
Abstract
This article proposes an expert-driven consensus and decision-making model that comprehensively considers expert behavior in Multi-criteria decision-making (MCDM) scenarios. Under the premise that experts are willing to adjust their viewpoints, the framework strives to reach group consensus to the utmost degree feasible. To tackle experts’ uncertainty during the evaluation process, this article employs the rejection degree in the picture fuzzy sets (PFS) to signify the level of ignorance while they deliver their evaluation opinions. Due to the diversity of expert views, reaching a group consensus is difficult in reality. Therefore, this article additionally presents a strategy for adjusting the weights of experts who did not reach consensus. This approach upholds data integrity and guarantees the precision of the ultimate decision. Finally, this article confirms the efficiency of the aforementioned model by means of a case study on selecting the optimal carbon reduction alternative for Chinese power plants.
Keywords
Introduction
In the actual MCDM problem, the ideal result is to find an alternative on which all experts can agree, but it is difficult to reach a consensus in reality due to the different backgrounds, knowledge and experience of each expert. As a result, scholars have paid great attention to the problem of reaching consensus, and many scholars have proposed various methods and models to address this issue.
Since Zadeh proposed the concept of fuzzy sets [1], fuzzy sets theory has become an effective method for dealing with uncertain and incomplete information. Atanassov proposed the concept of intuitionistic fuzzy sets (IFS) [2], which provides a more comprehensive measure for simple fuzzy sets by adding a non-membership degree. However, it was later discovered that certain voting cases require the inclusion of “abstention” votes, in addition to “yes", “neutral” and “no” votes. To address this issue more effectively, Cuong proposed the concept of PFS [3]. On the basis of the degree of membership, the degree of non-membership, PFS adds the degree of neutrality, the degree of rejection metric results. As an extension of IFS, PFS are extensively used in various industries, including medicine [4, 5], manufacturing [6–8], and finance [9, 10]. In order to further examine the relevance and applicability of PFS, Singh et al. enhanced and standardized the two distance measures originally proposed by Cuong, and used a case study of flood disaster response to illustrate the feasibility of distance [11]. Furthermore, Son proposed a generalized distance measure for fuzzy clustering analysis of PFS [12]. Liu et al. proposed weighted measures for PFS, including ordered-weighted and hybrid-weighted distance measures, and verified the feasibility with case studies [13]. Wei et al. proposed a PFS similarity measure, based on the cosine function, to address the MCDM problem [14]. Furthermore, Wei et al. proposed a normalized Dice similarity measurement formula with parameters [15]. Thao proposed the concept of entropy of PFS and established some similarity measurement methods using entropy [16]. Wang proposed novel information measures, specifically picture fuzzy similarity measures, based on fuzzy strict negations. Their superiority was demonstrated in a case study [17]. In this article, we comprehensively compare different similarity measures and finally choose the PFS similarity measurement formula proposed by Luo [18]. The chosen formula aligns better with our perceptual ability and addresses certain immeasurable scenarios. Furthermore, Luo provides evidence of the benefits of this formula through specific examples [18].
The attainment of group consensus is a topic of great interest among many scholars within the field of MCDM. Coch et al. used mathematical model to solve the group consensus dilemma [19]. French uses matrix and graph theories to assess how expert relations affect group consensus [20]. Cook proposes a novel approach to resolve the challenge of selecting between contrasting alternatives [21]. Zheng et al. proposed a CRP model based on prospect theory and used it in the medical field [22]. Furthermore, consensus reaching is used in freight transport evaluation [23], emergency decision making [24], urban planning [25] and food assessment [26]. Several articles have also explored models for reaching consensus, incorporating game theory [27, 28] and machine learning [29], respectively. Butler et al. proposed that there is no alternative that everyone can agree on due to the differences between experts, so a CRP is needed to deal with this issue [30]. For CRP research, Zou et al. proposed a social network-driven CRP approach using probabilistic language and applied it to the field of investment selection [31]. Gou et al. used the expert preference relationship matrix and merged it with expert confidence to create a consensus model [32]. Wu et al. examined the trust network links among experts and proposed a feedback mechanism based on experts’ maximum self-esteem to find optimal alternatives [33]. Wu et al. proposed a consensus model based on a mutual preference matrix among experts and applied it to two instances [34]. Xu et al. proposed the concept of a consensus index. The consensus index is controlled within a certain threshold to terminate the process [35]. Herrera-Viedma proposed a consensus-reaching model based on soft consensus, which can better represent human feelings [36]. Palomares et al. proposed an analytical framework AFRYCA to find the optimal alternative to the target problem [37]. For large scale group decision making, Zhou et al. proposed a concept of bipartite language trust and distrust relationships to address such issues [38]. Another important direction in the field research of group consensus reaching is to focus on the behavior of experts in group decision making. Zhang et al. relied on the social trust network to explore the experts’ willingness to revise their own evaluation results in the process of reaching consensus, and then constructed a personalized consensus realization mechanism based on the interaction dual optimization [39]. Zhang et al. also based on the compromise and tolerance qualities that experts may show in the decision-making process, put forward the idea that experts all have a tolerance threshold. Within that threshold, experts can just accept. This framework was applied to the case of risk assessment associated with new crown pneumonia in radiation oncology [40]. In addition, Zhang et al. investigated methods for handling expert disagreement during the CRP. Usually, studies allow experts to reach consensus through feedback, but they argued that the ordinal classification of alternatives could be obtained through an ordinal classification-based CRP. To demonstrate the validity and feasibility of this approach, they used the wine classification problem as an example [41]. In this article, we also conducted a study based on expert behavior and found that most of the CRP in existing studies focus on the moderator’s behavior to drive the agreement of expert opinions. In practice, due to the diversity of experts’ backgrounds and interests, some experts may refuse to accept the adjustments recommended by the moderator for various reasons. For this reason, this article proposes a new decision-making framework that not only provides moderator-driven feedback, but also fully takes into account the subjective behaviors of the experts in order to comprehensively address this problem. When the moderator suggests a modification to an expert, the expert can choose whether or not to accept the suggestion, thus taking various factors into account in a more comprehensive manner.
For the MCGDM issue, determining expert weights is crucial. In earlier research, expert weights were frequently assumed to be equal, without acknowledging the heterogeneity among experts. However, the articles by Liang et al. [42] and Pang et al. [43] show through sensitivity analyses that inconsistencies in the initial setting of expert weights lead to variations in ranking alternatives. Yue put forward a novel approach for calculating the weights based on similarity to the ideal decision made by each expert [44]. Wan et al. combined the Pythagorean fuzzy number with MCDM problems and defined a new comprehensive distance to obtain expert weights [45]. Liu et al. proposed a weight adjustment method using expert trust [46]. In recent years, the wide application of probability distribution functions in the decision-making field has led to the increasing richness and improvement of problem-solving models and frameworks. Chen et al. represent the utility function of fairness concerns as the impact of fairness based on the probability distribution function, and then obtain the collective opinion of experts [47]. They also constructed a paradigm for collective opinion generation in large-scale situations based on probability distribution functions to solve practical problems. The model provides flexibility in classifying experts and setting criteria weights in real-world problems, and the authors also applied it to the field of assessing barriers to blockchain adoption in healthcare supply chains [48]. In addition, Chen et al. combined Building Information Modeling (BIM) maturity assessment with probability distribution functions to provide an expert-based assessment system for BIM performance assessment [49]. Based on these results, this article proposes a new method for adjusting the weights of experts. By moderately adjusting the weights of expert opinions that are less similar to the overall opinions, we achieve the goal of effective decision making while avoiding completely ignoring certain expert opinions. This method provides strong support for obtaining expert weights and is expected to play an important role in various practical problems and scenarios.
The main innovations and contributions of this article can be summarized as follows: The article proposes a novel approach for obtaining weights by measuring the similarity between expert and group opinions and the degree of rejection of experts’ evaluations. For experts who do not reach the similarity threshold, their weighted weights for the corresponding alternative and corresponding criteria are adjusted in the decision-making stage. This approach considers expert opinions to enhance the efficiency of decision-making. This article constructs a decision framework for solving MCDM problems by applying PFS theory to the consensus process. The rejection degree concept of PFS is applied to more accurately represent the degree of experts’ lack of understanding of the target alternative or criterion, thus improving the accuracy of the decision. This article presents a strategy for incorporating experts’ subjective initiative into the decision-making process, fully considering their willingness to modify their own opinions and strongly supporting the final decision. This article proposes an expert weight subdivision method. In this article, the weight of each expert is divided into the weight of each alternative and criterion, to better reflect the experts’ contribution to the decision process.
In the following sections, this article elaborates the following: Section 2 centers on the concepts of MCGDM, CRP, and PFS. In Section 3, a formula based on similarity is proposed for obtaining expert weights. Section 4 constructs a CRP and a decision-making framework based on the PFS. Section 5 provides an example of the selection of optimal carbon emission reduction alternatives for a thermal power plant in China, verifies the feasibility and validity of this CRP and decision-making framework, and conducts a simple comparative analysis. Section 6 summarizes the main contents of this article.
Preliminaries
This section of the article reviews the relevant concepts and properties of MCGDM, CRP, and PFS to help readers better understand the subsequent content.
PFS and relevant concepts
Then D is a fuzzy set, where μ (x) denotes the possible membership functions of x ∈ X that satisfy 0 ⩽ μ (x) ⩽ 1. The significance of this simple fuzzy sets is that it indicates that the fuzzy situation of x ∈ X is not limited to the previous only belonging or not belonging.
Then E is an IFS, where μ (x) and ν (x) denote the degree of membership function and non-membership function of x ∈ X, respectively, which satisfy 0 ⩽ μ (x) + ν (x) ⩽ 1. Furthermore, π (x) = 1 - μ (x) - ν (x), where π (x) denotes a hesitancy function of x ∈ X. The IFS introduces the non-membership degree and hesitation degree, which can further respond to various fuzzy situations in a more complete way.
Then F is a PFS, where μ (x), η (x) and ν (x) denote a positive affiliation function, a neutrality function and a negative affiliation function of x ∈ X, respectively, and satisfy ∀x ∈ X, 0 ⩽ μ (x) + η (x) + ν (x) ⩽ 1. Furthermore, π (x) = 1 - μ (x) - η (x) - ν (x), where π (x) denotes a rejection degree of x ∈ X. PFS allows for a more comprehensive description of complex situations by introducing two parameters, neutrality and rejection.
We should note that all the above algorithms come out in the form of PFS as well.
Score function: S (F) = μ - η - ν (2)
Accuracy function: H (F) = μ + η + ν (3)
They satisfy conditions -1 ⩽ S (F) ⩽ 1 and 0 ⩽ H (F) ⩽ 1. The comparison rules are as follows: If S (F1) > S (F2), then F1 compares relatively well with F2. If S (F1) < S (F2), then F2 compares relatively well with F1. If S (F1) = S (F2), we will compare their precision functions next. If H (F1) > H (F2), then F1 compares relatively well with F2. If H (F1) = H (F2), then the two are equivalent in degree of merit, or there is an incomparable relationship.
Where R (F1, F2) is the similarity between two PFS F1, F2. The result of similarity calculation is a value between [0, 1].
In real life scenarios, MCGDM problems manifest themselves as a relatively complex class of problems that involve t experts (e1, e2, e3 ⋯ e t ), m alternatives (A1, A2, A3 ⋯ A m ), and n evaluation criteria (c1, c2, c3 ⋯ c n ).
When solving MCGDM problems, we need to fully consider the views of each expert on each criterion for each alternative, as well as how the weights are allocated among them. Due to the differences in knowledge and background of each expert, the evaluation results will also vary. In this context, we need to find an alternative that can be accepted by most experts, equivalent to reaching consensus. Therefore, the MCGDM problem is inseparable from the problem of group consensus reaching.
The evaluation given by each expert is a matrix of type m × n. We use P
x
to denote the evaluation matrix given by each expert, where x = 1, 2, 3 ⋯ t, the result is expressed as follows:
So we can get t initial decision matrix, where means the evaluation result given by the expert x for the criterion i of the j alternative.
After obtaining each expert’s assessment, we can begin the CRP. This process usually consists of two main stages. In the first stage, the results of each expert’s assessment are integrated using methods such as aggregation operators, and then the overall opinion is compared with the opinion of each expert, with the aim of identifying the experts, alternatives, and criteria that make it difficult to reach consensus. In the second stage, there are two situations: the first situation is that the integration results are notified to each expert, followed by a discussion that allows the experts to reach a final conclusion, and this group consensus model lacks a feedback mechanism. The second scenario is a consensus model where a feedback mechanism exists, which is driven by a facilitator who informs the experts who need to be adjusted of the identification results of the previous stage and asks them to make the corresponding modifications according to certain rules. Through this feedback and adjustment process, the group consensus is finally realized, and the specific group consensus reaching flow chart is shown in Fig. 1.

Flow chart for group consensus.
However, in real-world problems, reaching consensus is only an ideal state. Due to trust issues and conflicts of interest among experts, the possibility of reaching consensus is almost nonexistent. Therefore, this article focuses on solving the problem of making decisions in these real-world situations.
In the past research on group consensus, fuzzy sets can only represent the positive evaluation of experts in the evaluation process because they only have one parameter, the degree of affiliation, so they cannot represent the experts’ hesitation. Compared to fuzzy sets, intuitionistic fuzzy sets are extended, but still only consider positive evaluation, negative evaluation and hesitation degree in the evaluation process of experts. Zhang et al. combined intuitionistic fuzzy sets with the field of reaching group consensus and applied them to the problem of facility siting [52]. Hesitation fuzzy sets, on the other hand, can consider the existence of multiple possibilities of experts in the evaluation process, but it may lead to differences in the normalization calculation process and increased computation due to the different number of sets included. Liang et al. based on the characteristics of hesitation fuzzy sets, extended it to interval, and applied the interval hesitation fuzzy sets to the field of group consensus, which effectively solved the ambiguity and hesitancy of the experts [53].
However, none of the above studies considered the possibility of expert “abstention” from evaluation, where the expert refuses to give an evaluation due to lack of knowledge or other reasons. Since it is not possible for each expert to know all the criteria of each alternative, PFS has an advantage when it is not possible to accurately evaluate each criterion of each alternative in its entirety, such as in this case; the rejection degree of PFS appropriately reflects the uncertainty of this level of knowledge, and the neutrality degree of PFS is just enough to indicate the measure of hesitation of the expert. However, PFS also has a disadvantage, for large-scale decision-making in the calculation, still shows the problem of more complex calculations, the future can be used with the help of some R language, Matlab and other tools to assist the calculation, so as to make up for this disadvantage. As shown in Table 1, the disadvantages and advantages of partial fuzzy sets are visualized. Therefore, it is of great practical significance to apply PFS theory to the field of group consensus reaching, which helps decision makers to make decisions based on expert opinions more accurately and efficiently.
Advantages and disadvantages of each fuzzy set
This section focuses on methods for obtaining expert weights in the absence of consensus. In the MCGDM process, due to the diversity of expert opinions and criteria, different evaluation results may occur. Even after many rounds of dynamic adjustment, some experts may still insist on their opinions for various reasons. In this case, decision makers need to fully consider the opinions of all experts when making decisions to ensure the effectiveness of decision making. To solve this problem, this article proposes a new formula for obtaining expert weights. The formula can adjust the experts’ weights in the criterion at the final decision-making stage, thus helping us to make the best choice.
Regarding the newly proposed expert weight adjustment formula, the first thing to be clarified is that in the decision-making calculation process, the expert weight represents the degree of the expert’s contribution to the final decision-making result. The idea of adjusting the expert weights is divided into two parts: the first part is the ratio of the similarity between the partial expert evaluation and the overall evaluation to the similarity threshold; the second part is the degree of rejection of the partial expert evaluation, which should reduce the degree of the expert’s contribution to the final decision-making result due to their lack of familiarity with the alternatives and criteria.
The weight adjustment of the first part is as follows: in the CRP model and decision-making framework of this article, by default, each expert has the same status, and the weights are all 1/t, each expert contributes the same to the final decision-making result. However, in the case that the similarity between the evaluation of some experts and the overall evaluation has not reached the threshold, in order to follow the principle of minority to majority, and not to completely ignore the opinion of that expert, we need to reduce the degree of influence and the contribution of these experts to the final decision-making result. This adjustment is realized by calculating the ratio of the similarity of that expert’s evaluation to the overall evaluation to the similarity threshold. Accordingly, the ratio
The weight adjustment strategy for the second part is as follows: PFS is applied to the field of group consensus to utilize its main advantage. When an expert conducts an evaluation based on the PFS, the degree of rejection is used to measure the degree to which the expert is so unfamiliar with the criteria of the alternative at the time he conducts the evaluation that he is unable to accurately make an evaluation. In this case, the degree of rejection is denoted by π (x) = 1 - μ (x) - η (x) - ν (x), which can then indicate the percentage that should be reduced by the expert. Thus, μ (x) + η (x) + ν (x) can reflect the degree of familiarity of the expert with the subject of evaluation at the time of giving the evaluation. So, we can get that (μ (x) + η (x) + ν (x)) × (1/t) is the expert weight for the final second part.
Therefore, in order to combine and balance expert similarity and rejection, we introduce a new parameter λ for determining the weights of both in different situations. In summary, the following is the strategy for adjusting the expert weights:
The above formula takes full account of the effect of the similarity of the expert’s opinion to the overall opinion when determining the expert’s weight. When the similarity between the expert’s opinion and the overall opinion is farther away from the threshold, the weight of that expert will be reduced accordingly. In addition, from the perspective of PFS, when an expert’s understanding of certain information is lower, his weight will be reduced accordingly. Such a way of determining weights can more accurately reflect the actual contribution of experts and improve the accuracy and fairness of the overall evaluation.
This section of the article mainly elaborates on the construction of a CRP model and the selection process for the optimal alternative based on the theory of PFS. The process is divided into three stages: problem preparation stage, CRP stage and final decision-making stage.
Problem preparation
Firstly, we need to clarify the meaning of each parameter of the PFS when the experts conduct the evaluation. The membership degree of the PFS represents the degree of approval by the experts. The degree of neutrality represents the degree to which experts neither support nor oppose the alternative. The degree of non-membership represents the degree to which the expert is against it. The degree of rejection of the PFS is used to indicate the degree of ignorance of the expert about this criterion in the alternatives.
In problem preparation stage, suppose that t experts (e1, e2 ⋯ e
t
) give their evaluations P
x
for n criteria (c1, c2 ⋯ c
n
) of m alternatives (A1, A2 ⋯ A
m
) in the form of PFN in turn. In addition, the similarity threshold is
Since the core topic of this article is the setting of expert weights and the CRP when weighting each criterion of the alternative, we set the weight of each criterion w
ij
to be 1/n. In the CRP, since we do not yet have information about the experts, we initially set the weight of each expert
Consensus reaching
The CRP is divided into the following three main parts: similarity measurement; recognition phase and recommendation phase, which we next examine separately.
Similarity measure
First, we perform an integration of the initial decision matrix P
x
(x = 1, 2, 3 ⋯ t) given by each expert. The alternative weighting matrix M1 is obtained by using Equation (1) to perform an aggregated weighting of each expert’s opinion.
Where
Secondly for the alternative weighting matrix M1, a weighted aggregation of each criterion on each of its scenarios using Equation (1) is performed to get an overall weighting matrix M2.
Where w ij denotes the weight of the criterion j in the alternative i at the time of weighting, which is weighted w ij = 1/n.
Then for the initial decision matrix r
x
(x = 1, 2, 3 ⋯ t), the four experts’ expert opinion matrix M
x
(x = 1, 2, 3 ⋯ t) for each alternative is obtained by weighting according to each criterion using Equation (1).
Where w ij denotes the weight of the criterion i in the alternative j at the time of weighting, and that weight w ij = 1/n.
Next, the similarity matrix R
x
between each expert’s opinion on each alternative and the overall weighted opinion was calculated using Equation (4).
Similarity measure
In the previous stage, we calculated the similarity between each expert’s opinions on various options and the overall opinion. In the identification stage, we need to identify the opinions that need to be modified.
First we compare each
Since the other experts other alternatives have reached group consensus, by default there is no need to pay attention to the other guideline similarities, and finally (expert X, alternative I, criterion J) is used to indicate the opinion that needs to be modified.
Recommendation phase
Through the identification of the previous stage, we have found out what needs to be modified, then in this stage it is necessary to integrate the modification proposals and recommend to the expert X how to modify the criterion J of the alternative I.
First of all, we have to find the best and the worst evaluations of the experts for the criteria J of alternative I. Since we are using the score function Equation (2) and the precision function Equation (3), after removing the experts’ opinions that need to be modified, the best evaluation of the criteria J of alternative I is If the expert’s evaluation of criteria J for alternative I is better than the best evaluation If the expert’s evaluation of criterion J for alternative I is lower than the worst evaluation If an expert’s evaluation of criterion J for alternative I is between the best and worst evaluations, then it is sufficient for that expert to continue to fall between the two if modifications are needed.
After recommending the integrated modification suggestions to relevant experts, experts will modify their opinions accordingly based on the provided suggestions. After the modification, we need to repeat the process of reaching a consensus again. In actual situations, due to various reasons, experts may not be willing to modify their opinions, making it difficult to reach a group consensus. Therefore, the next step is to explore how to choose the best alternative in this situation.
Decision process
This section focuses on the decision-making process for implementing the best alternative. The core idea is to evaluate the image blur set of each alternative using a scoring function and an accuracy function, compare the scores and accuracy, and determine the best alternative. There are two situations as follows:
The first scenario is in the case where the experts eventually form a group consensus by revising their opinions several times, as long as all the experts reach consensus, their weights for each alternative and criteria will be uniformly distributed,
In the second case, when there are experts who are unwilling to amend their opinions in each round of opinion revision stage, resulting in the inability to reach a group consensus, we should adjust the weights of these experts by using Equation (5). In this way, we can ensure that their opinions are not ignored and avoid significant deviations in decision-making results due to their opinions.
After implementing the normalization of the expert weights, we use the updated weights for weighting to derive the overall weighting matrix M2. Next, in the same algorithm as in the first case, we select the best alternative by calculating the score and accuracy.
Algorithm overview
In summary, the following are the steps of the consensus and decision-making process:
The experts evaluated each criterion in each alternative in the form of a PFS.
The alternative weighting matrix M1 is calculated using the weighting operator of Equation (1), and once again the overall weighting matrix M2 is derived by weighting for each criterion, and then each expert’s expert opinion matrix M x is obtained by weighting each expert’s individual program criteria separately by the initial decision matrix.
The similarity between each expert’s expert opinion matrix and the overall weighting matrix at each position was calculated separately using Equation (4).
Based on the results of the similarity measure for each expert for each alternative, we compared it with the similarity threshold to identify the experts and alternatives that need to be modified. Subsequently, we further identify the criteria that need to be modified by calculating the similarity of each criterion for that expert’s alternative for that program to the overall.
Based on the preset recommendation rules, the modification suggestions are consolidated and recommended to the experts so that the experts who wish to make modifications can follow these suggestions accordingly.
After each round of expert revisions, the similarity is recalculated and a judgement is made as to whether consensus has been reached.
After all experts who are willing to revise their opinions have done so, we will use Equation (5) to adjust the weights of the remaining experts who are not willing to revise their opinions and have not reached consensus in order to proceed to the next stage of the final decision-making process.
After completing the adjustment of expert weights and implementing normalization, we will perform the weighting calculation of the decision-making session to obtain the overall weighting matrix. With Equation (2) and Equation (3), we can further calculate the score and accuracy of each alternative to arrive at the final ranking result and determine the best alternative.
In order to present the process of the framework more clearly, the specific framework flowchart is shown in Fig. 2.
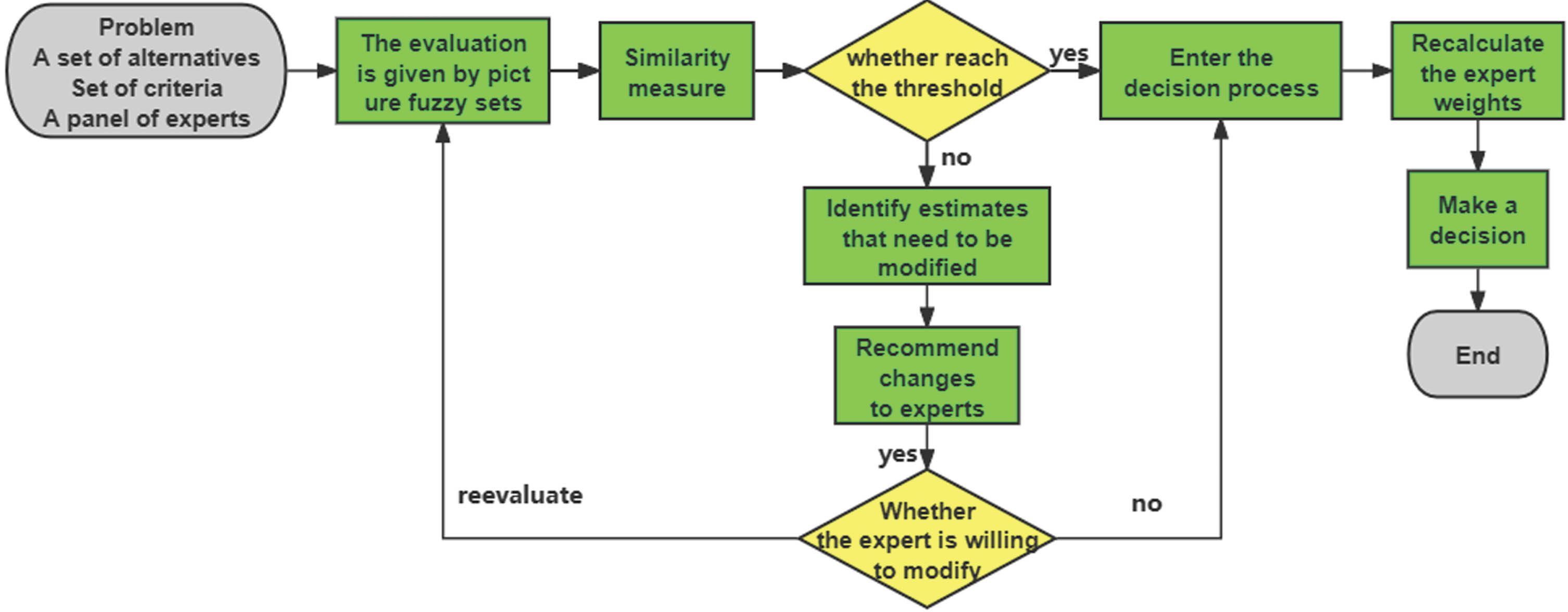
Flowchart of the proposed framework in this article.
We apply the previously proposed decision-making framework to an example application of carbon reduction alternatives for thermal power plants in China. By doing so, we will demonstrate the effectiveness and applicability of the decision-making framework.
Case background
With the development of industry, the emission of greenhouse gases, mainly carbon dioxide, has increased dramatically, and carbon reduction is therefore urgent. Carbon reduction can slow down global warming and thus promote sustainable human health. In addition, the trend towards a low-carbon economy has become a requirement for current social and economic development.
Currently, thermal power plants are one of the major sources of carbon emissions, so reducing carbon emissions from thermal power plants has become an extremely important issue. For different scales, funding, and personnel configurations of thermal power plants, choosing the best carbon reduction plan that suits them has become a very important MCDM problem.
Four experts (e1, e2, e3, e4) in a selected thermal power plant were appointed as experts in the selection of the best carbon reduction alternatives. After the discussion meeting, four alternatives for carbon reduction were tentatively decided, which are: A1: vigorously develop clean energy, such as solar energy, wind energy, hydroelectric energy, etc. A2: develop a circular economy, the thermal power plant resource utilization of wastes to produce some chemical products, construction materials, etc. A3: carry out technological innovations and apply new technologies to reduce carbon emissions. A4: improve energy utilization and reduce carbon emissions through efficient use of energy. Four criteria were also developed: c1: cost input; c2: completion cycle; c3: carbon reduction effect; c4: additional benefits.
Consensus reaching
After clarifying the significance of each parameter of the PFS for evaluation. Set some initial conditions: t = m = n = 4. Since there is no for the experts to have certain information at the beginning, the weight of each expert for each alternative and each criterion in the initial case is divided equally,
Four initial decision matrices are given by four experts using PFS for each of the four criteria for each of the four alternatives P1, P2, P3, P4, details of which are given in Table 2.
Initial decision matrix for the first round
Initial decision matrix for the first round
The data were processed, first for the initial data in Table 2 using Equation (1) to weight each expert’s opinion one by one according to each alternative, resulting in a weighted alternative matrix M1, the values of which are shown in Table 3.
Alternative weighting matrices
Next, for the M1, each criterion is weighted according to each criterion through Equation (1) to find the overall rating of each alternative, and the overall weighted matrix M2 is obtained, and the specific values are shown in Table 4.
Overall weighting matrix
After obtaining theM2, we asked for the evaluation of each expert for each alternative, so we once again weighted the initial decision matrix according to each criterion to find out the evaluation of each expert for each alternative, respectively, to obtain the opinion matrix M1, M2, M3, M4 of the four experts, see Table 5 for details.
Matrix of expert opinions
The next step is to carry out the similarity measure, we use Equation (4) for the M2 and (M1, M2, M3, M4) to obtain the similarity, respectively, to obtain the expert similarity matrix (R1, R2, R3, R4), the details are shown in Table 6.
Similarity Measure Matrix
Recognition matrix
When integrating modification suggestions, we first need to find the best and worst evaluations for the alternative and criterion. Using the identification rules proposed in the previous section, we can obtain the information shown in Table 8.
Modification of the proposal matrix
we compare the results of each similarity measure with the similarity thresholds in Table 6, and we can get the experts who did not reach the consensus with the alternative (e1, A1), (e2, A1), (e3, A3), (e4, A3). We find the experts who should modify their opinions with the alternative, and next we should look for the criteria that need to be modified in the opinion of that expert for the evaluation of the alternative, as detailed in Table 7.
By calculating for Table 7, we can identify the experts, alternatives and criteria that need to be modified, which are (e1, A1, c2), (e1, A1, c3), (e2, A1, c1), (e2, A1, c2), (e2, A1, c3), (e3, A3, c1), (e3, A3, c4), (e4, A3, c1), (e4, A3, c3). Then we have to integrate a set of modification recommendations to recommend to these experts to follow the recommendations.
Based on the recommendation rules proposed in the previous section, we submit the modification suggestions of the modification range of the experts to the experts. The experts modify their opinions and integrate the modified results with the previous unmodified opinions to obtain the second round of initial matrix.
For the initial decision matrix of the second round, we repeated the above calculation process and steps, and carried out the weighted integration and identification of the second round. By analyzing and integrating the evaluations, we identified the opinions that need to be modified as (e1, A1, c2), (e1, A1, c3), (e3, A3, c1), (e3, A3, c4), respectively, and also found out the best and the worst evaluations of these evaluations by using the recommendation rule, so as to be able to better derive the scope of opinion modification. The best and the worst of these evaluations are also derived from the recommendation rules to better derive the scope of opinion modification. In this round of modifications, the first expert insisted on his opinion. Therefore, we only modified the opinions of the experts who were willing to modify them, thus obtaining the initial matrix for the third round, which is shown in Table 9.
Initial decision matrix for the third round
For the third round of the initial decision matrix, we still follow the above algorithmic steps, weighting again and determining whether the similarity reaches the threshold. At the same time, we identify the experts, alternatives and criteria that need to be modified, integrate the modification suggestions and submit them to the experts. We can identify the opinions that need to be modified as (e1, A1, c2), (e1, A1, c3) and (e3, A3, c1). However, the three experts identified in this round all refuse to modify and approve of their evaluation results. Therefore, the CRP ends here.
At this stage, we can find that we have not reached consensus in the end, but our initial goal was to try to reach consensus based on the subjective wishes of experts. Due to the heterogeneity of experts, there are cases where experts are unwilling to modify their opinions, which is actually more common in real life.
In this decision-making session, we go through the decision-making steps presented in the previous section to perform a decision-making process for the selection of the best alternative for this case. Since there are three experts in this case whose evaluations are not willing to be modified, namely, (e1, A1, c2), (e1, A1, c3) and (e3, A3, c1), we use Equation (5) to adjust the weights of the corresponding alternatives and the corresponding criteria for the three experts.
The obtained expert weights are then normalized to obtain the weight matrix as shown in Table 10.
Weighted expert weight matrix
Weighted expert weight matrix
According to the updated expert weights, the expert evaluation matrix of the third round is weighted to get the weighted matrix of decision alternatives, which is then weighted by one criterion for the alternatives to get the final overall decision matrix, and finally, through Equation (2) and Equation (3), we get the final scores and accuracies of the options in the overall decision matrix, as shown in Table 11, and by comparing their sizes, we can judge the best carbon emission reduction alternative of this thermal power plant.
Score and accuracy matrix
It can be determined that the ranking of the alternatives is A1 ≻ A4 ≻ A3 ≻ A2, so the thermal power plant should choose A1: vigorously develop clean energy, such as solar energy, wind energy, hydroelectric energy, etc.
We perform a sensitivity analysis in this section for the expert weight acquisition method proposed in this thesis, varying the parameter λ to observe whether the results will change substantially.
Since we chose λ = 0.5 in the actual calculation process of the case in order to split the difference between the similarity and the threshold and the degree of unawareness of the expert on the weight of the expert in half, but for different companies, there may be different situations. We have selected several cases of parameter λ for a comparative analysis, to analyze whether their results have drastically changed or no.
We selected five cases λ = 0.1, λ = 0.3, λ = 0.5, λ = 0.7 and λ = 0.9 respectively the ranking results are shown in Table 12. In order to show the change in ranking more clearly, a line graph was plotted as shown in Fig. 3.
Sensitivity analysis
Sensitivity analysis

Changes in ranking of alternatives when weight λ changes.
As can be seen in Table 12, we can observe that the ranking results change only when λ = 0.9, which indicates that the equation has a high degree of stability, however, by comparing the degree of fluctuation of the program scores under different parameters λ, we can find see that the degree of expert understanding has a greater impact on which programs are available, and the distance between the similarity and the threshold has a greater impact on which programs are available, so that we can make better decision making.
This section provides a comparative analysis by varying the similarity threshold
The similarity threshold
The following comparative analyses all use the results of different consensus thresholds in the case of λ = 0.5 as shown in Table 13.
Comparative analysis
Comparative analysis
In Table 13 we use requires modification (RM) to denote the number of opinions that require modification by experts, willingness to modify (WM) to denote the number of opinions that experts are willing to modify, feedback rounds (FR) to denote the number of rounds of modification that require modification by experts, and finally degree of consensus (DC) to denote the degree of consensus in the final result.
Based on Table 13, we can clearly summarize the following points: The process of not setting In the process of not setting Without setting Through our analysis, we found that as
As the information age continues to develop, experts in MCDM processes are often disturbed by more fuzzy and uncertain information. To better express an expert’s evaluation of a particular alternative, the PFS introduces neutrality and rejection degrees on the basis of IFS, which can better express the expert’s opinions. However, due to differences in experience, background, and familiar fields among experts, as well as potential conflicts of interest and trust issues between experts in certain situations, group consensus is often difficult to reach in reality. Previous article has mainly been driven by moderators, with experts modifying their own opinions. However, this article is driven by the behavior of experts, first considering their willingness to modify their opinions and then whether a group consensus can be reached. This article proposes a consensus-reaching model driven by expert behavior based on PFS. Furthermore, this article proposes a new method for adjusting expert weights to optimize subsequent decisions when experts are unwilling to change their opinions and no consensus has been reached. The consensus-reaching method and decision-making framework can be widely applied to various MCGDM problems, such as candidate selection, green supplier selection, and optimal alternative screening, etc.
However, this article has shortcomings and limitations in several aspects. First, this article focuses on how to set the expert weights rationally, but the criterion weights are equally important in the decision-making process. This article fails to fully explore the rational setting of criterion weights and only distributes the importance of each criterion equally. Secondly, the application of the described method in real life problems is limited to small-scale decision-making, and the case study also involves only small-scale decision-making. However, when faced with large-scale decision-making, PFS has a high computational complexity due to multiple parameter problems, which becomes a problem to be solved. In the future, R language, Matlab and other tools can be used to realize the proletarianization of the calculation process and reduce the workload of decision makers. Finally, with the development of the information age, the explosive growth of data and the increasing complexity of the decision-making environment, the phenomenon of a few experts making decisions is no longer common. More often than not, large-scale experts are required to participate in decision-making. Therefore, how to generalize the group consensus reaching model and decision-making framework proposed in this article to large-scale group decision-making, requires further research.