
Abstract
In recent years, the burgeoning imperative of energy-efficient building management practices has surged dramatically, underscoring an urgent mandate for comprehensive studies that integrate cutting-edge optimization algorithms with precise heating load forecasting techniques. These studies are not merely endeavors; they represent concerted efforts to increase building energy efficiency and address mounting concerns regarding sustainability and resource utilization. In the intricate domain of heating, ventilation, and air conditioning (HVAC) systems, energy optimization challenges are being meticulously confronted through rigorous exploration and the application of innovative problem-solving methodologies. This pioneering study introduces groundbreaking methodologies by seamlessly integrating two state-of-the-art optimization algorithms— the Red Fox Optimization and the Golden Eagle Optimizer— with the Decision Tree model. This fusion is aimed at enhancing the accuracy of heating load predictions and streamlining HVAC system optimization processes, marking a significant leap toward achieving heightened energy efficiency and operational efficacy in building management practices. The study emphasizes the significance of precise heating load prediction in advancing energy efficiency, realizing cost savings, and fostering environmental sustainability in building management. Furthermore, it delves into the multifaceted impact of various building features on heating load, encompassing variables such as glazing area, orientation, height, relative compactness, roof area, surface area, and wall area. These insights furnish actionable intelligence for refined decision-making processes in both building design and operation. Based on the results, the DT single model experienced the weakest performance among the three models, with R 2 = 0.975 and RMSE = 1.608. The model DTFO (DT + FOX) achieves an extraordinary R 2 value of 0.996 and RMSE value of 0.961 for heating load prediction, surpassing the performance benchmarks set by other models. This achievement holds considerable promise for aiding engineers in crafting energy-efficient buildings, particularly within the swiftly evolving landscape of smart home technologies.
Introduction
The construction industry is a significant energy consumer and carbon emitter within contemporary society [1]. Mitigating building energy consumption and its linked carbon emissions calls for the effective prediction of building thermal loads, a vital aspect with extensive utility in optimizing HVAC systems [2], enhancing the operation of thermal energy storage [3], planning energy distribution systems [4], and managing smart grids [5], to name a few. To determine a structure’s cooling load (CL) or heating load (HL), it is essential to scrutinize the temperature profiles within smart homes. When the interplay between building structure and energy needs is understood, architects and builders can formulate energy-efficient building designs that optimally utilize energy for heating and cooling. Therefore, estimating a building’s HL and CL has posed a longstanding challenge in building energy efficiency [6–8]. The prediction of energy consumption holds a significant place in research, considering that it accounts for roughly 30% of the overall energy usage and contributes to approximately 33% of carbon emissions in 2021 [9]. Even with advancements in the construction industry, current initiatives fall short of achieving the 1.5°C scenario, necessitating the implementation of intelligent and sustainable infrastructures to accommodate the swiftly expanding urban landscape. Predicting and modeling energy consumption are essential to developing resource-efficient and intelligent infrastructure. Notably, three primary approaches for modeling and forecasting building energy consumption are physical, data-driven, and hybrid models [10]. Among the methodologies considered, data-driven approaches have become the most apt for integrating into smart homes [11].
In the physical models, predictions are made using equations that describe the physical dynamics of a system. In contrast, data-driven methods use historical system behavior data to generate output. Among data-driven methods, those employing regression models to identify the most precise function for mapping input parameters to observed output can be categorized into statistical and machine-learning methods [12, 13]. In statistical methodologies, the complexity of these functions is frequently preordained by the regression model, where the parameters and architecture of the model are explicitly specified. Conversely, within the domain of machine learning [14, 15], the methodology takes a divergent path as it autonomously adjusts and comprehends the complexity of the functions, typically through iterative processes such as training and optimization [16]. This distinction illuminates the intrinsic adaptability and self-learning prowess inherent in machine learning algorithms, setting them apart from traditional statistical approaches.
Efficiently managing and optimizing building energy consumption necessitates comprehensive data on the building’s performance and environmental conditions. While electricity, gas, and heating supply represent critical energy resources within a structure, the key applications for these resources encompass elevators, heating, ventilation, air conditioning (HVAC), domestic hot water, and more. Notably, among these energy sources, the effective operation of HVAC systems and the provision of indoor environmental conditions stand out as crucial elements in evaluating a building’s energy efficiency [17, 18]. HVAC systems, which serve as fundamental building infrastructure, are responsible for modulating the internal CL and HL of residential structures. While the necessity of these systems in buildings is undeniable, a substantial concern arises from the fact that approximately 40% of all energy consumption, particularly in office buildings, is attributed to these systems [19, 20]. Accurate prediction of thermal loads is a crucial factor in optimizing building heating and cooling expenses. Any deviations from the optimally scheduled load values can significantly escalate the overall operational costs [21]. Within engineering and the context of forecasting HL, the Decision Tree (DT) algorithm is a valuable instrument known for its proficiency in managing intricate relationships within datasets. As SB Kotsiantis highlighted in their foundational DT research [22], these models have proven their effectiveness in capturing intricate interdependencies among diverse parameters. Consequently, engineers benefit from a robust framework, enabling accurate estimations of HL demands across various building scenarios [23].
Researchers have employed various methodologies to forecast heating and cooling loads and energy demand across diverse building contexts [24–31]. For instance, in one study [32], the MLP method was utilized with meteorological data to predict building heating loads, while another [33] simultaneously forecasted both cooling and heating loads using meteorological and date data inputs. Furthermore, a study [34] investigated a building’s energy performance employing machine learning techniques such as general linear regression, artificial neural networks, decision trees, support vector regression (SVR), and ensemble inference models for cooling and heating load forecasting. The impact of structural and interior design factors on cooling loads was explored through a range of regression models [35], while HVAC system energy demand was estimated from cooling and heating load requirements using various regression models. In commercial buildings, cooling load and electric demand were forecasted for short-term and ultrashort-term management [36], augmenting energy efficiency through a hybrid SVR approach. Additionally, the SVR method was applied [37] to project cooling loads in a large coastal office building in China, introducing a novel vector-based SVR model to enhance robustness and forecasting precision [31].
This research primarily aims to offer indispensable support to architects and design engineers in the pre-design phase of energy-efficient building projects, focusing specifically on the precise estimation of HL. The DT model has been meticulously developed to realize this objective as a robust tool for accurately predicting building energy loads. This predictive capacity holds remarkable significance within this context. The model’s performance has been further enhanced by employing two distinct optimization algorithms: the Fox Optimization (FOX) optimizer and the Golden Eagle Optimizer (GEO). The outcomes generated by these three models, comprising a single model and two optimized versions, underwent rigorous assessment involving a range of performance metrics, such as R2, RMSE, MAE, SI, and n10-index. Consequently, this extensive evaluation identified the superior ensemble model, essential for precisely forecasting HLs in building systems.
The paper’s subsequent sections follow a structured progression: Section 2 meticulously delineates the materials and methodologies harnessed in the study, offering transparency into the research process. Section 3 unfolds the paper’s core, unveiling the research findings and initiating comprehensive discussions that probe their significance and implications. Finally, Section 4 concludes the paper, summarizing key takeaways and their broader implications to opt for the best-performed model to use in designing energy-efficient buildings.
Materials and methods
Data collection
This research aims to predict building HL using experimental energy consumption data. The study employs a DT simulation approach with two specialized optimizers to refine DT hyperparameters. Input parameters, such as relative compactness, surface area, wall area, and more, are used to estimate HL in kilowatts (kW), and Table 1 summarizes the input and output parameter statistics [38, 39].
The statistical properties of the input variable of heating
The statistical properties of the input variable of heating
Decision Tree (DT)
The DT is a supervised learning approach for regression and classification tasks [40]. It involves a hierarchical tree structure with distinct levels or divisions. In regression tasks, where no specific category or class is defined, this technique makes predictions based on independent variables [41, 42].
The model illustrated in Fig. 1 represents a straightforward DT. It consists of a single binary target variable, Y (0or1), and two continuous variables, x1 and x2, with values ranging from 0 to 1. This structure can be visualized as a partitioned physical space, as shown in Fig. 2. Segmenting the sample space into discrete, non-overlapping, and exhaustive segments is a fundamental aspect of this analytical framework. Each segment corresponds directly to a unique leaf node, the final output resulting from a sequence of decision-making steps. Each data point is assigned to a single segment, a leaf node. DT analysis aims to identify the optimal model for effectively partitioning the available data into discrete segments.

Sample DT based on binary target variable Y.
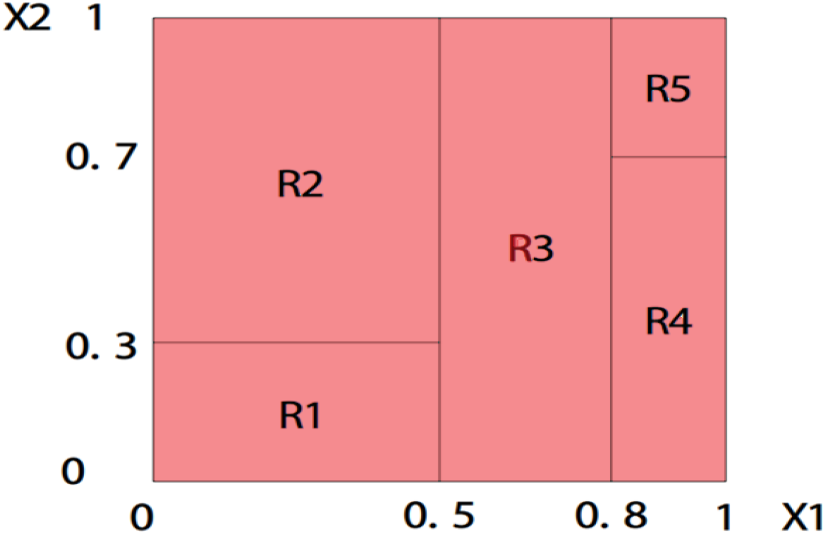
DT illustrated using a sample space view.
A DT model is primarily composed of nodes and branches. The key phases in constructing such a model involve the processes of splitting, stopping, and pruning.
Red Fox Optimization (FO)
The Red Fox Optimization Algorithm (RFOA) is inspired by red fox hunting behavior and consists of two main stages: exploitation and exploration. The exploitation stage mirrors a fox closing in on its prey, while their relative distance influences the exploration phase. The algorithm operates with a constant population of foxes, as outlined below [43]:
To identify each fox, denoted as
The notation
Additionally, concerning the solution space, a function
When the foxes cannot locate prey, family members venture out in search of food. When they discover a more favorable area, they share the location, and the population is sustained based on the associated cost. The Euclidean squared distance serves as the metric for this purpose:
Here 
In this case, α is randomly selected from the range
The random value β, falling within the range <0,1>, is applied as a single setting for all individuals within the population. This value characterizes the action of the fox as: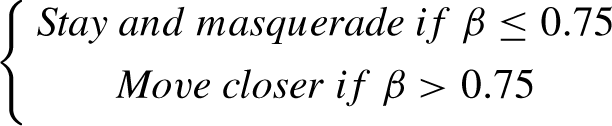
A sophisticated Cochleoid formula represents the actions of individuals if β affects the population’s migration in a certain cycle. The fox radius has two components: φ0∈ 〈 0, 2π 〉 for the initial observation angle and α∈ 〈 0, 0.2 〉as a scaling parameter, preset for all individuals in the population to represent random changes in distance as the fox approaches the victim:
Here, δ is a randomly determined variable that depends on the weather and is set once at the beginning of the process. It ranges from 0 to 1. The following is a description of the population’s movement pattern: 
Where “ac” in
To simulate this action in every iteration, 5% of the least successful candidates are chosen based on the criterion function. This choice is made as a subjective tendency to bring about little variances among the bunch. Two of the highest-performing people are chosen to create an alpha pair during iteration t:


Here, ‘H’ means habitat. In each iteration, a random parameter q, ranging from 0to 1, is selected to dictate the substitutions made during the repetition as follows:
The top two candidates denoted as 
RFOA (Red Fox Optimization Algorithm)
The hunting behavior of golden eagles can be mathematically delineated as follows [44]:
•The rotational movement exhibited by golden eagles
The exploration into the spiraling flight patterns of golden eagles revolves around a research inquiry where one eagle, denoted as n, selects its target prey from a different eagle through a random process fand loops the finest prior advert of f, with the ability to encircle its recollection(fin { 1, 2, . . . , PopSize }) .
•Selecting a Target from Potential Victims
During the iterative process, exploration agents adjust their positions by retrieving data from a collective repository, whereas the golden eagles in GEO’s system haphazardly choose prey from the memory of any fellow flock member without being restricted by spatial nearness.
•Attack (exploitation)
The computation of the attack vector, which extends from the present location of the golden eagle n to its recollected prey, is attainable Equation (10):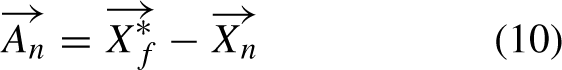
Given this situation,
•Cruise (exploration)
The cruise vector arises from altering the attack vector along the tangent of the circle in i-dimensional space, which symbolizes the speed of the prey and is established by Equation (11)’s hyperplane equation. 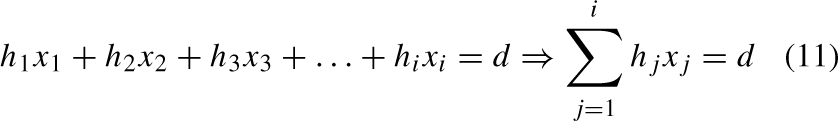
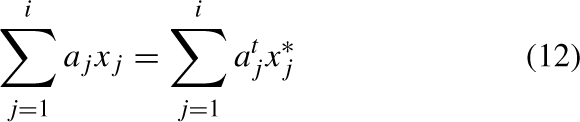
Given this situation, 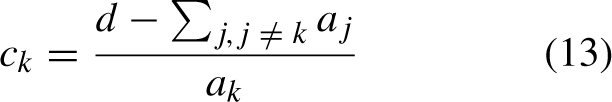
In this structure, c
k
represents the k - th component of point C, a
j
representing the j - th component in the attack vector A
n
, and d is linked to the value in Equation (11). Also,
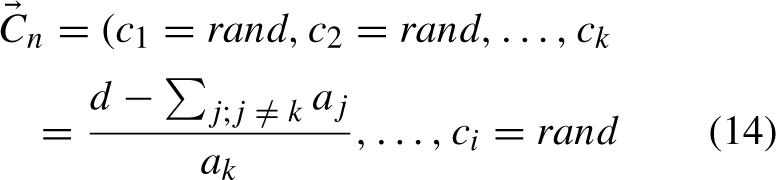
Compute the cruising vector for Golden Eagle ‘n’ in iteration ′t′ by using random values within the [0, 1] range. This steers the population away from prior recollections and enriches GEO’s exploration.
•Transitioning to Fresh Roles
Golden eagles possess both attack and cruise motion vectors. For golden eagle nduring iterationt, the step vector is determined by Equation (15).
During repetition ‘t,’ the navigation of golden eagles is impacted by crucial factors 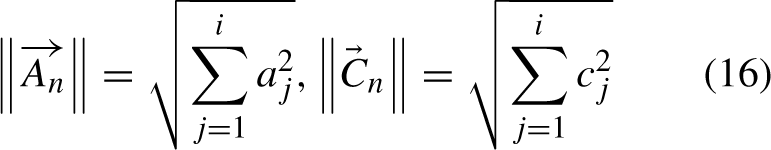
In iteration (t + 1) , the golden eagles’ locations are determined by merging the step vector computed in iteration t with their positions from iteration t.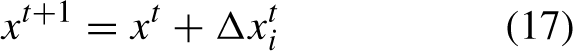
Golden eagles improve their locations through the coefficients in Equation (15), namely,
•Shifting from Exploratory to Exploitative Activities
The optimization strategy employed by the Golden Eagles comprises an initial soaring stage, succeeded by a hunting phase, and offers adaptability through the utilization of the parameters p
a
and p
c
.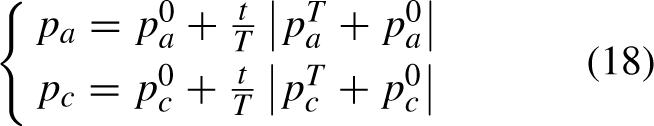
Within the mathematical representation, the symbol t denotes the current iterative step, and T represents the upper limit for the number of iterations. The variables
Within this investigation, the efficacy of prediction algorithms underwent a meticulous assessment utilizing an extensive set of five critical performance metrics, as reported in Table 2.
Performance evaluation metrics
Performance evaluation metrics
Here, n corresponds to the total number of data points, Ti and Hisymbolize the test and predicted results, respectively,
Results of evaluation metrics
Table 3 summarizes performance metrics, encompassing R2, RMSE, MAE, n10-index, and SI, across all prediction models applied to the training, validation, and testing datasets. Subsequent analysis delves into a detailed evaluation of the model’s predictive accuracy in estimating the HL:
The result of developed models for DT
The result of developed models for DT
The R2 values for all network models vary from 0.968 (noted in the DT single model during validation) to 0.996 (achieved in the training phase of the DTFO ensemble model). These results emphasize the substantial accuracy achieved by the developed models. The DTFO model stands out as the best model due to its R2 value being closest to 1, with a difference of 1.8% compared to the DT model and 0.9% compared to the DTGE model during the training phase.
In error analysis, the DTFO model outperforms other models with RMSE values approximately two times lower than the DT model and 1.5 times lower than the DTGE model. This highlights the DTFO model’s superior predictive accuracy and significantly reduced discrepancies between predicted and actual values compared to the other models.
The n10-index metric assesses the proportion of models with error values below the 10 percent threshold. The results indicate that during the training phase of DTFO, 97% of its models met this criterion, while the testing phase demonstrated 99.1% compliance. In contrast, DTGE had a lower percentage of models below the 10 percent threshold during the training phase, with 83.8%, and a higher proportion during the testing phase, reaching 80% compared to the corresponding testing results for DTGE.
SI is a valuable tool for gauging the dispersion or variability of data points within a dataset. Notably, a lower SI value signifies less divergence among the data points, highlighting superior model performance. This trend is evident when examining the DTFO model, which boasts an SI value of 0.031. This value outperforms DTGE by 39.21% and surpasses the DT single model by 54.41%, reaffirming its prowess in minimizing data spread and enhancing predictive accuracy.
In Fig. 3, a reference line, y = x, along with two lines, y = 1.1x, and y = 0.9x, incorporated to expedite the identification of the optimal model. Based on the data distribution close to the center line, it becomes evident that the DTFO model is the most favorable. This assertion is substantiated by the observation that the data points of the DTFO model exhibit significantly reduced dispersion as they approach the vicinity of the designated lines compared to the other models. Upon scrutinizing the remaining two figures and assessing the dispersion of data points between the reference lines, a hierarchical ranking of model performance emerges. After the DTFO model, the DTGE model takes the second position in performance, revealing a comparatively inferior performance compared to the best model. In contrast, the DT single model, when compared to the other models, exhibits the highest degree of data dispersion, indicating its comparatively weaker performance.

Plotting the dispersion of evolved ensemble models.
In Fig. 4, three plots are presented, of which two pertain to error metrics, while the third is associated with the R2 values. The representation takes the form of a column chart, where, concerning error metrics, a shorter column corresponds to superior model performance. In the case of R2 values, a taller column signifies enhanced model performance. Based on the elucidations offered, it becomes evident that in the RMSE and MAE charts, the DT model exhibits the tallest columns, signifying its comparatively weak performance when juxtaposed with the other models. Conversely, in the R2 chart, the tallest column corresponds to DTFO, which underlines the model’s superiority compared to the other alternatives.

Stacked column plot to compare the developed models by presented metrics.
Figures 5 and 6 depict the error values of three models (DTFO, DTGE, and DT) by utilizing two distinct visualization formats: the distribution-rug plot and the violin with quartile plot. As illustrated in Fig. 5, it is apparent that the DT model exhibits a frequency of approximately 0.05, the DTFO model has a frequency of around 0.15, and the DTGE model is associated with a frequency of about 0.06 all of the frequencies are effectively converging to a near-zero percentage of error. Consequently, the DTFO model emerges as the most favorable model due to its highest frequency compared to the other models. According to the visual representation as Fig. 6, an analysis of error percentages reveals notable distinctions among the DT, DTGE, and DTFO models. Specifically, the DT and DTGE models exhibit error percentages ranging from approximately 40% to –35%. In contrast, the DTFO model demonstrates a narrower error range, falling within the interval of approximately 20% to –10%.

The error percentage of the models is based on the distribution-rug plot.

The violin with quartile plot errors of proposed models.
Based on these two types of plots, to provide a more nuanced understanding of model performance, it is imperative to underscore that a lower error rate indicates superior model performance. So, the DTFO model emerges as the most proficient performer, as its error percentage range is closer to zero. This observation underscores the DTFO model’s ability to generate predictions with higher accuracy than the DT and DTGE models. Consequently, when considering the quality of model outcomes, the DTFO model outshines its counterparts by demonstrating superior predictive accuracy, enhancing its utility in practical applications.
The Wilcoxon test [45] was utilized to evaluate the relative effectiveness of three models: DT, DTFO, and DTGE. By analyzing the test outcomes, including the p-values and statistics for every model pair, valuable insights into their statistical significance were obtained. Table 4 displays the outcomes of the Wilcoxon test, indicating that there is no statistically significant distinction in performance between DT and DTGE (p-value = 0.7183, Statistic = 143539), as well as between DT and DTFO (p-value = 0.5041, Statistic = 145429.5). These results imply similar performance among the model pairs. Nonetheless, the assessment between DTFO and DTGE indicates a slightly noteworthy difference (p-value = 0.1771, Statistic = 139346). Although the findings do not meet the usual thresholds for significance, they hint at a possible distinction worth exploring further. To summarize, the Wilcoxon test indicates similar performance between DT and DTGE, as well as between DT and DTFO. However, there is a slight but noteworthy difference between DTFO and DTGE, underscoring the importance of careful interpretation and the potential for deeper investigation.
Results of the Wilcoxon Test
Results of the Wilcoxon Test
Table 5 presents the findings of prior research endeavors in Heating Load prediction, providing a comprehensive benchmark for comparison with the current study. Among the three models documented in this table from previous research, the GPR model, as presented in the study by Roy et al. [46], demonstrated the highest performance, boasting an R2 of 0.99 and an RMSE of 0.059. As elaborated in Sections 3.1 and 3.2, the investigation underscores the superior performance of the DTFO model during the training phase, yielding impressive metric scores with an R2 value of 0.996 and an RMSE of 0.691. This dual excellence in pivotal metrics firmly establishes the DTFO model in the study as surpassing its counterparts, emphasizing its efficacy in predicting Heating Load.
Comparing the results of the present study with previous studies
Comparing the results of the present study with previous studies
In summary, in the field of building energy management, this study examined the critical requirement for precise energy consumption predictions and the evaluation of retrofit techniques. It has traditionally been difficult to predict building energy use accurately because of a variety of variables, including building attributes, energy systems, weather patterns, and tenant behavior. Although physics-based simulations provided insightful information, their accuracy depended on the availability of thorough data and intricate modeling. In response to these difficulties, this research investigated the potential of machine learning approaches, concentrating on Decision Tree models, by using the ever-increasing amount of publicly available building energy data. The results revealed that the DTFO (Decision Tree optimized with Fox Optimization) model emerged as the top-performing model among the other two alternatives. The DTFO model displayed an impressive correlation with the actual measured HL, achieving a high R2 value of 0.996, surpassing DT and DTGE (Decision Tree optimized by Golden Eagle optimizer) by 1.8% and 0.9%, respectively. Notably, the DTFO model also showcased superior accuracy compared to the other models, evident through its minimal RMSE value of 0.691. This translated to a substantial 54.59% reduction compared to DT and a 39.86% decrease relative to DTGE in RMSE values. This underscores the considerable promise of machine learning, as demonstrated by DTFO, to greatly improve the accuracy of energy consumption predictions. Therefore, it gives stakeholders more influence over energy-saving and retrofit solutions, supporting the main goals of environmentally friendly building operations and sustainability.