
Abstract
Facial Emotion Recognition (FER) is a powerful tool for gaining insights into human behaviour and well-being by precisely quantifying a wide range of emotions especially stress, through the analysis of facial images. Detecting stress using FER entails meticulously examining subtle facial cues, such as changes in eye movements, brow furrowing, lip tightening, and muscle contractions. To assure effectiveness and real-time processing, FER approaches based on deep learning and artificial intelligence (AI) techniques was created using edge modules. This research introduces a novel approach for identifying stress, leveraging the Conv-XGBoost Algorithm to analyse facial emotions. The proposed model sustain rigorous evaluation techniques, for employing key metrics examination such as the F1 score, validation accuracy, precision, and recall rate to assess its real-world reliability and robustness. This comprehensive analysis and validation proved the model’s practical utility in facial analysis. Integrating the Conv-XGBoost Algorithm with facial emotion analysis represents a promising and highly accurate solution for efficient stress detection. The method surpasses existing literature and demonstrate significant potential for practical applications based on well-validated data.
Introduction
Facial expressions are powerful form of non-verbal communication. Expressions can often convey emotions and feelings more effectively than words. When stressed, their facial expressions can provide immediate insight into their emotional state, even if they choose not to express it verbally. Many facial expressions associated with stress, such as furrowed brows, tensed jaw, or a pained expression, are recognized as universal signs of distress. This universality makes them valuable indicators in stress detection, regardless of cultural or language differences. Stress detection using Facial Expression Recognition (FER) is one of the various stress detection methods. Physiological and psychological parameters can detect stress. The psychological state of a human is gauged by emotions, which could be positive and negative. Positive emotions help individuals stay focused and achieve their goals, while negative emotions create stress and lead to psycho-physiological disorders. There are seven basic emotions which can be identified by facial expression, namely happiness, sadness, surprise, anger, disgust, fear, and neural [1]. Facial expressions are integral in stress, psychology and mental health research. The possibility of using FER in mental health can be carefully applied in clinical settings to diagnose and assess anxiety disorders, post-traumatic stress disorder (PTSD), and depression.
Advances in machine learning and artificial intelligence have made it possible to develop systems that can automatically detect and analyze facial expressions to assess stress levels. Recently, deep learning has been the subject of substantial research to enhance face expression detection systems performance [2, 3]. Deep learning tools have proven highly effective in emotion detection from various data sources, including text, speech, and images. Hugging Face Transformers, OpenSMILE, OpenCV, TensorFlow, DeepFace, and NVIDIA Deep Learning AI are a few Deep Learning tools used in emotion detection [4]. Convolutional Neural Network (CNN) is a class of deep neural networks designed for tasks involving images and visual data. Convolutional Neural Networks (CNNs) have evolved, leading to various architectures designed for different tasks. The most potent CNN models are DeepLab, YOLO, SqueezeNet, Xception, and ResNet [5], and ideas for improving the CNN model are being developed to add additional convolution calculations and increase network depth.
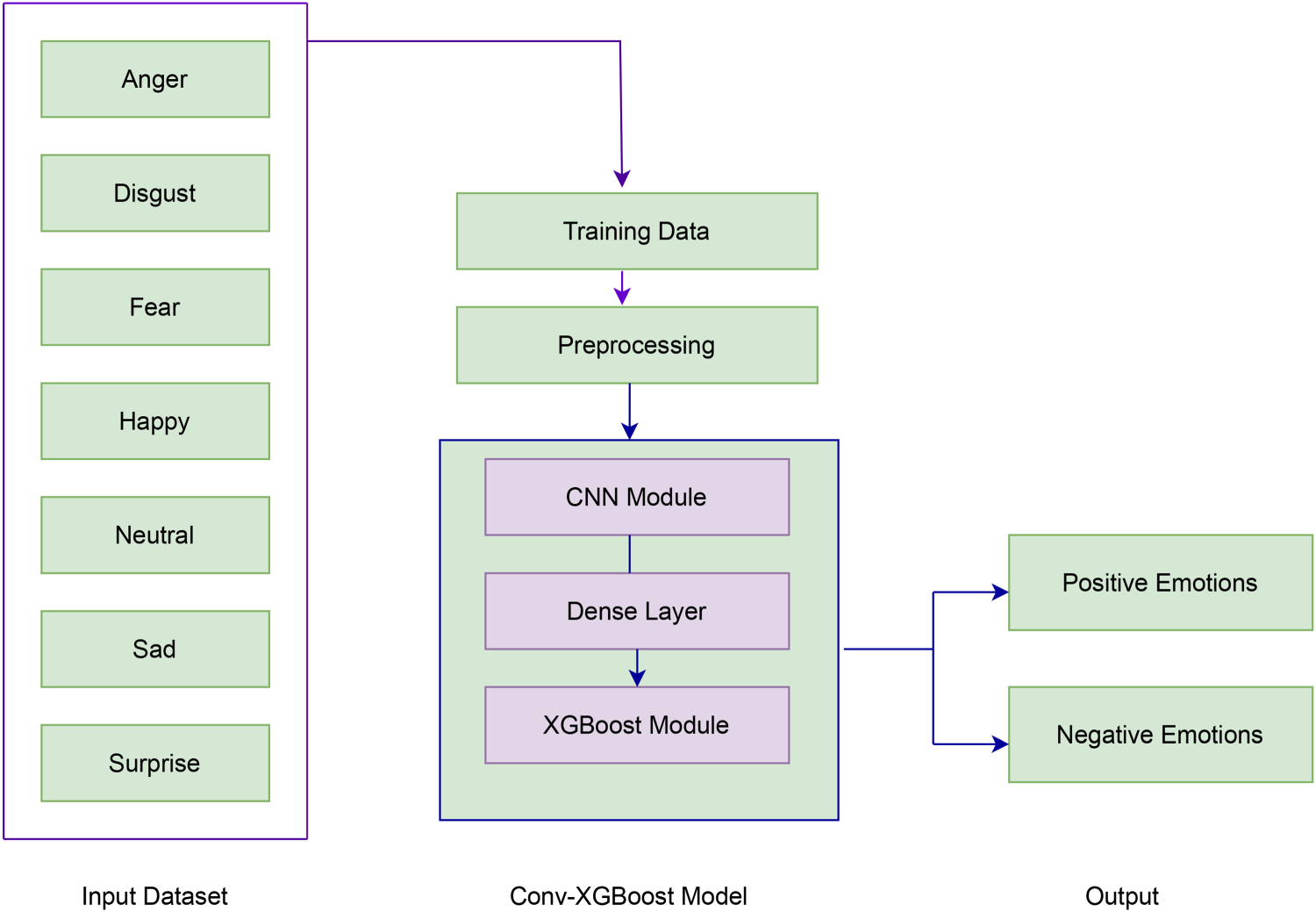
According to the survey conducted in India during Fit Report 22–23, titled Game Changing Health and Wellbeing Revolution in India, a startling 24% of Indians experience stress. The survey looks for answers to a few questions like, how the COVID pandemic has influenced mental health conditions and during the pandemic whether the stress level has increased or decreased. Surprisingly the survey shows that around 26% of Indians are stressed only because of present job conditions. So, there is an urgent need to implement a stress detection mechanism for the well-being of an organization. Stress can be detected by various stressors in our body [6], facial expressions, social media chats and other means. CNNs are excellent at automatically learning hierarchical features from facial images, which are rich source of non-verbal cues and emotional information. By leveraging a CNN-based FER model, stress-induced facial expressions can be mapped to corresponding emotional states, aiding in stress detection. FER is a good choice in stress detection at the organization level because of its implementational level efficiency and non-invasive nature. The proposed work shows the implementation of the Convolutional-XGBoost model (Conv-XGBoost) for facial expression recognition. Conv-XGBoost model offers a powerful and versatile approach by introducing an enhanced classification, over the normal conventional Convolutional models. Using the Facial Expression Recognition dataset, the model validation was performed. The seven basic emotions were mapped into two emotions, positive and negative, which help to detect whether a person is stressed. The model’s performance is compared with CNN and ResNet-50 models, and the proposed Conv-XGBoost model shows remarkable validation accuracy. The pipeline architecture of the proposed model is shown in Figure 1.

Emotions to Stress Detection.
The remaining section of the article is organized as, Section covers the review of the literature on face expression techniques and the background research is covered in Section. The general concept of the suggested system is explained in Section, and the experimental findings are shown in Section. Section concludes this study and outlines its future scope.
For millennia, both scientists and philosophers have been intrigued by facial expressions. For stress prediction, an efficient classifier is highly essential. Several researches have been conducted to date where emotion detection was done based on various classifiers like Fuzzy systems [7], Multi-Layer Perceptron [8], Convolutional Neural Networks [9] and many more. For psychiatrists, various detection tools are available: the State-Trait Anxiety Inventory (STAI) [10], Profile of Mood States (POMS) [11], Depression, Anxiety and Stress Scale–21(DASS-21) [12] and also analysing cortisol levels, hormone level analysis and the Cornell Medical Index (CMI) [13]. Hence selection of classifiers play a crucial role in AI related tasks, especially in the field of machine learning. Machine learning was used in a wide range of fields, including healthcare, remote sensing, seismic data analysis, geological exploration and structural health monitoring [14].
Numerous data from studies have demonstrated the effectiveness of stress detection from facial expressions. Mehrabian et al. [15] stated that information conveyed verbally was 7%, whereas 38% of information may be done by voice modulations, pace and rate of speech. At the same time, the total information conveyed through facial expression is 55% . This highlights the importance of facial expression in identifying emotions. The findings substantiate that, by correctly classifying emotions, stress levels in an individual can be analysed. Developing an emotion detection model for stress can be valuable in various fields, including mental health, healthcare, and stress management. The proposed model tries to implement an effective emotion detection model for stress prediction. During the course of development of any stress detection model, it is important to consider ethical and privacy concerns, as well as the need for robust and accurate algorithms. Finally, developing and using such model should make sure that it should always be used in a way that respects individual’s privacy and consent while providing valuable insights and support.
The various research findings in the Facial Expression analysis using several classification techniques and numerous datasets were abstracted in Table 1. For the literature survey, machine learning and deep learning techniques were considered. Using deep learning [16], emotions are classified from facial expressions. A multimodel approach was developed by considering emotions along with physiological signals. The signals were collected using Blood Volume Pulse sensors. The model shows an accuracy of 81.545% with physiological signals, 99.9% with facial expression and 86.2% with a combination of physiological and facial datasets. A FER system with BiLSTM and CNN [17] tries to avoid the dying ReLU problem by using the Elu activation function. The research shows the overfitting problem and how data augmentation can solve this problem. The accuracy of the model is 81.82% before augmentation and 99.43% after augmentation. A Committee neural network [18] was introduced for mood recognition. The work incorporates two separate networks: specialized and generalized committee networks. With this two networks an integral committee was proposed. The integral committee shows an accuracy of 90.43%, in which 255 within 282 images were correctly classified.
Various Datasets and Classifiers in FER
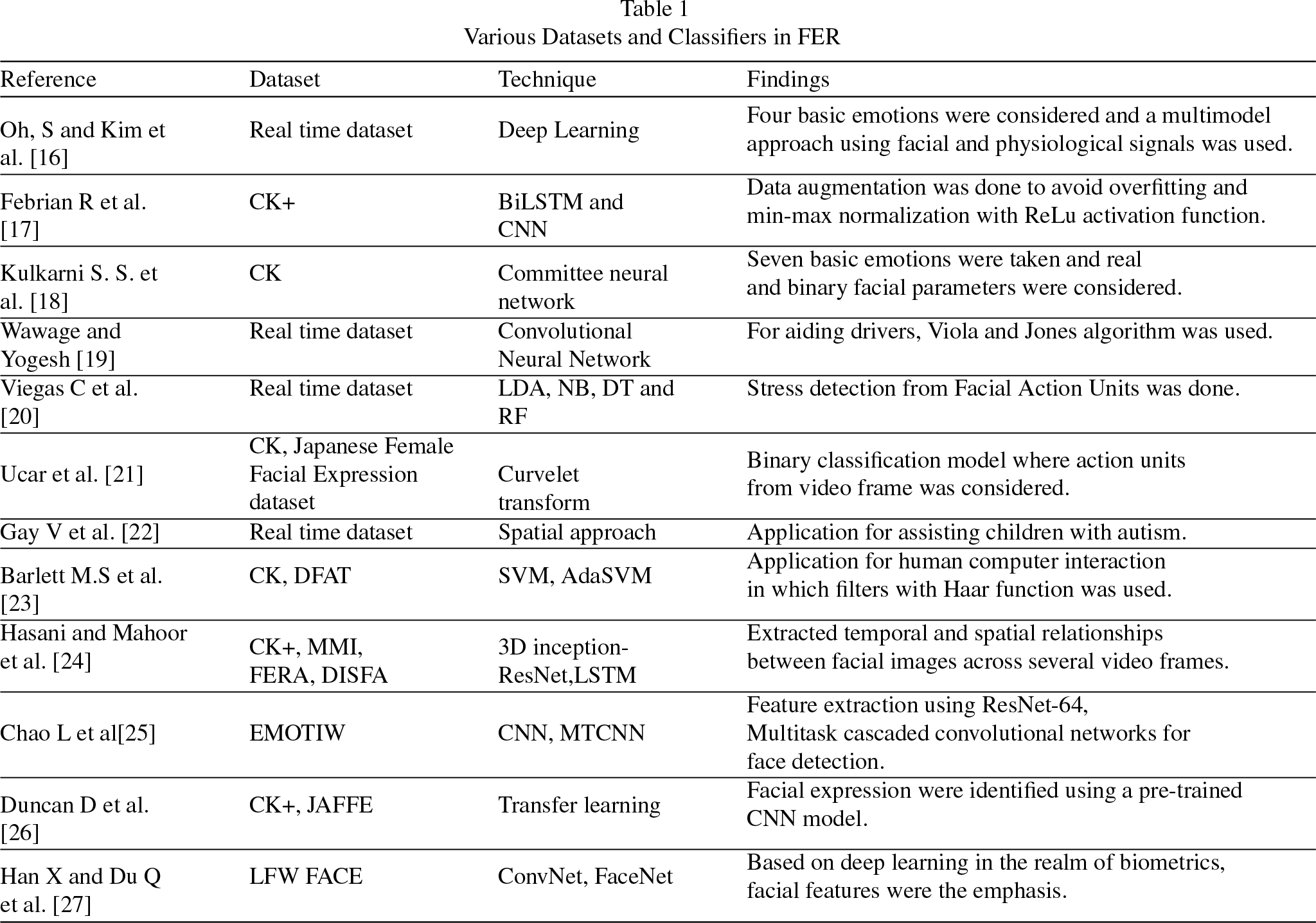
Various Datasets and Classifiers in FER
An emotion prediction system for car drivers was developed using CNN [19] with real-time data. For this CNN model, researchers use transfer learning to solve problems like time and the construction of convolution layers. Features like class loss to entropy loss were considered, and the model acquired an accuracy of 87% . Stress detection can be done with Facial Action Units (FAU) [20] with video data. With the action units, the proposed model performed binary classification using a variety of straightforward classifiers and successfully obtained an accuracy of 74% for classification with subject independence and 91% for classification with subject dependency. Using Curvelet transform [21], FER can be done with a radial basis function-based online sequential extreme learning machine. This model tries to overcome the time problem in finding the hidden node by introducing spherical clustering. For autistic children, a helping aid was developed to understand their emotions by analyzing facial expressions [22]. By identifying the arousal and valence levels, the model made the prediction. As an application towards human-computer interaction, a real-time FER system was developed [23]. The classification using Support Vector Machine (SVM) and a combined approach using SVM and AdaBoost called AdaSVM was performed. The model shows an accuracy of 93.3% .
From the literature analysis, there occurs an urge in developing a stress detection model for accessing stress at the organizational level, which is very comfortable and easy to use. As the economy entirely relies on the productivity of organizations, an ample algorithm for identifying stress is highly relevant. Using these benchmark references, the proposed model tried to develop an emotion detection system for organizational well-being that can overcome existing method’s drawbacks. Model uses periodic analysis for stress detection and easy to use. Also, an efficient emotion classification using FER has done which led to an accurate stress prediction.
The Convolutional eXtreme Gradient Boosting method is a pioneering deep learning architecture for classification problems. Convolutional XGBoost creates a cutting-edge performance with excellent accuracy by combining the strengths of a Convolutional Neural Network (CNN) [28] and eXtreme Gradient Boosting (XGBoost) [29]. The diligent method for adopting these two models is one of the main strength of Convolutional XGBoost [30, 31]. Data scientists frequently utilize XGBoost, an expandable machine-learning remedy for tree boosting that minimizes overfitting and model complexity. So, a deep insight into CNN, XGBoost and the combined version is essential for understanding the proposed methodology.
Convolutional neural network (CNN)
Convolutional neural networks (CNNs) have emerged due to contemporary advancements in Artificial Intelligence and supports novel image-processing technology that would supplant conventional methods [32]. The model demonstrated outstanding performance in several computer vision tasks, including image classification, object identification, and image segmentation. The fundamental idea behind this model’s working is to use convolutional layers to learn hierarchical patterns and features from the input data automatically. These patterns can represent different levels of abstractions.They are capable of identifying effortless features like edges and texture to more complex features like shapes and objects. CNN constitutes: Convolutional Layer: This layer applies convolutional operations to the raw input data which helps to detect local features in the input data. Activation Function: An activation function is applied element-wise after convolution to introduce non-linearity into the network. Pooling Layer: Pooling layers downsample the spatial dimensions of the input, reducing the computational complexity and the risk of overfitting. Fully Connected Layer: A set of convolutional and pooling layers may be followed by one or more fully connected layers that carry out classification or regression tasks using the high-level features discovered by the preceding layers. Softmax Layer: For classification tasks, a softmax layer is often used at the network’s end to convert the network’s outputs into class probabilities.
The mathematical formulation of CNN can be briefly explained as below. For an input grey image J, after applying filter K the output of the I
th
layer for the i
th
feature map is therefore obtained from the result of the layer’s preceding layer by Equation
Here ∅ implies the activation function, 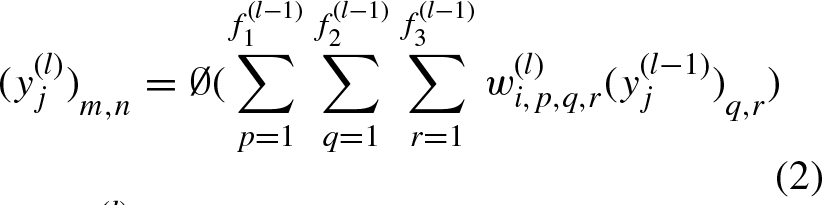
Extreme Gradient Boosting(XGBoost), is a robust and prevalent machine-learning technique that belongs to the gradient boosting class proposed by Chen and Guestrin [34]. XGBoost is a classification technique based on Classification And Regression Trees (CART). Here the sum of the prediction scores for each tree represents the final forecast,which can be calculated using the associated labels of classes as y
i
and is shown in Equation 
The Extreme Gradient Boosting algorithm, a well-liked and effective Gradient Boosting formulation for machine learning, has an improved version called Convolutional Extreme Gradient Boosting (Conv-XGBoost). As the original XGBoost technique, Conv-XGBoost is intended to rapidly train decision tree models for applications requiring classification, ranking, and regression. Conv-XGBoost reduces model complexity and the number of parameters needed for prediction by combining the benefits of CNNs and Extreme Gradient Boost. For implementing this functionality, CNNs without pooling or fully connected layers are used, and the final layer is XGBoost. As a result, there is a lower chance of overfitting, and the model is more effective and more straightforward to train. The architectural model of Conv-XGBoost consists of six essential layers that performs the key functionalities. Every layer will perform two significant functionalities the former is called feature learning, and the latter is the prediction of class labels. Conv-XGBoost architecture is shown in Figure 2.
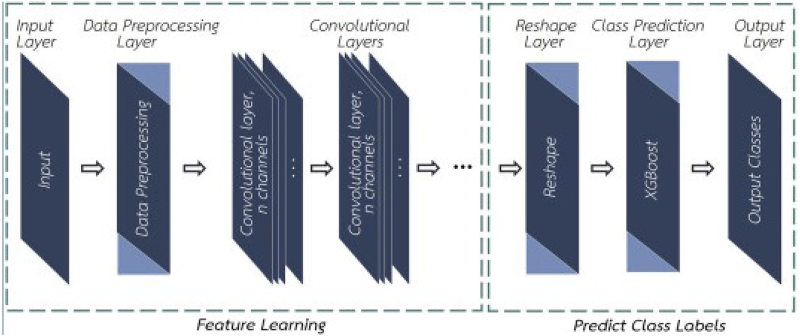
Convolutional Extreme Gradient Boost Architecture.

The proposed FER detection technique has two main parts: The Convolutional Model followed by an XGBoost Model. The output of the convolutional model is collected by an intermediate layer called the dense layer, which controls the input to the XGBoost model. The detailed algorithmic procedure is described in Algorithm.
Intermediate features extracted from the trained CNN model helps to leverage the interpretability and generalization capabilities of gradient boosting. The proposed model creates an intermediate layer model to extract features from the my _ dense layer, which is the output layer of the CNN. These features serve as input to the XGBoost model. XGBoost, a robust gradient-boosting algorithm, is used to build an emotion classification model. We initialize an XGBoost classifier with the objective set to multi : softprob, which is the key parameter setting for multi-class classification. The classifier is trained on the intermediate features extracted from the CNN model, using metrics like log loss. This matrix can also be used as the evaluation tool too. The XGBoost Algorithm in the proposed model has two significant steps: Initializing the XGBoost Classifier and Training the XGBoost Model.
Initializing the XGBoost classifier
The steps involved in initializing phases are: Initializing an XGBoost classifier using the XGBClassifier class. This classifier is suitable for multi-class classification tasks. Setting key parameters: objective= multi : softprob: This parameter specifies that the objective is multi-class classification with soft probabilities. It means the classifier will output class probabilities for each sample.num _ class = 7: Indicates the number of classes in your emotion classification task.
Steps involved in training XGBoost model includes: The XGBoost classifier is trained using intermediate features extracted from the trained CNN model. The training data for XGBoost consists of these intermediate features, and the labels represent the emotions associated with the images. Evaluation metric: use eval _ metric = mlogloss to specify that the model should be evaluated based on the multi-class logarithmic loss (cross-entropy loss) during training. eval _ set: evaluate the model’s performance on the same dataset used for training. This can help to monitor overfitting during training. verbose = True: Setting verbose to True allows you to see training progress, including evaluation metrics for each boosting round.
From the algorithmic procedure explained the time complexity of the algorithm can be effectively reduced to
The Conv-XGBoost algorithm has four convolutional layers, and after preprocessing, the image will be given to the initial input layer. The input layer defines the shape of the input data. In the model, the input images are grayscale images with a size of 48×48 pixels and a single channel (as indicated by 1). The image specification given to the input layer after preprocessing is shown in Table 2. Preprocessing was performed with the help of a tensor flow by Keras called ImageDataGenerator. The images are converted to gray scale and resultant images were resized and rescaled. This preprocessed data was used in training and testing datasets.
Image given to input layer

Image given to input layer
Using the Keras ImageDataGenerator, which builds batches of tensor image information with real-time data augmentation, the image is normalized to the range between 0 and 1. The Keras ImageDataGenerator is used to receive the input of the original data, which is then randomly modified and releases a result that contains only the newly altered data. Data augmentation is also done using this Keras method to broaden the generalization of the model as a whole. Proposed CNN architecture consists of convolutional layers, batch normalization, activation functions, max-pooling, and dropout layers. The complete methodological framework of the Conv-XGBoost algorithm’s initial half, which is the Convolution model is shown in Figure 3. The four convolutional layers processed the input image, while a dense layer collected the result.
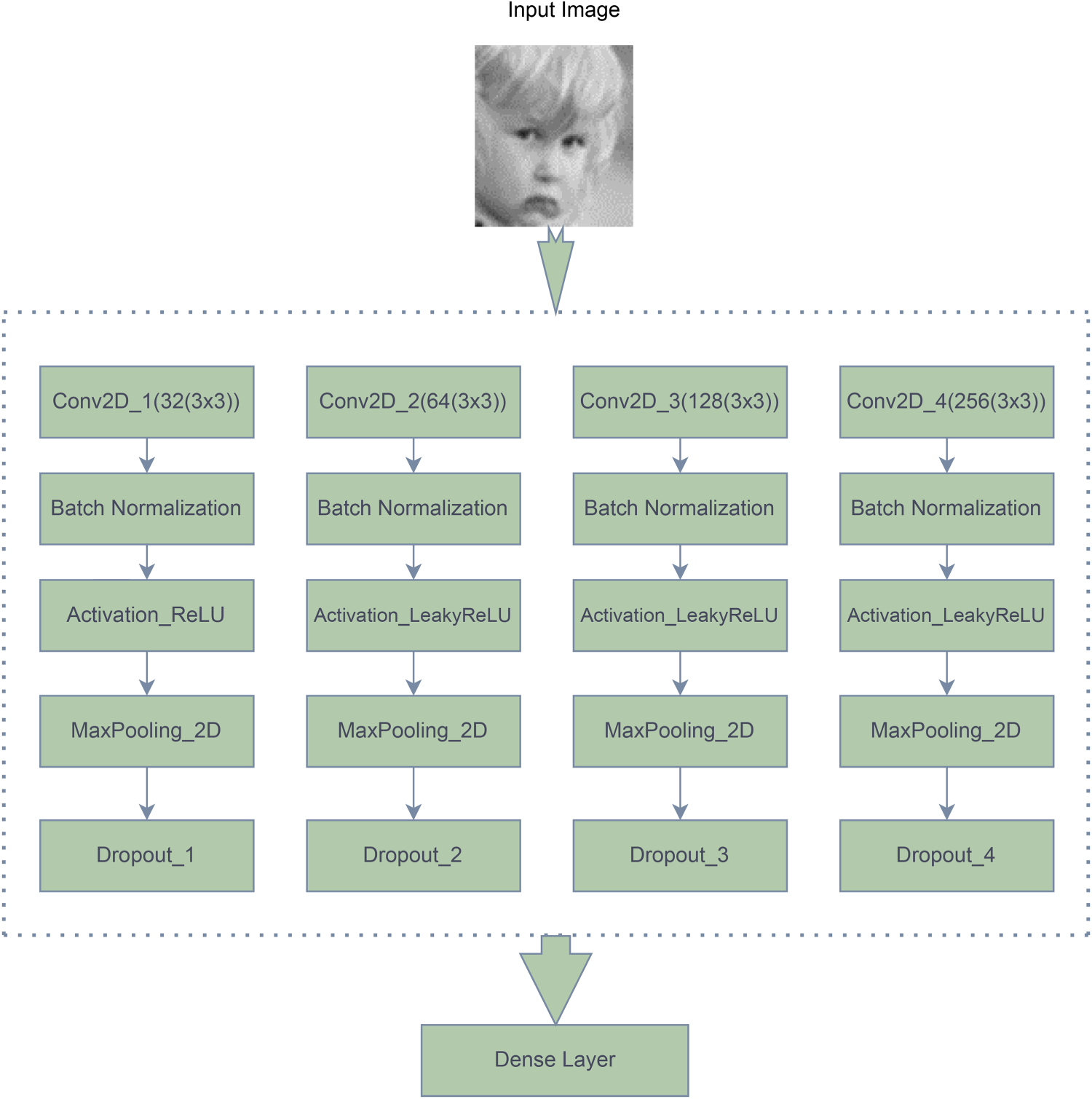
CNN Framework.
Extreme Gradient Boosting, or XGBoost, is a well-known and effective machine learning method for supervised learning problems, especially in regression and classification. This gradient boosting framework is acclaimed for its effectiveness, speed, and performance across various machine learning challenges and practical applications. XGBoost incorporates L1 (Lasso) and L2 (Ridge) regularisation terms into the objective function to prevent overfitting. Regularization helps to control the complexity of the learned model.
Convolutional layers
A series of learnable filters are applied to the input image using convolutional layers, which aid in the model’s ability to recognize regional patterns and characteristics. It takes images as input and utilizes trainable weights and biases to distinguish between images. These biases and weights are applied to hidden layers. The convolutional layer’s main objective is feature extraction [35], where they automatically recognize and extract valuable features from the incoming data.
The model uses multiple convolutional layers with different filter sizes and activation functions. In CNN, convolution is accomplished by applying a filter or kernel to an input image. Here, we use two filters of size 3×3 and 5×5. The values in the input represent the intensity or amplitude of the signal or the image’s pixel values.
Normalization
An output feature map represents the result that the convolution operation produces. This feature map records the relationship between the source data and the filter at each location. The output feature map’s size depends on factors like the input size, filter size, stride, and padding. Batch normalization is applied after each convolutional layer. This helps to stabilize and accelerate training by normalizing the activations of the previous layer.
Non-linearity
Convolution of filter over the initial input image, will affect the image dimensions and the final output will undergo one more stage known as a nonlinearity function or activation function. The network’s nonlinearity is implemented by determining whether to activate a neuron in response to an input. The activation used is Rectified Linear Unit (ReLU) which is a simple and widely used activation function and defined by Equation .
Convolved feature size reduction can be more efficiently performed by introducing pooling layer along the convolution layer. As pooling shows a substantial reduction in dimensionality, the power can be reduced to a lower level for data processing. Pooling has a lot of benefits like translation invariance, feature abstraction, preventing overfitting, improving computational stability and integrating local features. Pooling technique used is Max-pooling [36] with a pool size of (2,2). Max-pooling layers downsample the spatial dimensions of the feature maps created by the convolutional layers.
Dropout layers
Dropout layers are included after specific convolutional layers. Dropout is a regularisation strategy that, during each training iteration, randomly sets a portion of the input units to zero. As a result, there is less reliance on particular neurons, which helps to prevent overfitting. It forces the network to learn more robust and distributed representations. Dropout can be seen as a form of ensemble learning.
Fully connected layers
The model flattens the feature maps into a one-dimensional vector after passing through the convolutional and max-pooling layers. The flattened vector is passed through fully connected layers. These layers learn global patterns and relationships in the feature space. Final layer consists of seven neurons, corresponding to the number of classes, each representing one of the possible emotion classes. This layer receives a softmax activation function to transform the outputs of the model into class probabilities. The complete architectural diagram of the proposed Conv-XGBoost model is shown in Figure 4.
Convolutional XGBoost Architecture for emotion classification.
Facial Expression Recognition dataset, which is a publically available dataset was considered for the algorithm analysis [37]. The dataset has seven emotions labelled as disgust, anger, fear, happy, neutral, surprise and sad of more than three thousand different human faces, which include males, females and infants. Conv-XGBoost algorithm uses 200 samples from each of the seven primary emotion datasets for training and 100 from each for validation. Thus, a total of 1400 images were considered as training data and for validation, 700 images. The details of data usage for the Conv-XGBoost algorithm is shown in Table 3.
METADATA
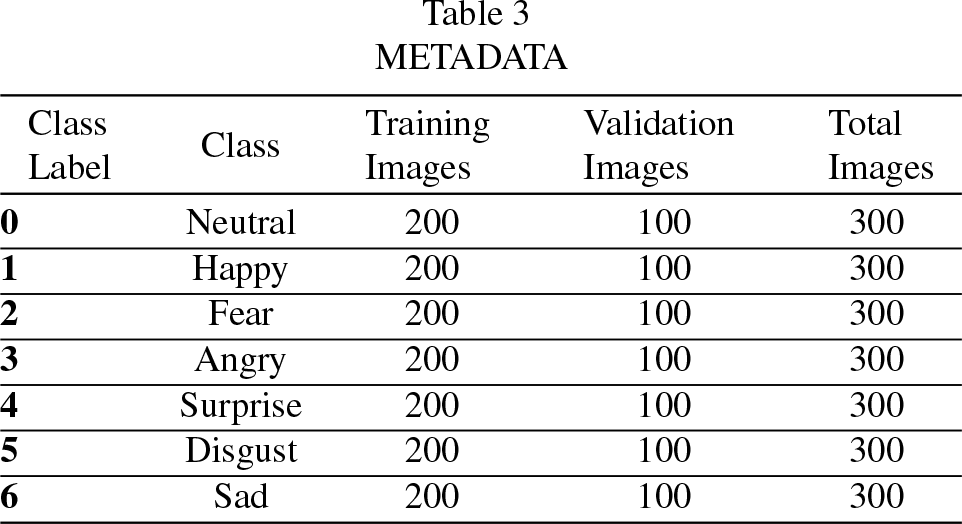
METADATA
All the image dimensions were set as (48×48×1) since the channel was 1 for greyscale and height and width as 48×48. Thus, all images were resized, and the number of classes was seven. The sample emotions considered from the Facial Expression recognition dataset is shown in Figure 5. The training dataset images were given to the Conv-XGBoost classifier, where the CNN model will train and validate the input model generators. To achieve the best results, various models and numbers of epochs have been run and tested in the Conv-XGBoost classifier. There are two different types of experiments where the initial will determine the accuracy of facial expressions, while the second computes the precision of stress detection. The performance analysis parameters considered were accuracy, F1-score, precision, and recall with the corresponding equation.

The F1 score combines precision and recall into one metric to assess a model’s accuracy. When dealing with imbalanced datasets, and one class considerably outnumbers the other, the F1 score is beneficial. The harmonic mean of recall and precision, defined as follows, generates the F1 score. Precision and recall depends on the True Positive (TP), False Positive(FP) and Fasle Negative (FN) measures.

Seven basic emotions from Face Expression recognition dataset.
The model evaluation has done in two phases for analysing the performance, with the basic CNN architecture and the secondly with Conv-XGBoost architecture. For comparing the efficiency, the model was compared with the ResNet 50 model since ResNet is considered to be one of the strong Deep Learning models. ResNet has various forms like ResNet-18, ResNet-34, ResNet-50, ResNet-101 and ResNet-152. The bottleneck building block is used in the 50-layer ResNet. A bottleneck residual block also referred to as a "bottleneck", uses 11 convolutions to cut down on the number of parameters. This makes each layer’s training significantly faster, and instead of using a stack of two levels, it employs three layers. It implements a convolution of 64 kernels with a 2-sized stride and a 7x7 kernel. The resultant is given to a 3×3,64 kernel convolution followed by 1×1,64 kernels and 1×1,256 kernels. In total, nine layers will be generated in this step. The further layer generation is shown in Figure 6.
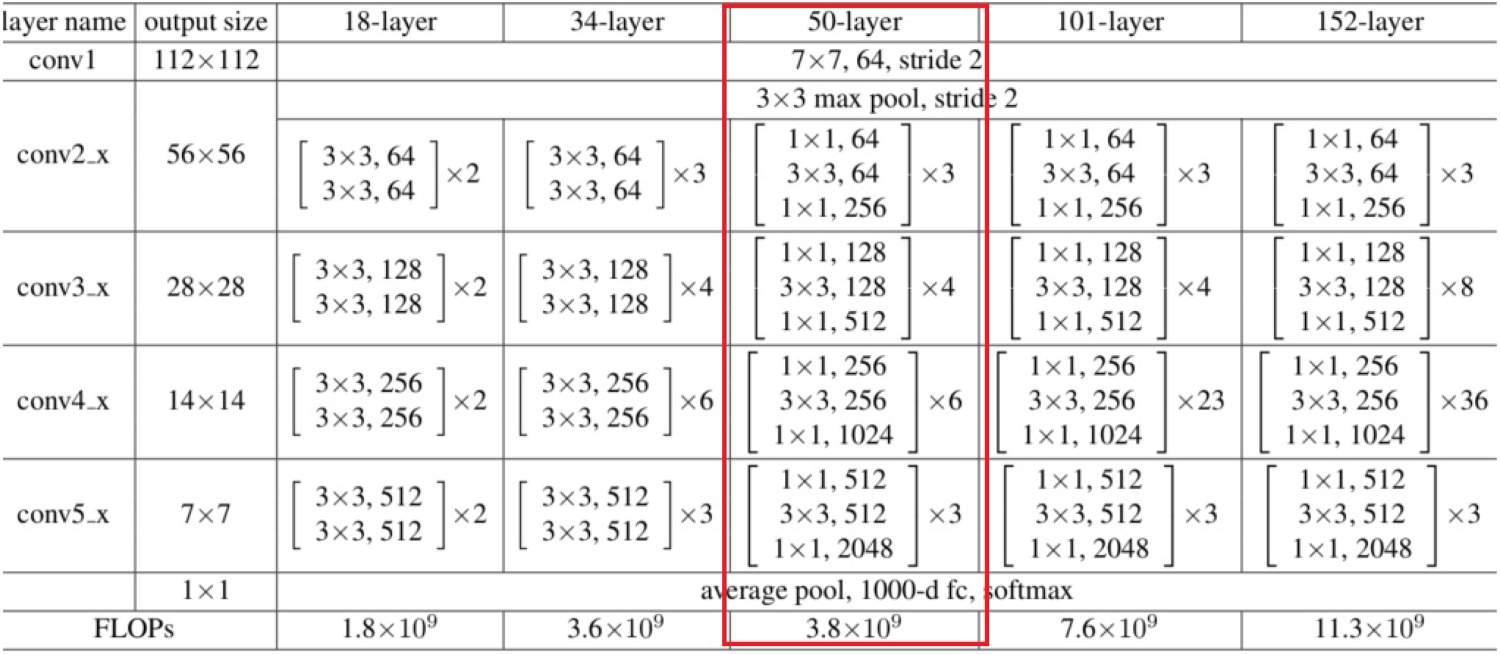
ResNet-50.
In this experiment, each model was trained using the Facial Expression Recognition dataset in 50 and 100 epochs, respectively. The cycle of learning is one epoch. The number of learning algorithms that will process the complete dataset depends on the number of epochs, and the precision increases with the number of epochs. The model was evaluated, and the performance parameters like training and validation accuracy, F1 score and training and validation loss were calculated.
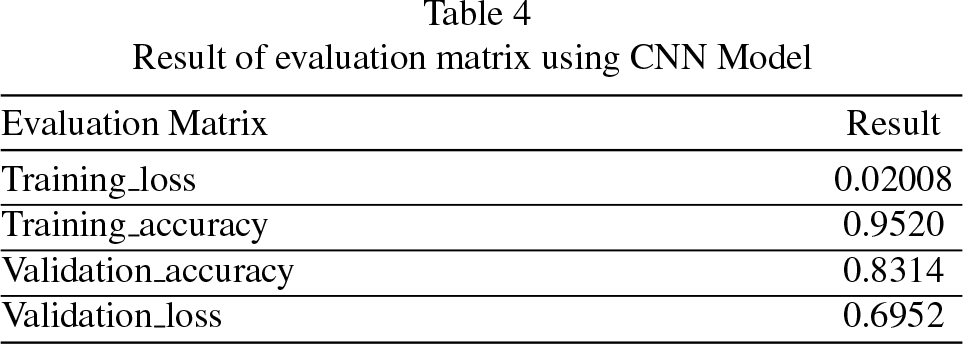
With the basic CNN architecture, the model shows a training accuracy 95.20% and a remarkable validation accuracy of 83.14% . For the same dataset with the ResNet-50, model training accuracy is 96.40% and validation accuracy is 86.13% . Labelled training data trains the model to categorize images into several emotion categories. The model adjusts its parameters during training to reduce the categorical cross-entropy loss, which gauges the discrepancy between expected and actual class probabilities. The model’s weights and biases are modified iteratively using an Adam optimizer and backpropagation during the training phase. The evaluation matrix parameters are shown in Table 4. Here, model loss is a statistic used to penalize the model when it fails to forecast the input data accurately.
Result of evaluation matrix using CNN Model
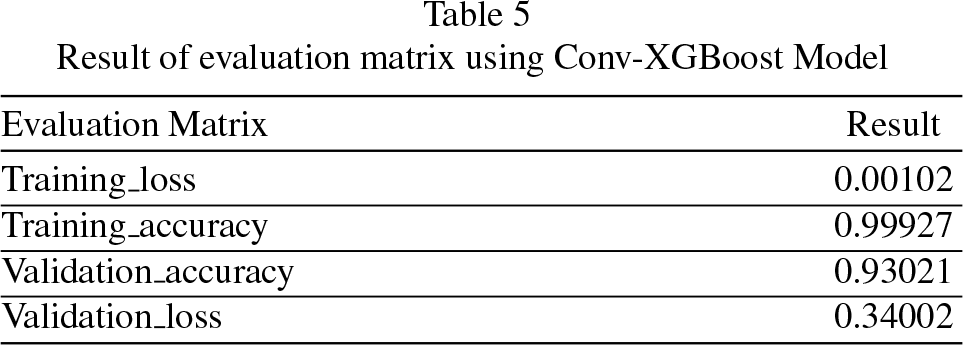
After training, the XGBoost model can make predictions for emotion classification. Several performance indicators are computed to assess the model’s efficacy and accuracy in classifying emotions. The proposed algorithm, Conv-XGBoost Emotion recognition, shows a better performance of 99.92% than the basic CNN architecture. The performance result of Conv-XGBoost is shown in Table 5. Among the three models, Conv-XGBoost model shows a remarkable validation accuracy of 93.02% and the comparison of three models is shown in Figure 9.
Result of evaluation matrix using Conv-XGBoost Model
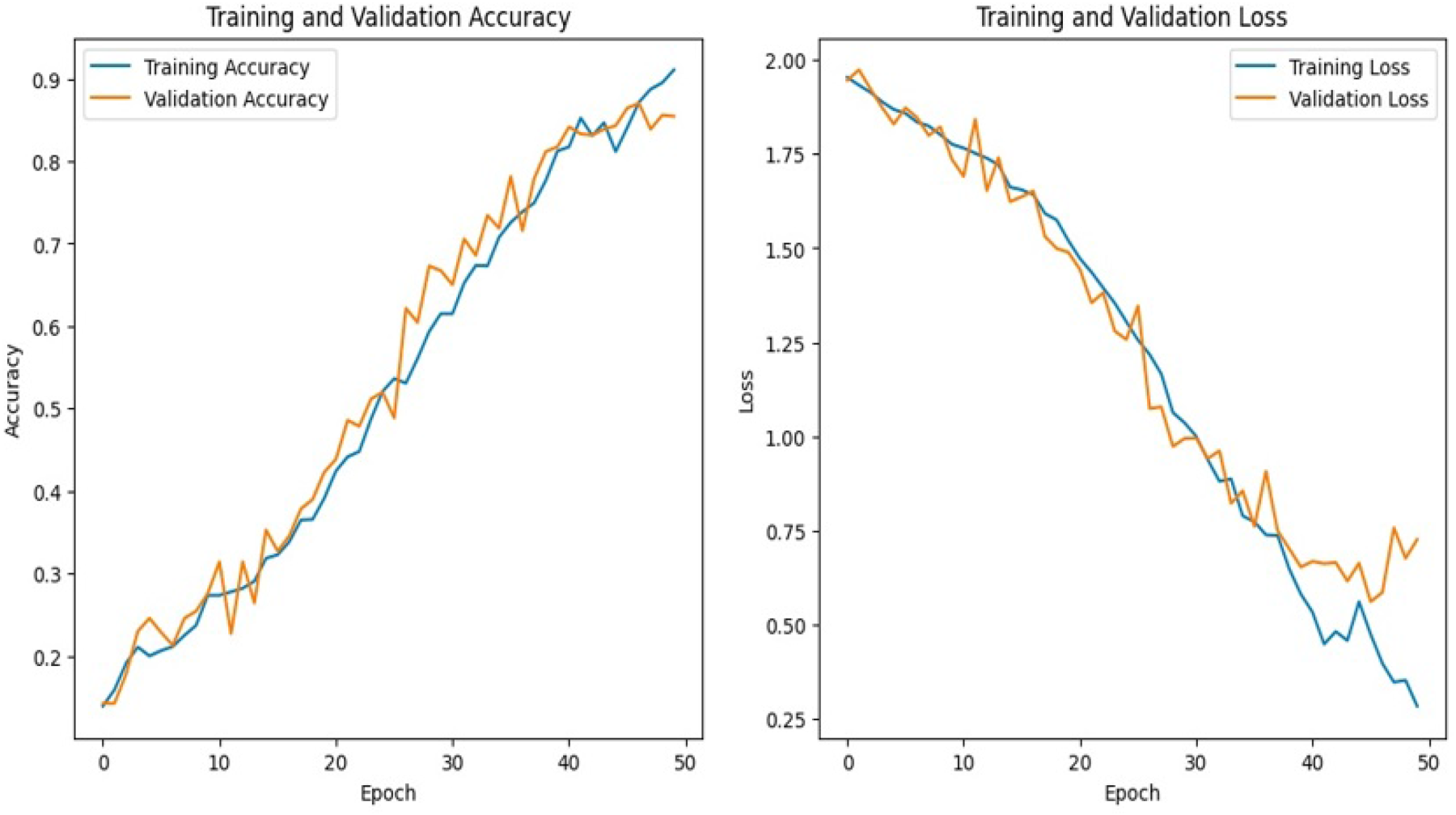
Accuracy and loss for 50 epochs.

Accuracy and loss for 100 epochs.

Validation Comparison
The detailed comparison of three reference models: CNN, ResNet-50 and Conv-XGBoost are shown in Table 6. Model has compared by considering 50 and 100 epochs and parameters like training and validation accuracy was considered. The CNN model shows validation accuracy of 78.25% and 83.14% for 50 and 100 epochs respectively. With ResNet-50 model shows 82.92% and 86.13% while the proposed model shows 89.68% and 93.02% as validation accuracy which substantiate the performance efficiency of the Conv-XGBoost model.
The proposed model shows a precision, which evaluates the predictions that are true, of 99.92%, Recall, that measures the capacity to detect positive examples, of 99.881% and F1 score, that provides a balance between precision and recall of 99.92% . The performance graph for the model is shown in Figure 7, which compares training and validation accuracy/loss for 50 epochs and in Figure 8, training and validation accuracy/loss for 100 epochs, respectively.
The performance of our model is summarised and portrayed using the confusion matrix. Confusion matrix is a fundamental tool in the evaluation of classification models. It provides a comprehensive summary of the performance of a classification algorithm by breaking down the number of correct and incorrect predictions made by the model. The confusion matrix to visualize the model’s predictions and the true labels for the validation dataset is shown in Figure 10.
In order to evaluate the precision of Conv-XGBoost’s stress detection system based on a facial expression identified in the initial trial, a follow-up experiment has been initiated after the first experiment. The input faces were classified as either stressed or non-stressed by Conv-XGBoost after it examines the facial expression. Happiness, neutrality, and surprise are categorised as positive emotions in the Facial Expression Recognition dataset, whereas sorrow, anger, disgust, and fear are classified as negative emotions. Hence the seven basic emotions are now classified into two classes as positive and negative emotions. Later the classifier consider a two input module and the stress detection module classify whether the person is stressed or non-stressed.
Performance Comparison of three models


Confusion matrix of proposed model.
The same experimental setup was considered for the stress detection phase. The second experiment evaluates the efficiency of the proposed Conv-XGBoost model in accurately identifying the different images of facial expressions into the appropriate stress categories. Our model shows an accuracy of 99.7% on identifying stress. While mapping the emotions into two primary classes as positive and negative, the chance of predicting the emotions and classifying them to correct class is crucial in stress prediction. The method typically create a duplicate of the dataset that is used for training in order to prevent unintentionally altering the original dataset. Stress prediction would be a periodic assessment process where the analysis of a continuous week data is considered for stress detection.
Stress detection and management are vital components of maintaining physical and mental well-being in today’s fast-paced and demanding world. With advancements in technology and a growing awareness of the detrimental effects of chronic stress, we can now employ various methods and tools to identify and address stress effectively. This research shows a detailed study of the architecture of CNN and XGBoost algorithms, which helps in developing the Conv-XGBoost algorithm for emotion detection. The proposed model developed an accurate stress detection model by analysing various existing algorithms for the implementation.
A detailed study was carried out for an accurate emotion detection model using Facial Expression Recognition dataset. Conv-XGBoost algorithm shows accuracy of 99.9% than the other state-of-the-art methods. An accurate prediction was produced by the convolution layers using Tensor Flow for fine-tuning and Leaky ReLu activation. For the performance evaluation, the proposed method is compared with the basic CNN model and ResNet-50 with the same Facial Expression Recognition dataset. Comparison of the three models for 50 and 100 epochs were performed and Conv-XGBoost model shows validation accuracy of 89.69% and 93.02% . As the emotion detection part is very crucial, the algorithm shows a better performance in classifying the basic seven emotions into either positive or negative emotion classes. This emotion classification model helps to make the stress prediction comfortable. The Conv-XGBoost model shows an accuracy of 99.7% when compared to the other reference models. This analysis can confirm the efficiency of the proposed model for stress prediction.
This work can be further extended by implementing a real-time stress prediction model with extended cloud storage provision. The extension can be used for assisting elder in a smart home environment with real-time monitoring. Real-time stress detection form motion pictures can be incorporated which has wide range of applications in intelligent healthcare, criminology and a lot more.