
Abstract
The conventional approaches to constructing Prediction Intervals (PIs) always follow the principle of ‘high coverage and narrow width’. However, the deviation information has been largely neglected, making the PIs unsatisfactory. For high-risk forecasting tasks, the cost of forecast failure may be prohibitive. To address this, this work introduces a multi-objective loss function that includes Prediction Interval Accumulation Deviation (PIAD) within the Lower Upper Bound Estimation (LUBE) framework. The proposed model can achieve the goal of ‘high coverage, narrow width, and small bias’ in PIs, thus minimizing costs even in cases of prediction failure. A salient feature of the LUBE framework is its ability to discern uncertainty without explicit uncertainty labels, where the data uncertainty and model uncertainty are learned by Deep Neural Networks (DNN) and a model ensemble, respectively. The validity of the proposed method is demonstrated through its application to the prediction of carbon prices in China. Compared with conventional uncertainty quantification methods, the improved interval optimization method can achieve narrower PI widths.
Introduction
As an advanced technology, artificial intelligence has been developed rapidly, and it has achieved significant advancements in several domains recently, including autonomous driving [1, 2], medical diagnosis [3, 4], power load [5], finance [6–8], and wind power generation [9–11].
The majority of the predictions made thus far are point predictions with no uncertain information. The uncertainty arises from both aleatory (or data) uncertainty and epistemic (or model) uncertainty. Specially, aleatory uncertainty originates from unobserved explanatory variables, beyond those represented by x, or from inherently stochastic processes. Epistemic uncertainty arises from incomplete knowledge about the model, often due to the inherent imperfections of models. The enduring objectives of point prediction systems are high prediction accuracy and the removal of prediction errors. Nonetheless, the prediction error and uncertainty cannot be eliminated in practical application [12]. Although artificial intelligence has achieved high prediction accuracy, the information provided by point prediction is limited in the face of high-risk tasks. Once the prediction fails, it will carry a high level of risk, and moreover, it is not enough for forecast demanders to provide a definitive point forecast. Therefore, we need to provide forecasting reliability to offer more information; this requires us to quantify the uncertainty of the forecast. Compared to point prediction, a prediction interval directly expresses uncertainty by providing both a lower and an upper bound. This ensures that the actual values are likely to fall within these boundaries. The quality of prediction intervals is typically assessed quantitatively using metrics such as Prediction Interval Coverage Probability (PICP), Mean Prediction Interval Width (MPIW), and Coverage Width Criterion (CWC). PIs are more reliable and provide additional information for decision-makers, contributing to more rational decision-making processes.
At present, there are methods that generate PI, including delta [13], Bayesian [14, 15], mean-variance estimation (MVE) [16, 17], bootstrap [18, 19], quantile regression [20, 21], kernel density estimation method [22, 23], Gaussian process [24], and LUBE [25]. These methods can be divided into two categories according to whether they require a priori assumptions.
The first type of method includes PI constructed by the delta, Bayesian, MVE, and bootstrap, it assumes that the data follow some prior distribution, and then the lower and upper bounds of the interval can be calculated in which the data may fall at a given probability level [26]. However, these methods have non-negligible drawbacks. The delta requires a large amount of computation and cannot be effectively applied in practice; the Bayesian calculates PI with low accuracy and requires a lot of computation because each parameter has a predetermined distribution; the MVE produces a small coverage of PI; and the bootstrap method is demanding and time-consuming for computing devices. Moreover, the approaches mentioned above make use of distributional assumptions that are constructed based on a priori knowledge or prediction errors; nevertheless, it is not always possible to guarantee that these distributional assumptions are accurate.
The second type of method includes quantile regression, kernel density estimation, and Gaussian processes, which are not constrained by the assumption distribution of data and prediction error, and we can construct PIs directly for uncertainty. Their core idea is to train a model by minimizing an error-based loss function, and then use the output of the trained model to construct PI. However, these methods rely on point prediction and have difficulty handling high-dimensional and massive data.
To solve the aforementioned issue, A. Khosravi et al. [25] introduced a new method for constructing PI based on a single-layer feedforward neural network that can output lower and upper bounds directly; this method is known as LUBE. Because the parameters used by the method to form the cost function of the training network are the same as those used to assess the quality of the generated PI, the computational effort is minimal. It provides PIs with a high coverage probability and small average width without assuming any data distribution [27]. Although the LUBE approach has achieved widespread popularity, it still has some defects that limit the accuracy development of interval prediction to some degree. Firstly, the loss function is non-differentiable, making optimization challenging. As training approaches, only non-gradient algorithms can be employed. However, gradient descent (GD) is the standard method for training neural networks. Second, because the LUBE loss function is defined by PI characteristics, it lacks statistical significance and achieves a global optimum only when the PI’s width is zero. Furthermore, the method simply accounts for the data noise variance and does not explain the model uncertainty. T. Pearce et al. [28] developed a loss function that can be utilized with GD and does not require distributional assumptions to address these flaws. The model uncertainty is taken into account in ensemble form. Salem et al. [29] introduced a multi-objective loss function that incorporates PIs and point estimations based on T. Pearce, and their incorporated penalty function enhances the semantic integrity of the results and stabilizes the training process of the network. In addition, it aggregates the set PIs into a split-normal mixture such that the PIs capture aleatory uncertainty and epistemic uncertainty. N. Rosenfeld et al. [30] proposed a discriminating learning framework for optimizing the expected error rate with interval-size budget constraints. In the framework of batch learning, PIs for a set of test points can be constructed simultaneously. Y. Lai et al. [31] integrated the MPIW into the form of the negative log-likelihood (NLL) as an estimate of the uncertainty. It makes the width of the constructed PI closely related to uncertainty.
The above works have largely contributed to the development of uncertainty prediction. Nevertheless, the deviation of the forecast target value from the forecast interval was not considered in previous research, which is a problem that cannot be ignored and, to some extent, limits the improvement of the forecast interval accuracy. In this work, a novel multi-objective loss function that further considers the accumulative deviation of the PI is built based on earlier works. First, the new loss function incorporates PIs and point estimates. Second, the width of the PI is closely related to uncertainty. In addition, the accumulative deviation of the PI is introduced by the loss function, which can lower the prediction risk. In this study, DNNs with robust learning capabilities are employed to build trustworthy PIs by implicitly learning uncertainty within the LUBE framework under the guidance of loss functions.
The majority of carbon price forecasting techniques examined in the literature to date are point predictions[32–36], and few uncertainty forecasts about carbon price are made. We try to use the created approach to predict the PI of carbon price. In contrast to previous research on time series forecasting of carbon price, this study considers multiple factors affecting carbon prices for multivariate regression forecasting. Moreover, a variable filtering procedure was used to remove variables with low correlation, thereby reducing redundant work.
The contributions of this study include: An improved PI optimization framework is established by introducing the optimization objective of PI deviation information in the loss function, which provides a new idea for optimizing PIs. This study combines the LUBE technique with deep learning models. Guided by the loss function, the DNN uses the LUBE framework to directly estimate the PI. A new carbon price forecasting framework that provides more information on carbon price uncertainty is proposed. This study enriches the research on carbon price forecasting, and PI can provide more comprehensive information to policymakers.
The rest of this paper is structured as follows: Section 2 describes the process of PI construction, and shows the prediction process of the proposed method. Section 3 presents the data selection process and the evaluation metrics of the PIs. Section 4 presents the procedure of the experiment and discusses the results. Section 5 summarizes the whole paper and points out the direction of future work.
Construction of the optimal PI for uncertain estimation
In this part, a LUBE-based quantified uncertainty approach for building PI in deep neural networks is provided; this model is called LUBE-PIAD-DNN. This section details the construction principle of the optimized loss function introduced into PIAD and also shows the theoretical and predictive process of LUBE-PIAD-DNN to generate PI.
The uncertainty framework
The principle of regression is to apply the data generation function f (x) in combination with additional noise to express the observable target value y:
In general, the goal of regression is to generate a function
is the source of model uncertainty or epistemic uncertainty, epistemic uncertainty arises from incomplete knowledge about the model, often due to the inherent imperfections of models. Whereas is the source of data uncertainty or aleatory uncertainty.
We assume that the size of a mini-batch is n, and x
i
is the i - th input of y
i
. The principle of uncertainty quantification is to predict a PI
MPIW stands for the mean PI width [25,28,31,37, 25,28,31,37], which is defined as:
Y. Lai et al. [30] have shown that their method of interval prediction outperforms Quantile Regression (QR) [38], Gradient Boosting Decision Tree with Quantile Loss (QR GBDT ) implemented in the Scikit-learn package [39], the quality-based PI construction method IntPred [40], Quality Driven Ensemble (QD-Ens) [28], and the prediction interval aggregation method SNM [28]. In the Y. Lai et al. [30] study, the loss function of uncertainty-based PI(UBPI) is defined with two terms:
We derive the
The
The
Studies [25, 28] provide inspiration for
Equation (11) implies that PICP will be penalized during the training process if it is less than a predetermined confidence level P c . That is, PICP should be greater than or equal to P c to avoid the penalty.
The Boolean c
i
in Eq. (4) results in the
The loss function of UBPI is defined as:
To the best of our knowledge, only the loss of width and coverage has been considered in the existing literature, while the loss of deviation information has not been taken into account, which would make the effectiveness of PI somewhat compromised. Based on the work of Y. Lai et al. [30], the PIAD optimization objective is introduced into the loss function. For the uncertainty to be quantified and the best PI to be provided, the loss function
PIAD is defined as:
Finding a fundamental equilibrium between the coverage probability and width of PI is the focus of recent research on the loss function of PI [25]. Recently, Y. Lai et al. [30] make the width of PI and uncertainty have a close link and verify that the method based on Loss UBPI outperforms the state-of-the-art methods [28, 38–40] at the time in terms of PI quality.
The loss function for the [24] is
The loss function of [28] is
Inspired by [25] and [28–29, 31], the proposed approach builds on them, and the case of prediction deviation information is further considered. As a result, while obtaining a “high coverage and narrow width” prediction interval, even if the forecast fails, the predicted value will still be as close to PI as possible. The advantages of the loss function constructed in this study have two aspects. First, both point estimates and PI are incorporated into this loss function. Second, the uncertainty is learned without requiring uncertainty labels.
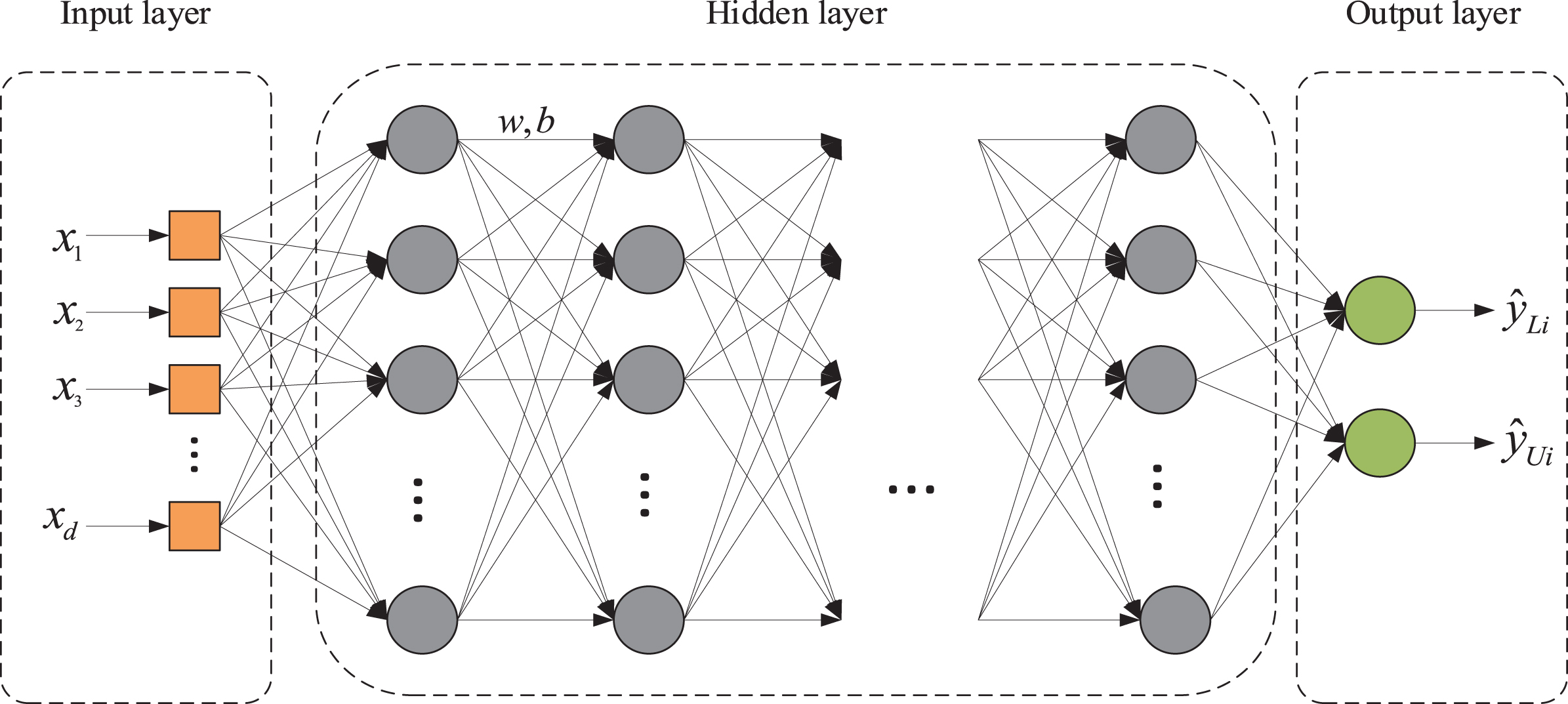
The basic structure of deep neural network.
Parameter settings
Deep neural networks are multilayer neural networks built on the basis of artificial neural networks (ANNs), where the more hidden layers there are, the more extensive the connections between neurons are. This makes it possible for autonomous learning to have more complex hidden features, which enhances DNN’s capacity to handle nonlinear problems in a range of domains. The DNN structure is shown in Fig. 1 and is made up of an input layer, many hidden layers, and an output layer, each of which uses the output of the layer before it as its input. w and b stand for the weight coefficient matrix and bias vector between layers, respectively, and x1, x2, ⋯ , x
d
are the DNN’s inputs,
Parameter setting and prediction process
In the experiment, the historical data of each carbon price series and the corresponding variables selected by MI-MRMR are used as inputs. The upper and lower bounds of the prediction interval are directly outputted using the machine learning-based LUBE-PIAD framework. After repeated trials, the parameters of the loss function and the neural network settings are shown in Table 1.
The prediction process is displayed in Fig. 2, and the specific steps are shown below.

The prediction process of the PI by DNN.
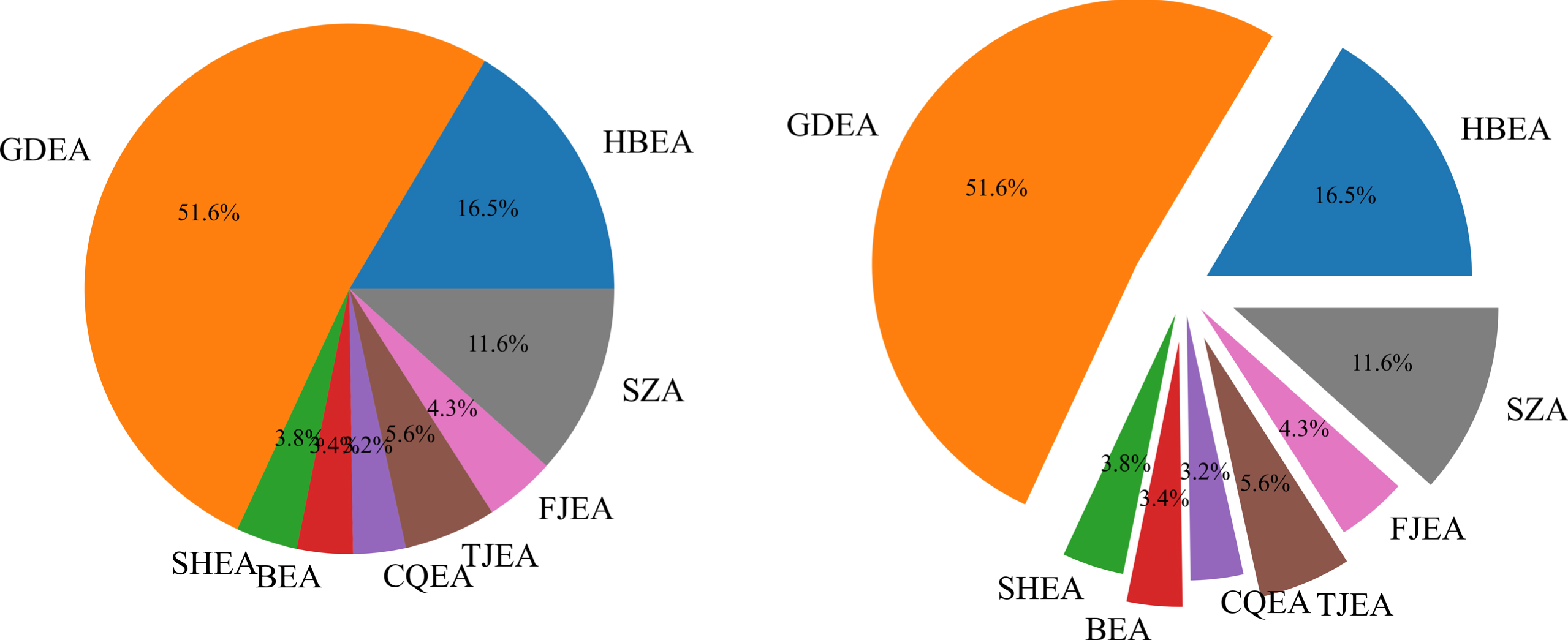
The trading volume of China’s carbon market.
Selection and description of data
Data on China’s carbon price will be used for the empirical analysis. China has now established eight pilots for carbon trading, namely Hubei carbon market carbon emission allowance (HBEA), Guangdong carbon market carbon emission allowance (GDEA), Shenzhen carbon market carbon emission allowance (SZEA), Shanghai carbon market carbon emission allowance (SHEA), Beijing carbon market carbon emission allowance (BEA), Chongqing carbon market carbon emission allowance (CQEA), Fujian carbon market carbon emission allowance (FJEA), and Tianjin carbon market carbon emission allowance (TJEA). The activity and stability of carbon trading pilots through trading volume and market liquidity are discussed in this section. Finally, the carbon price of HBEA, GDEA, SZEA, and SHEA is selected as the object of empirical analysis.
The trading volume of China’s different carbon markets is shown in Fig. 3. Carbon markets in Guangdong, Hubei, and Shenzhen are the top three in trading volume within the sample interval, accounting for 51.2%, 16.3%, and 11.5% of all pilot trading volume, respectively. The larger trading volume indicates a more active and representative carbon market.
The ratio of trading days in different carbon markets is exhibited in Table 2. Hubei, Guangdong, Shenzhen, and Shanghai have carbon market ratios that are greater than 60% within the sample interval (95.19%, 94.57%, 86.93%, and 60.24%, respectively). High ratios indicate good liquidity and activity in these four markets.
The ratio of trading days in different carbon markets
The ratio of trading days in different carbon markets
Factors affecting the carbon price
To more comprehensively validate the performance of the LUBE-PIAD-DNN, an empirical analysis is being conducted on four active and two inactive carbon trading price datasets. The sample period spans from January 1, 2017, to February 28, 2022.
With reference to the reference [44] on the selection of variables affecting carbon price, 15 pertinent variables that may affect changes in carbon price in terms of macroeconomics, international carbon markets, energy prices, climate and environment, and public attention are selected in this study. The specific variables and data sources are shown in Table 3.
Evaluation Metrics for PI
To verify the effectiveness of the proposed method, we evaluate the quality of PI in terms of PICP, MPIW, and the coverage width criterion (CWC). PICP and MPIW are defined as shown in Equations (4), and (16) above, respectively, and CWC is defined as follows.
The PI normalized average width (PINAW) is designed by:
The CWC combines the coverage and width of the PI, which is defined as:
Comparison of different variable screening methods
Note: The best value for each MPIW and CWC is shown in bold.
To improve the efficiency of subsequent predictions, the initially determined 15 variables are screened. Firstly, main variables for HBEA, GDEA, and SZEA are chosen using Mutual Information (MI) [47], Random Forest (RF) [48], Recursive Feature Elimination (RFE) [49], Correlation Coefficient (CC) [45–46], and Mutual Information-based Maximum Relevance Minimum Redundancy (MI-MRMR) [50] method, respectively. Variables with a Correlation Coefficient greater than 0.3 are chosen, while other methods aim to select the top 5 variables. Then, the LUBE-PIAD-DNN predicts based on the selected variables. The prediction results using different selection methods are shown in Table 4. The most suitable variable selection method is determined based on PICP, MPIW, and CWC. PICP assesses only one aspect of prediction intervals. According to the principles of high-quality prediction intervals, if a prediction intervals meets the requirements, then the width of the prediction intervals will be given more consideration. It can be easily observed that the MI-MRMR method has an absolute advantage in effectively selecting variables. All PICPs meet the predetermined Pc. While, the prediction intervals derived from variable selection using the MI-MRMR method show significantly lower values in MPIW and CWC compared to those obtained through other methods. Particularly in the case of HBEA, under the condition where all PICPs are greater than 0.9, the MPIW obtained by MI-MRMR is 11.766, which is 23.559 smaller than the 35.325 achieved by the best comparative method. Among the comparative methods, MI performs the best, yet it is still significantly inferior to MI-MRMR, which demonstrates the good performance of mutual information-based feature screening. Hence, the MI-MRMR method is employed for variable selection in the remaining samples as well.∥The results of variable selection are shown in Table 5. The table reveals a variation in the variables chosen for each carbon market. Notably, most carbon prices have selected x4, x5, x15, indicating that the carbon prices in China are greatly influenced by international carbon prices, energy prices, and public attention.
Variables selected for different carbon price series based on MI-MRMR
Variables selected for different carbon price series based on MI-MRMR
Comparison of LUBE-PIAD-DNN before and after screening variables
Comparison of LUBE-PIAD-DNN before and after screening variables
Note: The best value for each MPIW and CWC is shown in bold.
Comparison of LUBE-PIAD under different machine learning frameworks
Note: The best value for each MPIW and CWC is shown in bold.
Table 6 displays the prediction results of LUBE-PIAD-DNN before and after screening variables. As can be seen from Table 6, PICPs are all greater than Pc (0.9), and it can be judged from the MPIW and CWC that the quality of the prediction intervals obtained after variable screening is significantly better than that before variable screening, which proves the effectiveness and necessity of variable screening.
Performance comparison of the proposed model with the benchmark model
To obtain high-quality prediction intervals, a comparison experiment of the proposed interval prediction loss function under machine learning methods such as DNN, ANN, ELM, GRNN, etc. is conducted. The comparison of performance of prediction intervals obtained under different machine learning approaches is shown in Table 7. All PICPs meet the predetermined 0.9, and in all cases, the LUBE-PIAD-DNN achieves the narrowest MPIW and the lowest CWC. This suggests that deep learning frameworks surpass shallow machine learning frameworks in performance, aligning with our expectations. In shallow machine learning, GRNN exhibits the most inconsistent performance. In three out of the six cases (specifically SZEA, SHEA, and CQEA), it ranks just below DNN. This is particularly evident in the SZEA example, where GRNN achieves an MPIW of 25.385 when all PICPs are above 0.9, slightly higher than DNN’s MPIW of 25.185. However, in the other three cases, GRNN records the highest MPIW.
Comparison of prediction interval results for different method
Comparison of prediction interval results for different method
Note: The best value for each MPIW and CWC is shown in bold.
After filtering the variables, six examples of the Chinese carbon price are selected as the object of empirical analysis in the LUBE framework based on DNN, using Loss Total , Loss UBPI , Loss SNM and Loss LUBE as the objective functions, in turn, to compare the performance of these four loss functions (these four methods are referred to as LUBE-PIAD-DNN, UBPI, SNM, and LUBE), with each of the six models executed 20 times to eliminate the randomness of the initialization of the neural network. Table 8 shows the PI performance of the four PI forecasting models in terms of PICP, MPIW, and CWC.
It is easily observe from Table 8 that all models achieve a PICP greater than Pc. Among all the cases, the LUBE-PIAD-DNN exhibits the best performance; it maintains narrower MPIW and lower CWC while meeting the preset PICP levels. Notably, LUBE shows the poorest performance in five datasets, with significantly larger MPIW. Particularly in the case of the SHEA example, the MPIW of other methods is all less than 10, whereas the MPIW for LUBE is as high as 40.055. The performance of SNM is only second to that of LUBE-PIAD-DNN. Taking into account three indicators, it can be concluded that the advantages of the proposed model are more evident, as it can generate higher quality prediction intervals.
To more intuitively compare the performance of the proposed model in constructing Prediction Intervals, the interval forecasting results of the SHEA case have been chosen to be demonstrated through Fig. 4. It is evident that all models perform well in terms of coverage probability. Considering both the coverage and width of intervals, the LUBE-PIAD-DNN model performs the best, yielding high-quality prediction intervals. In contrast, the PI width of the LUBE method is excessively large, resulting in poorer quality of prediction intervals.

Comparison of the prediction intervals for the proposed model and other models in SHEA.
Table 9 lists the one-step, three-step, and five-step prediction results of the proposed model. The PICPs obtained by all models meet the 0.9 criterion. In 1-step forecasting, the LUBE-PIAD-DNN model achieved the smallest MPIW among all instances. In 3-step and 5-step forecasting, the width of its prediction intervals increases, as does the CWC. From this, it can be inferred that with the increase in forecasting step length, the quality of the prediction intervals obtained by the LUBE-PIAD-DNN algorithm diminishes.
Performance comparison of the proposed model and other models in multi-step forecasting
Note: The best value for each MPIW and CWC is shown in bold.
For a more intuitive comparison, the radar chart in Fig. 5 illustrates the uncertainty measurements, with all PICP values surpassing the predefined level of 0.9. It is readily observable from Fig. 5 that the LUBE-PIAD-DNN model consistently yields smaller MPIW values in one-step predictions. From subfigure (c) CWC in Fig. 5, it is observable that the prediction intervals for SHEA, HBEA, and SZEA are of higher quality, as determined by the composite metric of probability and width. This may be attributed to the carbon markets in these regions being more mature, having larger scales, and encompassing a greater number of participants, thereby contributing to price stability.

Radar chart for predictive performance metrics.
The impact of Pc on the prediction results of the LUBE-PIAD-DNN is shown in Table 10. The model with Pc = 0.9 achieved the highest PICP, followed by the models with Pc = 0.8 and Pc = 0.7. A large PICP and a small MPIW are expected, however, MPIW and PICP often display opposing trends. This is logical, as an increase in PICP comes at the cost of expanding the prediction intervals. When Pc is low, smaller MPIW and CWC will also be produced. As Pc decreases from 0.9 to 0.7, the PICP values drop from 0.988, 0.925, 0.932, 0.952, and 0.960 to 0.800, 0.733, 0.765, 0.790, 0.768, and 0.698. Concurrently, the MPIW decreases from 11.766, 39.117, 25.185, 4.418, 46.853, and 21.351 to 9.214, 13.545, 12.017, 3.179, 45.040, and 17.659. This indicates that the quality of prediction intervals varies with the confidence level. Forecasters can choose an appropriate confidence level based on their specific needs.
Impact of different confidence intervals on prediction results
Impact of different confidence intervals on prediction results
In this paper, uncertainty is quantified using prediction intervals. We propose a new model for constructing Prediction Intervals (PI) in Deep Neural Networks (DNNs), based on the Lower Upper Bound Estimation (LUBE) method. To our knowledge, this is the first model that considers the impact of prediction interval accumulation deviation (PIAD) on prediction intervals. The model introduces additional constraints to ensure that values outside the prediction interval are as close as possible to the interval boundaries, thus aiming to reduce the cost associated with prediction failures. We apply the proposed model to carbon price forecasting in China. Through empirical analysis, we draw the following conclusions: Variable selection can improve the quality of the prediction intervals in subsequent forecasts. The optimization of the loss function enables the proposed model to generate higher quality PI compared to other interval forecasting models. Under the LUBE-PIAD framework, DNNs achieve higher quality prediction intervals than other shallow machine learning models. The quality of PIs is influenced by the confidence interval of the loss function. Larger confidence intervals result in broader PI coverage, which in turn affects MPIW and CWC. The predictive quality of the LUBE-PIAD-DNN model decreases as the step size increases.
In conclusion, with the PICP obtained from the forecast greater than the pre-determined confidence level, the proposed method can construct a PI with a narrower width and a smaller prediction bias. The prediction interval can provide rich prediction information for the carbon price, which offers a novel idea for carbon price prediction.
In future studies, the loss function can be improved by further considering the relationship between the upper and lower limits of output, and we will develop a more effective ensemble form of deep neural networks. Additionally, we’ll try to apply this method to other fields of uncertainty prediction.
Footnotes
Acknowledgments
The work was supported by National Natural Science Foundation of China (No. 72371001).