
Abstract
To ensure a safe and pleasant user experience while watching content on YouTube, it is necessary to identify and classify inappropriate content, especially content that is inappropriate for children. In this work, we have concentrated on establishing an efficient system for detecting inappropriate content on YouTube. Most of the work focuses on manual pre-processing; however, it takes too much time, requires manpower support, and is not ideal for solving real-time problems. To address this challenge, we have proposed an automatic preprocessing scheme for selecting appropriate frames and removing unwanted frames such as noise and duplicate frames. For this purpose, we have utilized the proposed novel auto-determined k-means (PADK-means) algorithm. Our PADK-means algorithm automatically determines the optimal cluster count instead of manual specifications. By doing this, we have solved the manual cluster count specification problem in the traditional k-means clustering algorithm. On the other hand, to improve the system’s performance, we utilized the Proposed Feature Extraction (PFE) method, which includes two pre-trained models DenseNet121 and Inception V3 are utilized to extract local and global features from the frame. Finally, we employ a proposed double-branch recurrent network (PDBRNN) architecture, which includes bi-LSTM and GRU, to classify the video as appropriate or inappropriate. Our proposed automatic preprocessing mechanism, proposed feature extraction method, and proposed double-branch RNN classifier yielded an impressive accuracy of 97.9%.
Introduction
Inappropriate YouTube content detection is the automatic process of finding and classifying content on the YouTube platform that is considered improper, offensive, or unsafe [1, 2]. Since there are a ton of user-generated videos posted every day, it’s necessary to have strong systems in place to recognize and remove any content that breaks community guidelines or endangers viewers, especially younger or more susceptible audiences. Inappropriate YouTube content may contain violence, explicit language, hate speech, nudity, or dangerous activities. Children who spend a significant amount of time online are particularly vulnerable when it comes to inappropriate content [3, 4].
YouTube has gained popularity as a substitute for traditional screen media, and there are concerns about its relative lack of regulations in comparison to television [5, 6]. The frequent exposure of children to disturbing video content can have short-term and long-term impacts on their cognition [6], behavior, and emotions [7, 8]. Numerous instances of distributing irrelevant content through videos have attracted attention [9]. The Elsagate [10] controversy highlighted the presence of disturbing video content on YouTube featuring popular cartoon characters engaged in alarming scenarios [10, 11]. Regulations such as the Children’s Online Privacy Protection Act (COPPA) [12] have been established to offer a safer online platform, imposing demands on internet pages to implement security features for kids under the age of thirteen. YouTube has implemented features such as the “safety mode” [13] option and the YouTube Kids application to filter out unsafe content and provide parental control over approved videos for specific age groups. However, the challenges of identifying and controlling inappropriate content persist. To determine if the content is appropriate, several detection algorithms and techniques are utilized for text, audio, video, and other contextual elements. YouTube’s decision-making algorithms [14] heavily rely on video metadata, but the sheer volume of uploads makes it challenging to detect and remove unwanted and inappropriate content effectively. To tackle this, video-based content detection is utilized with the help of machine learning and deep learning algorithms.
Researchers are increasingly driven to employ deep learning techniques in the video content detection process, spurred by advancements in deep learning methodologies [15, 16]. Even when using deep learning for content detection, some preprocessing steps are required for efficient performance, such as removing unwanted frames from the video. Utilizing raw video without preprocessing, results in high computational costs, making it unsuitable for real-time video content detection. So it’s necessary to remove the unwanted frames before processing. The majority of the work utilized manual intervention, such as the manual removal of unnecessary frames from videos [12]. Some of the studies manually reviewed a large number of videos and chose the best for classification [17].
Some works focus on removing unwanted frames by using the key frame extraction technique [18]. In our work, emphasis is placed on K-means clustering. However, the K-means clustering method has limitations, especially when determining the optimal number of clusters [19, 20]. Inappropriate cluster count selection may limits the performance. If the number of clusters chosen is less, it compresses the diverse frames into a smaller number of clusters, thereby reducing the discriminative power of the clustering solution. However, if the number of clusters is set too high, duplicate frames or frames with the same content can be assigned to different cluster. The redundant cluster assignment process may increase computational complexity and possibly cause redundant analysis or classification processes. Additionally, it may result in an imbalance in the number of frames allocated to each cluster, which will reduce the ability of the clustering solution to accurately capture the variations and patterns in the video data. Automatic cluster count determination without manual specification is critical for improving adaptability in these scenarios.
To the best of our knowledge, no prior work has fully automated this preprocessing step by determining the optimal cluster count for the k means clustering technique, especially for video content classification. In our proposed work, we present a novel automatic preprocessing mechanism, the Proposed Auto Determined K-means –(PDAK-means) clustering algorithm, to deal with traditional method limitations. Instead of using all frames, our approach concentrates on selecting the best frames from the video. This approach automatically removes duplicate and unimportant frames from the video, significantly decreasing computational complexity. Additionally, the PDAK-means algorithm tackles the traditional k-means clustering algorithm limitations such as manual specification of cluster count. The innovation of the works is automates the preprocessing steps and automatically determines the optimal cluster count for the best frame selection. This frame selection process improves overall performance and optimizes computational resources. By automating the preprocessing step, we can that overcome the challenges of manual preprocessing and improve the efficiency of video content detection techniques. This automated preprocessing step eliminates the need for labor-intensive manual frame selection, making the process more efficient and suitable for real-time applications.
In addition, our proposed methodology uses the proposed features extraction method which includes the pre-trained architectures DenseNet121 [21] and Inception V3 [22] to extract features by their learned representations. These architectures have been trained on large-scale image datasets, allowing them to capture and encode meaningful visual features from the video frames effectively. DenseNet121’s dense connectivity specializes in capturing local features and fine details, while InceptionV3’s multi-scale analysis and global context support captures broader features. Incorporating these two approaches improves effectiveness by providing a full representation of the input images that takes into account both global and local features information.
Following the features extraction technique, Proposed Double Branch RNN (PDBRNN) classifier is utilized for video content classification. This architecture consists of two branches: a Bidirectional Long Short-Term Memory (Bi-LSTM) and a Gated Recurrent Unit (GRU). By incorporating these two types of recurrent networks, the architecture effectively captures temporal dependencies and contextual information within the video sequences features.
The study’s main contributions can be summarized as follows: Perform proposed auto-determined K-means clustering on video to obtain distinctive images to use for classification in order to get rid of similar images. To extract the global and local features from the frame the proposed features extraction method was utilized. To improve the overall model performance by capturing temporal dependencies and contextual information within the video sequences features using proposed double branch RNN classifier.
The following is a summary of the upcoming sections of the paper: Section 2 discusses the related research in this field. In Section 3, the methodology of our proposed system is described. Section 4 presents the details of the dataset. Results and discussion are covered in Section 5, and the work is concluded and some areas for future improvement are suggested in Section 6.
Related works
In this section, we discuss some of the key research problems and challenges in YouTube video content classification that have been studied. The widespread availability of multimedia data on YouTube has created numerous opportunities for researchers. Nonetheless, the primary challenge is to identify an effective technique for understanding the context of videos. While video metadata serves an important part in YouTube’s decision-making algorithms, the enormous number of uploads makes it difficult to efficiently identify and delete undesired and inappropriate content. Machine learning [23, 24] and deep learning techniques are used to address this through the use of video-based content detection [25].
Unlike machine learning methods, deep learning structures are increasingly being used to learn video-based interpretations of features in video categorization. CNN architectures have gained popularity in video classification for their ability to learn feature representations from various data modalities. By combining text, audio, video, and image data modalities and using greedy layer-wise training to train a restricted Boltzmann machine (RBM) model, [26] led the way in deep learning research. In [27], demonstrated successful multiclass classification of video outcomes on an extensive video dataset using convolutional neural networks. 3D CNNs are also utilized for video content classification [28-30] however, to deal with the complexity issue associated with 3D-CNNs, a novel architecture called Dissected 3D-CNN (D3D) [31] was developed, which effectively captures temporal information. Two-stream networks are another application for 3D-CNN [32]. It uses two different streams to capture temporal and spatial information efficiently [33]. Whereas the temporal stream computes optical flow to capture motion features, the spatial stream processes raw RGB image and optical flow image [34] pixel values to extract appearance features. The output features from the two streams are combined to create the final classification. Apart from the CNN model, recurrent neural networks, especially LSTM [35] models, Bi LSTM [12], and the combination of LSTM with CNN [36], have gained popularity for identifying inappropriate videos.
Generally, most of the work utilized pre-trained architectures for image feature extraction techniques in a variety of applications, especially medical imaging. DenseNet121 is utilized to diagnose diabetic retinopathy [37], whereas other pre-trained architectures like VGG16, VGG19, and Alexnet are utilized to diagnose coronavirus applications [38]. Compared to Densenet121 and inception v3, other architectures such as VGG16, VGG19, and the Resnet series have a longer computation time due to their large number of parameters [39]. Notably, VGG16 and VGG19 have lower accuracy than DenseNet121 and InceptionV3 [39]. In our proposed feature extraction method, DenseNet121 and the InceptionV3 architecture are utilized. Even using advanced CNN architectures, it still needs a preprocessing step to improve its performance.
Many of the studies utilized manual preprocessing steps before classification to improve the classifier’s performance. According to [12], the video data is initially divided into smaller segments called video clips, each with a duration of one second. These clips of video are then manually labeled during the annotation process. This architecture undergoes training with 152 million parameters. It requires a significant amount of computational time and memory, and it attains 95.67% accuracy while using BiLSTM with 128 neutrons. In [17], a CNN-LSTM framework was suggested for detecting disturbing and fraudulent material in videos. The study manually reviewed 5,000 videos and chose over 1,000 for classification. Accuracy in frame, audio, and movement modalities was 66.21%, 87.37%, and 92.83%, respectively. This work does not focus much on duplicate removal, so it attains less performance. In [18], a CCTV dataset was gathered to track various violent and nonviolent actions taken by students. To remove duplicates, a key frame extraction technique was used. The method involved calculating the difference between consecutive frames, considering a frame as a duplicate, and removing it if the difference exceeded a binary threshold. However, this method may not be effective in situations where the same frame reappears after a few seconds in real-time footage. Clustering-based duplicate removal methods could be investigated as a solution to this problem. Unlike this method, clustering-based approaches such as the K- means algorithm consider similarities between all frames. However, the K-means clustering method has limitations, especially when determining the optimal number of clusters. In [19], addressed this issue by proposing an automated method that changes the cluster count from 5 to 10 and compares it to 10 null reference distributions. Despite progress, the study recognizes limitations in handling a wider range of cluster counts for real-time video analysis.
The majority of previous research involved manually viewing over a thousand videos and employing preprocessing methods to collect suitable videos for video content classification [12, 15] and [16]. Manual annotation ensures accuracy, but it is time-consuming and unsuitable for real-time data. In our proposed work, we propose a fully automatic preprocessing scheme to improve performance and reduce computational complexity.
Proposed methodology
The proposed methodology starts with dataset collection, followed by an automatic preprocessing scheme Proposed Auto-determined K-means clustering algorithm. After removing unwanted frame from the video, PFE is used to extract features from the video frames, and a PDBRNN architecture is used for content classification. Figure 1. Illustrates the block diagram for detecting and classifying inappropriate content on YouTube.
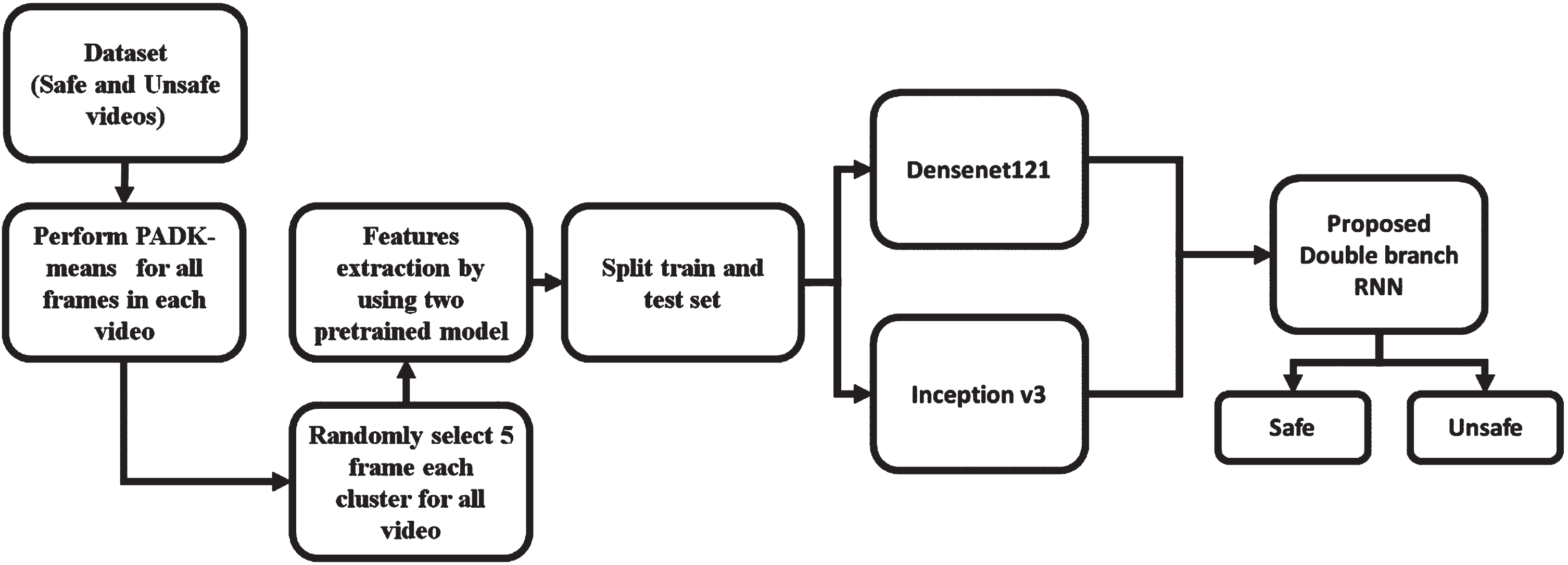
General block diagram of proposed work.
The frame work is divided into three major phases, as illustrated in Fig. 2. (1). Video Preprocessing by Proposed Auto-Determined K-means Clustering: PADK-means automatically identifies and removes unwanted and duplicate frames, resulting in reducing the computational complexity. (2). Feature Extraction by Proposed pretrained model (3). Classification is performed by Proposed PDBRNN.
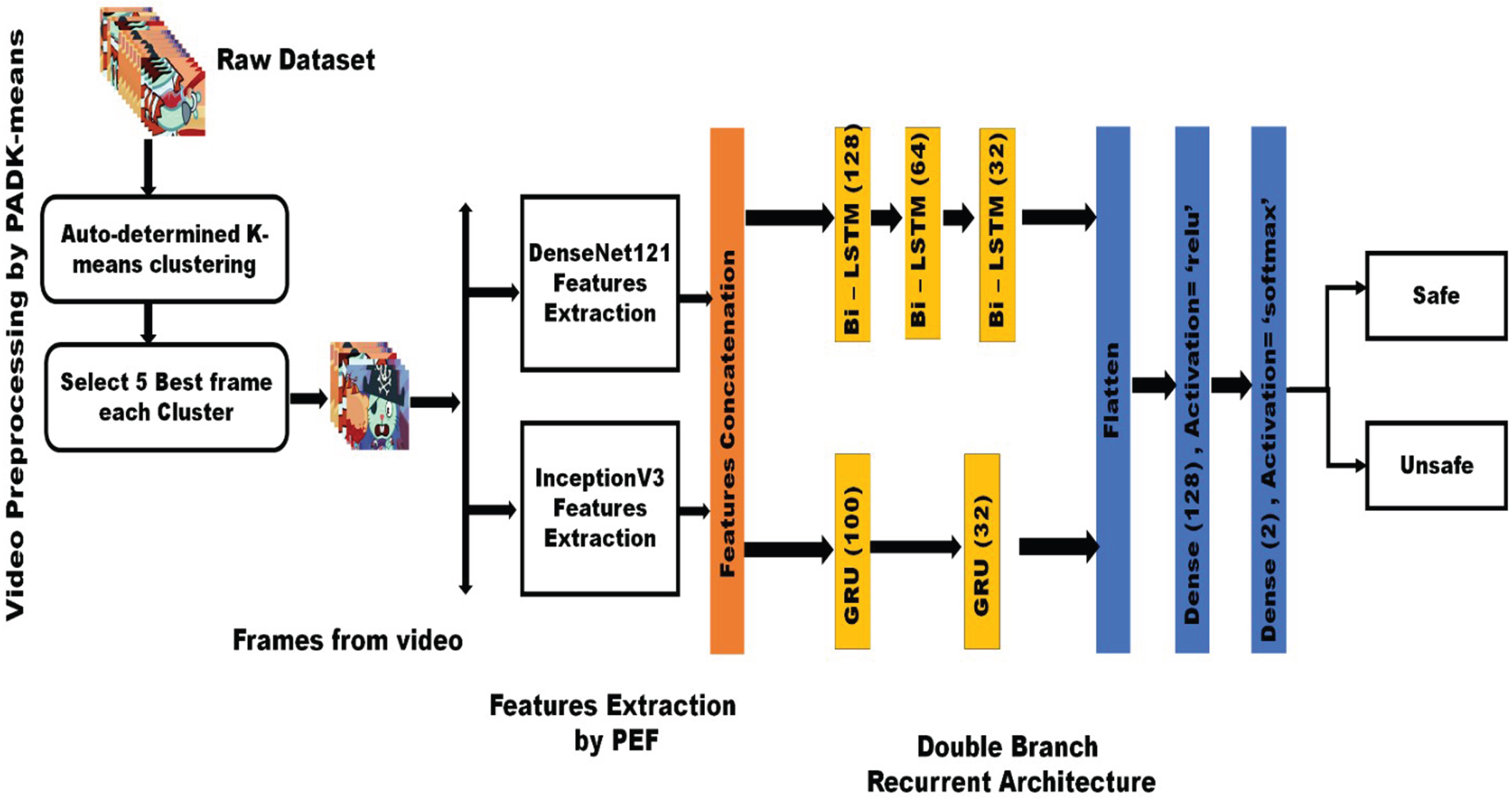
Proposed auto determined K means clustering and PDBRNN architecture.
Deep learning approaches rely heavily on video preprocessing because it helps to extract useful frames for better video content classification. However, these frames could include irrelevant frames such as black and white frames or duplicates, which can significantly increase computational time and reduce performance. For effective video content classification, it is essential to select the most informative frames from the video. To accomplish this in our proposed work, we proposed an automatic preprocessing scheme PADK- means algorithm.
The proposed PADK- means clustering algorithm is employed to select the most suitable frames and remove duplicates and noise frames from the video. The method aims to address the difficulties of manually specifying cluster count by introducing an automated strategy for determining the optimal cluster count. In the traditional k-means algorithm, if the cluster count is set low, the important frame is compressed, and it may have unwanted frames if the cluster count is high. Thus, choosing the right cluster count is essential for performance.
The proposed video preprocessing encompasses the following steps:
Step 1: Removal of noisy frames from the video. It is possible to have a fully or partially black frame in the video. Those frames are considered as noise frames and removed from the video.
Step 2: After removing the noise frame, finding the optimal cluster count with help of consecutive frames difference.
Step 3: After determination of optimal cluster count perform the K-means clustering based on cluster count.
Step 4: Finally perform frame selection. It is considered as best frame in that particular video.
Initially, video frames are extracted from videos. These frames are then scaled to a standard size of 224×224 pixels with three color channels. Generally, the video contains full and partial black frames which are unnecessary for processing, so it is preferable to remove them initially for better performance. Algorithm 1 represents the methodology for removing noisy frames from a video.
Removing noisy frames from video
The initial step involves converting the frames into grayscale images. Following this, the grayscale images are uniformly resized to 112×112 pixels and the pixel values are normalized within the range of 0 to 255, ensuring consistency in processing. To reduce dimensionality, each 2D G (112×112) grayscale image is transformed into a 1D (112×1) feature representation using Equation (1), capturing the mean pixel value along each column. Next, the detection of noisy frames is achieved through Equation (2).
The value of
Where
Proposed auto-determined k-means clustering
Algorithm 2 is used to determine the optimal cluster count. Initialize the variable j to 1 and set cluscount to 1 for tracking clusters. Where ‘j’ represents start index of new cluster. Loop through indices i from 1 to number of noise free frame (n’) from the video. Calculate the absolute difference between the element at index “j” and the element at index “i + 1” in M. If this difference exceeds t = 0.03, then that frame will be the next cluster’s start. Increment the cluscount by 1.
Update start to “j = i + 1” to pinpoint the next cluster’s start. Afterward, conduct k-means clustering with the specified cluscount. The threshold value t is decided empirically by observing the types of clusters formed. In observation, the t value is set to be 0.03. Increasing the threshold above t, fewer clusters are formed, which may reduce the performance of the clustering solution by excluding critical frames. In contrast, when the threshold value is below t, too many clusters are formed, which can cause problems with duplicate frames or frames with the same content assigned to different clusters. Finally, the computed optimal cluster count is used as cluster count in K means clustering.
Random selection of frames from each cluster
After performing k-means clustering, proceed to randomly select frames from each cluster. For each cluster, follow these steps: Iterate through clusters indexed as “i” from 1 to the cluscount. start represent the index details for the staring index of a cluster. If the consecutive start [i + 1] and start [i] index difference value more than 5 means it contain more than 5 frames in ith cluster; Otherwise, it contains below 5 frames. If that particular cluster contains more than 5 frame then randomly select 5 frames within the cluster. If not, balance the frame from the following cluster and include all frame indices from the cluster. Store selected frame indices in variableI ij .
Generate the final video frames with help of selected index. Repeat the entire process described above for all videos. Algorithm 3 provides the best-selected frames, which are then used for feature extraction.
Where O represents the original image, V j represents the jth video and I ij represents the jth frame of ith cluster.
Proposed features extraction
Following PADK-means, it provides the most suitable frames for next feature extraction process. The Proposed features extraction (PFE) is used for feature extraction which includes the two trained models, namely DenseNet121 [21] and Inception V3 [22]. The fusion of DenseNet121 and InceptionV3 provides a powerful way to overcome the shortcomings of each model individually. It can achieve a better balance between local specific and overall context, which leads to a more reliable and accurate representation of image features.
DenseNet121 introduces dense connectivity, where each layer is connected to every other layer directly in a feed-forward fashion. Feature maps from earlier layers can be directly accessed by later layers because of to this dense connectivity pattern. As a result, feature maps can be concatenated and combined in a dense manner, promoting feature reuse and enabling efficient information flow throughout the network. This dense connectivity enhances gradient flow, alleviates the vanishing gradient problem, and facilitates the learning of more expressive and discriminative features. DenseNet121 is indeed better suited for extracting local or fine-grained information rather than explicitly capturing global information. However, due to the limited receptive field and the absence of explicit mechanisms for multi-scale analysis, DenseNet121 may not capture global features as comprehensively as architectures like InceptionV3.
The multi-scale technique allows InceptionV3 to capture global features, contextual relationships, and a comprehensive understanding of the images. One of its shortcomings is that InceptionV3’s model prioritizes fine-grained local information over contextual connections and global features. Because feature maps are down-sampled using pooling techniques, accurate spatial information may be locally lost. As it focuses on capturing high-level features and global context, it is well suited for tasks that require a global understanding of images.
From these two architecture specifications, DenseNet121’s dense connectivity excels at capturing local features and fine details, while InceptionV3’s multi-scale analysis and understanding of the global context help capture broader features. These two methods can be combined to create a comprehensive representation of input images that includes both regional and global data. So our proposed feature extraction methods utilize these two methods for feature extraction.
Features concatenation
The feature vector produced by concatenating the features of DenseNet121 and InceptionV3 would be Fc×3072 in size. The features concatenation flow shown in Fig. 3. To achieve the proposed feature extraction, DenseNet121 (Fc×1024) and InceptionV3 (Fc×2048) feature vectors have been combined. Fc stands for the number of frames in a video.
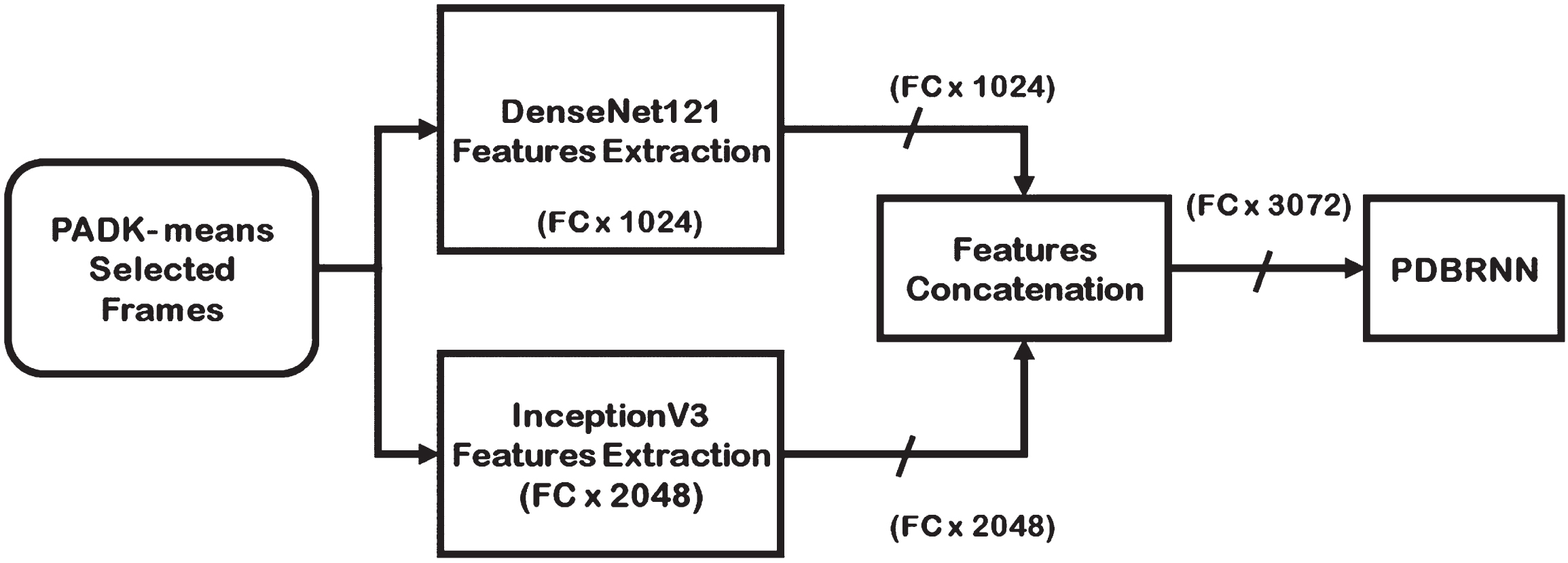
Proposed features extraction.
After feature extraction, the extracted features are applied to the global average pooling layer. A global average pooling layer creates a fixed-length vector for each frame by averaging the features from each frame across all spatial locations. The resulting fixed-length vectors are used as classification input.
Once features are extracted from PFE, extracted features given to Proposed DBRNN for classification. For sequence modeling and classification tasks, recurrent models such as LSTM, Bi-LSTM [40] and GRU are commonly used. Because these architectures can capture and process sequential data, they are well-suited for tasks involving time-dependent or sequential data. Practitioners and researchers frequently experiment with various RNN structures in order to find the best approach for their specific classification problem.
By incorporating both Bi-LSTM and GRU branches, the architecture can capture and exploit a comprehensive range of contextual information. The combination of Bi-LSTM and GRU allows the model to adapt and learn different representations from each branch. They capture different aspects of the input sequence, such as long-range dependencies and short-term patterns, enabling the model to learn diverse representations and extract complementary features.
BiLSTM are good at capturing long-term dependencies, whereas GRUs are good at modeling short-term dependencies. Table 2 clearly shows that the PDBRNN method achieves high accuracy while it dealing with existing feature extraction method like DenseNet121 and inception v3. Meanwhile proposed features extraction (PFE) method with traditional BI LSTM and GRU achieves an accuracy of less than 90%. So, our proposed PDBRNN Classifier dominate the existing classifier like Bi - LSTM and GRU. Figure 4 represents the proposed PDBRNN architecture.
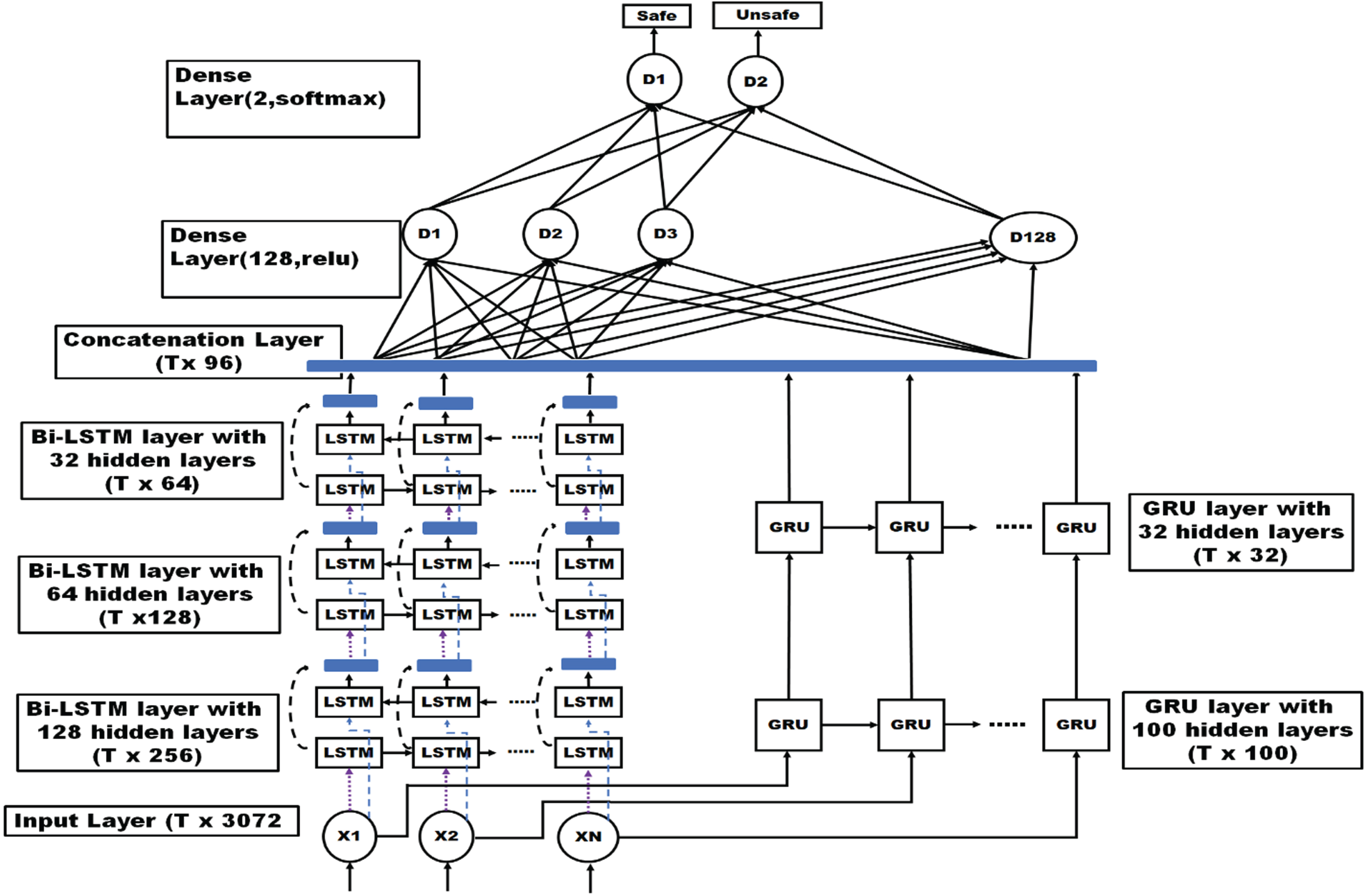
Proposed double branch recurrent architecture.
In our Proposed PDBRNN we utilized 3 Bi-LSTM layers with 128, 64, 32 units and 2 GRU layer with 100, 32 units. Multiple layers of neural network architecture allow the network to obtain hierarchical representations of the input image data instead of just one RNN layer. Higher layers excel at grasping more abstract features and complex relationships, while lower layers specialize in capturing low-level features.
By using a hierarchical approach, the network’s capacity to identify and extract useful features from the image data can be greatly improved. The outputs of the Bi-LSTM and GRU layers are concatenated along the feature dimension (T). The concatenated features are then passed through the first dense layer, which has 128 units. The ReLU activation function is applied, introducing non-linearity to the output. The output shape after the first dense layer would be (T, 128). The output of the first dense layer is fed into the final dense layer, which has 2 units corresponding to the number of classes. This layer use Softmax activation function. The Softmax activation function produces a distribution of probability over the classes that represent the predicted probabilities for each class predicted by the model.
YouTube is an open-source platform that helps collect datasets for classifying inappropriate video content. Most of the inappropriate video content research uses YouTube videos as a dataset source. In our work, we have collected nearly 1000 videos from YouTube with different run rime. The collected data is divided into two categories: “Appropriate” and “Inappropriate”.
The “Appropriate “category consists of 500 videos from sources like Coco melon, Dora the Explorer, and primary and nursery song etc. The search keywords used to identify appropriate content are as follows: kids cartoon video, kids watchable, children’s entertainment, animated kids shows, kids TV programs, cartoon series for children, age-appropriate animated content, child friendly cartoon videos, and fun cartoons for kids.
The “Inappropriate” category includes 500 videos from sources such as Happy Tree Friends, Scottish Ninjas, Zombie College, and potentially explicit or sexual content. The search keywords used to identify Inappropriate content are as follows: Horror cartoon video, scary cartoon video, family guy, adult cartoon, hilarious cartoon, Anime fights, fights animation, zombie cartoon, romance anime and love cartoon animation video.
After dataset collection process, all videos are preprocessed by our Proposed automatic preprocessing scheme namely PADK-means. By automatic this preprocessing scheme can reduce manpower support to analysis the raw video. Our proposed automatic preprocessing scheme analyzes the video frame, removes the unwanted and duplication frames with the help of proposed PADK means algorithm. Table 1 represent dataset and frame counts. During preprocessing, our proposed mechanism removes unwanted frames while also detecting duplicate frames using the PADK-means algorithm. After removing the unwanted frames, the remaining frames are clustered by the K-means algorithm using the optimal cluster count. Afterward, 5 frames were randomly selected from each cluster. The details of the automated preprocessing mechanism are discussed in section 3. Overall, we get an average cluster count of about 150 and an average number of frames per video is about 750 (5*150). The total average number of frames is about 7500000.
Dataset and frame counts
Dataset and frame counts
To assess the performance of video classification models, various metrics such as accuracy, precision, recall, specificity, and F1 score are computed using confusion matrices. We utilized Google Colab with a 13GB RAM environment for code execution. We performed 10-fold cross validation. Table 2 shows a 10-fold average performance comparison of our proposed approach to conventional techniques. We conducted two kinds of analyses. In the first analyses, the proposed pre-trained model was utilized to extract features, which were subsequently classified using Bi-LSTM, GRU, and the proposed PDBRNN architecture. In the second investigation, features were extracted from densenet121 and inception v3, then classified using the proposed PDB RNN architecture, respectively.
Performance analysis of proposed and traditional architecture
Performance analysis of proposed and traditional architecture
In this section, we examined the performance of the PFE technique using the proposed PDBRNN, Bi LSTM, and GRU. To carry out this analysis, we utilized our proposed preprocessing scheme along with the PFE technique. The validation performance shows that our PDBRNN model demonstrated superior accuracy compared to the Bi-LSTM and GRU models. Specifically, our PDBRNN model achieved a 97.9% accuracy, 97.85% F1 score.
Our proposed double branch classifier, when compared to the Bi- LSTM and GRU classifier, achieves 8.06%, 21.93% increased accuracy and 14.48%, 36.66% increased F1-Score, respectively. These results highlight the effectiveness of our proposed PDBRNN model in enhancing the accuracy of the classification task.
Figure 5 represents the average confusion matrix of the proposed PDBRNN, Bi-LSTM and GRU, respectively. In simple terms, the proposed model performed reasonably well with a balanced number of true positives and true negatives. The Bi-LSTM model showed higher true positives but struggled with false negatives. On the other hand, the GRU model had a lower number of false positives but still had some difficulty with false negatives. Figure 6 represent the average ROC curve of the proposed PDBRNN, Bi-LSTM and GRU, respectively.
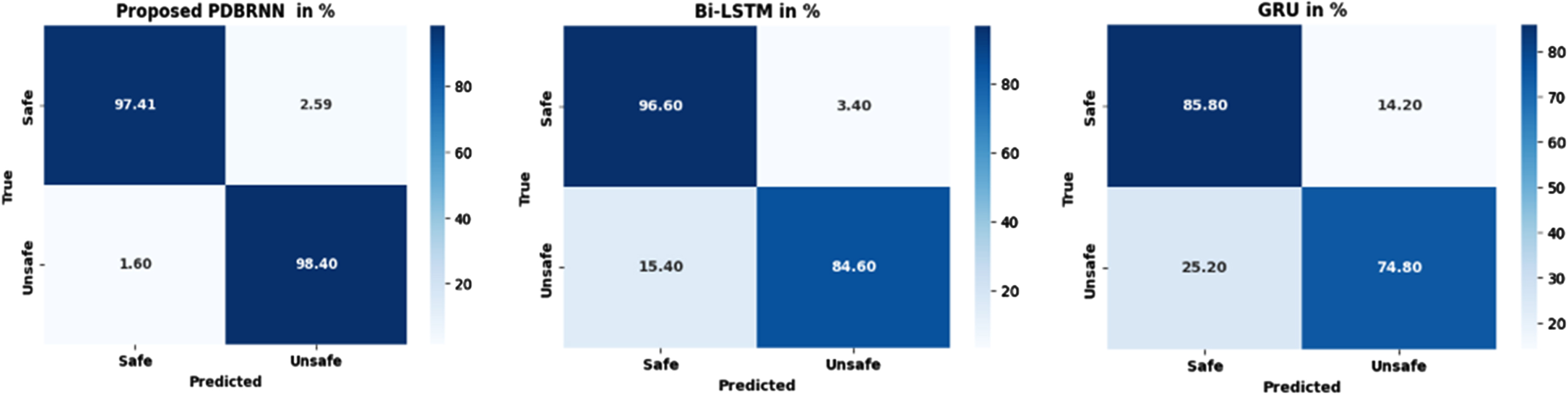
Average confusion matrix.
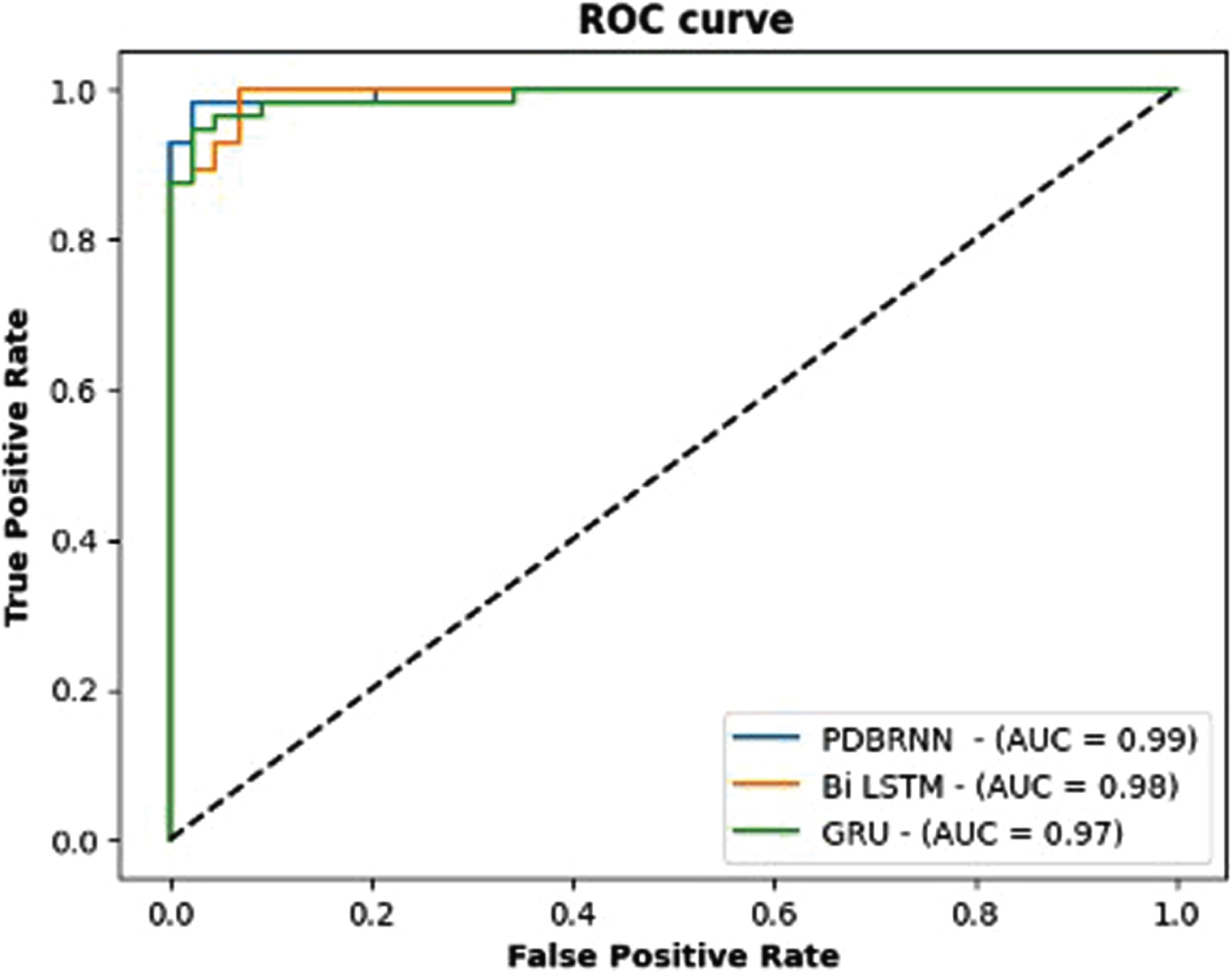
ROC curve –Proposed feature extraction method with various classifier.
In the proposed model’s ROC curve, the Area under the Curve (AUC) value was 0.99, indicating a high level of discrimination and excellent performance in distinguishing between the positive and negative classes. The GRU and Bi LSTM model’s ROC curve had an AUC value of 0.97 and 0.98, which also suggests a strong discriminatory ability, although slightly lower than that of the proposed model.
In this section, we also utilized our proposed preprocessing scheme. We conducted performance analysis for the PEF and other traditional methods by using the PDBRNN classifier. The proposed features extraction exhibited substantial accuracy improvements when compared to traditional features extraction method such as DenseNet121 [41], Inception V3 [22]. Figures 7 and 8 represent the average confusion matrix and ROC curve of the PFE, DenseNet121, and Inception V3, respectively. The validation performance shows that, our proposed feature extraction model achieved a 7.47% increased accuracy and 14.24% increased f1 score compared to DenseNet121, clearly showcasing the effectiveness of our PEF approach.
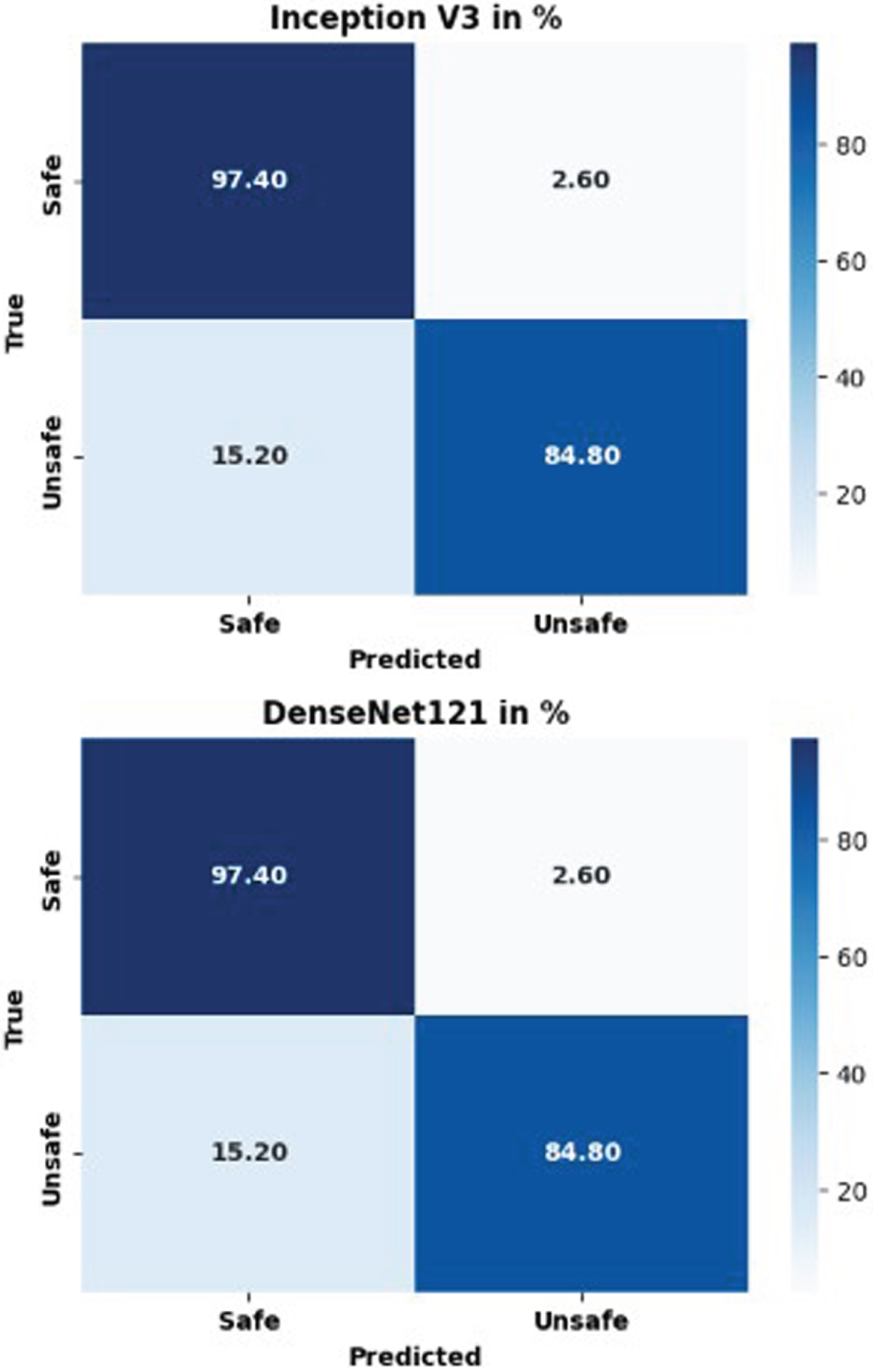
Average confusion matrix for PFE, Densenet121 and inception v3 feature extraction method.
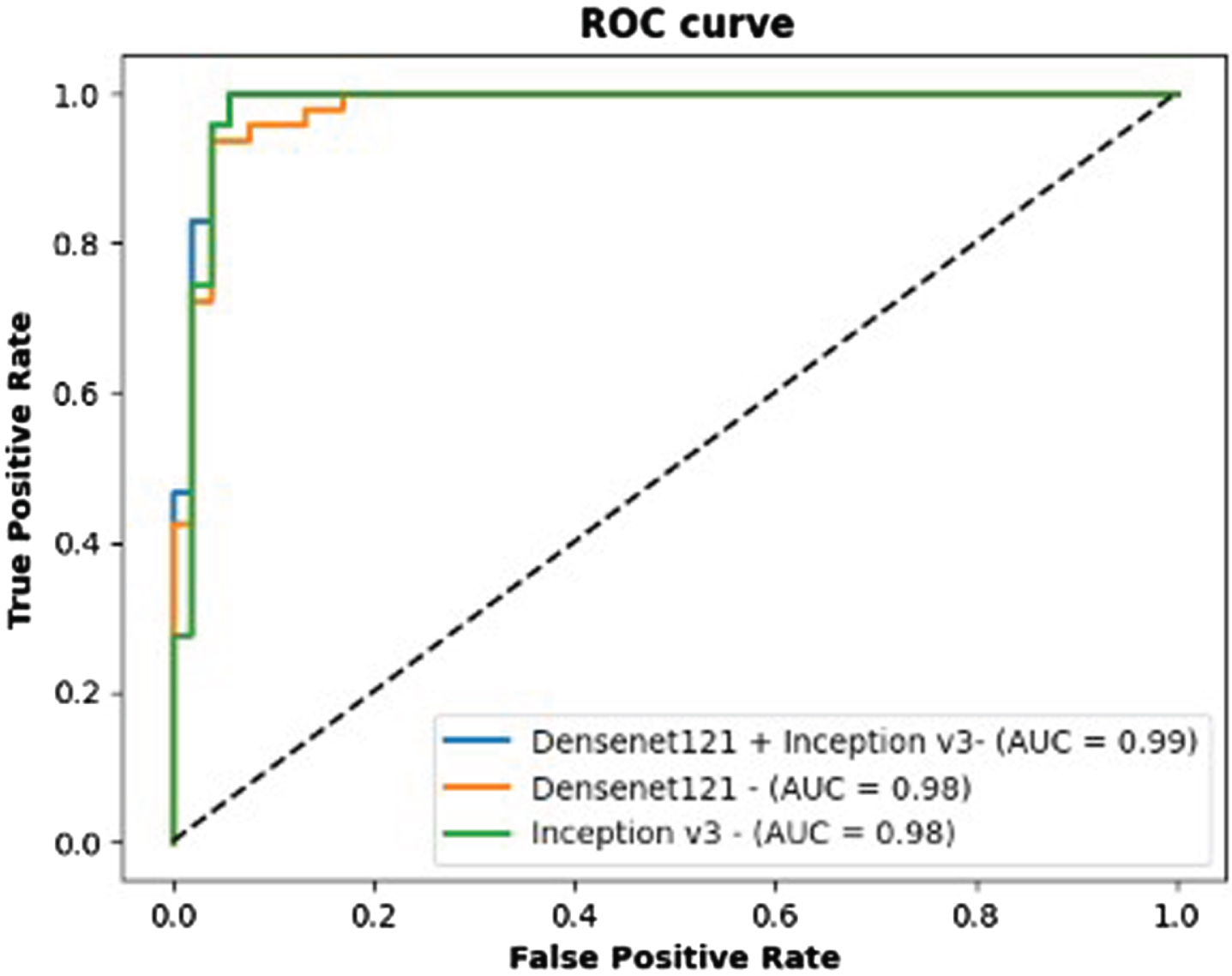
ROC of Proposed features extraction methods with traditional methods.
Additionally, our framework demonstrated an impressive improvement of 1.13% increased accuracy and 1.12% increased f1 score over Inception V3. These results demonstrate the superiority of our proposed PFE in terms of accuracy when compared to other features extraction methods. In the proposed model’s ROC curve, AUC value was 0.99, indicating a high level of discrimination and excellent performance in distinguishing between the positive and negative classes. On the other hand, the DenseNet121 model’s ROC curve showed an AUC value of 0.97, indicating reasonable performance, but it had a relatively lower ability to discriminate between the positive and negative classes compared to the proposed and Inception V3 models.
This study focuses on establishing an efficient approach for identifying and classifying inappropriate content. The proposed method introduces a novel preprocessing scheme that addresses the limitations of manual preprocessing. The Proposed auto-determined k means clustering algorithm determines the optimal cluster count instead of manual specification. The study uses PFE which includes, DenseNet-121 and Inception V3 pre-trained frameworks for efficient feature extraction to improve the content classification video. DenseNet121’s dense connectivity specializes in capturing local features and fine details, while InceptionV3’s multi-scale analysis and global context support captures broader features. Incorporating these two approaches improves effectiveness by providing a full representation of the input images that takes into account both global and local features information. Also, the PDBRNN framework, which includes Bi-LSTM and GRU models, is used for classification purposes. BiLSTM are strong at gathering long-term dependencies, while GRUs are effective at modeling short-term dependencies. The combined use of Bi-LSTM and GRU allows the framework to adapt and learn multiple representations on each branch.
Using our proposed preprocessing technique, proposed feature extraction method, and proposed double-branch RNN classification, we obtained an accuracy of 97.9%. Additionally, our suggested feature extraction strategy obtains a respectable accuracy of 90.59% when combined with a Bi-LSTM-based classifier, while using a GRU-based classifier gives an accuracy of 80.29%. DenseNet-121-based feature extraction and a PDBRNN classifier provide an accuracy of 91.09%, whereas Inception V3-based feature extraction provides a notable accuracy of 96.8%. In the future, we seek to investigate the incorporation of multiple data kinds, such as video footage, audio, text, and contextual information, in order to improve the accuracy and robustness of our content detection.