
Abstract
With the rapid proliferation of substantial textual data from sources such as social media, online comments, and news articles, sentiment analysis has become increasingly crucial. However, existing deep learning methods have overlooked the significance of part-of-speech (POS) and emotional words in understanding the emotion of text. Based on this, this paper proposes a sentiment analysis approach that combines multiple features with a dual-channel network. Firstly, the vector representation of the text is obtained through Robustly Optimized BERT Pretraining Approach (RoBERTa). Secondly, the POS features and word emotional features are separately updated using self-attention to calculate weights. Concatenating words, POS and emotion, feature dimension reduction and fusion are achieved through a linear layer. Finally, the fused feature vector is input into a dual-channel network composed of Bidirectional Gated Recurrent Unit (BiGRU) and Deep Pyramid Convolutional Neural Network (DPCNN). Experimental results demonstrate that the proposed method achieves higher classification accuracy than the comparative methods on three sentiment analysis datasets. Moreover, the experimental results fully validate the effectiveness of the proposed approach.
Keywords
Introduction
Sentiment analysis represents a deeply investigated area within the realm of Natural Language Processing (NLP), with its fundamental objective being the identification and interpretation of sentiments and emotional nuances present in textual content [1]. The surge in the volume of textual data, spanning social media posts, online commentary, and journalistic reports, has magnified the importance of sentiment analysis. Its applications are not confined to merely gauging consumer responses to products and services; rather, they extend to offering insightful analyses of societal trends and public sentiments. Therefore, sentiment analysis emerges as a field with significant potential for application across sectors such as business, social media surveillance, and the examination of public opinions [2].
Nevertheless, sentiment analysis confronts several hurdles, notably arising from the complexity inherent in textual data. Texts frequently contain a mix of sentiments, characterized by varying emotional tones, ambiguities, and multiple meanings. Traditional approaches to sentiment analysis often fall short in adeptly navigating these complex emotional layers. As a result, there has been a consistent effort among researchers to refine the accuracy and robustness of sentiment analysis techniques to better meet the needs of real-world applications [3].
This paper focuses on examining sentiment analysis methodologies that incorporate multi-feature fusion and dual-channel networks to improve the efficiency and effectiveness of sentiment analysis. Multi-feature fusion is a strategy that combines different types of feature information to bolster the model’s performance. Through the integration of textual, emotional, and part-of-speech (POS) features, we aim to achieve a nuanced understanding of the emotions conveyed in the text. POS features, which delineate the grammatical function of words within a text [4], aid the model in grasping the grammatical constructs and relationships of POS in the text. For instance, information on POS such as nouns, verbs, and adjectives can provide insights into the manner and intensity of emotional expression. Emotional features are pivotal in distinguishing the emotional content within a text, allowing the model to discern between emotional and non-emotional expressions, thereby enabling more precise assessments. Given the wide array of emotions and varied expressions found in texts, multi-feature fusion is essential for enabling models to capture this diversity of sentiments. This approach, in turn, enhances the depth and adaptability of sentiment analysis.
The dual-channel network introduced in this paper consists of a Bidirectional Gated Recurrent Unit (BiGRU) [5] and a Deep Pyramid Convolutional Neural Network (DPCNN) [6], forming a robust deep learning framework for textual data analysis. This architecture harnesses the capabilities of two distinct neural network models to encapsulate a wide range of information and features within the text. The BiGRU, as a Recurrent Neural Network (RNN) optimized for sequential data, effectively captures contextual nuances in text. Its bidirectional functionality allows for the assimilation of both preceding and succeeding contextual information, thereby enriching its understanding of context—a vital component in sentiment analysis due to the contextual dependency of sentiments. Concurrently, the DPCNN focuses on extracting features within a localized scope, adeptly identifying local patterns and attributes embedded in the text. The synergistic operation of BiGRU and DPCNN within the dual-channel network facilitates the comprehensive consideration of both the global context and localized features, culminating in enhanced performance in sentiment analysis. Deep neural networks, while powerful, are prone to overfitting, particularly in situations with limited data availability. The dual-channel network, by incorporating two distinct structures (BiGRU and DPCNN), introduces additional parameters and layers that significantly improve the model’s generalization capability, enabling it to adapt more effectively to texts across various datasets and domains. This strategy effectively reduces the risk of overfitting [7].
In summary, the main contributions of this paper are as follows. This paper explores the effective fusion of various types of feature information, encompassing textual features, POS features, and emotion features, aiming to enhance the performance of sentiment analysis. In multi-feature fusion, this paper introduces attention mechanism to distinguish the relatively important POS token and emotion token. In this paper, we combine a dual-channel network comprising BiGRU and DPCNN. This integration fully exploits the strengths of both BiGRU and DPCNN, enabling the consideration of both global context and local features. This approach not only mitigates the risk of overfitting but also facilitates multilevel feature extraction.
Multi-feature fusion for sentiment analysis
Literature [8] proposes an emotion analysis model based on multi-feature fusion, which combines contextual, syntactic, and semantic information to enhance emotion recognition. Additionally, to better capture the semantic information of sentences, an attention mechanism based on contextual emotion space is introduced. In Literature [9], a poetic sentiment analysis model is proposed, integrating multiple encoders to extract text features at various levels. This enrichment of text feature information aims to improve the accuracy of text semantics and enhance the learning and generalization ability of the model. In Literature [10], an emotion analysis model for enterprise brand evaluation is introduced. This model integrates depth features extracted from word vectors and named entities extracted using Conditional Random Field (CRF) [11]. Emotion results are obtained based on Support Vector Machines (SVM) [12]. In Literature [13], a multi-feature fusion GCN sentiment analysis method is proposed. This method constructs text maps based on several features, including aspect relation, word dependence relation, and semantic information relation, respectively. In Literature [14], an emotion analysis model for microblog comments is presented, introducing emojis to more accurately assess the emotional tendencies of microblogs. Emoji vectors and text vectors are input into the attention mechanism, and weights are assigned to extracted feature information to highlight important details. Finally, Literature [15] proposes an emotion analysis method based on bilingual feature fusion, combining Chinese and English to mitigate the influence caused by the deviation of sentence results. An aspect word attention mechanism is introduced to enable the model to acquire dependent information about aspect words.
Dual-channel networks for sentiment analysis
Literature [16] proposes a two-channel sentiment analysis method based on BiGRU+CNN. This method simultaneously incorporates global attention and local attention to explore the interaction between contextual semantic features and local structural features. Additionally, psychological characteristics are introduced to integrate psychological information into emotional classification. In another work, Literature [17] presents an emotion analysis model for course evaluation. This model constructs a dual-channel network of CNN and BiLSTM. Word vectors are obtained using BERT, and an attention mechanism is introduced after Bidirectional Long Short Term Memory (BiLSTM). Literature [18] introduces a sentiment analysis network based on the CNN-BiGRU architecture. This network utilizes BERT to obtain text vectors and subsequently fuses the output of a dual-channel network with an attention mechanism. Meanwhile, Literature [19] proposes a dual-channel Chinese sentiment analysis method based on multi-feature fusion. It combines word features and input BiLSTM and BiGRU respectively to extract context information. Finally, feature fusion is achieved through an attention mechanism. Literature [20] constructs a two-channel Chinese sentiment analysis model. This model inputs text into language models such as BERT and Word2vec [21] to obtain vector representations. Subsequently, through the dual-channel network of CNN and BiLSTM, the emotion category is determined by combining the attention mechanism.
Fusing multiple features is a pivotal strategy for augmenting the precision of sentiment analysis, with significant contributions made by several researchers [8–10, 14, 15] in this domain. However, the breadth of features they incorporate remains overly narrow, diminishing their relevance in sentiment analysis and constraining the model’s ability to generalize. Dual-channel networks, by contrast, leverage the advantage of assessing emotional data from diverse viewpoints. Studies [16, 17, 19, 20] have employed dual-channel frameworks to refine emotion classification accuracy. However, CNN applied in these investigations are of a shallow architecture, which curtails their capability for comprehensive feature extraction and results in a pronounced oversight of the global information intrinsic to emotional text.
Proposed methodology
Method structure
The network structure of the proposed method is shown in Fig. 1.

The text classification structure based on TTL and GCN.
As depicted in Fig. 1, the proposed methodology integrates several advanced neural networks, specifically RoBERTa, BiGRU, and DPCNN, to enhance performance. For ease of reference and clarity in subsequent discussions, this amalgamation will henceforth be designated as the RoBERTa-BiGRU-DPCNN (BGC) framework. Initially, the process involves the transformation of text data through RoBERTa to produce vector representations. These vectors are then enriched by integrating POS and emotion features, yielding multi-faceted feature vectors. These comprehensive vectors serve as inputs to a dual-channel network architecture, consisting of both BiGRU and DPCNN components. Upon normalization, the framework proceeds to output predictions across various emotion categories. The comprehensive methodology is meticulously outlined in Algorithm 1.

As depicted in Algorithm 1, the dataset requires preprocessing to render it compatible with the model. Initially, the dataset undergoes a cleaning process where irrelevant symbols and noise are removed from the original textual data. This is followed by the transformation of the text into RoBERTa encodings through the tokenizer tool provided by the transformers library [21]. Subsequently, the text is enriched with annotations for POS and emotional categories using the NLTK toolkit [22]. For example, given the text [‘I’, ‘like’, ‘to’, ‘watch’, ‘action’, ‘movies’], the corresponding POS sequence would be [’PRP’, ‘VBP’, ‘TO’, ‘VB’, ‘NN’, ‘NNS’], and the emotional categorization might appear as [’neu’, ‘pos’, ‘neu’, ‘neu’, ‘neu’, ‘neu’].
To enhance the semantic accuracy of POS vector representations, our study leverages the Continuous Bag of Words (CBOW) algorithm from Word2Vec for training the POS sequences. In addressing the representation of emotional words, the emotional valence of a word is identified by selecting the category with the highest score according to NLTK’s analysis. Given that emotional words are categorized into three distinct groups, their vector representation is simplified using one-hot encoding, facilitating a more direct interpretation.
BGC
RoBERTa
RoBERTa is constructed upon the Transformer architecture, which has established itself as the cornerstone for numerous state-of-the-art NLP models. It signifies a notable progression in the field of NLP, expanding upon the achievements of BERT. The input structure of RoBERTa remains analogous to that of BERT, as illustrated in Fig. 2.
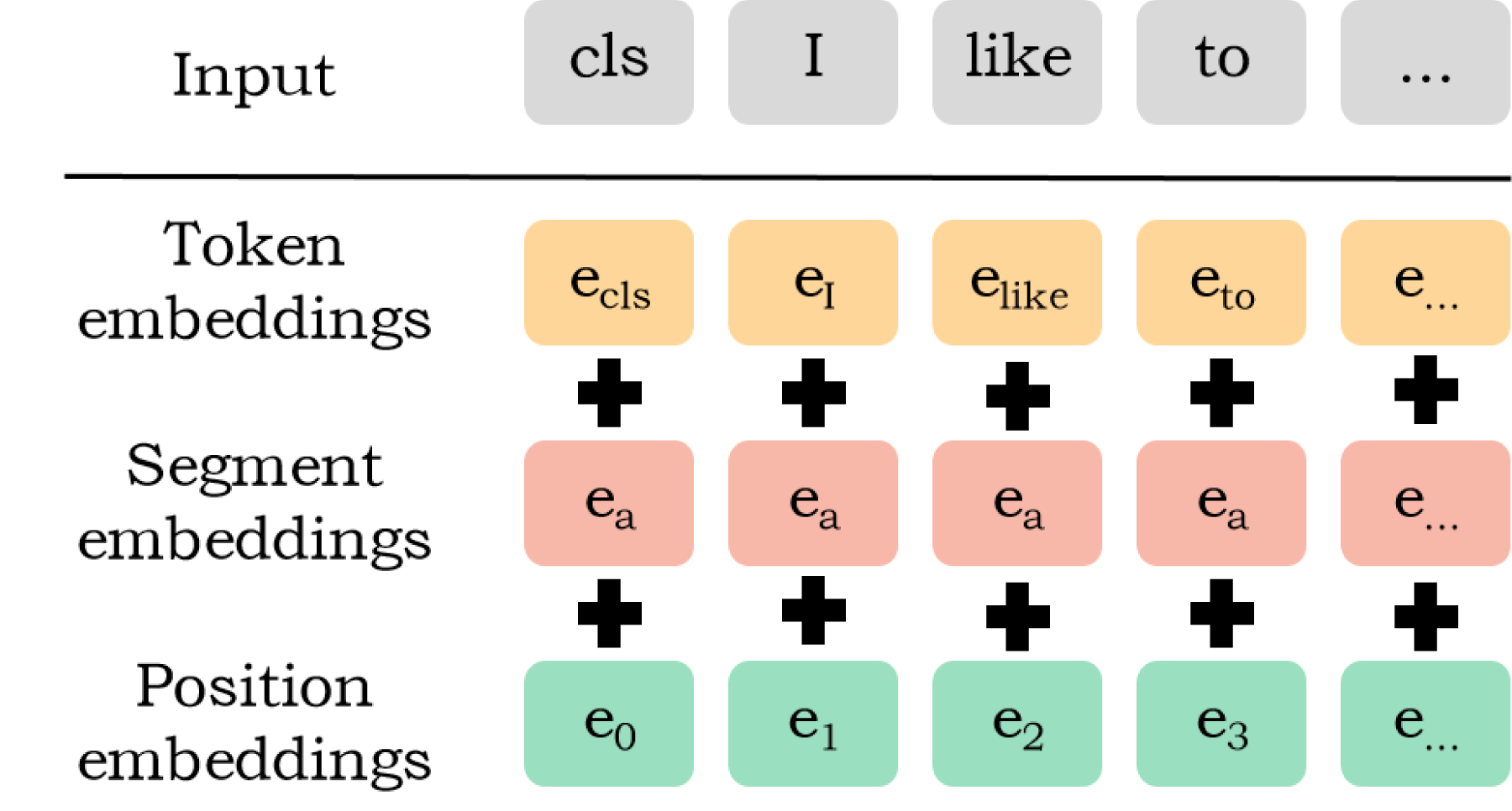
The input composition of RoBERTa.
RoBERTa has achieved significant improvements in its pretraining objectives, scale, and training techniques. Similar to BERT, RoBERTa follows a two-step process: pretraining and fine-tuning. During the pretraining phase, the model undergoes training on an extensive corpus of text data to acquire contextually relevant word representations. The key innovation in RoBERTa lies in its approach to pretraining objectives. Unlike BERT, RoBERTa employs a substantially larger dataset and eliminates the Next Sentence Prediction (NSP) task. Instead, it utilizes a Masked Language Modeling (MLM) objective, wherein the model predicts randomly masked words within sentences. This adjustment enhances RoBERTa’s ability to understand language and context more effectively [23].
RoBERTa’s training data scale significantly exceeds that of BERT, utilizing a corpus of 160 GB of text data, whereas BERT only uses 13.5 GB. Furthermore, RoBERTa employs a larger model with more layers and hidden units. This increased scale and scope contribute to its superior performance across various NLP benchmarks [24]. Additionally, RoBERTa employs larger batch sizes and undergoes more training steps [25].
The Self-Attention Mechanism [26], a cornerstone technique in deep learning, has garnered widespread acclaim for its pivotal role, particularly within NLP. It empowers models to dynamically allocate attention weights across various positions in a sequence, considering their interrelations. Such a feature significantly augments the model’s prowess in capturing contextual nuances and forging semantic linkages. The crux of this study lies in applying the self-attention mechanism to sequences of POS and emotion, serving a dual purpose. The first objective is to enhance the dimensionality of POS and emotion features to align with the dimensions of the RoBERTa model, thereby facilitating smoother computational processes. The second aims at discerning the relatively crucial POS tokens and the significant emotion tokens within their respective sequences. This nuanced differentiation is anticipated to sharpen the model’s focus and attentional allocation. The mathematical representation of the attention mechanism is delineated as follows.
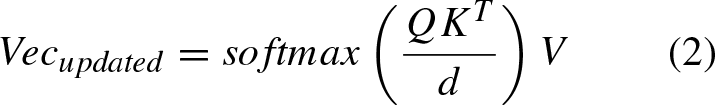
The BiGRU, or Bidirectional Gated Recurrent Unit, represents a sophisticated neural network architecture extensively employed within the domains of Natural Language Processing (NLP) and sequence modeling tasks. It significantly augments the functionality of the conventional GRU by facilitating the flow of information in both forward and reverse directions, thereby capturing a more comprehensive contextual understanding and relationships within sequential datasets. The GRU, recognized as an efficient alternative to the LSTM, is distinguished by its streamlined and practical parameters. Remarkably, it delivers performance on par with the LSTM, yet with a reduced parameter count [28]. Figure 3 illustrates the structural design of the BiGRU.
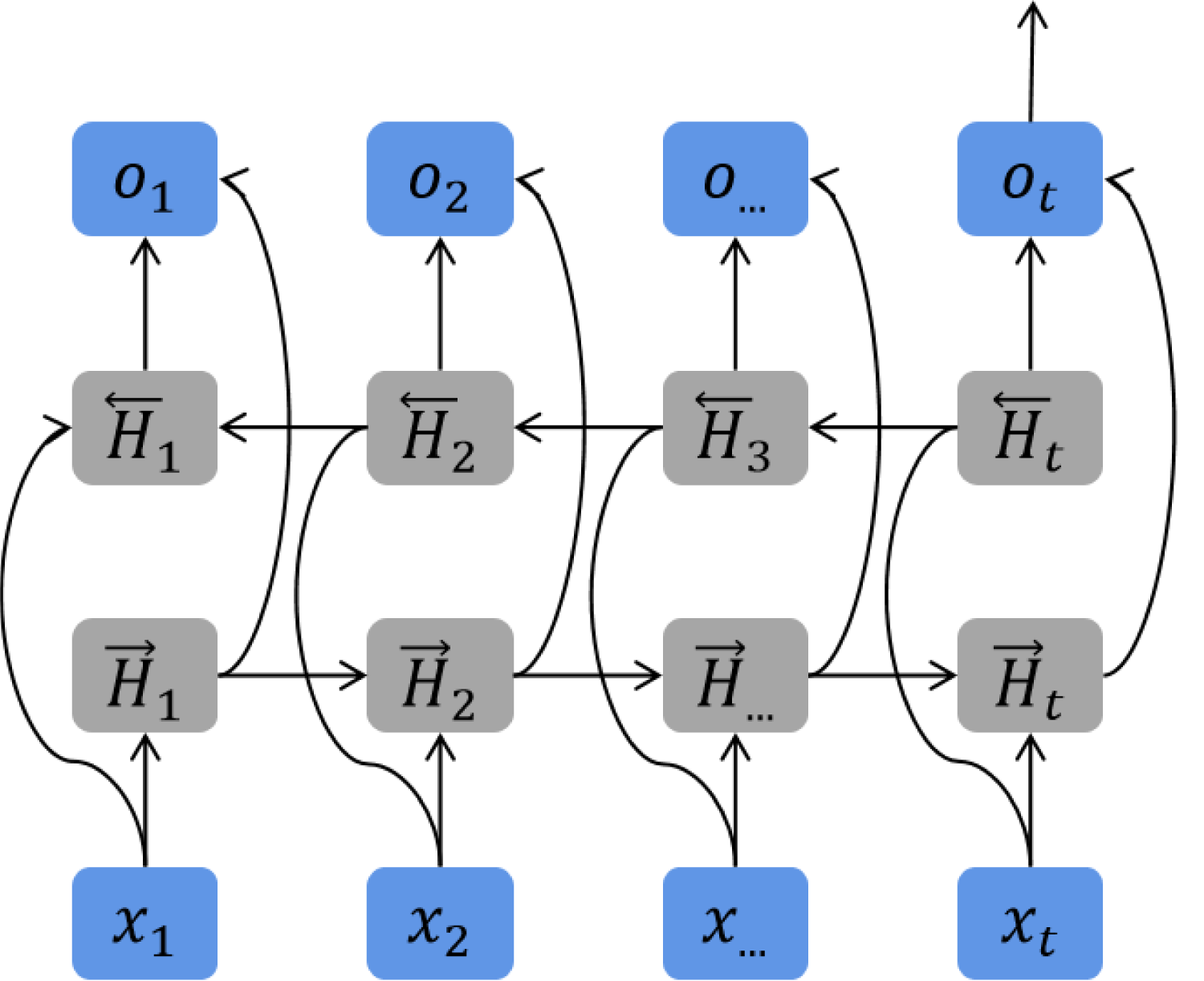
BiGRU.
The DPCNN represents an advancement in deep learning architectures, building on the foundational principles of TextCNN to address challenges in text classification and sentiment analysis tasks [29]. At its core, DPCNN is designed to harness the capabilities of a deep convolutional neural network, thereby adeptly capturing both the local and global characteristics inherent in text data. A distinctive feature of DPCNN is its implementation of a convolutional pyramid structure, which entails a hierarchy of convolutional layers each specialized in identifying various levels of textual features. This design principle facilitates a nuanced understanding of the text’s hierarchical nature. Further enhancing its robustness, DPCNN incorporates residual connections that promote the efficient flow of information across the network layers, effectively mitigating the vanishing gradient issue and making the network more amenable to training. These connections also play a crucial role in preserving information throughout the network. In the wake of each convolutional layer, DPCNN applies max-pooling to condense the data dimensionality, thereby spotlighting the most salient features. This strategy is pivotal in reducing computational demands and curbing the risk of overfitting [30]. The architecture of DPCNN is depicted in Fig. 4, illustrating its comprehensive approach to parsing and interpreting text data.
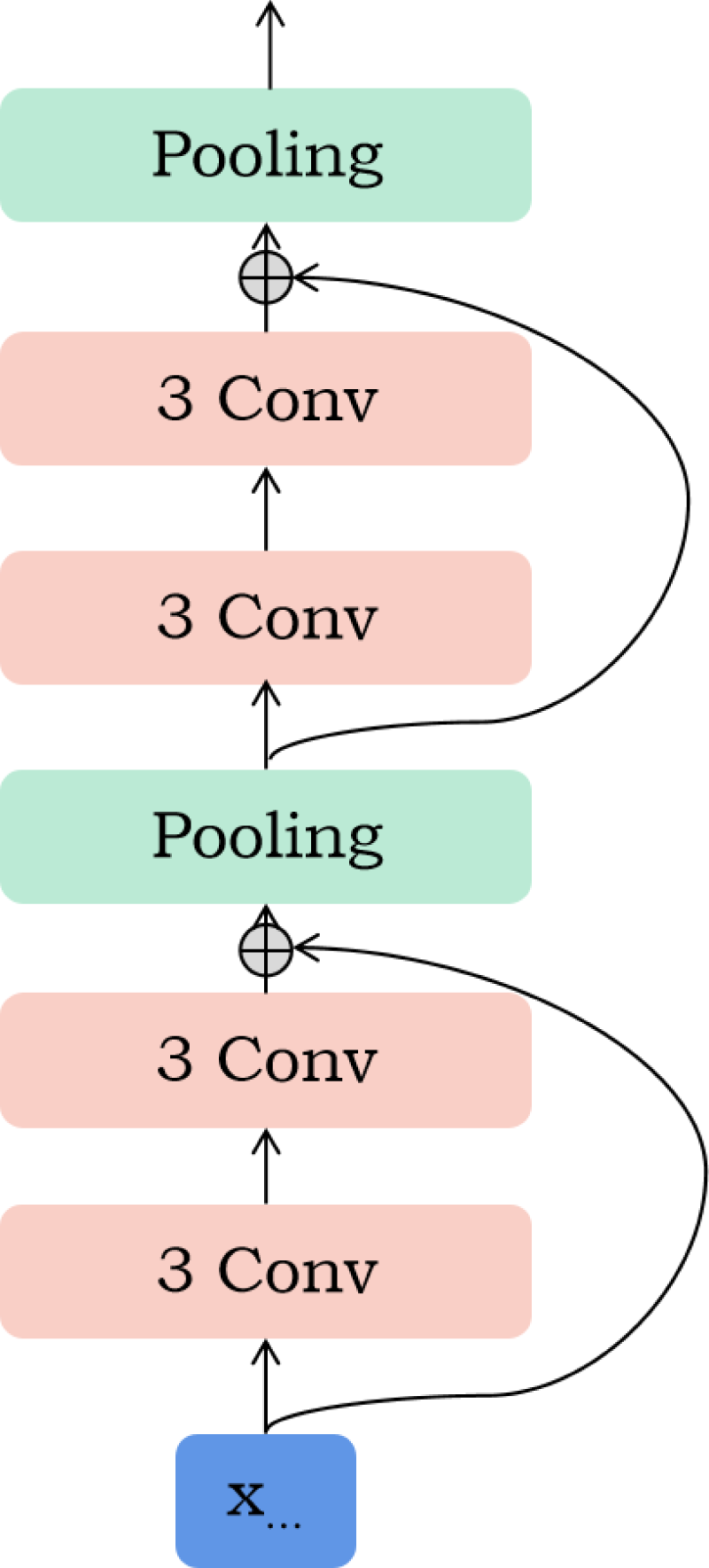
DPCNN.
While the DPCNN demonstrates certain proficiency in extracting global features, it may not achieve the level of comprehensiveness found in RNN architectures. Consequently, in order to more thoroughly capture both global and local information within sentiment analysis texts, this study integrates BiGRU with DPCNN. This approach harnesses the combined strengths of both RNN and CNN architectures.
In this section, we will experimentally verify the effectiveness and superiority of the method in this paper.
Experimental datasets
To fully demonstrate the superiority and effectiveness of the proposed method, this paper conducts experiments on three of the most common sentiment analysis datasets. These datasets include Imdb [31], MR [32], SST-2 [33], Twitter [34], and Amazon [35], their detailed information is presented in Table 1.
The datasets information
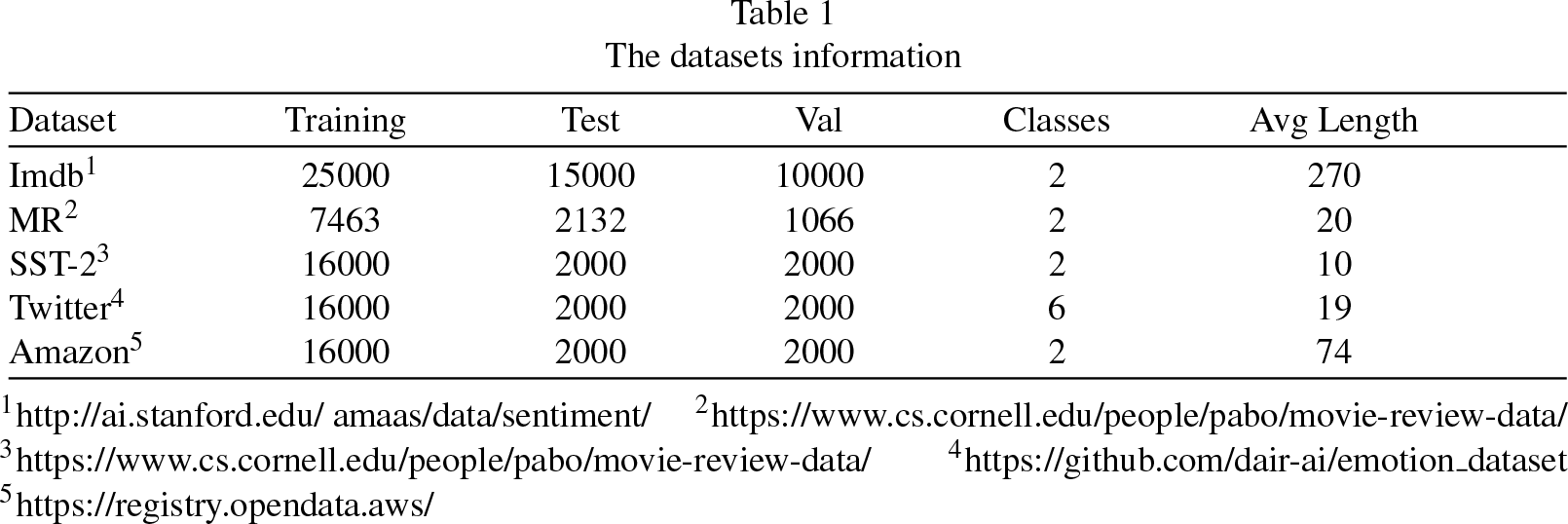
The datasets information
1 http://ai.stanford.edu/∼amaas/data/sentiment/ 2 https://www.cs.cornell.edu/people/pabo/movie-review-data/ 3 https://www.cs.cornell.edu/people/pabo/movie-review-data/ 4 https://github.com/dair-ai/emotion_dataset 5 https://registry.opendata.aws/
As presented in Table 1, the dataset employed in this study comprises a diverse array of text lengths, including long-text sources from IMDb and short-text collections such as MR, SST-2, and Twitter, thereby ensuring a broad spectrum of textual data for analysis. SST-2 is delineated as a subset within this dataset, with the training, testing, and validation partitions being randomly selected from the original corpus. The Twitter dataset is constituted of English-language tweets that encapsulate six primary emotions: anger, fear, joy, love, sadness, and surprise. Additionally, the dataset incorporating Amazon reviews consists of consumer feedback collected from the Amazon platform, spanning a dichotomy of emotional expressions.
Sentiment analysis falls within the realm of classification tasks. Therefore, in this paper, we have selected accuracy, recall, and F1 score as the evaluation metrics for the model. The calculation methods are illustrated in Eqs. (3), (4), and (5).


This paper delineates the methodology for training a model, employing a learning rate of 2e-5, with the training process defaulting to three iterations and terminating when the loss on the validation set does not diminish across three successive batches. The dataset is processed in batches of 32, with sentence length normalization conducted in accordance to the average length observed within the dataset. For optimization, the Adam algorithm is utilized, incorporating a dropout rate of 0.5 to mitigate overfitting. The architecture of the RoBERTa model is characterized by a hidden layer size of 1024. In contrast, the BiGRU model is configured with a hidden layer size of 512, and the DPCNN model is designed to utilize 256 filters.
Baselines
In this section, we will briefly introduce the baseline models of this paper.
Results
In this section, we present the relevant experimental findings along with a concise analysis of these results. Tables 2 and 3 display the testing accuracies of each method. It is important to note that the calculation here pertains to the macro-average result.
Classification accuracy on Imdb, MR, and SST-2 (%)
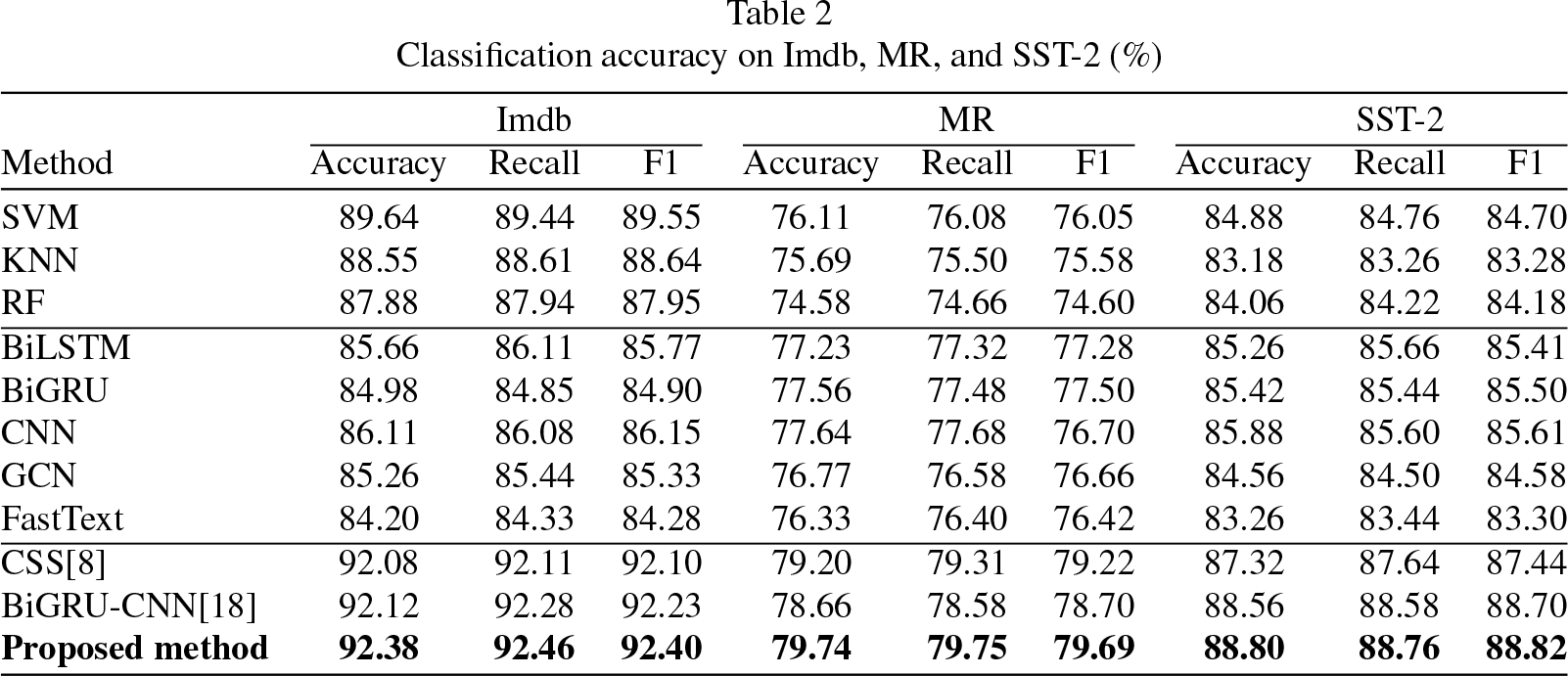
Classification accuracy on Imdb, MR, and SST-2 (%)
Classification accuracy on Twitter and Amazon (%)
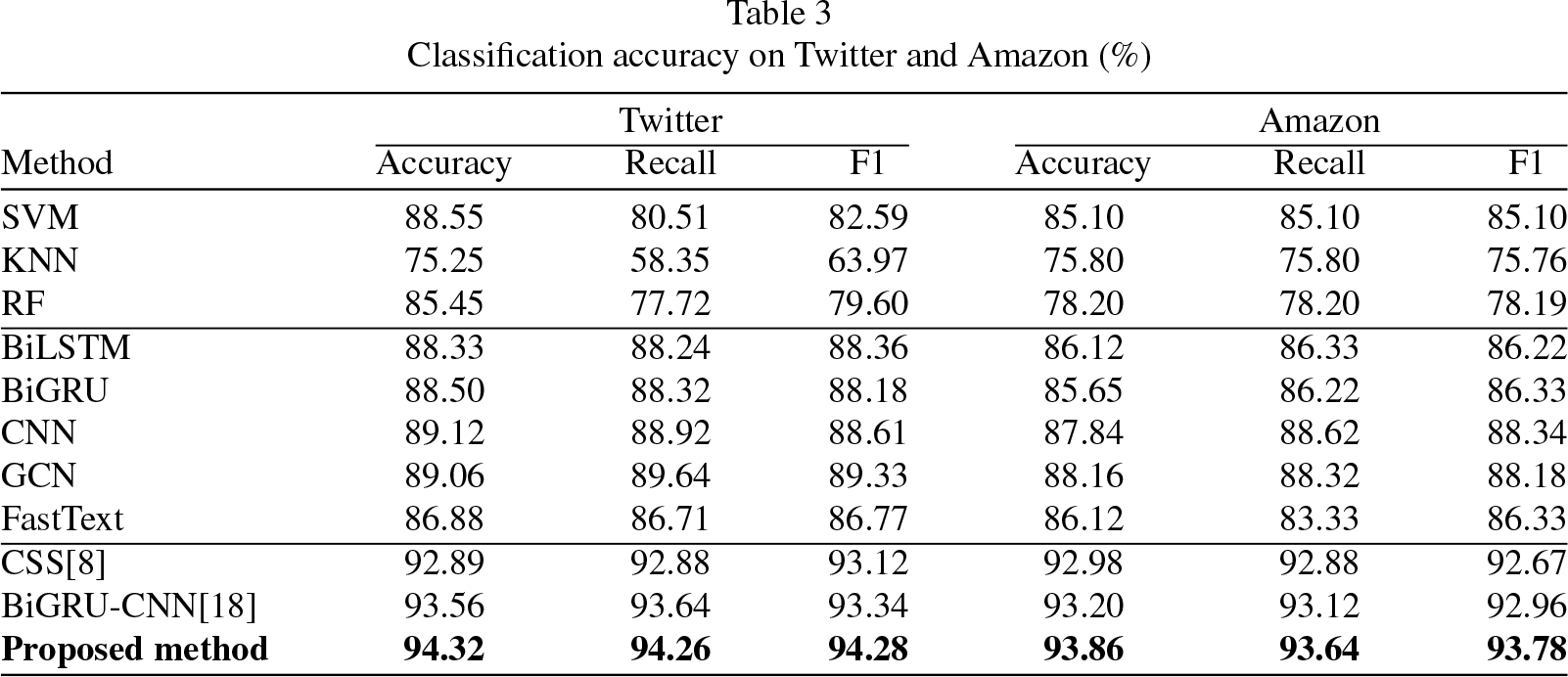
As delineated in Tables 2 and 3, the method introduced in this study has achieved superior classification performance across five distinct datasets. Within the IMDb dataset, the proposed approach realized an accuracy of 92.38%, exceeding the performance of BiGRU-CNN by 0.26% and CSS by 0.3% in terms of accuracy. In the MR dataset, the accuracy achieved by the proposed method was 79.74%, surpassing BiGRU-CNN by 1.08% and CSS by 0.54%. For the SST-2 dataset, an accuracy of 88.80% was recorded for the proposed method, outstripping BiGRU-CNN by 0.24% and CSS by 1.48%. Regarding the Twitter dataset, the proposed method’s accuracy exceeded that of BiGRU-CNN by 0.76% and CSS by 1.43%. In the Amazon dataset, the proposed approach’s accuracy was 1.66% higher than that of BiGRU-CNN and 1.88% higher than CSS. These outcomes suggest that employing RoBERTa as a language model facilitates the generation of more precise semantic text vectors, thereby outperforming static language models such as GloVe and BERT in performance metrics. Moreover, the configuration of BiGRU-DPCNN demonstrates superiority over BiGRU-CNN, indicating enhanced feature extraction capabilities afforded by DPCNN as compared to CNN. Collectively, these findings underscore the proposed method’s efficacy in sentiment analysis across both short-text and long-text contexts, affirming its preeminence in this domain. The efficacy of the proposed method is further corroborated by the results of ablation studies, illustrated in Figs. 5 through 9, where ‘MF’ and ‘Att’ denote ‘Multi-Feature’ and ‘Attention Mechanism’, respectively.
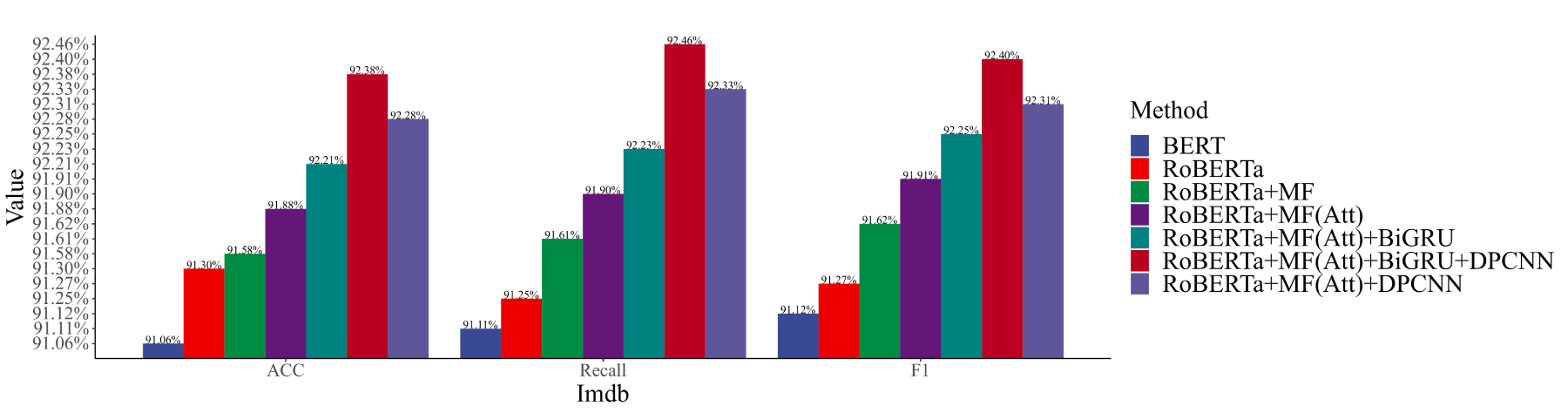
Melting experiment results on Imdb.

Melting experiment results on MR.
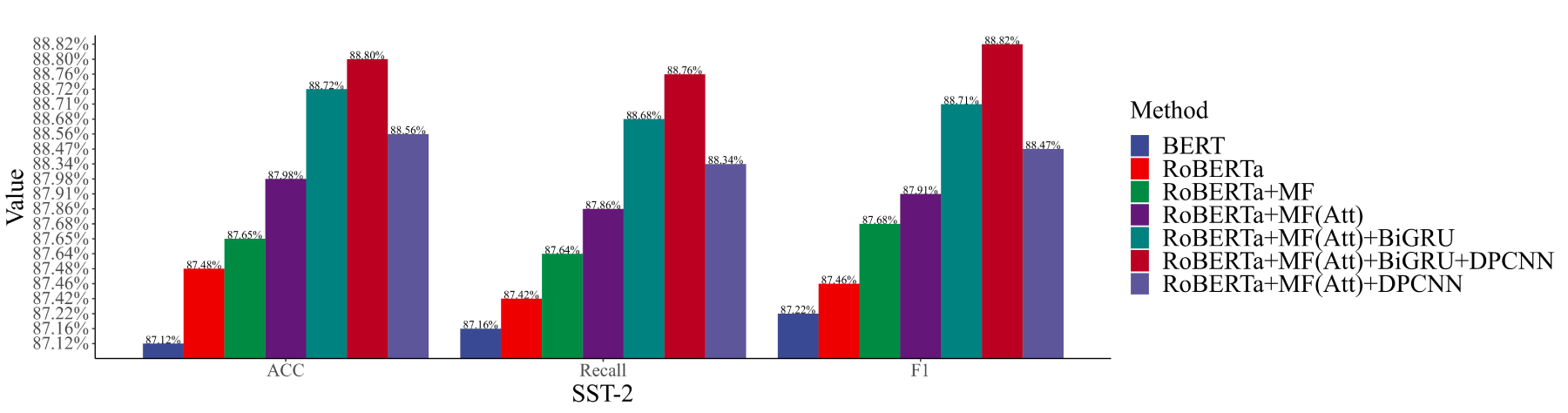
Melting experiment results on SST-2.

Melting experiment results on Twitter.

Melting experiment results on Amazon.
The results from the sentiment analysis experiments unequivocally indicate that RoBERTa surpasses BERT in classification performance across all three evaluated datasets, underscoring RoBERTa’s superior efficacy as a language model. Augmenting RoBERTa with POS information and emotion analytics yielded accuracy enhancements of 0.28%, 0.17%, 0.17%, 0.46%, and 0.43%, respectively. This enhancement evidences the premise that the integration of POS and emotional insights into the model significantly amplifies its capacity to discern the sentiment conveyed within sentences.
Further refinement of RoBERTa through the integration of an attention mechanism, referred to as RoBERTa+MF, resulted in accuracy increments of 0.3%, 0.14%, 0.33%, 0.28%, and 0.29% across the five datasets. This enhancement illustrates the pivotal role of attention mechanisms in enabling the model to concentrate on salient POS and emotional indicators. The evolution to RoBERTa+MF(Att) supplemented with a BiGRU-DPCNN architecture led to even more pronounced accuracy enhancements, registering gains of 0.5%, 0.88%, 0.82%, 0.78%, and 0.99%. Moreover, this composite approach exhibited superior performance over monolithic models such as BiGRU or DPCNN. These findings compellingly demonstrate that the dual-channel framework is adept at extracting comprehensive contextual sentiment information while simultaneously acknowledging localized cues. In conclusion, the efficacy of the proposed methodologies is conclusively validated by Figs. 5 through 9, showcasing their effectiveness in sentiment analysis tasks.
This research introduces an innovative framework for sentiment analysis that incorporates POS and emotional features, alongside a dual-channel architecture combining BiGRU and DPCNN to augment model efficacy. In this work, RoBERTa is preferred over BERT to achieve more accurate semantic representations of text. The integration of POS and emotional features facilitates a nuanced capture of emotional nuances within the text, marking a departure from conventional sentiment analysis approaches that predominantly rely on sentiment lexicons and syntactic analyses but often neglect the informative value of POS tags. The method proposed herein synergizes these elements, thereby enabling a more sophisticated understanding of both the syntactic and semantic dimensions underpinning emotions conveyed in texts. Furthermore, this approach leverages a dual-channel network structure that combines BiGRU and DPCNN, architectures that are adept at processing information at different granularities. BiGRU is renowned for its sequence modeling prowess, capably identifying long-term dependencies within text. Conversely, DPCNN is adept at delineating local features, rendering it particularly effective for discerning local patterns and sentiment expressions. The amalgamation of these dual channels equips the model with the capability to undertake a thorough analysis of text, significantly enhancing sentiment analysis performance. Through empirical studies conducted on datasets such as IMDb, MR, SST-2, Twitter, and Amazon, this paper substantiates the superior performance of the proposed methodology over conventional sentiment analysis models. In sum, this investigation not only advances model performance through the integration of POS and emotional features coupled with a dual-channel network but also sets a precedent for future research and development in textual sentiment analysis, underlining its potential to improve both the precision and the practical applicability of sentiment analysis tools.
Conflict of interest
The authors declare no competing interests.
Footnotes
Acknowledgments
This work was supported in part by the Liaoning Natural Science Foundation Program Grant 2019-MS-036; In part by the Liaoning Provincial Science and Technology Department under Grant 1655706734383; And in part by the Basic Scientific Research Projects of Colleges and Universities of Liaoning Provincial Department of Education under Grant LJKMZ20220826.