
Abstract
We investigate the semi-online problem of MapReduce scheduling on two parallel machines. We aim to minimize the makespan. Jobs are released over-list, and each job includes a map task and a reduce task. The job’s map task can be preemptive and scheduled simultaneously onto different machines, however, the reduce task is non-preemptive. The job’s reduce task needs to wait for its map task to complete before starting. We consider the following two versions: Firstly, we know the processing time of the largest reduce task beforehand, and then design a 4/3-competitive optimal semi-online algorithm. Secondly, we know in advance the value of the reduce task with the largest processing time and the the total sum of the processing times. Then we present a 4/3-competitive semi-online algorithm. We conclude that the algorithm is the best possible when the largest reduce task meets certain conditions.
Introduction
With the advent of the cloud age, big data has attracted more and more attention, and it has been integrated into business, energy information, economics, physics, and other fields. Faced with the complex and growing structure of big data, it is particularly important to find a simple and feasible solution, and MapReduce[1] is such a programming model used for parallel operations on large-scale datasets. The data processing process of MapReduce is mainly split into two phases: the map phase and the reduce phase. When submitting a job to the MapReduce system, these two phases are always included in its computation. Firstly, JobTracker is responsible for breaking down assignments into multiple tasks and assigning them to each TaskTracker. Then the input data is divided into fixed-size fragments, each of which is processed by a Map task. In the map phase, convert the raw data into key-value pairs. Finally, in the reduce phase, values with the same key-value are processed before outputting new key-value pairs as the final result. The specific process can be seen in Figure 1. All tasks are processed on a set of parallel machines, which can be summarized as a parallel machine scheduling problem.
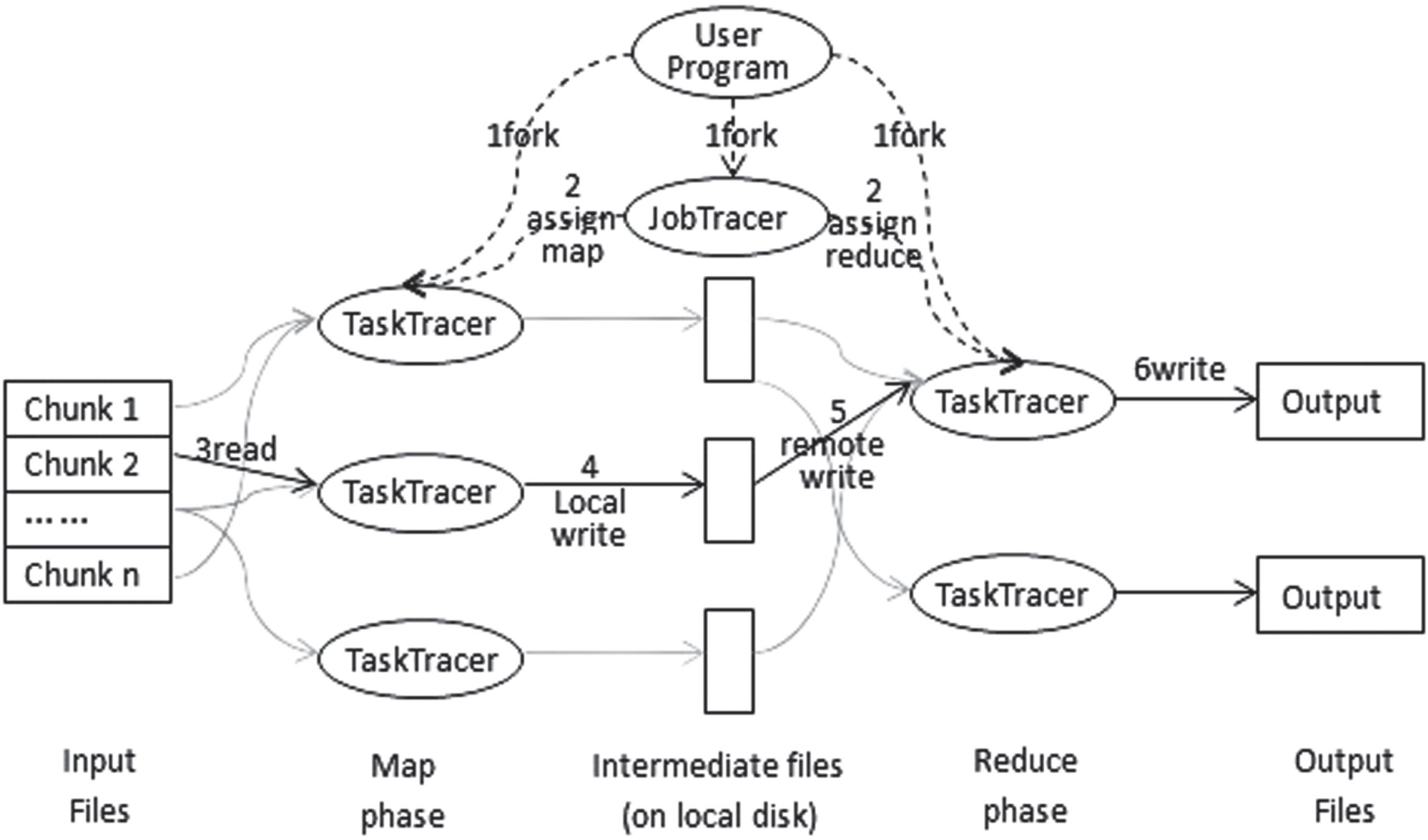
MapReduce execution flowchart.
leavevmode Formally, we study the following problem in MapReduce system. A list of jobs J 1, J 2, ⋯, J n are arrived over-list and are to be scheduled onto two identical parallel machines σ 1 and σ 2. We assume that each job J j concludes a map task M j and a reduce task R j , and the length of its M j is not greater than that of its R j . The reduce task of J j can be processed only after its map task have been processed. For each job, suppose that each map task can be preemptive and be processed on different machines simultaneously, however, the reduce task is non-preemptive. We aim to minimize the makespan. We take into account the following two cases: Firstly, we know the processing time of the largest reduce task beforehand. Secondly, we know in advance the processing time of the largest reduce task and the total sum of the processing times. Using the classical three-field notation, our problems are denoted by P2|MR, max|C max and P2|MR, sum & max|C max, respectively. For simplicity, use M1 and M2 to denote the problem P2|MR, max|C max and the problem P2|MR, sum & max|C max, respectively.
For the problems of semi-online scheduling, use the competitive ratio to measure the quality of a semi-online algorithm. For a set of jobs J and an algorithm A, then the algorithm A is referred to as ρ-competitive if
There are a great deal of researches on different MapReduce scheduling models over recent years. In addition to some papers focused on empirical works [2–5], a large number of theoretical works have also emerged [6–10]. Zhu et al. [8] considered offline MapReduce scheduling problems. They aim to minimize makespan and minimize total completion time on m identical machines. On makespan minimization, they gave an optimal algorithm for the case reduce tasks can be preemptive, and devised a (3/2 - 1/2m)-approximation algorithm for the case reduce tasks can not be preemptive. In terms of minimizing total completion time, they devised a heuristic and an approximation algorithm for the cases of preemptive and non-preemptive reduce tasks, respectively. Jiang et al. [11] expanded Zhu et al’s work and provided approximation algorithms for it.
For online scheduling problems in MapReduce system, Moseley et al. [6] used a two-stage flexible flow shop problem to model the MapReduce system. The goal is to minimize the total flow time. They designed an online (1 + ∈)-speed O (1/∈ 2)-competitive algorithm, where 0 < ∈ ≤ 1. Zheng et al. [7] constructed a new standard for measuring the performance of online algorithms, called efficiency ratio. Then, they devised an algorithm with a small efficiency ratio for the case that reduce tasks can be preemptive. Le et al. [9] discussed the online MapReduce load balancing problem under imbalanced data input. They proposed an online algorithm with a competitive ratio of 2 and a sample-based enhancement algorithm, which probabilistically achieved a 3/2-competitive ratio with bounded errors. Luo et al. [10] investigated the online MapReduce scheduling problem where the reduce tasks of a job are unknown before the completion of its map tasks. For both the preemptive and non-preemptive cases, they designed online optimal algorithms with the same competitive ratio of (2 -1/m). Chen et al. [12] studied the online MapReduce scheduling problem, where jobs are released over time. They aimed to minimize the makespan. They showed the lower bound and designed a (2 -1/m)-competitive algorithm for non-preemptive reduce tasks. They devised a 1-competitive online algorithm on two parallel machines for preemptive reduce tasks. Jiang et al. [13] addressed online problem of MapReduce scheduling on two parallel machines. They devised an optimal algorithm for the case that reduce tasks can be preemptive. Huang et al. [14] investigated a special case of online over-list MapReduce processing problem on two identical machines where each job consists of only one map task and one reduce task.
Almost all of the above MapReduce scheduling problems focus on online or off-line scheduling problems. In practical problems, however, there are few opportunities for these two situations. In most cases, we only know partial information about the problems, such as the total sum of the processing times, the largest processing time, the ordering of processing time, etc. Understanding the partial information of the job helps to arrange the execution order of tasks and allocate resources more reasonably in the MapReduce framework. This can reduce waiting time and improve the overall efficiency of job execution. To our best knowledge, there is limited literature on the semi-online MapReduce scheduling problem. If the largest processing time is known beforehand, He and Zhang [15] presented a 4/3-competitive optimal algorithm. For the case where the total sum of the processing times is known beforehand, Kellerer et al. [16] presented a 4/3-competitive optimal semi-online algorithm, too. Tan and He [18] considered the problem that the information sum and max are known beforehand. The sum denotes knowing the total sum of the processing times beforehand. The max means knowing the processing time of the largest job beforehand. They designed a 6/5-competitive optimal algorithm. Dósa et al. [19] addressed semi-online scheduling problem on two uniform machines where the optimal offline makespan is given beforehand. They aimed to minimize the makespan. They designed a compound algorithm and achieved tight bounds. Chen et al. [20] discussed several semi-online scheduling problems on two identical machines. The goal is to maximize total early work. When the total processing time of all jobs is given beforehand, they devised a 6/5-competitive optimal online algorithm. They proved that the tight bound is still 6/5 when the optimal criterion value is known in advance. When the the maximal job processing time and the total processing time of all jobs are known beforehand, they showed that the tight bound is reduced to 10/9. Dwibedy et al. [21] surveyed semi-online scheduling algorithms in various parallel machine models. Zheng et al. [22] studied a semi-online scheduling problem with lookahead, where an online algorithm knows the information of first k jobs in advance. The objective is to minimize makespan. They investigated three situations with different initial-lookahead information and designed online algorithms, respectively.
In this study, we investigate two different semi-online MapReduce scheduling problems on two parallel machines. For the case where we know the largest processing time of the reduced task beforehand, we provide a 4/3-competitive optimal semi-online algorithm. For the case of knowing in advance the total sum of the processing times and the processing time of the largest reduce task, we propose a 4/3-competitive semi-online algorithm. We can conclude that the algorithm is the best possible when the largest reduce task meets certain conditions.
We arrange subsequent section of the study as follows: In Sect.2 we propose an optimal semi-online algorithm for the problem M1. In Sect.3 we provide a semi-online algorithm for the problem M2. Finally, in Sect.4 we conclude the paper.
In the remaining paper, we use the notations below.
p (M j ) or p (R j ): the length of the task M j or R j , j ∈ N +.
C A : the makespan produced by algorithm A.
C *: the optimal makespan.
Next, we consider the semi-online scheduling problem P2|MR, max|C
max, where we suppose that a list of jobs J
1, J
2, ⋯ , J
n
are released one by one and we don’t know any other information about the jobs besides knowing the length of the largest reduce task beforehand. For job J
j
, we assume that the length of its map task M
j
is not greater than that of its reduce task R
j
, i.e. p (M
j
) ≤ p (R
j
). Let R
max denote the reduce task with the largest processing time. If the job’s reduce task is R
max, then we call this job a large job. Without loss of generality, let M
max denote the map task of the large job. We can easily get that the optimal makespan satisfies
Now, we show the lower bound of problem M1 below.
Hence, C A /C * ≥ 4/3. The Theorem holds. ■
We will provide the best possible algorithm as follows.
For the classic semi-online scheduling problem with known largest processing time, He et al. [15] proposed the optimal algorithm for two identical machines with a competition ratio of 4/3. According to the algorithm of proposed by He et al., we can get our algorithm.
C1. The currently arrived job is a large one.
C2. If the currently arrived job is scheduled onto σ 1, the completion time of σ 1 would be greater than 2R max.
For i = j to n - 1, do
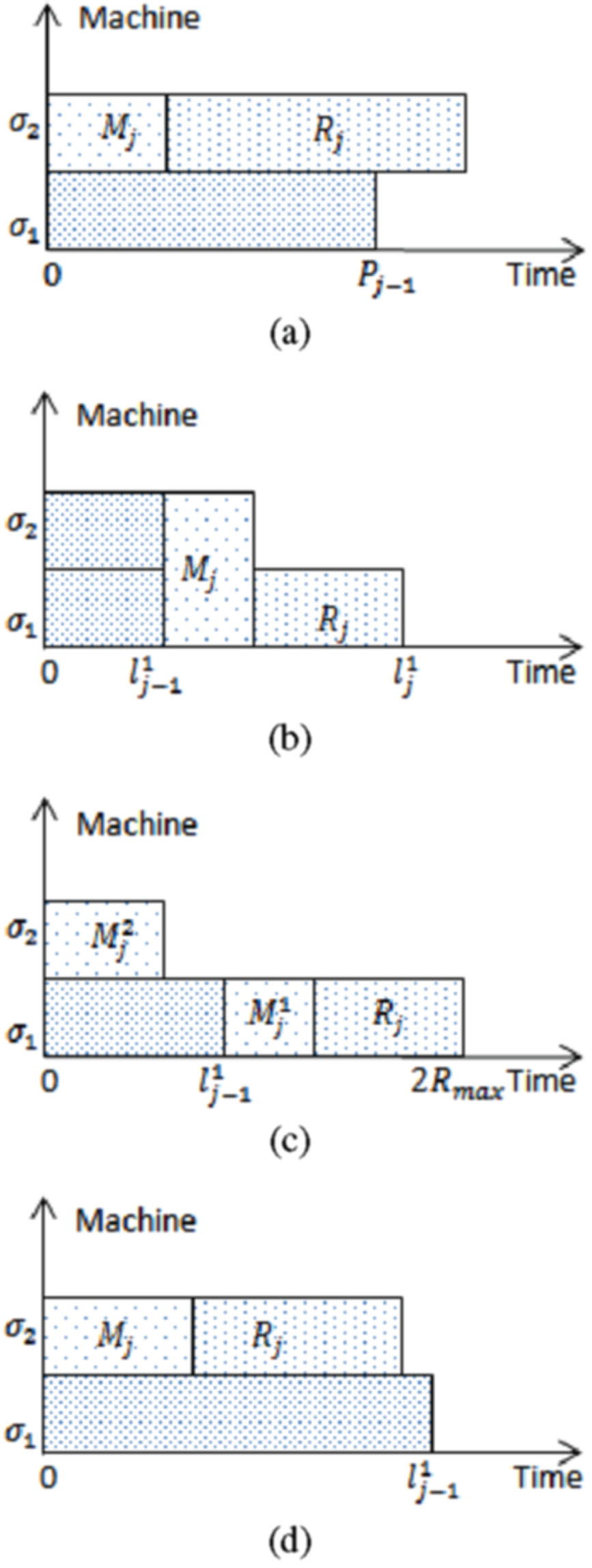
Schedule produced by Step 2 of Algorithm A 1.
Schedule produced by Step 3 of Algorithm A 1.
Case 1
Case 1.1
Case 1.1.1 J
n
is scheduled according to Step 2.1.1. We have C
A
1
= p (M
n
) + p (R
max). We can easily obtain that
Case 1.1.2 J
n
is scheduled by Step 2.1.2. We have C
A
1
= (P
n-1 + p (M
n
))/2 + p (R
max) and
Case 1.2
If
If
Case 2
Case 2.1
Case 2.1.1 J
n
is scheduled according to Step 3.1. We have
If
If
Case 2.1.2 J
n
is scheduled according to Step 3.2. We have C
A
1
= P
n
/2 + p (R
max)/2 and
Case 2.2 We consider two situations: firstly,
Case 2.2.1 J
n
is assigned according to Step 3.1. We have
Therefore, we get
Case 2.2.2 J
n
is scheduled by Step 3.2. We have C
A
1
= P
n
/2 + p (R
n
)/2 and
In this section, we discuss the semi-online problem P2|MR, sum & max|C
max. A series of jobs J
1, J
2, ⋯, J
n
arrive over list and will be scheduled onto two machines. We assume that we do not have much knowledge about the jobs except that we know the total sum of the processing times and the value of the largest reduce task beforehand. For job J
j
, we assume that the length of its M
j
is not greater than that of its R
j
, i.e. p (M
j
) ≤ p (R
j
). We use T to denote the total sum of the processing times, i.e.,
Now, we verify the lower bound of M2, and the conclusion is derived according to the following five lemmas.
Hence, C A /C * ≥ 6/5. The Lemma holds.■
■
■
■ Now we will propose an algorithm A 2 for problem M2. The design of algorithm A 2 depends on the ratio between T and p (R max). We can easily obtain the desired ratio if the ratio between T and p (R max) is too big or too small, i.e. T/p (R max) >5 or T/p (R max) <2. Therefore, we devise a new procedure to address the remaining cases carefully. According to the value of T/p (R max), algorithm A 2 chooses a suitable procedure.
0.8pt
0.8pt
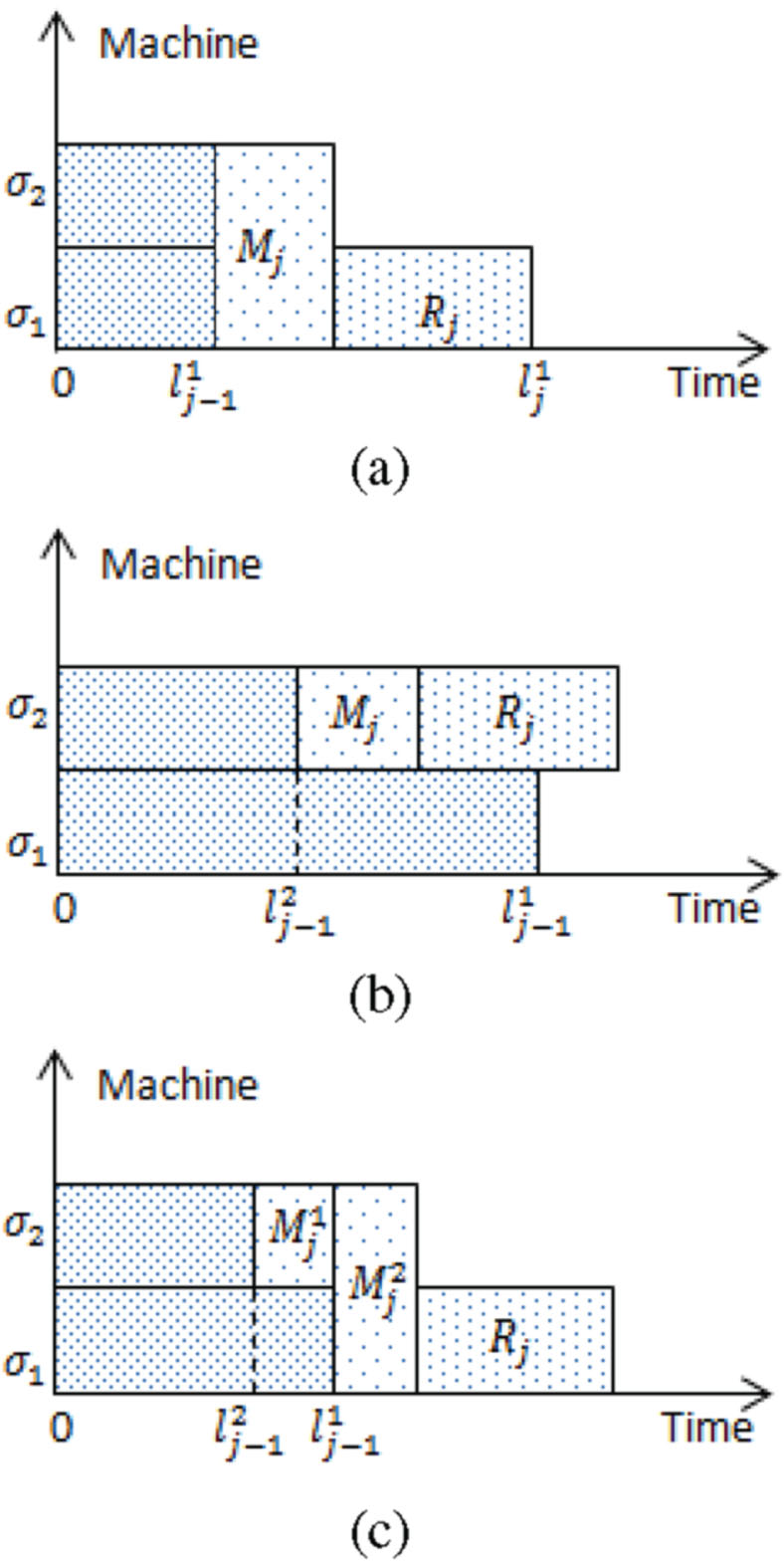
Schedule produced by Step 1 of Algorithm A 2.

Schedule produced by Step 2 of Algorithm A 2.
The difference between the completion times of the two machines does not exceed the processing time of the largest reduce task. The following theorem provides competitive ratio of the algorithm A 2.
Before we provide our main result, we introduce a lemma that is useful to prove Theorem 3.2.
Suppose that s1 and s2 are known information, such as the total processing time of all jobs, the largest processing time of all jobs and so on.
(2) if A is a l A -competitive semi-online algorithm for P2|s1|C max(or P2|s2|C max), then the competitive ratio of A is at most l A for solving P2|s1 & s2|C max.
Case 1. T/2 ≤ p (R max) < T. We can conclude that C * ≥ p (M max)/2 + p (R max). J j is scheduled as follows.
Case 1.1 J j is scheduled according to Step 1.1. We have C A 2 = p (M max) + p (R max). Therefore,
Case 1.2 J j is scheduled according to Step 1.2. We consider two cases below.
Case 1.2.1 p (M max) ≥ (T - p (R max))/2. We can obtain that C A 2 ≤ (T - p (R max))/2 + p (R max) = (T + p (R max))/2. Therefore, we have
Case 1.2.2 p (M max) < (T - p (R max))/2. We can obtain that C A 2 ≤ p (M max) + p (R max). Therefore, we have
Case 2. 2T/5 ≤ p (R max) < T/2. We take into account the following two cases.
Case 2.1 p (M max) + p (R max) ≤3T/5. Whether J j is scheduled by Step 1.1 or Step 1.2, we can conclude that C A 2 ≤ 3T/5 and C * ≥ T/2. Therefore, we have
Case 2.2 p (M max) + p (R max) >3T/5. We get C * ≥ max {T/2, p (M max)/2 + p (R max)}. J j is scheduled as follows.
Case 2.2.1 J j is scheduled according to Step 1.1. We can obtain that C A 2 = p (M max) + p (R max). Therefore, we have
Case 2.2.2 J j is scheduled according to Step 1.2. We think about the following two cases.
Case 2.2.2a p (M max) ≥ (T - p (R max))/2. We can obtain that C A 2 ≤ (T - p (R max))/2 + p (R max) = (T + p (R max))/2. Therefore, we have
Case 2.2.2b p (M max) < (T - p (R max))/2. We can obtain that C A 2 ≤ p (M max) + p (R max). Therefore, we have
Case 3. 0 < p (R max) ≤ T/5. All jobs are scheduled according to Step 2. Due to the difference in completion time between the two machines not exceeding p (R max), we get
Case 4. T/5 < p (R
max) <2T/5. All jobs are scheduled by Step 3. According to Lemma 3.6, we can get
By now, we show that the result holds for any cases. ■
According to Theorem 3, we can get the corollary as follows.
In this study, we address the semi-online problem of MapReduce scheduling on two parallel machines, aiming at minimizing the makespan. We discuss two versions under the assumption that the processing time of each job’s map task is not greater than that of its reduced task. Firstly, suppose that we know the processing time of the largest reduce task beforehand, we give a 4/3-competitive optimal algorithm. Secondly, suppose that we know the total sum of the processing times and the processing time of the largest reduce task in advance, we verify the lower bound and design a semi-online algorithm. When the largest reduce task meets certain conditions, the algorithm is the best possible. Future research direction is suggested to consider the general situation of m ≥ 2 parallel machines and semi-online algorithms with other basic types of partial information.
Acknowledgments
The authors would like to thank the editors and anonymous reviewers for their constructive comments, which have significantly improved the quality of the paper.
This work was supported by the National Natural Science Foundation of China(No.12271295), the National Science Foundation of China (No.12001313) and the Natural Science Foundation of Shandong Province of China (No.ZR2020QA023).
Conflict of interest
The authors declare no conflict of interest.