
Abstract
Cylinder liner is an internal part of the automobile engine, which plays an important role in the automobile internal combustion engine. Therefore, it is a top priority to accurately and quickly detect the cylinder liner surface defects. In order to effectively achieve the classification and localization of surface defects on the cylinder liner, this paper establishes a dataset for surface defects on cylinder liner and proposes a based on improved YOLOv5 algorithm for detecting surface defects on cylinder liner. Firstly, a machine vision system is established to acquire on-site images and perform manual annotation to build the dataset of surface defects on cylinder liner. Secondly, the GSConv SlimNeck mechanism is introduced to reduce the model complexity; the Bi-directional Feature Pyramid Network (BiFPN) is used to fuse the feature information at different scales to enhance the detection accuracy of small surface defects on cylinder liner; and embedding the SimAM attention mechanism to focus on the object region of interest and improve the accuracy and robustness of the model. The final improved YOLOv5 model reduces the number of model parameters by 15.8% compared to the non-improved YOLOv5. And the experimental results on our self-built dataset for cylinder liner defects show that the mAP0.5 is improved by 0.4%. This means that the accuracy of model detection was not compromised. This method can be applied to actual production processes.
Introduction
As a key component of an internal combustion engine, a defective cylinder liner surface can cause engine safety problems [1] thereby jeopardizing human safety. Therefore, in the manufacturing process of cylinder liner, its production quality should be strictly controlled. However, at present, the detection of cylinder liner surface defects still mainly relies on human eye observation [2]. Manual inspection methods are very susceptible to subjective emotions, fatigue, and other factors that affect detection efficiency. Moreover, some product defects are very small and of different shapes, which are difficult to be observed by the naked eye. Therefore, it is necessary to find a suitable detection method to meet the surface defect detection of cylinder liner.
Non-destructive testing (NDT) methods are an alternative approach to modern industrial inspections. Traditional NDT techniques primarily include X-ray inspection [3], eddy current testing [4], and magnetic particle testing. However, NDT methods are costly, require strict testing environments, and can potentially pose risks to human health. In the past two decades, the rapid advancement of image detection algorithms has driven the development of surface defect detection technology. Compared with manual detection, machine vision-based detection technology not only improves the efficiency and accuracy of detection, but also has the advantages of safety and reliability due to its non-contact nature. For example, at North University, the team led by Bai Ge has made advancements in the field of X-ray imaging systems by incorporating traditional image processing techniques. They perform image segmentation and classification, followed by preprocessing of the images. This enables accurate detection of defects and facilitates rapid classification of defect types [5]. However, traditional machine vision detection algorithms are less flexible in feature extraction and need to construct feature extraction algorithms based on the type of product surface defects. Due to the different shapes and sizes of defects on the surface of industrial products, feature extraction using image algorithms requires a lot of resources for algorithm design, which suggests that it is less generalizable to the object.
With the booming development of neural networks and their penetration into the field of object detection, many deep learning-based object detection algorithms have been born, which can be categorized into one-stage object detection algorithms [6] and two-stage object detection algorithms [7] based on the presence or absence of a separate step to acquire candidate boxes. In the 2014 CVPR conference, Girshick et al. first proposed the R-CNN two-stage object detection algorithm model [8]. Since then, a large number of scholar concerned in the field of object detection have proposed two-stage object detection models, such as SPPNet [9], Fast R-CNN [10], Faster R-CNN [11], Mask R-CNN [12], Cascade R-CNN [13] et al.
Although the detection accuracy of the two-stage object detection model has been greatly improved, its model is complex, with too many model parameters and too long training time. For this reason, Redmon et al. proposed the YOLOv1 algorithm [14]. Since YOLOv1 was proposed, many scholars have conducted a lot of research on object detection algorithms in this field, and some classical single-stage object detection algorithms have appeared, such as YOLOv2 [15], SSD [16], YOLOv3 [17], YOLOv4 [18], etc. Among them, the YOLO series is the main representative algorithm.
Deep learning-based cylinder liner surface defect detection algorithms have higher accuracy compared to traditional visual detection methods. And it will also have relatively stable detection results in the detection environment of complex scenes. Liu Qian et al. from Nanjing University of Technology proposed a transformer method with block division and masking mechanism to automatically detect defects on a newly collected cylinder liner defect database [19]. Gao Chengchong et al. from Nanjing University of Engineering studied a deep learning-based defect detection method for cylinder liner, in order to improve the accuracy of machine vision defect detection. The results show that the detection accuracies of this method for sand, scratch and wear defects are 77.5%, 70% and 66.3%, respectively, which is at least 26.3% higher compared with the traditional method [2]. Chen Yongbin et al. from Guangdong University of Technology proposed a surface defect detection algorithm based on the improved YOLOv4, and the experimental results show that the method can not only improve the detection accuracy and speed to meet the requirements of non-burr cylinder liner defect detection, but also can be extended to other application areas of surface defect detection [1].
The deep learning-based methods described above are mainly based on deep neural network models, however, powerful database resources can support deep learning detection algorithms better than deep neural network models. However, the sample size for surface defect detection in industrial field is often not enough to support the complex deep neural network model. Therefore, how to reduce the complexity of the neural network model with a smaller sample size, making the dataset sample size more compatible with the lightweight inspection model without affecting the accuracy of the model detection or even improving the model detection accuracy is the focus of this paper. Previous lightweight work, such as Xception [20], MobileNets [21–23], and ShuffleNets [24, 25], has greatly improved the speed of the detector through DSC operations, but the low accuracy of these models is a concern. [26], a new lightweight convolutional technique, GSConv, is introduced to lighten the model while maintaining accuracy.
Inspired by [26], this paper proposes a cylinder liner surface defect detection algorithm based on improved YOLOv5, which seeks to improve the detection accuracy while reducing the model complexity. The specific contributions of this paper are as follows:
In order to effectively detect defects on the surface of cylinder liner in the actual production environment, a cylinder liner surface defect dataset is established in this paper. Based on this dataset, this paper improves the basic YOLOv5 network architecture and introduces GSConvSlimNeck, BiFPN and SimAM attention mechanism.
The improvement modules are: to reduce the model complexity and save computational resources, GSConv SlimNeck is introduced; to improve the detection accuracy, BiFPN is added, which not only accelerates the training speed but also is more suitable for detecting small-target defects on the surface of the cylinder liner; and in order to help the model pay better attention to the target region of interest and to improve the model’s accuracy and robustness, the SimAM attention mechanism is introduced.
The final result of the experiment was a 15.8% reduction in the number of model parameters and a 0.4% improvement in mAP0.5. This shows that the complexity of the improved model was reduced and the accuracy of the detection was not affected, and the method can be applied to real production processes.
The rest of this paper is structured as follows: Section 2 introduces the algorithmic architecture of YOLOv5, and gives the theoretical principles of the three improvement strategies based on YOLOv5, as well as the improved YOLOv5 algorithmic architecture. Section 3 and 4 build the experimental platform, obtain the cylinder set surface defect dataset and enhance the dataset, do a comprehensive comparison experiment on the improved YOLOv5 algorithm and analyze the experimental results. Finally, a summary is made and an outlook is presented.
YOLOv5 and improvements
YOLOv5 algorithm
The network structure of YOLOv5 consists of four parts: input, BackBone, Neck and output, including ConvBNSiLU block, C3 bottleneck module and SPP, which is shown in Fig. 1.
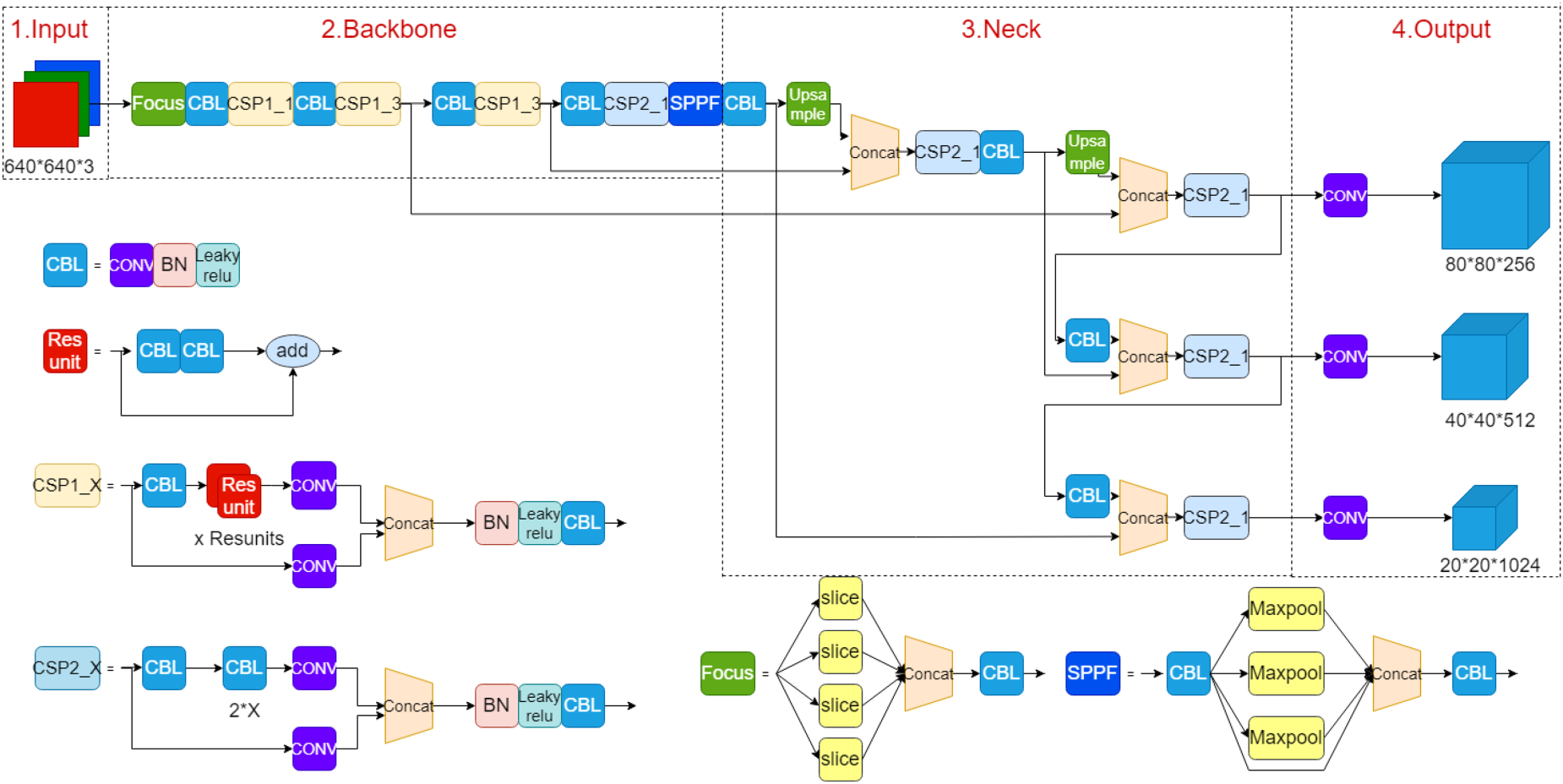
YOLOv5 structure.
YOLOv5 input data utilizes adaptive image scaling and mosaic data enhancement techniques. The method enriches the training dataset by splicing four images with random scaling, random cropping and random alignment. Finally, the mosaic-integrated images are rotated, panned, flipped, and colorimetrically adjusted.
Backbone
The backbone network consists of ConvBNSiLU module, the C3BottleNeck1_X module and the SPPF module. The residual structure added in BottleNeck1 module effectively improves the gradient vanishing problem caused by network deepening. SPPF module contains three different sizes of maximal pooling layers, which can convert feature images of arbitrary size into fixed-size feature vectors, and realize the fusion of multi-scale local features and global features.
Neck
Neck is a feature fusion network that employs both top-down and bottom-up feature fusion methods. The bottom-up path better conveys localization information from the bottom to the top; the top-down path fuses high-level and low-level features to improve detection of small objects. Combining these two paths can further improve the detection performance of dense objects by aggregating features from different detection layers and different backbone layers.
Output
YOLOv5 algorithm for Head uses three YOLO head classifiers to detect large, medium and small scale feature images. The prediction results contain the prediction class, confidence level, and prediction position for each prediction box. Therefore, when constructing the loss function, it is necessary to calculate the loss for each of the three predicted outcomes. This can be described in mathematical language as:
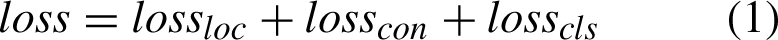
The YOLO series algorithms can classify and localize objects with high real-time performance [27]. However, the complex working environment may lead to low detection accuracy. In order to develop a lightweight and high-accuracy cylinder liner defect detection algorithm, this paper improves the YOLOv5 algorithm in terms of GSConv+SlimNeck lightweight network, BiFPN improved feature fusion, and addition of SimAM attention mechanism.
GSConv+SlimNeck
The design of lightweight networks can effectively reduce the high computational cost. The goal of lightweighting is mainly achieved by the deep separable convolution (DSC) operation, which is shown in Fig. 2. It is partly a deep convolution on a single channel input and partly a pointwise regular convolution with a kernel size of 1×1.

In the given image part (a) represents the SC structure, part (b) is the DSC structure.
However, DSC separates the channel information of the input image. A new method, GSConv, is introduced. The hybrid convolution of SCDSC and shuffle [24] is called GSConv, Fig. 3 shows the structural principle of GSConv. GSConv can reduce computational costs, but it can’t do so while maintaining accuracy and shortening computation time, which requires other models to accomplish.

Structure of GSConv.
The “Conv” box consists of three layers: a convolutional layer, a batch normalization layer, and an activation layer. The blue mark “DWConv” here refers to the DSC operation. The time complexit of SC, DS and GSConv is:
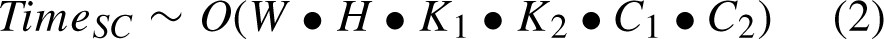
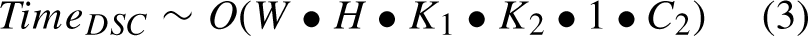
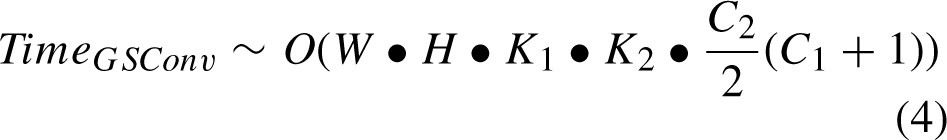
But if GSConv is used in all phases of the model [26], then the network layers of the model are much deeper. And by the time these feature maps reach the neck, they have reached their maximum channel size and minimum width and height dimensions. Therefore, a better option would be to use GSConv only at the neck.
The GS bottleneck is built on top of GSConv and the structure of the GS bottleneck module is shown in Fig. 4(a). Then, the one-time aggregation method was used to design the cross-layer localized network (GSCSP) module VoVGSCSP. The VoVGSCSP module reduces the complexity of the computational and network structure, but maintains sufficient accuracy.

In the given image part (a) represents the GS bottleneck structure, part (b) is the VoVGSCSP structure.
BiFPN is an improved version of the FPN network structure that is weighted and bi-directionally connected [28]. That is, cross-scale connectivity is realized by constructing bi-directional channels through top-down and bottom-up, which retains the shallower semantic information without losing too much of the deeper semantic information.
The fast normalized fusion in the BiFPN structure is proposed for the slow training speed and weight scaling to the 0∼1 range, the BiFPN structure is shown in Fig. 5.
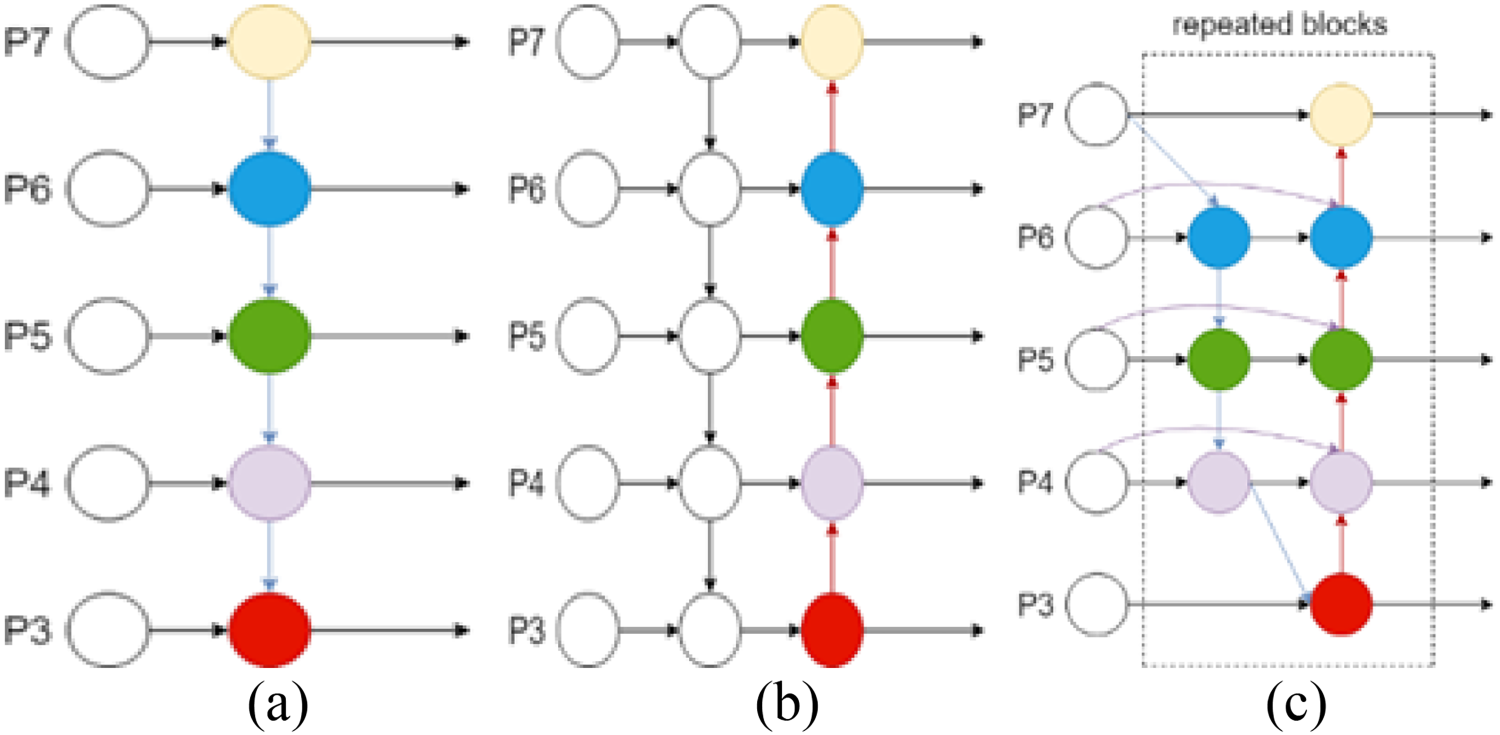
In the given image part (a) represents the FPN structure, part (b) is the PANet structure, part (c) is the BiFPN structure.
P3-P4 are downsampled from the input image with a resolution of 1/2i times of the input image in that order, and finally the formula for feature fusion is:
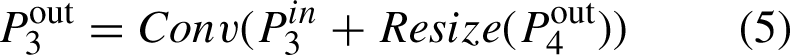

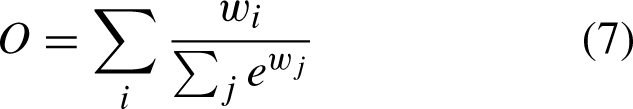
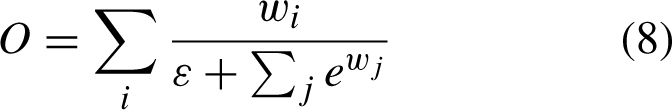
Weighting is to add a learnable weight, that is Equation (6), but if the range is not restricted, it is easy to lead to unstable training, so softmax is used for each weight, that is, Equation (7) but this is too slow, so a fast restriction method is proposed: Equation (8). In order to ensure that the weight is greater than 0, weight before the use of Relu function, Resize operation is usually upsampling. This completes the feature fusion capability of the Enhanced Neck module [29].
Attention modules are now widely used in deep learning to enhance feature extraction. Most existing attention modules typically extract feature maps based on channel and spatial dimensions, but this is challenging. In addition, some attention modules rely on hyperparameters and require extensive knowledge from experts to ensure performance. In contrast, this study employs a parameter-free SimAM model with 3D attention weights, as shown in Fig. 6. In this paper, SimAM is embedded into the improved YOLOv5 model proposed in this paper to improve the performance of detection [29]. SimAM is derived from neuroscience theory and extracts the basic features based on the energy function. The energy function of each neuron is as follows: SimAM attention module.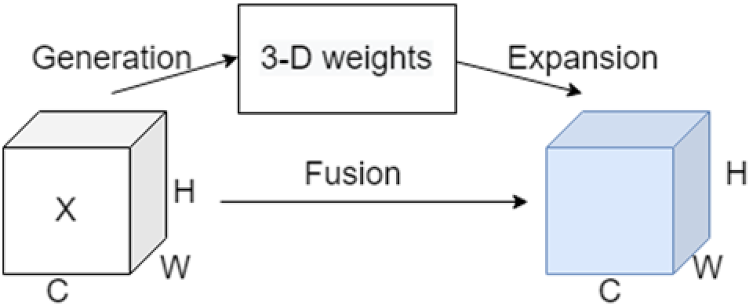
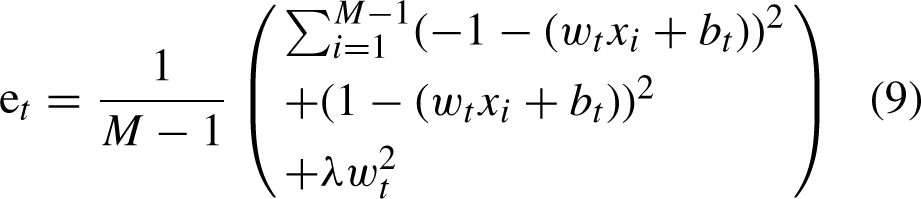
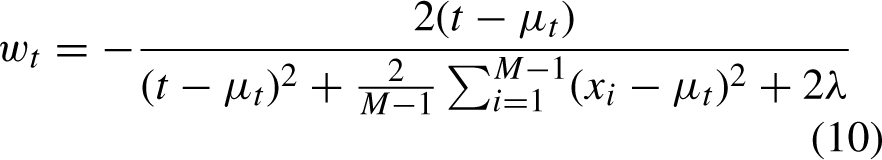




Assuming that all pixels have the same distribution and each neuron has a weight of

In summary, the overall structural design of the simplified YOLOv5 model before and after improvement is shown in Fig. 7.
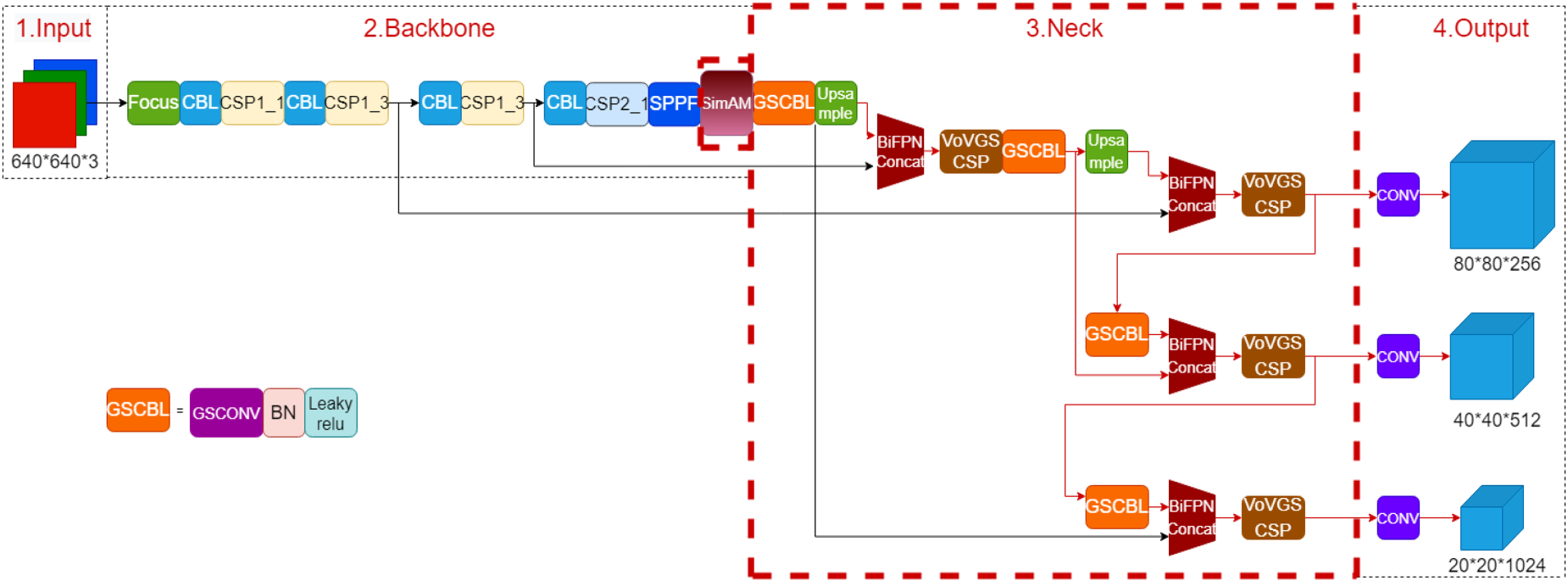
Improved YOLOv5 structure.
Experimental platforms
This paper builds a machine vision experiment platform for cylinder liner surface defect detection, the specific computer hardware configuration and software installation as shown in Table 1.
Hardware and software information
Hardware and software information
According to the size of the algorithm, YOLOv5 is divided into four versions, YOLOv5n, YOLOv5s, YOLOv5m, and YOLOv5l, which increase the width and depth of the model in turn. The experiments and analyses in this paper use the relatively lightweight YOLOv5s.
Build a machine vision platform
As shown in Fig. 8, the cylinder liner defect detection machine vision system consists of a fixture on a rotating platform to control the cylinder liner, as well as a face array camera and a line array camera. The No. 1 surface array camera is used to shoot the end face image, and the No. 2 line array camera is used to rotate the cylinder liner to shoot the image of the outer wall first, and then the robotic arm is used to extend the light source and the camera into the inside of the cylinder liner at the same time and then rotate the cylinder liner to shoot the image of the inner wall.
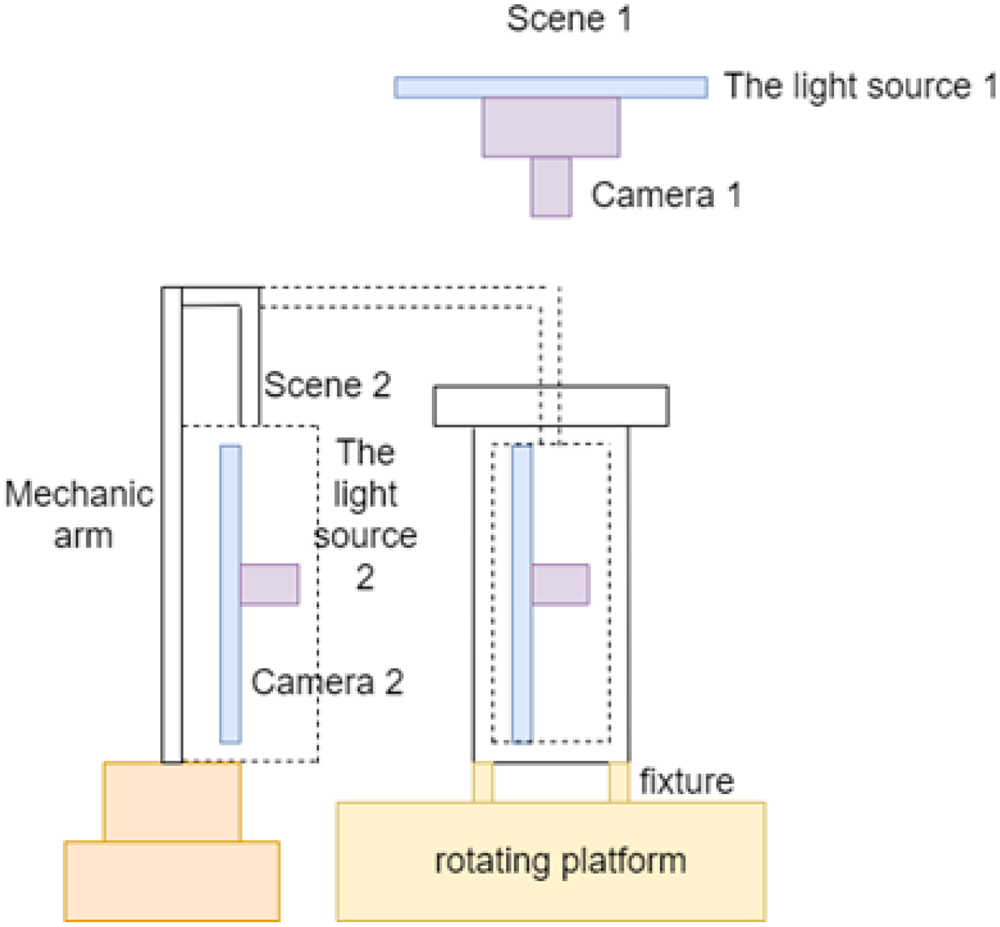
Machine vision platform.
Using the above machine vision system, images of the end face, outer wall and inner wall of the cylinder liner are captured as shown in Fig. 9.

(a), (b) and (c) represent, respectively cylinder liner end faces, outer and inner walls.
For the detection model, the larger the dataset the more accurate training results will be obtained accordingly. In order to further extend the cylinder liner dataset, some image transformations such as panning, mirror flipping and adding noise in the image to the original dataset are required to enhance the robustness of the model.
The translation transformation of an image is to add all the pixel coordinates of the image with specified horizontal and vertical offsets respectively. Assuming that the original pixel’s position coordinates are (x0, y0), after the translation amount (vartrianglex, vartriangley), the coordinates change to(x1,y1), as shown in Fig. 10(b): Cylinder liner image data augmentation Comparison of results. In the given image part (a) represents the original figure, part (b) is the result of upward shift, part (c) represents the result of mirroring, part (d) is the pre-noise image, part (e) is the result of post-noise.
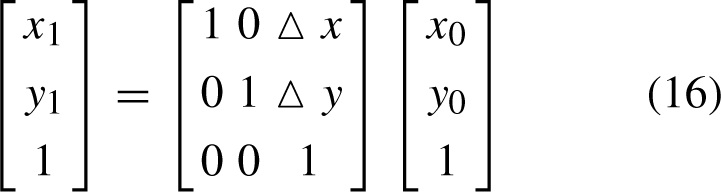
Mirror Flip, also known as Mirror Image, is generally categorized as Horizontal Mirror Image and Vertical Mirror Image. They both take the central axis of the image as the center of transformation. The mathematical formula for horizontal mirroring is as follows:
Think of an image as a signal, then the noise is the interfering signal. We can think of an image as a function, then an image with noise can be thought of as the sum of the original image function and the noise function added together.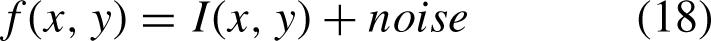
To add salt noise to an image, the intensity values of the pixels in the image are changed to black or white, where the black points have an intensity value of 0 and the white points have an intensity value of 255. The intensity value of the original image is in the interval [0, 255], so the corresponding points in the noise function are 255 or -255, and the two are added together as 0 or 255. Pretzel noise is a method that randomly changes the values of the pixels in the image to black or white, and the result after adding noise is shown in Fig. 10(e).
In the object detection project, in the face of high-resolution, small object image data, if the image is directly resized to the appropriate size of the model, a large amount of information will be lost, and the model can not learn the information. Therefore, large resolution images need to be processed, and common technical methods include: sliding window [30], randomized center point cuts.
In this paper, we use the sliding window method to set a window of specified size to slide the shear high-resolution image. Since clipping may cause the image to be segmented, the overlap rate can be set so that there is an overlap between neighboring clipped subgraphs, which can better solve the case of the object being segmented. However, there may still exist subgraph object boxes with incomplete cuts, and a specified IOU value is set so that the subgraph object box information is retained only when the IOU value between the new object box and the original object box is greater than a certain value, and removed if it is less than. Table 2 shows the resolution size before and after cutting the image using a sliding window, which excises unnecessary parts of the image and greatly improves the training speed.
Memory size before and after image cutting
As shown in Fig. 11, the common surface defects of cylinder liner are sand defects, scratch defects, wear defects and pit defects.

Common types of cylinder liner defects. (a) is sand defect, (b) is scratch defect, (c) is wear defect and (d) is pit defect.
Sand defect is one of the main defects of the cylinder liner, which will reduce the impact resistance and fatigue resistance of the cylinder liner, and easily cause collapse, leakage and other failures. Sand defects may occur in any part of the cylinder liner.
Scratch defects are in the processing or transmission process, impurities and cylinder liner friction produced by an uneven strip groove defect. Scratch defects are often found on the inner and outer walls of the cylinder liner, which reduces the wear resistance and mechanical properties of the cylinder liner.
Cylinder liners often have wear defects on their end faces, and such defects reduce the sealing and wear resistance of the cylinder liner, which can lead to a decrease in engine power.
The surface of the cylinder liner has patches of uneven roughness, localized or continuous occurrence of pits (pitting) defects. It is caused by uneven hardness or long service time.
Data and environment
The adaptive image scaling size was set to 640×640 pixels, and a total of 546 defective images obtained were divided between the training set and the test set in the ratio of 7:3. After creating the training set, yolov5s.pt is utilized to train the weights and configure the yaml file. Log files and weight files are saved during the training process. The specific parameter configuration is shown in Table 3.
Modle training hyperameters
Modle training hyperameters
The measures of the detection model chosen in this study are the number of model parameters, FPS and mAP0.5. Among them, the number of parameters can measure the size of the model computation in the spatial dimension, the FPS is used to measure the speed of the model computation, and mAP0.5 can reflect the accuracy of the model recognition. The mAP0.5 represents the average AP when the IOU threshold is 0.5, and the AP is the area under the P-R curve. The average value of each class of APs can be used to evaluate the detection accuracy of the model in a multi-class object detection task by calculating the mAP as follows: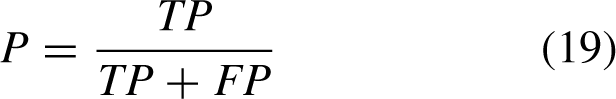
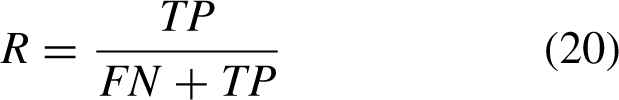
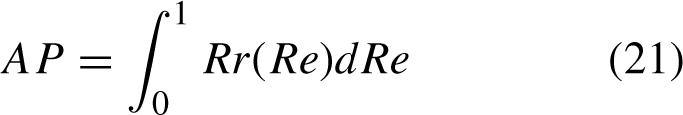
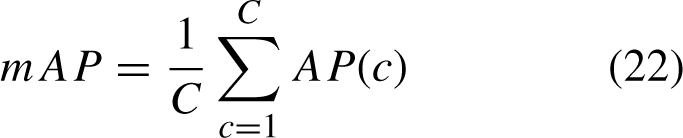
As shown in Table 4, the results of the cylinder liner surface defect dataset under four different YOLO algorithms are shown. It can be seen that the results trained by YOLOv5s model have 1 or even 2 million parameters less than YOLOv3 and YOLOv3-tiny model in terms of the number of parameters, which makes the model simpler and reduces a large number of parameters, and the mAP0.5 is higher than that of YOLOv5s model by 11 or even 15 percentage points, which makes the model lighter and at the same time has higher detection accuracy, which is a very rare point. The model is lighter and at the same time more accurate, which is very rare. Although the detection speed of YOLOv8 is faster, its model is huge and needs a larger dataset to show good performance, which is slightly inferior to YOLOv5s algorithm in terms of detection accuracy. YOLOv5s, on the other hand, has a smaller model and requires less computational resources to deploy and run, but achieves similar or better detection performance. After comprehensive analysis, YOLOv5s algorithm can be used as the basic algorithm for detecting surface defects dataset of cylinder liners in this paper.
Comparison of results of baseline methods on the cylinder liner dataset
Comparison of results of baseline methods on the cylinder liner dataset
To further reduce the model, MobileNet [21], ShuffleNet [24], GhostNet [31] and the GSConv+SlimNeck method of this paper are selected to realize the lightweighting of the model, and the specific results are shown in Table 5. From the table, it is easy to see that although embedding ShuffleNet can greatly reduce the number of parameters of the model, the detection accuracy can hardly be guaranteed; while the detection accuracy of embedding MobileNet is also worrying; although the effect of embedding GhostNet is better than the former two, the actual application of the detection of the industrial field is still centered on the accurate detection, and we cannot pursue the lightweight network model and lose the most basic detection accuracy. The GSConv+SlimNeck method chosen in this paper is the optimal choice because it is closest to the detection accuracy of the original YOLOv5 without embedding the lightweight model and reduces the model complexity.
Comparison of different lightweight network ablation experiments
Although the method of embedding GSConv+SlimNeck is closest to the detection accuracy of the original YOLOv5, it still reduces the detection accuracy of the model, which is not a desirable result. On this basis, BiFPN multi-scale feature fusion was introduced for model optimization, and after increasing the mAP0.5 to 75.3, the attention mechanism was added to better apply to the lighter YOLOv5 model. Table 6 analyzes and compares the four attention mechanisms. Embedding the ECA attention mechanism reduces the mAP0.5 of the model; embedding the CBAM and SE attention mechanisms not only reduces the mAP0.5 of the model but also increases the model complexity. In the end, this paper chooses the SimAM attention mechanism with a small number of parameters and high mAP0.5.
Ablation test results for the attention module
Table 7 evaluates the performance of the proposed improved YOLOv5 cylinder liner surface defect detection algorithm through comprehensive ablation experiments. In order to reduce the model and save computational resources, the introduction of GSConv SlimNeck reduces the parameters of the model by 1.1 million, but the mAP0.5 of the model is reduced by 2.8%. Therefore, in order to improve the detection accuracy of the model, BiFPN is added as a bidirectional feature fusion mechanism, which can both speed up the training speed and apply to the small target detection problem of surface defects on cylinder liner in this paper. After the introduction of BiFPN, the mAP0.5 of the model is improved by 2.1%, which meets the expectation of improvement. In order to further improve the detection accuracy of the model, this paper chooses to introduce the SimAM attention mechanism to help the model better focus on the target region of interest and improve the accuracy and robustness of the model. After the introduction of the SimAM attention mechanism, the mAP0.5 of the model is improved by 1.1%, and no new parameters are introduced. Overall, the improved YOLOv5 algorithm in this paper improves the mAP0.5 by 0.4% over the basic YOLOv5 algorithm and reduces the number of parameters by 15.8%, which makes the lightweight model and higher detection accuracy more suitable for industrial environments in the field where GPUs are not available, and the improvement effect is good enough to be applicable to the real production life.
Ablation test results for the cylinder liner dataset
Table 8 shows the overall comparison between the improved YOLOv5 and other algorithms. In addition to the comparison with the basic YOLO series algorithms, this paper also compares the current mainstream Transformer framework in the field of object detection. Two algorithms, YOLOv8 detection head plus Transformer framework and Mask R-CNN detection head plus Transformer framework, are used. The results show that the accuracy of the improved YOLOv5 algorithm is 11.6% higher than that of YOLOv3. Although the detection speed of the improved YOLOv5 algorithm is slightly lower than that of YOLOv8, its accuracy is higher. Moreover, the model of YOLOv8 is more complex, which does not meet the detection target of lightweight in this paper. However, Transformer framework has higher architectural complexity, higher requirements on computing resources, and lower detection accuracy than the improved YOLOv5 algorithm. In addition, due to the large number of model parameters and computationally intensive, training and reasoning the Transformer model requires a large amount of computing power and memory, which may bring certain challenges to deployment and practical application. Therefore, the improved YOLOv5 algorithm model is more suitable for the cylinder liner industrial inspection site, and more suitable for the site without GPU inspection environment. The lightweight and high detection accuracy of the model are more suitable for the actual production process.
Comparison of results of methods on the cylinder liner dataset
The following is a comparison of the results predicted by the algorithm based on YOLOv5 before and after improvement after training on the cylinder liner surface defect dataset.
As can be seen in Fig. 12, the improved YOLOv5 algorithm improves the accuracy of the overall inspection results and reduces the misdiagnosis rate. The basic YOLOv5 algorithm recognizes sand defects that are not marked, while the improved YOLOv5 algorithm does not misclassify unmarked images as sand defects, which indicates that the improved YOLOv5 algorithm improves the accuracy of detection and reduces the misclassification rate of the model, which is in line with the expected improvement goal. It can also be seen that the improved YOLOv5 algorithm also has a higher recognition accuracy for scratch defects and pit defects than before the improvement. Therefore, the improved YOLOv5 algorithm can recognize the surface defects of cylinder liner collected in the field more efficiently, and it is an effective improved algorithm that can be put into practical application scenarios.

Comparison of detection results. (a) is pre-improvement, (b) is post-improvement.
As can be seen from the confusion matrix results before and after the improvement of YOLOv5 in Fig. 13, the improved YOLOv5 algorithm improves the overall prediction accuracy. For sand defects, the detection accuracy improves from 0.78 to 0.80 without being misdiagnosed as pit defects, and the probability of a sand defect being judged as a background defect decreases from 0.21 to 0.20. For pit defects, the prediction accuracy improves from 0.37 to 0.47, and at the same time, the probability of a pit defect being judged as a background defect decreases from 0.63 to 0.53. Overall, the improved YOLOv5 algorithm improves the detection accuracy of the four surface defects of the cylinder liner and reduces the misjudgment rate of determining the target defects as background defects, which is an effective improvement method.
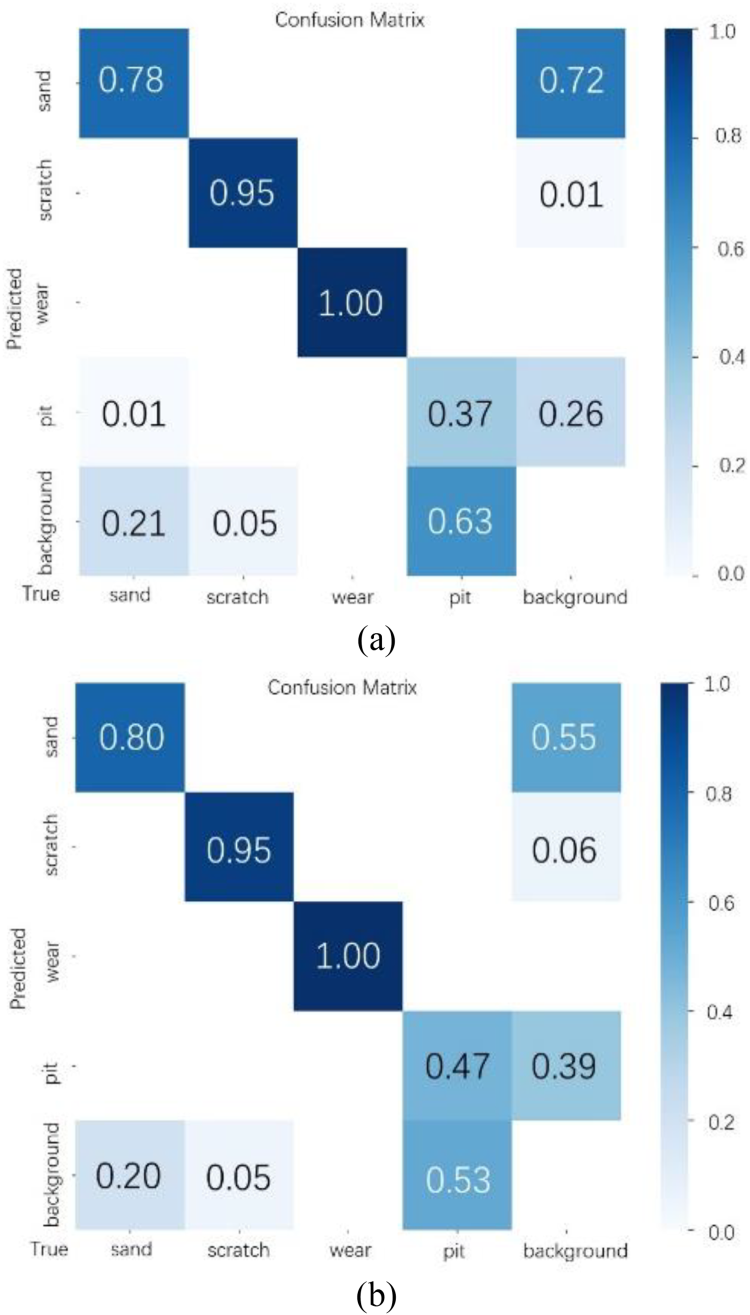
Comparison of confusion matrix results. (a) is pre-improvement, (b) is post-improvement.
In this paper, large-scale cylinder liner images captured by line array industry are obtained from a cylinder liner production plant in the field, and a sliding window method is used to crop the 78.4M image into a 62KB 640×640 small image with cylinder liner defects to make a small cylinder liner dataset for network training of YOLOv5. In terms of reducing the number of model parameters, the selected GSConv SlimNeck is 45.4%, 36.1% and 10.4% higher than the mAP0.5 of ShuffleNet, MobileNet, and GhostNet, respectively; the introduction of BiFPN bidirectional feature fusion improves the mAP0.5 of the model by 2.1%; and on the basis of this, embedding SimAM into the improved YOLOv5 network proposed in this paper improves the overall detection performance and ultimately reduces the amount of parameters of the model by 15.8% and improves the mAP0.5 value by 0.4% on this basis.
Future additions and improvements can continue to be made in the following areas: Contacts with cylinder liner manufacturers should be strengthened to expand the production of cylinder liner defect datasets; small datasets alone are still not enough; The number of pit defects in the dataset is too low, which has a significant impact on the accuracy of the whole model, and some defect images of pit defect types should be added; Consider other ways to reduce the number of parameters to make the network more lightweight, as well as consider whether reducing the number of parameters in the model has an impact on detection effectiveness; Only 0.4% improvement in mAP0.5 value is not optimistic, less pit defects will reduce the detection effect of the whole model is one aspect, at the same time can be tried again for other cylinder liner defect detection methods, improve the network, get higher and faster detection model.
Footnotes
Acknowledgements
This work was supported in part by the National Key Technologies R & D Program of Henan Province under Grant 232102221028, the Key Scientific Re-search Projects of Colleges and Universities in Henan Province under Grant 22A460020, the Startup Foundation for Ph.D. of Henan Polytechnic University under Grant B2016-22, and the Henan International Joint Laboratory of Advanced Electronic Packaging Materials Precision Forming.