
Abstract
Due to the complexity of the maritime environment and the diversity of the volume and shape of monitored objects in the maritime, existing object detection algorithms based on Convolutional Neural Networks (CNN) are challenging to balance the requirements of high accuracy and high real-time simultaneously in the field of maritime object detection. In response to the characteristics of complex backgrounds, significant differences in object size between categories, and the characteristic of having a large number of small objects in maritime surveillance videos and images, the Maritime dataset with rich scenes and object categories was self-made, and the OS-YOLOv7 algorithm was proposed based on the YOLOv7 algorithm. Firstly, a feature enhancement module named the TC-ELAN module based on the self-attention mechanism was designed, which enables the feature map used for detection to obtain enhanced semantic information fused from multiple scale features. Secondly, in order to enhance the attention to the area of dense small objects and further improve the positioning accuracy of occluded small objects, this study redesigned the SPPCSPC structure. Then, the network structure was improved to alleviate the problem of decreased object detection accuracy caused by the loss of semantic feature information. Finally, experimental results on self-made datasets and mainstream maritime object detection datasets show that OS-YOLOv7 has a better object detection effect compared to other state-of-the-art (SOTA) object detection algorithms at the cost of reasonable inference time and parameter quantity and can achieve good object detection accuracy on mainstream datasets with high real-time performance.
Introduction
Maritime object detection technology is the foundation of maritime intelligent monitoring and plays an essential role in fields such as maritime rescue, maritime traffic organization and management, and autonomous navigation of ships [1]. However, due to the complexity and diversity of maritime object detection scenarios, there are many challenges in the real-time and accurate detection of maritime objects [2, 3]. In recent years, maritime object detection methods based on Computer Vision (CV) have become a research hotspot in the field of maritime object detection due to their high reliability and practicality [4, 5]. Although CV can achieve maritime object detection based on visible light images, it still faces the following challenges: firstly, maritime objects have the characteristic of significant size differences between categories, and existing object detection methods cannot adapt to objects of all sizes. Secondly, due to the unique and ever-changing maritime environment, the background of maritime images is complex, making it difficult for object detection algorithms to separate objects from the background and extract their feature information, which has a negative impact on maritime object detection. In summary, existing maritime object detection systems based on the CV are challenging to meet practical needs.
In response to the above issues, the OS-YOLOv7 maritime object detection algorithm has been proposed. Among them, the TC-ELAN module is proposed to enhance the feature extraction ability for large objects. For small objects, the MS-SPPCSPC module is proposed while ensuring the real-time performance of the object detection algorithm, and the structure of the network model is redesigned to extract the features of small objects in the image or video frames effectively. At the same time, in response to the problem of a single scene and small size differences of objects in the current mainstream maritime object detection dataset, this study made the maritime object detection dataset named Maritime. Compared with the YOLOv7 algorithm, the OS-YOLOv7 maritime object detection algorithm significantly improves the average accuracy of maritime object detection on publicly available datasets named SeaShips [6] and the Maritime dataset proposed in this study while meeting the detection speed requirements. It can effectively detect small and large objects in real-time and has a good cross-scale detection effect. The main contributions of this study are as follows: In order to solve the problem that small maritime objects are challenging to detect, the improved algorithm improves the network structure of the YOLOv7 algorithm. In view of the significant difference in the scale of maritime objects, we proposed two network module that integrates the self-attention mechanism, named MS-SPPCSPC and TC-ELAN, to extract and enhance the features of different scales better to improve the detection accuracy. According to different types of maritime objects, a new dataset, Maritime, is made, which can meet the common maritime object detection tasks.
Related work
Since the popularity of the Deep Learning (DL) theory, researchers have attempted to improve the universal detection framework based on neural networks and gradually apply it to maritime object detection [11, 12]. Qi et al. [13] proposed an improved Faster R-CNN algorithm for maritime object detection, which extracts useful information in images through the image downscaling method. They also proposed the scene-narrowing technique, which integrates the object area positioning network and Faster R-CNN into the hierarchical narrowing network to reduce the search scale of object detection and improve the speed of reasoning. The algorithm proposed by Shao et al. [14] integrates saliency maps, deep semantic features, and coastline information, achieving high detection accuracy while ensuring good real-time performance. Prasad et al. [15] discussed the evaluation indicators for maritime object detection and proposed the idea of using the bottom edge proximity metrics as a new evaluation indicator for maritime object detection. Gao et al. [16] used YOLOv4 as the basic framework, introduced a threshold attention module to suppress the adverse effects of complex backgrounds and noise, and embedded a channel attention module into an improved BiFPN to fuse features, improving the detection performance of maritime objects. However, these algorithms do not significantly improve the detection performance of maritime objects in complex backgrounds, especially for multi-scale objects.
Redmon et al. [17] proposed YOLOv3 based on FPN, which adopts the multi-level residual network structure and realizes multi-scale feature fusion, which takes into account both detection speed and detection accuracy to a certain extent and brings new ideas for object detection. With the further development of the YOLO series algorithm, YOLOv4 [18] uses a large number of strategies that can improve detection performance on the basis of YOLOv3, which not only reduces the number of model parameters, improves recognition speed but also improves recognition accuracy to a certain extent, which makes it more suitable for real-time detection tasks [19]. YOLOv7 [20] series algorithm is a kind of one-stage object detection algorithm, which is improved based on YOLOv5. It including YOLOv7-tiny, YOLOv7, YOLOv7-d6, YOLOv7-e6, YOLOv7-e6e, YOLOv7-w6, and other versions. The YOLOv7 algorithm can ensure a balance between accuracy and speed during inference on edge devices. The network model of the YOLOv7 algorithm consists of the Input, Backbone, and Head structure. Compared with previous generations of YOLO algorithms, the YOLOv7 algorithm adds the Extended Efficient Layer Aggregation Network (E-ELAN) to the feature extraction network model to accelerate the convergence of the algorithm and improve detection accuracy. Meanwhile, the Spatial Pyramid Pooling Cross Stage Partial Convolution (SPPCSPC) module [21] is introduced in the enhanced feature extraction network of the YOLOv7 algorithm to increase the receptive field. Re-parameterization Convolution (RepConv) [22] is added to the Head structure as a special residual structure of the YOLOv7 network model to assist in training and adjusting the number of channels, reducing network complexity. However, when the object to be detected has interference factors such as multiple categories, is occluded, and has a complex background, the YOLOv7 object detection algorithm is difficult to deal with effectively due to the lack of an efficient feature fusion strategy and feature enhancement method.
This study aims to improve the YOLO series object detection algorithm as the baseline algorithm for engineering application scenarios of maritime object detection. At present, there are many versions of the YOLO series algorithm, and the YOLOv7 algorithm and YOLOv8 algorithm have also emerged with strong detection performance. The YOLOv8 series algorithm has brought an improvement in detection accuracy on the COCO dataset, but its model computation is much larger than YOLOv7, and it sacrifices inference speed. At the engineering application level, as the object detection model needs to be deployed on a hardware platform, considering the computing power issue of the hardware platform, more attention should be paid to the inference speed, computational complexity, and lightweight of the model when the object detection accuracy meets normal requirements. Although the target detection accuracy of the YOLOv7 series algorithm is slightly lower than that of the YOLOv8 series algorithm, it can already meet practical needs and has smaller computational complexity and faster inference speed compared to YOLOv8 (see Table 1). Compared with the YOLOv8 series algorithm, it can better achieve a good balance between detection accuracy, inference speed, and computational complexity. In addition, the YOLOv8 series algorithm is still being continuously updated, which is Not stable enough. Therefore, based on the above considerations, this study ultimately chose the YOLOv7 algorithm for improvement and constructed the OS-YOLOv7 algorithm.
Comparison between the mainstream object detection algorithms on the Microsoft COCO dataset [11, 12]. It can be seen that compared with some mainstream algorithms, the YOLOv7 algorithm has basically maintained a leading position in various evaluation indexes, so this study improves on the basis of the YOLOv7 algorithm. The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better
Comparison between the mainstream object detection algorithms on the Microsoft COCO dataset [11, 12]. It can be seen that compared with some mainstream algorithms, the YOLOv7 algorithm has basically maintained a leading position in various evaluation indexes, so this study improves on the basis of the YOLOv7 algorithm. The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better
In this study, the object detection algorithm used in the maritime environment is based on the OS-YOLOv7 algorithm trained with the self-made dataset. The role of the proposed object detection algorithm in practical applications, such as autonomous navigation, is shown in Fig. 1. This section mainly introduces the main structure and components of the OS-YOLOv7 algorithm.

Taking autonomous navigation of ships as an example, summarize the role of the proposed object detection algorithm in practical applications. In order to achieve the goal of enabling ships to navigate autonomously according to environmental changes like humans, the autonomous navigation system of ships must have capabilities such as environmental perception, intelligent decision-making, and control. Environmental perception is the key to achieving autonomous decision-making. Firstly, images with other targets (such as ships and obstacles) are detected through trained object detection algorithms to generate labeled images. Secondly, autonomous navigation of ships can be achieved by using wired or wireless networks to input the marked image as the current state into the decision system (usually based on reinforcement learning) and output decision signals.
TC-ELAN
Large objects often exist in maritime images [23]. From a type perspective, there are large ships, such as cargo ships, and from the perspective of visual distance, there are objects very close to the camera. These maritime objects account for a large proportion of the image, and the object detection algorithm cannot effectively obtain complete object feature information, resulting in missed or false detection falling into other categories. Therefore, it is necessary to enhance the feature extraction ability for large objects. Efficient Layer Aggregation Network (ELAN) is a new module used for the YOLOv7 object detection algorithm, aimed at solving the bottleneck problem of YOLOv7 object detection algorithm training and deployment on resource-limited devices. The main idea of ELAN is to make full use of their complementary advantages by aggregating the feature maps of shallow and deep networks. The large scale and diverse shapes of objects, such as cargo ships and cruise ships, seriously reduce the detection efficiency of object detection algorithms. Specifically, the spatial location of the distribution of such objects is uncertain, and semantic features are difficult to fully express their shape and appearance information, resulting in some missed and false detections in the detection process of the object detection algorithm. At present, due to the strong ability of non-local feature extraction, the self-attention mechanism is outstanding in the field of CV [24]. However, the self-attention mechanism lacks the characteristic of inductive bias, so its generalization ability is at a disadvantage compared to convolution. The ELAN module uses normal convolution to extract features, which has certain limitations. Compared to the convolutional module, the Multi-Head Self-Attention (MHSA) [25] module dynamically calculates weights using the similarity function between relevant pixel pairs, which enables the MHSA module to obtain the global feature relationship and adaptively capture more effective feature information. This study proposes a new module, TC-ELAN, that combines the advantages of self-attention and convolution. This module not only enhances the sensitivity of object detection algorithms to large maritime objects but also reduces the noise impact caused by the background. Fig. 2 shows the structure diagram of TC-ELAN.

The network structure of the TC-ELAN module. The TC-ELAN module accelerates the speed of reasoning by introducing GSConv and then embeds the MHSA attention mechanism and the DCN module to focus on large object areas, which can reduce the missed detection and false detection rates for large object detection.
Due to the different shooting angles taken by the camera and the types of maritime objects themselves, the effectiveness of DL-based maritime object detection methods is not satisfactory. In this study, the Deformable Convolutional Network (DCN) module with offsets learning ability is embedded in the TC-ELAN module to enable convolutional to change the shape and size of the receptive field according to different maritime objects. Normal convolution can only achieve feature extraction for fixed-size receptive fields, while Deformable Convolutional V2 [26] can make the receptive field change with different shooting angles, maritime object shapes, and sizes. Deformable Convolutional V2 has the ability to adapt spatial aggregation, making up for the shortcomings of normal convolution in long-range dependence and adaptive spatial aggregation and achieving a better balance between computational complexity and accuracy. At the same time, in order to reduce the parameter quantity and computational complexity of the object detection algorithm and accelerate the inference speed of the network model, this study introduces the GSConv [27] module to ensure the real-time performance of the object detection algorithm. Although the GSConv model promotes information connectivity between feature maps, if the network model uses GSConv at all stages, it will deepen the depth of the network model, thereby reducing the detection speed of the algorithm. This study uses the 1 × 1 convolution operation to reduce the spatial dimension of the feature map and increase the channel dimension. At this time, the use of the GSConv convolution method not only reduces redundant and repetitive semantic information and ensures sufficient extraction of object feature information but also reduces the number of parameters, thus laying the foundation for the realization of the lightweight network model.
In the field of maritime object detection, due to the diversity of scales among different maritime object individuals, most maritime object detection methods are not sensitive to small-scale objects. The proportion of distant maritime targets in the image is relatively small, so additional attention needs to be paid to the small object detection ability of the object detection algorithm. The Microsoft COCO dataset [7] defines objects with a ground truth box area of less than 32 × 32 pixels as small objects. Mainstream algorithms that focus on small object detection come at the cost of longer detection time and are often unable to effectively detect large targets, making them unsuitable for maritime object detection. Therefore, in order to enhance the attention to the area of dense small objects and further improve the positioning accuracy of small objects under mutual occlusion, this study proposes the MS-SPPCSPC module. The SPPCSPC module and MS-SPPCSSPC module are shown in Fig. 3 (a) and Fig. 3 (b).
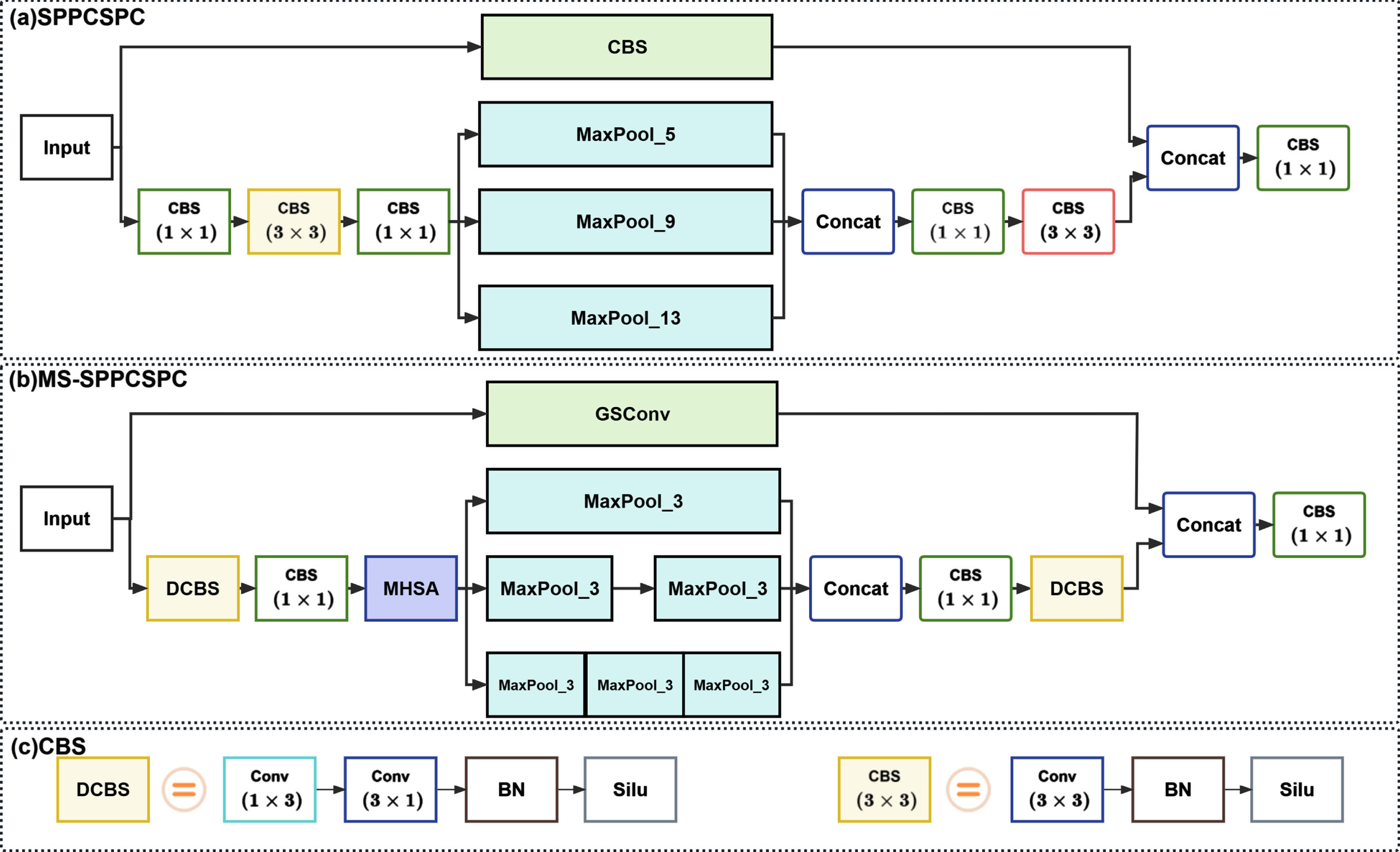
The network structure of the MS-SPPCSPC module. The parallel pooling operation of the MS-SPPCSPC module can fuse multi-scale non-local context information, improving the feature extraction ability of small objects without affecting the feature extraction of large objects effects.
This study proposes the MS-SPPCSPC module. Firstly, in order to reduce memory access costs and improve model training efficiency, we remove the first 1 × 1 CBS module to reduce computational complexity and parameter quantity. We divide the 3 × 3 convolution module into 3 × 1 convolution and 1 × 3 convolution to reduce parameter quantity. Secondly, the normal convolutional layer in the residual branch structure of SPPCSPC is replaced with a GSConv convolutional module with the channel shuffling ability to reduce computational complexity while fusing multi-channel semantic features. At the same time, MHSA is embedded before the maximum pooling layer to reduce the loss of effective features and suppress obfuscated feature expression. During training, although the SPPCSPC module performs well, the parameter quantity and computations are too large. As inspired by the SimSPPF module [28], we change the size of the three pooling kernel from (5,9,13) to (3,5,9) so that the receptive field expanded by the pooling kernel matches the scale of the small object, which is conducive to extracting more small object features and further improving the accuracy of small object detection. The MS-SPPCSPC module divides the input into two parts, with part one cascade pooling the maximum pooling layer with a kernel size of 3 × 3. Among them, the maximum pooling module with two pooling layers with kernels of 3 × 3 and the maximum pooling layer with one pooling kernel of 5 × 5 have the same receptive field size. The maximum pooling module with three pooling layers with kernels of 3 × 3 and the maximum pooling layer with one pooling kernel of 9 × 9 have the same receptive field size. Replacing pooling layers that have large pooling kernels by cascading pooling layers that have small pooling kernels can reduce computational costs and improve the reason speed and detection reason efficiency can be improved. Part two consists of the GSConv module. The concatenate of part one and part two through 1 × 1 CBS module to generate the fixed-size feature map to play a role in feature enhancement.
Aiming at existing object detection algorithms based on Convolutional Neural Networks (CNN) is challenging to meet the requirements of high accuracy and real-time in the field of maritime object detection, and the mainstream object detection algorithms were compared on the Microsoft COCO dataset (see Table 1). That is, YOLOv7 is selected for subsequent research based on the self-made dataset of this study.
The head section of YOLOv7 includes three detection heads, with output feature map sizes of 80 × 80 pixels, 40 × 40 pixels, and 20 × 20 pixels, respectively. The detection head with the largest output feature map (80 × 80 pixels) is suitable for detecting small objects due to its small receptive field, so it is the small object detection head. Similarly, the smallest output feature map (20 × 20 pixels) is the large object detection head. The output feature map size (40 × 40 pixels) is the normal object detection head. Due to the semantic information of small objects in maritime objects being easily lost after multiple convolutions and downsampling, the accuracy of object detection is low. In response to this problem, this study improves on the head section of YOLOv7 by adding the tiny object detection head to enhance the extent ability for shallow features. The original 3-scale detection has been changed to 4-scale detection, and that tiny object detection head of 160 × 160 pixels has been added to preserve shallow semantic feature information while obtaining as much deep semantic feature information as possible. Although the addition of small object detection heads increases the complexity of the model and affects the detection speed during training, the final experimental results show that the accuracy of the detection algorithm has been improved to a certain extent (see Table 2). The network model of OS-YOLOv7 is shown in Fig. 4.
The comparison of experimental accuracy on the Microsoft COCO dataset [7] dataset between the improvement of the detection head and the YOLOv7 algorithm is added. The Microsoft COCO dataset was created by Microsoft Corporation in the United States. The purpose is to promote the development of object detection technology by placing object detection problems in a broader background of scene understanding. Therefore, the images in the Microsoft COCO dataset include not only common objects in the natural environment but also objects in complex daily scenes. The Microsoft COCO dataset contains 80 categories, including almost all common object categories in daily scenes, with a large portion being small objects. The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better
The comparison of experimental accuracy on the Microsoft COCO dataset [7] dataset between the improvement of the detection head and the YOLOv7 algorithm is added. The Microsoft COCO dataset was created by Microsoft Corporation in the United States. The purpose is to promote the development of object detection technology by placing object detection problems in a broader background of scene understanding. Therefore, the images in the Microsoft COCO dataset include not only common objects in the natural environment but also objects in complex daily scenes. The Microsoft COCO dataset contains 80 categories, including almost all common object categories in daily scenes, with a large portion being small objects. The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better
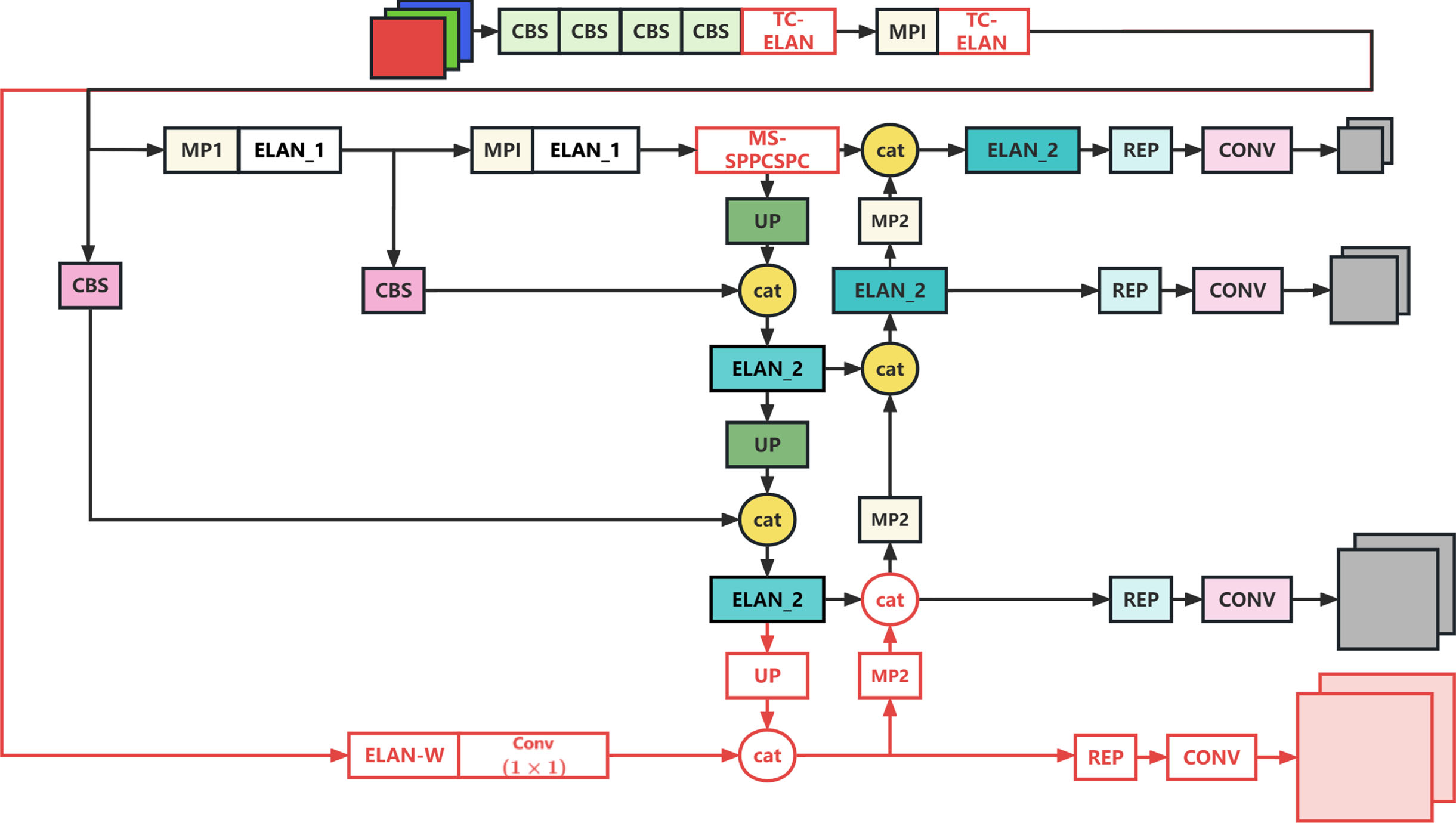
The network structure of the OS-YOLOv7 network model. The red boxes and arrows represent the improvements made to the YOLOv7 algorithm in this study.
In order to verify the practicability and effectiveness of the proposed algorithm, the self-made dataset was used for training and test verification on a desktop computer equipped with NVIDIA RTX 3070Ti. The experimental environment uses the Windows 10 operating system, and the algorithm proposed in this study is built through the Pytorch framework. In order to better compare with similar networks, the hyperparameters during our algorithm training are mainly set according to the study. During network training, the batch size is 8, the optimizer selects ReLU, the maximum iteration epoch is 200, and the learning rate is 0.0001. The software version and hardware configuration of this network model are shown in Table 3.
Experimental software version and hardware configuration
Experimental software version and hardware configuration
At present, there are few publicly available maritime object datasets. Through analyzing the existing maritime object datasets, we found that these datasets have few data categories and simple backgrounds. The size changes of maritime objects are not significant, which is not in line with the diverse changes of maritime objects in actual scenarios. As a result, the detection ability of the trained maritime object detection algorithms is limited. The results of object detection based on DL are not only related to the network framework structure of the object detection algorithm but also highly dependent on the design of the object detection dataset [29, 30]. Only when the dataset can contain as many maritime object characteristics as possible can the network framework of the object detection algorithm fully extract the semantic features of maritime objects. The data samples mainly come from surveillance video frames at different shooting angles and scales captured by 42 cameras. At the same time, the dataset is augmented by rotating, blurring, and changing saturation on the maritime object dataset and annotated using the LabelImg tool. The dataset is named Maritime, and the dataset instance and the augmentation effect of the dataset are shown in Fig. 5 and Fig. 6. This dataset contains a total of 13178 images, divided into training, validation, and testing sets at a ratio of 8:2. To verify the universality of the OS-YOLOv7 algorithm, we also conducted simulation experiments on the public dataset, namely SeaShip [6].

The examples of the self-made dataset.

The data augmentation effect of some images of the self-made dataset.
This study uses a variety of detection-related evaluation indicators to evaluate the performance of the object detection network from various aspects. The evaluation index of this experiment includes Intersection over Union (IoU), Precision, Recall, F1-Score, and mAP. The formula of the Precision, Recall, F1-Score, and mAP coefficient can be expressed as follows:
The mAP indicator represents the average of different types of average precision, the mAP @ 0.5 indicator represents the probability of accurate prediction when the IoU of candidate bound and ground truth bound is more significant than 0.5; the mAP @ 0.5 : 0.95 indicator represents the mean value of the probability of accurately predicting the IoU of candidate bound and ground truth bound within the range of 0.5 ≤ IoU ≤ 0.95.
In recent years, there have been many achievements in object detection, but there are few studies on real-time target detection. Real-time target detection is more in line with the development requirements of practical applications. Different methods have different speeds for image target detection. In the field of autonomous driving, the algorithm that the detection speed exceeds 30 FPS is called the real-time image processing algorithm [33].
In order to verify the effectiveness of the OS-YOLOv7 algorithm, this experiment was conducted on the self-made dataset, and the detection results of the OS-YOLOv7 algorithm were compared and analyzed with the detection results of current mainstream object detection algorithms. Table 5 shows the experimental results of different algorithms on the self-made dataset, mainly comparing the detection accuracy and speed of YOLOv5n, YOLOv5x, YOLOv7, and OS-YOLOv7 algorithms. Fig. 7 shows the curves of the four evaluation indicators for the OS-YOLOv7 algorithm, the YOLOv7 algorithm, and the YOLOv5x algorithm during training on the self-made dataset. The experiment shows that the OS-YOLOv7 algorithm has significantly improved detection accuracy compared to the YOLOv7 algorithm, mAP@0.5 and mAP@0.5:0.9 increased by 9.28% and 9.21%, respectively, which significantly improved detection accuracy without significantly reducing detection speed.
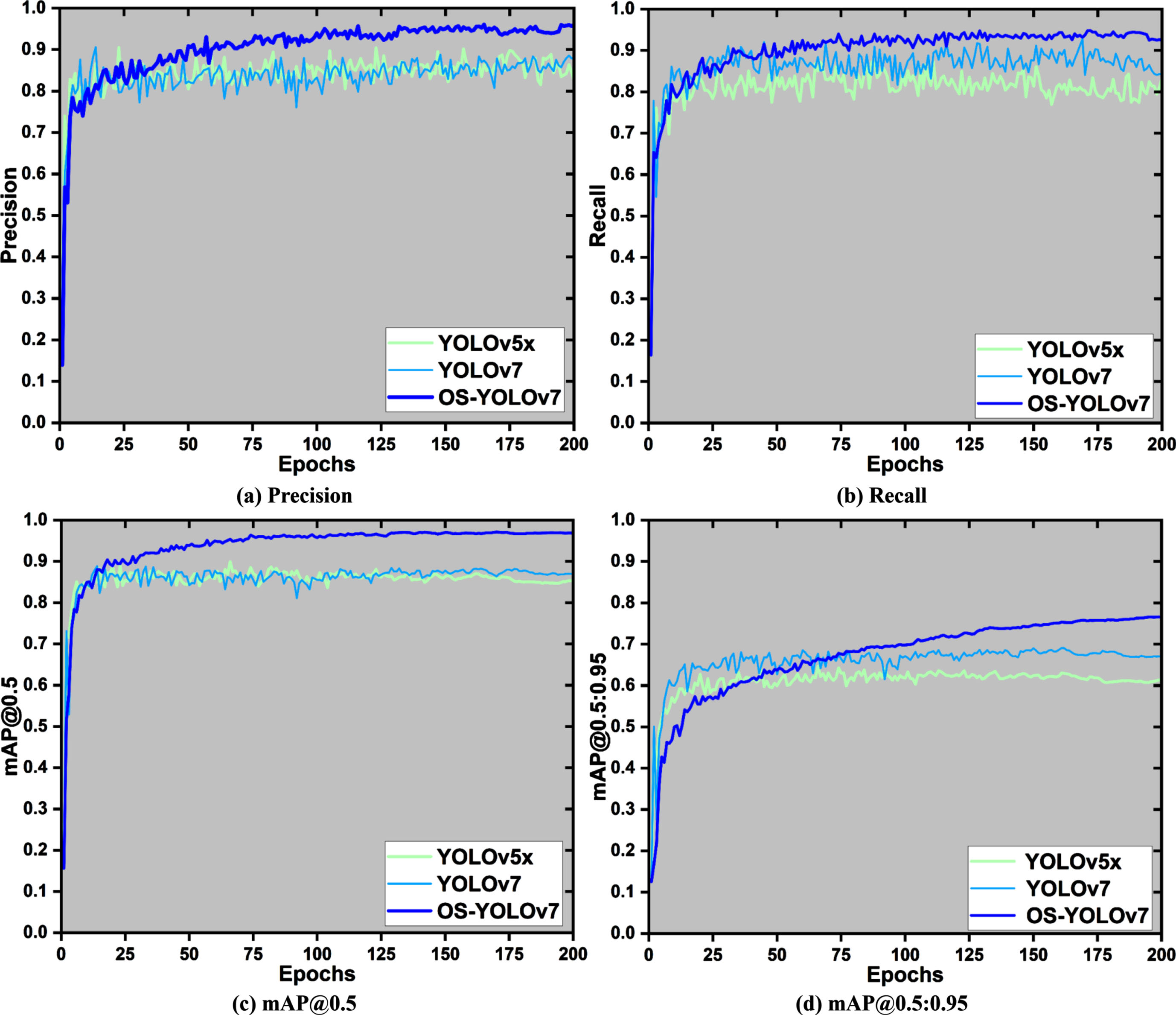
The curves of the four evaluation indicators for the OS-YOLOv7 algorithm, the YOLOv7 algorithm, and the YOLOv5x algorithm during training on the self-made dataset. (a) The precision curve. (b) The recall curve. (c) The mAP@0.5 curve. (d) The mAP@0.5:0.95 curve.
To further verify the algorithm’s detection performance for different objects, Fig. 8 visually compares the detection accuracy of YOLOv7 and the improved algorithm OS-YOLOv7 for various types of objects. The data shows that OS-YOLOv7 has higher detection accuracy than YOLOv7 in various categories, with the most significant improvement in detection performance for the category named Person, and compared to YOLOv7, the precision indicator has been improved by 13.76%. Among all maritime objects, the objects in the Person category are usually smaller, and the experimental results verify the improvement of the OS-YOLOv7 algorithm in conventional maritime object detection ability and significant improvement in maritime small object detection ability. Finally, to verify the generalization performance of the OS-YOLOv7 algorithm, comparative experiments were continued on the SeaShip dataset. The results are shown in Table 4. Compared with other mainstream object detection algorithms, the improved algorithm performs better in Precision indicator and Recall indicators. Compared to the YOLOv7 algorithm, the Precision indicator and Recall indicator increased by 4.3% and 0.6%, respectively.
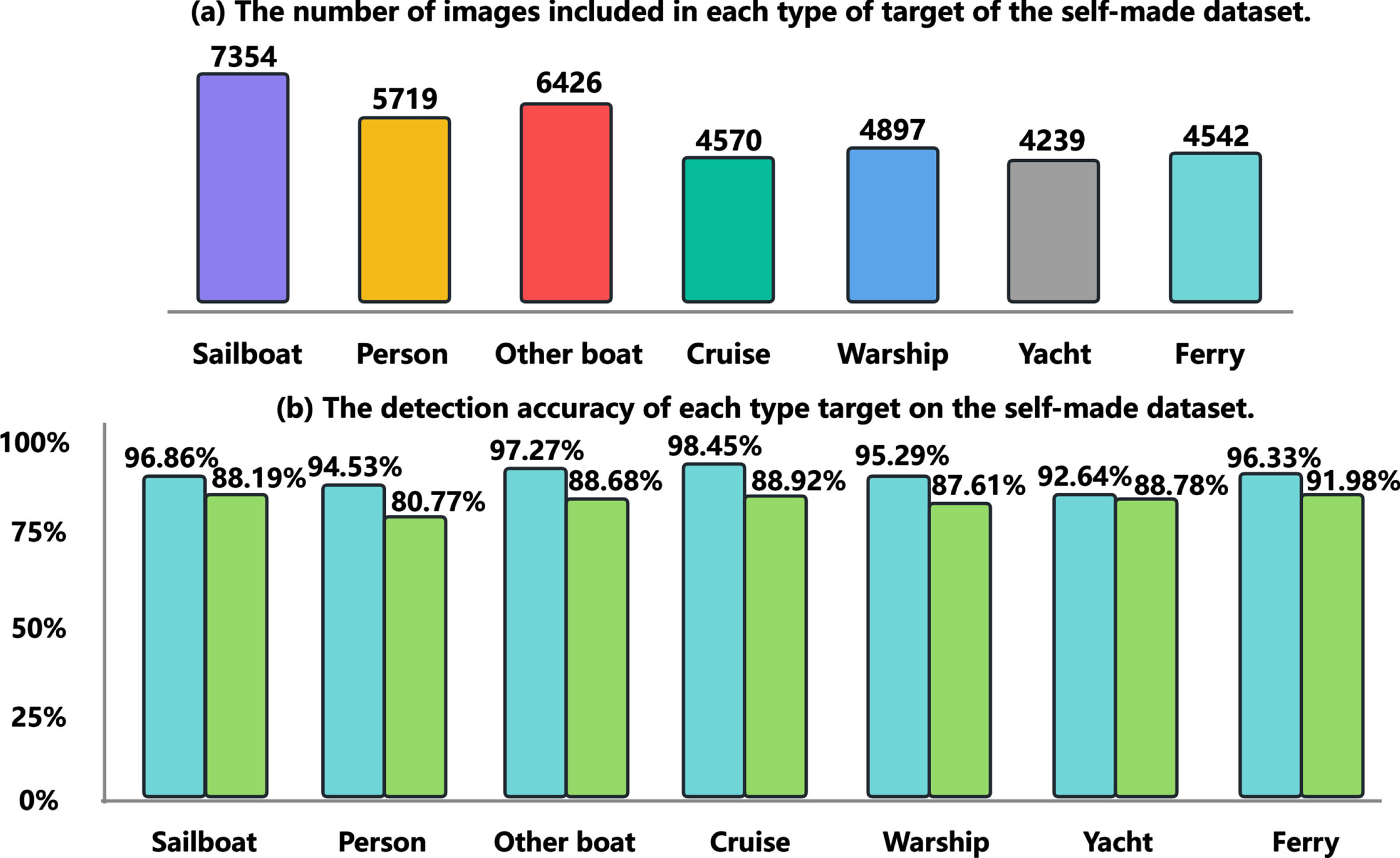
The number of images in the self-made dataset containing each object type and the detection accuracy of each object type on the self-made dataset.
On the Maritime and SeaShip datasets, the OS-YOLOv7 algorithm has different performance improvements compared to the YOLOv7 algorithm, and its improvement is more significant on the self-made dataset. This is because the image illumination changes in the SeaShip dataset are more intense, which, to some extent, limits the algorithm’s ability to process detailed information. However, the improvement in detection performance is still considerable, indicating that the OS-YOLOv7 algorithm still has stronger detection ability compared to the original algorithm in complex light conditions. Fig. 9 shows the comparison of detection results between YOLOv7 and OS-YOLOv7 algorithms on the self-made dataset. For each set of images, the left side is the original image, the middle is the result of YOLOv7 algorithm detection, and the right side is the result of OS-YOLOv7 algorithm detection. As shown in the figure, the OS-YOLOv7 algorithm has improved its ability to detect small objects compared to the YOLOv7 algorithm while also improving the problem of missed detection of small objects. At the same time, the OS-YOLOv7 algorithm can also effectively detect large maritime objects and improve the detection of occluded objects.
Comparison between the mainstream object detection approaches on the SeaShip [6] dataset. The SeaShip dataset is a current publicly ship target detection dataset consisting of 31455 ship images with a resolution of 1920 × 1080 captured through video surveillance. It includes six types of ships: ore carrier, general cargo ship, container ship, bulk cargo carrier, fishing boat, and passenger ship. This dataset takes into account factors such as different types of ships, different proportions of ship bodies, different perspectives, different illumination, and different degrees of occlusion in various complex backgrounds, and it is the first publicly available dataset created for ship detection tasks. The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better
Comparison with mainstream object detection approaches on the self-made dataset (The best results are bolded). The optimal value for each of these evaluation criteria has been bolded in black, “↑” indicates that a larger value of the evaluation criterion is better, while “↓” indicates that a smaller value of the evaluation criterion is better

Visual comparison between the YOLOv7 algorithm and the OS-YOLOv7 algorithm.
The original network and the improved network with each module were tested on the self-made dataset, and TC-ELAN, MS-SPPCSPC, and small object detection heads were used as validation modules for ablation experiments. The training results are shown in Table 6. It can be seen that the TC-ELAN module, MS-SPPCSPC module, and small object detection head all improve the model detection performance. Among them, the introduction of the MS-PPCSPC structure will, to some extent, improve the detection accuracy of the model, while the introduction of TC-ELAN will significantly improve the detection accuracy. Different combinations of the proposed modules can improve the detection performance of the model to a certain extent, and the mAP@0.5 indicator of the OS-YOLOv7 algorithm in the training results is 96.59%, 9.28 percentage points increase compared to the YOLOv7 algorithm, which is the optimal result, while the FPS index only slightly decreases. Overall, the OS-YOLOv7 algorithm is more accurate and has a higher level of detection for maritime objects.
Comparison between related detection algorithms. Among them, “✓” means adding the corresponding module, “×” means not adding the corresponding module (the best results are bolded). Overall, the OS-YOLOv7 algorithm improves the detection accuracy of the algorithm, effectively balancing accuracy and lightweight, providing feasibility for algorithm deployment on edge terminal devices
Comparison between related detection algorithms. Among them, “✓” means adding the corresponding module, “×” means not adding the corresponding module (the best results are bolded). Overall, the OS-YOLOv7 algorithm improves the detection accuracy of the algorithm, effectively balancing accuracy and lightweight, providing feasibility for algorithm deployment on edge terminal devices
This study aims to address the issue of low accuracy in existing maritime object detection algorithms. The self-made dataset with the rich scene and object categories is built, and the OS-YOLOv7 object detection algorithm based on YOLOv7 is proposed. This algorithm has cross-scale detection capabilities and can effectively detect maritime objects. The OS-YOLOv7 algorithm improves the structure of the network model and proposes the MS-SPPCSPC module to capture multi-scale non-local context information, enhancing the ability to detect small objects. By introducing the TC-ELAN module into the network model, the ability to extract large object features is enhanced. Experiments on the publicly available SeaShips dataset and the self-made dataset in this study have confirmed that the OS-YOLOv7 algorithm proposed in this study has good multi-scale detection capabilities and can effectively improve the missed and false detection problems in small and large object detection in maritime scenarios. On the self-made dataset, the mAP@0.5 indicator increased by 9.21%, and the Precision indicator increased by 8.09%. The OS-YOLOv7 algorithm can be used in object detection systems in maritime supervision or autonomous ship driving scenarios to monitor real-time maritime traffic conditions, timely reflect safety hazards in ship navigation, and play an important role in the safe operation of ships.
In future research, the real-time performance of the OS-YOLOv7 object detection algorithm needs to be further improved to achieve faster object detection. The types of maritime objects will be further refined, expanded, and fused with other maritime sensor data to construct larger and more complex datasets to train the object detection algorithm, thereby making the object detection algorithm more accurate in identifying maritime objects.