
Abstract
Biomedical image analysis has progressed significantly with the integration of artificial intelligence, presenting new opportunities for early diagnosis and treatment of diseases with high mortality rates, such as skin cancer. This research work introduces a novel Hybrid Attention Residual Deep Convolution Learning (HARDCL) Model designed to enhance the accuracy of skin lesion classification, which is often challenging due to the subtle characteristics of lesions. The HARDCL Network employs an innovative hybrid attention mechanism within a residual learning framework, effectively distinguishing between benign and melanoma skin lesions with a high degree of precision. The encoder-decoder network segments the lesion from dermoscopic images, followed by feature extraction and classification, achieving a maximum accuracy of 97.11%, precision of 98.10%, recall of 98.81%, and an F1-score of 98.45%. This performance surpasses conventional deep learning algorithms such as AlexNet, InceptionV3, and ResNet18, demonstrating the effectiveness of the attention-based features in identifying critical lesion characteristics. However, despite its strengths, the HARDCL Network’s computational intensity and the need for a substantial dataset for optimal training highlight areas for further refinement. The proposed network advances the field of skin cancer diagnostics, offering a robust tool for medical professionals and setting a foundation for future enhancements in automated biomedical image analysis techniques.
Keywords
Introduction
The proliferation of artificial intelligence is visible and unavoidable in biomedical image analysis. With accurate prediction and classification techniques, early diagnosis of deadly diseases reduces the mortality rate. Skin cancer is one among them; specifically, early diagnosis of melanoma reduces the mortality rate by 90%. The statistics of the American Cancer Society report that 186,680 new melanomas will be diagnosed in 2023, which could increase in the year 2024. With the advancement of computational methodologies, early skin cancer assessment can be done using skin lesions. Lesions represent abnormal melanocyte production. However, identifying the correct cancer type based on the lesion is quite difficult as lesions have complex visual characteristics like shape, texture, and color. For example, it is difficult to differentiate if anyone saw nevi and melanoma. In some cases, typical nevi might be treated as melanoma due to their dermatological characteristics. Seborrheic keratosis is another lesion that looks like melanoma. Thus, to improve the diagnosis accuracy, dermoscopic imaging is used, which provides a magnified lesion image without any light reflections.
The early stage dermoscopic image analysis introduces rules and checklists to enhance the diagnosis accuracy [1]. However, due to complex visual characteristics, the diagnostic accuracy is limited and unreliable sometimes. Thus, computer-aided diagnosis is combined with lesion classification to attain improved accuracy. The process in computer-aided diagnosis includes preprocessing, segmentation, feature extraction, and classification. The dermoscopic image is initially preprocessed, in which additional features like an ebony frame, ruler marks, blood vessels, hair, and air bubbles are removed. Further, the lesion is segmented using segmentation techniques. Further, the features are extracted and classified to detect lesion types. Clustering-based, region-based, edge-based, and thresholding methods are used in earlier stages of skin lesion analysis.
Computer-aided diagnosis systems have utilized machine learning algorithms for biomedical image analysis for over a decade. Automated detection of skin cancer is performed in diagnosis systems using algorithms like SVM, RF, NB, kNN, ANN, gradient boosting, etc., [2, 3] The features extracted using feature extraction techniques like GLCM, local binary pattern, HOG, gaussian filter, etc., additionally Gabor methods are used in lesion feature extraction which extracts the texture, shape, and color features. The features extracted from the preprocessed image are classified using machine learning classifiers. However, machine-learning skin lesion classification models have limited discriminative abilities due to their basic learning skills. Moreover, the adaptability of the machine learning-based models is less in skin lesion classification.
Deep learning algorithms have recently been used in various domains to handle complex data [4]. In this progress, computer-aided diagnosis systems utilize deep learning techniques for medical data analysis [5]. Specifically, in biomedical image analysis, the performance of deep learning models is better than that of machine learning models. AlexNet, ResNet, and CNN are some of the familiar models used for biomedical image analysis [6, 7]. In skin lesion classification, higher performance can be achieved using deep learning models. But practically, dermoscopy images of different skin diseases have visual similarities, or the same disease has differences in their visuals. In addition to that skin lesion area, a large irrelevant portion in the image might reduce the inference accuracy. Thus, developing an effective technique that could provide higher accuracy in the classification process is essential. The objective of this research work is to attain improved classification accuracy in skin lesion classification. For this, this research work contributes the following. Presented a Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network for skin lesion classification, which classifies the lesion into benign, non-benign, melanoma, and non-melanoma. Segmentation is important in skin lesion classification. An encoder-decoder network is presented to accurately segment lesions from the dermoscopic image. Presented the experimental analysis using the standard skin lesion image database ISIC 2020 and evaluated the proposed model performance through recall, precision, f1-score, and accuracy metrics. Presented a brief comparative analysis with existing techniques evolved for skin lesion classification, which utilizes the ISIC2020 database, and discussed the observations.
The arrangements of the remaining discussion are given in the following points. A few recent deep learning and machine learning models based on skin lesion classification are studied, and the summary is presented in the related works section. The proposed model’s complete process is presented in detail in Section 3. Results and discussions are presented for the proposed model, and a comparative analysis summary is presented in Section 4. The conclusion is presented in the last section.
Related works
Skin lesion classification is found to be an accurate diagnostic procedure, and numerous approaches have evolved in recent times. The observations made while studying the recent research works are summarized in this section. The CNN-based skin lesion classification model presented in [8] utilizes multiple imaging modalities to acquire patient metadata. Then, the multiple modality data are combined and classified using the CNN model for automated skin lesion diagnosis. The presented model attained an average accuracy in melanoma classification, which is lower than that of recent classification models. The skin lesion classification model reported in [9] presents an attention CNN model to classify dermoscopy images. The architecture of the attention CNN model includes global average pooling, convolution, and classification layers. The residual network-based attention module included in the classification network enhances the feature discrimination ability of the deep convolution neural network. Experimentations using standard datasets validate the better classification performance over conventional methods [10].
The mask RCNN-based skin lesion segmentation and classification model reported in [11] employs ResNet50 and the feature pyramid network as the backbone. Then, the features obtained from the fully connected layers are mapped for mask generation. Further, using CNN, the features are processed and classified through the SoftMax classifier to attain better classification performances. However, the accuracy obtained is comparatively lesser than that of the recent model. The hierarchical model reported in [12] for skin lesion classification initially enhances the lesion contrast by fusing the local image with a globally enhanced image. Further, three-step super-pixel lesion segmentation is employed for skin lesion segmentation. By mapping the enhanced images, a segmented color image is obtained. Finally, using ResNet50, the features are learned to classify the skin lesions. Additionally, an improved grasshopper optimization is included to select the optimal features. Due to this, better classification is attained compared to existing machine learning-based classification models.
The multi-class skin lesion classification model presented in [13] initially employs a local color-controlled histogram intensity approach to enhance the image quality. Further, the deep saliency segmentation method utilizes a ten-layer CNN to estimate the saliency. Based on the threshold function, the generated saliency heat map is converted into a binary image, and then features are extracted using CNN. Improved moth flame optimization is included to handle the dimensionality issues in the classification process, which optimally selects the discriminant features. The obtained features are fused through multiset maximum correlation analysis and then classified through a kernel extreme learning machine. Compared to other approaches, the computation complexity of the presented model is high due to multiple feature processing techniques. The multi-class extreme learning machine-based skin lesion classification model presented in [14] initially incorporates a hybrid strategy to fuse the binary images obtained from the CNN model. Then, using a contrast transform, enhanced saliency segmentation is performed. Further, using maximal mutual information, the features in the binary and saliency segmented images are fused to obtain a segmented color image. Finally, using pre-trained DenseNet201, the lesion is processed and classified to attain better accuracy compared to existing methods.
The multi-scale CNN model presented in [15] for skin lesion classification employed EfficientNetB0 and EfficientNetB1 models to extract the deep features from skin lesions. The extracted features are fused further to attain better classification performances. However, the accuracy obtained in skin lesion classification is comparatively lesser than that of the recent deep-learning models. The AlexNet-based skin lesion classification presented in [16] incorporates a transfer learning procedure to enhance the classification performance of the traditional classifiers. The presented model randomly initializes the network weights and evaluates the performance using a benchmark dataset. The experiment results show that the transfer learning combined with AlexNet outperformed lesion classification compared to conventional AlexNet.
An adaptive neuro-fuzzy classifier-based skin lesion diagnosis procedure presented in [17] utilizes a top hat filter and inpainting technique to preprocess the input image. Further, the preprocessed image is segmented using the grabcut algorithm, and feature extraction is performed using the Inception model. Finally, features obtained from the inception network are classified using an adaptive neuro-fuzzy classifier with better accuracy and sensitivity compared to conventional approaches. The skin cancer classification model presented in [18] employed pre-trained GoogleNet with a transfer learning procedure to attain better classification performances. The presented model extracts the deep features by adjusting the training parameters. Experimentations using the benchmark ISIC dataset validate the proposed model’s better classification accuracy over conventional classification procedures. A similar model presented in [19] employed GoogleNet and Inceptionv3 models for skin lesion classification. The presented approach initially utilizes the CNN model to classify the skin lesions as a binary classification process. Further, using the results of binary classification, the network is trained to provide multi-class skin lesion classification results with better accuracy.
The patch-based attention architecture presented in [20] addresses issues like high resolution and class imbalance in the classification process. The presented model offers a global context between high and small-resolution patches and utilizes pre-trained deep-learning architectures to classify the lesions. A diagnosis-guided loss weighting method has also been provided for ground truth annotation. Due to this, the classification sensitivity is improved, and losses are balanced in the skin lesion classification process. An entropy-controlled neighborhood component analysis model was presented in [21] for skin lesion classification. The presented model integrates the deep features to obtain the most discriminate feature vector using deep models. Using principal components, the feature fusion is optimized, and the redundant or irrelevant data are removed. Due to this, the presented model attained better classification accuracy than conventional methods. The generative adversarial network used in [22] classifies different lesions from the dermoscopic image. The presented model modifies the conventional GAN noise input and style control and adjusts the discriminator and generator parameters to synthesize the skin lesion images. Finally, using DNN with transfer learning, the images are classified and attain better classification performance. In addition to the traditional evaluation metrics, inception score and inception distance are also considered to measure the performance of GAN in the skin lesion classification process.
An ensemble of DCNN models is presented in [23] for skin lesion classification. The presented model fuses the classification layers outputs of different CNN models used in the ensemble network and performs a final classification using the weighted output of member CNN. Due to this fusion and classification process, the presented model attained better detection performance in skin lesion analysis. The ensemble model presented in [24] for malignant melanoma detection includes multiple CNN architecture to represent the different levels of feature abstractions. The architecture of CNN is similar, but the hyperparameters are varied for each network to extract the diverse deep features. Finally, the features are classified using the SVM classifier, and the average prediction probability is fused to provide the final results. Due to this diverse feature extraction and fusion, the classification accuracy is improved better than that of traditional models but increases the computation cost. An ensemble of deep learning models presented in [25] for skin lesion classification employed EfficientNet, ResNet, and SENet algorithms to construct the classification model. The presented model processes the lesion images through each deep-learning model and extracts the results. Finally, the best-performing model is selected in the classification process using a search strategy.
The deep CNN model presented in [26] attained improved classification performances in skin lesion analysis using a novel regularization technique. The presented model categorizes the objects based on the regularization technique, and then deep features are extracted and classified using DCNN. Due to this, the presented model attained enhanced classification performance than the conventional CNN models. A mutual bootstrapping DCNN model is presented in [27] for skin lesion segmentation and classification. The presented model includes a coarse segmentation network for generating coarse lesions, a mask-guided classification network for generating localization maps, and an enhanced segmentation network to segment the lesions with higher accuracy. The performance of the presented bootstrapped DCNN model was evaluated using benchmark datasets and attained better AUC and Jaggard index compared to conventional segmentation and classification models.
A DCNN-based skin lesion classification presented in [28] optimizes the color features to enhance the classification accuracy. The presented model fuses the optimal color features with deep features using a pixel-based fusion process. Further, the high-ranking features are selected using a normal distribution-based feature selection procedure and then classified to attain better classification performances. Experimentations using the ISBI benchmark dataset exhibit the presented model’s average accuracy. A similar DCNN-based skin lesion classification model reported in [29] modifies the traditional CNN architecture with multiple layers and different filters to improve the efficiency of the classification process. The modified architecture performance is evaluated using the benchmark ISIC dataset and attained better specificity and sensitivity compared to the traditional CNN model. From the summary, it can be observed that deep learning approaches are widely used for skin lesion classification. However, the performance of the deep learning models is limited due to inefficient feature processing. In a few research works, multiple deep learning models are employed, which increases the computation cost. It is essential to develop a system that should extract the features optimally and classify them with high accuracy in skin lesion classification.
Research gap
In reviewing the existing literature on skin lesion classification, several key gaps have been identified that our research directly addresses. Firstly, while deep learning models have significantly advanced the field of biomedical image analysis, their effectiveness is often limited by their inability to focus on critical features within highly variable images, leading to misclassification. This issue is particularly prevalent in images where lesions exhibit minute characteristics that are crucial for accurate diagnosis. Existing models, including widely used architectures like AlexNet, InceptionV3, and ResNet, primarily rely on global feature analysis, which can overlook these critical local features. Our Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network introduces a novel hybrid attention mechanism that enhances the model’s ability to identify and focus on these crucial features, thereby addressing this limitation.
Secondly, the segmentation of relevant features from biomedical images remains a challenge for current methodologies. Traditional approaches often employ separate preprocessing steps for segmentation, which can lead to loss of information or inclusion of irrelevant features, adversely affecting the classification accuracy. Our approach integrates an encoder-decoder network for segmentation directly within the classification model thereby ensuring precise extraction of relevant features without the drawbacks of separate segmentation processes.
Further, the optimization of network parameters is a critical yet often overlooked aspect of model development. Many existing studies utilize standard optimization techniques that may not fully explore the parameter space, leading to suboptimal model performance. By incorporating Jellyfish Swarm Optimization (JSO), our study not only enhances the HARDCL Network’s classification accuracy but also highlights the importance of advanced optimization methods in developing more effective biomedical image analysis tools.
Thus, to enhance the classification accuracy in skin lesion classification, a hybrid attention residual deep convolution learning network is presented in this research work.
Significance of proposed hybrid model
Here, we provide an in-depth comparison of our novel components—hybrid attention mechanism, integrated feature segmentation and classification, and optimization with Jellyfish Swarm Optimization (JSO)—against these conventional approaches.
Proposed work
The proposed Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network for skin lesion classification is presented in this section. The complete overview of the proposed classification model is presented in Fig. 1. The input Dermoscopic image is initially preprocessed in which haze reduction, fast local Laplacian filter, and HSV color transformation are performed. The preprocessed image is further processed through an encoder-decoder network with extracts and segments of the features. The final HARDCL network classifies the features using the convolution learning procedure and attention residual network. Additionally, Parameter optimization is performed using the Jellyfish Search Optimizer (JSO) algorithm to enhance the classification performance of the HARDCL network.
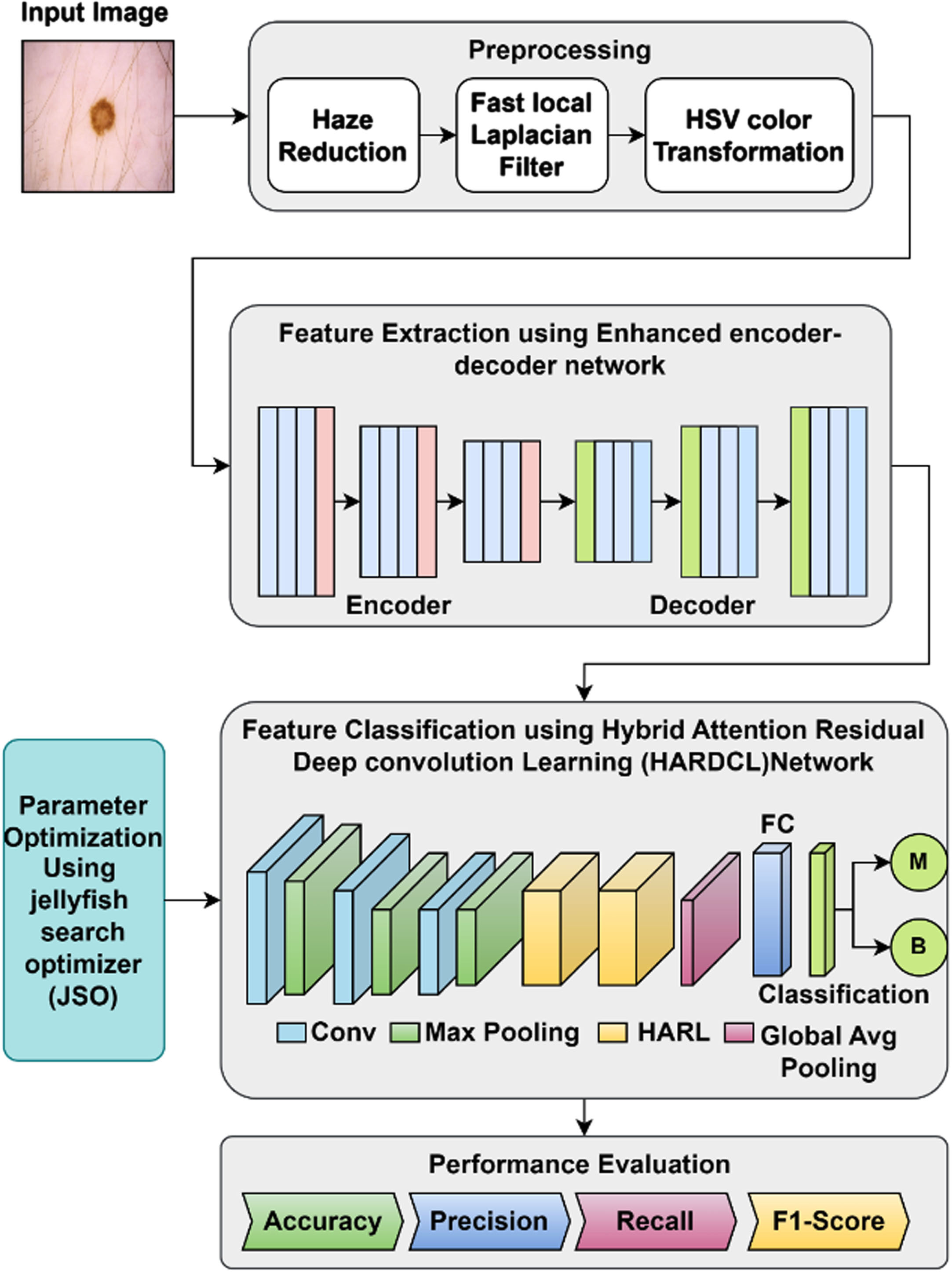
Proposed Skin Lesion classification model.
The HARDCL Network’s architecture is intentionally designed with components that collectively contribute to its performance in classifying skin lesions. The encoder-decoder network serves as the backbone, facilitating detailed feature extraction and efficient data compression, which is essential for capturing nuanced patterns within biomedical images. This component is crucial in handling the spatial complexity of skin lesions, enabling the network to differentiate between benign and malignant cases with high accuracy.
The integration of attention modules represents a significant enhancement, strategically focusing the network’s capacity on the most relevant features within a lesion. By weighting the importance of different areas in the image, these modules allow the network to prioritize lesion characteristics that are more indicative of malignancy, thus improving the precision and recall of the classification.
Lastly, the utilization of Jellyfish Swarm Optimization (JSO) in the parameter tuning process enables the network to find an optimal set of weights and biases, further refining its predictive capabilities. This optimization algorithm is particularly effective at escaping local minima, which can be a common limitation in the training of deep learning models. It ensures that the network’s parameters are adjusted in a way that enhances its ability to generalize from the training data to real-world diagnostic scenarios, which is evidenced by the improved accuracy and F1-scores reported in our results.
In the initial preprocessing, the input dermoscopic image contrast is enhanced using a haze reduction technique. The lesion region boundaries are cleared in the haze reduction process. consider the image as u (x), hazy image is considered as s (x), medium of transmission as y (x), the haze affected image is mathematically represented as
Next to haze reduction, a fast local Laplacian filter is used for edge emphasizing and smoothening. Mathematically, the Laplacian filter is represented as
The multi-scale feature learning network presented in this research work is a deeply supervised network that comprises encoder and decoder sections, each section consisting of three consecutive stages. The complete architecture of the encoder-decoder-based multi-scale feature learning model is presented in Fig. 2. The convolution layer, activation layer, SoftMax, and a conditional random field are included in the architecture. The convolution layer kernel size is 3×3, and the convolution filter size is increased from the first stage to the last stage. The activation function used in the model is ReLU, which improves the network training process. The convolution layer extracts the feature vectors and max pooling used in the encoder section down samples the input. Mathematically, the process is formulated as

Encoder-Decoder Network.
where the down-sampled feature map is indicated using f, activation function, ReLU is indicated as R, and the up and down sampling module is indicated using u and d. The final output of the encoder is indicated using Y i . The decoder up-samples the feature vectors to provide enriched information. Due to this, the vanishing gradient is avoided, and the feature information is restored with better accuracy. Followed by the decoder section convolution layer and pooling layers, the SoftMax layer is used to map the pixels. Each pixel class is predicted with a probability, which is formulated as follows.
where the feature map is indicated as x, the kernel operator is indicated as w, and the number of classes is indicated as n. The conditional random field (CRF) used in the encoder-decoder network is a fully connected dense network that includes a linear combination of Gaussian Kernels for efficient mean filed inference and edge potentials. The CRF refines and enhances the lesion contour and produces the final predicted feature map and mask. In the encoder-decoder-based multi-scale feature learning and segmentation process, the encoder provides a resolution feature vector. Also, it learns the skin lesions coarse appearance and localization details. The decoder restores the feature vectors with full resolution and learns the lesion boundaries. Thus, the system effectively processes the lesion images and provides better features for the further classification process.
The final classification in the proposed work is performed using the Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network, which includes deep convolution layers in a sequence and a hybrid attention residual learning network. Figure 3 depicts the illustration of the HARDCL network. The deep convolution layer processes the multi-scale feature segmented image obtained from the encoder-decoder network through the convolution and pooling layers. Three consecutive convolution and pooling layers are used in the proposed deep learning model. After the third convolution and pooling layer, a hybrid attention residual learning module is included in the proposed architecture. Generally, attention mechanisms are used to select the critical information for the current process from a huge volume of information. Attention mechanisms improve the feature representation abilities of deep learning models in the classification process. Thus, in the proposed classification process, the attention module is used to focus more on the critical information, which provides information about the lesion type.
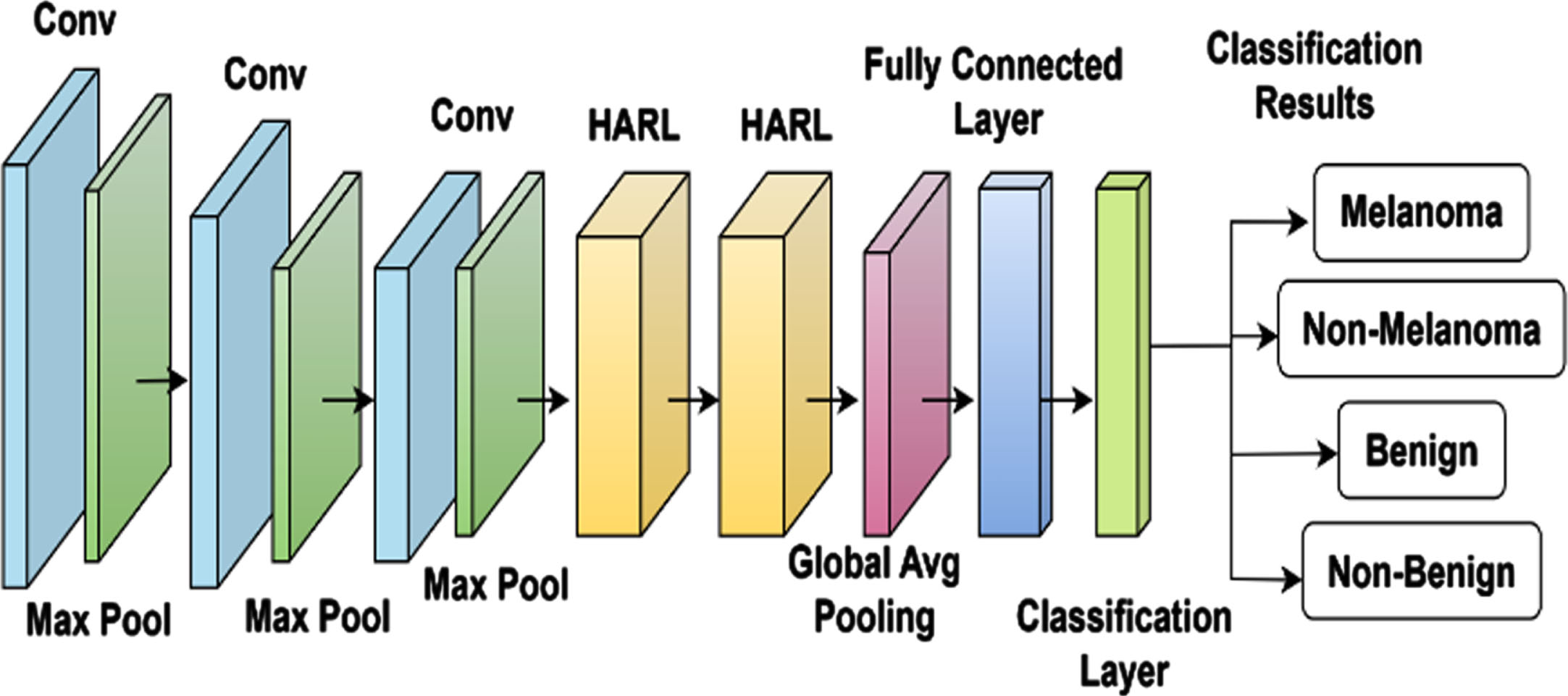
Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network.
The construction of the attention residual learning network is obtained basically from the residual network. A conventional residual network includes three convolution blocks and utilizes an identity element to combine the results of convolution. In the proposed work in between convolution and output, a spatial-wise attention mechanism and channel-wise attention mechanisms are introduced to improve the feature focus toward critical information. Figure 4 depicts an illustration of a hybrid attention residual learning module. Before formulating the spatial and channel-wise attention mechanisms, the mathematical model of the residual network is presented. The residual network comprises multiple convolutions, batch normalization, and activation layers. The learning procedure of the residual network is mathematically formulated as
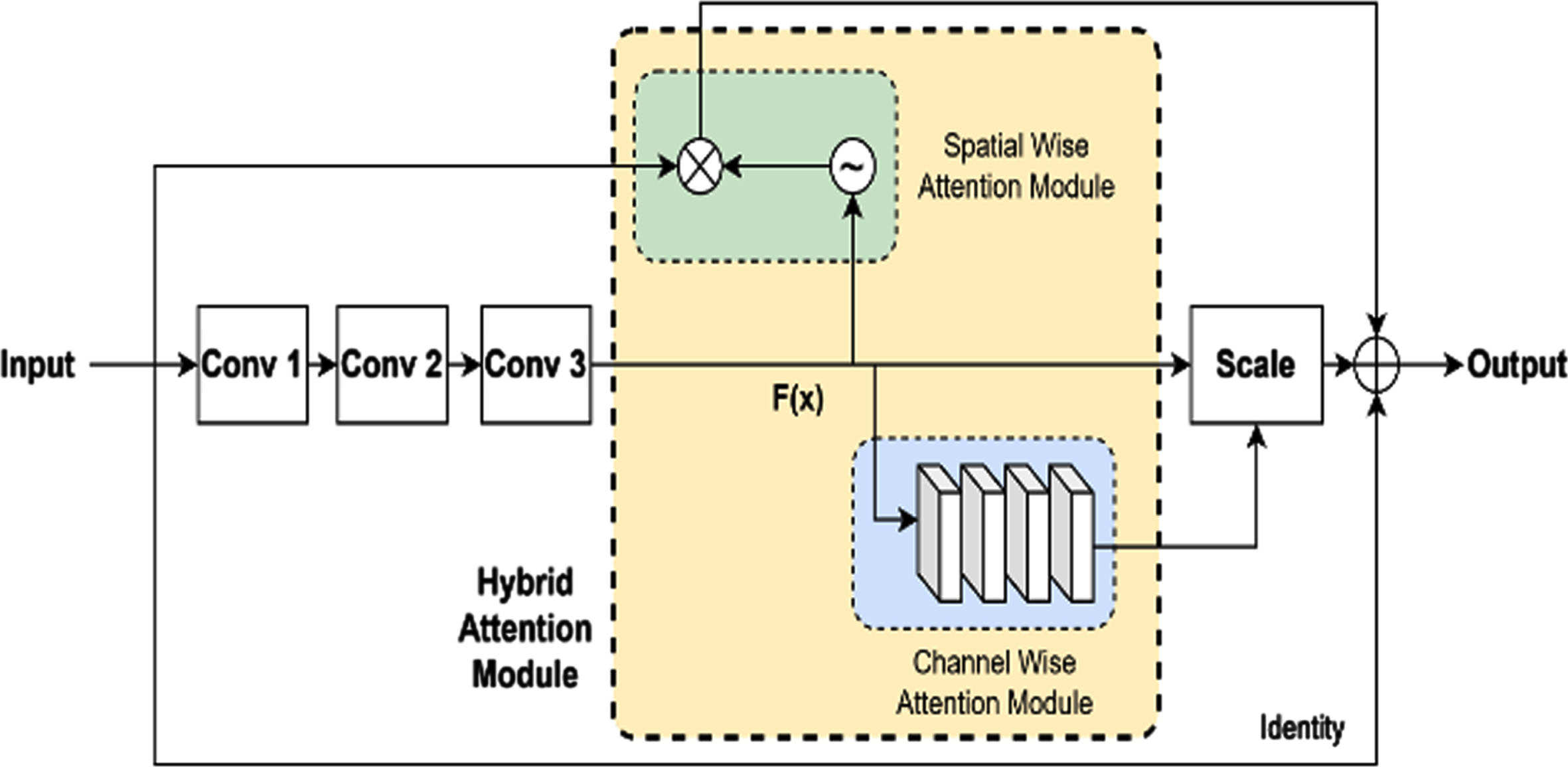
Hybrid Attention Residual learning module.
where residual mapping is indicated using the function f (·), layer weights are indicated using w, and x indicates the residual block input. During the forward propagation, the input signal directly propagates from the lower to the upper layer. Due to this, the vanishing gradient problem is addressed through the CNN-stacked multiple-residual block.
In the proposed hybrid attention residual learning mechanism, the spatial-wise attention module generates a spatial-wise attention feature map by processing the residual block input (x) and feature map f(x). In the process of generating a spatial-wise attention feature map, an attention weight is generated by performing spatial normalization on the feature map. Further element-wise multiplication is performed between the generated attention weight and residual block input (x). Mathematically, the process in spatial-wise attention module is formulated as
The channel-wise attention mechanism used in the hybrid attention residual learning module is obtained based on the SENet [30] excitation and squeeze blocks. The channel-wise attention module has four layers which are a global average pooling layer, a fully connected layer, a ReLU layer, and a sigmoid layer. The squeeze operation is performed by the global average pooling layer so that the features are down sampled to describe the statistical information as a vector function. The remaining layer performs the excitation operation, which is similar to the gating mechanism of a recurrent neural network. Two fully connected layers are used in the channel-wise attention module to describe the channel correlations. Considering the weights of the fully connected layers are given as w1 and w2, channel-wise attention weight ω is defined using the excitation operator as follows.
Further, to improve the classification performance, the network parameters of the classifier are optimally selected using a metaheuristic optimization algorithm. Jellyfish swarm optimization (JSO). Based on the food-searching behavior of jellyfish, this optimization model is developed to solve the optimization problems. The optimization model effectively avoids the local minimum and provides better convergence toward the optimum solution by effectively covering the search space. Using the ocean movement and current, Jellyfish search for food on time. The process of updating the solution based on the ocean current direction is formulated as
The performance analysis of the proposed HARDCL network for lesion classification is done using the benchmark skin lesion ISIC 2020 dataset [31, 32]. The experiments are performed using the Python tool. The essential library packages like tensorflow = = 2.10.0, keras, tqdm, opencv-python, scikit-image, numpy, pandas, scipy, matplotlib, seaborn, scikit-learn, pyqt5, prettytable, and cmapy are included for the experimentation. The ISIC dataset used for the experimentation has a diverse collection of skin lesion images. The dataset is organized with training and testing samples. The proposed model experimentation selects 1500 samples for the experimentation, in which 70% of the data is used to train the network, and 30% of the data is used to test the network. 70% of training data includes 525 benign and melanoma samples, and 30% of testing data includes 225 benign and melanoma samples. To check the proposed model’s performance, some of the melanoma samples are added to the benign test process and vice versa. Performance metrics like precision, recall, F1-score, and accuracy are considered for performance evaluation.
Figure 5 depicts the original and segmented output of the proposed model for the ISIC samples used in the proposed work.
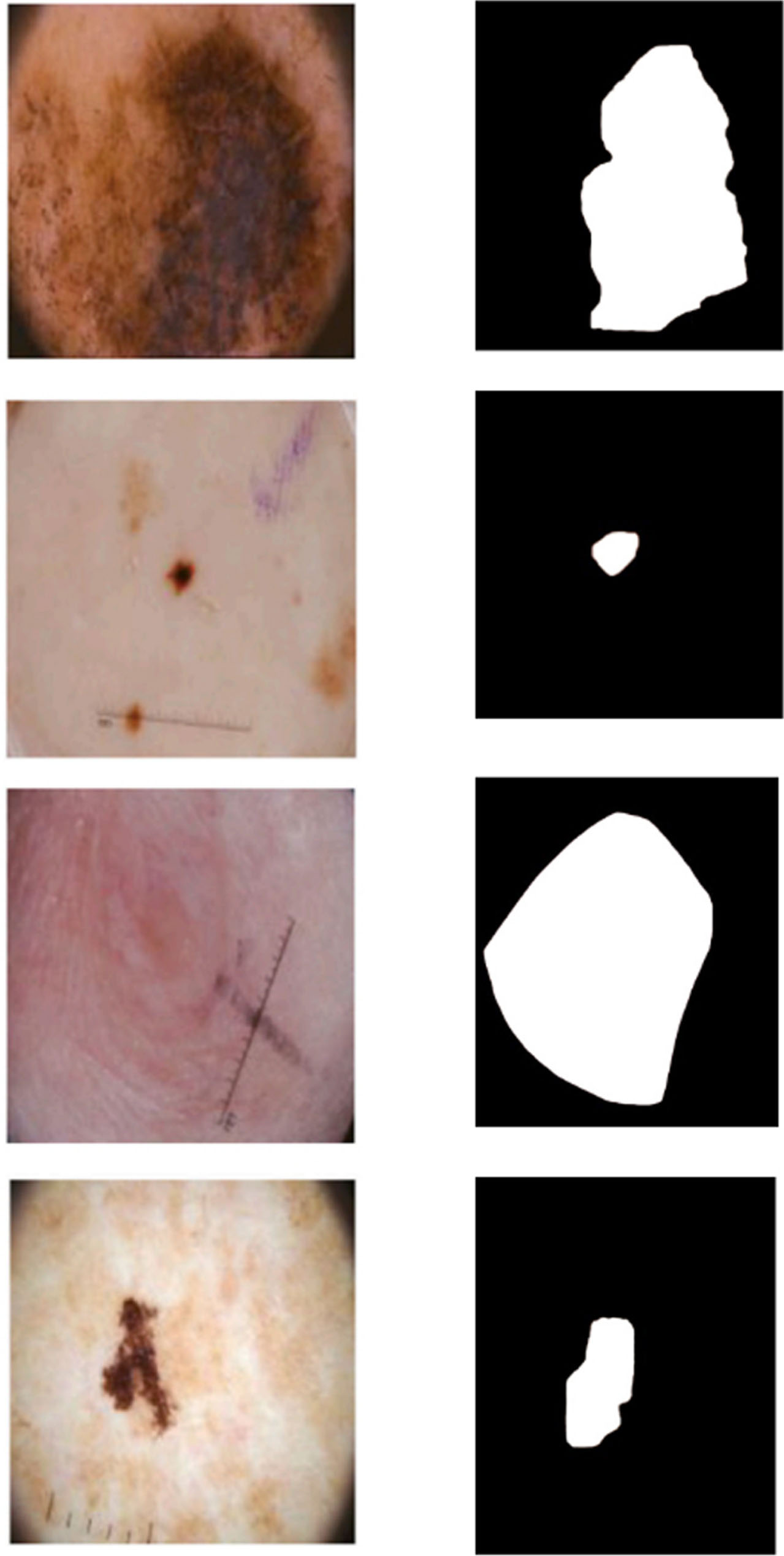
(a) Original Image (b) Segmented output.
Figure 6 (a) & (b) depicts the training and validation curve obtained in the proposed model experimentation. The training and validation curves are obtained by testing benign and melanoma samples separately. Figure 6(a) depicts the accuracy curve for benign, and Fig. 6(b) depicts the accuracy curve for melanoma. The maximum accuracy attained in the proposed model training is 97.78% and 97.79% for benign and melanoma. The test accuracy of the proposed model for benign and melanoma is 96.89% and 97.33%. This result indicates that the proposed model closely follows the training process and classifies the lesions into benign or melanoma with better accuracy.

(a) Accuracy analysis for Benign.
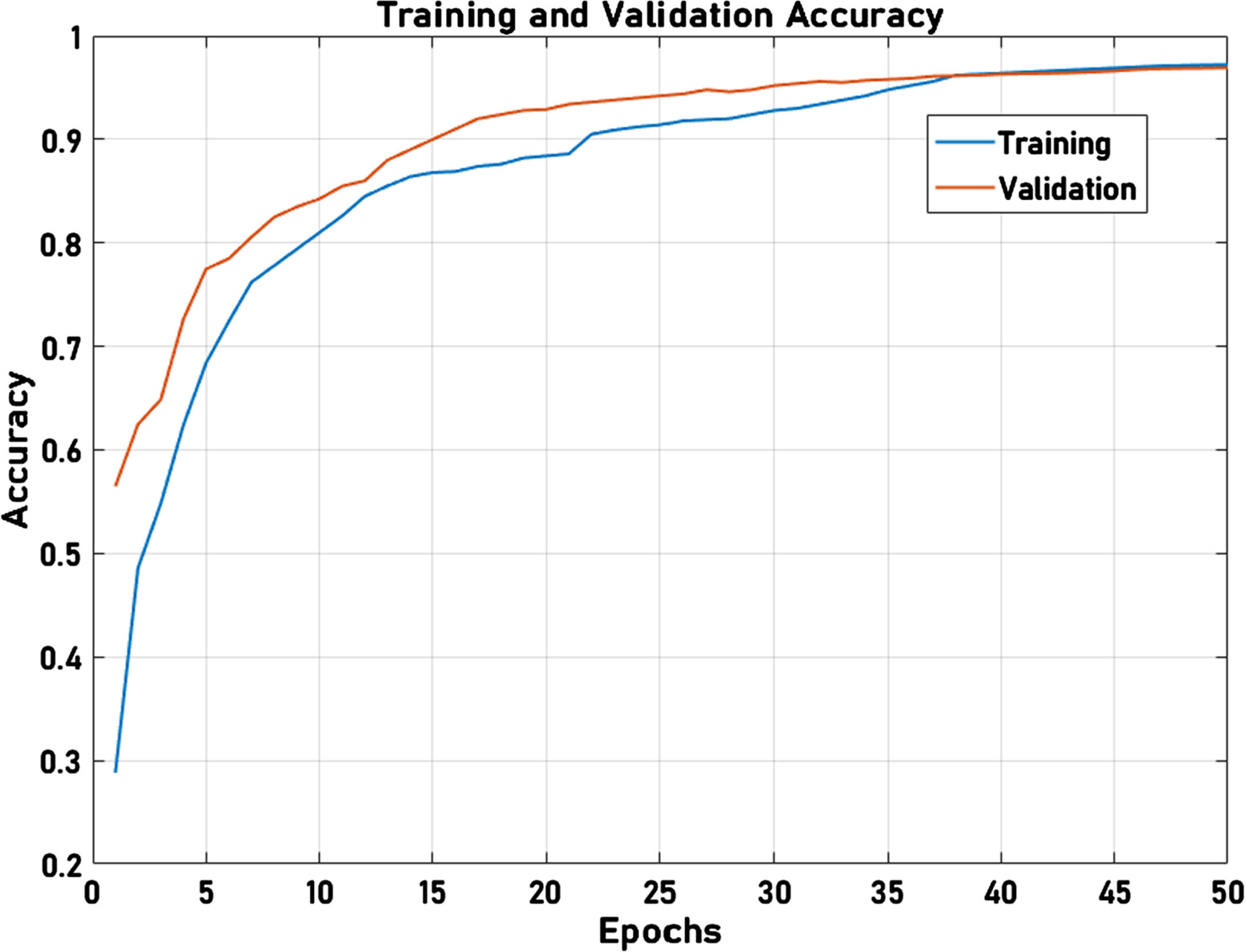
(b) Accuracy analysis for Melanoma.
The precision-recall curve of the proposed model for benign and melanoma lesions is presented in Fig. 7(a) and (b), respectively. The proposed model effectively identifies the benign and melanoma with AP values of 0.9520 and 0.9526, which indicates the proposed model’s better performance. For non-benign and non-melanoma cases, the proposed model exhibited AP of 0.9125 and 0.9344. Due to few training losses, the benign and melanoma inputs are classified as non-benign and non-melanoma, which can be observed from the AP scores of non-benign and non-melanoma cases.
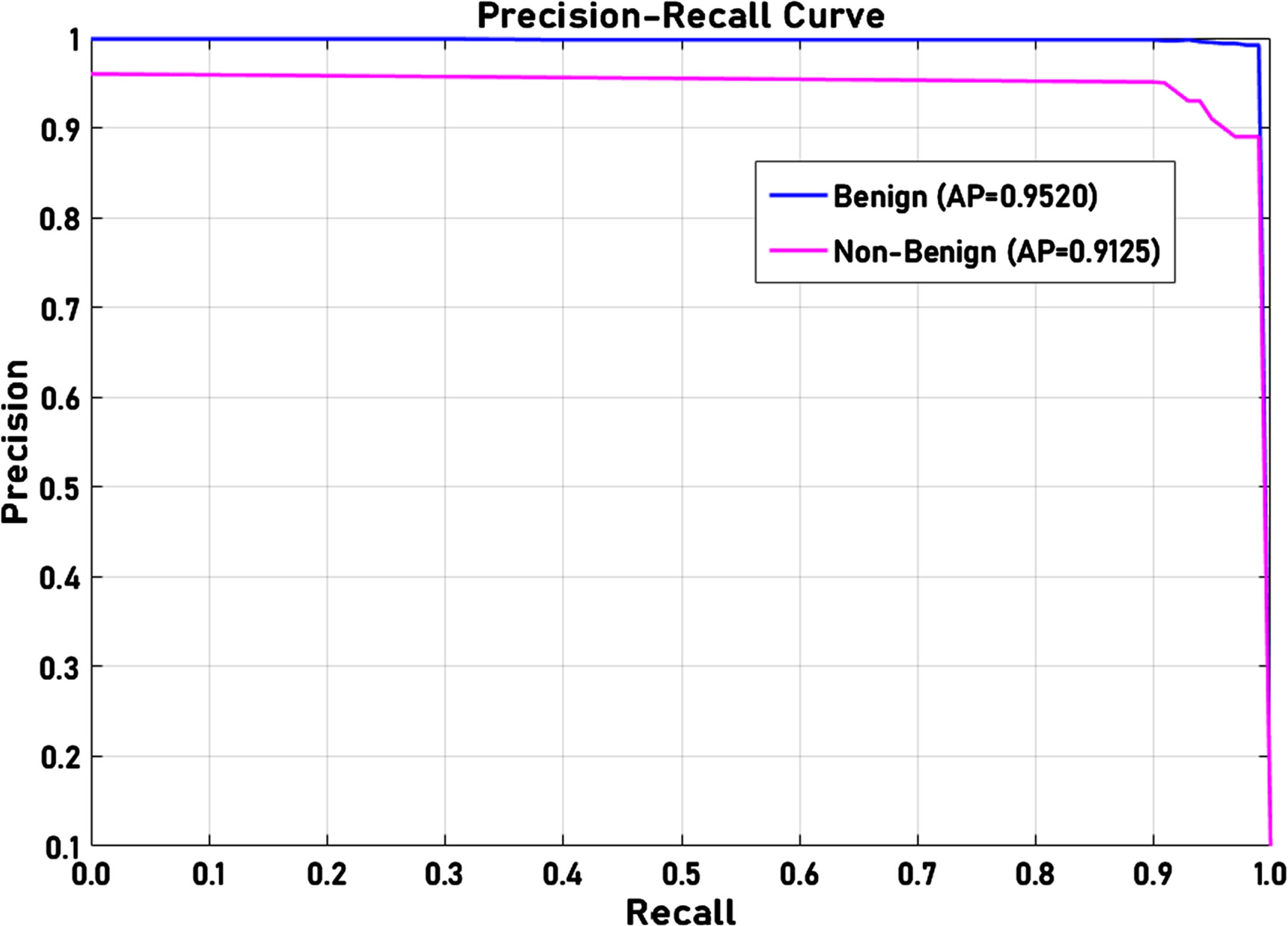
(a) Precision-Recall analysis for Benign.
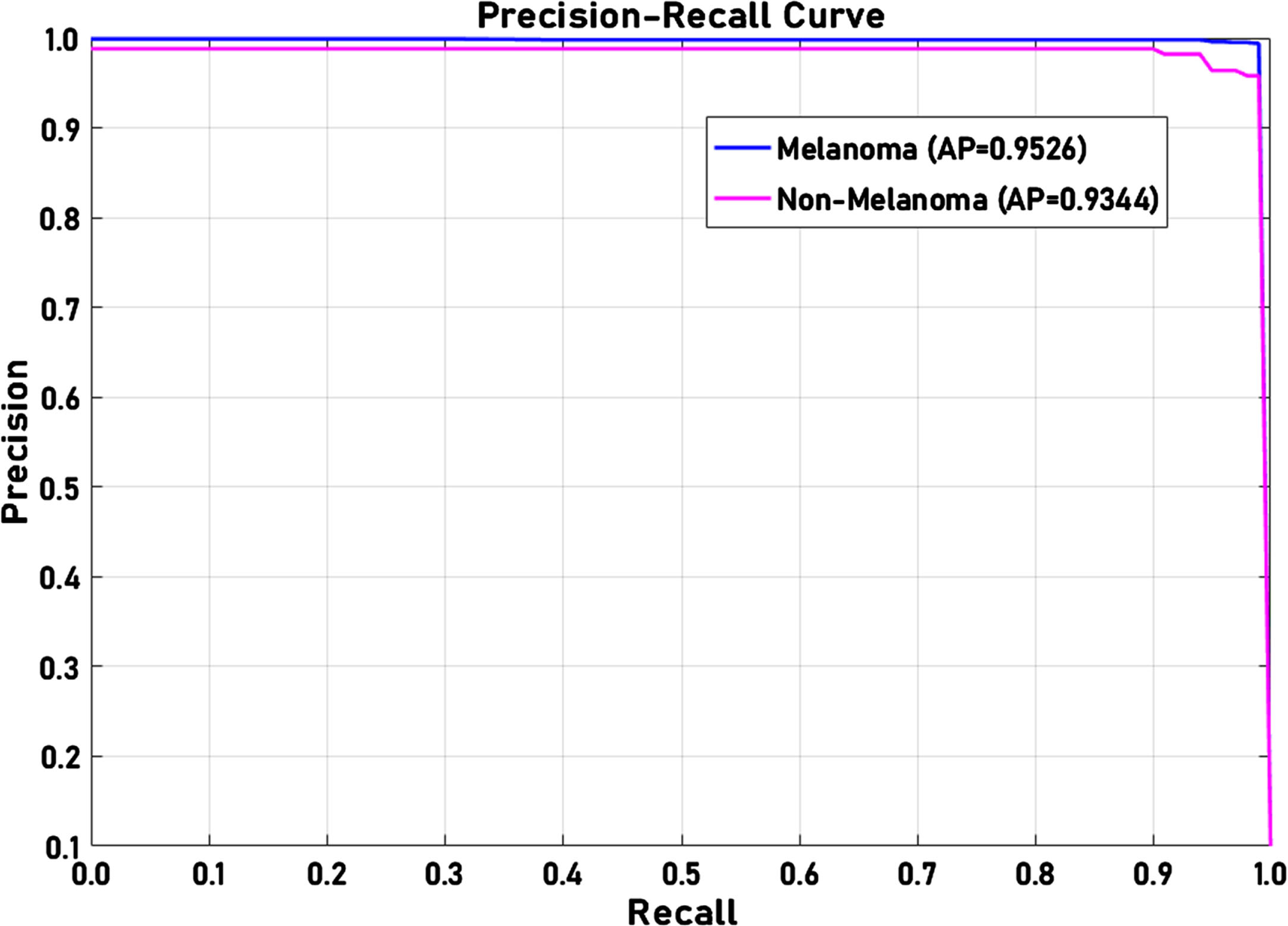
(b) Precision-Recall analysis for Melanoma.
The confusion matrix obtained by the proposed model for the benign and melanoma test process is presented in Fig. 8(a) and (b), respectively. With a total of 225 test samples, the proposed correctly identified 205 samples as benign and four non-benign samples are identified as benign and three benign samples are identified as non-benign, 13 melanoma samples are identified correctly. Similarly, the test confusion obtained for the melanoma lesion classification is presented in Fig. 8(b). The total number of true positives is 208, and the true negatives are 11. The false positive and false negative samples are 4 and 2, respectively.

(a) Confusion matrix for Benign.
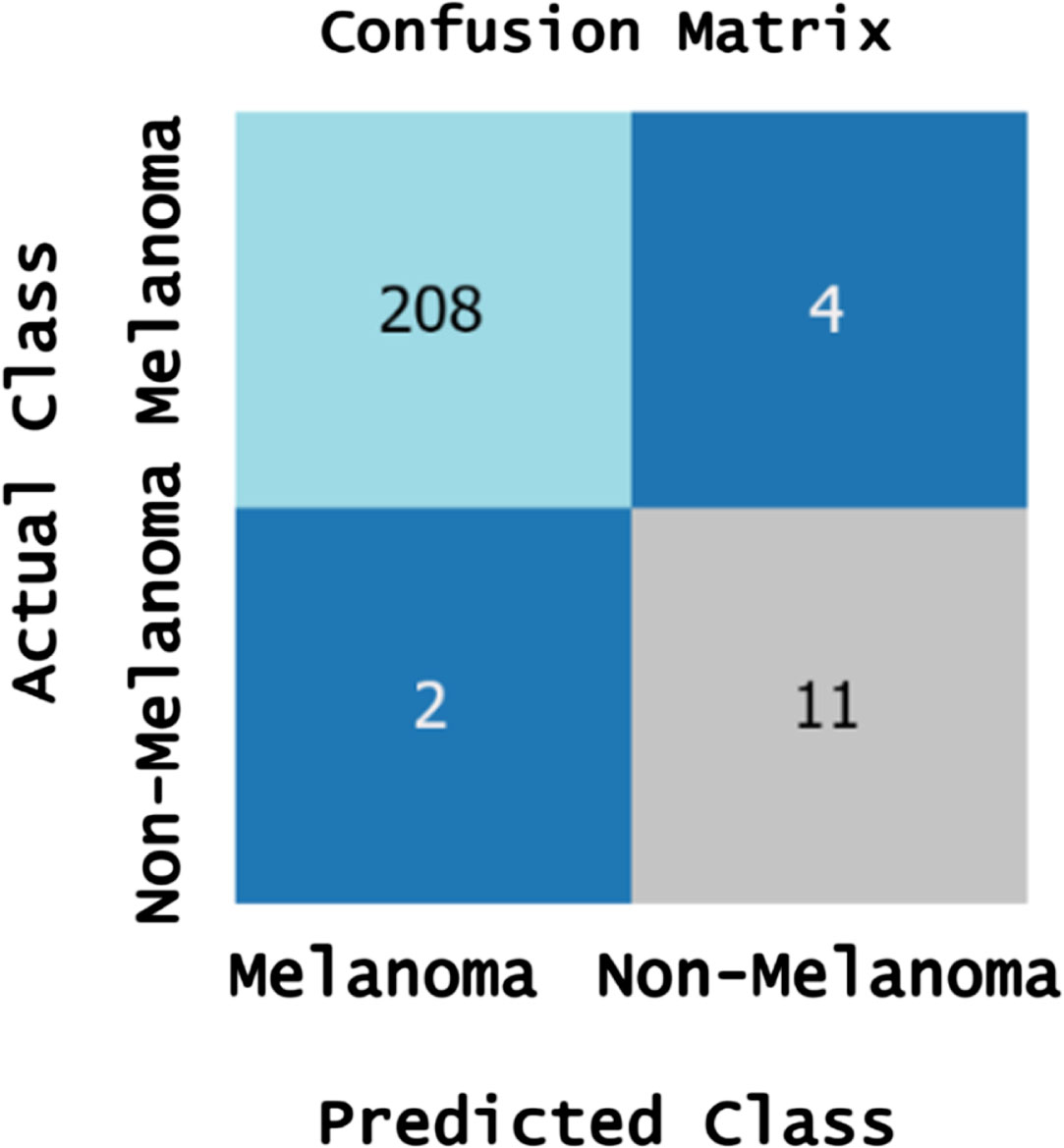
(b) Confusion matrix for Melanoma.
The numerical results of the proposed model training and testing process are presented in Table 1. The performance metrics outlined in Table 1 justify the robustness and effectiveness of the proposed HARDCL Network in distinguishing between benign and melanoma skin lesions. Notably, the model achieves high accuracy in both the training and testing phases, with a high accuracy of 97.78% for benign and 97.79% for melanoma lesions during training, which slightly decreases in the testing phase to 96.89% and 97.33%, respectively. This modest drop in performance from training to testing indicates good generalizability and minimal overfitting, suggesting that the model is well-regularized and can perform consistently on unseen data. Precision is another critical metric in medical diagnostics to avoid false positives. It remains above 98% for both lesion types in training and testing. This is particularly significant for melanoma classification, where high precision is paramount due to the serious nature of missed diagnoses. Recall rates are equally high, indicating the model’s sensitivity in identifying true positive cases of both benign and melanoma lesions. The recall is especially significant for melanoma in the testing phase, reaching 99.05%, which is crucial for a condition where early detection significantly improves patient outcomes.
Proposed HARDCL Network training and testing performance for benign and melanoma images
The F1-Score balances precision and recall and remains above 98% for both lesion types across training and testing, reinforcing the model’s balanced performance. This balance is essential in medical imaging tasks where both false positives and false negatives carry significant consequences. Area Under the Curve (AUC) values of 98.26% in training and 97.68% in testing further validate the model’s discriminatory power. AUC is a measure of the model’s ability to distinguish between classes across all thresholds, and these high values suggest that the HARDCL Model is capable of differentiating between benign and melanoma lesions with high confidence.
In summary, the performance metrics provided affirm the proposed HARDCL Network’s capability for high-precision, high-recall classification of skin lesions. It is particularly adept at handling melanoma cases, which is essential for clinical applications where the cost of misclassification is exceedingly high. These results support the model’s potential for implementation in clinical settings to aid dermatologists in the early detection and accurate classification of skin lesions.
To evaluate the better performance of the proposed model, the performance metrics like precision, recall, f1-score, and accuracy are comparatively analyzed with existing models like Ensemble, AlexNet, Inception v3, ResNet18, LCNet, and HMDL (Hybrid metaheuristics Deep Learning) models [33, 34]. Figure 9 depicts the precision comparative analysis in which the maximum precision of the proposed model is clearly visible compared to other models. The difference in precision levels of proposed and existing HMDL is about 3%, LCNet has an 8% difference in precision level, ResNet18 has an 11% difference, Inceptionv3, and AlexNet have a 31% difference in precision level, and the ensemble has a 22% difference in precision levels which indicates the superior performance of the proposed model.
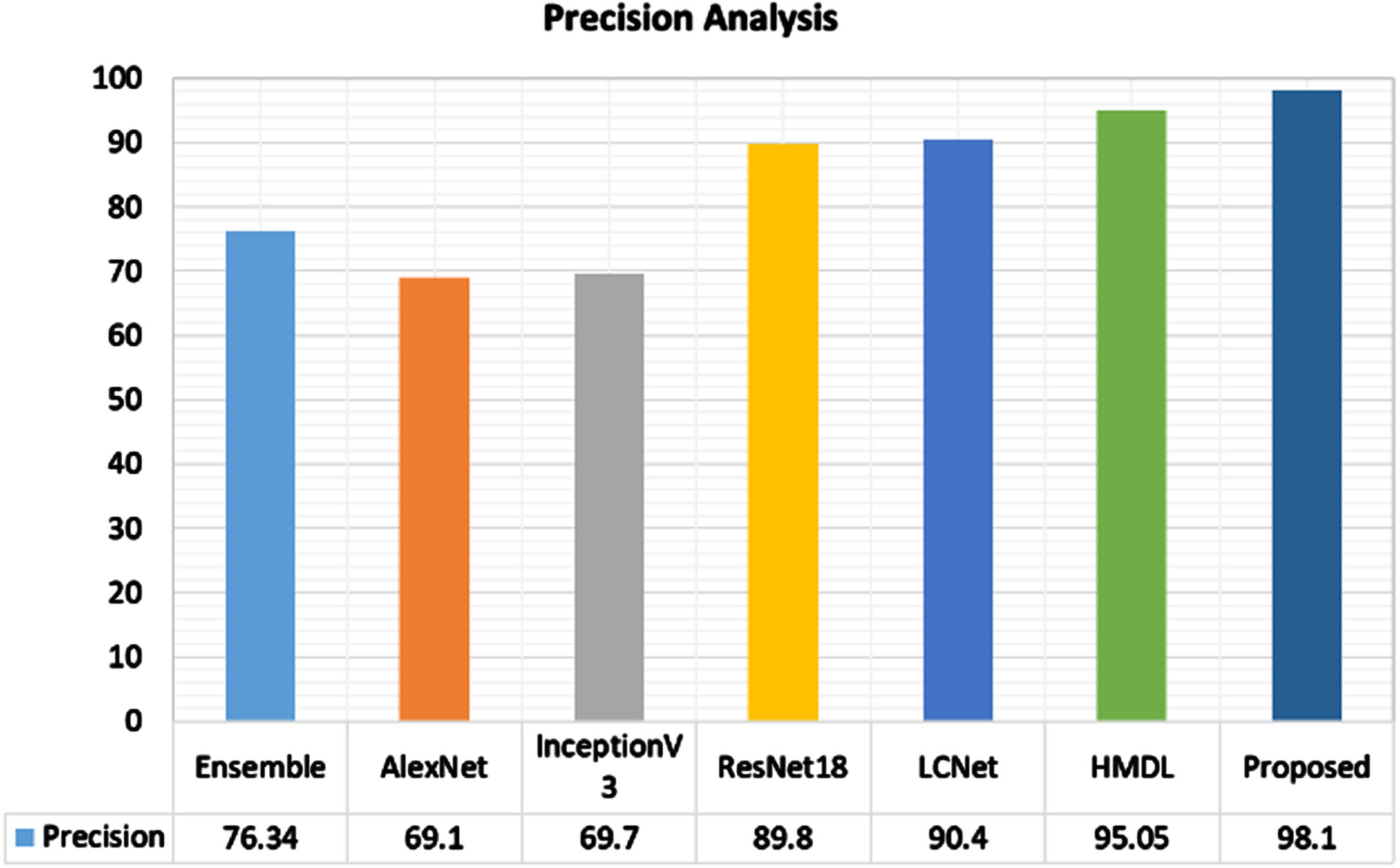
Comparative analysis of precision metric.
Figure 10 depicts the recall comparative analysis in which the recall of the proposed model is maximum (98.81%) compared to conventional models. The difference in recall levels of proposed and existing HMDL is about 4%, LCNet has a 9% difference in recall level, ResNet18 has an 11% difference, Inceptionv3 has a 51% difference in recall level, AlexNet has 30% difference, and the ensemble has 21% difference in recall levels which indicates the superior performance of the proposed model.
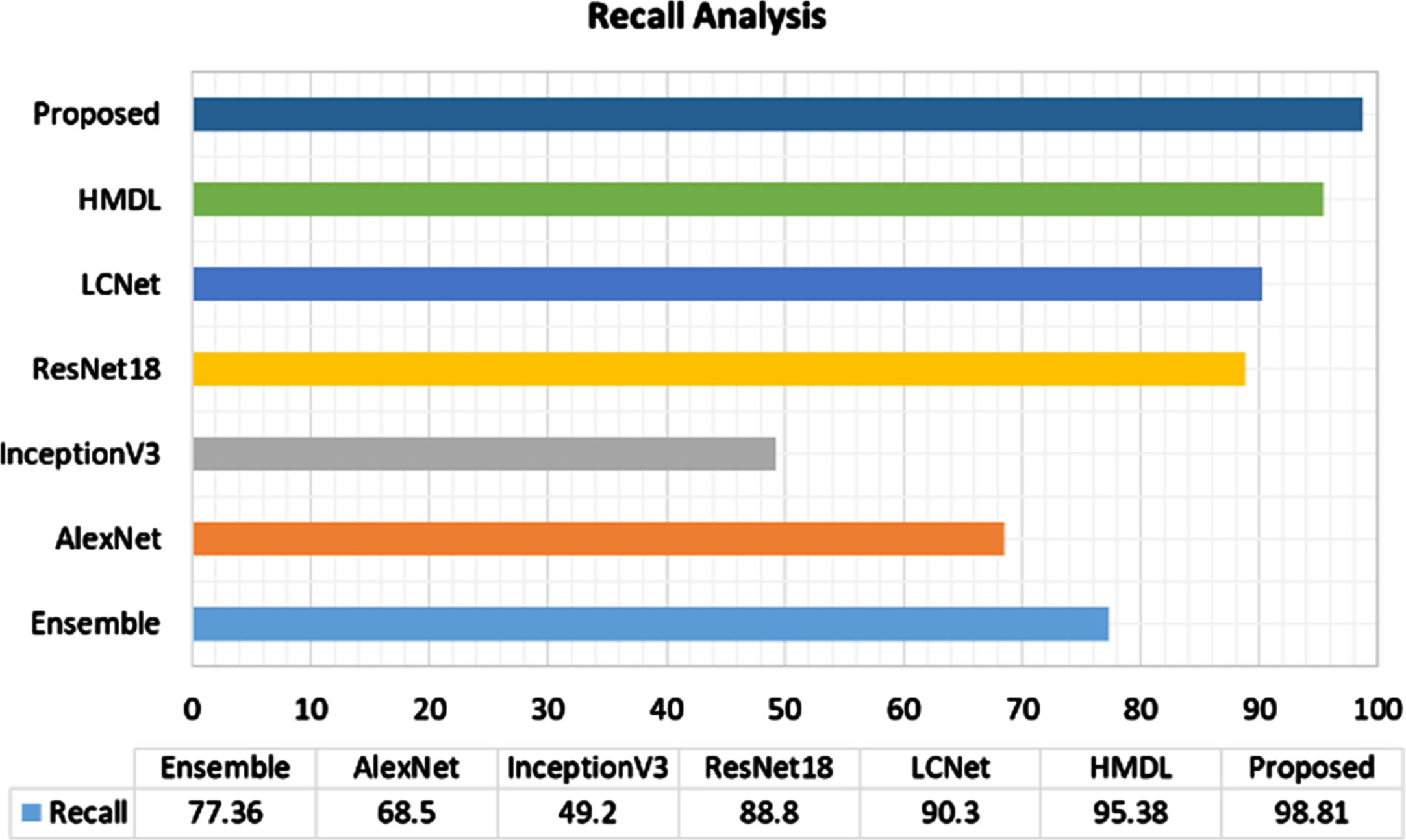
Comparative analysis of recall metric.
The F1-score comparative analysis of the proposed model is presented in Fig. 11. As the proposed model exhibited maximum precision and recall, the mean of precision-recall is indicated as the f1-score, which is comparatively higher than that of the existing methods. The maximum F1-score exhibited by the proposed model is 98.45%, whereas the existing HMDL F1-score is about 3% less than the proposed. LCNet F1-score is 8% less, ResNet18 score is 11% less, Inceptionv3 score is 41% less, AlexNet is 30% less, and ensemble score is 22% less than the proposed model.

Comparative analysis of F1-score metric.
Figure 12 depicts the accuracy comparative analysis of the proposed model in which the maximum accuracy of the proposed model, 97.11%, is clearly visible compared to other models. The difference in accuracy levels of proposed and existing HMDL is about 2%, LCNet and ResNet18 have a 7% difference in accuracy levels, Inceptionv3 has a 49% difference in accuracy level, AlexNet has a 22% difference in accuracy, and the ensemble has a 21% difference in accuracy levels compared to the proposed model.

Comparative analysis of F1-score metric.
The overall performance analysis of the proposed HARDCL network and existing deep learning models are numerically presented in Table 2. The maximum accuracy of the proposed is due to the better preprocessing, enhanced multi-scale feature learning and segmentation, and attention residual deep convolution learning process. The proposed model effectively categorizes benign and melanoma lesions with higher accuracy, which could be helpful for further diagnosis and medication.
Comparative analysis with existing methods
A Hybrid Attention Residual Deep Convolution Learning (HARDCL) Network for skin lesion classification is presented in this research work to categorize benign and melanoma lesions from dermoscopic images. The proposed model includes haze transform, fast local Laplacian filter, and HSV color transformation to preprocess the input lesion image. Then, using an encoder-decoder network, the multi-scale features are learned and segmented for the classification process. Finally, using the hybrid attention residual deep convolution learning network, the features are classified to detect benign and melanoma lesions. The hybrid attention residual mechanism used in the learning network performs spatial attention and channel-wise attention to process the critical information in the lesion. To improve the classification performances, metaheuristics jellyfish swarm optimization (JSO) is included in the proposed model which optimizes the network parameters. Due to this, improved classification accuracy was obtained in the proposed model experimentation. Benchmark ISIC 2020 skin lesion dataset is used for experimentation, and the results are compared with existing deep learning models. With an accuracy of 97.11%, the proposed model outperformed conventional methods in lesion classification. In terms of limitations, the complexity of the model may lead to computational inefficiencies, particularly when processing large datasets or deploying in real-time diagnostic settings. Additionally, the network’s reliance on high-quality, annotated data could limit its performance in scenarios with suboptimal image quality or incomplete lesion boundary information. Although the Jellyfish Swarm Optimization algorithm improves parameter selection, it may introduce additional overhead that could affect the scalability of the model. Furthermore, the model could face challenges when generalizing to datasets with significantly different characteristics from the ISIC 2020 dataset, potentially reducing its efficacy. In the future, this research work can be extended by adopting multiple optimized deep learning models to avoid minor misclassification errors.
Data availability
The data used to support the findings of this study are included within this article.
Conflicts of interest
The authors declare that they have no conflicts of interest.
Funding
For this research work, authors don’t receive any funding from funding agencies.