
Abstract
Traditional fault detection methods in acoustic signal feature extraction of rolling bearings often make the signal denoising process complex due to low signal-to-noise ratio and weak fault features, making this method difficult to meet real-time requirements. Therefore, a fault detection model based on Fast-Renoriented SIFT feature extraction is proposed, which can quickly extract a large number of features from the original signal without the need for noise reduction processing and can effectively improve the efficiency and accuracy of fault detection. At the same time, to adapt to the fault detection of rolling bearings under multiple working conditions, this study also proposes an adaptive extended word bag model that combines local kurtosis and local 2-dimensional information entropy features, improving the adaptability and flexibility of the new model. It obtained a 100% overall recognition rate and a fault detection time of no more than 0.5 seconds in a 5-fold cross-validation experiment, verifying the excellent recognition accuracy, stability, and operational efficiency of the detection model. Its recognition accuracy in the multi-working condition rolling bearing fault detection experiment was above 97%, which was improved by about 21.25% compared to the traditional word bag model and had significant advantages in fault recognition accuracy and computational efficiency.
Keywords
Introduction
As the machinery manufacturing industry marches towards high accuracy and intelligence, large-scale equipment in industrial production is becoming increasingly intelligent, automated, and complex. Although mechanical equipment upgrading has brought significant help to the improvement of production efficiency and product quality of enterprises, it is difficult to avoid problems such as parts aging, operational errors, and equipment failures in large-scale machinery engineering applications [1, 2]. The core components of rotating machinery often have several types of failures due to long-term high-speed operation, load changes, and other objective or artificial reasons. In particular, rolling bearings in automated rotating machinery account for approximately 30% of all rotating machinery failures [3]. Roller bearing life has a greater dispersion than other parts with significant differences in the service life, failure rate, and severity of rolling bearings produced in the same batch [4, 5]. Therefore, achieving accurate detection of rolling bearing fault types is important for production loss reduction and the safe operation insurance of equipment. Currently, most rolling bearing fault detection analyzes the vibration signal, and the characteristics of acoustic signals need further study. Compared with traditional methods, fault detection methods based on acoustic signals have higher detection efficiency, simpler acoustic sensor structure, and easier acquisition of acoustic signals, making acoustic signal fault detection methods more promising for research. At the same time, acoustic sensors are easier to realize the signal measurement, which makes the acoustic sensors have a wider scope of application. Fangli et al. proposed a rolling bearing fault diagnosis method that combined acoustic signals and visual converters, the new method diagnosed the mechanical bearings by adding the mechanism of attention, but the fault identification accuracy of the new method was insufficient [6]. Xu et al. proposed a fault diagnosis method for mechanical rolling bearings based on wavelet packet decomposition, which established a fault diagnosis model through convolutional neural networks. However, the application scope of fault diagnosis was limited. Therefore, this study focused on the acoustic signals of rolling bearings. To improve the accuracy and stability of fault recognition, a feature extraction and word bag modeling method based on the Fast-Unoriented Scale Invariant Feature Transform (SIFT) algorithm was proposed [7]. To enhance the applicability of the method, an adaptive extended bag-of-words model of acoustic information is introduced to enhance the applicability of the method. This study is divided into four parts. The first part summarizes and analyzes the literature in the current field; The second part builds a fault detection model based on acoustic signals and the Fast-Unoriented SIFT algorithm; The third part mainly tests the limitations and progressiveness of the current algorithm through experiments; The fourth part is a summary and analysis of the current research.
Related work
Feature extraction is a prerequisite and an important process for fault detection based on collected data, especially in acoustic signal-based fault diagnosis, which has more complex background noise information. Therefore, noise reduction preprocessing and feature extraction of the original signal are essential. Zhang and other scholars, to solve the problems of traditional fault diagnosis methods that rely on experimenters’ experience for feature extraction and unsatisfactory classification rate of shallow diagnostic models, proposed a method of converting raw signals into two-dimensional images and introduced an intelligent diagnosis algorithm based on a convolutional neural network. The research results showed that the new method automatically completed the feature extraction and fault diagnosis, eliminating the influence of expert experience and improving the classification accuracy [8]. Glowacz et al. proposed a corner domain virtual multi-channel signal composite fault detection method to solve the problem of mechanical fault diagnosis under variable speed conditions, especially with limited research on composite fault diagnosis. The new method converted non-stationary vibration signals into steady-state signals by constructing virtual multi-channel signals and eliminated the effect of velocity fluctuations. The experimental results showed that the new method effectively detected the composite faults of rolling bearings under different velocity conditions, which proved the effectiveness of the new method [9]. Gunerkar et al. proposed a new technique of fusing vibration sensors and acoustic emission sensors to improve the accuracy and comprehensiveness of bearing fault diagnosis. The new technique obtained more comprehensive fault information through advanced sensor fusion. The results showed that vibration-based sensors were more advantageous in detecting inner and outer raceway defects, while acoustic sensors were better at detecting ball defects. The fused approach helped in the early detection of all faults in bearings [10]. Plaza et al. studied four feature extraction methods by vibration signals, finding that singular spectrum analysis and wavelet packet transformation can better extract vibration signal features. Computational costs of singular spectrum analysis were high, and vibration signals and wavelet packet transform had the advantages of high accuracy and low cost in real-time surface finish monitoring [11]. Based on compression sensing theory, Wang C proposed a method to enhance the weak fault feature to diagnose acoustic bearing emission signal fault. This method used compression theory for the compression and sample of the square acoustic emission signal and used particle swarm optimization for the weight coefficient, effectively improving its accuracy and efficiency of fault feature extraction and bearing fault classification [12]. Mostafaei et al. proposed a new modeling method to monitor the status of synchronous generators and described the drawbacks and challenging issues in modeling. The results of the study showed that the behavior of synchronous generators in the presence of faults was very complex and its condition monitoring was not studied deeply enough [13]. Kumar et al. proposed a fault detection method combining convolutional neural network and batch normalization to perform early fault detection of squirrel cage induction motors to improve productivity. The results showed that the new method was able to perform feature extraction and selection automatically and reliably, and effectively detect bearing faults and rotor bar breaks [14]. Strömbergsson et al. proposed a method for vibration state monitoring using discrete wavelet transform (DWT) and Fourier transform (FFT) to address the issue of premature failure of fan components. The results of the study showed that the DWT and Fourier transform were superior in bearing failure detection compared to the FFT and detected bearing failures earlier and more clearly [15].
The detection of bearing faults in automated machinery is a process of identifying fault types. Common methods include support vector machine (SVM), clustering analysis, and neural networks. Hasan et al. proposed a fault classification technique with high diagnostic accuracy and robustness based on acoustic emission signal spectroscopy imaging as an accurate health state in response to the easily changing characteristic characteristics under variable speed conditions with migration learning. [16]. Chen et al. extracted different frequency signal features by two different CNN cores automatically and then identified fault types by LSTM. This not only achieved an average accuracy of 98.46% but also verified its superior performance in noisy environments [17]. Wang et al. proposed a bearing fault detection method combining attention mechanism and CNN for the difficulty in understanding and learning fault features in complex detection signals and verified excellent detection performance on wheelset bearing data sets [18]. Wang et al. achieved automatic extraction of image features based on symmetric point pattern representation, attention mechanism, and CNN. This method achieved a classification rate of over 99% and had good generalization performance and stability [19]. Y Tian et al. introduced an attention mechanism to help depth networks locate useful data segments and perform discriminant feature extraction and diagnostic knowledge visualization. This bearing fault detection method can achieve good detection results with little training data [20].
In summary, many experts and scholars have proposed various innovative methods to improve the accuracy and efficiency of feature extraction in acoustic signal analysis in the field of fault detection. These methods include converting signals into two-dimensional images, integrating multiple sensor technologies, utilizing advanced algorithms such as CNN and attention mechanisms, and utilizing compressed sensing and particle swarm optimization. However, at the same time, these methods still have some problems in acoustic signal analysis and fault detection, such as low data extraction ability and insufficient recognition accuracy. Therefore, to solve these problems, this study proposes the Fast-Unoriented SIFT algorithm and adaptive extended word bag model to enhance the fault recognition accuracy and feature data extraction ability of the current detection method.
A rolling bearing fault detection model based on fast-unoriented SIFT and word bag model
Feature extraction algorithm based on fast-unoriented SIFT
Due to the problems of low signal-to-noise ratio, severe signal modulation, and weak fault characteristics in acoustic signals of rolling bearings, traditional feature extraction methods have become complex and require small extraction amounts. Therefore, this study proposes a fault detection method that does not undergo complex noise reduction and redundant feature removal and uses a three-layer fault detection method for fault detection. The process is shown in Fig. 1.
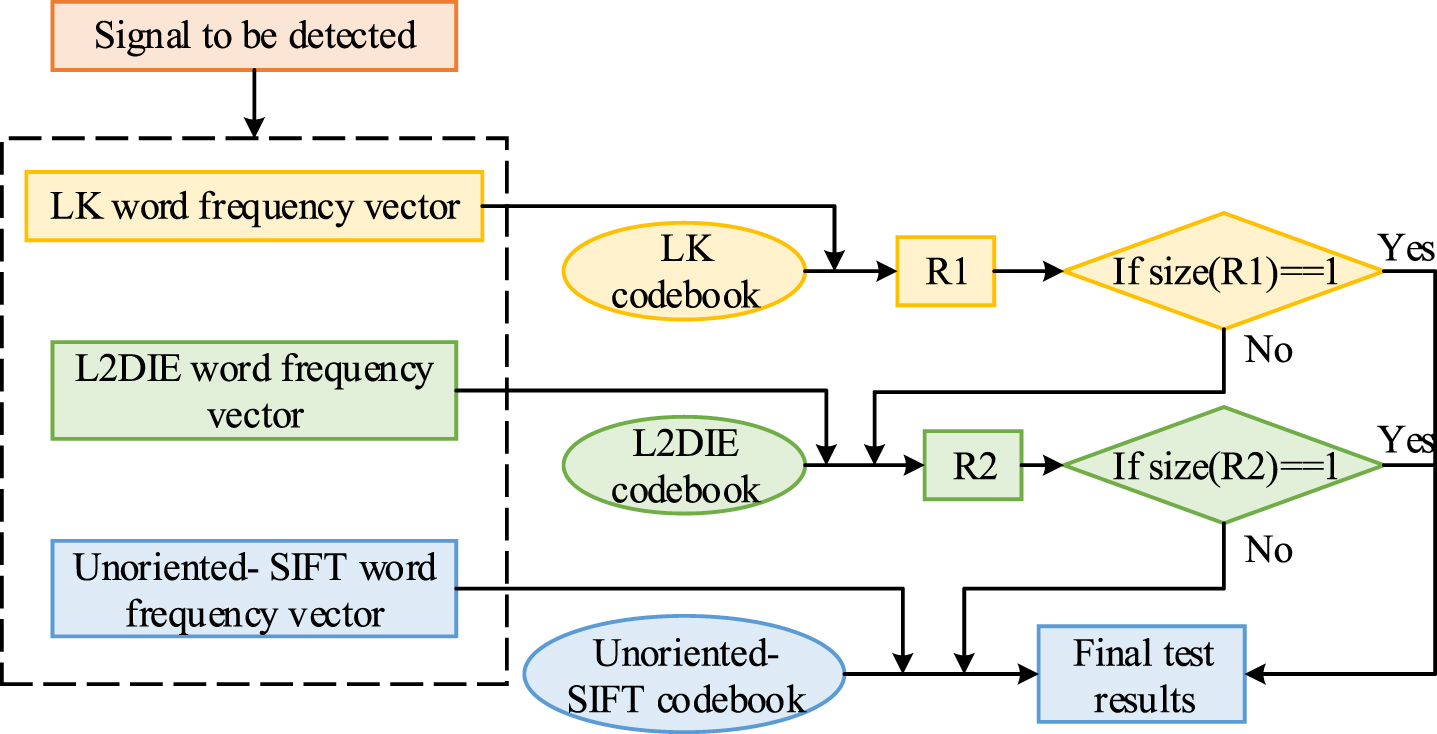
Flow chart of three-layer fault diagnosis.
In Fig. 1, to make the word bag model more suitable for fault diagnosis under multiple working conditions, the study extends the word bag model to a three-layer structure and establishes the codebook for each layer using local kurtosis (LK) features, local 2-dimensional information entropy (L2DIE), and Fast-Unoriented features. R1 in the figure represents the diagnostic result after the completion of the first layer fault detection, and R2 represents the diagnostic result after the completion of the second layer fault detection. In the first layer of fault detection, the distance between the LK word frequency vector of the signal segment and each codebook vector in the LK codebook is calculated. The smaller the distance, the more similar the fault type represented by this vector is. In the second layer of diagnosis, the vocabulary vector L2DIE for the signal interruption and the fault types represented by the vector distance in the L2DIE codebook are calculated. Then, the fault probability in the upper layer results is calculated, and more than 99% of the fault types are used as the diagnostic result R2 for the second layer, and as the diagnostic input result for the next layer. Otherwise, the next layer calculation is carried out. The third layer calculates the distance between the Unoriented SIF codebook and the fault type, selects the type with the lowest distance as the diagnostic result, and completes the fault diagnosis. The evaluation of the probability that the signal of the segment belongs to each fault type is calculated as shown in Formula (1).
In Formula (1), the variable N
f
represents the overall count of fault categories.
In Formula (2), S p q represents the state of the candidate feature point p relative to the pixel point q. There are three states: darker q d , brighter q b , and similar q s . q is a pixel circle point, p is its circle center. I represents pixel gray, and t p the threshold. If the number of pixels with a grayscale value of p greater than or less than the grayscale value of n is greater than the set threshold value q d + q s > n, then p is a feature point. For computers to have the same understanding of objects at different scales, extracting features that remain unchanged at different scales as much as possible during the feature extraction process are necessary. The calculation of the scale space L (x, y, σ) of an image at different scales is shown in Formula (3).
In Formula (3), performing a convolution operation can gain L (x, y, σ) between G (x, y, σ) and I (x, y). The definition of the Gaussian kernel function is shown in Formula (4) [23].
In Formula (4), (x, y) is the coordinate of the pixel point, and σ is the standard deviation of the Gaussian kernel, reflecting the degree to which the image is smoothed. It is also referred to as the scale space factor. Downsampling the original image can obtain a series of images from large to small, which form a pyramid shape from bottom to top. By smoothing the images of each layer in the image pyramid with different σ values of Gaussian, the resulting images with different spatial scales are called Gaussian pyramids. After obtaining a Gaussian pyramid, it is necessary to construct a Gaussian difference pyramid using the Difference of Gaussian (DoG) function. When constructing a Gaussian difference pyramid, you only need to subtract the adjacent images in the image Gaussian pyramid. The specific calculation is shown in Formula (5).
In Formula (5), k represents the factor scaling the near group in the pyramid, D G (x, y, σ) is the Gaussian difference scale space, and the L (x, y, σ) function represents the scale space of an image. All local extreme points of the DoG function are considered feature candidates, but some extreme points are not stable, so it is necessary to remove extreme points with asymmetric local curvature. In addition, it is also necessary to calculate by fitting a three-dimensional quadratic function for their precise location. Taylor expansion is performed on the DoG scale space as shown in Formula (6).
In Formula (6), X
D
= (x, y, σ)
T
. Then the derivation is performed and the equation is made equal to zero to obtain the offset
The calculated offset plus the original position is the accurate position. The key to making feature points rotationally invariant is to calculate the principal direction, and then the coordinate system is rotated to the principal direction. The gradient direction and size of each pixel are calculated, as shown in Formula (8).
In Formula (8), mg (x, y) and θ (x, y) are the pixel (x, y)’s modes and directions. When obtaining the gradient direction and size of each pixel in the feature point field, its direction is reduced to 36 directions, and the main direction has the largest gradient among the 36 directions. After rotating the coordinate system to the main direction, the feature point description is performed, as shown in Fig. 2.
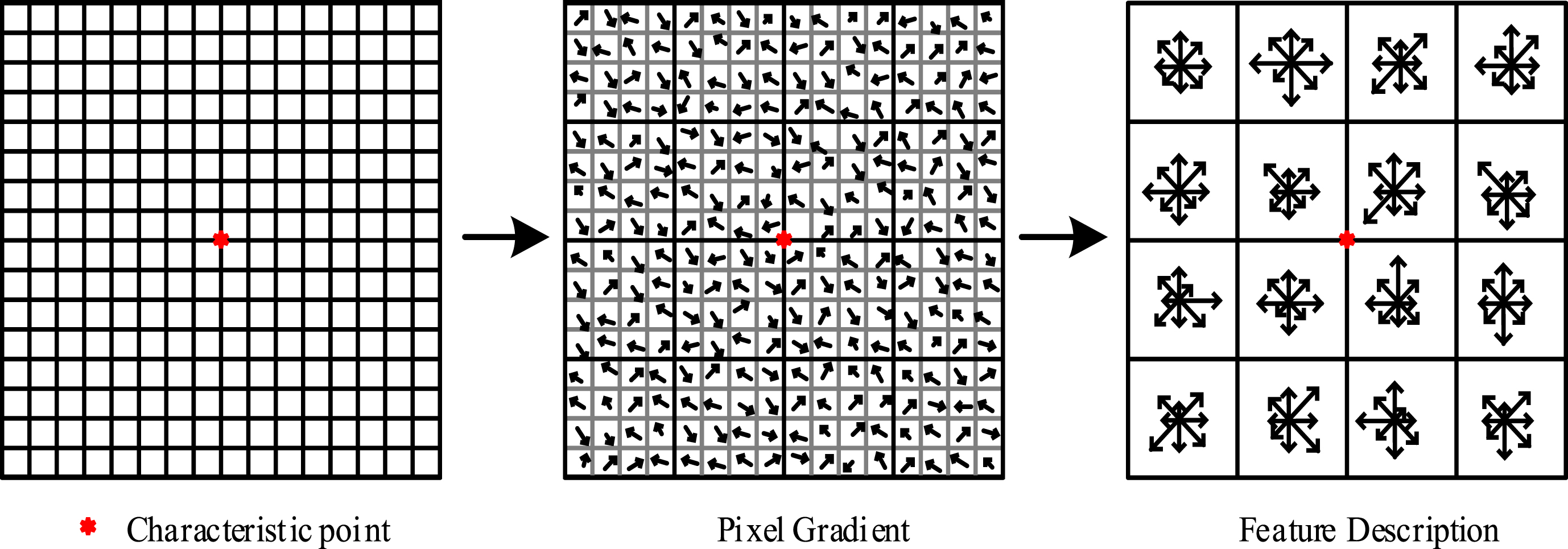
Schematic diagram of the process described by feature points.
In Fig. 2, a 16×16 window is used as the domain. The gradient direction and size of each pixel in the window are calculated. The window is then divided into sixteen 4×4 small blocks. The direction is reduced to 8 directions and the size of the gradient in different directions is counted in each small block. Eventually, each small square can obtain an 8-dimensional description vector composed of eight directional gradient sizes, while the entire window can obtain a 16×8 = 128 dimensional vector. Considering that the rotation invariance of feature points obtained by calculating the principal direction in the SIFT algorithm does not help bear fault detection, the direction information in the SIFT algorithm is omitted and the description vectors of each feature point are directly calculated to simplify the calculation and save computational time. Therefore, the research extracts features by the Fast-Unoriented SIFT that mainly includes FAST to detect features and Unoriented-SIFT to describe features.
The word bag model is a model proposed for text classification. Due to the similarity between image classification and text classification, some scholars have successfully applied it to image classification. The main idea of using it for image classification is to first extract feature points in an image through a feature extraction algorithm, then their description vectors work as visual words. Finally, the frequency is calculated in an image for visual word frequency vectors. Building an image word bag model includes three steps: feature extraction and description, feature clustering for the vocabulary, and codebook construction. Each description vector is a word used to represent a class of features. The research used FAST and SIFT to extract and describe features. After completing feature extraction and description, the K-Means algorithm is used to cluster similar words into one category, and all similar words are described by one word. Each clustering center is a basic vocabulary. The K-means algorithm is suitable for text data that is not pre-labeled. It can effectively reduce the complexity of the high-dimensional feature space generated by the bag-of-words model, making the data easier to analyze and visualize. The K-means algorithm does not require a priori data in the analysis of text clustering, and it can adapt to different sizes and types of text data. At the same time, the K-means algorithm can deal with high-dimensional data, carry out unsupervised learning, and efficiently deal with large-scale text data sets. Therefore, the K-means algorithm is applied to the bag-of-words model for text clustering. The schematic diagram of obtaining basic vocabulary through feature clustering is shown in Fig. 3.
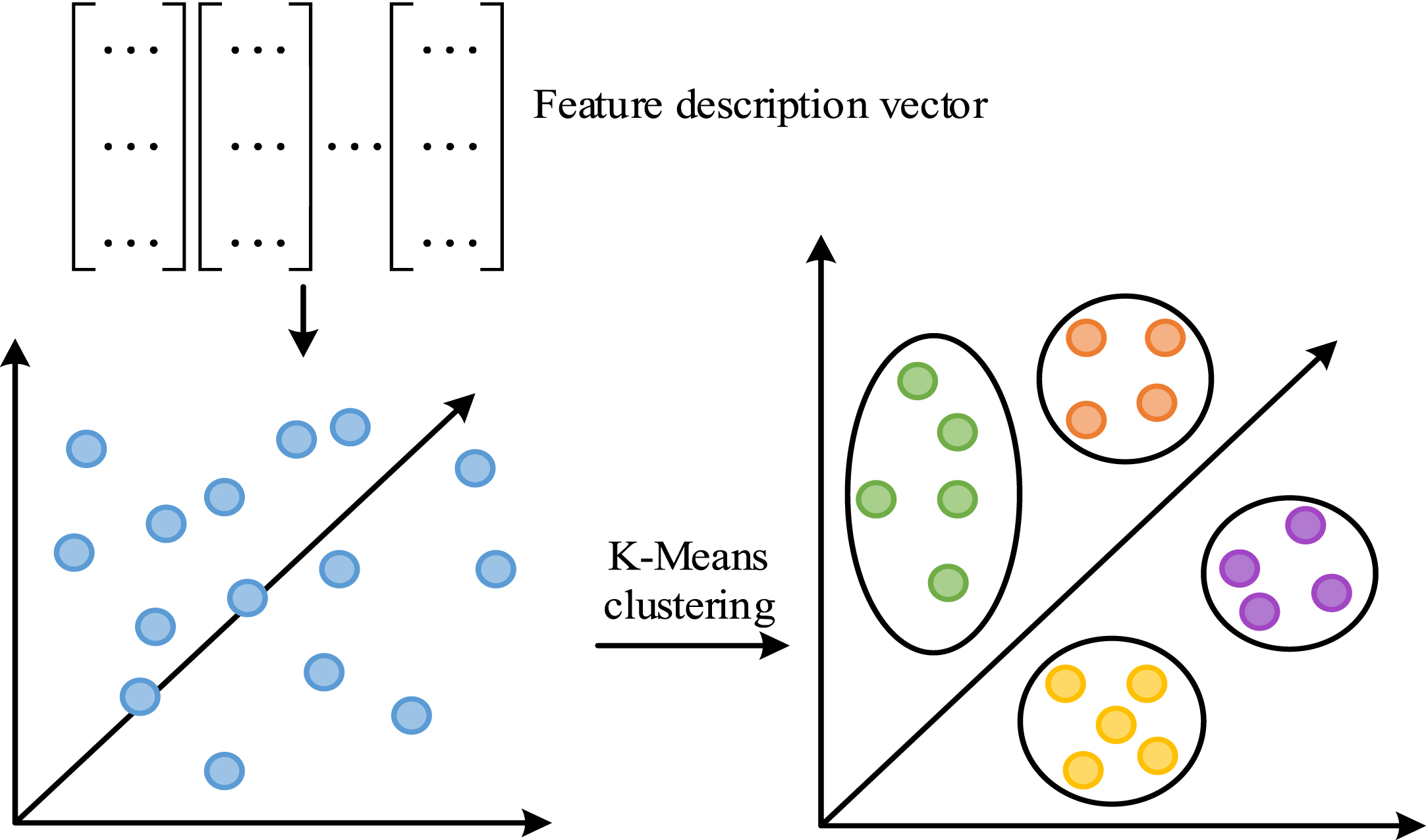
Sketch map of basic vocabulary obtained by feature clustering.
In Fig. 3, the extracted description vectors are aggregated into k classes through K-Means, and the basic vocabulary in the word list is misplaced. Samples in the same cluster are very similar, while samples in different clusters are on the contrary. Assuming that the sample set D
N
={ X1, X2, ⋯ , X
N
} contains N samples with no label, and X
i
= (Xi1, Xi2, X
in
) refers to a n dimensional vector, the K-Means algorithm ultimately creates the {C
h
|h = 1, 2, ⋯ , k } by minimizing the square error, where Ch′ ∩ Ch″≠h′ = φ and
In Formula (9), C
i
’s mean vector is
In Formula (10), the K-Means algorithm first determines the ownership of the sample point by calculating the distance d ji . X j is the sample point. And then labels the sample point with a cluster label λ j based on the distance. The center vector μ i is recalculated after classifying. The results of K-Means clustering can be obtained by iteratively updating λ j and μ i through the formula until convergence. After obtaining k basic terms, each feature point can be changed to the nearest term. Then, its frequency occurrence is counted for a k dimensional vector. When a word frequency vector describes a type of image, it is called a codebook vector. The frequency of the occurrence of each basic word is counted in each image, a word frequency vector is obtained, and then the word frequency vectors are aggregated to describe various types of images to form a codebook. The method of bearing fault detection includes two parts: one is to construct a dictionary model using training sets, and the other is to implement fault classification by substituting test sets. The process is shown in Fig. 4.
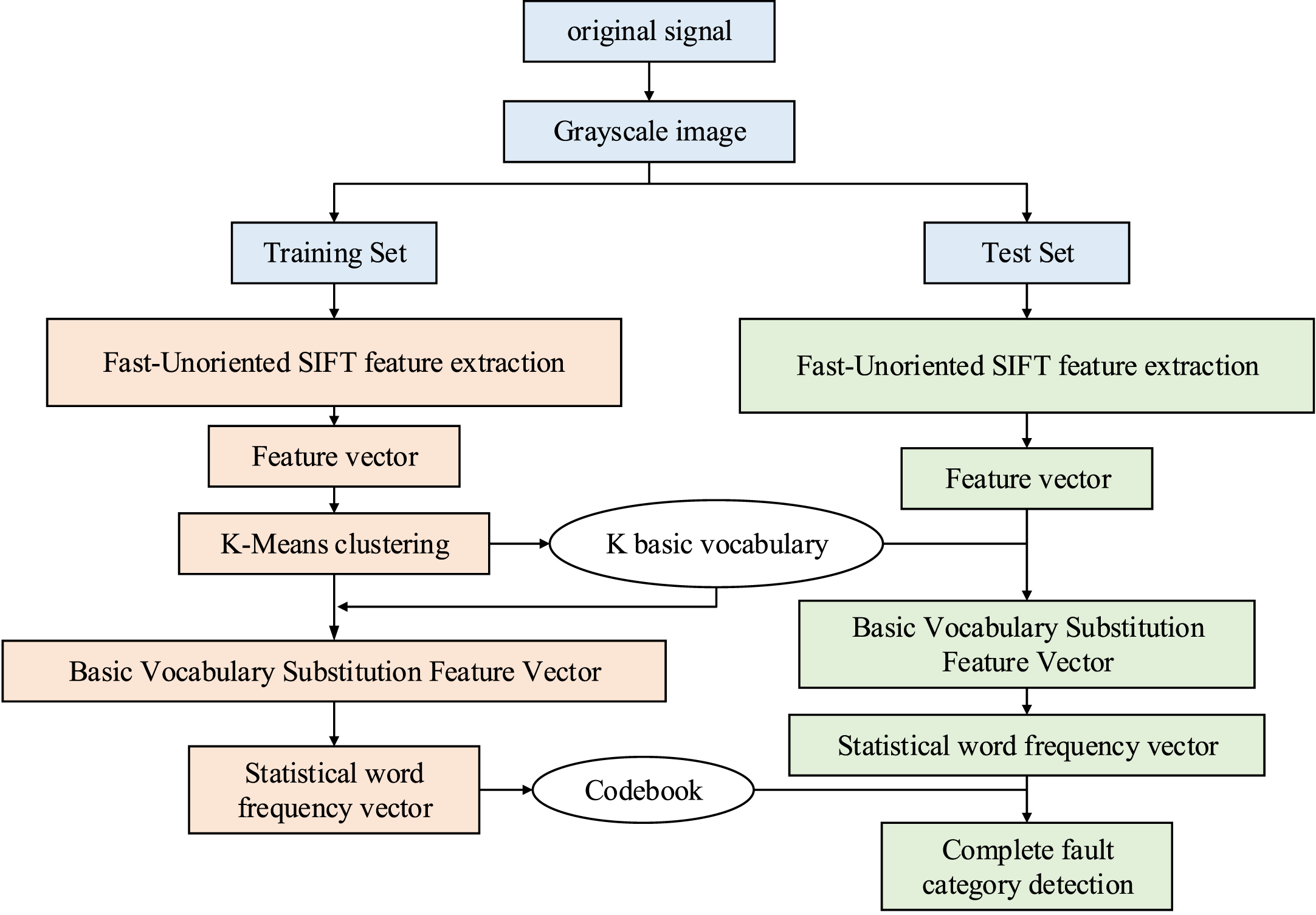
A bearing fault detection method flow chart with fast-unoriented SIFT and word bag model.
In Fig. 4, the process of building a word bag model using training sets mainly includes three steps: feature extraction, basic vocabulary requisition, and codebook requisition. Test sets are introduced into the word bag model to achieve classification by four steps: feature extraction, basic vocabulary substitution, word frequency vector requisition, and fault diagnosis. In traditional word bag models, setting the basic words is necessary, which leads to poor efficiency and portability [26]. In addition, codebook vectors increase with fault types increasing, which will lead to a decrease in the model recognition efficiency and classification accuracy. According to the centrifugal force formula, the centrifugal force exerted on a certain center of mass and the vibration amplitude of a rolling bearing has a direct ratio with the square of rotational speed. The amplitude of the acoustic signal also has a relation with the square of the rotational speed.
In Formula (11), n represents sampling points; a i represents i’s oscillation. LK features are shown in Formula (12) [27].
In Formula (12), pk
p
is the LK value at the feature point p, I
xy
is the gray value,
In Formula (13), F xy represents the frequency at which the grayscale values. When acquiring basic vocabulary, the K-Means algorithm divides all features into k clusters. The Squared Errors (SSE) dispersing samples within a cluster is defined, as shown in Equation (14) [28].
In formula (14), μ i is the cluster center of the cluster. SSE is the dispersing degree of samples within the overall cluster, so the larger the SSE, the worse the clustering effect.
In this study, SIFT was used in fault diagnosis and health monitoring of rolling bearings. The bag of words model was used to quantify and classify the extracted features in the application of this problem, to build a prediction model, which can monitor the health status of bearings based on the visual characteristics of bearings and identify and classify different types of fault modes. The bearing fault test bench used in this study was used for the experiment, and the acoustic and signal data used in the study were both from the test results of the test bench. The test bench is shown in Fig. 5.

Simulation experiment platform for fault diagnosis of rolling bearings.
The acoustic transducer used in the study adopted the MPA201 acoustic transducer, and the testing system used the DH5923 N dynamic information testing and analysis system, which can simultaneously meet the measurement of multiple parameters such as measurement, strain force, vibration, speed, temperature, etc. The compatibility of hardware and software is good, and it can connect sensors to complete the measurement of multiple data parameters. The schematic diagram of the two components is shown in Fig. 6.

Schematic diagram of two components.
By using acoustic sensors and signal analysis systems, the current research data can be collected. At the same time, 3208A-2RS commonly used rolling bearings were selected for the rolling bearing model used in the study. The parameters of the rolling bearings used in the study are shown in Table 1.
Table of bearing parameters used in the study
Table 1 shows that the bearing model used in the study is 3208A-2RS, with an inner diameter radius of 40 mm, an outer diameter radius of 80 mm, and a bearing width of 30.2 mm. To verify the method’s effectiveness for automated mechanical rolling bearings using Fast-Unoriented SIFT and word bag model, the study took acoustic signals of six fault types at 20 rad/s rotational speed as an example and substituted the acoustic signals into the fault detection model to test the model’s effectiveness in detecting and diagnosing the fault. Before conducting experiments, the collected acoustic signals were first divided into training sets and test sets. The 30 middle fault states were divided into 100 segments according to the length of seconds, and the signal length was divided into 20000, and the different signals were converted into 160*125 grayscale image information to get 30*100 grayscale images. Preliminary processing was conducted for acoustic signals of six fault types at a speed of 20 rad/s, obtaining 100 grayscale images. The first 70 images were used to establish a word bag model, and the remaining 30 images to test the model’s fault detection and diagnosis effectiveness. When extracting the feature, the number of features from each segment of the signal was closely related to parameter t p . Therefore, first of all, a t p parameter selection experiment for feature extraction was conducted. The average feature extraction amount of each segment of signal for various fault types when taking t p as [1, 100] is shown in Fig. 7.
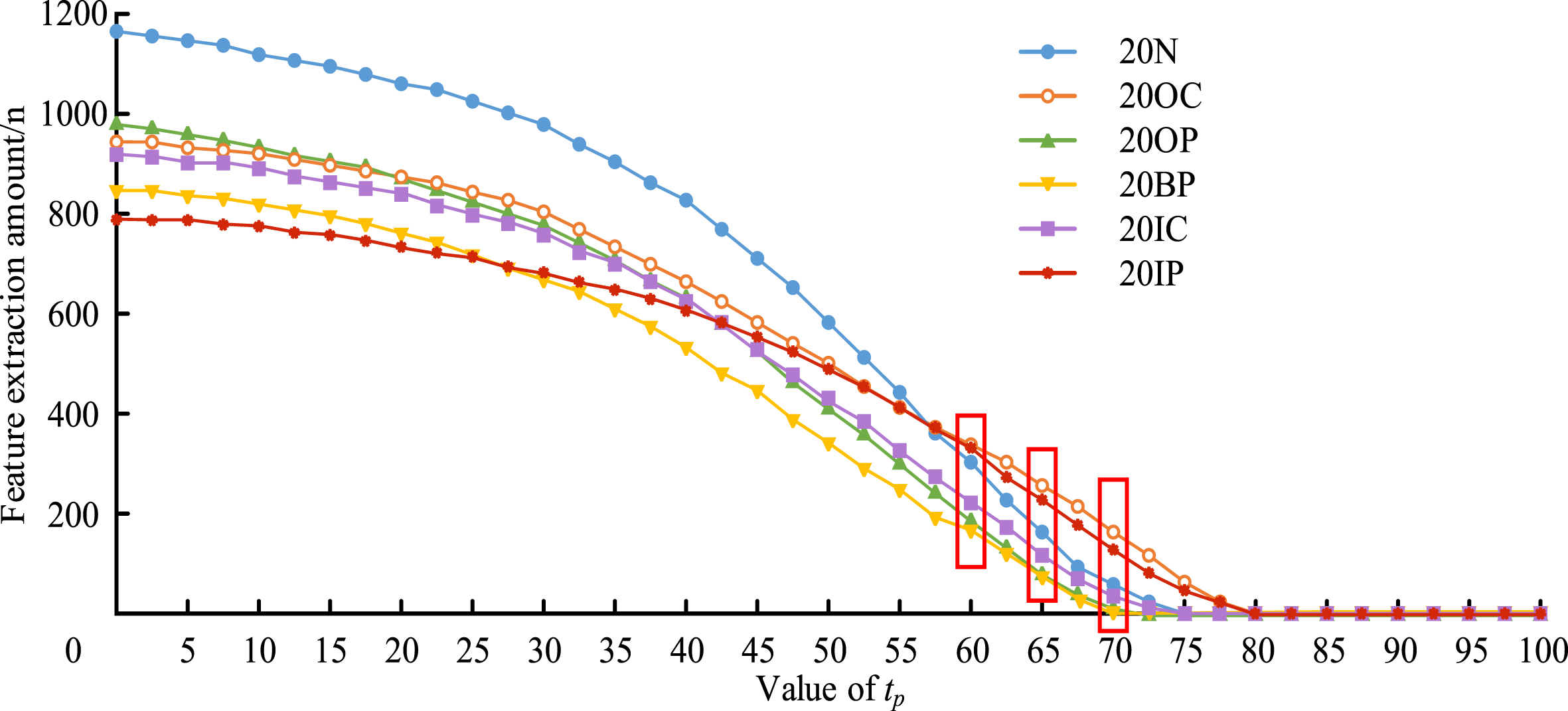
Number of features extracted by different t p values.
In Fig. 7, 20N∼20IP refers to 6 types of rolling bearing failures at 20 rad/s. 20 n indicates that the fault is wear, 20oC indicates that the fault type is fatigue detachment, 20op indicates that the fault type is corrosion, 20 bp indicates that the fault type is plastic deformation, 20ic indicates that the fault type is fracture, 20ip indicates that the fault type is gluing, and the number before the parameter indicates the bearing speed. In Fig. 7, the number of extracted features gradually decreases from over 800 to 0 as the value of t p increases. When t p = 70, the number of 20 N and 20IP was already very close to zero. When t p = 65 and t p = 60, the characteristic quantities of the six fault types were sufficient as a whole, the fault recognition rates in both cases were tested experimentally to determine the final value of t p . Before experimenting, it was also necessary to confirm the value of the basic vocabulary quantity k. When t p is taken as 65 and 60, the correlation between the recognition rate and the quantity of fundamental words k is shown in Fig. 8.

The correlation between the recognition rate and the quantity of fundamental words k.
In Fig. 8, when t p is taken as 60, the fault identification accuracy rate is always above 95%, significantly higher than when t p is taken as 65, and the stability is better. The recognition rate stabilized at 100% after taking 60 from k, t p = 60 and k = 60. To corroborate its precision and consistency, a 5-fold cross-validation experiment was conducted. The schematic diagram and experimental outcomes of the 5-fold cross-validation experiment are shown below.
In Fig. 9(a), the experiment still takes the acoustic signals of six fault types at a speed of 20 rad/s as an example. The 100 grayscale images of each fault type were evenly divided into 5 copies, and one of them was taken as a test set for 5-fold cross-validation, while the remaining 4 copies were as a training set. The average value was the final recognition rate obtained by the 5-fold cross-validation. The overall recognition rate of the five cross-experiments is 100%, indicating that the proposed method detecting the rolling bearing fault using Fast-Unoriented SIFT and word bag model had an excellent performance in fault recognition accuracy and stability. To verify the practicality and real-time performance of the detection method, the research calculated the time spent in each step of the detection process for a segment of signals with different fault types through experiments, as shown in Fig. 10.
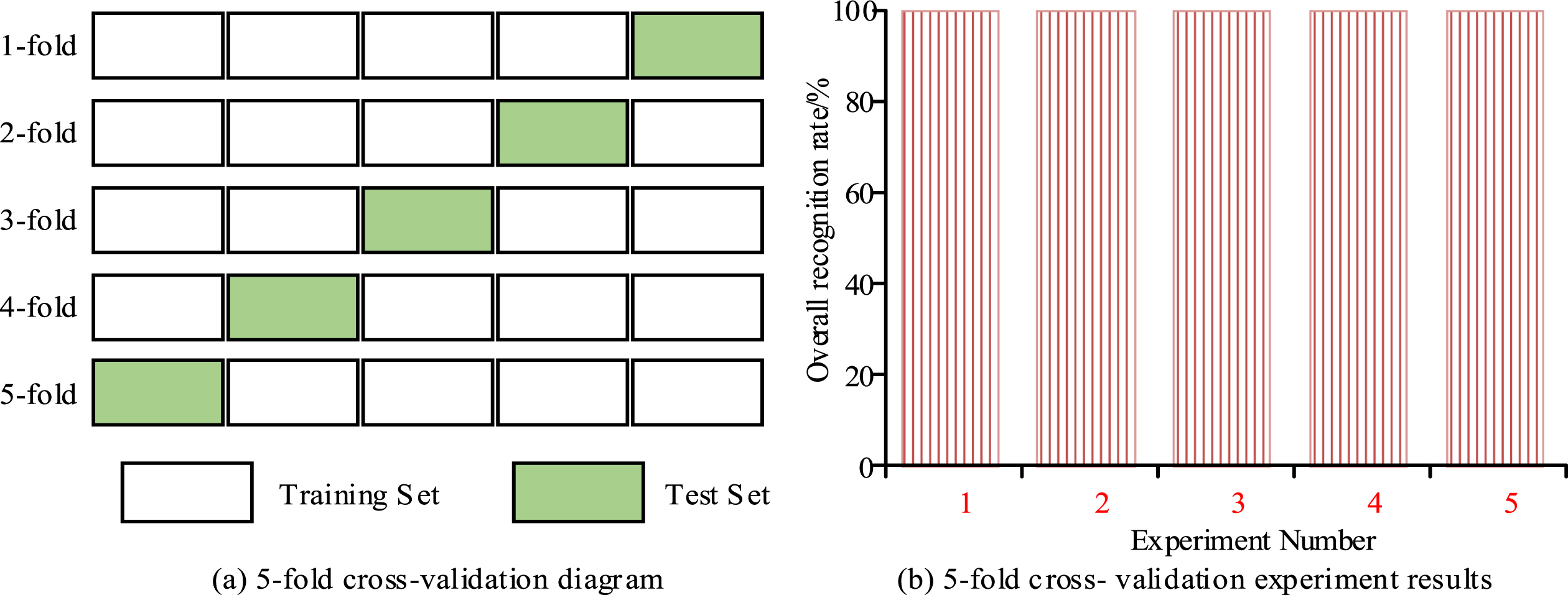
Schematic diagram and experimental results.
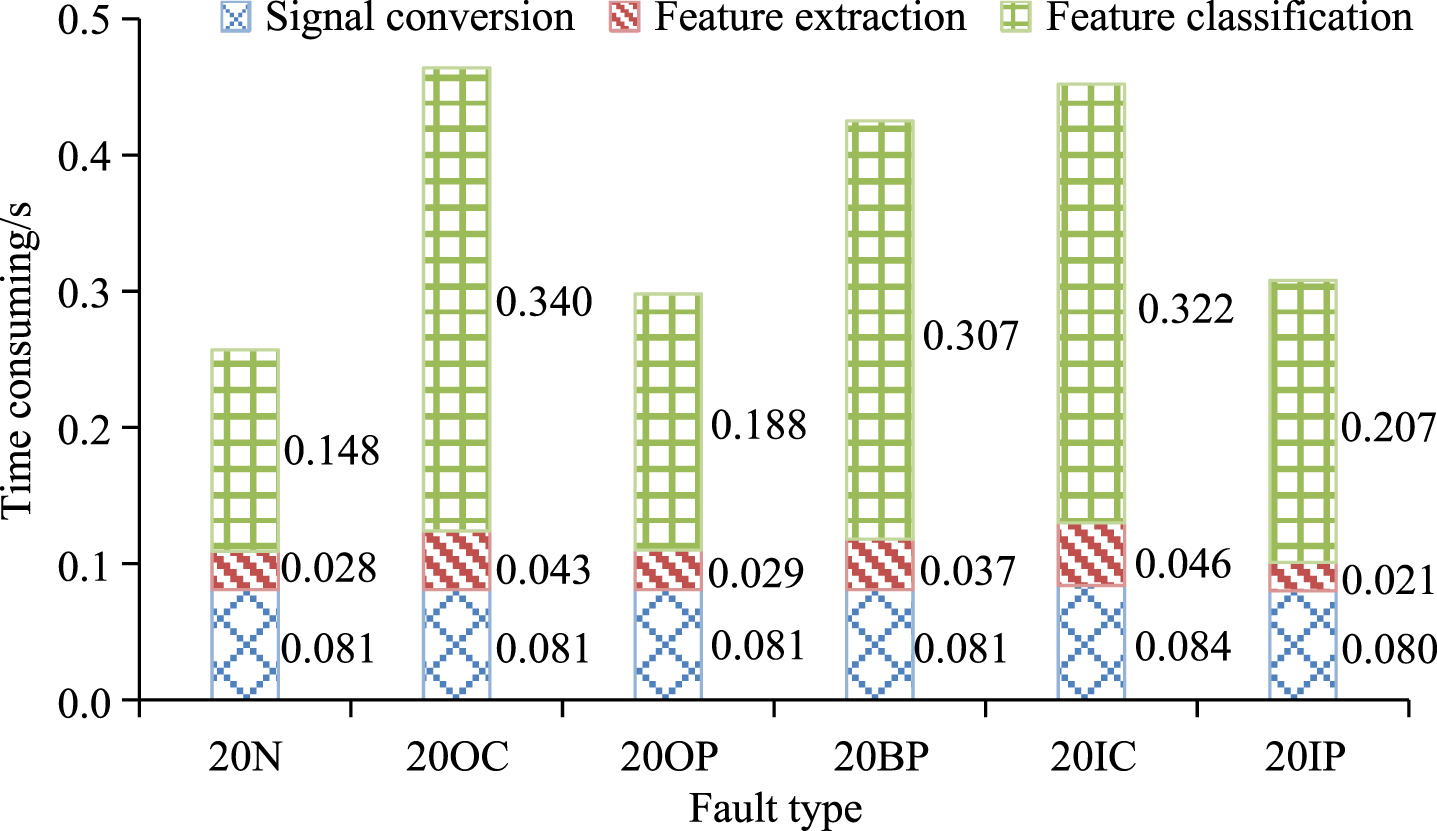
Time consumption of different detection steps for each fault type.
In Fig. 10, the overall detection time for different fault types does not exceed 0.5 s, and the length of each signal segment is the signal collected within 1 s. Therefore, real-time requirements can be fulfilled by the diagnostic model proposed in the study. In terms of the different steps in the entire detection process, the average time spent in the feature classification step was 0.252, accounting for 68.66% of the total time spent. Therefore, if the number of fault types increased, the computational efficiency would decrease accordingly. Table 2 shows the comparison results.
Comparison between fast-unoriented SIFT algorithm and SIFT algorithm
In Table 2, the Fast-Unoriented SIFT algorithm can extract 269 features per segment of signal on average, while the SIFT algorithm extracts features for fault 20IP, and the amount of features extracted in other cases is 0. The SIFT algorithm took 14.322 ms in the feature detection process, which was approximately 28 times the time consumed by the Fast Unknown SIFT algorithm. Due to the very few feature points extracted by the SIFT algorithm, the time consumption of the SIFT algorithm in the feature description stage was much lower than that of the Fast-Unoriented SIFT algorithm. The comprehensive experimental results demonstrated that the Fast-Unoriented SIFT algorithm had significant advantages in both feature extraction amount and operational efficiency and speedily extracted an extensive range of features. The research selected the more commonly used K-Nearest Neighbor algorithm, Extreme Learning Machine (ELM), and SVM classifiers for a 5-fold cross-validation comparative experiment for the performance verification of the word bag model.
In Fig. 11(a), the average fault recognition rates of KNN, SVM, and ELM are 97.17%, 98.34%, and 95.43%, respectively. However, the fault detection model proposed in Fig. 11(b) has an average recognition rate of 100% for all 5 times resulting in better overall recognition rates and detection stability. Therefore, under the experimental conditions of the study, good detection results can be achieved by constructing codebooks, which had better diagnostic accuracy and stability for machine-bearing faults and did not require the use of other classifiers. The experimental outcomes showed that the method detecting rolling bearing fault using Fast-Unoriented SIFT and word bag model exhibited high efficiency, high accuracy, and strong stability. It can fulfill the requirements of real-time detection and has practical application value. The experimental results of parameter selection for the adaptive extended word bag model are shown in Fig. 12.

Experimental results of 5-fold cross-validation of KNN, SVM, and ELM classifiers.

Experimental results of parameter selection for adaptive extended word bag model.
In Fig. 12(a), the SSE decline speed starts to slow down when the basic vocabulary number k is 131, indicating that the clustering effect starts to stabilize, so k = 131. Figure 12(b) shows the average feature amount that can be extracted from each segment of the signal at each rotational speed. 254 feature points can be extracted from an average segment of the signal. For illustration, LK is considered. The calculated LK interval for all training samples is [4.4565, 8.9499], and the calculation accuracy is either too high or too low. When the calculation accuracy was up to one decimal point, it was most appropriate to obtain a total of 46 LK basic terms from 4.4 to 8.9. Similarly, L2DIE was also set to one decimal place. In the adaptive word bag model, fault categories with a probability greater than 98% were selected for each layer as the classification result. Taking 5 rad/s rotational speed and 20 rad/s rotational speed as examples, the comparison between the detection results of the adaptive extended model for multi-mode faults is shown in Fig. 13.

Adaptive extended word bag model and traditional word bag model for multi-condition fault detection results.
In Fig. 13, the fault detection effect of the adaptive extended word bag model outperforms the traditional word bag model significantly, with a recognition accuracy rate of over 97%, while the recognition accuracy rate of the traditional word bag model is only about 80%. The experimental results showed that the adaptive extended word bag model had significant advantages over the traditional word bag model in terms of fault diagnosis accuracy. To compare the stability of the current research algorithm training set and test set, a loss function comparison was performed between the test dataset and the training dataset, as shown in Fig. 14.
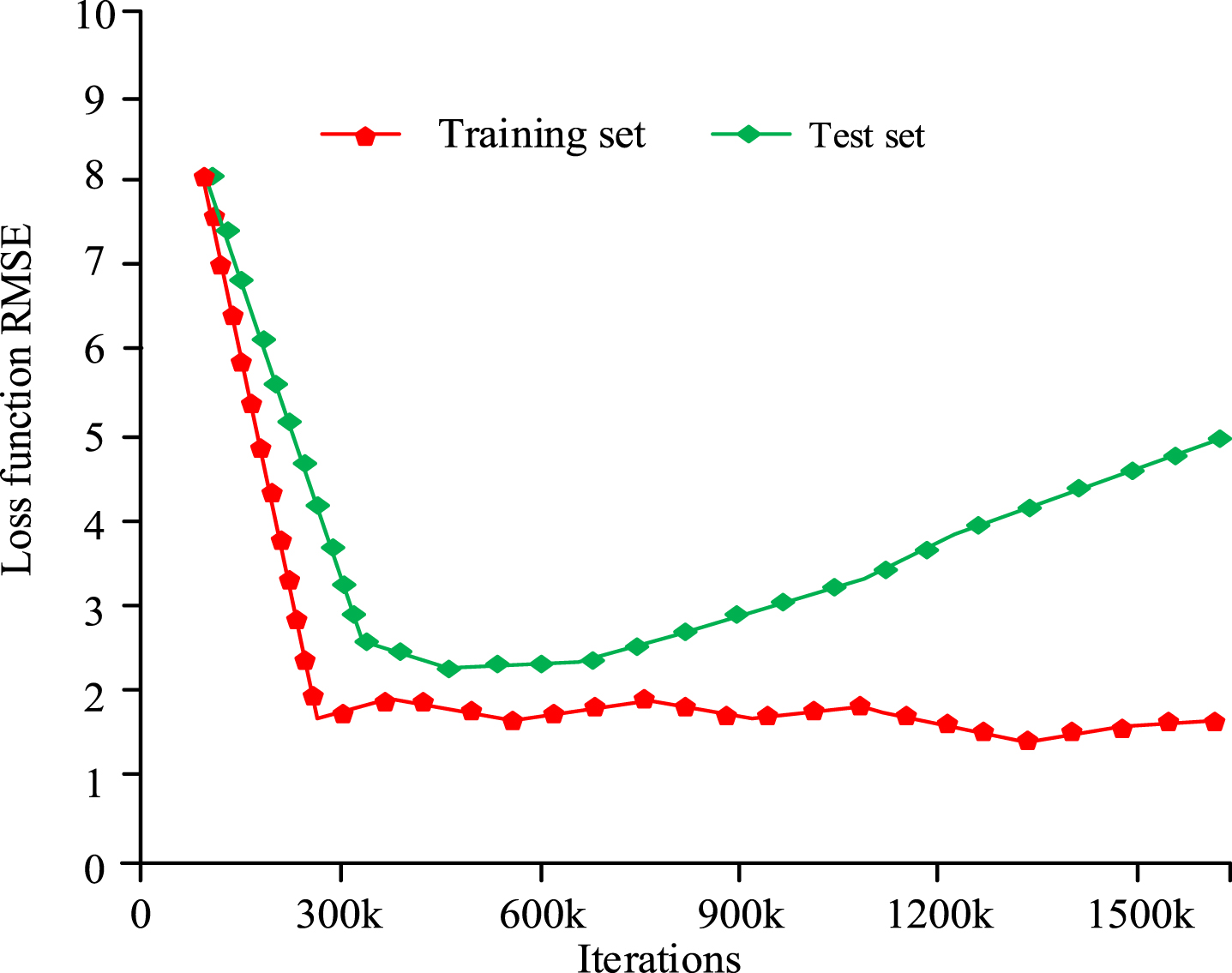
Loss function variation curves of the test set and training set with increasing number of iterations.
In Fig. 14, in the initial stage of increasing the number of iterations, the loss function of the training set rapidly decreased during the change of the loss function, possibly because the model can better adapt to the training data at this time. As the training progressed, the loss function of the training set no longer decreased and gradually stabilized, with the value of the loss function stabilizing at around 1.7. In the initial stage of increasing the number of iterations, the loss function of the test set decreased as the training progressed, due to the continuous improvement of the model during the training process. Afterwards, the loss function of the test set began to rise, due to the model overfitting the training data. The minimum loss function value of the test set reached 2.2 and then began to show an upward trend. To verify the feature extraction capability of the current algorithm, traditional feature extraction algorithms Fourier Transform (STFT), Wigner Ville Distribution (WVD), and Wavelet Transform (WT) were compared for feature extraction time, and the results are shown in Table 3.
Comparison of feature extraction time between traditional feature extraction methods and research methods
In Table 3, when the threshold or tp value between two pixels was the same, the four methods exhibited different feature extraction times under the same amount of feature extraction. Among them, the feature extraction time of the Fast Renoriented SIFT algorithm was shorter than that of other algorithms, indicating that the feature extraction speed of the Fast Renoriented SIFT algorithm was faster and more efficient. To verify the accuracy of the current algorithm model in data feature extraction and fault type diagnosis, the accuracy and other performance of the Graph Neural Network Based Bearing Fault Detection (GNNBFD), AutoEncoder Generation (AE), and Generative Adversarial Network (GAN) algorithms were compared with the algorithms used in the study, as shown in Table 4.
Performance comparison of different algorithms in bearing fault diagnosis
In Table 4, among the changes in fault recognition accuracy of different algorithms, the Fast Unknown SIFT algorithm had the highest fault recognition accuracy, which was higher than the other three algorithms. Compared to the data extraction time, the Fast Unriented SIFT algorithm model had the shortest data extraction time. Finally, in comparing the errors of the four algorithm models, it was found that using the algorithm model resulted in the smallest error value. In summary, among the four algorithm models compared, the study found that the algorithm model performed better in recognition accuracy, error, and data extraction time.
Automatic mechanical rolling bearings are the largest source of mechanical failures in the industrial field. Compared to acceleration sensors, acoustic sensors can achieve non-contact measurement, and have advantages such as wide application range and easy signal acquisition. Therefore, combined with image feature extraction algorithms, a Fast Uniriented SIFT feature extraction algorithm that directly and quickly extracts a considerable number of features without noise reduction is proposed. Fault type detection is implemented using the distribution information of redundant features through the word bag model and its improved model. After determining the model parameters through parameter selection experiments, in the 5-fold cross-validation experiment, the proposed fault detection model exhibited an overall recognition rate of 100%. The overall detection time for different fault types did not exceed 0.5 s. Its detection accuracy and efficiency can fulfill real-time demands. The recognition accuracy of the adaptive extended word bag model proposed in the study was above 97%, which significantly improved the detection accuracy compared to 80% of the traditional one. It had significant advantages in multi-working condition rolling bearing fault detection. However, the research simulates the situation where acoustic sensors are arranged at fixed points in signal acquisition, and it is crucial to investigate the acoustic signals process collected during mobile inspection of the working state of the inspection robot in subsequent research. At the same time, the study only considered the case of constant speed, so in the follow-up study, the impact of different bearing state changes on the study will be considered. Since this study only considers the diagnosis of one working condition, which cannot meet the diagnosis requirements of multiple working conditions, the subsequent research will consider the fault diagnosis of multiple variable working conditions.
Statements and declarations
Competing interests
The authors have no relevant financial or non-financial interests to disclose.
Fundings
The research is supported by: Supported by General Program of Basic Science Foundation of Jiangsu Province Grant (No. 21KJD510008).