
Abstract
This paper presents a deterministic algorithm for approximating the solution of the Symmetric Traveling Salesman Problem (STSP) using a multi perfect matching and partitioning technique. Initially, we find the minimum cost collection of sub-tours that cover all cities, such that each sub-tour consists of at least four edges. The obtained solution is then partitioned into k branches, where k is the length of the smallest sub-tour in the resulting solution. The algorithm solves the sub-problems in parallel and selects the sub-problem with the minimum resulting cost to be partitioned further. The algorithm converges when a complete cycle without sub-tours is found. The performance of the proposed algorithm is evaluated and compared with the optimal values obtained by some well-known algorithms for solving STSP using 24 instances from the TSPLIB online library. The results of the experiments carried out in this study show that our approach yields optimum or near-optimum solutions in polynomial execution time.
Introduction
The Traveling Salesman Problem (TSP) is a combinatorial optimization problem of huge importance in operations research. It has many real-world applications in different fields such as transport routing, network design, spatial crowdsourcing, protein alignment, DNA sequencing, scheduling, logistics practice, micro-chips production, wireless and sensor network planning, shipping, and aviation [1]. There are a number of variants of this problem and it is immensely studied in computer science. It is also well-known that this problem is a hard problem belonging to the NP-complete class of problems for which no efficient algorithm, that runs in polynomial time, is known to exist [2–4].
Over years, many researchers have developed various algorithms to solve the TSP problem. These algorithms are categorized as either exact or approximate (heuristic) algorithms. Exact algorithms are designed to find the optimal solution to the TSP. However, they are computationally expensive. Examples of the exact algorithms that have been applied to the TSP problem include exhaustive search which generates and evaluates all possible tours, Branch and Bound (B&B) and its predecessor algorithm, the ranked assignment method [5, 6]. B&B explores all potential solutions using constraints. It divides the solution into tree nodes and branches (sub-problems), and then solves these sub-problems in sequence by calculating lower and upper bounds. In the worst case, it has complexity similar to exhaustive search.
An improvement of the B&B algorithm is the Branch and Cut (B&C) algorithm which uses the Cutting Planes method to cut down the scale of the B&B solution. According to Mitchell [7], this approach is able to solve and prove optimality of far larger instances than other methods. It currently holds the world’s record for solving the largest instance of a TSP problem covering a tour of 85,900 cities [8]. Solving such a large instance was achieved with a special tool targeted to solve the TSP called Concorde, using many super computers running in parallel to solve the problem which will otherwise take more than 136 CPU-years. However, the B&C algorithm still has an exponential worst-case running time.
Approximate algorithms use heuristics for global optimization and can be much more practical to solve problems with a large number of nodes. However, they do not guarantee an optimal solution. According to [9], these algorithms can be divided into tour-construction algorithms, tour-improvement algorithms, hybrid (composite) algorithms, and metaheuristic algorithms. Examples of these algorithms include Nearest Neighbor, Greedy Algorithm, Genetic Algorithm (GA), Ant Colony Algorithm (ACO), Particle Swarm Optimization (PSO), Tabu Search, and Simulated Annealing (SA) [10]. In [11], the authors applied ant colony optimization to successively search for shorter tours in the traveling salesman problem (TSP). In [12], Osaba et al. presented an improved discrete version of the bat algorithm, which is a population-based metaheuristic inspired by the echolocation characteristics of bats, to solve the traveling salesman problem. They also compared it with evolutionary simulated annealing, genetic algorithm, island-based distributed genetic algorithm, discrete firefly algorithm and imperialist competitive algorithm. A description of genetic algorithms for solving the traveling salesman problem is presented in [13]. A review of a number of attempts made to solve the TSP problem using genetic algorithms is presented in [14]. An improved cuckoo search for solving the TSP problem is described in [15]. Another approximate approach based on a hybrid discrete artificial bee colony is proposed in [16].
Simulated annealing (SA) uses the idea of statistical mechanics and the behavior of physical systems in heat bath where the solution state is initialized with an initial temperature and cools down to different states or temperatures until it reaches a frozen state [17]. SA starts by defining a neighborhood to an initial solution, and then randomly selects a solution from the neighborhood of the current solution. If the new solution is better than the current one, it updates the current state to be the new state. Otherwise, it updates the current state only with a certainprobability which decreases as the algorithm proceeds. This helps the algorithm escape local minima and allows for downhill moves (for a minimization problem). Many researchers used the SA algorithm to approximate the solution of the TSP such as Bayram and Şahin [18] who also proposed methods to improve the search capabilities and convergence to better results and faster execution times. In addition, Zhao et al. [19] also used SA with a hybrid local search to solve the TSP and compared the results with a number of meta-heuristic algorithms.
Based on a comparative study between SA and GA, Adewole et al. [20] observed that SA was faster while GA gave better results. According to Antosiewicz et al. [21], metaheuristic algorithms that proceed with a single solution at each stage – such as SA – usually produce much better results for the TSP than the population-based algorithms within limited time span based on simulation results of various TSP instances of different sizes. Metaheuristic algorithms are usually evaluated based on the fitness of the solution, uncertainty of the solution, and convergence speed. The effectiveness of those algorithms can vary from one problem to another. Deng et al. [22] suggested a strategy for population initialization to improve the performance of the genetic algorithm for solving the symmetric TSP. In [23], a hybrid approach is described for solving the TSP by integrating ACO with SA and the mutation operator. In [24], the authors compared attained solutions for TSP by the Golden Ball multi-population metaheuristic, which is based on soccer game, with evolutionary simulated annealing and tabu search.
The proposed multi-matching algorithm improves the Murty’s Ranked Assignment Method for minimum cost bipartite matching [6]. It is used to find the k-best assignments and is most widely used with either the Hungarian algorithm or JVC algorithm. Miller et al. [25] has studied the possible ways of optimizing Murty’s Ranked Assignment Method and JVC algorithm. He found that the worst-case execution time of Murty’s method is O (kN (N3 + kN) or O (kN4) if k ≤ N2, and applied several optimizations to reduce it to O (kN3). Multi-matching algorithm is inspired by Murty’s original work. However, rather than solving the partitioned nodes using a bipartite matching algorithm, we propose using a non-bipartite matching algorithm called Minimum Sum Algorithm or Blossom Algorithm. Blossom Algorithm is based on two main procedures, shrinking blossoms (odd degree nodes or odd alternating cycles) to look for an augmenting path, and expanding the blossom again to arrive to a final augmenting path in the original graph before shrinking. In [26], Kolmogorov proposed an enhancement to Blossom Algorithm to find the minimum cost perfect matching in general graphs which has a worst case complexity of O (n3m) but appears to be effective in practice.
In this paper, we review the existing algorithms that are used to solve the TSP in literature. Then, we propose a multi-matching algorithm to deterministically find an approximate solution to the Symmetric TSP problem. Finally, the algorithm results are compared with best known tours (solutions) for a number of TSP test instances.
The remainder of this paper is organized as follows. Section 2 formulates the problem under investigation. Section 3 describes the proposed methodology for solving the problem. Section 5 evaluates and compares the effectiveness of the proposed approach. Finally, Section 6 concludes the paper.
Problem formulation
Given a set of cities (locations), a starting (home) city, and the distance between each pair of cities, the goal of the TSP problem is to find the shortest possible tour (simple path) such that every city is visited exactly once and the salesman returns to the starting city. The input of TSP is a cost matrix which represents a complete undirected weighted graph of n cities with non-negative weight edges that connect each city with every other city in the graph. It is required to find a minimum cost tour or a minimum cost Hamiltonian cycle which is a tour that starts at one city and visits each of the other n - 1 cities exactly once before returning to the starting point and having the minimum total cost among all other possible valid tours. Thus, the optimal solution of the TSP problem is a permutation of the cities with minimum distance. There is a large number of feasible tours, which is given by (n - 1) ! for n cities.
The mathematical formulation of the TSP problem is as follows:
Decision variables:
Objective: Let c
ij
be the cost of traveling from city i to city j. The objective is to:
First constraint set: Every city must have exactly one edge leaving to another city; thus,
Second constraint set: Every city must be arrived at from exactly one city; thus,
Sub-tour elimination constraints: For every subset of cities, S, taken from the solution, such that 2 ≤ |S| < n/2 if n is even or 2 ≤ |S| < (n - 1)/2 if n is odd, the number of edges should be less than the total number of cities in that subset:
To minimize the number of constraints, later these sub-tour elimination constraints have been expressed using the following form:
The two most common classes of the TSP are the Symmetric TSP (STSP) and the Asymmetric TSP (ATSP). In the STSP, the cost to travel from i to j is the same as traveling from j to i, while in the ATSP they may differ. The ATSP can be transformed into STSP according to Kutkut [9].
In this paper, a multi-matching algorithm has been designed, implemented, and tested to solve instances of the Symmetric TSP with an Euclidian distance function that satisfies the triangular inequality. It is used to find a deterministic approximation of the TSP which provides very close to, or equal to optimum results in acceptable execution time. The proposed algorithm can be explained as sequence of stages as follows: Problem instance loading. Initiate upper cost matrix. Find solution with sub-tours by merging two different minimum cost non-bipartite perfect matching solutions (found by applying Minimum Sum Matching Algorithm or Blossom Algorithm twice). Create m different sub-problems and solutions pairs by fixing/excluding the shortest sub tour edges, where m is the shortest sub tour length, and solve these sub problems using the same method used in Step 3. Select the sub-problem with the lowest cost tour, and apply same branching method used in Step 4. Iterate until the result consists of one complete tour (no sub tours). Convert the non-directed tour to a directed one, calculate the cost, and return the result.
The proposed algorithm takes an input file and finds the Euclidian distance between its cities, and builds the matrix such that the rows represent cities (0 . . i) and columns represent cities (0 . . j) and the values inside the matrix represent the Euclidian distance between city i and j. The main diagonal of the matrix will be replaced with infinity or a very large number to ensure no city can travel to itself.
The first iteration will use the minimum sum perfect matching algorithm with a slight variation. The minimum sum perfect matching algorithm finds a perfect matching in graph (G) such that the sum of selected edges weights is minimized. The advantage of using this algorithm is that it takes an undirected graph as an input. Since the Multi-Matching algorithm target is to solve the Symmetric TSP, the direction of the edge only matters when we want to construct a tour and it is not necessary while finding a minimum cost matching. This algorithm finds the minimum sum perfect matching using a labeling and shrinking procedure. The input graph, however, has to be of even number of nodes. Thus, in order to input an odd number of nodes file, the last node in the file will be duplicated, since the added city will not change the solution of the problem or the optimum cost. This procedure takes the input as an undirected graph, therefore, a procedure has been used to convert the full cost matrix to an upper cost matrix by excluding all values where i = j or i > j for any two cities i and j. Furthermore, zero valued row and column are added to the matrix as shown in Figure 1.
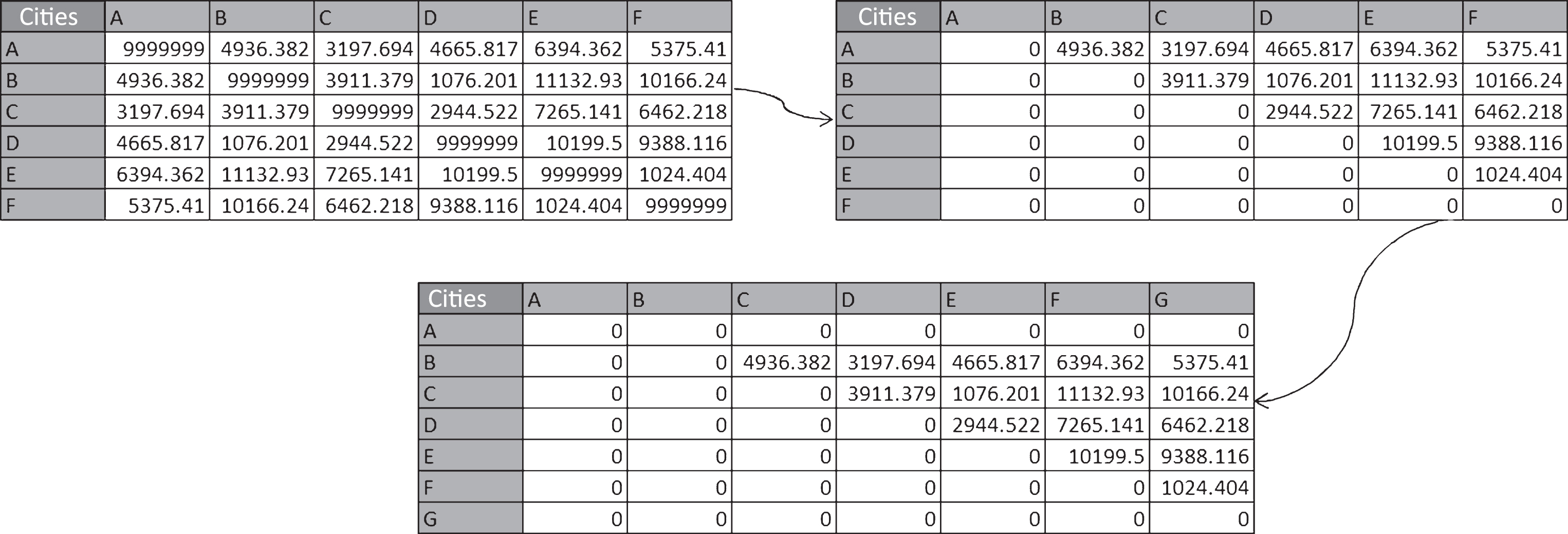
Cost matrix transformation from directed to undirected graph.
The results from this algorithm is a matching where if edge (A-B) is selected then edge (B-A) is also selected by default. Thus, given that n as the total number of cities, the total number of edges returned by this algorithm is n/2 since every edge will be matched to itself on the opposite direction. Our aim is to find an edge cover with no tours of degree two (tours between two nodes only). To solve this issue, we mask the output of the first call to the Minimum Sum Algorithm – by setting the corresponding edges values to infinity – and call the algorithm again. The second call will produce another set of edges, which is different from the first set. The result will give us a complete set of edges where the length of the sub-tour is four or more. Figure 2 shows an example of the output of the modified algorithm for a problem instance of 38 nodes.
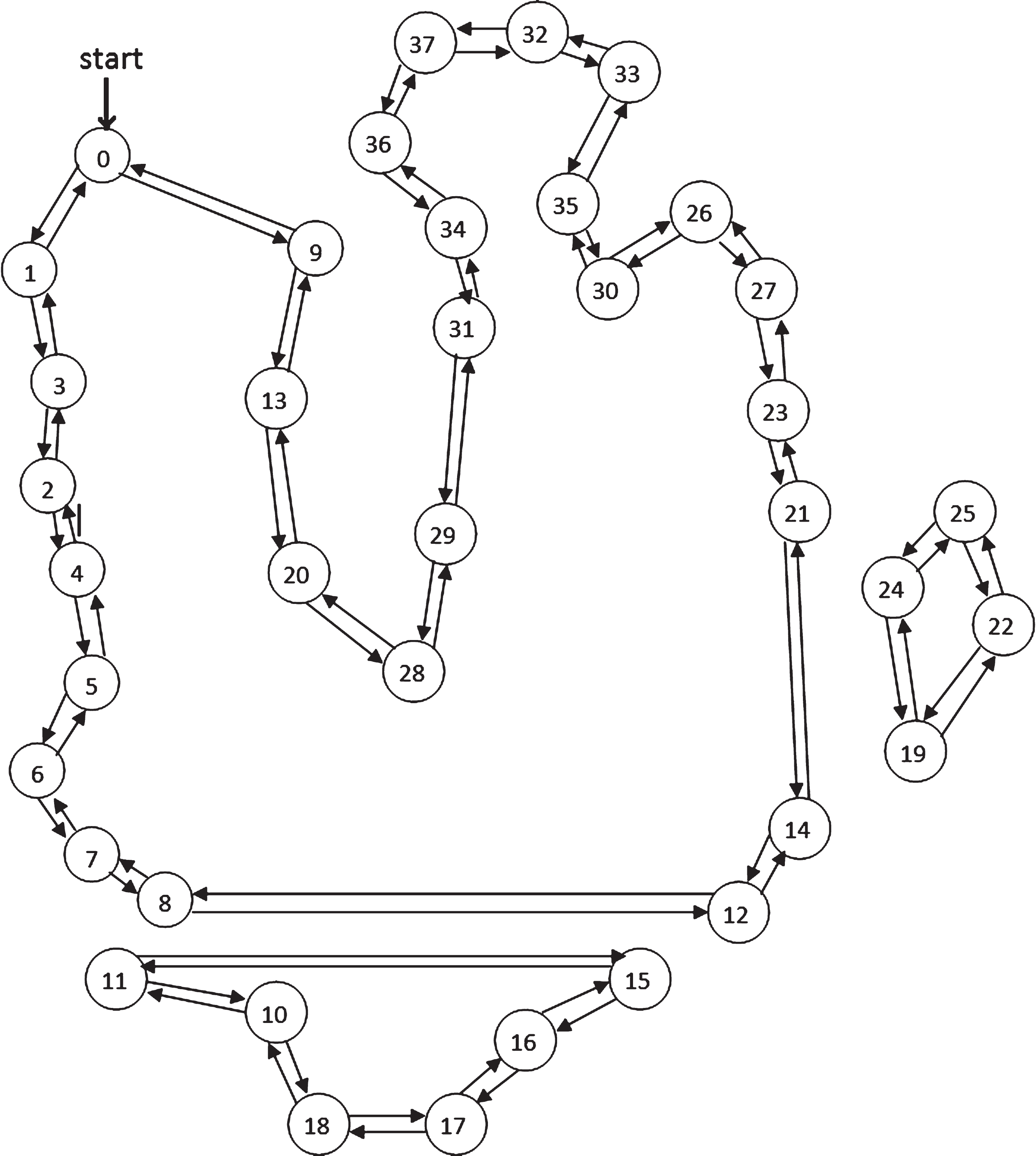
A 38-city output from the modified Min-Sum matching algorithm.
From this output, it is easy to convert the solution to a directed tour by starting from city 0 and traveling to next connected city such that the edge we select will not take us back to the city we arrived from. We need to connect these sub-tours together and arrive at a complete tour.
The partitioning stage will be executed in parallel since each sub-problem is independent from the other sub-problems from the node to be partitioned. This stage starts by identifying the shortest sub-tour. The reason for choosing the shortest sub-tour is to force this sub-tour to merge with the bigger sub-tour, taking us a step closer to the complete tour. We partition the input problem into m different sub-problems such that the length of the shortest sub-tour is equal to m. For each sub-problem, we exclude one of the edges from the sub-tour and force all others. The nodes on the two sides of the excluded edge will then have to search for a new node to link to, so we have to prevent them from linking to nodes that are fixed already, so they will have to link with other sub-tours in the problem. This will force the sub-tours of the input problem to grow in size, reducing the total number of sub-tours to be partitioned in the next iterations. It is not guaranteed, however, that the result of the sub-problem will have less number of sub-tours in all the branches. Some branches might lead to growing the current sub-tour by one additional node for example, while shrinking one of the other sub-tours. However, next iterations will eventually force two or more sub-tours to merge together, so complete tour is guaranteed to be found. Figure 3 illustrates the method of partitioning the shortest sub-tour for our example of 38 cities.
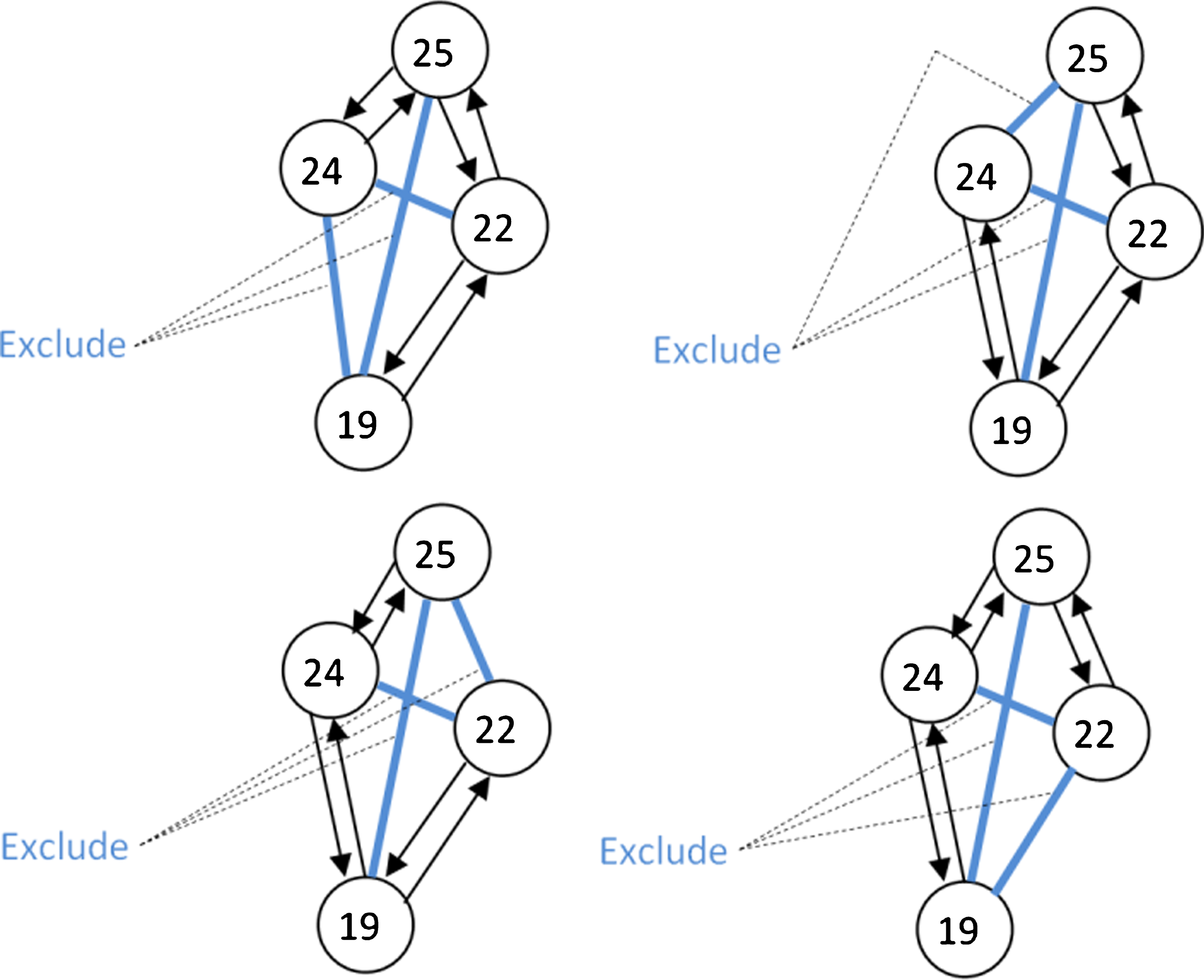
Shortest sub-tour partitioning.
Before sending the branch to be solved again by our Minimum Sum Matching algorithm, we have to verify that: No two fixed edges intersect. By examining many optimal solutions, it was noticed that edges of the optimal tour do not intersect with each other. Fixed edges do not form a cycle. Prevent fixed edges from traveling to each other by excluding any other edges that connect them except the edge that is fixed. The main reason behind this is to force the small sub-tour to merge with the larger sub-tour in an aim to complete the tour on the original graph. This will ensure that the method will eventually reach to a solution.
To find if two edges in the fixed list intersect, we use the following procedure. Given two line segments (p1, q1) and (p2, q2) . If the orientation of (p1, q1, p2) is not the same as the orientation of (p1, q1, q2), and the orientation of (p2, q2, p1) is not the same as the orientation of (p2, q2, q1), then the two line segments intersect. The orientation of the ordered triple of planar points (p, q, r) can be clockwise, counter-clockwise or colinear. It can be determined based on the value of:
Out of the solved sub-problems, the one with the lowest cost will be selected to be explored or partitioned next. The algorithm iterates until a complete tour is found as illustrated in Figure 4.

Optimal tour of the 38-city problem.
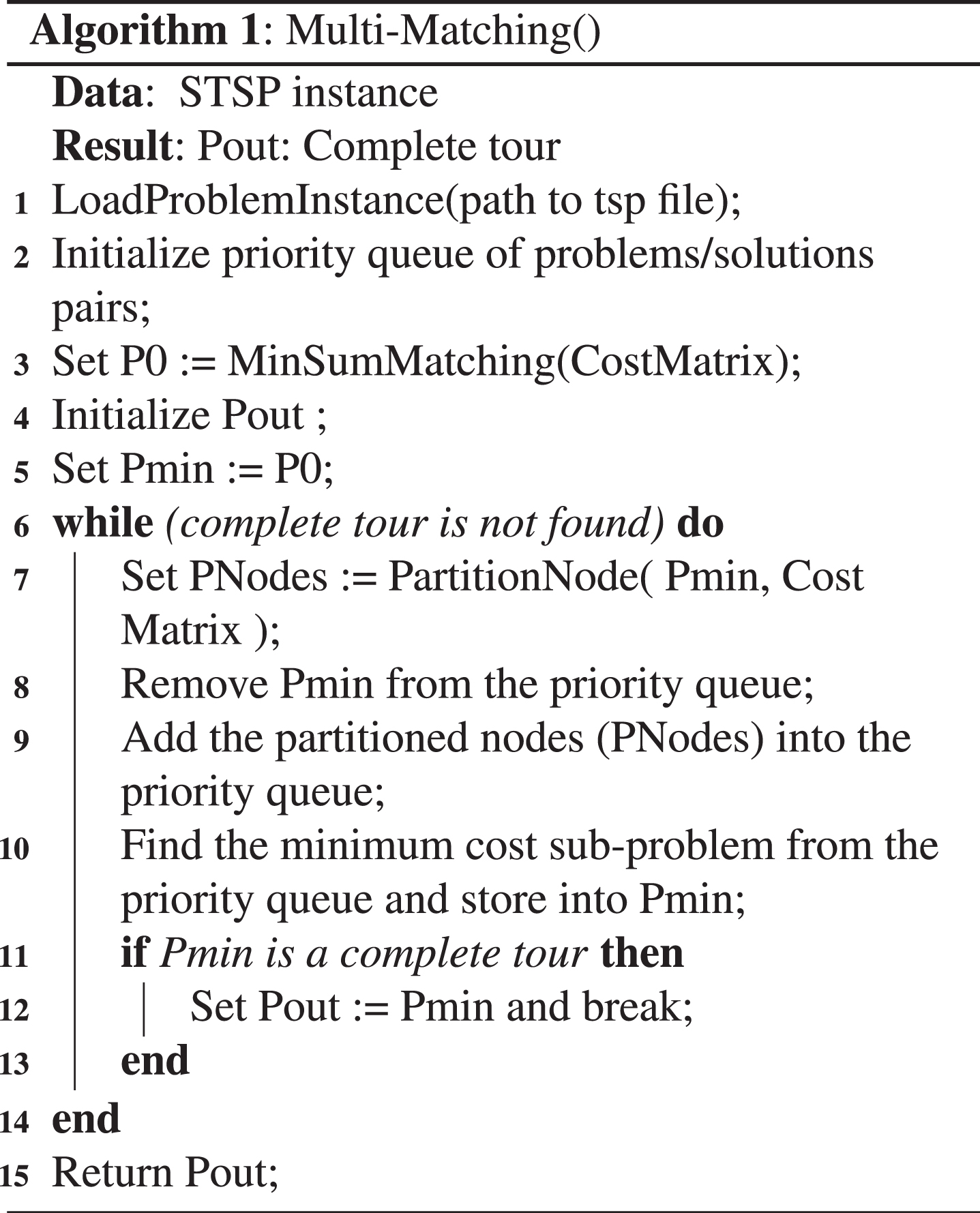
The pseudocode of the proposed STSP solution using multi-matching algorithm is shown in Algorithm 3. This algorithm uses the LoadProblemInstance() function, which is shown in Algorithm 3, to read the city coordinates from the input file and initialize the cost matrix. It also uses the MinSumMatching() function, which is shown in Algorithm 3, to compute the minimum cost collection of sub-tours. The MinSumMatching() function uses the BlossomAlgorithm() function, which is a direct call to the blossom procedure for finding minimum cost perfect matching with no modification, so we skipped its implementation details which can be found in [26] and a sample Java code is provided by Lau [27]. There is also the PartitionNode() function, which is shown in Algorithm 3, to find the m sub-problems/solutions pairs.
MinSumMatching(CostMatrix)
PartitionNode(P, CostMatrix)

To evaluate the effectiveness of the proposed solution, we conducted several experiments. The simulation has been carried out on Windows 8.1 64-bit machine having Intel(R) Core(TM) i7-4700HQ CPU @ 2.40GHz quad-core processor with 8 threads/core and 12GB RAM. The tested instances and their best known or optimal results are collected from the publicly available online TSP library (TSPLIB), which was published on the websites of Heidelberg University and University of Waterloo. It was created and managed by Reinelt [28] and Cook [29], respectively. A description of this library is provided in [30]. It also provides the known lower and upper bounds for each problem instance.
The resulting tour length from the proposed multi-matching algorithm might be one city more than the number of cities in the original instance file. The extra city is just a duplicate city in the instance since our matching algorithm can only accept an even number of nodes as input as discussed earlier and can be excluded from the final output. Table 1 shows the simulation results of running the Multi-Matching Algorithm on 24 different TSP instances ranging from 29 cities to 200 cities and comparing the resulting tour length against optimal tours. Table 2 shows a side-by-side comparison against SA applied on the same TSP instances. The reason for choosing SA for our comparison is due to the fact that it is considered one of the best meta-heuristic algorithms for the TSP according to Antosiewicz et al. [21] and Arora and Giras [10].
Multi-Matching()
Multi-Matching()
LoadProblemInstance(filename)
The SA implementation is configured with 500,000 fixed iterations count, cooling rate of 0.95 and a starting temperature of 10,000. Table 1 shows that the proposed algorithm is capable of producing results that are very close to the optimal, however, the execution time was variable depending on the cities coordinates, how close the initial solution is to the result, and the effectiveness of smaller sub-tours elimination through our partitioning or branching stage. The execution time jumped considerably at 100, 150, and 200 instances, while all instances in between had a much lower execution time. This is also verified by the total number of iterations the program had to go through before reaching to the result varying significantly as well between problems of very close sizes.
Simulation Results on various problem instances with different number of cities in terms of resulting tour length compared to the best-known solution, running time and number of solved subproblems
We could not predict the worst case execution time since it highly depends on how the points are scattered in the Euclidean two-dimensional (2D) space. We might have a case where the initial matching does not form a large enough sub-tour to be the base of the next iterations and instead consisted of many small sub-tours, and this might be possible depending on the coordinates and distances between the cities which might prove more difficult to solve in the same average execution time we achieved. However, all the instances solved in Table 1 converged to a solution in polynomial execution time. Using multi-threading for parallel solving of sub-problems gave us the opportunity to reduce the total execution time. Moreover, the total number of sub problems or iterations the algorithm had to solve also proves that the algorithm’s time complexity is polynomial in average for the selected problem instances.
Table 2 shows that the solution quality comparison against SA proved that for most of the cases where instance size is medium, proposed algorithm produced better results than SA and much closer results to the optimal tours. However, SA is observed to be faster even when left to run for 500,000 iterations on big instances. Since the results of SA depend on the number of iterations, cooling rate, and starting temperature as input variables, changing these values might lead to different results.
Comparison of the proposed algorithm against Simulated Annealing (SA)
In addition, the proposed Multi-Matching Algorithm is deterministic so running the algorithm multiple times will always lead to the same results for the same problem instance. While on the other hand, most of the other meta-heuristic algorithms – such as SA or GA – are probabilistic and their solution values might change for every single run.
We presented a new approach to deterministically find approximate solutions for STSP that are very close to the optimum in a reasonably good execution time. The experimental results show that the proposed algorithm could always converge to a solution even for difficult and large problems which makes it a promising approach for future development in the combinatorial optimization field. On the other hand, the proposed algorithm is only tested on Symmetric instances of the TSP with Euclidean distances that satisfy the triangular inequality. Due to the symmetry feature, we could replace the directed edges with undirected edges to be able to run the minimum sum perfect matching algorithm for general graphs. The main advantage for using Multi-Matching algorithm for approximating the TSP solution is that it uses a deterministic, structured approach towards finding the solution rather than using randomness to refine the result which gives it an advantage over many other meta-heuristic algorithms. It can be applied in areas where consistent and close to optimal solutions are required when other exact algorithms are very inefficient. Future work can improve the multi-matching algorithm by proposing other techniques to find a non-directed minimum cost collection of sub tours where sub tour length is equal to or larger than 4, or find factors other than the cost in the selection of the next best sub-problem to partition. Moreover, the proposed algorithm’s partitioning or branching stage can be considerably improved both theoretically and in implementation. Different techniques in selection of sub-tours to partition as well as fixing or excluding edges from the selected sub-tour might lead to faster and better results. Further analysis on time complexity and generalization of the algorithm is also to be considered for future work.
Footnotes
Acknowledgements
The authors would like to express their appreciation to Ahlia University (Bahrain) and King Fahd University of Petroleum and Minerals (Saudi Arabia) for the support during this work.