
Abstract
Non-speech emotion recognition involves identifying emotions conveyed through non-verbal vocalizations such as laughter, crying, and other sound signals, which play a crucial role in emotional expression and transmission. This paper employs a nine-category discrete emotion model encompassing happy, sad, angry, peaceful, fearful, loving, hateful, brave, and neutral. A proprietary non-speech dataset comprising 2337 instances was utilized, with 384-dimensional feature vectors extracted. The traditional Backpropagation Neural Network (BPNN) algorithm achieved a recognition rate of 87.7% on the non-speech dataset. In contrast, the proposed Whale Optimization Algorithm - Backpropagation Neural Network (WOA-BPNN) algorithm, applied to a self-made non-speech dataset, demonstrated a remarkable accuracy of 98.6%. Notably, even without facial emotional cues, non-speech sounds effectively convey dynamic information, and the proposed algorithm excels in their recognition. The study underscores the importance of non-speech emotional signals in communication, especially with the continuous advancement of artificial intelligence technology. The abstract thus encapsulates the paper’s focus on leveraging AI algorithms for high-precision non-speech emotion recognition.
Introduction
Non-speech emotion recognition is a cutting-edge field that digs into the complex area of comprehending and interpreting human emotions without the use of spoken words. Emotions are an important part of human communication that go beyond verbal representation. Non-verbal emotion recognition investigates the subtle subtleties hidden in facial expressions, body language, and physiological reactions to reveal an individual’s emotional landscape in the absence of word clues [1]. This growing profession aims to untangle the intricacies of human emotion, providing a greater understanding of emotions in a variety of circumstances where verbal communication might be restricted or absent. By leveraging modern technology and computational models, non-speech emotion identification offers new pathways for applications in human-computer interaction, mental health monitoring, and the creation of empathic AI systems. The possibility of unraveling the riddles of nonverbal emotional communication offers promise for a wide range of companies and social developments as academics continue pushing [2].
Emotion classification
How to make machines automatically recognize human emotions must first be based on emotion theory and analyze the description model of emotion theory. Commonly used models of speech emotion include discrete and continuous emotion speech models. Discrete emotion models represent several independent emotions. These emotions are unrelated and clear, suggesting that a particular passage has a separate emotion. Continuous verbal emotions imply that verbal emotions are within the emotional domain. Various emotions have different strengths in each dimension, and all human emotions are at one point in the dimensional space. For the discrete emotion model, each emotion is a discrete entity, single, strong, and distinguishable, and the physiological mode of each emotion (facial expressions, gestures, etc.), tone and sound expression are different, and the various humans Complex emotions are based on different degrees of combinations of these independent emotions. Turner and Otrony summarized the definitions of discrete emotion models by different scholars in academia as shown in the Table 1 [3].
The common independent emotions in discrete emotion speech models include anger, happiness, surprise, sadness, disgust, and neutrality. These emotions are the most obvious, but some scholars have added independent discrete emotions that are not too obvious such as shyness and curiosity or want to be close to other emotions. Emotional speech, how to define a group of emotional speech categories, has different ideas for different experts, and also has different requirements for different applications. An accurate and good independent emotional speech classification still needs continuous discussion and research Fig. 1.
Emotion classification
Emotion classification
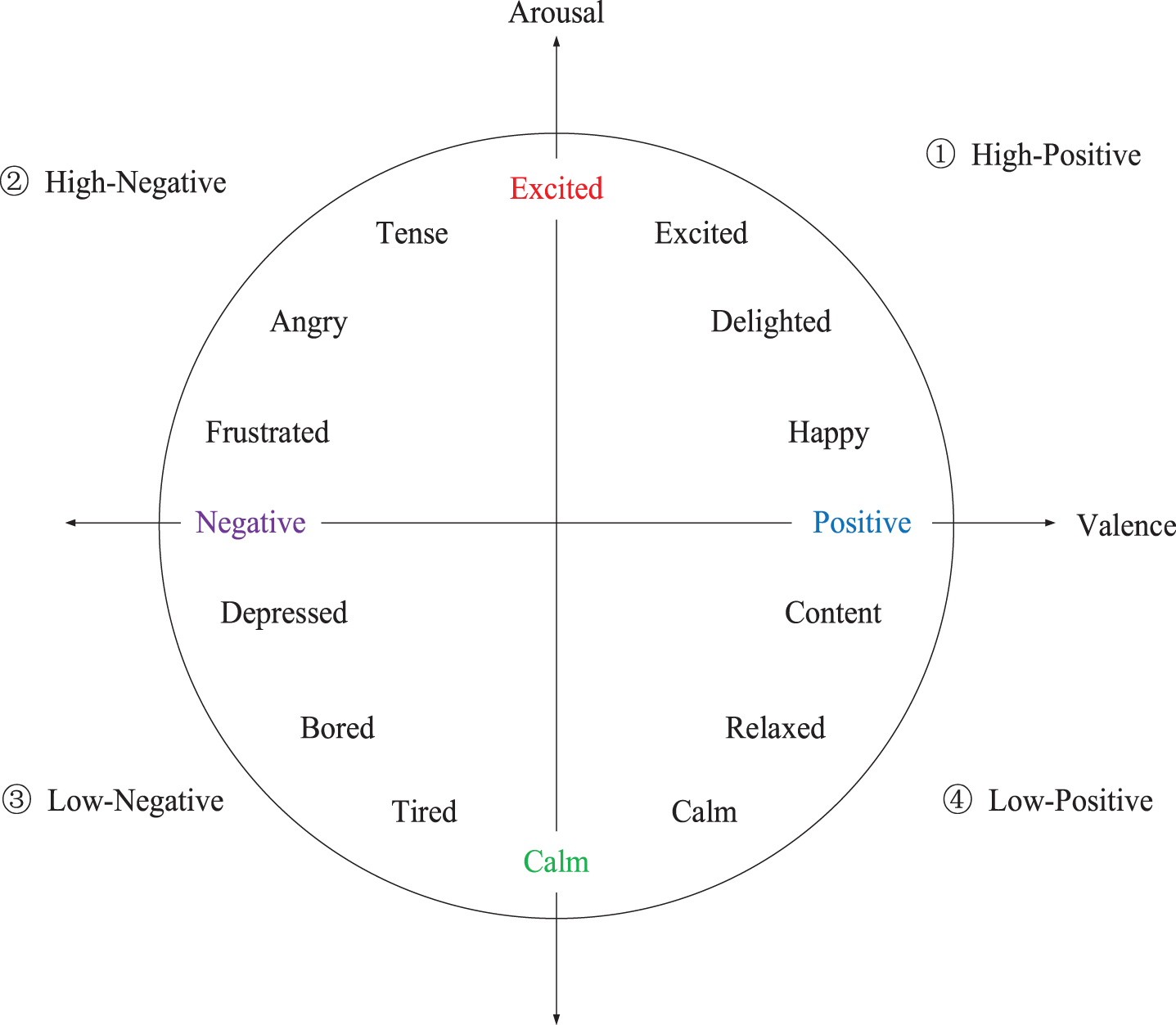
Continuous emotion model.
Figure 1’s continuous emotion model offers a conceptual framework for comprehending emotions more complexly and continuously. The continuous model of emotions recognizes human emotions’ complex and dynamic character, in contrast to discrete emotion models that divide emotions into discrete and separate categories. This paradigm treats emotions as mapped into a two- or three-dimensional space, rather than as discrete entities. A more detailed depiction is made possible by the axes of this space, which stand for various emotional dimensions or facets. Arousal (activity levelexcited, calm), valence (positive or negative), and intensity are a few examples of the particular aspects. Rather than neatly falling into predetermined categories, the approach acknowledges that human emotions are complex and can fluctuate throughout the spectrum. Rather than merely designating an emotion as “happy” or “sad,” for instance, the continuous model permits a more comprehensive description that takes into account variances in the intensity of happiness or sadness.Comparing the two models, the description of the discrete emotion model is relatively concise, which is in line with people’s daily emotion cognition. When modeling and recognition, the category is clear, which is convenient for research. However, human emotions are more complex than simple independent discrete emotions, and in terms of theoretical cognition. There are still some differences in academia. For the continuous emotion model, the emotions of people are mapped to two-dimensional or three-dimensional space. The emotions are more delicate, and the emotions are more real. However, for each sentence, it is difficult to quantify the emotion in space to ensure the quality. Different people have the same emotional speech. There are different feelings, so there are great difficulties in dynamic labeling, and it isn’t easy to standardize.
Non-verbal emotion identification has difficulties in adequately capturing the complexities of human emotions. Ambiguities in face expressions, cultural disparities, and individual differences all provide substantial challenges. Furthermore, the lack of standardized datasets for nonverbal emotional indicators makes the construction of strong models difficult. The changing nature of emotions, along with limited contextual knowledge, adds to the complexity. Addressing these restrictions is critical for the field’s advancement, assuring dependable and culturally sensitive emotion identification in a variety of real-world circumstances.
Contribution of the Study
Non-speech emotion recognition is the study of the feelings expressed by unexpected vocalizations of emotion. In this paper, a nine-category discrete emotion model, happy, sad, angry, peaceful, fearful, loving, hateful, brave, and neutral, was used. Then, we proposed a method of the WOA-BPNN Algorithm.
The research Abbreviations
The following sections of the paper are organized as follows: Section 2 contains a list of related studies. Section 3 discusses the extra phases of the suggested technique. Sections 5 and 6 describe the outcomes of their ranges and discussions. Section 7 concludes the report with a discussion of the findings and suggestions for further research.
Related works
Atmaja et al. [4] suggest combining the silence-removal technique with an attention model to enhance speech emotion recognition ability. According to the findings, using a combination of silence removal and an attention model works better than using either noise reduction alone or an attention model alone. Praseetha et al. [5] examined the association between the emotions and characteristics is learned in order to detect the emotions automatically. In order to identify the feeling in a voice signal, preprocessing, and feature extraction are performed on the input signal. The derived features are then compared with feature vectors stored in the database. Perez et al. [6] utilize the MSP-Podcast dataset to provide a unique framework that looks at combining language and silence representations for emotion recognition in realistic speech. Guerrieri et al. [7] suggest as a first step toward the eventual construction of a Speech Emotion Recognition (SER) system, determining the speaker’s gender identity, a Gender Recognition (GR) module is used. The technology was created to be deployed on social robots to monitor patients who were in hospitals or were living at home. Yunxiang et al. [8] provide made use of the AFEW6.0 database and the Audio/Visual Emotion Challenge (AVEC) database, both of which contained field recordings. Data balance operations were performed on the data sets during the data preparation phase in order to address the issue of data imbalance between datasets.
Matin et al. [9], in categorizing inputs in voice processing, SVM has demonstrated great accuracy. Unique audio datasets have been created to train models for the emotion identification task. The “Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), which is utilized for training the model in this study, is one such speech corpus." Using Python libraries, the pre-processing stage will include the extraction of acoustic features. In this work, the libROSA library is utilized. Fahad et al. [10] examined primarily discussed SER approaches for natural environments, as well as their benefits and drawbacks with regard to speaker, text, language, and recording conditions. It also focuses on SER in a natural context. Byun et al. [11] created a database in order to analyze speech emotion; Korean emotional speech was used, and a feature combination that, when combined with a recurrent neural network model, may improve the performance of emotion detection. Tsouvalas et al. [12] Provide an SER strategy that protects privacy while being data-efficient. This is the first federated SER strategy that, to the best of our knowledge, utilizes both labeled and unlabeled on-device data, which requires federated learning as well as self-training learning. Wen et al. [13] suggest a model called CapCNN, which stands for convolutional neural network and capsule network combined. The benefit of CapCNN is that it supplies the general features and a solution for time sensitivity. According to this study, CapCNN is capable of handling the SER assignment. Our algorithm performs well on the CASIA and EMODB datasets when compared to other cutting-edge approaches. Yadav et al. [14] examine the best machine learning architectures, as well as the system applications, algorithms used, and voice and visual processing. The study offers a detailed examination of the needs of speech and vision systems from the viewpoints of both hardware and software systems. The fields of research and development in speech and vision systems will change as a result of the fast-emerging machine learning technology.
Problem statement
The problem of chosen modalities must be used to train the system on labeled data including instances of various emotions. To ensure correct emotion categorization, it is tough to build neural network architecture, apply the backpropagation algorithm, preprocess the input data, and choose the right features. Depending on the mode of the incoming data, several features and preprocessing methods may be used. In this study, we try to overcome the problem with the help of WOA-BPNN.
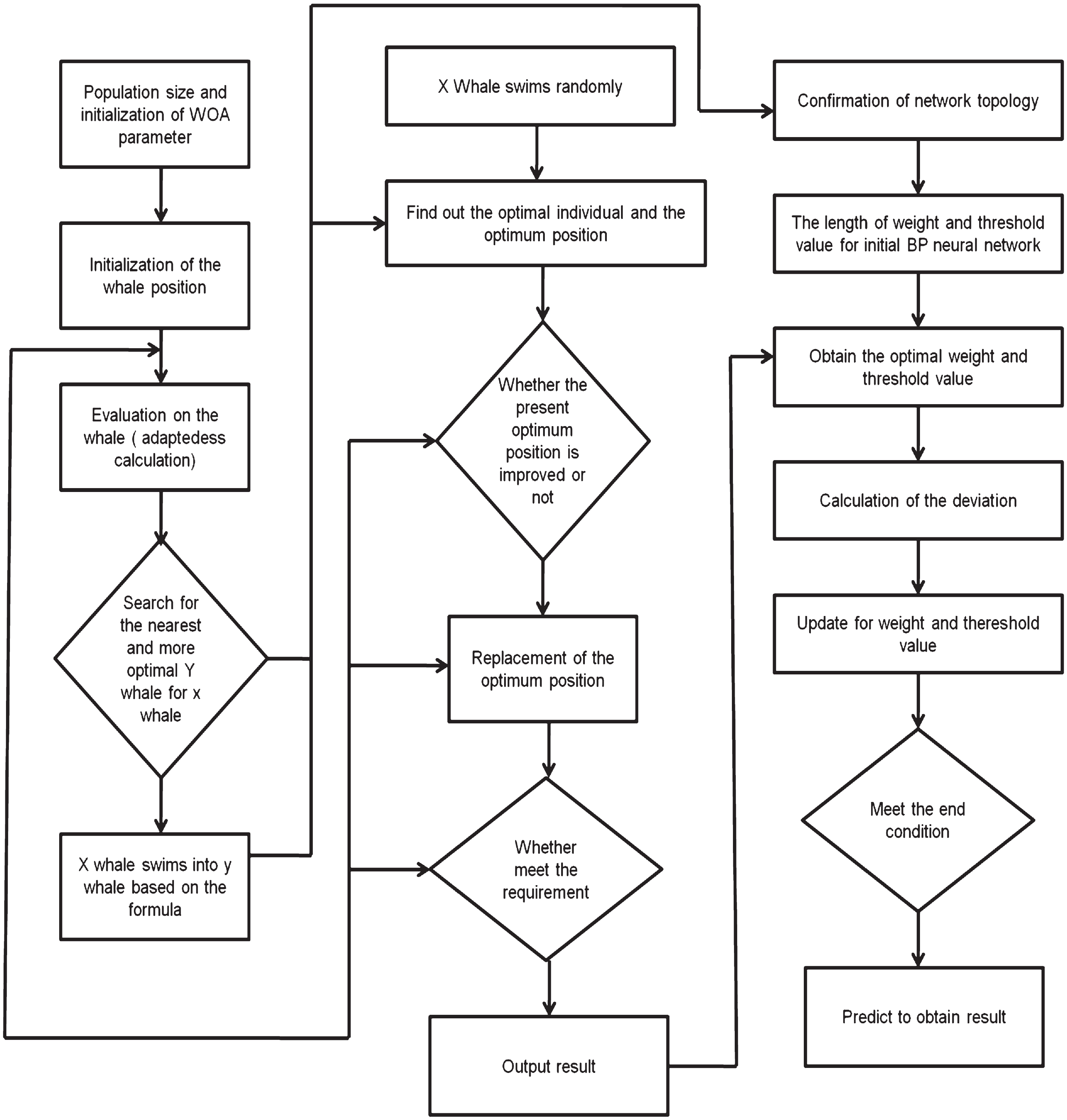
Methodology
In the section, the “Whale Optimization Algorithm and Back Propagation Feed-forward Neural Network (WOA-BPNN)”, in combination with the suggested approach for emotion recognition, are shown in Fig. 2. First, we collected the data set and then explained about the emotion model. A significant non-speech dataset consisting of 2337 instances is first composed as a component of the procedure. After that, a nine-category emotion model is applied to this dataset, which includes feelings like happiness, sadness, anger, calm, fear, bravery, disgust, affection, & neutrality.
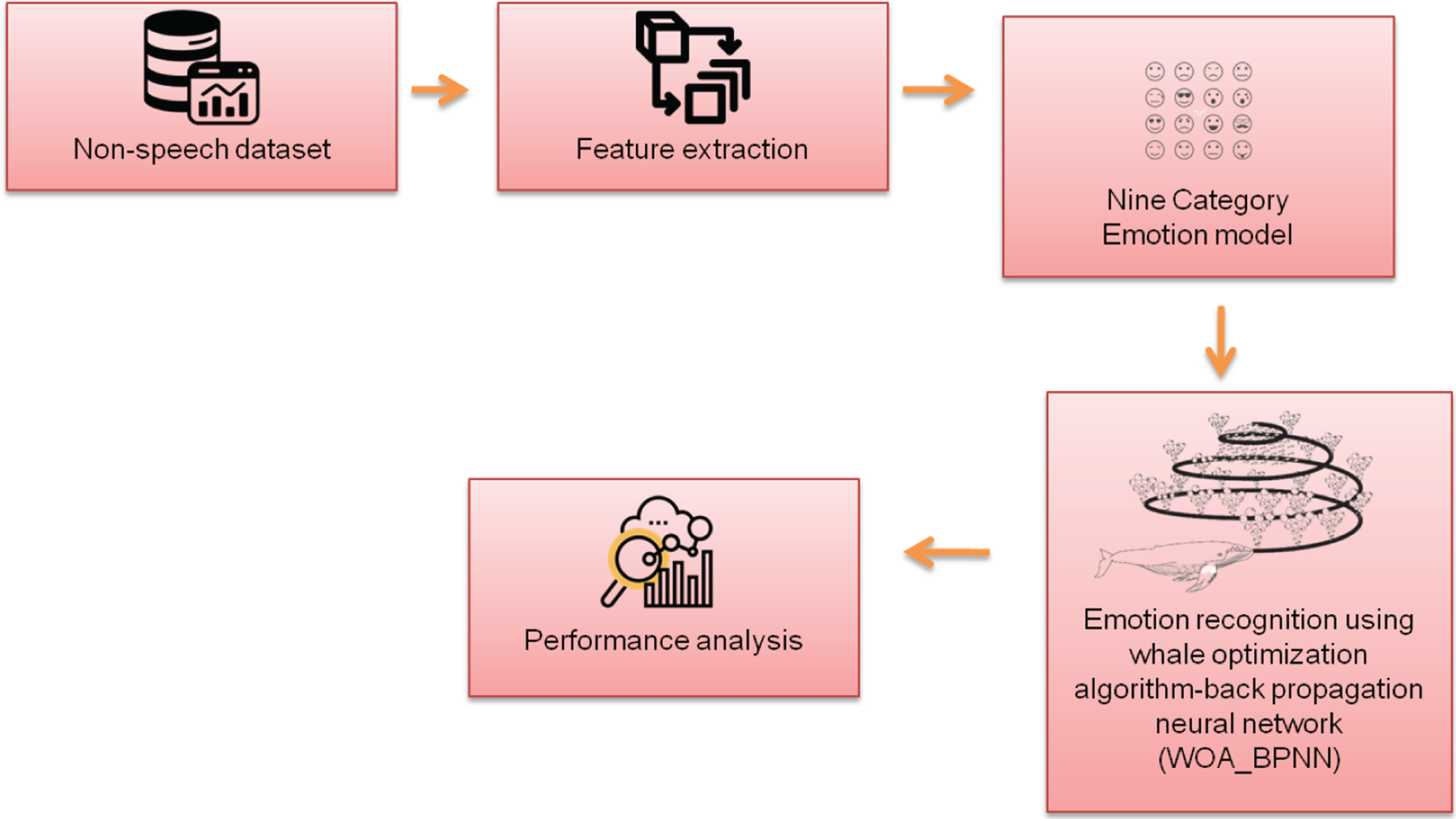
Methodology.
The core of our analysis was a homemade non-speech dataset that included a sizable collection of 2337 occurrences of non-speech data. This extensive dataset’s inclusion of a wide variety of non-speech audio recordings was carefully selected to allow for a thorough investigation of its properties. The method produced impressive results as it recovered detailed 384-dimensional feature vectors from each data point.
Nine classification emotion model
This article independently designed a nine-category emotion model. The nine branches are happiness, sadness, anger, peace, fear, bravery, disgust, affection, and neutrality. The four emotions correspond to each other in pairs, as shown in Fig. 3.
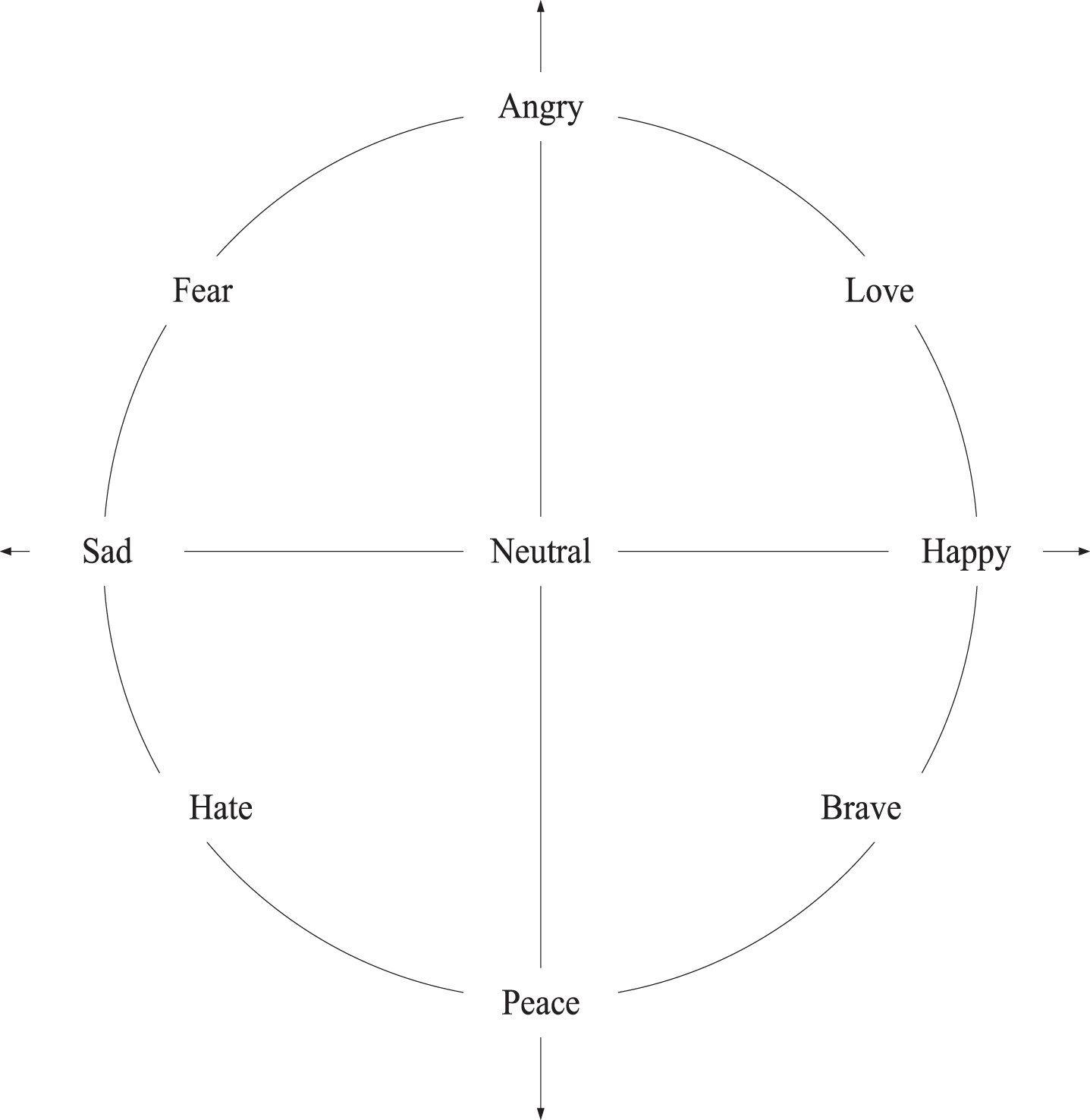
Nine-category emotion model.
There is no complex between the nine emotions. For example, surprise is a compound emotion, which itself includes happy surprise and scared panic.Their pairwise correspondence can fully express a person’s essential emotional characteristics, whether it is the x-axis of happiness and sadness or the y-axis of calmness [15].
Back Propagation Feedforward Neural Network, abbreviated as BPNN [16, 17]. Backpropagation involves obtaining the error from the expected result by comparing the practical output of the output layer with the expected result, followed by adjustment of the web weight among the final hidden layer and its output layer by the associated error equation. After that, the network weights between them are adjusted by providing oil feedback until the map weight modifications between the input layer and the first hidden layer are finished, from the last hidden layer to the penultimate hidden layer, etc.
There is a feedback loop in the output layer that serves as an input to the input layer, or it can be understood as a feedback loop in the control system block diagram, which can be represented by a directed loop graph or an undirected graph, as shown in Fig. 4.
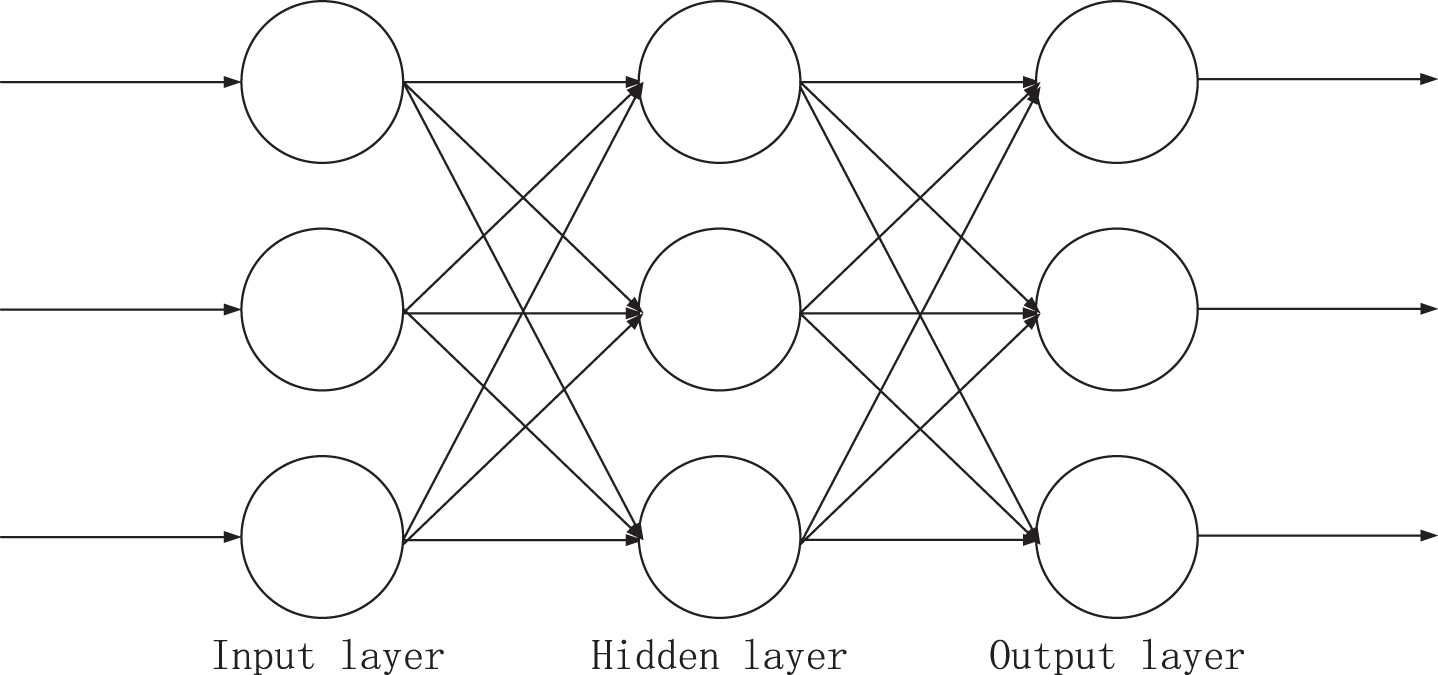
Architecture of BPNN.
Equation 1 shows the multiplicative weights and the corresponding connectionweights of the outputs from those of each member of the former network layer.
Equation 2 provides the expression for calculating the output of neurons.
Within the equations: “ f () stands for activation function, n indicates the quantity of neurons in the network layer, the network layer,
A brand-new meta-heuristic method for intellectual optimization called The Whale Optimization method (WOA) was introduced in 2016 by Mirjalili et al. [18, 19]. Its mathematical model’s calculation method mimics a particular foraging behavior of individual humpback whales, which is known as bubble netting. WOA’s hunting behavior is tracked using random or current best search agents in the space. The prey’s attack behavior simulates humpback whales’ foam net attack mechanism by spiraling upward. The hunting behavior of humpback whales includes two stages. The exploration stage before determining the general location range of the prey. The development stage after determining the general location range of the prey. The value of the vector parameter A is used to control the conversion between these two stages of the humpback whale. The position movement trajectory of the humpback whale during the development phase can be simulated using a spiral rise, which means that the humpback whale will reduce the surrounding circle while updating its position. The algorithm divides the position update in this phase into two states. It uses the value of a random parameter pbetween the [0,1] interval to achieve the replacement of these two states.
The definition of the WOA algorithm is explained as follows. When |A| ⩽ 1 the algorithm was in the development stage, the foraging activity by humpback whales was unique in terms of searching for food in foam webs.The dietary method contains a contraction and encirclement mechanism and a spiral rise mechanism, which are determined by the size of the parameter p. The mathematical models of the two processes are divided into two situations, as shown in Equation 3.
When p ⩽ 0.5 executing the contraction bounding mechanism based on the best proxy position of the current generation and reducing the parameter. Update the part of the humpback whale at the next moment by counting the value of A. WOA assumes that its goal hunt object is a present top prospect position or near top prospect position. Once the best possible agent has been identified, the other search agents adjust to the potential solution, and the most effective agent to update their positions will update the mathematical model in the next time step. That is, if the parameter A obtains a random value in the [–1, 1] interval, the updated location for the searching proxy at the next moment can be defined at any position from the initial location for the searching proxy to the current best location. The update of the new specific position at the next moment is completed through the duplication
When p > 0.5, execute the spiral up mechanism. During the spiral ascent process, first calculate the space among the humpback whale at the present proxy location (x, y) and the prey at the optimal position (x, y), and then renew the location based on an equity shown in the second equation of Equation 3.
Within the equation: t stands for the present count of iterations, X (t) represents a current location, and X best (t) represents the best location. Both A and C are factor vectors, A = 2a · (r - a), C = 2r. r an arbitrarily generated vector with a value among [0,1] intervals, a linearly decreasing from 2 to 0 during the iteration process, b as one fixed number, l as one free value.
The three fundamental WOA techniques are surrounding the prey, searching for prey with a spiral bubble net. The WOA’s enhancement procedures looked like this:
“Where W is the current position, t is the current iteration, W * is the location of the best solution, and q is a random number between [0, 1], and a declines linearly from 2 to 0 during iteration”.
“where b is a constant, l is a random number between [–1,1], p is a random number between [0,1]”.
It is clear that the WOA optimization method is simpler to develop, has a more straightforward structure, and only needs a small number of parameters to be changed. It is necessary to provide in advance information on population size and iteration count as shown in Algorithm 1.
In this work, 2337 non-speech audio files were intercepted using Pr software, and they were made into a self-made dataset which has been uploaded into the ieee-dataport.org website, which has a DOI number of 10.21227/3h06-8204. Extract the 384-dimensional feature vector of each data in the dataset. To name a few: F0 envelope, short time beyond zero rate, and Meier cepstral coefficients. This 384-dimensional feature vector has been applied to the input layer for backward-feed forward neural network, and a preceding discrete nine-classification sentiment model has been applied to its output layer for backward-feed forward neural network [20].
Finding an optimal number of hidden layers will lead to a better classification. Using any number of hidden layers as X (t) of the whale optimization algorithm, the recognition rate can be optimized by the whale optimization algorithm by infinitely approximating X best (t). Workflow reference Fig. 5.
Implementation of the process.
The number of weights and thresholds that make up the proposed WOA-BPNN’s dimension dim is calculated as follows:
“Where g1 represents the number of nodes in the first hidden layer, g2 represents the number of nodes in the second hidden layer, and g3 represents the number of nodes in the third hidden layer”, respectively.
A Validation of self-made dataset using improved algorithms
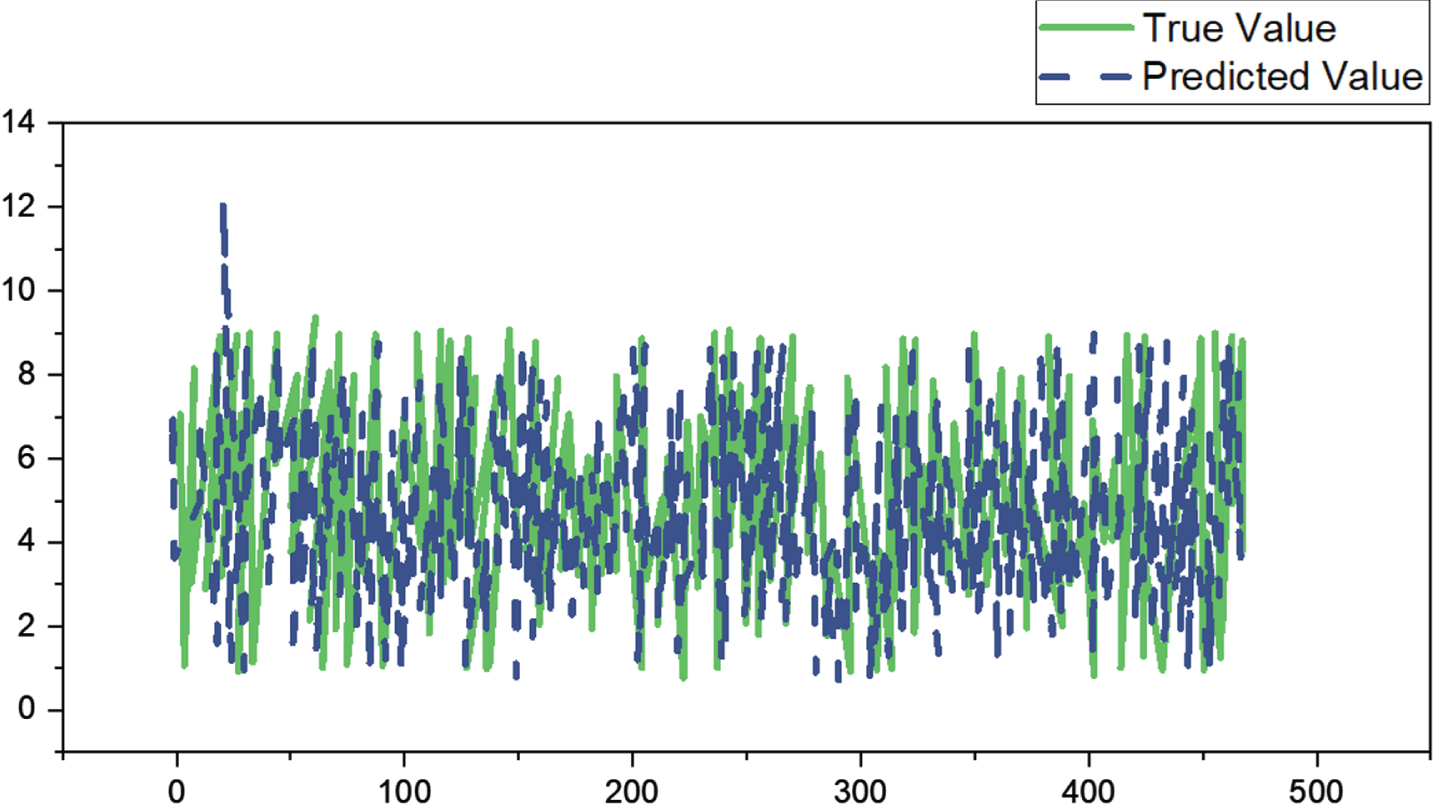
After augmentation, the self-created data collection has 2337 audio files. The machine learning results for recognition using the enhanced BPNN algorithm are shown in the Fig. 6. Refer to Figs. 6 and 7, where 20% of the data set was utilized as the test set and 80% of the data set as the training set.
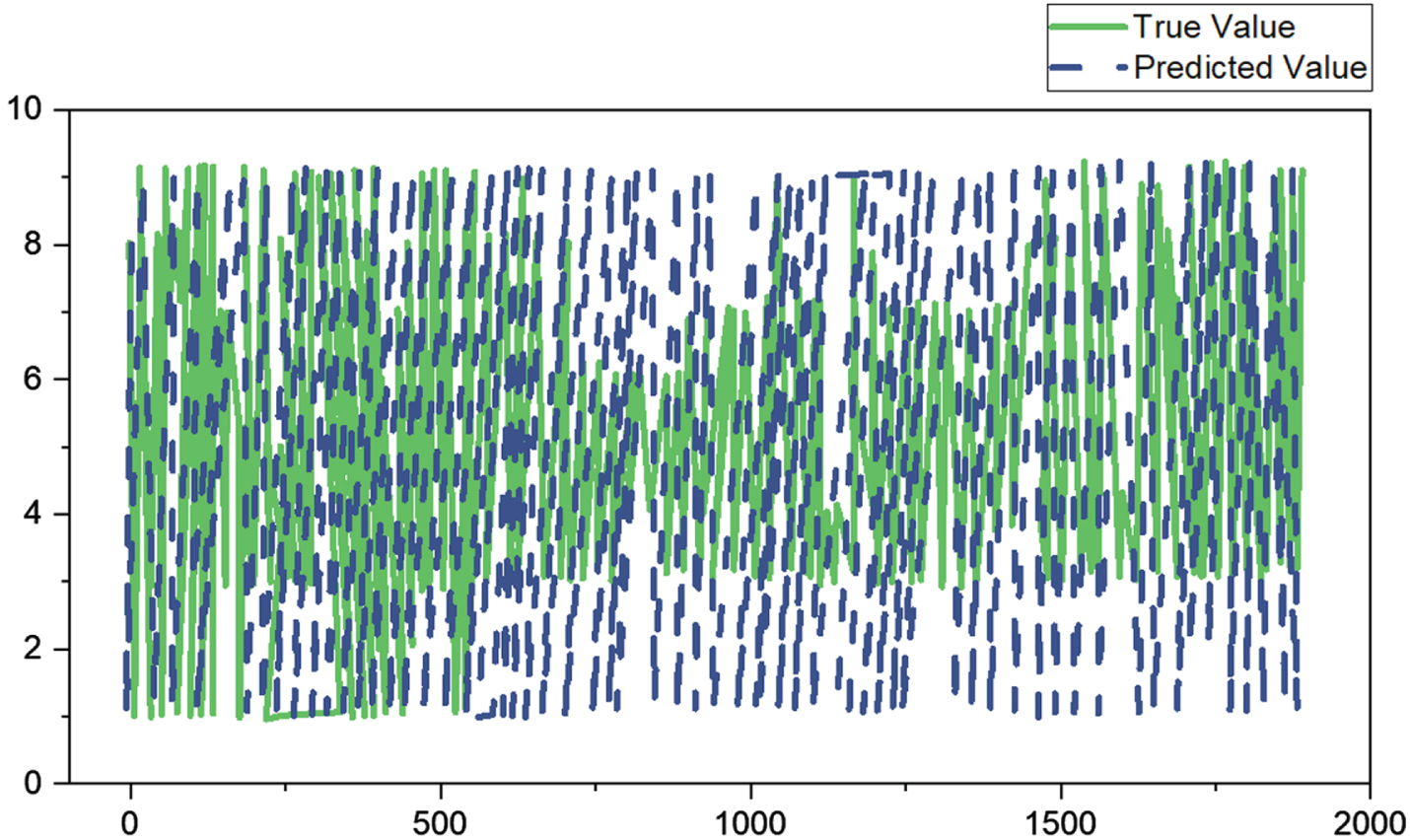
Results of a self-made dataset training set.
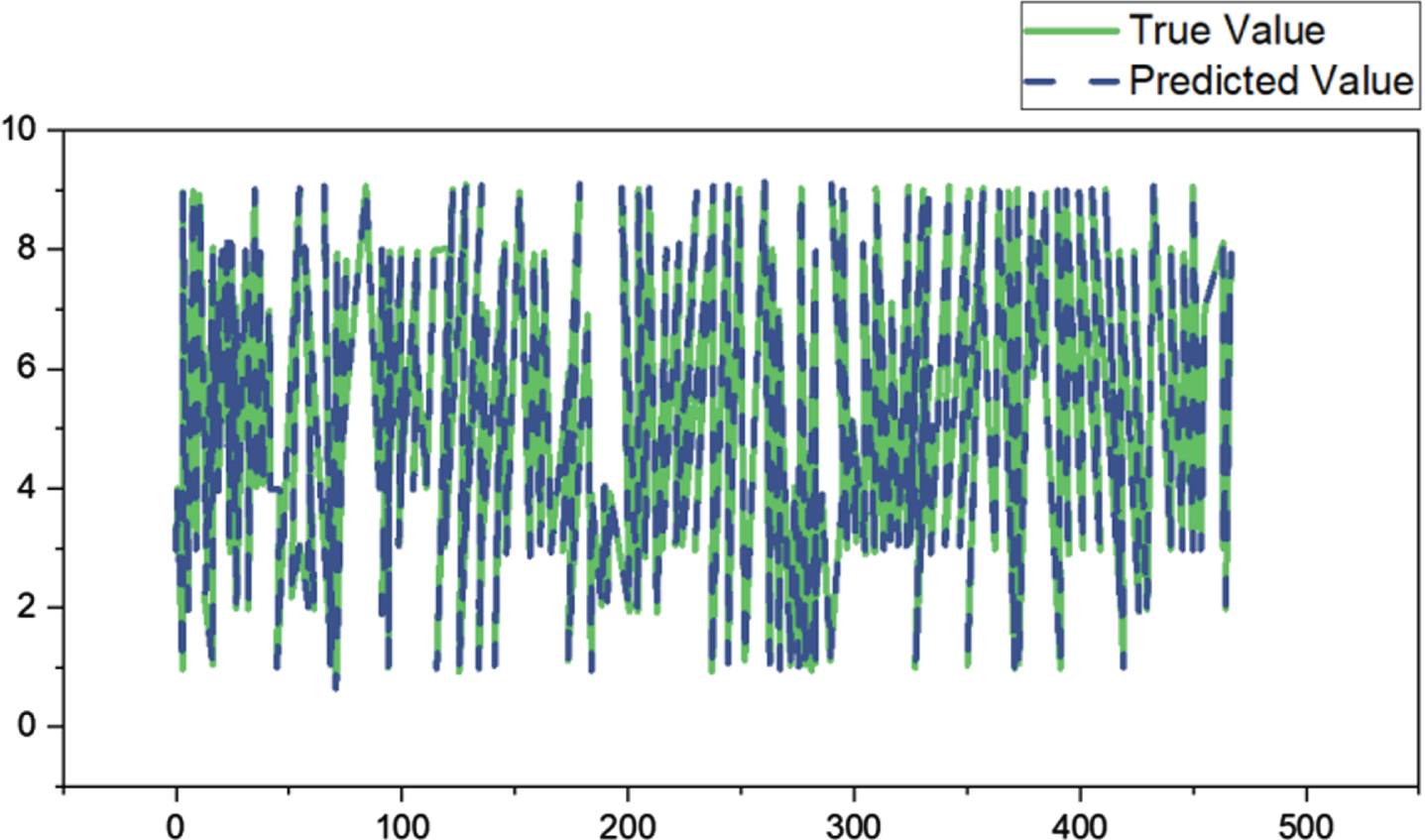
Self-created dataset test set identification outcome.
After augmentation, the self-created data collection has 2337 audio files. The recognition outcomes utilizing the original BPNN machine learning method are shown in the figure. Refer to Figs. 8 and 9 for further information. 80% of the data set was utilized as the training set, and 20% as the test set.
Non-verbal emotion recognition is the correct identification and classification of emotions transmitted by nonverbal clues, obtaining a high level of accuracy in emotion detection via facial expressions, gestures, or physiological indications. In the realm of non-speech emotion detection, two models, the Backpropagation Neural Network (BPNN) and the Whale Optimization Algorithm-enhanced BPNN (WOA-BPNN), were tested for their accuracy in recognizing distinct emotions. Happiness, sadness, anger, calm, fear, bravery, disgust, affection, and neutrality are among the emotions evaluated. According to the findings, BPNN beats WOA-BPNN in identifying Happiness, with an accuracy of 98.6% vs 87.7%. WOA-BPNN, on the other hand, recognizes Fear, Bravery, and Neutrality with significantly higher accuracy, shows as Fig. 10 and Table 2. These findings imply that the model used may be determined by the emotion being recognized, underlining the subtle nature of non-verbal emotion detection tasks.
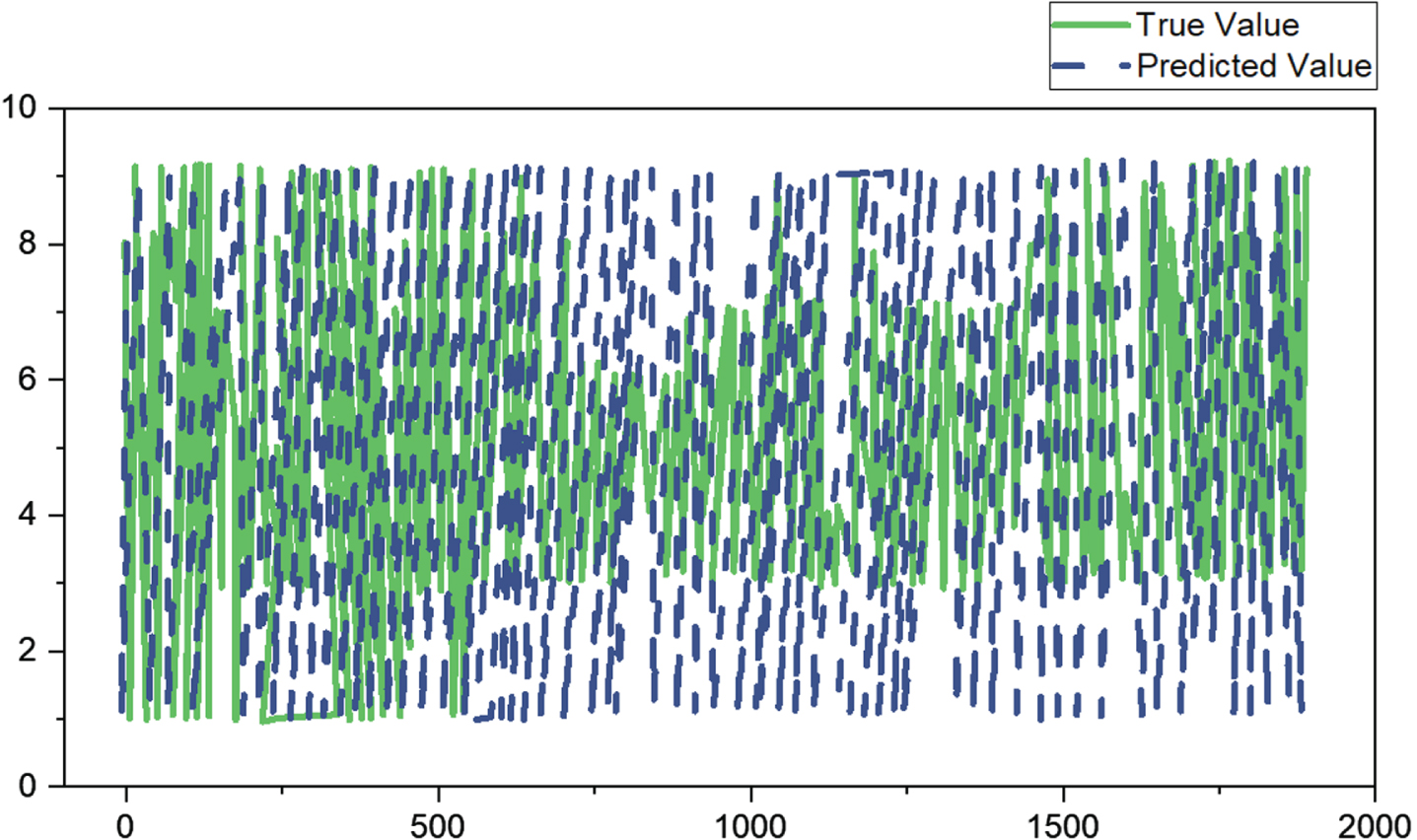
Results of a self-made dataset training set.
Self-created dataset test set identification outcome.
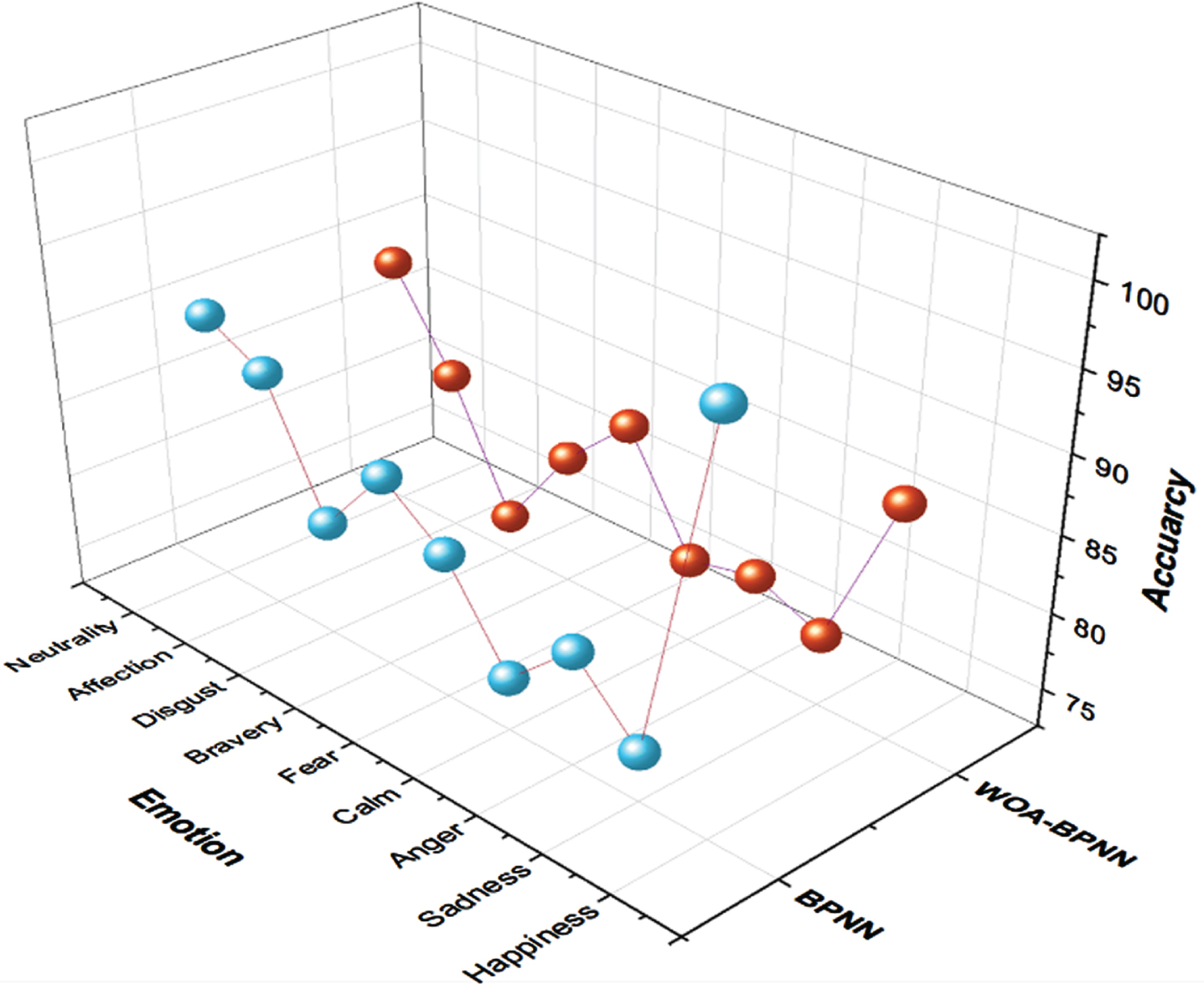
WOA-BPNN accuracy graph.
Comparison of results from different algorithms and datasets
The study used two alternative methods to validate a self-made data set for nonverbal emotion identification in this study: the BPNN and the WOA-BPNN. The data set, which included 2337 enhanced audio recordings, was separated into training and testing sets, with 80% utilized for training and 20% for testing. The findings indicated nuanced performances of BPNN and WOA-BPNN across distinct emotions, stressing the necessity of selecting a suitable model for certain emotional categories. Notably, BPNN outperformed WOA-BPNN in detecting happiness, whereas WOA-BPNN outperformed in recognizing fear, bravery, and neutrality. The speech emphasizes the complexities of nonverbal emotion detection tasks and emphasizes the need to address both algorithmic advancements and emotion-specific model selection. The findings add essential knowledge to the area, leading future studies in enhancing emotion detection algorithms based on the intricacies of different emotional displays.
Conclusion
The study is to discuss non-speech emotion identification, which entails determining emotional states from sounds that do not include spoken communication. In this study, the Whale Optimization Algorithm (WOA) is employed to simulate the social behavior of humpback whales, enhancing its suitability for optimizing neural network parameters. The fine-tuning of Back Propagation Neural Network (BPNN) with WOA aims to improve convergence, potentially avoiding local optima and enhancing model resilience and generalization. The research utilizes a self-made non-speech dataset, classifying it into nine emotion categories. Comparative analyses between the original and speech-modified vector sets reveal that the enhanced WOA-BPNN algorithm outperforms the conventional BPNN, achieving a recognition accuracy of 98.6% compared to 87.7%. The study suggests future work involving semantic recognition of audio files, encompassing both speech and non-speech emotion recognition. The conclusion section is acknowledged as being general and may benefit from a more explicit representation of the manuscript’s content and purpose. The study recognizes the use of a self-created non-speech dataset, but the limits associated with its size and variety may impair the model’s applicability to real-world circumstances. A larger and more diverse dataset may improve the model’s resilience. Extending the concept to real-time applications might be a promising direction for future study. Addressing the difficulties involved with processing and identifying non-verbal emotions in real-time circumstances will improve the suggested approach’s practical usability.