
Abstract
This paper proposes a rule base simplification method for fuzzy systems. The method is based on aggregation of rules with different linguistic values of the output for identical permutations of linguistic values of the inputs which are known as inconsistent rules. The simplification removes the redundancy in the fuzzy rule base by replacing each group of inconsistent rules with a single equivalent rule. The simulation results show that the aggregated fuzzy system with the consistent rule base approximates quite well the original fuzzy system with the inconsistent rule base. The main advantage of the proposed method over other methods is that it does not require any refinement of the rule base using additional data sets or expert knowledge. In this context, the method is quite suitable for applications where rule base refinement is unacceptable due to time constraints or impossible due to lack of additional data or knowledge.
Introduction
Fuzzy systems are usually good at capturing the qualitative complexity of a wide range of problems by means of their linguistic modeling and approximate reasoning capabilities. However, this comes at a price because the associated operations during fuzzification, inference and defuzzification increase the quantitative complexity of the solution to these problems. This price gets even higher as the amount of fuzzy operations increases as a result of the increased number of rules in the fuzzy system.
The number of rules in a fuzzy system is often an exponential function of the number of inputs to the system and the number of linguistic values that these inputs can take [1, 2, 3, 4]. This exponential function has been used as a main indicator for the quantitative complexity of the associated fuzzy system. However, this is a fairly rough indicator because the quantitative complexity depends on the overall amount of operations during fuzzification, inference and defuzzification. For example, a 4-input fuzzy system with 2 linguistic values per input has the same number of 16 rules as a 2-input fuzzy system with 4 linguistic values per input but the amount of operations in the first system is about twice as big as the one in the second system due to the twice bigger number of inputs in the rules.
There has been a growing interest recently in complexity issues of fuzzy systems [5, 6, 7, 8]. This is due to the fact that fuzzy systems are already more widely used in large-scale applications where their quantitative complexity becomes more obvious. In particular, many methods have been developed for reducing this quantitative complexity. These are known as rule base reduction methods as they reduce the number of rules by reducing the number of inputs or the number of linguistic values that these inputs can take. The main objective in this case is to suppress the associated exponential function. These methods are classified into six groups and discussed below.
The first group of methods are aimed at removing less significant or merging similar linguistic values [9, 10]. From these two strands, the one based on removal of linguistic values is more straightforward but it involves a higher risk as a result of the removal of the associated fuzzy set. On the other hand, the strand based on merging of linguistic values is more difficult for application due to the necessity to define a new fuzzy set for each of the merged linguistic values.
The second group of methods are aimed at removing less significant or merging similar inputs [11, 12]. From these two strands, the one based on removal of inputs is more straightforward but it involves a higher risk as a result of the removal of the associated physical variable. On the other hand, the strand based on merging of inputs is more difficult for application due to the necessity to justify physically the merging of the associated variables.
The third group of methods are based on singular value decomposition of the matrix representing the crisp values of the output from a fuzzy system [13, 14]. As a result of this decomposition, the number of linguistic values for the inputs to the system is reduced. Although this group of methods can be quite effective in reducing the number of rules in a fuzzy system, they are applicable mainly for systems with two inputs. In the case of more inputs, the singular value decomposition process becomes quite complex as the dimension of the space in which the associated matrix is defined increases significantly.
The fourth group of methods are based on conversion of the intersection rule configuration of a fuzzy system into a union rule configuration with a smaller number of rules [15, 16]. This group of methods can be quite effective in reducing the number of rules in a fuzzy system but they can only be applied to a special class of problems called ‘additively separable’. For problems that don’t belong to this class, the conversion of the intersection rule configuration into a union rule configuration is not possible.
The fifth group of methods convert a fuzzy system into spatially decomposed subsystems as a result of which the overall number of rules is reduced [17, 18, 19, 20, 21, 22]. In this case, the interactions among the subsystems are partially compensated and the resulting decomposed system has a decoupled structure. Although this group of methods have been widely used recently, the success of their application depends on the strength of interactions among the subsystems and the level of their compensation.
The sixth group of methods rearrange the inputs in a fuzzy system in a way that leads to the reduction of the number of rules [23, 24, 25, 26, 27, 28]. In this case, the fuzzy system is decomposed into a multilayer hierarchical structure such that each layer has only two inputs and one output. Although these methods have become quite popular recently, they don’t offer clear interpretation of the intermediate variables between the first and the last layer. Besides this, only two inputs are taken into account in each layer while all other inputs are ignored.
Most of the above rule base reduction methods for fuzzy systems have serious drawbacks such as empirical nature and limited scope. The empirical nature of the methods in groups 1–2 and 5–6 assumes the use of a ‘trial and error’ approach that can be unreliable. Besides this, the limited scope of the methods in groups 3–4 makes them inapplicable to a wide range of fuzzy systems.
This paper addresses the above two drawbacks of rule base reduction methods by proposing a novel rule base simplification method that is characterised by systematic nature and universal scope. Besides this, the method leads to solutions which approximate very closely the precise solutions.
The main novelty in the paper is the proposed approach used for removing inconsistency in rule bases that is conceptually different from the established approaches. Instead of re-examining existing or collecting additional data or expert knowledge in order to remove the inconsistency that may be time consuming or even impossible, this approach aggregates inconsistent rules based on reasonable physical considerations and sound mathematical proofs.
The remaining part of this paper is structured as follows. Section 2 provides some theoretical preliminaries for fuzzy systems. Section 3 introduces the rule base simplification method. Section 4 illustrates the application of this method to several examples with inconsistent rule bases. Section 5 summarises the main advantages of the method and highlights future research directions.
Theoretical preliminaries
A fuzzy system can be represented by the following rule base
where
The maximum number of rules
where
However, if the number of linguistic values that each input can take is not a constant, the maximum number of rules in a fuzzy system is given by
where
Fuzzy rule bases have some important properties [31]. These properties describe the extent to which the permutations of linguistic values of inputs and outputs are present in the rule base. The properties also describe the type of mapping in the rule base between permutations of linguistic values of inputs in the ‘if’ part and permutations of linguistic values of outputs in the ‘then’ part. Four basic properties of fuzzy rule bases are introduced below by definitions. These definitions make use of logical equivalence, i.e. a property is present when the corresponding condition holds and vice versa. This logical equivalence also implies that a property is absent when the corresponding condition doesn’t hold and vice versa.
The aim of the rule base simplification approach in fuzzy systems is to remove the redundancy in the rule base that is caused by inconsistent rules, i.e. rules with different linguistic values of the output for identical permutations of linguistic values of the inputs rules. Such rules may be present in fuzzy systems irrespective of whether the rule base has been created using data sets or expert knowledge. In this case, the approach has to identify all redundant inconsistent rules and remove these rules from the rule base by aggregating them into a single equivalent rules. Therefore, this approach acts as an aggregator for redundant inconsistent rules in the rule base that reduces the quantitative complexity in fuzzy systems at the expense of slight compromise of the solution.
In order to follow the proposed approach, it is necessary to consider the stages of fuzzification, inference and defuzzification. This consideration is presented further below whereby the inference stage includes three substages – application, implication and aggregation [32, 33]. The considerations are for single-output systems but they can be easily extended to multiple-output systems whereby each output is considered separately and in relation to the same set of inputs.
The fuzzification stage in a fuzzy system maps the crisp value of each input to the system to a fuzzy value by a fuzzy membership degree. This degree can be obtained from the fuzzy membership functions for the inputs to the fuzzy system. The considerations presented are based on normal triangular or trapezoidal fuzzy membership functions that have a maximum equal to 1 and are commonly used in fuzzy systems due to their simplicity.
In this case, the fuzzy membership degree
where
The application substage in a fuzzy system maps the fuzzy membership degrees of the inputs in each rule to a firing strength for this rule. The considerations presented here are based on rule bases with conjunctive terms in the ‘if’ part. Such rule bases are commonly used in fuzzy systems due to their ability to represent the simultaneous effect of all inputs.
In this case, the firing strength
where
The implication substage in a fuzzy system maps the firing strength for each rule to a fuzzy membership function for the output in this rule. The considerations presented here are based on horizontal truncation that cuts the normal fuzzy triangular membership function for the output in each rule to a subnormal fuzzy trapezoidal membership function whose maximum is equal to the firing strength for this rule. This type of truncation is commonly used in fuzzy systems due to its simplicity.
In this case, the fuzzy membership function
where
As the subscript
where
The aggregation substage in a fuzzy system maps the fuzzy membership functions for all rules to an aggregated fuzzy membership function representing the overall output for the rules. The considerations presented here are based on disjunctive rule bases. Such rule bases are commonly used in fuzzy systems due to their ability to represent the effect from the most dominant rule.
In this case, the aggregated fuzzy membership function
where
The defuzzification stage in a fuzzy system maps the aggregated fuzzy membership function for an output to a crisp value from the discrete variation range for this output. As this value is of a continuous type, the associated discrete variation range is mapped to its continuous counterpart. The considerations presented assume that the defuzzified value of the output is the centre of gravity for the aggregated fuzzy membership function for this output. This defuzzification method commonly used in fuzzy systems due to its applicability for any shape of aggregated fuzzy membership function for the output.
In this case, the defuzzified value
where
The method introduced here removes statically the redundancy in an inconsistent rule base of a fuzzy system during the fuzzification, inference and defuzzification stages for each simulation cycle. The redundancy is expressed by the presence of inconsistent rules and it is removed by aggregating the redundant subset of these rules with the aim of making the rule base consistent.
Aggregation of inconsistent rules in a fuzzy system is equivalent to representing a ‘one-to-many’ mapping as a ‘one-to-one’ mapping. A mathematical theorem for this representation is shown below. The proof of the theorem is based on Boolean logic laws and it is also shown further below.
where
Proof Equation (10) represents a set of ‘if-then’ implications that can be rewritten as
where the ‘if-then’ notations are replaced by ‘implication’ operators.
The implications in Eq. (12) are also disjunctive rules that can be rewritten as
where all rules are disjuncted together in one rule.
Using implication related laws, Eq. (13) can be rewritten as
where the ‘implication’ operators are replaced by ‘negation’ and ‘disjunction’ operators.
Using commutative laws, Eq. (14) can be rewritten as
where the terms for the inputs are grouped separately from the terms for the output.
Using idempotent laws, Eq. (15) can be rewritten as
where only one of the
Using again implication related laws, Eq. (16) can be rewritten as
where the ‘negation’ and ‘disjunction’ operator are replaced by an ‘implication’ operator.
Equation (17) represents an implication that can be rewritten as Eq. (11) where the implication operator is replaced by an ‘if-then’ notation. So, this concludes the proof.
The ‘one-to-many’ mapping from Eq. (10) is represented equivalently as a ‘one-to-one’ mapping from Eq. (11). In this case, the
Theorem 1 can be trivially extended to an arbitrary number of sets of inconsistent rules where each of these sets can be represented by a separate single equivalent rule. In this way, the inconsistent rule base of a fuzzy system can be converted to an equivalent consistent rule base of a smaller size.
Theorem 1 describes the theoretical foundations of the rule base simplification method. The practical implementation of this method is given by the algorithm below.
Put all inconsistent rules in disjoint sets whereby the rules in each set have the same permutation of linguistic values of inputs and different permutations of linguistic values of the inputs. For each set of inconsistent rules, aggregate the rules into a single equivalent rule. For each set of inconsistent rules, keep only the single equivalent rule.
Algorithm 1 guarantees that there are only consistent rules left in a fuzzy rule base after the completion of the simplification process. In this case, the number of consistent rules is equal to the number of inconsistent groups of rules plus the number of consistent rules. Therefore, the simplification process can be applied with a guaranteed success whereby the resulting simplified rule base is always consistent.
All steps in Algorithm 1 can be applied off-line. This is because the single equivalent rule can be found before the start of the fuzzification stage.
Algorithm 1 describes the aggregation process for inconsistent rules but it does not say when this process can be applied with full success, i.e. without any residual inconsistency being left. In other words, the question is when it would be possible to aggregate all inconsistent rules from each set into a single equivalent rule. This would be possible if the following conditions are fulfilled with respect to the fuzzy membership functions for the output:
The number of these fuzzy membership functions is odd, i.e. there is a fuzzy membership function in the middle, The fuzzy membership function in the middle is symmetrical, i.e. it has an axis of symmetry, Each of the remaining fuzzy membership functions has a symmetrical image with respect to the axis of symmetry of another symmetrical fuzzy membership function.
The above three conditions guarantee that the aggregation process will lead to a single equivalent rule for each set of inconsistent rules. In this case, the single equivalent rule for each set of inconsistent rules in the aggregated system would represent a reasonable compromise for the associated inconsistent rules from the same set in the original system. Although the conditions may appear to be restrictive, they are actually not as most fuzzy systems meet these conditions anyway as part of the requirements for spreading the fuzzy membership functions for the output uniformly across its discrete variation range.
Theorem 1 and Algorithm 1 are presented above for a single-output fuzzy system but they can be trivially extended to a multiple-output fuzzy system with an arbitrary number of outputs. In this case, the multiple-output fuzzy system from Eq. (1) can be represented by the following
whereby all considerations from the theorem and the algorithm can be applied repetitively to each of these systems.
The rule base simplification method is applied to several single-output examples in which the rule base includes a single set of inconsistent disjunctive rules. In this case, the remaining rules are ignored as they are irrelevant to the considerations.
The first example is fairly simple in that it has one input and contains a set of two inconsistent rules. This example illustrates the rule base simplification method theoretically in detail.
The remaining two examples are more complex in that each of them has two inputs and contains a set of more than three inconsistent rules. These examples illustrate the rule base simplification method briefly by simulations.
where the simple linguistic terms
In accordance with Theorem 1, this system can be represented with the single equivalent rule
where the simple linguistic term
For clarity, the fuzzy system from Eq. (19) will be called ‘original’ whereas the fuzzy system from Eq. (20) will be referred to as ‘aggregated’. The difference between these two systems can be illustrated by the implication substage, the aggregation substage and the defuzzification stage. In this case, the fuzzification stage and the application substage for the two systems are the same due to the identical ‘if’ parts for the input, as shown by Eqs (19) and (20).
As the ‘if’ parts of the two rules in the original system are identical, the firing strength
At the implication substage, the fuzzy membership functions
where
Due to the trapezoidal shape
where the parameters of the membership functions
At the aggregation substage, the aggregated fuzzy membership functions
At the defuzzification stage, the defuzzified value
At the implication substage, the fuzzy membership function
where
Due to the trapezoidal shape of
where the parameters of the membership functions
At the aggregation substage, the aggregated fuzzy membership function for the output from the aggregated system is equal to
At the defuzzification stage, the defuzzified value
It follows from Eqs (26) and (30) that the defuzzified value
where the simple linguistic terms P, VS, S, M, B and VB denote the linguistic values positive, very small, small, medium, big and very big, respectively.
In accordance with Theorem 1, this fuzzy system can be represented with the single equivalent rule
where the simple linguistic term
Output surface for original and aggregated fuzzy system in Example 2.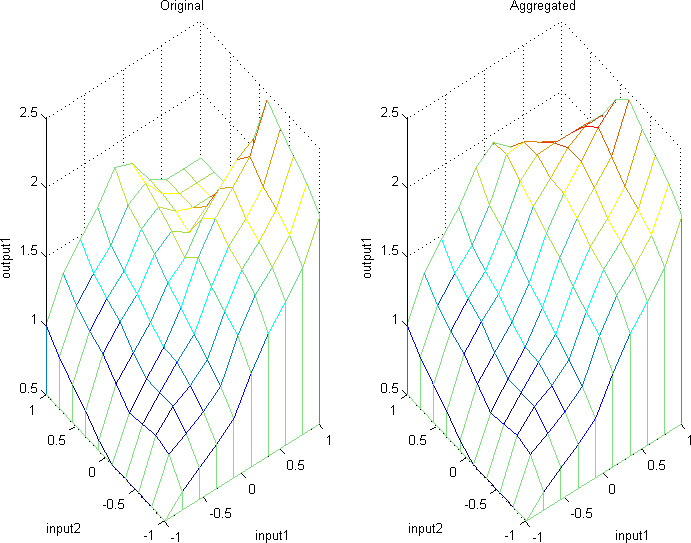
Output surface for original and aggregated fuzzy system in Example 3.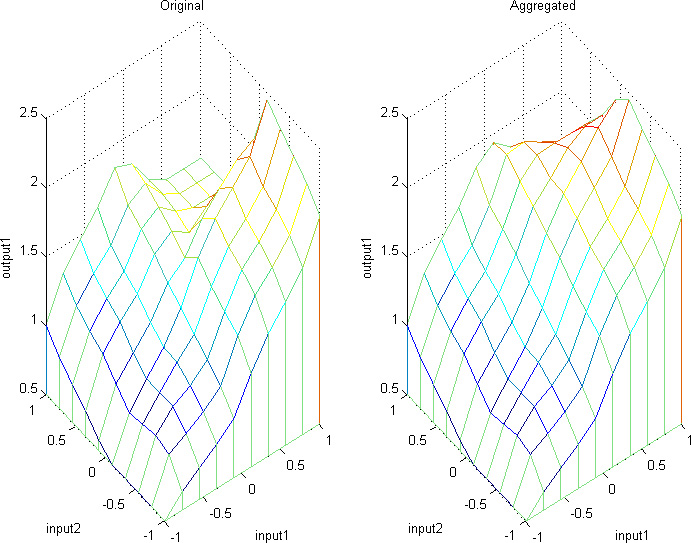
The output surfaces for the original fuzzy system from Eq. (31) and the aggregated fuzzy system from Eq. (32) are shown in Fig. 1. It can be seen from this figure that the output from the consistent aggregated system is a close approximation of the output from the inconsistent original system although the number of rules has been reduced.
where the simple linguistic terms P, VS, S, M, B and VB denote the linguistic values positive, very small, small, medium, big and very big, respectively.
In accordance with Theorem 1, this fuzzy system can be represented with the single equivalent rule
where the simple linguistic term
The output surfaces for the original fuzzy system from Eq. (33) and the aggregated fuzzy system from Eq. (34) are shown in Fig. 2. It can be seen from this figure that the output from the consistent aggregated system is a close approximation of the output from the inconsistent original system although the number of rules has been reduced.
Average number of inconsistent rules for an inconsistent rule base
The proposed rule base simplification method reduces the number of rules in a fuzzy system. This translates into a reduction of the associated computational complexity in terms of the overall amount of operations during the stages of fuzzification, inference and defuzzification. Therefore, the method is suitable for time-critical applications in which rule base refinement is either unacceptable due to time constraints or impossible due to lack of additional date or knowledge. Besides this, the solutions obtained by the proposed method are close approximations of the precise ones. This loss of accuracy is quite tolerable bearing in mind the gaining of consistency as a result of the aggregation of inconsistent rules in the rule base.
To illustrate the efficiency of the proposed method in general terms, the average number of inconsistent rules has been estimated in Table 1 for a single output taking 3 or 5 linguistic values. The table shows this average number as a function of the number of consistent rules for a complete rule base with 2 or 3 inputs, taking 3 or 5 linguistic values each. It can be seen from the table that the average number of inconsistent rules is almost equal to the number of consistent rules when the output takes 3 linguistic values and almost twice as big this number when the output takes 5 linguistic values. This demonstrates the efficiency of the proposed method in terms of the reduction of the number of rules due to the aggregation of the inconsistent rules. It is obvious that the efficiency of the proposed method would be even more significant for inconsistent rule bases with outputs taking more than 5 linguistic values.
The proposed method can be used without modification for other types of fuzzification, inference and defuzzification. For example, instead of triangular membership functions for fuzzification, it is possible to use trapezoidal ones or others. Also, instead of truncation type of implication, it is possible to use scaling type or others. And finally, instead of centre of gravity type of defuzzification, it is possible to use weighted average type or others.
The proposed method is illustrated for single-output fuzzy systems but it can be trivially extended to multiple-output fuzzy systems. This would lead only to a small linear increase of the associated computational complexity.
The proposed method is illustrated for single-input fuzzy systems whereby the input can take up to a few linguistic values but it can be trivially extended to fuzzy systems with an arbitrary number of inputs and number of linguistic values per input. However, this would lead to a significant non-linear increase of the associated computational complexity.
The proposed method is illustrated for fuzzy systems with a single rule base but it can be also used for fuzzy systems with multiple rule bases such as fuzzy networks. In this case, the fuzzy network can be transformed into a linguistically equivalent single rule base system by means of rule base merging operations and the method can then be applied in exactly the same way to this single rule base system.
The proposed method is illustrated for non-evolving fuzzy systems. However, it can be also used for evolving fuzzy systems whose rule base is updated before the start of the fuzzification stage. In this case, if the updated rule base is inconsistent, it can be made consistent by aggregation of the inconsistent rules.
Footnotes
Acknowledgments
The first author would like to thank the Faculty of Technology at the University of Portsmouth for the granted research sabbatical that made possible the writing of this paper.