order of decoding O12 and O31 respectively, if the tardiness and order of 1 → 3 is smaller, then decode the gene “1” directly, and the other order remains unchanged; if the tardiness and order of 3 → 1 is smaller, then place the gene “3” in the gene “1" and do the same for job 4 if it is an important job. Job 1 is an ordinary job, and both jobs 3 and 4 are important jobs. Since process O12 and process O31,process O43 are the same processing machine, then calculate the 1 → 3 and 3 → 1 decoding order process O12 and process O31, respectively, the total tardiness, if the 3 → 1 order tardiness and smaller, then the gene “3” placed in the gene “1” before the first decoding and do not need to be compared with the important jobs that have the same processing machine after; if the total tardiness of sequence 1 → 3 is small, then the process corresponding to gene 1 and gene 4 will be compared according to the above method.
Based on the above analysis, a decoding algorithm based on the minimum local tardiness of the job is proposed, and the steps of the algorithm are described as follows: Let l denote the gene number and L be the total length of the chromosome; Let l = 1, set all machines idle (the queue to be processed is empty), and set all genes corresponding to the process to the unscheduled state; Extract the gene at the l-th locus and analyze its actual corresponding process. If the process is in an unscheduled state, go to (4), otherwise go to (9); Add the process to the pending queue of its processing machine; Preferring all the processes that arrive no later than the machine idle moment according to the MLT priority rule; Scheduling the preferred process in a manner that generates active scheduling, determining its processing time interval, and placing the process in the scheduled state, provided that the preceding five assumptions are satisfied; If the preferred process is not the last process of the job, turn to (8), otherwise, turn to (9); Add the next process of the preferred process to the queue of the corresponding machine to be processed; If l < L, make l : = l + 1, go to (3), otherwise, go to (10); Calculate the performance index, end of decoding.
Figure 3 shows the conventional decoding sequence and the MLT rule decoding sequence, as shown in Fig. 3(b), the first gene in the decoding sequence would have been gene 2, and the corresponding process and processing machine would have been O21 and M3. Since the processing machine for process O11is M3, total tardiness times of the decoding sequences process 2 → 1 and process 1 → 2 in terms of O21 and O11, respectively, need to be calculated. In the decoding order of 2 → 1, the total tardiness of the process is 5.5, and in the decoding order of 1 → 2, the total tardiness of the process is 2.4 (k = 1.3, w = 5), so gene 1 is placed before gene 2 for decoding.
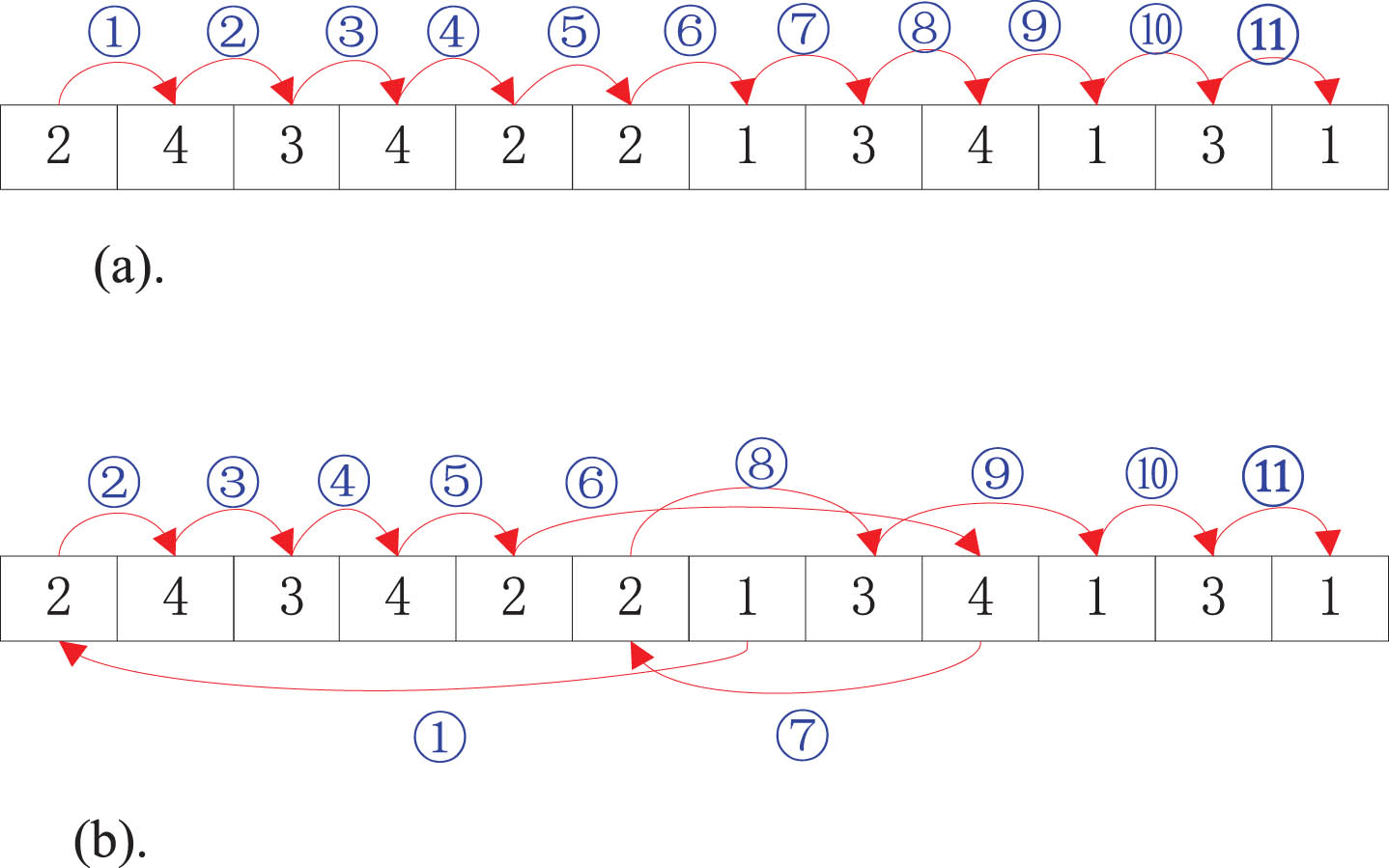
(a) Schematic of the routine decoding sequence of a chromosome. (b) Schematic of the decoding sequence of MLT rules for a chromosome.
As can be seen from the above subsection, in the process of priority rule-based decoding, the decoding order of chromosomal genes does not unconditionally follow the left-to-right order, but needs to consider both the machine’s queue to be processed and the rule preference. Therefore, priority rule-based decoding usually differs from the original chromosomal gene arrangement order. From the point of view of conventional decoding methods, the scheduling scheme obtained by the priority rule-based decoding method actually corresponds to another new chromosome.
Based on the above decoding sequence, the original chromosome has been reorganized into a new chromosome, as shown in Fig. 4. In this paper, the process of obtaining new chromosomes by decoding based on priority rules is called chromosome recombination, and this new chromosome is called a recombinant chromosome.

Recombinant chromosomes corresponding to the decoding order based on MLT rules.
Figure 5 shows the Gantt chart of the scheduling scheme obtained from the decoding algorithm based on MLT priority rules. As shown in the figure, although the maximum completion time is increased in the MLT priority rule based scheduling scheme as compared to the conventional decoding scheduling scheme, the completion time of both the important job 1 and job 4 is reduced. The total weighted tardiness of the conventional decoding scheduling scheme is calculated to be 34.6 and the total weighted tardiness of the MLT priority rule based scheduling scheme is 11.2 (k = 1.3, w = 5). It can be concluded that the decoding algorithm based on MLT priority rule can effectively reduce the total weighted drag period.
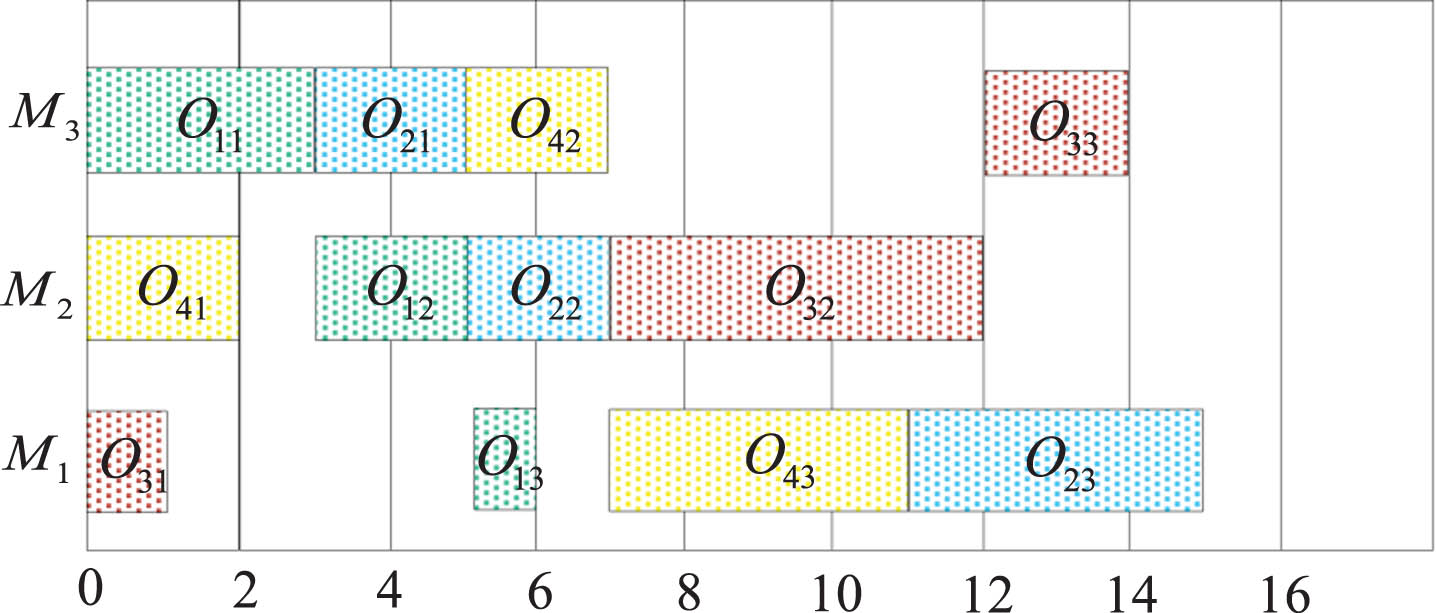
Gantt chart of scheduling scheme based on MLT priority rule decoding.
When using genetic algorithms to solve the job shop scheduling problem, it is difficult to initialize the population in a random way to ensure the quality of the initial population, for this reason, many scholars have incorporated various existing heuristic rules or scheduling methods into the initialization of the population, which has improved the quality of the initial population. The current research on initial population is mainly dominated by simply using heuristic rules, active scheduling, or combining active scheduling with heuristic rules. Depending on the objective function, by incorporating the corresponding effective heuristic rules, and then selecting the process to be scheduled according to the rules, the final scheduling result will be relatively improved. Among them, Earliest Due Date (EDD) and shortest processing time (SPT) rules are two of the more effective rules for improving the maximum completion time objective function. When using heuristic rules, no single heuristic rule is the best, so a certain probability is still used to randomly select the process, and at the same time, the diversity of the population is also maintained to some extent, which facilitates further iterative optimization of the subsequent genetic algorithm.
In this paper, we combine no-tardy scheduling with heuristic rules, in order to verify the proportions of the three initialization methods: random initialization, active scheduling combined with heuristic rules, and no-tardy scheduling, the population initialization quality index of the three initialization methods at different ratios was tested. This index combines the initial population in the decoding rules. Factors such as the maximum completion time and total weight delay under the conditions, the closer the index is to 1, the higher the quality of the population. Since the random initialization ratio should be lower than the other two methods, the ratio is set to 0.1:0.45:0.45; 0.2:0.4:0.4; 0.3:0.35:0.35. Table 3 shows the comparison results of the initial population quality under the three ratios.
Heuristic rule ratio and population quality
Heuristic rule ratio and population quality
It can be concluded from Table 3 that when the ratio of the three initialization methods is 0.2:0.4:0.4, the population quality is the highest. When selecting the process, a random number R∈[0,1) is generated, and when R = 0.6, the rule SPT is selected; otherwise, the random rule RANDOM is selected 26].
From the above, it can be seen that compared with the conventional decoding method, the MLT priority rule-based decoding method can obtain a significantly superior scheduling scheme, for this reason, in the improved genetic algorithm of this paper, the chromosome decoding adopts the MLT rule-based decoding method. Since the rule-based decoding scheduling scheme usually corresponds to a new chromosome with a different gene order from the original chromosome, and the scheduling scheme corresponding to this chromosome usually has better performance index values. Therefore, the chromosomes are recombined in the genetic algorithm corresponding to the decoding order and the recombined chromosomes are used for subsequent selection, crossover, and mutation operations with a view to obtaining better performance of the algorithm. The overall flow of the improved genetic algorithm is shown in Fig. 6.

Overall flow of the improved genetic algorithm.
In the algorithm, the initial population is randomly generated on the premise that it satisfies completeness and non-redundancy; decoding adopts the decoding method based on the MLT rule; the termination condition is determined according to the maximum number of iterations; chromosome recombination is as described in the previous subsection; the selection operation adopts the roulette wheel method; and the variation operation adopts the single-point reciprocal variation, which is to randomly select the two loci of the chromosome, and exchange genes on the two loci. The crossover operation is compared using two ways: one is POX (Precedence Operation crossover) crossover operator proposed by Chaoyong Zhang et al. [5], and the other is PiMX (Precedence in Machine crossover) crossover operator proposed in this paper. The two crossover operators are specifically described as follows:
(1) POX crossover operator the POX crossover operation proceeds as follows: Randomly select the number of a particular job; Inherit the gene with the selected job number on chromosome 1 of the parent retaining the original locus to chromosome 1 of the offspring; Inherit the genes of the selected job number on chromosome 2 of the parent retaining the original locus to chromosome 2 of the offspring; Retaining the order of the genes other than the selected job number on chromosome 2 of the parent and populating the other loci on chromosome 1 of the offspring; Preserve the order of the genes on chromosome 1 of the paternal generation other than the selected job number and populate the other loci on chromosome 2 of the offspring.
Let the two paternal chromosomes be “2 4 3 4 2 2 1 3 4 1 3 1” and “1 2 1 4 2 3 4 1 3 2 4 3", and the selected job number is “3", POX The schematic diagram of the crossover operation is shown in Fig. 7.
(2) PiMX crossover operator: The steps of PiMX crossover operation are as follows:
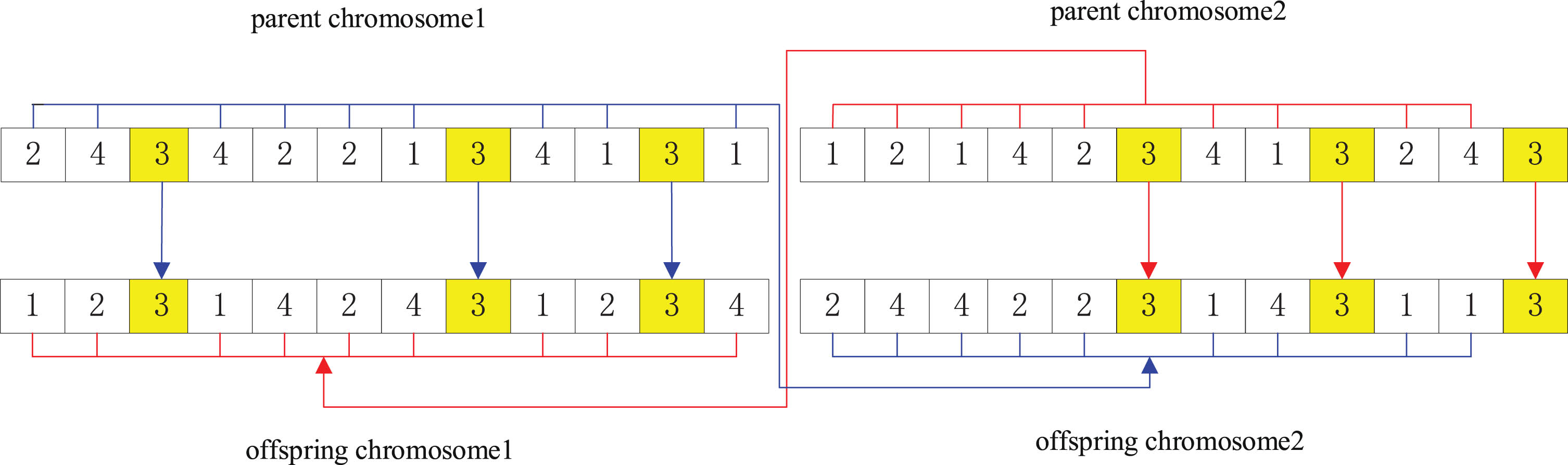
An Example of POX Crossover.
Randomly select a particular machine;
Select the job number corresponding to the process that needs to be processed with the selected machine on parent chromosome 1, and retain the original locus to be inherited to the offspring chromosome 1;
Select the number of the job corresponding to the process on chromosome 2 of the parent that needs to be machined with the selected machine, retaining the original locus to be inherited to chromosome 2 of the offspring;
Retain the order of the genes on chromosome 2 of the parent other than the selected job number and populate the other loci on chromosome 1 of the offspring;
Preserve the order of the genes on chromosome 1 of the paternal generation other than the selected job number and populate the other loci on chromosome 2 of the offspring.
Let the two paternal chromosomes be “2 4 3 4 2 2 1 3 4 1 3 1” and “1 2 1 4 2 3 4 1 3 2 4 3", and the corresponding processing machines are shown in Table 1. Let the selected machine be, and the schematic diagram of the PiMX crossover operation is shown in Fig. 8.

An Example of PiMX Crossover.
In order to verify the performance of the improved genetic algorithm proposed in this paper for solving the JSSP/TWT scheduling problem, simulated scheduling is carried out for a randomly generated larger scale scheduling problem and the scheduling results are compared and analyzed.
Simulation scheduling experiment design
Based on the literature review and verification, this paper proposes six large-scale instances of the same size to verify whether the proposed algorithm can solve the JSPTW scheduling problem and whether it outperforms the original algorithm and other intelligent optimization algorithms in terms of solution performance. The proposed method is implemented in Intel Core i5, RAM 8.00 GB, Window 11 64-bit operating system and Matlab 2018a.
In this paper, six groups of instances with the same scale are generated, and the scale of the six groups of instances is 50×10. The number of jobs to be scheduled is taken as follows; each job contains a channel process, and the working hours of each process are randomly taken from the discrete uniformly distributed DU [5,100], and the channel process is respectively processed on a machine, and the order of the processing is randomly generated; all machines are idle and available in the initial state (at zero moment), and all the jobs are put in the zero moment, The due date is generated according to the TWK (Total Work Content) method. According to the experimental data of Bierwirth C and Kuhpfahl J [3], and according to the actual situation of this paper, the margin coefficients are set to 1.3 and 1.5, and the weight of the randomly generated 25% of the jobs is 5, and the weight of the other jobs is 1.
In order to compare and analyze the effects of population initialization method, decoding method and crossover operator on the problem solving performance in the algorithm improvement, the genetic algorithm in the simulation scheduling experiment is configured according to three factors: population initialization method, decoding method and crossover operator. The specific configurations and algorithm codes are shown in Table 4.
Operators of genetic algorithm in our experiment
Operators of genetic algorithm in our experiment
Except for the differences listed in Table 4, all the algorithms have the same configurations as follows: the initial population generation and mutation operators are as described in Section 4.3, the population size is taken as 100, the crossover probability is 0.90, the mutation probability is 0.05, and the maximum number of iterations is 100. SGA is the conventional genetic algorithm, IGA is the improved genetic algorithm [21], and MLTGA is the improved genetic algorithm based on minimum local tardiness. In addition to the above improved algorithms, both the Genetic Local Search Algorithm (GLS) (by Essafi et al. [11]) and the Hybrid Evolutionary Algorithm (HEA) (by Gonzá lez et al. [15]) effectively solve the JSPTW scheduling problem. This paper introduces the Genetic Local Search Algorithm (GLS) and the Hybrid Evolutionary Algorithm (HEA) in order to verify whether the proposed algorithm is better than other intelligent optimization algorithms.
The purpose of the simulation experiments is to explore the performance of genetic algorithms and other intelligent optimization algorithms for solving the JSPTW scheduling problem under different configurations. Considering the stochastic nature of the algorithms, six scheduling cases are generated, each of which is simulated with seven algorithmic configurations, and the corresponding performance metrics are obtained. The total tardiness obtained by using the kth algorithm configuration for the rth scheduling case is noted as
Measurements in results
Tables 6–11 shows the six groups of cases in the simulation cases, and Figs. 9– 14 show the simulation boxplots of insta01–insta06 algorithms. In all the cases, the results obtained by the SGA algorithm will be used as the lower bound for comparison with other improved genetic algorithms and intelligent optimization algorithms, so as to verify whether the improvement of genetic algorithms in this paper is effective and whether the solution performance is superior to other intelligent optimization algorithms, and through the analysis of the above by analyzing the data, the following conclusions can be drawn:
Results for insta01
Results for insta02
Results for insta03
Results for insta04
Results for insta05
Results for insta06

Boxplots for insta01 (f = 1.3, f = 1.5).
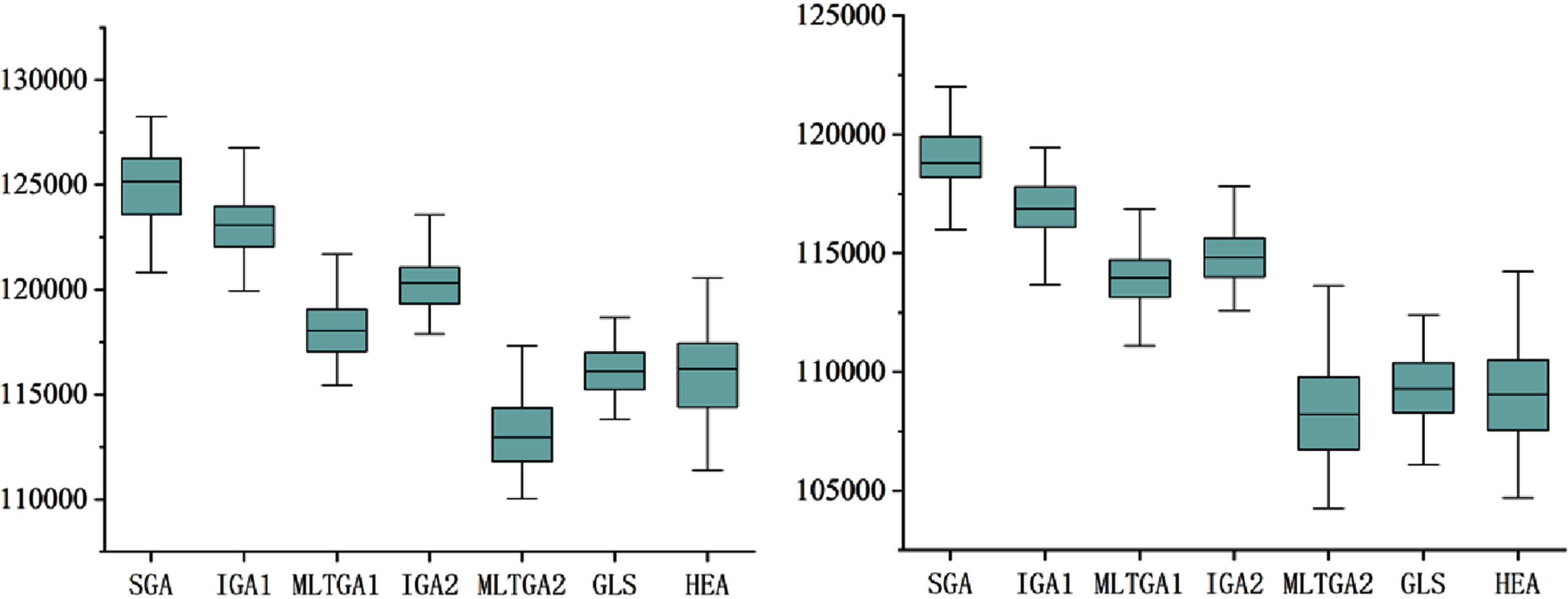
Boxplots for insta02 (f = 1.3, f = 1.5).
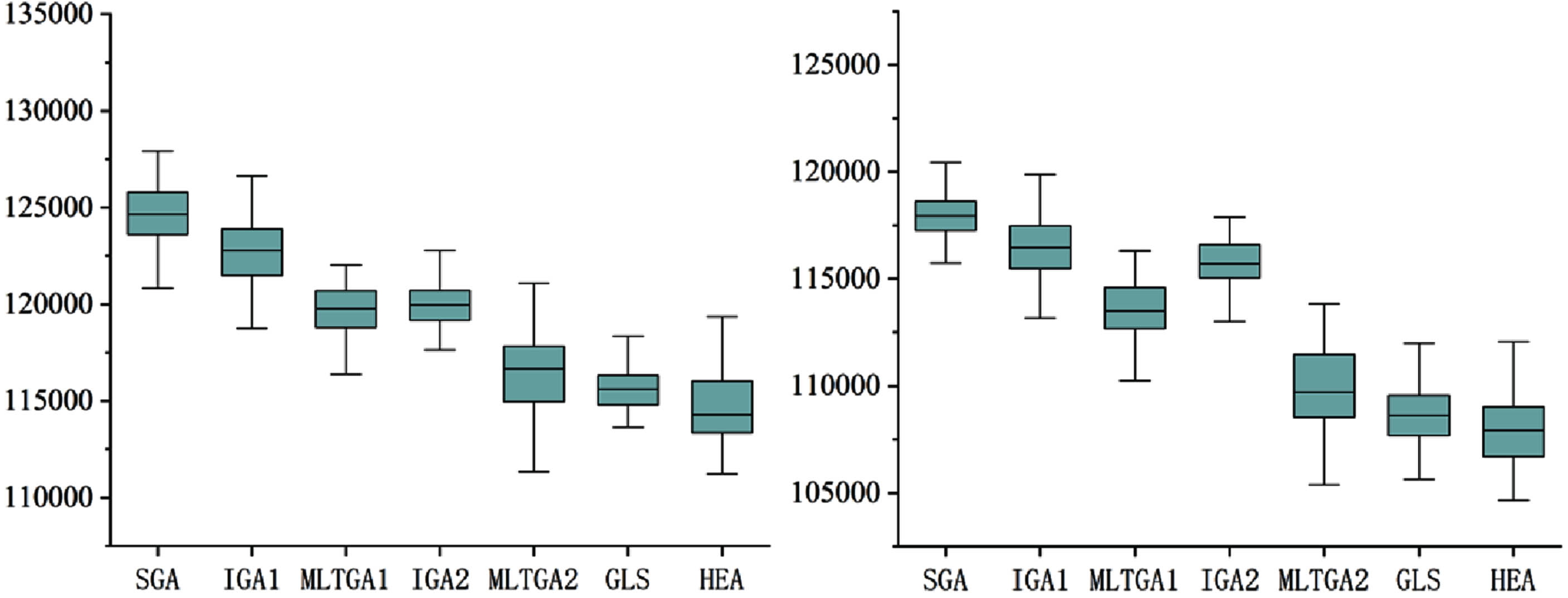
Boxplots for insta03 (f = 1.3, f = 1.5).

Boxplots for insta04 (f = 1.3, f = 1.5).

Boxplots for insta05 (f = 1.3, f = 1.5).
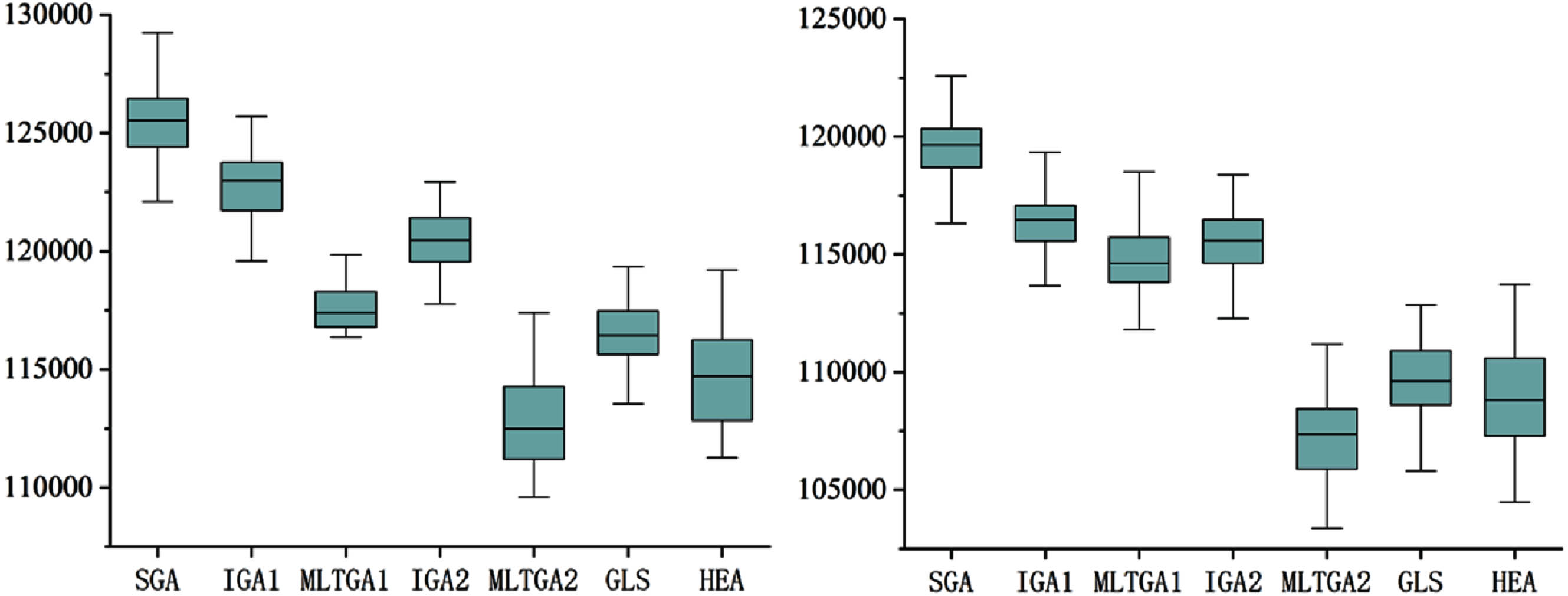
Boxplots for insta06 (f = 1.3, f = 1.5).
From the data in Tables 6–11, it can be concluded that the worst values of the total tardiness of the MLTGA1 and MLTGA2 algorithms are better than those of the SGA, IGA1, and IGA2 algorithms, which proves that the population initialization method combining no-tardy scheduling and heuristic rules proposed in Section 4.1 can effectively improve the quality of the initial population.
When the parameter f is changed, the solving efficiency of MLTGA2 algorithm is changed, when f = 1.5, the solving efficiency of MLTGA2 algorithm is higher than when f = 1.3, which proves that when the grace time of the due date is increased appropriately, the solving efficiency of MLTGA2 algorithm will be increased as well.
By comparing the IGA1 and IGA2 algorithms, as well as the MLTGA1 and MLTGA2 algorithms, it can be found that IGA2 and MLTGA2 are significantly better than IGA1 and MLTGA1 in all the numerical values, which suggests that the newly proposed crossover operator PiMX has a better performance than POX, regardless of chromosome recombination or not.
Figure 9–Figure 14 further verifies that the improved MLTGA1 algorithm can effectively solve the problem of minimizing the total weighted drag period of the job shop compared to other algorithms, from Fig. 9–13, the worst value of the total weighted drag period of the MLTGA2 algorithm is slightly higher than that of other algorithms, and there is still room for future improvement in this area.
In order to better analyze the specific differences of each algorithm in each group of samples from another perspective, skewness test was introduced. Skewness test shows that all samples satisfy normality. One-way ANOVA results of the samples are shown in Table 12. In the table, Sig.1 and Sig.2 are the significances of Levene’s test and test of between-group effects respectively. It can be seen that Sig.1 of all the samples are greater than 0.05, which indicates that all samples satisfy the homogeneity of variance, the differences of sample mean are statistically significant. In order to better compare the performance of different algorithms, Duncan multiple-range test (under significance level 0.05) is conducted to obtain the homogeneous subsets of the sample means. Table 13 and Table 14 list the homogeneous subsets of the sample mean under the insta01 example. It can be seen from the table that the MLTGA2 algorithm belongs to the best homogeneous subset and is quite different from the homogeneous subsets of other algorithms.
Results of one-way ANOVA
Results of the best homogeneous subset for insta01(f = 1.3)
Results of the best homogeneous subset for insta01(f = 1.5)
In the number-of-jobs-based coding genetic algorithm for solving JSSP/TWT, the chromosomes are usually decoded strictly in left-to-right order, which may lead to the decoding of important jobs at the backward position, resulting in the increase of the total weight tardiness of the overall workshop. In this paper, we propose an improved genetic algorithm for the JSSP/TWT problem oriented to minimize the total t weight tardiness. Considering the queue to be processed by the machine and the importance of the job, a chromosome decoding method based on the local minimum total weight tardiness of the job is proposed, and the decoding method based on the MLT priority rule is verified through simulation examples to obtain a better scheduling solution under the total weight tardiness index. And the improved algorithm of NEH is proposed to improve the initial population, further adding the chromosome reorganization operator in the algorithm, and inspired by the POX crossover operator in the literature, a PiMX crossover operator based on the processing order on the machine is designed. Through the experimental design, simulation scheduling experiments are carried out more systematically, and the experimental results and statistical analysis show that the three-aspect improvement of the basic genetic algorithm has a positive impact on the total tardiness minimization JSSP/TWT problem, which can significantly improve the quality of the scheduling solution and reduce the total tardiness of the scheduled job. The positive effects of the three improvements are reflected in (1) the improved MLTGA2 algorithm can significantly improve the quality of the initial population, which can enhance the efficiency of the subsequent algorithm solution; (2) the decoding method based on the MLT rule can significantly reduce the total drag period of the initial population, so that the subsequent evolutionary process is carried out at a more optimal starting point; and (3) the PiMX crossover operator can significantly improve the initial stage of the evolutionary Speed. The MLTGA2 improved genetic algorithm that combines the three improvements shows the most superior performance in solving the JSSP/TWT problem of minimizing the total tardiness.
It is worth noting that (1) the efficiency of the improved MLTGA2 algorithm in improving the initial population quality decreases after the size of the solved cases keeps increasing, and the main direction of the later research is to improve the efficiency of the MLTGA2 algorithm in improving the initial population quality in large-scale cases. (2) The local search and global search capabilities of the MLTGA2 algorithm can be improved to prevent the algorithm from falling into local optimality. (3) The three improvements proposed in this study are based on the basic genetic algorithm. In subsequent research, the MLTGA2 algorithm can be combined with other intelligent optimization algorithms to better improve the solution efficiency of the algorithm, on the other hand, the impact of the improvements proposed in this paper on the performance of the algorithms can be further investigated in the context of JSSP/TWT problems oriented to other objectives and other variants of JSSP/TWT problems [29]. (4) Further improve the solving speed and efficiency of the MLTGA2 algorithm so that the algorithm can effectively solve large-scale cases in real shops.
The JSSP/TWT problem is a common problem on real factory production lines, but due to the difficulty of solving it, there are few researchers. The successful solution of this problem in this paper has strong practical significance, which can reduce the factory’s processing costs and storage costs, and greatly improve production efficiency.