
Abstract
Cell nucleus segmentation plays a significant role in Computer-Aided systems for cancer diagnosis. However, the nuclear images are characterized by different sizes, overlap, adhesion, and similarities between nuclei and other structures, making this task challenging. Aiming to adjust and enhance the feature learning ability of the network, this paper proposes a FourierFilter Irregular Attention U-Net (FFIA-UNet), which contains FourierFilter Irregular Attention (FFIA) and multi-receptive filed fusion (MRF) module. FFIA module seeks to learn deeper characteristics by taking advantage of frequency information and deformable convolution. MRF module improve the learning capacity of fuzzy edges and irregular forms via multiple dilated convolution. Experiments on three datasets show that the proposed FFIA-UNet achieves state-of-the-art. Dice-Score and mIoU reached 0.929 and 0.885 respectively on DSB2018. Furthermore, numerous ablation experiments have demonstrated the module’s efficacy.
Keywords
Introduction
Cell morphology in histopathological images provides key information for cancer diagnosis, treatment planning, and survival analysis [1]. Many academics have created deep models to analyze histopathology pictures because of deep learning’s potent feature learning capabilities [2]. Nonetheless, there are a few additional challenges in the nuclear image segmentation process when compared to natural images, such as the disorganized distribution of the nucleus and the poor contrast between the nucleus and background. Therefore, researchers have proposed a more effective and novel deep learning segmentation method according to the characteristics of nuclear images.
Similar to the segmentation task of natural images, the segmentation method for cell nucleus can be divided into two stages and one stage based on the training process of the model. Mask RCNN [3], which has a significant impact in the two-stage model, is also used for cell nucleus segmentation. Furthermore, the nucleus is viewed as a clustering core by SPANet [4]. Based on the border, BRPNet [5] produces region recommendations. The risk of over-fitting is increased by the high parameters and sophisticated models and the tiny parameters of medical databases.
Then multitude of one-stage nucleus segmentation techniques have been developed. According to the different network structures, these methods can be categorized as U-Net type and Transformer structures. U-Net [6] is a structure specifically designed for medical segmentation tasks, which can achieve excellent segmentation results even in small amounts of data. As a result, U-Net and its variations [7, 8] have been used to segment nuclei with remarkable outcomes. UNet++ [9] uses the nested U-Net structure to increase accuracy and performance, however doing so comes with an increase in parameters. To mitigate the issue of connections, UNet3+ [10] develops a full-scale skip connection architecture that is capable of capturing multi-scale information, hence reducing model parameters. Stacking two U-Net networks and adding VGG-19 as a new encoder allows Double-UNet [11] to increase the segmentation accuracy and deepen the network depth. A multi-path attention approach is used by DCSAU-Net [12] to recover features for improved segmentation. AttentionU-Net [13] introduced attention gates modules as a practical way to improve model sensitivity and accuracy. ResUNet [14, 15] included residual links in the encoder and decoder phases to improve model performance. To further enhance model performance, ResU-Net++ [16] included Test-Time Augmentation and Conditional Random Field techniques. Recurrent and residual connections are combined in R2U-Net [17] to provide a novel framework. Besides, the lesion-attention pyramid network (LAPN) [18] is presented to enhance the learning ability of network by integrating the subnetworks with different resolutions. And MSRF-Net [19] also apply multi-scale residual fusion network for biomedical image segmentation.
In recent years, the Transformer has achieved better results in computer vision, and therefore it has also been used to solve cell nucleus segmentation. Leading performance in several medical image tasks has been attained by combining TransUNet [20] with the Transformer. Additionally, the encoder-decoder-based segmentation approach [21–24] makes use of the Transformer’s features. By combining text and Vision Transformer, LViT [22] extracts text and image information and enhances cell nucleus segmentation accuracy by combining the two kinds of data. However, LViT does not apply local text information to segmentation, which leads to low segmentation accuracy in local regions. Besides, a spatial dependence multi-task Transformer (SDMT) network [25] is proposed for MRI segmentation and landmark localization. Regretfully, the Transformer is ill-suited for the nucleus segmentation task due to data limitations [26]. These networks usually ignore the irregular form and edge blurring.
Fourier transform has been an important tool in digital image processing for decades. For vision problems, the Fourier transform is widely used in deep learning techniques [27]. Some use the convolution theorem to speed up CNNs using fast Fourier transform (FFT) [28], while others use the discrete Fourier transform to translate the images to the frequency domain and use the frequency information to increase the performance [27]. Fast Fourier convolution (FFC) [29] accomplishes convolutions in the frequency domain by substituting a local Fourier unit for the convolution seen in CNNs. Additionally, the Fourier transform is employed in place of self-attention in the Transformer to enhance the computational efficiency of network training and inference while also better capturing global frequency domain information and establishing long-term semantic relationships. The Fourier transform can lower the number of parameters and processing expenses as compared to the Transformer.
This paper proposes a FourierFilter Irregular Attention U-Net (FFIA-UNet), which contains the U-Net structure and two designed modules: multiple receptive fields (MRF) and the FourierFilter Irregular Attention module (FFIA), to better learn the irregular shape and distinguish edges. Every level of the encoder phase contains the FFIA module, which uses learnable filters and deformable convolution to communicate information globally in the frequency domain, recalibrates the feature map and enhances irregular shape learning. Because of the nucleus’s tiny size, density, and propensity for adhesion and overlap, we propose a feature fusion mechanism dubbed MRF to enhance the learning ability, which sits between the encoder phase’s two convolution layers. Moreover, because the up-sampling technique is not learnable, a predicted spatial mismatch arises when integrating information from multiple stages. We also employ the MRF module to move the feature information from the encoding process to the matching decoding stage. These two plug-and-play modules provide a framework that is simple to utilize. Tests conducted on four datasets demonstrate that the suggested FFIA-UNet reaches state-of-the-art performance. The following are the contributions:
A FourierFilter Irregular Attention (FFIA) module is proposed to fit the irregular shape. This module is plug-and-play, realized by fast Fourier transform and depthwise deformable convolution. A multi-receptive field fusion (MRF) module is proposed to improve the capacity to learn spatial feature information. The designed FFIA-UNet achieves the state-of-the-art on the 2018 Data Science Bowl, MoNuSeg and TNBC datasets.
Methods
The thorough overview of our planned network is shown in Fig. 1. It constructed the Multi-receptive feature fusion (MRF) module and the FourierFilter Irregular attention (FFIA) module, which are positioned at the encoder and skip connections.

The overall structure of our FFIA-UNet. (a) The FFIA-UNet; (b) FourierFilter Irregular Attention module (FFIA); (c) Multi Receptive filed fusion module (MRF).
Our FFIA-UNet retains the Encoder and Decoder structure of U-Net. The FFIA module, shown in Fig. 1, comes after the downsampling process and aims to minimize information loss by modifying the feature map’s learning emphasis using FourierFilter and deformable convolution. Following four downsamplings, the features undergo inverse and Fourier transforms to alternate between the frequency and time domains. There is more information in the retrieved feature edge. To extract richer features, the MRF module is incorporated into two standard convolutions of each stage. Additionally, by using multi-scale features, the MRF module is used to transport feature information from the encoder stage to the matching decoding stage, thereby reducing the misalignment phenomena.
We did not make any modifications to the original bilinear interpolation for upsampling and convolution operations during the Decoder phase. After two convolutions for feature fusion, the bilinear interpolation process doubles the size of the feature map and compresses the channel number. Lastly, a pointwise convolution yields the anticipated segmentation outcome.
FourierFilter irregular attention (FFIA) module
In medical image, the object typically looks very similar to the surrounding background tissue and takes on an uneven shape. Deformable convolution and attention mechanisms offer comparable benefits when seen through the lenses of adaptive feature selection and receptive field alteration. Furthermore, the Fourier transform ignores the impact of irregular shapes and converts the image into the frequency domain. Then, this research presents a FourierFilter Irregular Attention (FFIA) module to fit the nucleus shape better in feature maps of the network. The FourierFilter module (FF), depthwise convolution (DWC), deformable convolution (DFC), and pointwise convolution (PWC) make up the FFIA module depicted in Fig.1(b).
The FF module receives the features as input, converts them to the frequency domain using the Fast Fourier Transform, then uses the Inverse Fourier Transform to return the features to their spatiotemporal form. Subsequently, the features undergo additional calibration via deformable convolutions. We employ DWC to extract more characteristics from the frequency domain feature maps produced by the Fourier transform before utilizing DFC. The spatial feature information is then extracted from the feature graphs produced by the deformable convolution using PWC. Afterwards, similar to other image attention mechanisms, we will obtain an attention map and combine it with the input feature map to adjust the learning direction of the network. To be more precise, the FFIA module can be shown like this:
The image is converted from the time domain to the frequency domain via the fast Fourier transform, allowing for additional angles of observation and analysis. Fourier transform physically converts the grayscale distribution function of an image to its frequency distribution function, which reflects the intensity of grayscale change in the image. The region with slow gray change is the low frequency region, and the region with large gray change is the high frequency region. The 2D fast Fourier transform (FFT) along the spatial dimensions is performed to convert the input ϰ ∈ RH×W×D to the frequency domain:
Finally, we adopt the inverse fast Fourier transform (IFFT) to transform the modulated spectrum
In the neural network, the convolution operation is based on the regular receptive field. The receptive field of the 3 × 3 convolution kernel is a square with 9 pixels. Complex targets, such as the nucleus, appear to be of varying sizes and roundish forms depending on the nature and location of the lesion. As a result, making the receptive field of the convolution kernel circular helps in nuclear segmentation. Deformable convolution [31], different to regular convolution, introduces learnable offsets in the receptive field. Hence the receptive field of deformable convolution is based on the irregular shape of this region rather than the region of regular convolution. This design allows it to learn the edge and contour information of shapes more effectively, and it has performed well in certain image segmentation tasks. Therefore, we briefly introduce deformable convolution in the following content.
Let x, y be the input and output feature map of the conventional convolution layer respectively. And each location p0 on y is expressed as
Deformable convolution [31], shown in Fig. 2, first learns an offset value through an additional convolution to obtain the coordinate value with offset value after each convolution. This process can be expressed as

Illustration of 3 × 3 deformable convolution [31].
Owing to the dense, microscopic targets that are commonly found in nuclear pictures, problems like adhesions and overlaps can easily result in the loss of feature information during the downsampling process. One effective solution to the aforementioned issues is to expand the receptive field. This leads to the proposal of a multi-receptive field fusion (MRF) module in this study, shown in Fig. 1(c). This module is placed between two 3 × 3 convolution layers of the encoder, and multi-receptive fused feature maps are obtained by obtaining features of different receptive fields. The multi-receptive fusion module can effectively handle abnormal nucleus of different shapes and sizes through multiple dilated convolutions with different dilation factors, so that the output of each convolution contains a larger range of information. This module contains three different dilation factor dilated convolutions (dilation factor sizes are set to 1, 3, and 5 respectively) as shown in the Fig. 3, where the first dilated convolution is the same as the 3 × 3 ordinary convolution. Dilated convolutions with larger dilation factors are used to capture global contextual semantic information, while dilated convolutions with smaller dilation factors are used to capture detailed internal structural information to avoid excessive pixel loss and improve the segmentation effect of image details and edges.
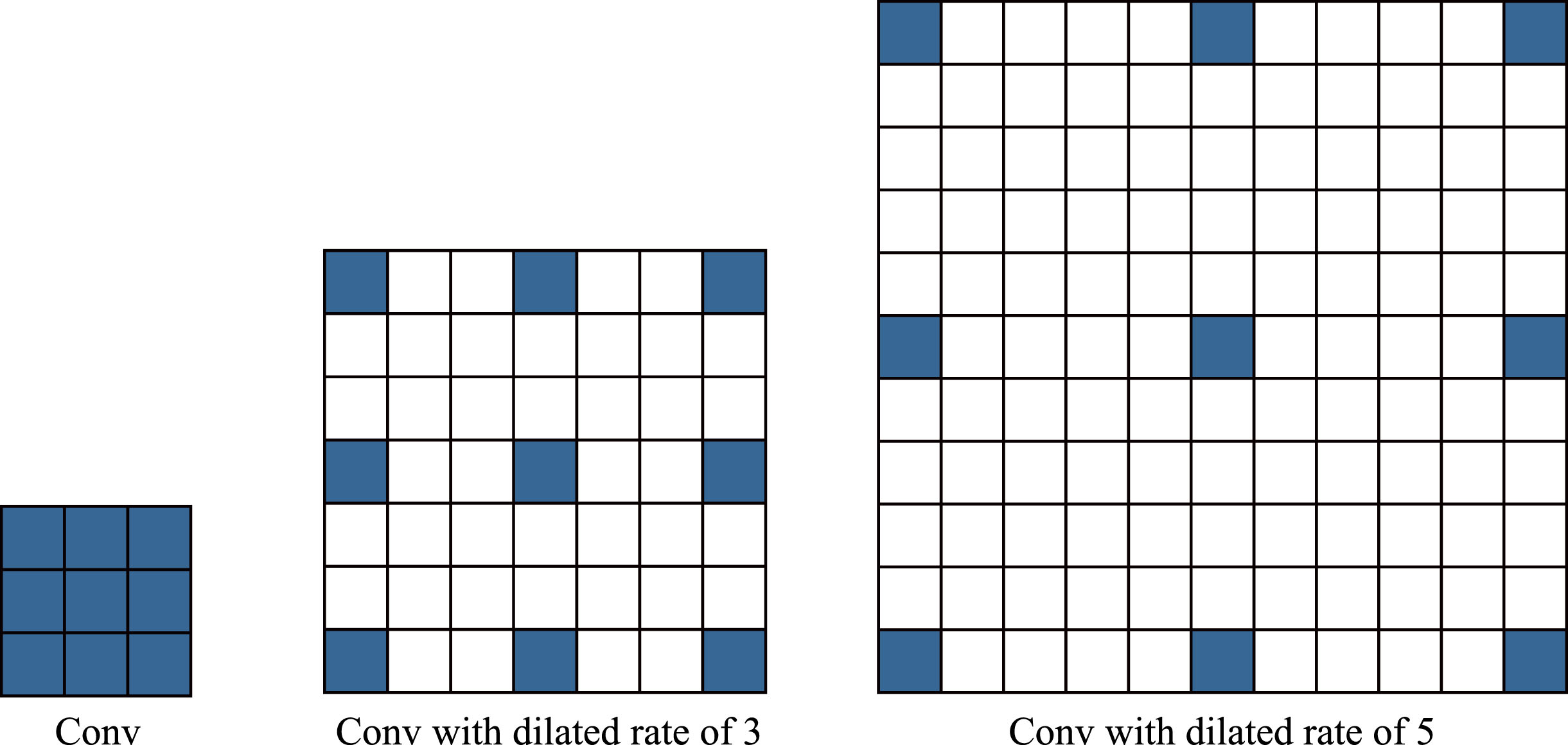
3 × 3 convolution with different dilated ratios.
In addition, there is usually a predictable spatial deviation between the feature maps obtained through the downsampling operation of the encoder and the feature maps obtained through the upsampling operation of the decoder. Directly using element addition or channel cascading for feature fusion can disrupt predictions around object boundaries. Therefore, this article transfers the feature information from the encoder stage to the corresponding decoding stage through a multi-receptive fusion module, and reduces feature misalignment by extracting multi-scale features. In addition, to reduce parameters and improve computational speed, the proposed MRF module adopts deep convolution. This process can be represented as follows.
As the loss function, we employ the Dice loss [32]. The Dice coefficient, stated as follows, is used to calculate how similar two samples are to one another.
Datasets and training details
2018 Data Science Bowl (DSB)[9] contains 670 manually labeled nucleus segmentation images. These images are acquired under various conditions and are different in cell type, magnification, and imaging mode (brightness and fluorescence). The purpose of this dataset is to test algorithms’ capacity to generalize in these variations. Ten percent are used for testing, twenty percent are used for verification, and seventy percent are utilized for training in this work.
MoNuSeg [33] dataset involves 32 teams and more than 80 researchers from institutions in different regions. The training set consists of 30 images and 21623 single core annotations, and the test set consists of 14 images. This dataset comes from multiple organs.
TNBC [34] datset contains a large number of annotated cells, including normal epithelial and myoepithelial breast cells (located in ducts and lobules), invasive cancer cells, fibroblasts, endothelial cells, adipocytes, macrophages, and inflammatory cells (lymphocytes and plasma cells). The TNBC dataset consists of 50 images, with a total of 4022 annotated cells. The maximum number of cells in one sample is 293, and the minimum number of cells in one sample is 5. On average, each sample has 80 cells, with a high standard deviation of 58.
CVC-ClinicDB [16] is the official dataset for the training phase of the MICCAI 2015 Colonoscopy Video Automatic Polyp Detection Challenge. The database consists of 612 static images extracted from colonoscopy videos, which come from 29 different sequences. The image size is 288 × 384. Each image is accompanied by a ground truth mask to identify the area covered by the polyps in the image.
Performance comparison
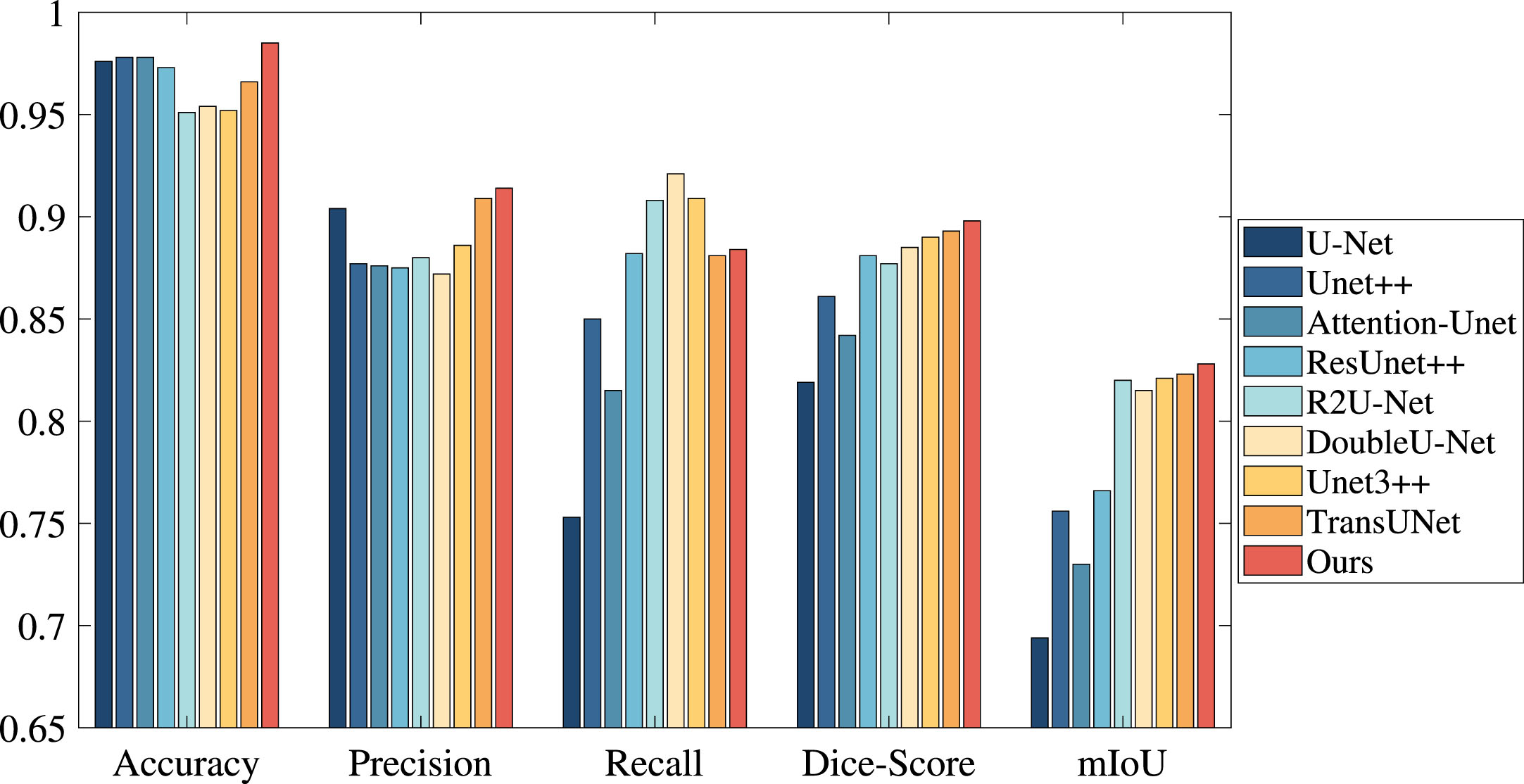
Results on the DSB dataset, where “–” denotes that no relevant data is provided in references. Color convention: Best, Second-Best
Results on the DSB dataset, where “–” denotes that no relevant data is provided in references. Color convention: Best, Second-Best
We present five examples with predictions from our network and benchmark models in Fig. 4. We can see from the red box in the last column that our method can successfully segment the nucleus compared to the previous method using the green box. Our approach integrates deeper semantic and frequency domain features, increasing the abundance of extracted features and highlighting edge features by using learnable filters to exchange information globally among the tokens in the Fourier domain and further calibrating the frequency domain features through deformable convolution. The nucleus that our approach segments is distinct and essentially accurate. The two black images in the fourth line indicate that the corresponding two models did not segment the nucleus. The number of nucleus in this image is large, but the individual size is modest, making segmentation more difficult.

Visual comparison with the benchmark techniques on the DSB Dataset.
Results on the MoNuSeg
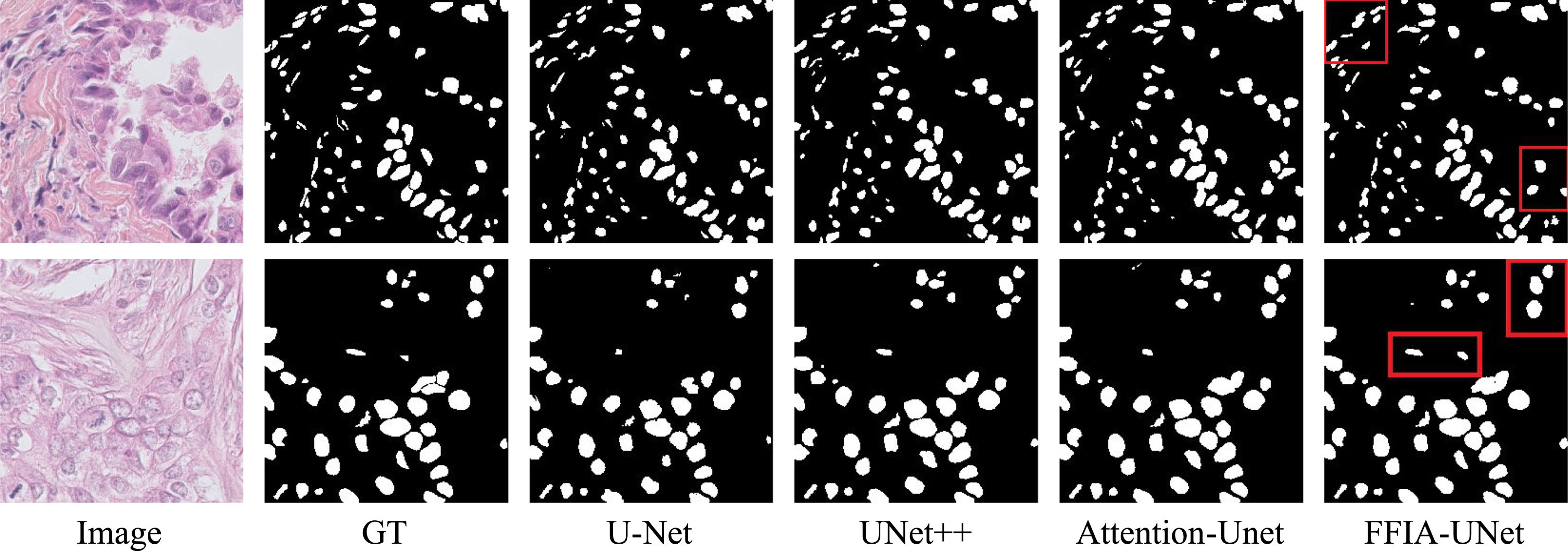
The visualization results on the MoNuSeg dataset are shown in the Fig. 5. It can be seen that the accuracy of the model in cell nucleus segmentation has been further improved, and the occurrence of missegmentation and missegmentation has been further reduced. This indicates that the model has good segmentation ability for small targets, can extract richer features, and better distinguish cell nucleus.

Visual comparison on the MoNuSeg Dataset.
Comparison results on the TNBC Dataset.
The two examples of visualization results on the TNBC dataset is shown in the Fig. 7. From the figure, it can be seen that the segmentation effect of the model is closer to the original GT image, and the segmentation effect is further improved. In the second row, the missed segmentation phenomenon of other models is obvious, while FFIA-UNet can segment more accurately. The model can better distinguish between foreground and background in nuclear images, and effectively segment the nucleus from other structures.
Visual comparison on the TNBC Dataset.
We set up several ablation experiments to illustrate the rationality of FFIA and MRF modules. ALl the ablation experiments are finished on the 2018 DSB dataset.
Ablation Study of FFIA module, where “w.o.” denotes “without”
Ablation Study of FFIA module, where “w.o.” denotes “without”
Dilated rate configuration of MRF module
Ablation experiments of module effectiveness, where ✓ and × indicate whether the module is employed respectively
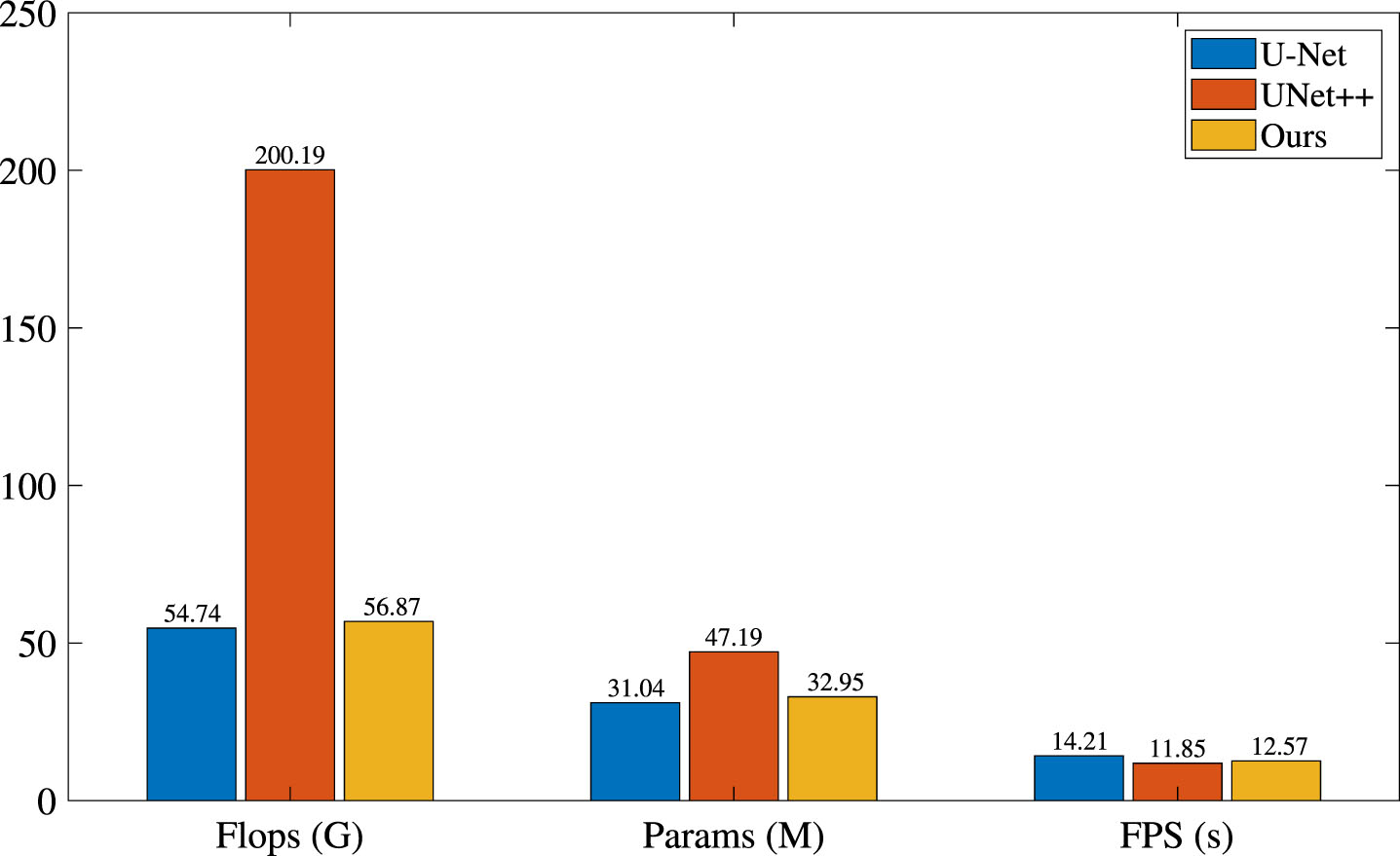
Ablation experiments on the parameter and calculation speed.

Visualization of class activation mapping.
comparison with other attention modules
Results on the CVC-ClinicDB
Figure 10 show the qualitative analysis results on the CVC-ClinicDB dataset. The segmentation result of the FFIA-UNet proposed in this paper is closest to the GT image, and the segmentation effect is excellent. In other rows, other models have experienced misclassification and unclear edge segmentation effects. This is mainly due to the unclear distinction between foreground and background in medical images, and other networks only rely on extracting temporal and spatial features. Our method rely on fast Fourier transform to convert the spatiotemporal domain into the frequency domain, which can better distinguish foreground and background, resulting in better segmentation results.

Visual comparison on the CVC-ClinicDB dataset.
In this paper, we propose a FourierFilter Irregular attention (FFIA) and a multi-receptive field fusion (MRF) module. The former can interchange information globally among the tokens in the Fourier domain and can adaptively extract features from the backbone network, and the latter fuse features from multiple receptive fields. Our FFIA-UNet achieves state-of-the-art on the 2018 DSB, MoNuSeg and TNBC datasets. With a slight number of parameters, the Dice score and mIoU on DSB dataset reached 0.929 and 0.885, respectively. And on MoNuSeg and TNBC, the Dice score also reached 0.815 and 0.83, respectively. The requirement and efficiency of the modules were further confirmed by the ablation experiments.
The model in this paper also has some limitations. Firstly, the feature learning ability of the network backbone needs to be further enhanced. Second, frequency domain information is very important and widely used in computer vision. However, this article is only the simplest use of frequency-domain information. Third, the experiment was conducted on a public data set, which is different from clinical data.
We will conduct the following operations in the follow-up study. Mamba structure will be used to extract global information. And we will use frequency domain information more efficiently with wavelet transform.
Footnotes
Acknowledgment(s)
This work is supported by the Natural Science Starting Project of SWPU (No. 2022QHZ023, 2022QHZ013), the Sichuan Provincial Department of Science and Technology Project (No. 2022NSFSC0283), the Sichuan Scientific Innovation Fund (No. 2022JDRC0009), the Key Research and Development Project of Sichuan Provincial Department of Science and Technology (No.2023YFG0129), and the Key Laboratory of Internet Natural Language Intelligent Processing in Sichuan Provincial Higher Education Institutions (No. INLP202202). In addition, we also thank the High-Performance Computing Center, Southwest Petroleum University for its support.
Conflict of interest statement
No potential conflict of interest was reported by the authors.