
Abstract
This study proposes a weighted composite approach for grey relational analysis (GRA) that utilizes a numerical weather prediction (NWP) and support vector machine (SVM). The approach is optimized using an improved grey wolf optimization (IGWO) algorithm. Initially, the dimension of NWP data is decreased by t-distributed stochastic neighbor embedding (t-SNE), then the weight of sample coefficients is calculated by entropy-weight method (EWM), and the weighted grey relational of data points is calculated for different weather numerical time series data. At the same time, a new weighted composite grey relational degree is formed by combining the weighted cosine similarity of NWP values of the historical day and to be measured day. The SVM’s regression power prediction model is constructed by the time series data. To improve the accuracy of the system’s predictions, the grey relational time series data is chosen as the input variable for the SVM, and the influence parameters of the ideal SVM are discovered using the IGWO technique. According to the simulated prediction and analysis based on NWP, it can be observed that the proposed method in this study significantly improves the prediction accuracy of the data. Specifically, evaluation metrics such as root mean squared error (RMSE), regression correlation coefficient (r2), mean absolute error (MAE) and mean absolute percent error (MAPE) all show corresponding enhancements, while the computational burden remains relatively low.
Keywords
Introduction
The intrinsic stochastic nature and intermittency of solar and wind energy sources present formidable challenges and technical limitations in achieving accurate power generation forecasts. The absence of a robust theoretical underpinning for solar/wind power forecasting indirectly contributes to phenomena such as curtailment of surplus energy. Accurate forecasting of solar/wind power not only augments the operational efficiency of solar/wind farms but also plays a pivotal role in supporting the power dispatch department in guaranteeing the secure, stable, and economically viable operation of the grid subsequent to the substantial integration of solar/wind energy resources. The production of power is resilient may thus be improved in the power system by upgrading the wind power forecast technology [1]. The numerical weather prediction (NWP) is connected to the power output when taking into account the time series-related data it contains. For this reason, different classifications of wind power climate data have a direct impact on improving prediction accuracy [2].
In recent years, the depth and breadth of machine learning techniques have been extensively explored and have seen significant advancements. These techniques are increasingly being applied across a wide range of industries, including but not limited to healthcare, finance, automotive, and especially in renewable energy sectors. It has become instrumental in forecasting power generation from renewable sources, such as solar and wind, where traditional methods fall short due to the inherent unpredictability of these resources. Machine learning algorithms are capable of processing vast amounts of data from various sources, including weather patterns and historical energy production data, to make more accurate predictions [3–5]. In reference [6] uses the classification and classification of strong convective weather to prove the correlation between wind speed fluctuation and meteorological nature. In reference [7], NWP and meteorological observation data of meteorological stations are used for wind power prediction. Then use three machine learning algorithms-support vector regression, artificial neural network (ANN), and Gaussian processes-to combines and forecast the data. Then, the results of the three algorithms are mixed with the mean of the Bayesian model to generate a set prediction. In reference [8], clustering analysis is used to effectively extract the wind characteristics of the same type of time period, conduct modeling analysis, and improve forecast accuracy through a systematic approach. In reference [9], to improve the predicted accuracy of the combined model that was produced as a consequence, the redundancy is eliminated by the use of grey relational analysis (GRA), and the relationship between the anticipated and actual power series of each individual model is examined. The above-mentioned wind power prediction methods based on NWP all adopt a feature extraction approach that “degrades” to adapt to clustering methods, failing to capture the dynamic changes in weather over continuous time periods. There may be scenarios where the dynamics of change are different but the feature quantities are similar, which weakens the effectiveness of weather categorization for wind power, thereby impacting the parameter selection of the wind power prediction model.
Wind power prediction methods mainly cover the time series method [10], ANN [11], support vector machines (SVM) [12], etc. The time series approach is one of them and is straightforward and simple to use, although it is less accurate than other methods. ANN technology offers the capacity for adaptive learning, and the research time is longer in the application field, but the training samples are higher. Thus, the outcome is not the world’s best answer. While SVM are popular due to their practical utility, they face challenges in the realm of parameter optimization. Consequently, there is a necessity for further refinement of its parameters to enhance the operational performance of SVM, ensuring a more effective and efficient application in various fields.
Among the parameter optimization methods based on SVM, the widely used algorithms include Particle Swarm Optimization (PSO) [13], Grid Search (GS) [14], Artificial Bees Colony (ABC) [15], etc. A quick convergence rate is achieved through PSO, but the solution is locally optimal. Among them, the particle swarm algorithm and the artificial group peak algorithm converge faster, but they are also locally optimal. The nature of GS work is system-indiscriminately search, cross-validation using parameters, comprehensive and intuitive, and global optimal solution can be obtained. However, a more comprehensive search interval results in longer search times and a large number of invalid operations. In 2014, the grey wolf optimization (GWO) algorithm [16, 17], a revolutionary swarm intelligence optimization technique is proposed, which is simple to realize and has fewer adjusting parameters. It is proved to be better than the PSO algorithm [18]. Based on parameter tuning and convergence speed and has a self-adaptive adjustment of convergence factor and pyramid hierarchy, which may balance the benefits of global retrieval and local optimization. As a result, it performs better in terms of accuracy and convergence rate.
To address the issue of parameter optimization in SVM, and considering the connection between NWP and the wind power prediction model, a wind power prediction method based on weighted composite index grey relational analysis and SVM has been proposed. At first, we use the non-linear dimension reduction method of t-distributed stochastic neighbour embedding (t-SNE) to lower the dimensionality of the Meteorological Indices in NWP and filter out the noise. Second, we use the entropy weight method (EWM) to calculate the relative importance of the various meteorological variables and wind power for our reduced-dimensional sample set. To get a better selection of relational degree, a new composite index is merged using the weighted cosine similarity [19] and the grey weighted relational degree. The improved GWO is used to optimise the parameters in order to establish the ideal settings, which in turn improves forecast precision and operational efficiency. Unlike conventional time series, ANN, or traditional SVM methods that either lack accuracy or face parameter optimization challenges, the proposed method effectively harnesses the complex interplay of meteorological data and wind power output. Through sophisticated machine learning algorithms and innovative optimization techniques, this study establishes a new benchmark for accuracy and efficiency in wind power forecasting, making a contribution to the sustainable and efficient utilization of renewable energy resources.
Weighted composite indicator gray relational analysis
Dimensionality reduction using t-SNE
NWP provides a large number of meteorological indicators, usually based on experience to screen out the relevant indicators, but there are always indicators affecting wind power output in the data types, so the indicators screened by experience can not be directly related to wind power output. Related and redundant meteorological indicators will increase the calculation amount of the prediction system and also reduce the prediction accuracy. The approach of extracting primary components may be used to guarantee that the NWP data model is more accurate. A multivariate data analysis technique called principle component analysis (PCA) [20] may convert a collection of linked variables into new, uncorrelated ones called principal components, which include the majority of the original data set’s total variability. In reference [21], principal component analysis is carried out, and a binary model is extracted from five original variables to simulate the power consumption of office buildings. It has been extensively reported how crucial it is to reduce the dimensionality of the input data and choose the right model variables. In this paper, the t-SNE [22, 23] dimension reduction method is used.
Distributed Stochastic Neighbor Embedding (SNE) is the foundation of the enhanced method known as t-SNE. The main function of this is to measure the similarity between data points in both low-dimensional and high-dimensional spaces, which is appropriate for reducing high-dimensional data to low-dimensional data for presentation. The Gauss joint distribution P is used to measure similarity in high-dimensional space instead of the Euclidean distance between data points, the distance distribution in low-dimensional space is expressed by the joint distribution Q which obeys the t distribution with degree of freedom 1, the cost function is written by Kullback-Leibler divergence and the optimization result is obtained by gradient descent method so that the distance distribution in high-dimensional space and low-dimensional space is as close as possible. If the n-dimensional data set is
Where σ
i
is the Gaussian distribution’s standard deviation with the data point in its center. To express the best I through binary search, T-SNE makes use of the perplexity σ
i
. The confusion is:
Where H(P
i
) is the entropy of P
i
. After dimension reduction, the distribution P and Q should be close to each other as much as possible. If the local features remain intact after dimension reduction, then p
ij
= q
ij
. The objective function of Kullback Leibler divergence is:
To minimize the objective function, the gradient descent approach is used. The iteration update and solution formula are as follows:
Where φ(t) is The t iteration’s solution, and η is the pace of dimension learning. d(t) is the t iteration’s momentum.
Grey system theory has been extensively used as an interdisciplinary technique. An essential component of grey system theory is GRA [24, 25], which quantifies how closely related distinct factors are based on whether they have the same or divergent development trends. GRA has several uses, including in the fields of information technology [26], finance [27], and industry [28]. The weather sample set composed of the dimensionally reduced multivariate index data has
The characteristic vectors of the test samples are:
The grey relational degree between two series samples can be obtained [29]:
Where, ξ
i
(j) is the characteristic correlation coefficient of x0 (j) and x
i
(j);
Where,
The weight is applied to the selection function in order to balance the percentage of the influence function to choose the correct relation degree. The weight is generally limited by the lack of expert knowledge and experience. The entropy weight method [30, 31] can reflect the uncertain information in the determination of weight, which is objective. The weight of the NWP parameters in this study is determined using the entropy weight approach. Assume that n weather sample data include m meteorological parameters, and b
ij
represents the meteorological value of j-th during the i-th historical day, then the proportion that the j-th index represents for the i-th historical day is:
Entropy of index j-th:
If a
ij
is 0, In a
ij
is meaning less. In this case, correct it to:
Hence, the j-th meteorological parameter’s weight is:
Where
Grey relation degree is an effective way to evaluate the approximate degree of the correlation coefficient. The weighted gray correlation degree between x0(j) and x
i
(j) may be represented as follows using the weight index discovered using the entropy weight method:
The NWP numerical similarity filtering of text uses the positions of data points as an indicator to judge similarity. Specifically, it checks if they appear at the same time point in different dates and are similar in the same dimension at that time. The importance of differences in values within the same dimension is reduced for NWP data points. Therefore, the cosine value of the vector included angle in this paper’s NWP processing and the correlation degree between weather vectors can be screened out better. Cosine similarity [32] is usually used to measure the similarity of data clustering analysis. In this study, a new index classification function is created by fusing the grey correlation degree and weighted cosine similarity degree. The weighted cosine similarity calculates the similarity between the weather parameters of a specific sample (designated as “i-th") and a characteristic vector representing the parameters to be measured:
A correlation coefficient of the normalised feature vector is chosen before the data is processed. The correlation features of the entire NWP physical characteristics are higher than those of the data for any individual physical characteristic. The similarity will lean more in the direction of the individual physical parameters when standardisation is applied, rather than being influenced by the overall physical parameters. Even if the meteorological data from the NWP is lacking or influenced by other reasons, Similarity in selection is guaranteed by using local criteria. In sample X
i
, after standardization, we can get:
There are the following changes in cosine similarity:
Therefore, formula (18) can be simplified to:
The simplified formula can effectively improve the calculation efficiency. According to the weighted grey relation degree and weighted cosine similarity of NWP,
Where
SVM
SVM’s non-linear insinuation-based data ingestion method for regression [33] entails doing linear regression after entering data into a feature space with a large number of dimensions. Suppose the given sample data is {x
i
,y
i
}, (x
i
∈R
n
,y
i
∈R
n
), where x
i
is the input value and y
i
is the output value. In the SVM regression problem, the function selected in this paper is:
Where,w-weighted vector, φ (x)-nonlinear function, b-threshold. Get the extreme value for the objective Optimization:
Where, C-penalty factor; ξ
i
, ζ
i
-relaxation factor; ɛ-loss function. The loss function may be written as follows:
Add Lagrange multiplier {α
i
,β
i
} to obtain the regression function:
Where K(x
i
,x
j
) is the kernel function. RBF kernel function was chosen as the kernel function for this work:
In GWO [34], three optimal wolves are defined as l
α, l
β and lδ according to social level, and the rest are defined as l
ω. The optimal wolf (optimal solution) guides the other wolves (candidate solution). The main process is: surround the prey - Hunt - attack the prey - search for the prey. Hunting is defined as:
Among them,
Where
Where
The optimal optimisation strategy will think about both the local and global levels of search. The algorithm’s convergence is correlated with its ability to search locally, while its variety is ensured by its global search capabilities. Improving the algorithm’s precision requires striking a compromise between the algorithm’s local search capabilities and its global search capabilities. In GWO, the convergence factor
Where e represents the natural logarithm base, p is a probability value in the range [0,1], v denotes degrees of freedom, Γ (•) is the gamma function, t stands for the current iteration number, and T represents the maximum number of iterations. For example, if the number of iterations is 100, the nonlinear decreasing diagram of
According to the comparison curve in Fig. 1, a higher convergence factor
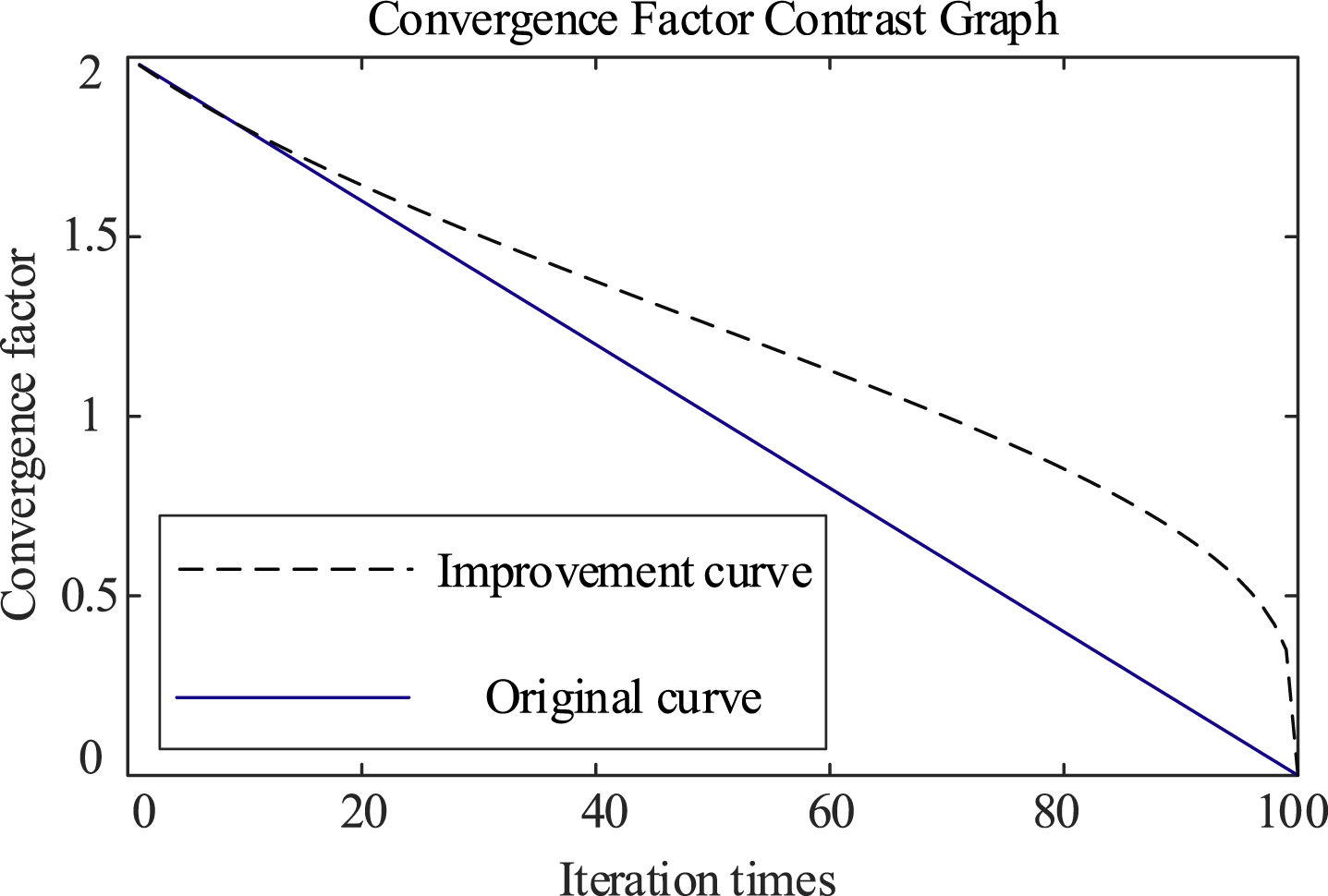
Convergence Factor Contrast Graph.
In the gray wolf algorithm, wolf l
α is not optimal, which leads to wolf l
ω approaching the local optimal in the iterative process. Weight modification is implemented to balance the capabilities of local search with global search. According to equation (34)–(36), obtain the proportional weight of the position:
Among them ∂1, ∂2, and ∂3 correspond to the learning speed of three wolves l
α, l
β and lδ, respectively. Because the calculation of proportion weight includes the dynamic position change of three wolves, it has the role of position guidance. In this way, to successfully balance the capabilities of local and global search across algorithms and speed up convergence, ongoing dynamic adjustment is necessary. Finally, the iteration mode of adding weight proportion is as follows:
The following measures may be taken to improve the GWO_SVM regression model in light of the study above: Set the parameter limit and initialize the wolves, and the individual position is composed of r and C. SVM trains samples according to r and C in individual positions, and tests individual fitness functions in SVM. The updated GWO algorithm is utilized to update each wolf’s specific location. At the end of the hunting process, the best r and C are obtained and the best individual position is returned. The r and C obtained by the improved GWO are utilized to create the model and do the analysis of the predictions.
Figure 2 depicts the flow chart for enhanced GWO_SVM wind power forecast based on the weighted composite index’s gray relation.

Similar Days of Compound Indicators and Flow Chart of Improving GWO_SVM Wind Power Prediction.
The performance of the GWO_SVM method is intricately tied to the quality and accessibility of input data. Should the dataset incorporate noise or display missing values, this may lead to a diminishment in prediction accuracy. Consequently, this article undertakes a preprocessing step on NWP data to ameliorate the performance of GWO_SVM. However, intrinsic limitations persist due to the inherent characteristics of the SVM model itself.
Firstly, when confronted with extensive datasets, the GWO_SVM method may encounter constraints pertaining to computational resources, given the relatively time-intensive nature of SVM model training and optimization. Consequently, further optimization of computational time is warranted when conducting long-term wind power predictions.
Secondly, the GWO_SVM method may exhibit suboptimal performance in addressing highly nonlinear wind power prediction scenarios, as SVM inherently possesses restricted modeling capabilities for nonlinear data. Despite the integration of IGWO to enhance SVM, performance may still wane with larger datasets.
Furthermore, the generalization proficiency of the GWO_SVM method may be influenced by idiosyncratic datasets. Thus, judicious evaluation of its performance is imperative when extending the model’s application to diverse regions or distinct temporal intervals.
Lastly, if the distribution of newly acquired data markedly deviates from the training dataset, recalibration or retraining of the GWO_SVM model may be necessitated to uphold predictive accuracy.
In summation, notwithstanding the advantages exhibited by the GWO_SVM method in short-term wind power prediction, pragmatic application demands a nuanced consideration and resolution of the associated limitations.
Case analysis
This article uses 2018 wind farm data with NWP data to verify its conclusions. There is a 15-minute pause between samples. The 24 dynamic and thermodynamic indices produced by NWP are shown in Table 1. These indices include air pressure, wind direction, wind speed, cloud quantity, and precipitation. Evaluation indexes of prediction results: root mean squared error (RMSE), regression correlation coefficient (r2), mean absolute error (MAE) and mean absolute percent error (MAPE) in regression problems [35].
Meteorological Index
Meteorological Index
Among these metrics, RMSE is calculated as the square root of the average of squared deviations between predicted and actual values, normalized by the sample size. It serves as a gauge for the disparity between predicted and observed values, exhibiting a high sensitivity to outliers within a set of forecasted values. Consequently, RMSE serves as a robust indicator of model precision. R-squared (r2), which delineates the proportion of variability in the dependent variable that the model accounts for, manifests superior regression performance with increasing values. It is derived by dividing the absolute error of each observation by its corresponding actual value, followed by computing the average. Meanwhile, MAE quantifies the average of absolute discrepancies, offering a reliable portrayal of the true magnitude of prediction errors. MAPE delineates the distinctions between predicted and actual values, with higher values signifying diminished predictive efficacy.
Where S is the real electricity generated by the wind; Y is the anticipated performance of wind power;
Over two days, 192 sets of data, totaling 4608 data points, were carefully selected for a thorough analysis involving dimensionality reduction and visualization. The t-SNE method was employed to effectively reduce noise in the NWP sample set and provide an intuitive representation of weather sample characteristics in lower-dimensional spaces. This led to a reduction from the original 24-dimensional space to both two and three-dimensional subspaces, as illustrated in Fig. 3. Here, distinct colors signify different contributing factors, while individual points represent specific data points. Our analysis utilized a perplexity of 30, a learning rate of 500, and involved 1000 iterations. The application of the t-SNE algorithm resulted in a clear and discernible representation of all sample points in the two-dimensional space. Notably, the majority of samples displayed characteristic trajectories, demonstrating a consistent evolution even after perturbations. This observation highlights the temporal continuity and pulsatile nature inherent in weather variations.

t-SNE visualization results. (a) The two-dimensional output of the t-SNE technique for dimensionality reduction. (b) The t-SNE technique produces a three-dimensional output for reducing dimensionality.
To assess the efficacy of dimensionality reduction techniques, both t-SNE and PCA were employed to reduce the training set data to two and three dimensions respectively. Table 2 presents the credibility results [36, 37], while Equation (49) defines the mathematical formulation for credibility. Credibility stands as a pivotal metric for assessing the preservation of local data structures post-dimensionality reduction. A higher level of credibility indicates a superior retention of data integrity following dimensionality reduction. The findings in Table 2 demonstrate that t-SNE, when utilized for low-dimensional representation, significantly enhances dimensional reliability compared to PCA. Additionally, t-SNE effectively preserves the temporal characteristics of the original data.
Two-day data credibility calculation results
Where M1(k) ranges from 0 to 1. r(x i ,x j ) represents the rank of sample x j sorted according to the distance from x i in the original data space, and U k (x i ) represents the set of adjacent data points k in the low dimensional space.
In the selection of training data based on the Grey Association, the time series data with the largest method is selected as the association sample. Figure 4 shows the two-day data association value view of WGRA and GRA. The entropy weight method yields a weight: Δ1 = 0.7332, Δ2 = 0.2668.
Figure 4 demonstrates that the data with a relation value of more than 0.5 accounts for around 35% of the total and the data with a relation value of more than 0.8 accounts for roughly 5% of the total. Because of the different conditions of relation, the data selection of the two methods has different effects. To compare the impact of training on data selection of WGRA and GRA, the selection conditions are defined as Ψ> 0.8and F > 0.8, respectively, so that the data with strong correlation can be retained as training parameters, and the data with weak correlation can be eliminated.

Grey correlation results for two consecutive days.
In the short-term prediction analysis, the power output of the next day is predicted by taking 69120 data points of 2880 groups of data in 30 days as the training set. To demonstrate the good functionality of the suggested model (t-SNE_Weighted Composite GRA_IGWO Algorithm optimized SVM, t-SNE_WGRA_IGWO_SVM), this paper employs the t-SNE_ GRA_Improved Grey Optimization Algorithm optimized SVM (t-SNE_GRA _IGWO_SVM), t-SNE _IGWO_ SVM, IGWO_ SVM for comparison. Meanwhile, in order to more thoroughly assess the benefits of the enhanced gray wolf algorithm, the vector machine model based on ABC [38], GWO, PSO [39], and Genetic Algorithm (GA) [40] are established, which are t-SNE_WGRA_GWO_SVM, t-SNE_WGRA_ABC_SVM, t-SNE_WGRA_PSO_SVM, and t-SNE_WGRA_GA_SVM respectively. In order to forecast the production of wind energy, single back propagation neural network (BPNN) models have also been created.
Table 3 presents the initialization configurations for various methods. The parameter and error penalty ranges for kernel functions are specified as [0.01, 100]. These parameters are set to ensure uniformity in the number of iterations across algorithms, thus upholding the integrity of the comparison.
The simulation parameters that are used by the algorithm for predictions
Table 4 displays a comparison of credibility results for PCA and t-SNE under different dimensionality reduction scenarios. The higher the credibility value of data, the more perfect the retention of data characteristics. At the same time, the lower the dimension, the smaller the calculation amount. t-SNE can also retain the feature value of data more completely in low-latitude data, so this paper selects two-dimensional data after t-SNE dimension reduction.
30-day data credibility calculation results
Figure 5 presents the visualization results of t-SNE dimensionality reduction. It is evident from Fig. 5 that, whether in two or three dimensions, the data exhibits a discernible classification effect. This observation suggests that even after dimensionality reduction, the continuity of NWP data may still be preserved within the dataset.

Visualization results of t-SNE dimension reduction of 30 day data. (a) The two-dimensional output of the t-SNE technique for dimensionality reduction. (b) The t-SNE technique produces a three-dimensional output for reducing dimensionality.
Figure 6 shows the distribution of correlation values. The entropy weight method yields weights: Δ1 = 0.5734, Δ2 = 0.4266, and the training data selected by WGRA and GRA are about 5% of the total data.

Visualization results of gray correlation between 30 day data and forecast days.
Figure 7 shows the predicted output waveform. Figure 7(a) shows that the single model BPNN and IGWO_SVM with no preprocessing data are poor in predicting wind power generation, which indicates that the single model can’t make good use of NWP data as training samples. In contrast, the prediction value of t_SNE_IGWO_SVM and t_SNE_BPNN methods are acceptable, but there are many weak association data, as the training sample of prediction, affects the accuracy of the forecast. Moreover, in training samples, WGRA outperforms GRA in terms of prediction impact. In addition, Fig. 7(b) shows that under the same data processing premise, IGWO has a better effect on SVM parameter optimization and a better prediction effect.

The outcomes of making forecasts using a variety of models. (a) t-SNE_WGRA_IGWO_SVM, t-SNE_GRA_IGWO_SVM, t-SNE_IGWO_SVM, IGWO_SVM and BPNN; (b)t-SNE_WGRA_GWO_SVM, t-SNE_WGRA_ABC_SVM, t-SNE_WGRA_PSO_SVM and t-SNE_WGRA_GA_SVM models.
Table 5 presents a compilation of reductions in MAE, RMSE, and MAPE. As per equations (43) to (46), these numerical values offer a quantitative assessment of the accuracy and reliability of the algorithm’s predictions. With reference to the data provided in Table 5, the following conclusions can be drawn:
One day wind power prediction results from different algorithms
The t-SNE_WGRA_IGWO_SVM model, which was suggested, obtains the greatest performance out of all of the other prediction models. Compared with t-SNE_GRA_IGWO_SVM and t-SNE_IGWO_SVM models, with reference to the assessment indices of MAE, RMSE, and MAPE, it can be discovered that the WGRA algorithm may reportedly enhance the capacity for anticipating the series of wind power production.
In comparison with t-SNE_IGWO_SVM and t-SNE_BPNN, the prediction performance of IGWO_SVM and BPNN models are worse, demonstrating that the t-SNE data preprocessing can better remove redundant features and prevent overfitting caused by too many features.
In parameter optimization, IGWO has better prediction performance than GWO. For instance, the MAE of t-SNE_WGRA_IGWO_SVM is 4.13, while the MAE of t-SNE_WGRA_GWO_SVM is 4.50. The upgraded IGWO model’s addition of the new convergence formula and iterative equation, which gives the IGWO model superior learning and generalization capabilities to quickly find the global optimum solution, maybe the main factor. Compared with other SVM optimization methods, on the premise of data preprocessing, the prediction results of all algorithms can have high accuracy. Meanwhile, the operation time of ABC, PSO, and GA is longer than that of IGWO. For the data in this paper, IGWO has better global performance and higher accuracy.
Making the findings more understandable, Table 6 lists the reductions in MAE, RMSE, and MAPE compared to models other than t-SNE_WGRA_IGWO_SVM. The correlation coefficient in Table 6 further demonstrates the superior performance of the suggested enhancement strategy.
The reductions in MAE, RMSE, and MAPE compared to models other than t-SNE_WGRA_IGWO_SVM
Additionally, Table 7 details the timespan needed to calculate data related to different approaches. The results in Table 7 show that single models, like BPNN, need much less time to run than their hybrid equivalents. However, hybrid models significantly outperform single models in terms of prediction accuracy. At the same time, without data preprocessing, including dimension reduction and association selection, the running time of the algorithm will be more burdened. For instance, IGWO_SVM takes quadruple as long to operate as t-SNE_WGRA_IGWO_SVM. Hence, in order to guarantee the reliability of the power system, it is acceptable to implement a way of producing wind power that is more precise and to devote sufficient time to the calculation process.
Regression correlation coefficient r2 of different algorithms and optimal SVM parameters
Table 8 provides a workload comparison between the proposed method and traditional approaches. The proposed method demonstrates notable contributions in data preprocessing, iterative process optimization, and data correlation analysis, thereby enhancing prediction accuracy in contrast to conventional methods. In the table, work1, work2, and work3 represent the work of data dimensionality reduction, iterative process optimization, and data correlation analysis, respectively.
Comparison of workload between different methods
To illuminate the merits of our proposed methodology, we conducted Wilcoxon [41] and ANOVA analyses[42]. The former distinguished disparities in related or paired samples, while the latter ascertained potential differences in means across multiple groups. The Wilcoxon test, robust to non-normality, compared paired samples. In contrast, ANOVA evaluated differences in means among groups, assuming normality and variance homogeneity. Subsequently, both analyses were applied to forecasted and actual values from the proposed algorithm.
In the Wilcoxon analysis, a p-value of 0.66535 supported the null hypothesis, indicating favorable prediction accuracy. The ANOVA results (see Table 9 and Fig. 8) revealed non-significant differences between predicted and actual values (p = 0.7819 > 0.05), affirming the model’s accuracy. Where the sources of variance include Groups (between groups), Error (within groups), and Total (total); SS (Sum of squares) represents the sum of squares; df (Degree of freedom) represents the degree of freedom; MS (Mean squares) represents the mean square error; F represents the F value (F statistic). The F value is equal to the ratio of the mean square between groups and the mean square within the group, which reflects the random error. In summary, the proposed method demonstrates commendable predictive precision.
One-way ANOVA

ANOVA analysis.
To enhance the precision and utility of wind power prediction models founded on NWP, this study introduces an integrated approach that combines NWP composite index grey correlation with an augmented GWO_SVM framework. For preprocessing NWP data, t-SNE is employed for dimensionality reduction and redundancy elimination, while the entropy weight technique is applied to compute data weights. These weights are then allocated to both the grey correlation degree and the simplified cosine similarity, thus constituting a novel composite index grey correlation for training data selection. Simultaneously, in recognition of the algorithm’s nonlinearity, we introduce a nonlinear convergence factor and an iterative method featuring dynamic proportion weight within the GWO. This strategic integration serves to harmonize local optimization capabilities with global search proficiency, expediting the optimization convergence process. Empirical findings substantiate that preprocessing data prior to predictions mitigates computational burden. Furthermore, optimization of data association procedures substantially amplifies prediction accuracy. Finally, augmenting the GWO algorithm markedly enhances the overall efficacy of wind power prediction. The effectiveness of this approach is substantiated through rigorous experimental scrutiny, providing valuable guidance for subsequent development of classification and regression models grounded in wind power time series data.
In recent years, notable progress has been made in both deep learning and reinforcement learning, resulting in significant breakthroughs across a multitude of domains. Within the realm of bionic intelligent algorithms, the integration of deep learning techniques has demonstrated pronounced efficacy in augmenting algorithmic convergence and dynamic iteration effects. Future research initiatives should emphasize the harmonious integration of deep learning and reinforcement learning methodologies, with the aim of refining the precision and responsiveness of wind power prediction models. This integrative approach holds substantial potential for advancing the capabilities of predictive models in the domain of renewable energy resources.