
Abstract
Existing multi-hop knowledge graph question answering (KGQA) methods, which attempt to mitigate knowledge graph (KG) sparsity by introducing external text repositories instead of leveraging the question-answer information itself, ignore the semantic gap between the question modality and the knowledge graph modality as well as the role played by neighboring entities in the best answer selection. To address the above problems, we propose a Joint Reasoning-based Embedded Multi-hop KGQA (JREM-KGQA) method, which addresses these issues through three key innovations: 1) Early Joint Embedding. We construct a Question Answering-Knowledge Graph-Collaborative Work Diagram (QA-KG-CWD) and train the diagram using a knowledge graph embedding (KGE) model. This not only alleviates the knowledge graph sparsity but also effectively enhances the model’s long-path reasoning ability. 2) Semantic Fusion Module. We narrowed the semantic gap between the question modality and the knowledge graph modality through the semantic fusion module to achieve more effective reasoning. 3) Node Relevance Scoring. We employ three node relevance scoring strategies to ensure that the best answer is selected from the huge knowledge graph. We evaluated our model on MetaQA as well as PQL datasets and compared it with other methods. The results demonstrate that our proposed model outperforms existing methods in terms of long-path reasoning ability, effective mitigation of knowledge graph sparsity, and overall performance. We have made our models source code available at github: https://github.com/feixiongfeixiong/JREM-KGQA
Introduction
KGQA is a key technology in the field of natural language processing (NLP), aiming to find answers to natural language questions from structured KGs. Since this task have been proposed, a large number of researchers have done meaningful work in this field.
The previous works (Hu et al. [1], Cui et al. [2]) primarily focused on answering simple questions. For instance, Zhang et al. [3] proposed a KGQA model based on Bayesian neural networks, which addressed interpretability issues in KGQA using Bayesian methods. Wang et al. [4] introduced a multi-task learning framework that achieved notable results by incorporating three subtasks: entity recognition, entity linking, and relation prediction. These subtasks assisted in completing the multi-hop KGQA task. In recent years, with the continuous improvement in the accuracy of simple question answering, researchers(Wang Xin et al. [5], Saurabh et al. [6], Xu et al. [7])’ attention has shifted from simple questions to complex questions. Compared to simple questions, complex questions typically involve multiple relations internally and require multiple inferences on the KG to obtain the answer. He et al. [8] proposed a teacher-student model that addressed the issue of false path reasoning by having a student network query answers and a teacher network learn intermediate paths. Hu et al. [9] introduced a generative approach for KGQA, which improved model generalization by incorporating three subtasks: entity disambiguation, relation classification, and logical form generation.
Although researchers have made progress in the field of multi-hop KGQA, they still face certain challenges. In reality, KGs are often sparse, and when models attempt to reason across longer paths, the absence of any triple along the path can result in the failure to retrieve the correct answer.
To address this challenge, researchers have introduced external text corpora to alleviate the sparsity of KGs. For example, Thai et al. [10] proposed a case-based reasoning approach that retrieves similar questions or reasoning chains from a historical case repository to form new reasoning chains, thereby mitigating the sparsity of KGs. Similarly, Shi et al. [11] introduced TransferNet, which extracts textual triples from external corpora and obtains answers through step-by-step reasoning, offering a high level of interpretability. While the approach of incorporating external text corpora has shown promising results, it is not always possible to gather suitable text resources for all KGs, thus posing limitations..
Recently, some methods have incorporated knowledge graph embedding techniques to alleviate the sparsity of KGs. For instance, Saxena et al. [12] proposed the EmbedKGQA, which embeds both the KG and the question into the same space and predicts answers by scoring candidate entities. Wang et al. [13] argued that previous embedding-based methods overlooked higher-order relations and introduced a multi-hop KGQA model based on hypergraphs and reasoning chains. This method models the KG using a hypergraph-based KGE module, capturing higher-order relations among entities and achieving promising results. Li et al. [14] argued that Saxena et al. [12]’s work did not consider the path factor and proposed a path-aware multi-hop KGQA model. This model incorporates a path retriever to capture the relevance between the question and paths, achieving state-of-the-art results on multiple datasets.
However, these methods, such as PKEEQA [15] and RceKGQA [16], face limitations.
1) There are deficiencies in the utilization of information in QA pairs. QA pairs are knowledge in themselves and can provide more complex relations to the KG and alleviate KG sparsity.
2) There are deficiencies in the fusion of questions and KGs. The independent encoding of LM+KG (language model + knowledge graph) is adopted, which seldom considers the semantic gap between textual modality and KG modality, which limits the model’s ability to reason over long paths.
3) There are deficiencies in the selection of the best answer. The answer selection process overlooks the role of a node’s neighbors, focusing only on the node itself. Yet, neighboring information can offer richer context and evidence for choosing the best answer.
This paper aims to present an integrated approach to simultaneously address these challenges.
In this paper, we try to mitigate KG sparsity by utilizing information from the QA pairs themselves rather than relying on external text repositories. We construct QA-KG-CWD for reasoning, which compensates for the missing links in the KG and cleverly converts the multiple reasoning processes on the monadic KG into a single reasoning process on the multivariate KG, enhancing the model’s long-path reasoning capability.
To achieve deeper fusion between the question features and the KG features, we cross-fuse the question vectors encoded by the text encoder with the relation vectors encoded by the knowledge graph embedding generator through the semantic fusion module.
To ensure that the best answer is selected from a large number of entities, we employ three node relevance scoring strategies to filter the candidate entities from different perspectives.
This paper’s key contributions are summarized as follows:
1) Proposing joint reasoning by constructing QA-KG-CWD significantly improves the model’s long-path reasoning ability and alleviates KG sparsity.
2) Proposing a semantic fusion module that narrows the semantic gap between the question modality and the KG modality, enhancing the model’s long-path reasoning capability.
3) Designing a node relevance scoring module that effectively improves the model’s prediction ability.
4) Conducting extensive comparative and ablation experiments to demonstrate the effectiveness of the proposed method.
Related work
Researchers have proposed various methods to solve the Multi-hop KGQA tasks.
Some researchers (Ye Liu et al. [17], Yawei Sun et al. [18], Yu Gu et al. [19]) have adopted semantic parsing approaches to fulfill KGQA tasks. By utilizing semantic parsing grammar tools or encoder-decoders, this approach effectively transforms intricate questions into structured logical expressions. These expressions are then employed to query the KG and retrieve the corresponding answers. These methods provide clear reasoning but heavily depend on the design of semantic representations.
Some other researchers (Jiale Han et al. [20], Gaole He et al. [21]) have used information retrieval methods to perform KGQA tasks. The fundamental concept of this approach is to construct a subgraph of the KG based on the given question. Subsequently, graph matching techniques are employed to retrieve the answer from the constructed subgraph. However, the neighborhood size of the subgraph limits the range of answers that can be selected by the model, and larger subgraphs result in significant computational overhead.
Saxena et al. [12] found that KGE has not yet been applied to multi-hop KGQA tasks and therefore proposed an embedded multi-hop KGQA method. It is divided into three modules: the question embedding module, the KGE module, and the answer selection module. The question embedding module embeds the question, while the KGE module is responsible for embedding the KG. The answer selection module employs a scoring function to evaluate the candidate entities and selects the entity with the highest score as the predicted answer. This class of methods goes beyond the limitation of local subgraphs and performs well in coping with KG sparsity.
Weiqiang Jin et al. [22] argued that Saxena et al. [12] did not consider the path factor, so they proposed the Rce-KGQA model. The model performs an initial answer screening in the first stage and conducts a refined selection in the second stage. Unlike previous studies, Rce-KGQA is the first model that considers the relational direction and order information of a question and possesses better performance on multiple datasets.
However, none of the above methods consider the role played by QA pair information in coping with KG sparsity, and the reasoning performed is done on a monadic KG, which can limit the model’s ability to reason over long paths as well as to cope with KG sparsity. Second, the above embedded KGQA methods (Saxena et al. [12], Weiqiang Jin et al. [22]) all use LM+KG independent encoding, which does not take into account the problem of deeper fusion between the questions and the KG. In addition, the relaxation of the subgraph neighborhood restriction mentioned by the above researchers (Saxena et al. [12], Weiqiang Jin et al. [16], Jiao et al. [22] and Wang et al. [23]), although it provides a wider range of choices for answer selection, it also introduces too many noisy entities, which is not conducive to the selection of the bestentities.
To tackle the aforementioned issues, this paper proposes a Joint Reasoning-based Embedded Multi-hop KGQA method. Compared with previous models, we construct QA-KG-CWD, which performs the multi-hop KGQA task on a multivariate KG, thereby enhancing the model’s ability for long-path reasoning. Meanwhile, since QA-KG-CWD introduces QA pair information, this will greatly alleviate the KG sparsity. Secondly, we propose a semantic fusion module for deeper feature interaction between question features and KG features, which will effectively improve the ability of the long-path reasoning of the model. Moreover, we design a node relevance scoring module that employs three different scoring strategies to select the best entities from the KG.
Model
Problem Definition: We define a KG as G (E, R). G is a directed graph, E represents the set of entities and R represents the set of relations. The knowledge in the KG can be represented as K ∈ (h, r, t). Where h represents the head entity, r represents the relation, and t represents the tail entity. Given a question Q, the subject entity involved in the question is called the topic entity. The KGQA task can be defined as finding an entity c, with the highest probability, from the set of candidate entities C ∈ E, as the answer to question Q.
The proposed model consists of five components: a text encoder, a knowledge graph embedding generator (KGE Generator), a semantic fusion module (SF Module), a node relevance scoring module (NRS Module), and an answer prediction module. Figure 1 illustrates the overall architecture of the Joint Reasoning-based Embedded Multi-hop KGQA (JREM-KGQA) proposed in this paper.
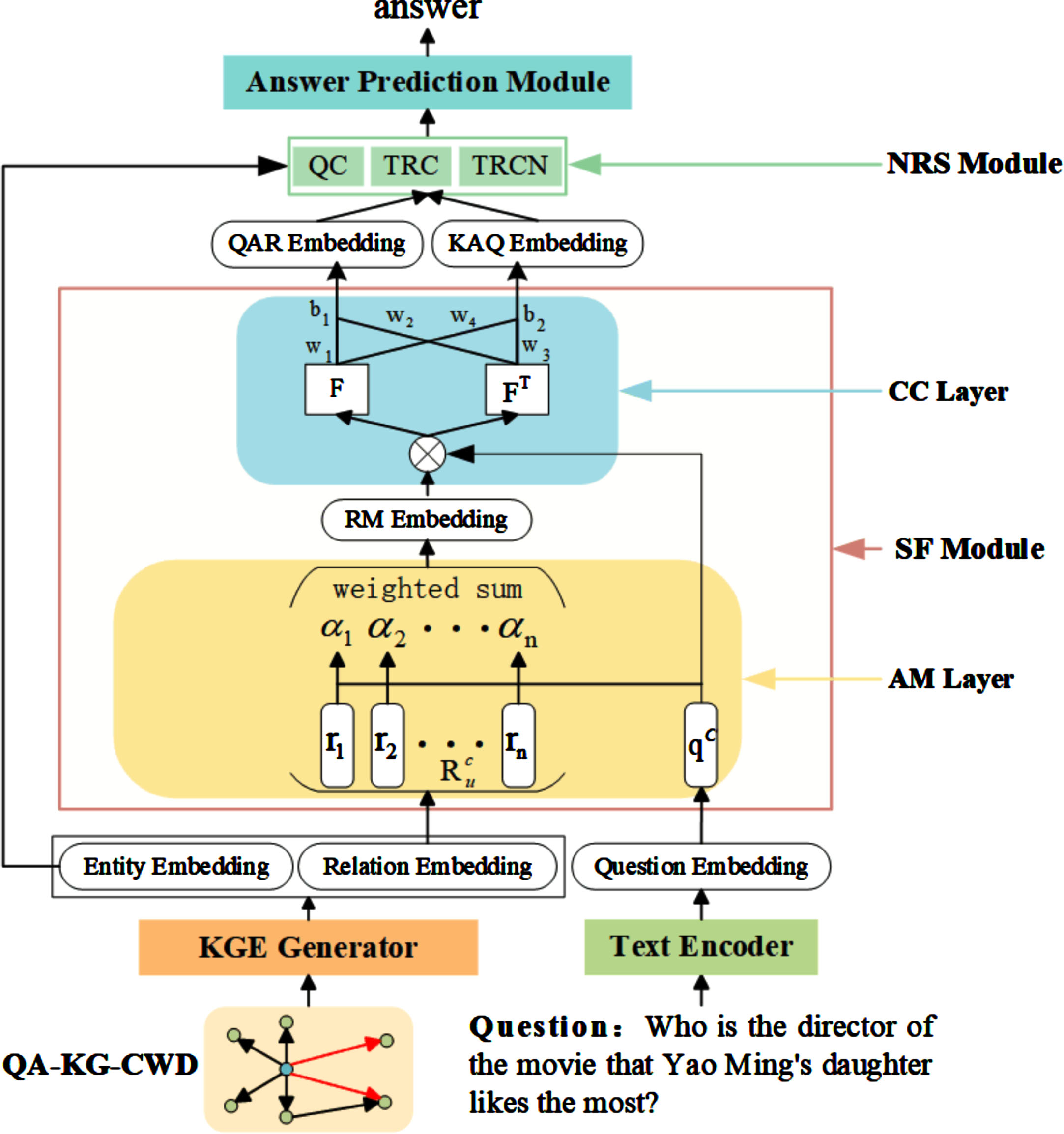
The structural diagram of JREM-KGQA.
First, we construct a Question Answering-Knowledge Graph-Collaborative Work Diagram (QA-KG-CWD), and encode it using the KGE Generator to achieve early fusion of features between the question and the KG, obtaining the required relation embeddings and entity embeddings for subsequent reasoning. Second, we input the question into the text encoder to obtain the required question embedding for subsequent reasoning. Then, we input the question embedding and relation embedding into the Semantic Fusion Module (SF Module) for feature fusion, obtaining the Knowledge Aware Question Embedding (KAQ Embedding) and Question Aware Relation Embedding (QAR Embedding). After that, we input the Question Aware Relation Embedding, Knowledge Aware Question Embedding, and Entity Embedding into the Node Relevance Scoring Module (NRS Module) for relevance scoring to get the scores of the candidate entities. Finally, the scores of the candidate entities are input into the Answer Prediction Module to get the prediction results.
To fully utilize the information of QA pairs, alleviate KG sparsity, and enhance the model’s ability for long-path reasoning, in this section, we will construct QA-KG-CWD, and then encode it using the KGE Generator.
First of all, to exclude the interference of the topic entity and construct the composite relation in QA-KG-CWD, we need to preprocess the QA dataset. In addition, to avoid the risk of data leakage, we only process the training set of the QA dataset. We replace the topic entities in the questions with the string ’NE’ to get the set of composite relations, denoted as R multi . For ease of distinction, we denote the set of relations in the original KG as R single .
Next, we form a triple <topic entity, composite relation r multi , answer entity>by combining the composite relation r multi ∈ R multi with its corresponding topic entity and answer entity. Then, we merge these triples into the original KG, resulting in QA-KG-CWD. QA-K-CWD is shown in Fig. 2. The left side of Fig. 2 represents the original monadic KG, while the right side of Fig. 2 represents the QA-KG-CWD that we constructed. where the red-colored relations represent composite relations and the black-colored relations represent monadic relations. It is worth noting that if a relation can be further decomposable, we refer to it as a composite relation. If a relation cannot be further decomposable, we refer to it as a monadic or atomic relation. QA-KG-CWD is defined as QA - KG - CWD = E × R u × E. Where R u = R multi ∪ R single represents the set of relations in QA-KG-CWD, and R multi is the set of composite relations, and R single is the set of relations in the original KG, and E is the set of entities in the KG.
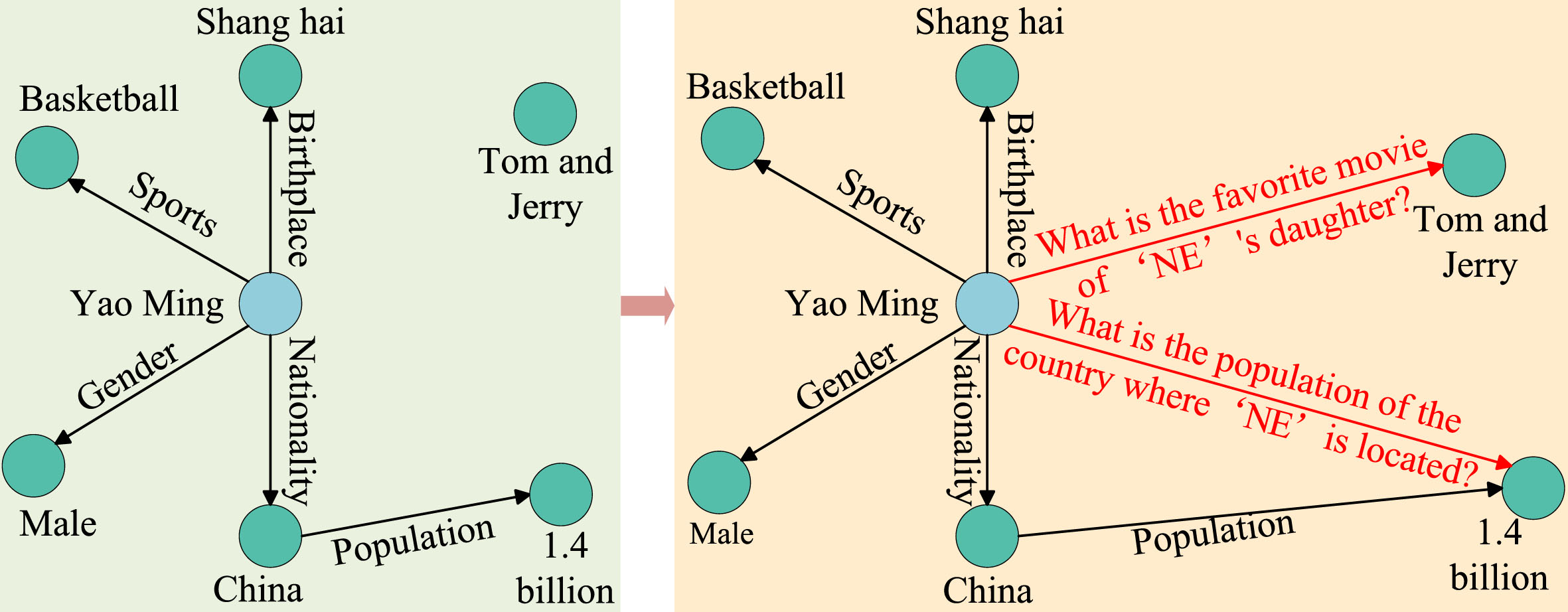
Schematic diagram of QA-KG-CWD. The left side represents the original KG, while the right side represents our constructed QA-KG-CWD.
Ji et al. [24] proposed the Complex model, which considers learning vector representations of entities and relations in a complex space, and measures the reasonableness of facts through semantic matching. Some prior works by researchers (Saxena et al. [12], Niu et al. [25]) in the field have indicated that the Complex model exhibits advantages in implicit relational reasoning and can effectively handle the sparsity of KGs. Hence, we adopt the Complex model to encode QA-KG-CWD.
We input the QA-KG-CWD into the Complex model for encoding, obtaining the sets of entity embeddings and relation embeddings required for subsequent reasoning. The above computational process is shown in Equation 1.
Where E represents the set of entities of QA-KG-CWD and R
u
represents the set of relations in QA-kG-CWD. Complex() represents the Complex model, E
c
∈ Cm×d is the set of entity embeddings in QA-KG-CWD,
In this section, we will utilize a text encoder to encode the questions and obtain question embeddings.
BiLSTM [26] is a variant of recurrent neural network RNN [27], which avoids the problem of gradient vanishing by introducing a gating mechanism.
First, each question Q = (t1, t2, t
len
) is input into the BiLSTM model for processing, resulting in the question embedding q
R
. The computation process is depicted in Equation 2.
Where Q represents the question embedding, t i (i ∈ [1, len]) is initialized as a low-dimensional vector, len represents the length of the question, q R ∈ R dim is the question embedding obtained after processing with BiLSTM, R represents the real number domain, and dim represents the dimension of the question vector.
Second, the KGE generator maps entities and relations to the complex domain space, and to maintain the consistency of the space, we process the question embedding q
R
in the real number field according to Equation 3, obtaining the question embedding q
C
in the complex vector space.
Where q R represents the question embedding in the space of the real number domain, Linear1() represents the linear transformation, q C ∈ C d represents the question embedding in the complex space, and d represents the dimension of the question embedding in the complex domain space.
At this point, we have obtained the set of relation embeddings
To narrow the gap between question features and KG features, we do a deep fusion of both in the Semantic Fusion Module (SF Module). This module contains two components, namely Attention Match Layer (AM Layer) and Cross Compress Layer (CC Layer). In this module, the question embedding q
C
, obtained through the text encoder, and the relation embedding set
Attention match layer
The objective of the Attention Match Layer (AM Layer) is to compare the question embedding with the relation embeddings in the KG, capturing the deep semantic correlations between them. The input to this layer is the question embeddings q
C
and the set of relation embeddings
First, to compute the attention scores between the question embedding and relation embeddings, we calculate the semantic similarity between the question embedding and each relation embedding by using Equation 4. Then we normalize the semantic similarities using Equation 5.
Where
Finally, we use the attention scores as weights to perform a weighted sum of the relation embeddings in the KG proportionally to obtain the relation match embedding r*. The calculation process is described in Equation 6.
Where α i stands for the attention score, r i represents the relation embedding in the QA-KG-CWD, n represents the number of relations in the QA-KG-CWD.
At this point, we have the question embedding q C with the relation match embedding (RM Embedding) r*.
The goal of the Cross Compress Layer (CC Layer) is to perform interactive fusion between the question embedding and the relation match embedding. In this layer, instead of using the traditional vector concatenation approach for feature fusion, we adopted the cross-compression unit designed by wang et al. [28] Compared with the traditional vector concatenation approach, this cross-compression unit can realize finer-grained interaction between two vectors through the cross operation and compression operation to make up for the lack of its own information. The input to this layer is question embedding q
C
and relation match embedding r*, while the output is the knowledge aware question embedding
First, to achieve the fine-grained interaction between the question embedding and the relation match embedding, we perform a cross operation between them, resulting in a cross-feature matrix F. The specific calculation formula is shown as Equation 7.
Where (q C ) (i) represents the element of the question embedding q C in the i-th dimension. (r*) (j) represents the element of the relation match embedding r* in the j-th dimension, F represents the cross-feature matrix, and d represents the dimension of the question embedding q C and the relation match embedding r*.
Second, to obtain a vector of size 1*d while maintaining the symmetry of the operation, we perform compression operations on the cross-feature matrix along the vertical and horizontal directions to obtain the knowledge aware question embedding
Where F represents the cross-feature matrix and F
T
represents the transpose of F. w1, w2, w3, w4, b1, and b2 represent the trainable parameters.
So far, we have obtained the knowledge aware question embedding (KAQ Embedding)
The number of entities in the KG is very large. Given a question, it is difficult to retrieve the most relevant entity to the question. To select the best entity, we have designed a Node Relevance Scoring Module (NRS Module). The inputs to this module are knowledge aware question embedding
In this module, we employ three scoring strategies to select candidate entities from different perspectives.
1) TRC (Topic entity, Relation, and Candidate entity) scoring strategy: Measures the rationality of the triple <topic entity, relation, candidate entity>.
2) TRCN (Topic entity, Relation, and the Candidate entitys Neighbor entity) scoring strategy: Measures the rationality of the triple <topic entity, relation, the neighbor entity of the candidate entity>.
3) QC (Question and Candidate entity) scoring strategy: Measures the relevance between the question and the candidate entity.
First, for each candidate entity c, we define its one-hop neighboring entities as (c1, c2, …, c p ). Where c i ∈ [1, p] represents the i-th one-hop neighbor entity of candidate entity c, and p represents the number of one-hop neighbor entities of candidate entity c.
Then, we obtain the vector representations of the topic entity, candidate entity, and its one-hop neighboring entities through the entity embedding set E c , denoted as e t , e c , and (e1, e2, …, e p ), respectively.
We calculate the average representation of one-hop neighbor entities of the candidate entity c using Equation 10, denoted as e
neighbor
.
Where p is the number of one-hop neighbor entities of candidate entity c. e i is the vector representation of the i-th one-hop neighbor entity of candidate entity c.
Finally, we compute the rationality of the triple <topic entity, relation, candidate entity>by Equation 11 and the rationality of the triple <topic entity, relation, the neighbor entities of candidate entity>by Equation 12;
Where e
t
is the vector representation of the topic entity,
To obtain the complete semantics of the question and perform fine-grained feature extraction, we concatenate the knowledge aware question embedding with the topic entity embedding and then input it into TextCNN, which is superior in fine-grained feature extraction, for processing after linear transformation, and obtain the
The correlation scores obtained using different correlation scoring strategies have different weights on the results. Therefore, we summed the relevance scores proportionally according to Equation 15 and normalized the weighted results according to Equation 16 to obtain the final scoring results of the model.
Where α, β and γ ∈ [0, 1] represent trainable parameters. score self , score neighbor and score question represent the results of the three scoring strategies, respectively. Sigmoid () represents the sigmoid function.
we determine the prediction result of the model by selecting the candidate entity with the highest score based on Equation 17.
Where score correlation represents the output of the node relevance scoring module. Top () represents selecting the entity with the highest score.
In this paper, the cross-entropy loss function is employed to train the model.
Datasets
We conducted experiments on the MetaQA [29] dataset and the PQL [30] dataset to verify whether the model outperforms other methods.
MetaQA dataset
MetaQA is a specialized KGQA dataset in the field of movies, featuring varied hop counts and a large KG, ideal for evaluating multi-hop reasoning and large-scale KG processing.
Table 1 shows the data statistics of the MetaQA dataset. Where MetaQA1H represents one-hop questions, MetaQA2H represents two-hop questions, and MetaQA3H represents three-hop questions.
Data statistics of the MetaQA dataset
Data statistics of the MetaQA dataset
We renamed the MetaQA dataset to MetaQA_Full and created MetaQA_Half by removing 50% of its relations to test our model on incomplete KGs.
The PQL dataset, based on Freeze KG, is favored for multi-hop KGQA. Our emphasis on PQL2H enriches question and relation types, offering better answers. Data statistics are in Table 2.
Data statistics of the PQL dataset
Data statistics of the PQL dataset
We generated PQL2H_Half by randomly removing 50% of relations from PQL2H to test our model on sparse KGs, while the original dataset is termed PQL_Full for clarity.
We constructed QA-KG-CWD based on MetaQA as well as PQL datasets respectively according to the method mentioned in Section 4.1 of this paper. The comparison of QA-KG-CWD with the original KG is shown in Table 3.
Comparison of knowledge graphs
Comparison of knowledge graphs
Where Entity nums represents the number of entities. Relation nums represents the number of relations. Number of relation types represents the number of relation types. MetaQA1H_QA-KG-CWD, MetaQA2H_QA-KG-CWD, and MetaQA3H_QA-KG-CWD respectively represent the QA-KG-CWD constructed based on MetaQA1H, MetaQA2H, and MetaQA3H. PQL represents the PQL dataset. PQL2H_QA-KG-CWD represents the QA-KG-CWD constructed based on PQL2H.
Table 4 shows the model’s training hyperparameters. The setup includes Torch (1.12.1+cu113), GPU (3090), Cuda (11.3), Python (3.8), and Ubuntu (20.04.1).
The hyperparameter configuration of the model
The hyperparameter configuration of the model
We conduct a comparative experiment with a range of state-of-the-art multi-hop KGQA models on MetaQA and PQL datasets, including SGReader [31] (2019), ReifKB [32] (2020), SRN [33] (2020), EmbedKGQA [12] (2020), 2HR-DR (2020) [34], LEGO [35] (2021), Biet [36] (2022), and HDH-GCN [37] (2022).
Analysis of experimental results
Table 5 presents the experimental results of the baseline model and the model proposed in this paper on MetaQA with the PQL dataset. In this case, the experimental data of the EmbedKGQA model on MetaQA_Full are reproduced data, and the rest of the data are those recorded in the original paper. We can observe that the overall performance of the proposed model is consistently better than that of the baseline models across all datasets used in this paper.
Experimental results on MetaQA and PQL datasets
Experimental results on MetaQA and PQL datasets
From Table 5, it can be seen that the proposed model, compared to mainstream models, achieved an improvement of 0.8% and 1.7% in accuracy for two-hop and three-hop questions, respectively, on the MetaQA_Full dataset compared to the second-ranked model. On the MetaQA_Half dataset, the proposed model achieved an improvement of 0.9%, 1.0%, and 0.4% in accuracy for one-hop, two-hop, and three-hop questions, respectively, compared to the second-ranked model. Additionally, on the PQL_Full and PQL_Half datasets, the proposed model outperformed the second-ranked model by 0.2% and 1.4% in accuracy for two-hop questions, respectively. These experimental results demonstrate the effectiveness of the proposed joint reasoning-based embedded multi-hop KGQA method, showing superior overall performance. Our model excels at handling KG sparsity and enhancing long-path reasoning capabilities. This is achieved by utilizing question-answer pair information to alleviate KG sparsity and reducing the semantic gap between the question modality and the KG modality through a semantic fusion module. Additionally, the model employs a node relevance scoring module to select the optimal candidate entity. The reduced semantic gap between the question modality and the KG modality facilitates long-path reasoning. We propose three node relevance scoring methods that consider both the information of the nodes themselves and the information of their neighbors. These methods enable the model to make answer selections from multiple perspectives, thereby improving the model’s performance.
It should be noted that the proposed model performs lower in accuracy for one-hop questions on the MetaQA_Full dataset compared to other models. This is because the KG itself is complete, and introducing question-answer pair information to alleviate KG sparsity is ineffective in this case. However, the proposed model shows improvements in accuracy for two-hop and three-hop questions on the complete MetaQA dataset. This is because the proposed model transforms the multi-hop reasoning process on a unary KG into a single reasoning process on a multi-relational KG, thereby enhancing the model’s long-path reasoning capabilities.
We conducted five experiments on the MetaQA and PQL datasets under identical conditions.
From Table 6, it can be observed that after removing QA-KG-CWD, the proposed model experienced a decrease in accuracy on the MetaQA_Full dataset. Specifically, the accuracy dropped by 0.1%, 1.5%, and 7.8% for one-hop, two-hop, and three-hop questions, respectively. On the MetaQA_Half dataset, the corresponding accuracy drops were 5.9%, 12%, and 5.9%. Additionally, the accuracy for two-hop questions decreased by 5.0% on the PQL_Full dataset and by 9.1% on the PQL_Half dataset. These results demonstrate the effectiveness of incorporating question-answer pair information to alleviate KG sparsity and improve the model’s long-path reasoning capabilities.
Ablation experiments on MetaQA and PQL datasets
Ablation experiments on MetaQA and PQL datasets
After removing the semantic fusion module, the proposed model exhibited decreased accuracy on the MetaQA_Full dataset. The accuracy dropped by 0.5%, 3.5%, and 2.9% for one-hop, two-hop, and three-hop questions, respectively. On the MetaQA_Half dataset, the accuracy decreases were 1.5%, 3.1%, and 1.6% for the respective question types. On the PQL_Full and PQL_Half datasets, the accuracy for two-hop questions decreased by 1.3% and 2.6%, respectively. These findings highlight the effectiveness of the proposed semantic fusion module. By narrowing the gap between question features and KG features, the module enhances the model’s long-path reasoning capabilities.
After removing the cross compress layer, the proposed model’s accuracy on the MetaQA_Full dataset decreased. The accuracy dropped by 0.6%, 1.8%, and 0.8% for one-hop, two-hop, and three-hop questions, respectively. On the MetaQA_Half dataset, the accuracy decreases were 1.2%, 2.1%, and 1.3% for the respective question types. On the PQL_Full and PQL_Half datasets, the accuracy for two-hop questions decreased by 1.3% and 1.4%, respectively. These results indicate the effectiveness of the proposed cross compress layer. The fine-grained interactions between question embedding and relation match embedding, enabled by cross compress layer, compensate for information deficiencies and contribute to improved performance.
After removing the TRCN scoring strategy, the proposed model’s accuracy on the MetaQA_Full dataset decreased. The accuracy dropped by 0.4%, 1.3%, and 7.1% for one-hop, two-hop, and three-hop questions, respectively. On the MetaQA_Half dataset, the accuracy decreases were 1.6%, 2.3%, and 0.2% for the respective question types. On the PQL_Full and PQL_Half datasets, the accuracy for two-hop questions decreased by 1.8% and 3.3%, respectively. These findings demonstrate the effectiveness of the proposed TRCN scoring strategy. Leveraging neighbor information provides finer evidence for selecting the best answers, thus aiding in the choice of optimal answers.
After removing the QC scoring strategy, the proposed model’s accuracy on the MetaQA_Full dataset decreased. The accuracy dropped by 0.8%, 2.6%, and 6.4% for one-hop, two-hop, and three-hop questions, respectively. On the MetaQA_Half dataset, the accuracy decreases were 1.7%, 7.7%, and 0.4%. On the PQL_Full and PQL_Half datasets, the accuracy decreases were 2.5% and 1.3%, respectively. These results highlight the effectiveness of the proposed QC scoring strategy. Evaluating the correlation between the question and the nodes assists the model in selecting candidate entities more effectively.
To accurately assess the impact of the proposed method in alleviating sparsity, we conducted an analysis of graph sparsity using average degree as a metric for both the MetaQA_Half and PQL_Half datasets. Table 7 presents a comparative analysis of the original average degree and the average degree of the proposed QA-KG-CWD.
The comparison of average degrees in the knowledge graphs
The comparison of average degrees in the knowledge graphs
The Original average degree represents the average degree of the original KG, while the New average degree indicates the new average degree introduced by the proposed QA-KG-CWD approach. MetaQA_Half_1H, MetaQA_Half_2H, and MetaQA_ Half_3H represent the KGs of the MetaQA_Half dataset for one-hop, two-hop, and three-hop questions, respectively. PQL_Half_2H represents the KG of the PQL_Half dataset for two-hop questions.
From Table 7, it can be observed that there is a significant improvement in the sparsity of the KG after constructing QA-KG-CWD. On MetaQA_Half_1H, MetaQA_Half_2H, and MetaQA_Half_3H, the average degree of the graph increased by 2.41, 2.73, and 2.62, respectively. On PQL_Half_2H, the average degree of the graph increased by 0.16. This is because the composite relationships we constructed connect distant nodes, providing richer connections in the KG. It can be seen that the proposed method effectively increases the average degree of the KG, greatly alleviating its sparsity.
The maximum shortest path in the KG can reflect the performance of a model in complex path reasoning. Therefore, we analyzes the maximum shortest path in the KG on the MetaQA_Full and MetaQA_Half datasets. Table 8 shows the comparison of the maximum shortest paths in the KG.
Comparison of maximum shortest paths in the knowledge graph
Comparison of maximum shortest paths in the knowledge graph
Among them, “original maximum shortest path” represents the maximum shortest path in the original KG. “new maximum shortest path” represents the new maximum shortest path generated after using the proposed QA-KG-CWD method. MetaQA_Full_1H, MetaQA_Full_2H, and MetaQA_Full_3H represent the KGs corresponding to one-hop, two-hop, and three-hop questions in the MetaQA_Full dataset, respectively. MetaQA_Half_1H, MetaQA_Half_2H, and MetaQA_Half_3H represent the KGs corresponding to one-hop, two-hop, and three-hop questions in the MetaQA_Half dataset, respectively.
From Table 8, it can be observed that after applying the proposed QA-KG-CWD method, the maximum shortest paths in MetaQA_Full_2H and MetaQA_Full _3H were reduced by 2 each. On MetaQA_Half_1H, MetaQA_Half_2H, and MetaQA_Half_3H, the maximum shortest paths were reduced by 3, 5, and 5, respectively. This is because the proposed method effectively utilizes the information from question-answer pairs, thereby reducing the distance between distant nodes. When the maximum shortest path in a graph decreases, the graph becomes more accessible, information propagation becomes more efficient, and it benefits the model in complex path reasoning. This further demonstrates the advantage of the proposed model in handling long path reasoning.
It is worth noting the following observations from Table 8: (1) The maximum shortest path in MetaQA_ Full_1H did not change. (2) The reduction in the maximum shortest paths for MetaQA_Full_2H and MetaQA_Full_3H is smaller than the reduction observed in MetaQA_Half_2H and MetaQA_Half_3H. (3) The decrease in the maximum shortest path for MetaQA_Half_1H is smaller than the decrease observed in MetaQA_Half_2H and MetaQA_Half_3H.
These phenomena can be attributed to the following reasons: (1) The MetaQA_Full KG is denser compared to MetaQA_Half. (2) Two-hop and three-hop questions have the ability to bridge the distance between more distant nodes compared to one-hop questions. This indicates that the proposed method is more effective on relatively sparse KGs, and its impact is more pronounced in reasoning with longer paths.
We propose a joint reasoning-based embedded multi-hop KGQA method and show that: (1) QA-KG-CWD enhances long-path reasoning and addresses KG sparsity. (2) A semantic fusion module aligns KG and question features, improving model performance. (3) Multiple node relevance strategies aid in selecting the best answer. Our results on MetaQA and PQL confirm our model’s effectiveness in overcoming KG sparsity and enhancing long-path reasoning, underscoring our contribution to improving reasoning and question-KG integration.
There are many challenges and opportunities for improving our model. We plan to conduct in-depth, innovative research for further advancements. First, since the KGE model is underperforming in semantic understanding, we will try to use graph neural networks for embedding QA-KG-CWD. Second, our early joint embedding module is trained independently from the question encoder module, and we will try to perform a multi-layer dynamic fusion of question modality and KG modality.
Declaration of competing interest
The authors declare no competing financial interests or personal relationships that could affect this paper’s findings and conclusions.
Footnotes
Acknowledgments
This work has been supported by the National Natural Science Foundation of China (62166042, U2003207), Natural Science Foundation of Xinjiang, China (2021D01C076), and Strengthening Plan of National Defense Science and Technology Foundation of China (2021-JCJQ-JJ-0059).