
Abstract
Accurate load forecasting is an important issue for safe and economic operation of power system. However, load data often has strong non-stationarity, nonlinearity and randomness, which increases the difficulty of load forecasting. To improve the prediction accuracy, a hybrid short-term load forecasting method using load feature extraction based on complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) and refined composite multi-scale entropy (RCMSE) and improved bidirectional long short time memory (BiLSTM) error correction is proposed. Firstly, CEEMDAN is used to separate the detailed information and trend information of the original load series, RCMSE is used to reconstruct the feature information, and Spearman is used to screen the features. Secondly, an improved butterfly optimization algorithm (IBOA) is proposed to optimize BiLSTM, and the reconstructed components are predicted respectively. Finally, an error correction model is constructed to mine the hidden information contained in error sequence. The experimental results show that the MAE, MAPE and RMSE of the proposed method are 645 kW, 0.96% and 827.3 kW respectively, and MAPE is improved by about 10% compared with other hybrid models. Therefore, the proposed method can overcome the problem of inaccurate prediction caused by data and inherent defects of models and improve the prediction accuracy.
Keywords
Introduction
Short-term load forecasting is very important for the stable operation of power system. Accurate load forecasting can not only ensure the balance between supply and demand, but also avoid abnormal fluctuations in voltage and frequency and reduce the risk of failure [1]. With the reform and promotion of power market and the development of power technology such as demand response and load aggregation, power load presents more complex and changeable new features and forms [2], which also puts forward higher requirements for the accuracy and reliability of load forecasting. In order to provide reliable data for optimal dispatching of power grid and ensure the stable operation of power system, it has become an urgent problem to enhance the level of load decomposition, improve traditional load forecasting methods and make full use of error information to further improve forecasting performance [3].
Many scholars have studied the short-term load forecasting. The forecasting methods can be roughly divided into two categories, mathematical statistics algorithm and machine learning algorithm. Commonly used statistical methods include linear regression method [4], Kalman filter [5], exponential smoothing method [6] and so on. Although these methods have the advantages of simple model and fast calculation speed, they are not robust and easy to be destroyed by random factors, which leads to low reliability of load forecasting in complex environment. Machine learning algorithms include support vector machine (SVM) [7], extreme learning machine (ELM) [8], random forest (RF) [9] and so on. Reference [7] uses SVM combined with adaptive neuro-fuzzy inference system (ANFIS) to make prediction, and the results show that SVM has smaller prediction error than ANFIS in training stage, while ANFIS has higher prediction accuracy in testing stage. Reference [8] adopts ELM to modify the structure of group method of data handling, and obtains accurate prediction results. This kind of method can deal with nonlinear and multidimensional data well, but it is sensitive to outliers and easy to lead to the decline of model performance in the face of data mutation.
In recent years, deep learning has been widely concerned in the field of load forecasting because of its excellent data expression ability. Among them, long short-term memory (LSTM) [10, 11] is an improved structure of recurrent neural network (RNN), which is suitable for processing time series and has achieved good forecasting results in the field of load forecasting. Reference [10] proposes a hybrid method based on support vector regression (SVR) and LSTM, which can handle high-dimensional time series data well, and the prediction accuracy is higher than that of single LSTM. Reference [11] proposes a multi-task learning model based on ResNet-LSTM network, which mines the spatial coupling interaction features between multiple energies and realizes the differentiated selection of shared features by using attention mechanism. Although LSTM solves the problem of long-term dependence to a certain extent, there is still the phenomenon of information loss when dealing with long-term time series problems. The bi-directional structure of bidirectional long short-term memory (BiLSTM) enables it to learn the forward and backward time series relationship of the sequence, which optimizes the problems that LSTM neural network does not fully learn the global information of historical data and ignores the correlation between forward and backward time series. Reference [12] compares four load forecasting models, which proves the advantages of bidirectional structure and that BiLSTM has better forecasting performance than LSTM and gate recurrent unit (GRU). Reference [13] adopts Conv1D to extract depth features and BiLSTM and attention mechanism to learn load data features, which has high prediction accuracy and anti-interference ability. In [14], considering the internal relationship between multivariable and time series, important features are extracted from the row vectors of BiLSTM hidden state matrix by temporal pattern attention (TPA), and the hyperparameters of BiLSTM are optimized by chaotic sparrow search algorithm (CSSA), which further improves the prediction accuracy. The existing research proves that compared with single models such as GRU and LSTM, the hybrid model can make full use of the advantages of each model, can overcome the limitations of the single model and have better prediction performance.
However, load series are easily influenced by various factors, showing instability and nonlinearity, which increases the difficulty of load forecasting. Therefore, scholars often use load decomposition method to obtain smoother and more stable components, and predict each component separately, thus improving the overall prediction accuracy. Reference [15] uses wavelet transform package (WTP) to decompose the original signal, which improves the prediction accuracy of local features. But it is necessary to choose a suitable wavelet function. Reference [16] uses complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) to preliminarily decompose the sequence and extract the characteristic frequency. Compared with the traditional empirical mode decomposition (EMD) and wavelet transform (WT) method, CEEMDAN has higher sensitivity and adaptability. Reference [17] suppress the interference of load fluctuation by the CEEMDAN algorithm, propose the method combined GRU with improved gray wolf optimizer (IGWO) to predict power load, which can effectively improve the prediction accuracy. Reference [18] uses CEEMDAN mining and permutation entropy (PE) to judge the component noise, further decomposes the noisy components through wavelet packet decomposition (WPD) and make prediction, which effectively improves the prediction accuracy. But two decompositions produce more components, resulting in a large amount of calculation and low training efficiency.
Aiming at the problems of mode mixing and high entropy of high-frequency components that may be caused by load decomposition, and in order to solve the problems that the traditional deep learning model has long-sequence information loss and the prediction error cannot be corrected, a short-term load correction forecasting framework that combines CEEMDAN, refined composite multi-scale entropy (RCMSE), BiLSTM and improved butterfly optimization algorithm (IBOA) is proposed. Firstly, the preprocessed original load data is decomposed by CEEMDAN to reduce the information loss and improve the forecasting performance, RCMSE is used to evaluate the entropy of the decomposed components, the components with similar values are reconstructed into new components, and Spearman coefficient is used to screen the characteristics of each component. Secondly, the IBOA is used to search the optimal hyperparameter combination of BiLSTM, the reconstructed components is predicted, and the prediction results of each component are added to get the preliminary load prediction results. Finally, an error correction model based on the improved BiLSTM is constructed, which further improves the prediction accuracy.
The innovations and contributions of the proposed method are as follows: Based on the existing advantages of CEEMDAN, the RCMSE is introduced to decompose and reconstruct components with similar complexity. Using CEEMDAN-RCMSE decomposition framework, the original load is decomposed and reconstructed adaptively, so as to effectively extract the time series characteristics such as periodicity and trend in load data and reduce its non-stationary characteristics. The IBOA with strong optimization ability and fast convergence speed can search the optimal hyperparameter combination of BiLSTM, which enables the BiLSTM to fully explore the past and future deep time series characteristics of load data and give full play to the advantages of model itself. The error correction model can correct the accumulated error in the prediction process and the error caused by residual noise in CEEMDAN. A practical case shows that the hybrid forecasting method proposed in this paper can effectively improve the load forecasting accuracy.
The remainder of this paper is organized as follows. The decomposition and reconstruction method is introduced in Section 2. The improved BiLSTM error correction model is introduced in Section 3. The total procedure of hybrid forecasting method is explained in Section 4. The forecasting model performance is evaluated in Section 5. Conclusions are drawn in the last part.
Complete ensemble empirical mode decomposition with adaptive noise
The short-term load forecasting framework is shown in Fig. 1. Short-term load forecasting is based on historical data, comprehensively considering meteorological factors and external factors, reflecting the complex relationship between them by establishing mathematical relations, and accurately forecasting the future load. Aiming at the characteristics of strong qualitative and remarkable randomness of the original load series, CEEMDAN is used to decompose the original load series into multiple components, which reduces the difficulty of forecasting.

Short-term load forecasting framework.
CEEMDAN is an adaptive data preprocessing algorithm. Based on EMD, CEEMDAN adds adaptive Gaussian white noise at each stage, which decomposes the load data into a series of intrinsic mode function (IMF) and residual component (RES) with high to low frequencies. CEEMDAN algorithm effectively solves the problem of mode mixing, which greatly improves the decomposition efficiency. Each mode component reflects the characteristics of the original load data on different time scales, which effectively weakens the non-stationary and nonlinear characteristics of the load series and provides a basis for the detailed analysis of load data.
The calculation steps of CEEMDAN decomposition are as follows: adding Gaussian white noise with standard normal distribution ω
i
(t) to the original signal X (t), averaging the components E
k
(*) obtained by empirical mode decomposition for many times as the final actual component, and the k + 1st order mode component IMF
k
+1 is

The short-term load forecasting model combined with CEEMDAN algorithm can improve the evaluation indexes of the forecasting model. However, with the increase of the number of components, the computational complexity and time consumption cost of the prediction model will increase exponentially, which is not conducive to the superposition of subsequent optimization algorithms. Therefore, in order to balance the prediction performance and time cost, the mode components obtained by CEEMDAN decomposition is aggregated. Considering that the regularity and complexity of each mode component are quite different, the RCMSE is used to evaluate the complexity.
RCMSE is an improved algorithm based on multi-scale entropy (MSE) and composite multi-scale entropy (CMSE), which can make up for the inaccurate or undefined entropy of MSE and CMSE, overcome the limitation of single scale, and obtain more stable entropy values than other multi-scale entropy algorithms [19]. For load time series, the formula of RCMSE value is defined as follows:

Bidirectional long short time memory network
BiLSTM is a combination of forward LSTM and backward LSTM, which is suitable for processing time series data. It is precisely because BiLSTM can use both past and future sequence information to train the model, which effectively solves the problem of long-term dependence and improves the ability to extract data features. At the same time, the time correlation between features can be fully utilized, which is conducive to further improving the accuracy of load forecasting. The structure of BiLSTM is shown in Fig. 2.

The structure of BiLSTM.
The output of BiLSTM at time t is obtained by adding the outputs of forward layer and backward layer simultaneously. The calculations are as follow:



Improved butterfly optimization algorithm
The BOA is a heuristic optimization algorithm based on natural inspiration. Its core strategy is to imitate the foraging and mating behavior of butterflies. The BOA imitates these behaviors to find the optimal value in the search space. When the traditional BOA is applied to load forecasting, although it is better than other optimization algorithms, it also has the problems of falling into local optimum, poor convergence accuracy and reduced population diversity. Aiming at the limitation of traditional BOA, this paper makes full use of the advantages of dynamic transformation strategy, optimal neighborhood disturbance strategy and random inertia weight strategy in solving complex problems with constraints and unknown search space, which optimizes the global search stage and local search stage and solves the problems that the algorithm is easy to fall into local optimal value, low convergence accuracy and reduced population diversity [20].
(1) Dynamic conversion probability strategy
The conversion probability p determines whether the butterflies enter the global search stage or the local search stage. In order to improve the convergence speed of the algorithm in the later stage, the conversion probability p is adjusted to a dynamically changing value. The formula is

(2) Optimal neighborhood disturbance strategy
In the process of iteration, the butterflies in BOA will move randomly or move to the optimal butterfly. When the butterflies move randomly, the BOA enters the global search stage. The expression is as follows:

In order to reduce the diversity of butterfly population, the neighborhood space is searched by disturbing the current optimal position in the global search stage, which can ensure that the real optimal position can be found and thus jumping out of the local optimal position. The optimal neighborhood disturbance strategy formula is

(3) Random inertia weight strategy
When the butterflies move to the optimal butterfly, the BOA enters the local search stage. The expression is as follows:

Aiming at the problem that the traditional BOA easily falls into local optimum in the later stage, random inertia weight is used to change the influence of the previous position on the current position update in the local search stage. The formula for calculating the random inertia weight is

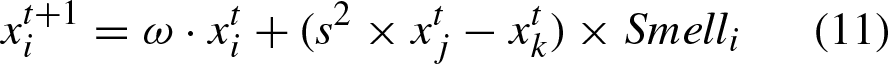
It can be seen from Equation (11) that ω realizes the adjustment and control of the position to be updated by the previous position of the butterfly. When the value of ω is large, the position of butterfly to be updated is greatly affected by the previous position. When the value of ω is small, the position of butterfly to be updated is less affected by previous position.
When BiLSTM is used for short-term load forecasting, the accuracy depends not only on the comprehensiveness of feature extraction, but also on the selection of model hyperparameter. In this paper, IBOA is used to search the optimal hyperparametric combination of BiLSTM. The training times λ, learning rate μ and the number of hidden layer neurons γ of BiLSTM are determined, which further improves the accuracy of BiLSTM model in short-term load forecasting. The process of IBOA optimizing BiLSTM is shown in Fig. 3.

The flow chart of IBOA optimizing BiLSTM.
The white noise signal added in the process of CEEMDAN decomposition leads to the residual noise of components, which makes errors in component reconstruction and reduces the prediction accuracy. Therefore, an error correction model based on IBOA-BiLSTM is established. Further compensation for the prediction results can effectively improve the prediction performance.
Firstly, IBOA-BiLSTM is used to make a preliminary load forecasting, and the real load data is subtracted from the preliminary forecast sequence to get the error sequence. Then, the IBOA-BiLSTM is used to learn the changing trend of error and predict the error to obtain predicted sequence of errors. Finally, the error prediction sequence is removed from the preliminary predicted load sequence, so as to obtain the final load prediction result after error correction. The final predicted value is
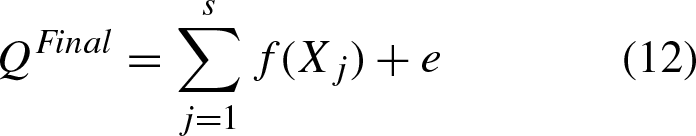
Load data is easily influenced by multiple factors, so it shows strong non-stationarity and nonlinear characteristics. Due to the advantages of CEEMDAN in non-stationary sequence processing and the remarkable effect of BiLSTM in short-term load forecasting, the CEEMDAN-RCMSE and improved BiLSTM error correction model is proposed. The specific process is shown in Fig. 4.

The flow chart of CEEMDAN-RCMSE-IBOA-BiLSTM-EC.
The total procedure mainly includes four parts:
Data description and evaluation metrics
Data description
To verify the performance and effectiveness of the proposed forecasting framework, the short-term load forecasting is carried out by taking 8640 pieces of data with a granularity of 10 minutes from November 1, 2017 to December 30, 2017 in a certain area in northern Morocco as an example. The data set includes load data, temperature, humidity, general diffusion flow, wind speed and diffusion flow. Taking the load data from November 1, 2017 to December 29, 2017 as the training set data, with a total of 8496 data points. Taking the load data of December 30, 2017 as the test data, with a total of 144 data points.
To improve the training speed and prediction accuracy of the model and avoid supersaturation in the training process, it is necessary to preprocess the data. Data preprocessing mainly includes outlier processing, missing value filling and normalization. Quartile method is used to detect abnormal values in data set, and average value is used to replace abnormal values and missing values to ensure the relative integrity of data. The characteristics of load data after outlier processing and missing value filling are shown in Table 1.
Division and characteristics of load data set after preprocessing

Division and characteristics of load data set after preprocessing
When the outlier size accounts for 0.5% –1% of the data set, it indicates that the data set is available. The proportion of outlier data in the selected data set is 0.74%, so the selected set can be used for short-term load forecasting. Meanwhile, normalization is adopted to eliminate the dimensional influence between different factors. The normalization formula can be express as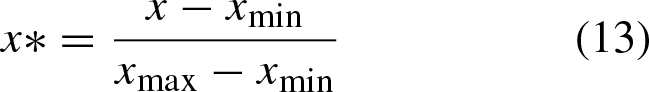
In the absence of feature selection for prediction, the future load can only rely on historical data. However, the power load is subject to the influence of multiple factors in the power system, and weather features exhibit complexity, variability, and high volatility. Selection of pertinent features can enhance the stability of the model. Randomly selecting features as inputs to the model may ignore significant contributors like temperature. Conversely, employing all features instead of omitting any may introduce noise and compromise accuracy due to the dataset’s extensive size and inclusion of redundant elements, such as diffusion flow. Hence, feature selection assumes a pivotal role, as a judicious selection of input features can substantially improve the computational efficiency and prediction accuracy of the model. Spearman correlation analysis is used to analyze the correlation between load data and other factors. Assuming that two variables α = (α1, α2, …, α n ) and β = (β1, β2, …, β n ) are given, the Spearman correlation coefficient can be expressed as

As can be seen from Table 2, power load data has strong correlation with temperature and humidity, with the correlation coefficients of 0.3482 and 0.3127 respectively, followed by general diffusion flow with correlation coefficient of 0.2002. However, power load data has small correlation with wind speed and diffusion flow, which are characterized by weak correlation. Therefore, temperature, humidity and general diffusion flow are taken as input characteristics.
The correlation coefficient of Spearman

In order to verify the forecasting performance of the proposed model and compare the forecasting effects of different modeling methods, this paper adopts mean absolute error (MAE), mean absolute percent error (MAPE), root mean square error (RMSE) and determining coefficient R2 as the evaluation metrics of load forecasting accuracy.


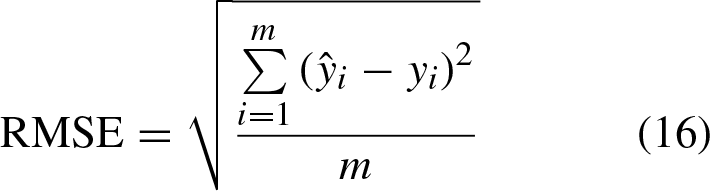

In this paper, CEEMDAN is used to decompose complex original load data series. The original load data is decomposed into 12 mode components and 1 residual component at different frequency scales by CEEMDAN. Considering that the components are directly modeled and predicted will lead to too much calculation, this paper uses RCMSE to evaluate the complexity of each component. Based on the entropy value, the component sequences are aggregated and reconstructed to improve the prediction efficiency and the input feature quality. The embedding dimension, conditional threshold and time delay of RCMSE algorithm are set to 2, 0.2std (IMF i ) and 1 respectively. According to RCMSE values, the results of reconstruction of each component are shown in Fig. 5.

Components reconstruction based on RCMSE value.
It can be seen from Fig. 5 that the RCMSE values of each component sequence are mainly distributed in seven numerical neighborhood ranges of 4.7, 5.5, 2.6, 3.5, 0.8, 0.5 and 0.1. Therefore, this paper aggregates and reconstructs each component sequence, and the results are as follows: F1 = IMF1, F2 = IMF2 + IMF3, F3 = IMF4 + IMF7, F4 = IMF5, F5 = IMF6 + IMF8, F6 = IMF9 + IMF10, F7 = IMF11 + IMF12 + IMF13. Figure 6 shows the process of components reconstruction based on RCMSE values. The number of components after reconstruction is reduced by 6. Therefore, the purpose of reducing mode components and improving calculation efficiency can be achieved.

The process of components reconstruction based on RCMSE.
Comparison of the single model prediction results
In order to compare the performance of single forecasting models, six forecasting models, including RF, SVM [21], ELM-NN, forward feedback back propagation (FFBP), LSTM and BiLSTM, are established respectively with load series, temperature, humidity and general diffusion flow as input. The training epoch of all models are 500, and the learning rate is 0.01. Other parameter settings are shown in Table 3.
Hyperparameter setting

Hyperparameter setting
Table 4 shows the comparison of their predicted performance. Among the six single models, the error of RF, SVM and FFBP are large, which indicates that they are unstable and easy to fall into local optimum.
Prediction performance comparison of the single models

The error of ELM-NN is lower than that of RF, SVM and FFBP, indicating that the forecasting result is relatively stable, but the error is still high. The error of LSTM has obviously decreased, which shows that the fluctuation range of prediction result of LSTM is smaller and more accurate. BiLSTM has the highest prediction accuracy, and the prediction result is more stable than other neural networks. To sum up, the neural network is more suitable for dealing with multi-feature input and long-term large-scale load data than machine learning, and BiLSTM can learn the relationship of load data from two directions, so compare with other models, BiLSTM is relatively stable and accurate. Therefore, this paper adopts BiLSTM as the basic prediction model.
BiLSTM is superior to other neural networks, but hyperparameter setting according to experience is random and lacks theoretical basis. Therefore, it is necessary to optimize the hyperparameters of BiLSTM. The population number of IBOA is set to 20 and the maximum iteration number is set to 200.
As can been seen from Table 5, compared with the single BiLSTM, the prediction accuracy of the improved BiLSTM is obviously increased, which indicates that the IBOA can fully mine the potential information in discontinuous data and effectively improve the prediction accuracy and fitting degree. Because the original load series tends to be nonlinear, random and fluctuating, the performance of load forecasting will be not significantly improved only by using the improved BiLSTM. Therefore, it is necessary to use the mode decomposition algorithm to decompose the original data to reduce the prediction difficulty and the prediction error. Compared with IBOA-BiLSTM, the MAE, MAPE and RMSE of CEEMDAN-RCMSE-IBOA-BiLSTM are reduced by 14.59%, 19.35% and 13.28%, and R2 is increased by 0.21%, which effectively verifies that the feature extraction of the original load series can effectively eliminate the influence of nonlinearity and randomness of the load series.
Prediction performance comparison of the hybrid models

Prediction performance comparison of the hybrid models
Meanwhile, the hybrid models in [17] and [22] are used to predict the data set in this paper. It can be seen from Table 5 and Fig. 7 that all the hybrid methods have good performance, but CEEMDAN-RCMSE-IBOA-BiLSTM is the closest to the actual load data and its MAPE is 1.25%. In the peak period, the error value of CEEMDAN-RCMSE-IBOA-BiLSTM is the smallest value, which is still closet to actual value, indicating that it can achieve accurate prediction and deal with uncertainty well. All these verify the superiority of the hybrid method. To sum up, compared with other hybrid methods, the hybrid method based on CEEMDAN-RCMSE and improved BiLSTM can effectively eliminate the influence of nonlinearity and randomness of load series, thus improving the forecasting performance.

The prediction results of the hybrid model.
The hybrid forecasting model using decomposition method is limited by the cumulative error in the process of forecasting, and the forecasting accuracy cannot be further improved. Therefore, the proposed method adopts an error correction model to correct the error of decomposition algorithm and the accumulated error in the prediction process. As can be seen from Fig. 8 and Table 6, compared with the model without error correction, the prediction accuracy of the proposed model is obviously improved. The MAPE of the proposed method is 0.96%, which is 22.96% higher than that without error correction, and the R2 of the corrected model is 0.9964, which is the closest to 1 and the closest to the real value. In the peak period, the proposed method is closer to the actual value and has higher ability to deal with uncertainty. To sum up, the error correction model can fully mine the hidden information in the error sequence, reduce the error in the reconstruction of the subsequence and caused by the limitations of the model itself, deal with uncertainty of load sequence better and effectively improve the prediction accuracy of the model.

The prediction results of error correction model.
Prediction performance comparison of error correction model

To observe the forecasting capacity of the proposed hybrid forecasting model when a parameter changes, the sensitivity analysis is conducted to explore the sensitivity of forecasting results in the algorithm. The MAE is applied to evaluate the extent to which parameters impact the properties of the proposed method. The parameters considered by IBOA are the butterfly number and iteration number. The hyperparameter combination of BiLSTM is obtained by IBOA, so BiLSTM considers the number of hidden layers under the optimal hyperparameter. For the number of butterflies, the parameter is set to 10, 20, 30 and 50. The number of iterations is 100, 150, 200, 250 and 300, and the number of BiLSTM hidden layers is set to single layer and double layer.
As can be seen from Fig. 9, when the number of BiLSTM hidden layer is fixed, with the change of IBOA parameters, MAE also changes accordingly. When the IBOA parameters are fixed, MAE also change under different layers of BiLSTM. The number of butterflies and iterations and the number of layers of BiLSTM have certain influence on the prediction accuracy, so the parameters of the proposed method should be selected reasonably. In single-layer BiLSTM, when the number of butterflies is 20 and iterations is 200, the MAE is 645 kW. Similarly, in the double-layer, when the number of butterflies is 30 and iteration is 150, the MAE is 682 kW. Therefore, it is of great significance to select appropriate parameters in load forecasting, which has a great influence on the prediction accuracy.

The sensitivity analysis for each parameter involved in the proposed method.
In order to further analyze the prediction errors of each model, this paper draws the figure of error of 144 data points in the test set and uses Gaussian mixture distribution to test and statistically analyze the errors of each hybrid model. It can be seen from Fig. 10 that the mean value of RMSE and MAPE of the proposed method is the smallest and the model can always be stable. At the peak and valley period, the proposed model can keep a low prediction error and can adapt to the uncertainty in power system. From the histogram in Fig. 11(a) and the fitting curve in Fig. 11(b) describing the error distribution of each model, it can be seen that in the error comparison of different prediction models, the error value of the proposed method is mainly concentrated near zero, with the most concentrated distribution and the narrowest distribution area compared with other models. From the statistical point of view, the proposed method has a lower probability of producing large errors, which also verifies the stability and reliability of the proposed model.

The error of 144 data points.

Error distribution diagram.
Figure 12 shows the comparison results of the proposed method with other hybrid models in three dimensions: standard deviation, R2 and RMSE. According to Taylor diagram, the standard deviation and RMSE of the proposed method are the smallest. Compared with other hybrid models, the prediction result of the proposed method is the closest to the actual value.

Taylor diagram.
To further verify that the stability and reliability of the proposed method, an applicability case is added. Short-term load forecasting is carried out for 8832 pieces of data with granularity of 30 minutes from July 1, 2019 to December 31, 2019 in Singapore. Taking the load data from July 1, 2019 to December 29, 2019 as the training set data. Taking the load data from December 30, 2019 to December 31, 2019 as the test data. The parameter setting of decomposition and reconstruction method is the same as above, and the computational parameters of IBOA-BiLSTM are obtained by the same method as above. The final prediction results are shown as Fig. 13.

Prediction results of hybrid model in applicability verification.
Figure 13 and Table 7 show the prediction results of the hybrid methods in different references. Besides comparing with the hybrid methods in [17] and [22], the comparison among the proposed method and novel prediction methods in [23–25]. Compared with other hybrid models in other references, the proposed method has the smallest error. Its MAE, MAPE and RMSE are 25.77 MW, 0.44% and 32.89 MW, respectively. At the peak and valley period, the proposed method is the closest to the actual value and has the strongest ability to deal with uncertainty compared with the hybrid models in other references. All these prove that the proposed method is not only superior to other novel hybrid methods, but also can achieve accurate prediction under different data set.
In practical application, noise data will inevitably be generated, which increase the uncertainty of load forecasting. To fully verify the reliability of the proposed method, the power price series with strong randomness and many abnormal values is added to the input variable as noise data. R2 is used as the evaluation standard to evaluate the ability to deal with noise data. It can be seen from Table 8 that the prediction accuracy of all noiseless hybrid models is higher than that of noisy models. After the noise sequence is removed, the R2 of the proposed method decreases from 0.9971 to 0.9950. On the premise of maintaining the highest accuracy, the R2 of the proposed method decreases the least, which shows that it can deal with noise data and deal with uncertainty best.
Prediction results of hybrid model in applicability verification

The R2 value of hybrid models with noise and noiseless

The receiver operating characteristic-area under the curve (ROC-AUC) is usually used to evaluate the performance of classification problems. Especially in binary classification problems, the performance of the classifier is evaluated by true positive rate (TPR) and false positive rate (FPR) under different thresholds. Kappa coefficient is a statistical index used to evaluate the performance of classification model, which is especially suitable for evaluating the performance of classifier in multi-category problems. It considers the classification accuracy of the model and corrects the accidental consistency of classification. Kappa coefficient is usually used to measure the consistency between observers, and can also evaluate the consistency of classification models. When the proposed method is applied to classification problems, ROC-AUC and Kappa coefficient perform well, and Table 9 shows the comparison with other hybrid methods.
The ROC-AUC and Kappa coefficient of each hybrid model

To sum up, the CEEMDAN-RCMSE in extracting and processing the differentiated and refined features of load series and IBOA-BiLSTM error correction forecasting model can deal with uncertainty well and perform well in stability and reliability.
Short-term load forecasting of power system plays an important role in economic dispatching, ensuring the effective utilization of renewable energy and optimal scheduling, and ensuring the safe and stable operation of power system. Short-term load forecasting is taken as the research content in this paper. Aiming at the problem of high-frequency components caused by load decomposition, and in order to solve the problems that the traditional deep learning model has long-sequence information loss and the prediction error cannot be corrected, a hybrid short-term load forecasting method using load feature extraction based on CEEMDAN and RCMSE and improved BiLSTM error correction model is put forward. Through the analysis and verification of concrete examples, the following conclusions are drawn: Aiming at the non-stationary and nonlinear characteristics of load series, CEEMDAN algorithm is introduced to decompose the preprocessed original load series, which effectively reduces the fluctuation and nonlinearity of the original load series. The complexity of each mode component after CEEMDAN decomposition is calculated by using RCMSE, and the subsequence is aggregated according to RCMSE values, which reduces the model complexity and calculation scale and improves the prediction efficiency. It is difficult for a single prediction model to achieve accurate prediction, so IBOA is used to search the optimal hyperparameter combination of BiLSTM from both global and local perspectives, effectively avoiding the problems of easy falling into local optimal value, low convergence accuracy and reduced population diversity. The short-term load forecasting model based on CEEMDAN-RCMSE and improved BiLSTM is constructed. The MAPE of the hybrid model is 1.25%, which is about 10% higher than the hybrid model in other references. These effectively prove that the proposed hybrid model can improve the accuracy and generalization of the forecasting model and fully excavates the deep time series characteristics of the data. The load forecasting model considering error correction overcomes the problem of inaccurate forecasting caused by adding white noise, data defects and model limitations to some extent. The MAPE of the proposed model is 0.96%, which is 23.30% higher than the hybrid model without error correction and about 28% higher than other hybrid models. These indicate that the proposed model can fully mine the hidden information in the sequence and further improves the forecasting accuracy of the forecasting model.
The research content of this paper not only provides a reference for short-term load forecasting methods and diversity of choices, but also has a good reference significance for studying other forecasting problems in the field of power system.
Footnotes
Acknowledgments
This work was supported by Innovation Fund for Production, Education and Research in Chinese Universities (2022IT039) and Basic Research Project of Education Department of Liaoning Province (LJKQ20222276).