
Abstract
It is generally known that counting statistics is not correctly described by a Gaussian approximation. Nevertheless, in neutron scattering, it is common practice to apply this approximation to the counting statistics; also at low counting numbers. We show that the application of this approximation leads to skewed results not only for low-count features, such as background level estimation, but also for its estimation at double-digit count numbers. In effect, this approximation is shown to be imprecise on all levels of count. Instead, a Multinomial approach is introduced as well as a more standard Poisson method, which we compare with the Gaussian case. These two methods originate from a proper analysis of a multi-detector setup and a standard triple axis instrument.
We devise a simple mathematical procedure to produce unbiased fits using the Multinomial distribution and demonstrate this method on synthetic and actual inelastic scattering data. We find that the Multinomial method provide almost unbiased results, and in some cases outperforms the Poisson statistics. Although significantly biased, the Gaussian approach is in general more robust in cases where the fitted model is not a true representation of reality. For this reason, a proper data analysis toolbox for low-count neutron scattering should therefore contain more than one model for counting statistics.
Introduction
The nature of the physical sciences is to apply a hypothesis to a system, such that it is possible to either confirm its accuracy, or falsify it, based on observation [2]. Usually, this observation consists of physically measured data which necessitates a statistical analysis, the type of which depends on the observation in question. In this article, we investigate analysis methods for low-statistics counting measurements, in particular inelastic neutron scattering data. Here, the current common practice is, due to convenience, to utilize the Gaussian limit of the Poisson statistics. This limit allows for the evaluation of fits by using the least squares method for which many algorithms are readily available, and to enable easier data transformation and normalisation. The approximative nature of the Gaussian treatment is well known and some software libraries are equipped to perform both the least squares method as well as the statistically correct Poisson treatment, e.g. MANTID [1].
Numerous previous studies of counting statistics and their influence on Poisson parameter estimation have been published both in the statistical case, see e.g. Ref. [12], or in the case of both single crystal and powder diffraction [5]. In the latter case, both the low and high count limits are of concern, with the high limit being more common in the elastic case. The low limit results in wrong estimation of the counting uncertainty when using the fitting method of Gaussian least squares. However, in the high count regime, the counting uncertainty no longer provides the main source of error and thus, counting “too” long results in an underestimation of the uncertainties. This, in turn, obscures and possibly falsifies the parameter uncertainty in the presence of systematic errors originating from the experimental setup, an oversimplification in the model utilized, or other sources [5]. We will here only be concerned with the question of statistical uncertainty, which will interchangingly be denoted as uncertainty and error.
In this article, we deal with the low-count limit of the Gaussian approximation, which we denote the Poisson regime. This is usually taken to be the regime with
Model fitting by Gaussian and Poisson statistics
Parameter estimation of a suggested model given a data set can be seen as a problem particularly well suited for the Bayesian approach. Using this method, it is possible to update the estimates of model parameters, given particular observations. That is, given the initial, or a priory, information I for a model and set of parameters M, one updates their probabilities given the measured data D, according to Bayes Theorem [2]
The Poisson and Gaussian distributions
Because of the discrete and uncorrelated nature of counting statistics, it is known that it follows the Poisson distribution [2] with the probability of observing n counts for a process that has an expected mean count of λ,
Statistics on scattering
For simplicity, let us limit our discussion to reactor-based instruments with a monochromatic incoming beam. In most triple axis instruments, the process of measuring the scattering intensities, or more correctly the scattering cross section, for different processes in a material is either performed through a series of scans or with a multi-detector setup. Multi-detectors are also used for SANS, imaging, and powder diffraction. Here each detector (or detector pixel) corresponds to a specific momentum transfer Q (and possibly energy transfer E). Despite the apparent differences the resulting statistics is the same. This can be seen by first considering the case of a point by point measurement. At each setting, one of two things can happen; either the neutron ends in the detector or it does not. This gives two pixels. At the next instrument setting, the same outcomes are possible. If the neutrons hit the detector, they are collected in pixel number 2, while neutrons missing are added to the missing neutrons from the previous setting. This goes on throughout the scan. Alternatively, if multiple detectors are used simultaneously, one splits all neutrons into the neutrons hitting individual detectors plus one for the neutrons that do not hit any detector.
Although these two methods might appear to be completely equivalent, they are in fact not. Even though the end spectra seem equivalent there is one key difference. When all data points are measured at the same time, it is known that any neutron entering the instrument had the same probability distribution of being detected, and the total number of neutrons was fixed. When a single point at a time is being measured for a certain amount of time, or equivalently number of neutrons released from the source, it is not known that each detector setting had the exact same number of incoming neutrons, only that the total spectrum had a certain number. This is, albeit small, a difference between the two measurement styles. When the multi-detector instrument is used in a scanning setup the knowledge of the same total incoming neutron count is lost and one is to revert back to the same analysis as for the scanning setup. An example where these two setups are in use is a time-of-flight spectrometer measuring a powder sample and a single crystal. In the prior case nothing is moved or scanned over during a spectrum acquisition while this is not the case for a single crystal. Here, usually the sample is rotated.
Looking at the case of many pixels being measured simultaneously, these are denoted
Multinomial distribution. In order to optimize these parameters, one needs to maximize the likelihood, which is given by a Multinomial distribution
The above log-likelihood is found when considering a collection of measurement data with a fixed total number of neutrons, i.e. N.
Poisson distribution. Taking one step back from the above derivation, what is usually performed is an analysis dealing with a data set where the total number of counts is not fixed, i.e. corresponding to the standard triple axis setup. This corresponds to removing the
Gaussian distribution
It is instructive to compare by repeating the similar calculation for data governed by Gaussian statistics, which can be found in an expansion of the Poisson result (15) around a large value of
Fitting experimental data
Fitting a model using the above found likelihoods then consists of optimizing
The Multinomial log-likelihood can be split into two parts; one concerning the zeroth pixel, the other the rest. The parameters only changes the latter part, which can be found to be proportional to
For the Poisson distributed data, the negative log-likelihood contains the term
Lastly, for the Gaussian distribution the log-likelihood is simply proportional to
In the Gaussian log-likelihood, it would also be possible to use the model value for the uncertainty, i.e.
Difficulties arise from using this equation in the extreme low-count limit. In particular, when a counting number of 0 is measured, we have
For these reasons, practical applications of modeling of scattering data use different tactics to accommodate zero count values. The most often used way to circumvent the zero-count problem is by increasing the uncertainty of the zero-measurement to unity [1,3]. This, however, allows for the unphysical situation where
Three different tactics for dealing with zero count values in Gaussian statistics. The third method simply removes zero count points
Three different tactics for dealing with zero count values in Gaussian statistics. The third method simply removes zero count points
In the similar case, when a count of unity is found, the corresponding uncertainty is then
In the rest of this paper, we will quantify how these introduced imprecisions affect the data analysis in a few simple examples, where we also compare with the more accurate Poisson and multinomial treatments.
We here set out to investigate the difference between minimizing the three different log-likelihoods, when used on simple, synthetic counting data. We first show a study of a data set of no features, i.e. a flat background. Later, we discuss the case of one simple Gaussian peak on a flat background.
For the flat background, 1000 individual spectra are generated using the
Constant background
We here consider the simplest model
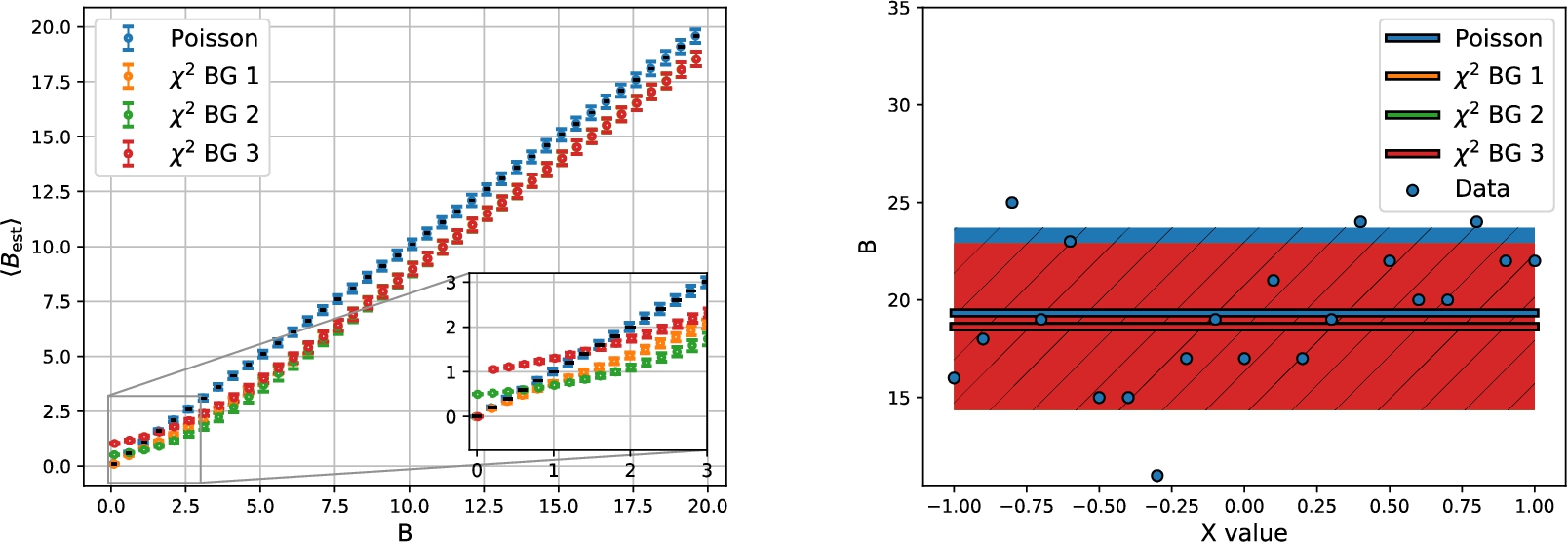
Figure 1 shows the mean estimation parameter and the standard deviation on it, the size of which is described in Section 4. While the Poisson fit shows a striking agreement with the underlying model, we observe a clear underestimation of the background parameter in all the Gaussian least square method fits. This is visible for all medium and large values of the background parameter,
Turning to the case of low background rates,
In the medium range
None of the Gaussian methods, however, compare anywhere near the Poisson method in fitting precision for this simplest of models.
An example very relevant to scattering is that of a peak with the shape of a Gaussian on a constant background. This model is given by
In contrast to the above data, it here makes sense to also do parameter optimization using the Multinomial log-likelihood, where
For this model the different values of the background, B, was used with fixed center,
In the data, we observe the same tendency of the three Gaussian least square fits overestimating the
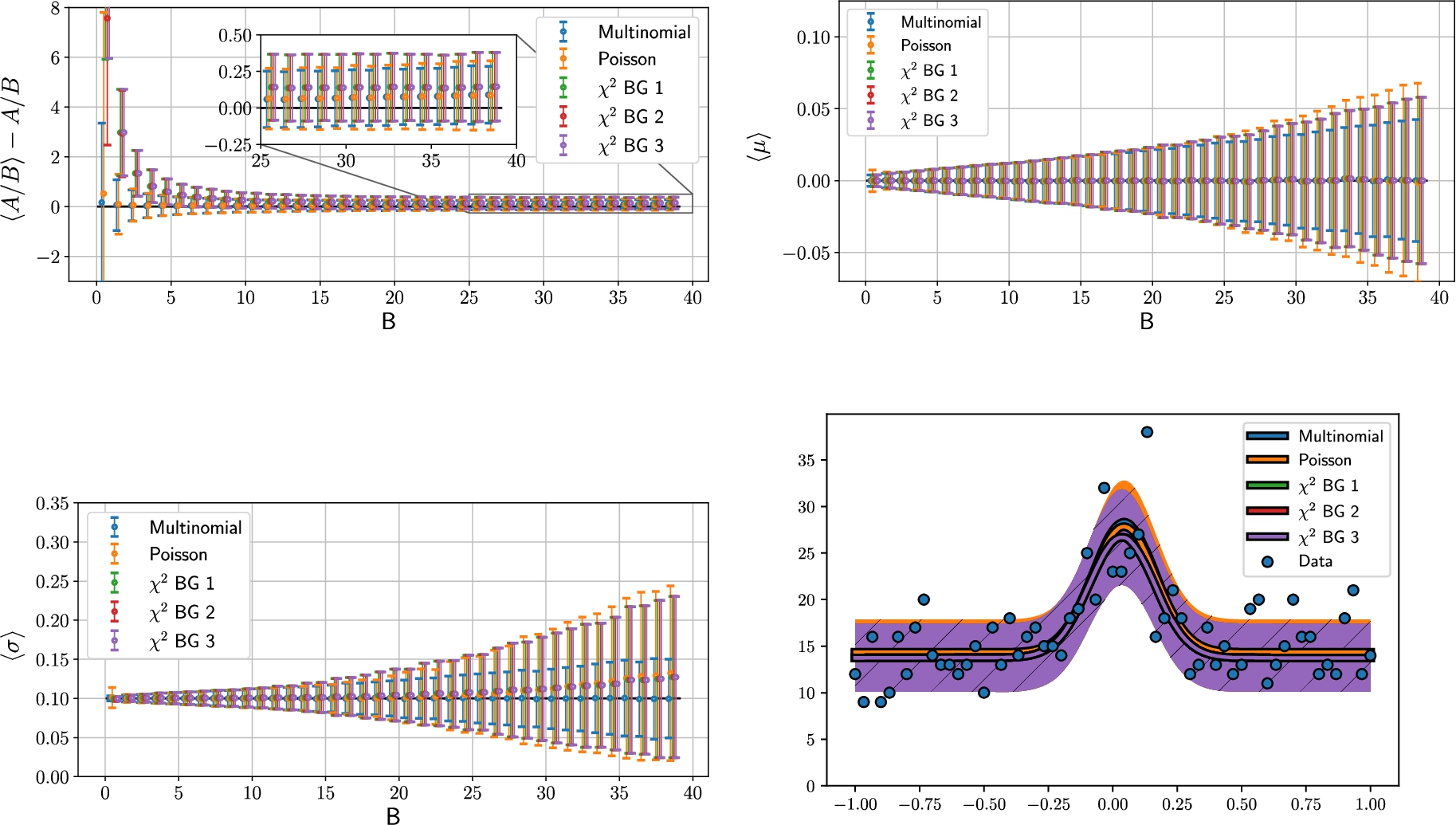
Distance away from the truth for estimated values of A/B, μ, σ, and a sample data set with a background level
When it comes to the center position of the peak, μ, all methods agree across all levels of background, accurately finding the true mean value,
There is no doubt that the Multinomial method out-performs the other 4 methods when the peak width is to be determined. When the background to amplitude reaches a ratio of 1, all but the Multinomial method, on average, overestimate the peak width. The Multinomial method not only finds the correct width but also with significantly smaller standard deviation.
In most neutron experiments, the acquired raw count is somehow normalized. Often this is done with respect to monitor count, resolution volume and detector sensitivity, just to mention a few. The standard progression is to normalize the intensity measured and then find the estimated uncertainty on the data points, that is
However, the cleanest way to perform this transformation is to transform the model instead of the data, for example that the expected count rate is proportional to the count time:
When visualizing data, it is common practice to display an errorbar on the individual data points, representing the statistical uncertainty. However, following the discussion on the Gaussian and Poisson statistics above, this is formally a wrong presentation of counting data. In principle, there is no uncertainty on the actual measurement in a given point. Rather, the uncertainty lies on the estimation on the underlying true scattering intensity
Finding the confidence intervals for the Multinomial and Poisson methods requires a little work. By the notion of uncertainty on the model it is meant that it is independent of the uncertainty on the fitted parameters and represents the statistical uncertainty in drawing counts from its distribution. This is an alternative to providing an error estimate on the data points with the best fitting model plotted on top. In the case of the least squares fit, the region of model uncertainty is the count values corresponding to
Thus, one can define the confidence interval limits a and b equivalently as for the Gaussian with
For the Multinomial distribution, one can use the confidence interval methods for binomial distribution. At each point along the fitted curve the success probability is simply the estimated value, while all other outcomes are regarded as fails. As was the case for the Poisson, many different procedures for calculating confidence intervals exist [13]. Weighing calculational complexity and correctness, it has been chosen to use the Wilson score interval with continuity correction. Specifically, the confidence interval is found from
Error estimate on parameters
An experimentally determined parameter has little scientific value without a corresponding uncertainty value. That is to say that when tabulating fitting parameters or other extracted variables, one needs to quantify the degree to which this value represents the true underlying numerical value. In general, two different ways of estimating the error exists; (1) change only the parameter in question until the log-likelihood value changes a certain amount or (2) change the parameter in question and optimize the others until the log-likelihood has changed by the given amount.
For the case of a normally distributed variable being fitted by a single parameter, the uncertainty on the parameter is given by a change in the chi-square value of unity, or, when the log-likelihood method is used, by a change of this value by 0.5. This, in turn, corresponds to a confidence interval of 68.27%, usually denoted the
Further, curves for constant log likelihood can also be plotted, and an example for the Multinomial, Poisson and
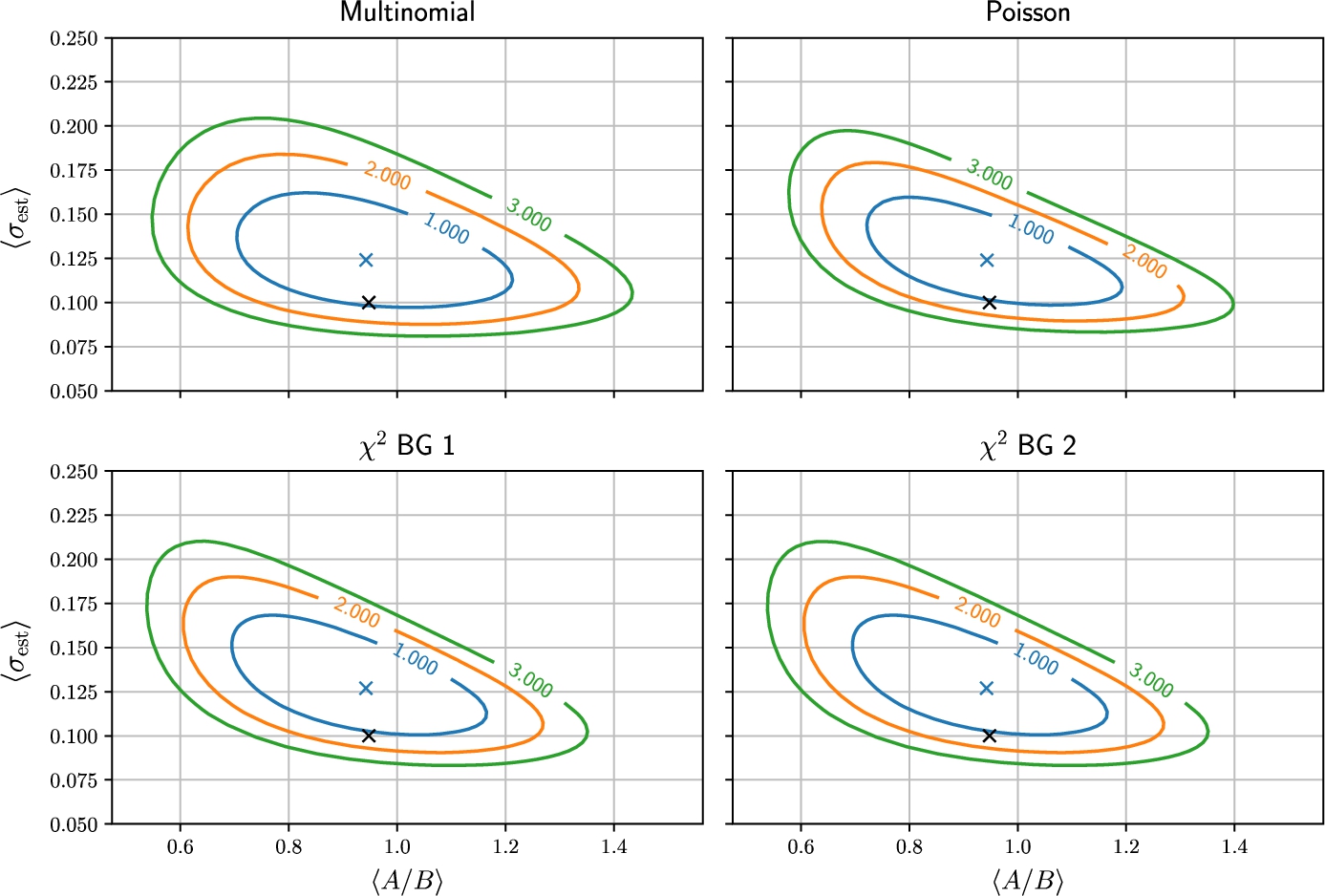
Estimated
Looking at the distribution of parameter estimations for the three different statistics types it is seen that on average the Multinomial distribution is both most accurate and precise with the Poisson statistics following its precision. Comparing the extend of the 1, 2, and 3 σ intervals for the Multinomial distribution with the error estimate in Fig. 3 it can be argued that its error estimate is too large. A true correspondence between change in log-likelihood and error estimate might not have been achieved resulting in an overestimation of uncertainty in single parameters.
Diving into spectra for the peak-to-background level of 0.926, depicted in Fig. 4, the spread of parameter differs between the methods. Except for a few outliers both the Multinomial and Poisson methods have centre close to the correct value, while the Gaussian methods both diverges somewhat. Plotted together with the distribution of fits are co-variance ellipses signifying 1, 2, and 3 σ. Again the Multinomial and Poisson methods are superiour, but a clear advantage can be seen for the Multinomial method as its co-variance ellipses are close togehter.
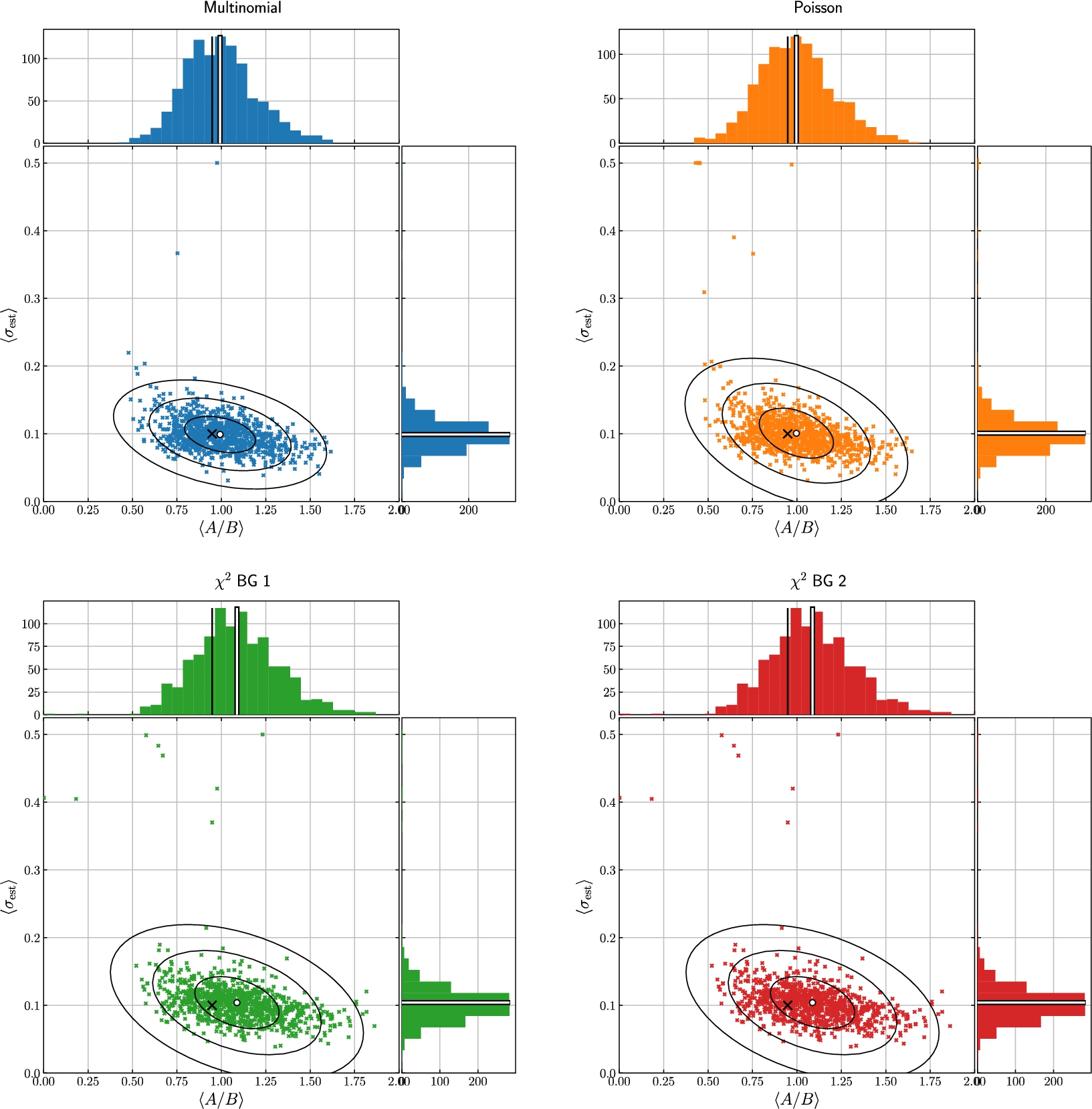
Scatter plot of parameters determined from a series of synthetic data sets, using the Multinomial, Poisson and
Our exploration of synthetic data from simple models gave rather clear results in favour of the both the Multinomial and Poisson fitting methods. However, the litmus test would be the influence of the methods on real-world scattering data.
To investigate this, we use an inelastic neutron scattering data set from a measurement of spin waves in MnF2. We chose this system as a demonstration case, because MnF2 has simple inelastic features consisting of only one spin wave branch, as well as the fact that a large single crystal of great quality was available. Important in this context is that since MnF2 orders in an antiferromagnetic structure, different parts of the spin wave spectrum have different intensities. In particular, the magnon intensity around the magnetic Bragg peaks with Miller indices
All data presented were taken during the early commissioning of the new cold-neutron multiplexing spectrometer CAMEA (PSI) in November-December 2018 [4,9]. We used a 6.2 g single crystal sample, held at a temperature of 2 K. The measurements were taken as pure sample rotation scans, using two settings of the analyzer-detector tank and four values of the incoming energy,
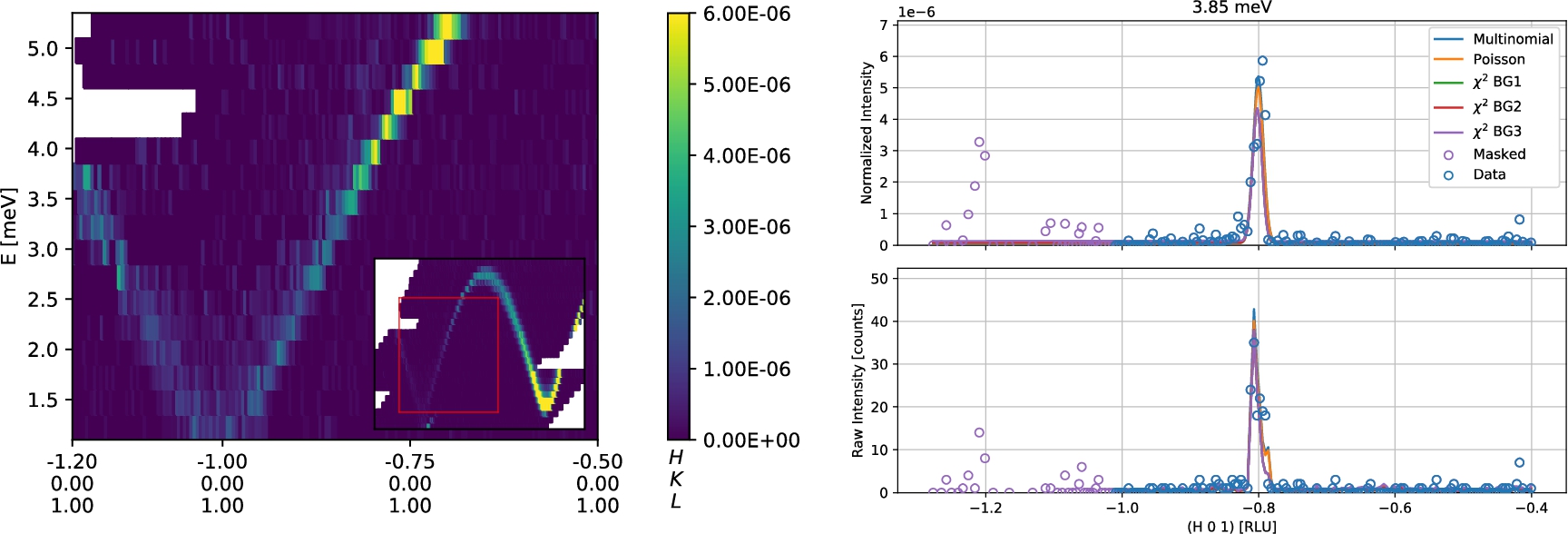
The main data is shown as a color plot in Fig. 5 (left). A full view of all of the cuts is found in Appendix B. We observe a smooth and sharp spin wave dispersion with maximum intensity at the single ion anisotropy gap at 1.0 meV at
Comparing the raw counts with the normalized intensity (Fig. 5 (right)) illustrates that one cannot use the (unnormalized) raw counts directly to fit the data. Instead a model is imposed on the data consisting of three parts: First the peak model,
In total the model reads
This combined model has been fitted to the raw neutron counts using the fitting methods discussed above using
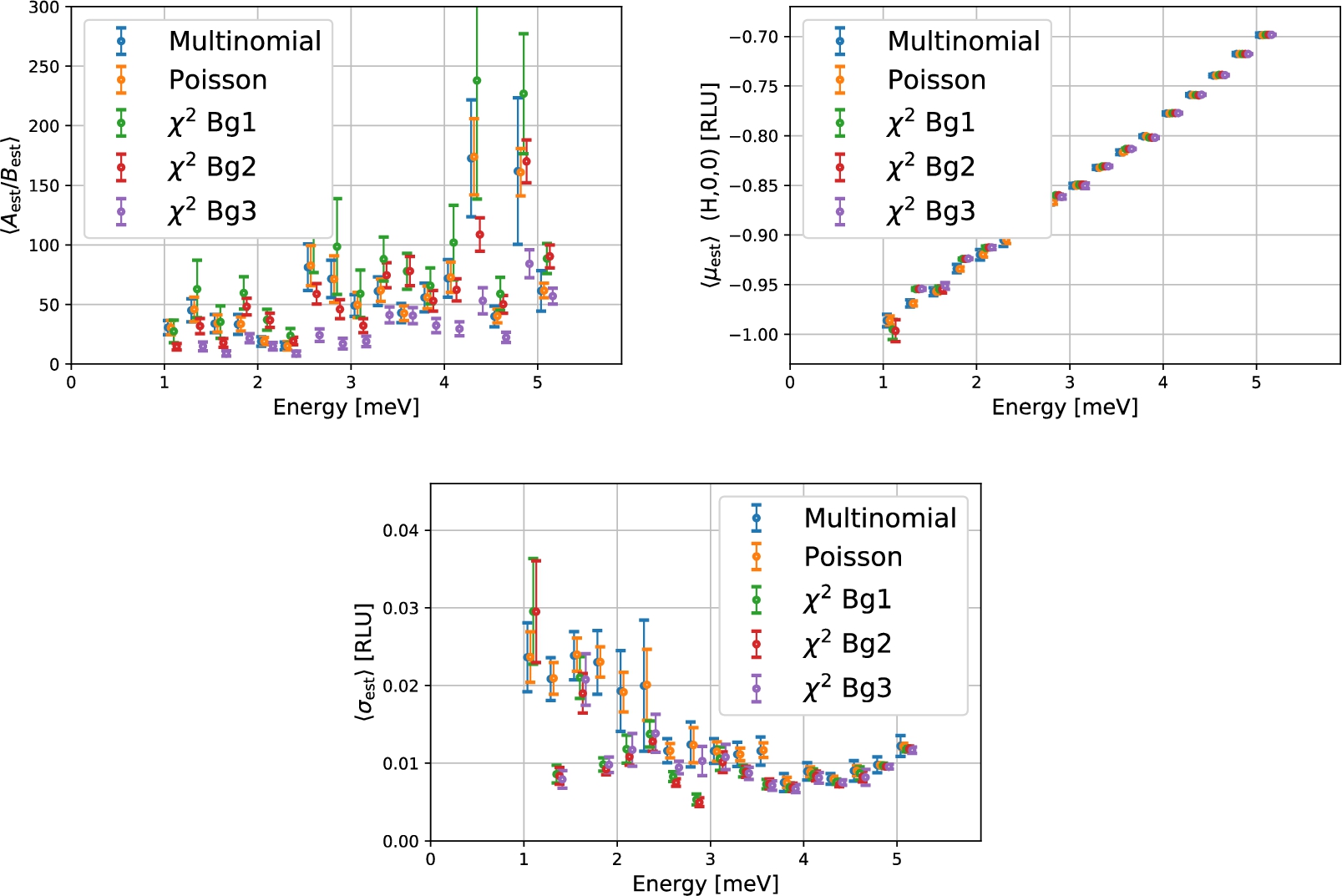
Parameter values and uncertainty as fitted to the MnF2 data using the 5 different methods and
Figure 6 shows the outcome of the data analysis for the four different fitting methods. From the found parameters it can be seen that all methods agree largely on the determination of μ, while some spread is present for the other parameters. As a trend, the Poisson method predicts the largest values for the width of the peak. All methods agree that the amplitude of the peak grows for larger energies, but the exact value is disputed. As the background level in general is low, it is expected that the least squares method where zero counts are excluded overestimates the background and in turn underestimates the amplitude to background. This is indeed the case and this estimate lies below. The Poisson and Multinomial fits agree across all three parameters and at all energies. In order for the fits to converge properly, special care had to be given not to include any intensity to the data that was not described by the fitting function. Especially the background estimation of the Poisson and Multinomial fitting were sensitive to any other structures in the data, see Appendix D. Looking at the estimated uncertainties in the parameters, it is seen that the Multinomial distribution provides the largest error estimates as compared to the Poisson. This was also seen in Section 4 where the conclusion is that the error estimates might be a little to large when compared to the standard deviation on a large sample of spectra.
This example of inelastic scattering data has been measured using a multi-detector setup but with a scan over sample rotation. This results in the requirements for using the Multinomial not being met, but rather one is to use the Poisson formalism.
Three different log-likelihoods have been presented having their origin in the Multinomial, Poisson and Gaussian distributions. We have reviewed the formalism to perform data analysis through parameter estimation using these in order to tackle the difficulties arising when performing simple
When treating a featureless spectrum we have clarified analytically and by the use of synthetic data that the Gaussian approximation of the Poisson distribution, both inside and outside the Poisson regime, will result in a clear bias. The simple reason is that Gaussian statistics weigh low-count data points higher. In contrast, the Poisson fits yields unbiased results, while the Multinomial method simply (and correctly) provides the mean count value as a constant value.
When fitting synthetic data with a peak on a constant background it was shown that the Multinomial and Poisson fitting methods produced much better results for parameters as compared to the three different least squares method. All of the methods had, on average, a good estimation of the peak center, with the Multinomial having the smallest standard deviation. In addition, in both the signal-to-noise and width parameters the
One of the drawbacks of using Multinomial and Poisson statistics is the need for maintaining the original count values of all data, for example in case of efficiency and monitor normalization as well as background subtraction. This complication makes development of data analysis software one level more complex. Nevertheless, we have implemented such a framework in the MJOLNIR analysis package and used this to compare the Poisson and Gaussian methods on simple, but real, data on spin waves in MnF2. Our findings show that the Multinomial and Poisson methods are less stable than the Gaussian methods with regards to the case where the fitting function does not fully describe the data. This necessitated masking away data regions containing other signals than the peak being fitted. For none of the Gaussian methods, such a masking procedure was necessary in order to get an acceptable fitting result.
It is only in the case of a one-shot acquisition that the Multinomial distribution is correct, i.e. when all data points are measured at the same time. If a scan is performed it is actually the Poisson distribution that is to be used. Despite the Multinomial and Poisson statistics being the correct methods in each their setting, the sturdiness and reliability of the Gaussian least-square certainly counts in the favour of this well-established method.
In conclusion, the Multinomial, Poisson and Gaussian methods have their strengths and justification, and we advocate that future full-fetched analysis programs should be equipped with more than one fitting method for their data analysis algorithms. A process could consist of first a
Footnotes
Acknowledgements
It is a pleasure to thank Toby Perring, Tobias Weber and Dmitry Gorkov for valuable discussions regarding understanding of error estimates and visualization of model and parameter uncertainties. We would also like to thank Christof Niedermayer for the assistance while obtaining the MnF2 data set at CAMEA.
Multinomial Log-likelihood derivation
Taking the logarithm, and applying Stirling’s approximation for all faculty terms, one gets
Solving the above equation can be split into two; firstly if Eq. (44) is zero, the first term in Eq. (43) is independent of
The full MnF 2 data set
Proof of the systematic errors in the values of background estimators
In the following the deviation of the background estimation using the least squares method on scattering data is investigated. Starting from the chi square
The limit for large background values is found for all three estimators in (64) by identifying the important parts to be the exponential in the nominator and the exponential integral in the denominator. In the large limit
Sensitivity of Multinomial and Poisson fits
During the fitting procedure of the MnF2 it became apparent that the stability of the different methods were different, see Fig. 11. When performing the parameter estimations using the different techniques and the same initial guess only the Gaussian approach was robust against a model not fully capturing the data. Both the Multinomial and Poisson methods are influenced by the second feature in the data. This is seen by the lowering of peak intensity and broadening of peak width balancing to fit both peaks. From the discussion of log-likelihoods shallowness of the Poisson and Multinomial log-likelihood as compared to the