
Abstract
In modern communication systems, it is necessary to develop new approaches to optimize them. To achieve this objective, new paradigms are necessary. The present work proposes an autonomic communication system, which uses a system of decision-making based on a Bayesian network, and a knowledge base based on an ontology, to take decisions of reconfiguration in the system. The main goal of the autonomic communication system is to adapt the communications platform to the characteristics of the context, in order to improve its performance. The ontology provides the knowledge about the performance factors and their relationships in the communication networks, to configure the structure of the Bayesian network. The Bayesian network is the stochastic reasoning mechanism used by the decision-making system. We present several tests on the NS2 simulator. In the tests carried out, we observe an improvement between 85% and 96% in the system performance, for scenarios where our approach of autonomic decision reconfigures the communication system.
Introduction
Research background
Currently, due to the great number of devices of interconnection, to the technologies of interconnection, and to the development of new communication platforms, we have a diversity of available mass media. On the other hand, the multimedia applications are more common every day, and the real time communications need of major bandwidths, minor latencies, minor variation in the time of arrival of packages (jitter), major reliability, and in general, of sensitive environments to variations in the flow (throughput). In this way, it is necessary to optimize the use of the resources of the communication networks. One answer to these necessities, it is to develop self-configurable communication systems; that is, it is required the development of autonomous communication systems that improve their performance.
In that sense, this work proposes an autonomic communication system that optimizes its performance, as a function of what it knows about the context (data transmission problems, etc.) and of the applications running on it (multimedia or not, with or without quality of service, etc.). The autonomic communication system requires of a decision-making system to guide the reconfiguration process, in order to adapt it to the new operational conditions. In our case, the system of autonomous decision requires of an ontology that describes the communication system, the autonomous tasks to carry out the reconfiguration process, among other things. Moreover, with our ontology is developed a decision Bayesian model, which is updated through a learning process, in order to adapt its behavior based on the changes in the operational context. So, we propose to develop an autonomous decision system based on an ontology, from which is conceived a Bayesian network as an inference mechanism for decision making. The main idea of using Bayesian networks is because they allow the management of uncertainty, typical in the systems of communication. The principle of the autonomic communication system proposed in this work is to make intelligent decisions based on the ontologies and Bayesian networks.
Literature review
The autonomous communication systems have been inspired by the autonomic computing, with the goal of allowing the self-configuration, self-management and self-regulation of the communication infrastructures. Some works in autonomic communication systems are [10, 17, 23, 3, 1, 26]. The topics most developed in autonomic communication are: the development and implementation of an autonomic communication kit (ACT) for a communication system that meets its requirements of quality of service (QoS) [26]. This work uses the Markov chains for taking decisions about whether the system must be or not reconfigured, and proposes a theoretical model of reinforcement learning to optimize the communication systems. Another work is proposed in [20], which used cognitive networks and influence diagrams to make decisions about how to improve the communication. Finally, a work linked to the problem of autonomic reconfiguration is proposed in the DAISY project (Diagnosis for Adaptive Strategies in collaborative systems). In particular, this project proposes an architecture of an autonomous system of communication, which is based on the identification of the current situation in the communication system; they propose an approach to invoke the process of self-adaptation, which ensures that the system is able to continue functioning properly [2].
In decision-making of self-adaptive systems (SASs), [6] proposes a methodological specification that uses dynamic networks of decision based on Bayesian networks, enriched with a short-term memory, to improve the performance in decision-making processes with uncertainty. In intelligent decision systems based on ontologies, the doctoral thesis [30], at INSA-Toulouse, uses an ontology based on the ODA (Ontology Driven Architecture) paradigm, for the autonomous management of the quality of service in communications networks. It defines a framework based on ontologies, to develop an autonomous system of communications. This ontology allows describing the QoS requirements, so as to enable an autonomic process in the communication system that provides the required QoS.
Finally, Bayesian networks can represent uncertainty in the relationship of dependency between variables that describe a process of decision making (in our case, linked to communication systems) [7, 25, 5]. The learning in the Bayesian networks can be divided into two types [24]: parametric and structural. In particular, several works propose methodologies for the construction of Bayesian networks by means of ontologies. For example, in [21] proposes a framework called BayesOWL, which specifies a formal method for the creation of Bayesian networks from ontologies that allows the handling of uncertainty over the domain for which it was designed the ontology.
Paper positioning
The main contribution of this work is the definition of an autonomic communication system based on an ontology used to build a Bayesian network that is defined for the decision-making process of reconfiguration. With respect to previous works, it is used an ontology based on the mix of several ontologies of references of communication systems, which provides a knowledge base for the system of decision-making. With this ontology is built a Bayesian network, which makes that the system be able to deal with the uncertainty typical of the communication systems. The Bayesian network is used to choose the action of reconfiguration that maximize the performance of the communication network. In addition, the autonomous system can predict with effectiveness the trend of performance of the communication network, in order to prevent its degradation. In addition, the system is able to learn, so as to update the parameters of the Bayesian network, to reconfigure the communicational platform according to the current information. Finally, the system can make decisions with partial or total information about the communication system.
This paper is organized as follows: Section 2 presents
the theoretical framework, specifically, the communication systems from the point of view of the autonomous systems, and the Bayesian networks for decision-making processes, and how they are constr- ucted from ontological frameworks. Section 3 presents the architecture of our autonomous system based on Bayesian Networks, as well as the process of transformation of the ontology to the Bayesian network to be used in the autonomous system. Section 4 details the experiments, and the results are analyzed. Finally, the conclusions and recommendations are presented.
Architecture for self-adaptation [2].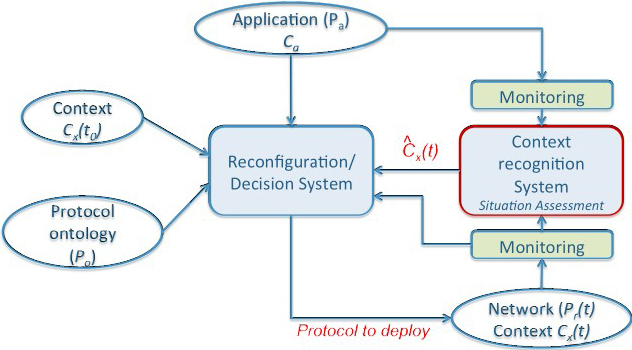
Autonomic communication systems
The autonomic communication is an extension of the concept of autonomic computing, which is applied to the communication networks. In general, an autonomic communication system must monitor, analyze, take decisions and act, in the communication platform. An autonomic communication must self-configure, self-optimize, self-protect and self-heal, with minimal human intervention, to adapt it to the changes to its context.
The paradigm of Autonomic Computing (AC) is inspired by the autonomous nervous system of the human being. Its fundamental objective is that the computer systems can be self-managing. An autonomous system takes decisions by its account, using high-level policies, to review and to constantly optimize its situation, and adapt to the changing conditions of its environment [27, 3, 17]. The architecture of an autonomic system has been described in [16]. The components are:
Managed Resource: Can be any type of resources (hardware or software) that can be managed. The managed resources are controlled through its sensors and actuators.
Touch Points: Binds to the sensors and/or actuators required for the management of resources.
Autonomic Local Manager: Implements the intelligent control loops that automate the tasks of self-management. The components of the control loop, which share a common knowledge base, are:
Monitoring Component: It provides mechanisms for the collection of the information about the resources to be handled. Analysis Component: It provides mechanisms to correlate and model complex situations, to analyze that may be occurring in the system. These mechanisms allow understanding the current situation, inferring future situations, among other things. Planning Component: Provides mechanisms for the constructing and planning of the actions necessary to meet the goals of the autonomous system. Execution Component: Defines mechanisms that execute the actions defined in the planning component, to reach the goals of the system.
These four components, with the component of knowledge representation, define the control loop.
Orchestrator of the Autonomic Managers: Due to an autonomous system can count with several local managers, which need to work together to ensure the correct operation of the system, this level provides the communication channel for the coordination between them.
Manual Manager: Allows to humans configure the autonomic managers to perform their task of self-management, providing for this a man-machine interface.
Sources of Knowledge: Provides access to the knowledge required for the autonomic system.
An example of an autonomic communication system is DAISY [2], which is shown in Fig. 1. In this architecture, the reconfiguration process takes into consideration different entries:
The initial context The properties required by the application The current state of the context
DAISY architecture is based on a system of recognition of context, which monitors and evaluates the context of the communication system, to propose changes on the same.
The autonomic communication is a concept than, in addition to the concepts derived from the autonomic computing, also we can add some other principles, such as: advanced handling of the communication platform in aspects such as the virtualization of the network, the specialized management of certain applications on the network (telephony, video conference, etc.), support systems to communications (disaster recovery, etc.), the incorporation of the management of applications as a service (SaaS), among others.
Bayesian networks (RB), also known as networks of beliefs, belong to the family of probabilistic graph models. These structures of directed graphs are used to represent uncertain knowledge as a multivariate probability model, which describes a set of random variables and their causal influences [7]. In the RB, each node represents a random variable, and the arcs represent probabilistic dependencies between the variables (the absence of the arcs indicates conditional independence). Uncertainty displayed in RB can be modified based on the events on the real system monitored.
A RB represents knowledge through causal relationships (structure of the graph) characterized by conditional probability tables between nodes. Thus, the knowledge network is composed of the following elements [18]:
A set of nodes that represent each variable in the model. A set of arcs between the nodes that have a causal relationship. A table of conditional probabilities associated with each node, indicating the probability of its states for each combination of the states of its parents.
The inference process in the RB is based on the Bayes Theorem [18]. In the RB, the probabilistic inference consists in, given certain known variables (evidence), calculate the probability of the other variables (unknown). The Bayes theorem expresses the conditional probability of a random event
where
In general, this model can be extended considering the constraints
where, the domain
The learning in the RB consists in the development of a model of the structure, and the definition of the parameters of the network, from the data in the system to monitor [24]. In this way, the learning can be in two ways [24].
It is based on the fact that, given the structure, must be obtained the associated probabilities. There are many methods in the literature for the parametric learning, in this work were used [7, 19].
Learning by method of maximizing the expectation
The method of learning of the method of EM (EM, expectation maximization) is very used in the case of hidden nodes. The hidden nodes are defined as the nodes where the values that a variable can have are not known. The algorithm of this method is [24, 13]:
Start the unknown parameters (conditional probabilities) with random values (or estimated by experts): Use the known data, with the current parameters
Use the values estimated in the previous Step
Repeat Steps 2 and 4 until there are no significant changes in the odds.
Learning by counting is the method simplest and fastest, when there are not many missing data or many uncertain data. The counting method can be used to learn or reinforce the conditional probability tables (CPT).
In the case of learning, this method part of a network that is in a state of total ignorance, in which all the probabilities are uniform. The mechanism allows to learn the probabilities. The other case in which this method is used is to reinforce the learning. In both cases, the next procedure is followed [19]:
For the nodes of the network in which there is a finding (for example, there is a finding for a given node (
The belief generally takes the value of 1, but the same can have a higher value, as for example 2, if there are two identical cases at once. Additionally, it can take the value of
The probabilities of the brothers of
In this way, the new vector is normalized according to the factor of
Structural learning consists mainly of getting the structure or topology of the network, that is, finding the dependency relationships between the different variables. These relationships can be found mainly in two ways; the first is to obtain the structure from an expert, and the second is to use data mining to obtain the structure. The second case, according to the type of structure, can use the methods [24].
Trees Learning. Polytree Learning.
In both cases the problem is about optimization, to obtain the tree structure that is closest to the’real’ distribution. For the majority of the cases is used the algorithm of Chow-Liu [7]. The Chow-Liu algorithm assumes that each variable has at most one root (father node), and is based on approximate a probability distribution from a probability product of second order. In the Chow-Liu algorithm, the joint probability of n variables is expressed by the equation:
where
To obtain the structure of the network is optimized a measure of the difference of the information (DI) between the actual distribution
We can define this difference in function of the information (
Finally, the optimal tree is found by the algorithm [24, 29]:
Create an empty Calculate the mutual information between all pairs of variables (in general). For this is used the Eq. (11). Sort the mutual information from highest to lowest. Add the arc with the largest value of mutual information to graph Add the following arc while it does not form a cycle, otherwise discard. Repeat Steps 3 to 5 until cover all variables
This kind of learning is not required for this work.
Decision-making in Bayesian networks is not only based on the probability of an event, but also the potential benefits (utilities) and the costs of the same, in order to determine how it affects the possible decision. The main idea is to be able to find a plan of action to maximize the benefits and minimize the costs. In this way, Bayesian networks have been extended to handle the theory of decisions.
To do this, the Bayesian network defines influence diagrams, which is an extended version of it. The influence diagrams have three types of nodes, the first corresponds to nodes of the RB original (uncertain), the second are nodes corresponding to the actions to be taken (decision), and finally, the last nodes corresponding to the utility function (see Fig. 2). A node of function of utility is represented by a diamond, and an action node as a box.
The influence diagrams [31] are used to make decisions that will maximize the benefits of the actions to be implemented, based on the expected utility (MUE). In that sense, solving a decision problem is equivalent to determine the maximum expected utility using the chosen strategy. The utility of the action
The MUE is obtained as the maximum result of UE(
Thus, a diagram of influence can be considered as a Bayesian network augmented with decision variables, the utility functions that specify preferences in the decision-making, and an order of precedence.
Example of diagram of influence.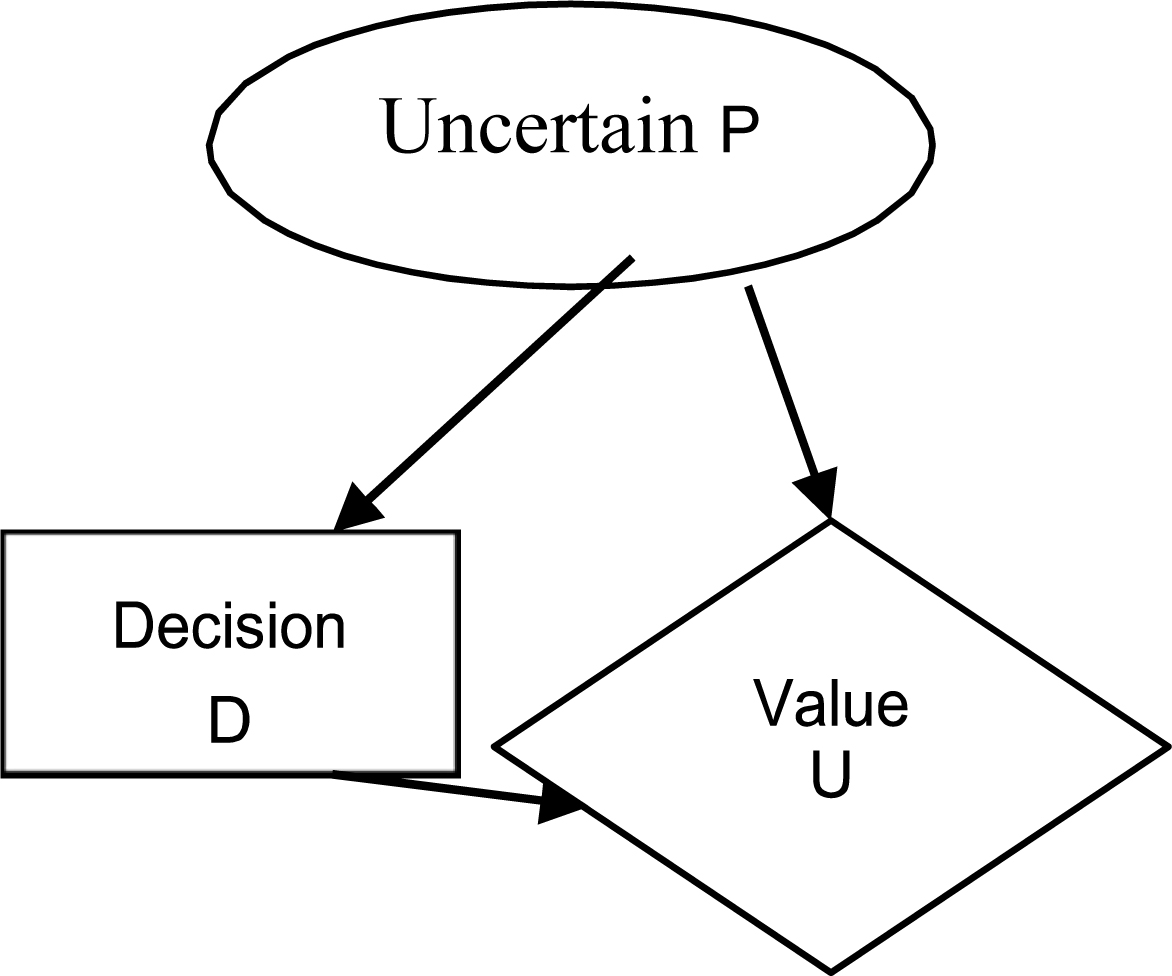
Formally, a diagram of influence is a directed acyclic graph (DAG) that contains N nodes representing the variables of the problem of decision
Uncertain Nodes, Decision Nodes, Utility Nodes,
The CPT represents the quantitative information about the probabilistic network, the same is represented as a real number in the range [0.1]. The CPT is a simple table, which has a numeric value for each possible combination of a parent node with its child nodes, which represents the conditional probability of occurrence of the son given that occurs the father (Bayes theorem). All the probabilities that come out of a parent node must sum 1 [19].
In a diagram of influence are seeking, in general, take the optimum decision, which is the one that maximizes the value of utility. When there is no quantification, simply is limited to choose the possible actions.
There are multiple jobs that address the transformation of an ontology in a Bayesian network [14, 15, 21]. In particular, in this work we use the framework BayesOWL. The framework BayesOWL [22] provides a set of rules and procedures for the direct transformation of an ontology described in OWL in a Bayesian network. BayesOWL allows:
Represent information of OWL as probabilities. Translate OWL ontologies to RB.
Rules to build the structure of the RB from triplets OWL. Help for the addition of special nodes for the logical relationships. Construction of tables CPT.
For the structural translation of an ontology described in OWL in a Bayesian Network are used rules. The general conversion rule is that all classes are transformed into nodes in the Bayesian network (the classes are specified as subjects and objects in a RDF triplet), and an arc is drawn between two nodes only if the two nodes are related by a predicate described in OWL, from a superclass to a subclass [21]. Additionally, it creates a special class of nodes, L-Nodes, also called nodes of control, which are created to facilitate the modeling of the logical relationships between the classes described in OWL. Control nodes contain convergent connections from each one of the concept nodes involved in a logical relationship. There are five classes of control nodes, corresponding to the logical relationships “an” (Owl: intersectionOf), “o” (Owl: unionOf), “no” (Owl: complementOf), “disjoin” (Owl: disjointWith), and “same a” (Owl: equivalentClass). The rules of BayesOWL are based on five steps to the structural translation [21]:
rdfs: subClassOf.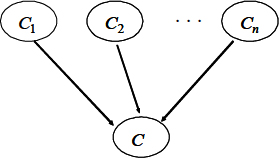
oel: intersecctionOf.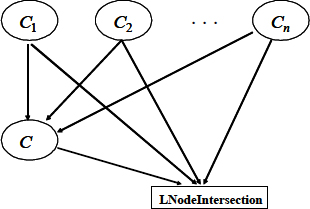
owl: unionOf.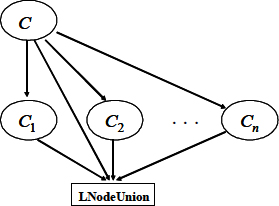
Each primitive or class The constructor “rdfs: subClassO” is modeled by a direct arc node of the parent class (parent superclass) to each node of the subclass son. For example, a concept of class A Class concept of A class concept If two concepts of class
Based on the previous rules, the RB translated will contain two classes of node. The nodes of regular class for the concepts, and the L-nodes that are nodes associated with the logical relationships. Using the L-nodes, the relationship “rdfs: subClassO” is differentiated from the other logical relationships. Thus, from these relationships are built the CPT of each regular node
owl: complementOf, owl: equivalentClass, owl: disjointWith.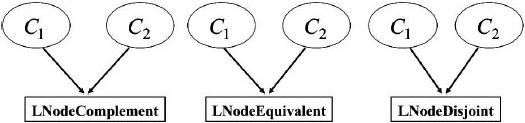
To build the CPTs of the Bayesian Network must be taken into consideration the two types of nodes: the logical nodes (called L-nodes) and the nodes of a concept. The following are the steps for this transformation [21]:
CPT for L-nodes (are five types) are specified as follows:
LNodeComplement: The relationship complement between LNodeDisjoint: The relationship disjoint between LNodeEquivalent: The relationship equivalent between LNode Intersection: The relationship CPT for the nodes of concept is calculated by (
Determine the marginal probability Determine the conditional probability (
The probability distribution for an input
Architecture of our autonomic communication system
The proposed architecture for the implementation is based on the architecture DAISY (see Fig. 1). In particular, in this work are redone the system of recognition of the context and the decision system. The latter system is a separation of the reconfiguring of the system, which consists of two parts, one that makes the decision to reconfigure, and another that sets the protocol of the transport layer, in order to optimize the performance criteria of the communication (i.e., increasing flow, reducing latency, reducing errors, among others). To achieve this goal, one must obtain the traces of the supervised communications system, and calculated from them all performance measures related to Quality of Service (QoS). This is carried out by the monitoring of the Fig. 1.
Ontology of Shannon and Weaver.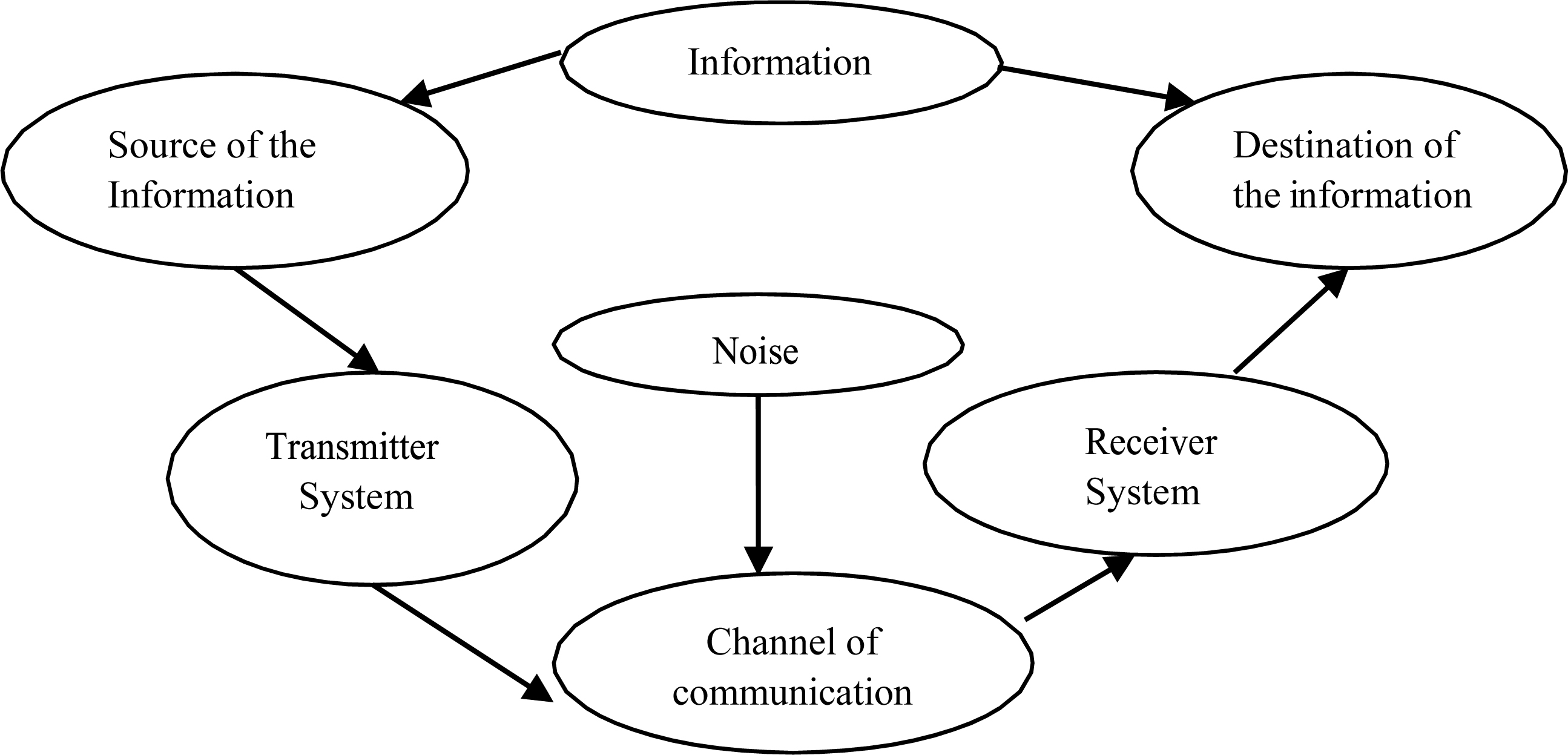
Ontology for the transport layer [11].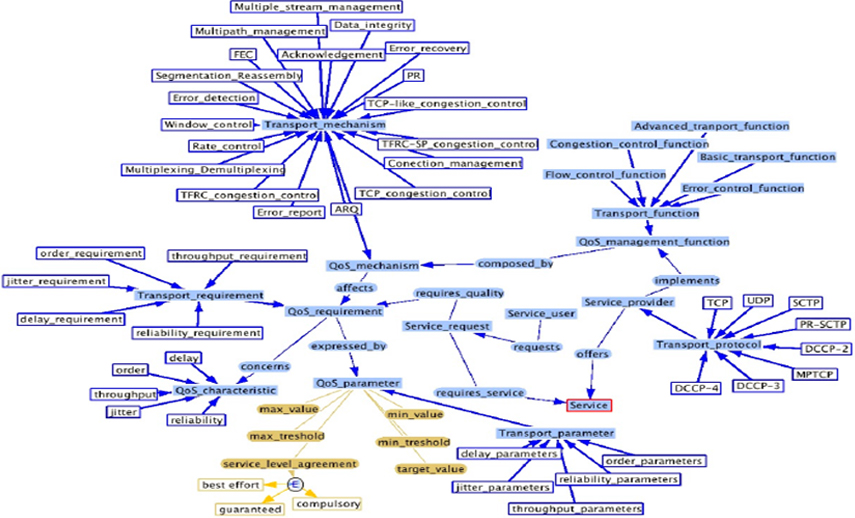
Ontology of the Hydra project [8].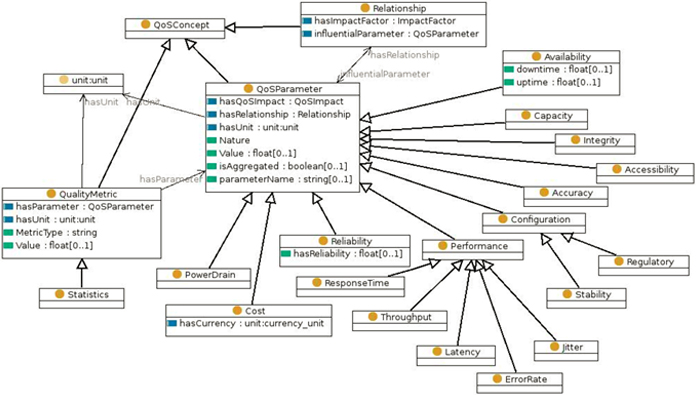
Ontology of control protocols based on IETF, for the case of multimedia content.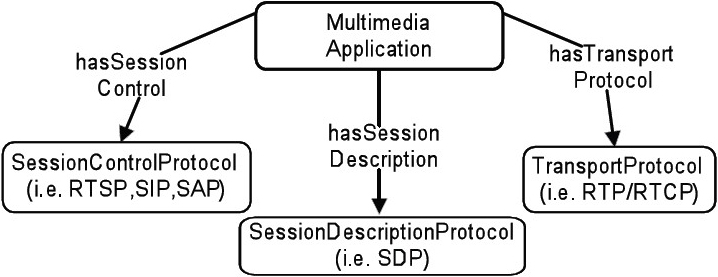
This system is part of the system of reconfiguration of the Fig. 1, which is composed of two components: The sub-system of decision of reconfiguration (it takes the decision to reconfigure), and the sub-system for the execution of the reconfiguration (it adjusts the transport layer protocol). The sub-system of decision of reconfiguration (see Fig. 1) is based mainly on a diagram of influence, as the main element for decision-making. It uses the observed patterns in the supervised communication system (these parameters are: flow, delay, rate of losses, among others), which are obtained through the analysis of the traces of communication (subsystem of performance calculation). These parameters also contribute to update the diagram of influence through the learning by counting, in this way the system is updated on the basis of the different experiences that contribute positively with the communication system. In general, the diagram of influence takes the decision whether or not there should be a reconfiguration in the communication system.
System of recognition of context
To build the diagram of influence, this system is composed of the ontology of domain and the Bayesian network. With the ontology, the Bayesian network is built like a previous step to define the diagram of influence. This subsystem monitors the real system, and with its knowledge and the current context, it instances the diagram of influence to make a decision. The ontological characterization is shown in the following sub-section.
Domain ontology
Domain ontologies are ontologies derived from Metaontologies, which are specific to our system of communication. The ontologies characterize all standards that are used. Below are presented the Meta- Ontologies used in the present work. We start with a general ontology based on the model of Shannon and Weaver (see Fig. 7), which is the model of communications used.
From the model of Shannon and Weaver was defined the ontology to the communication system. However, in this ontology are not taken explicitly into account some aspects, which are described by other ontologies. Some of these aspects are the problems of quality of service, types of protocols, etc., which is important in the modern communication networks. These ontologies are shown in the Figs 8–10. Figure 8 represents an ontology about QoS at the level of the transport layer, it integrates the requirements of applications, mechanisms, functions and protocols of the transport layer, among other things [11]. Figure 9 defines an ontology that represents the quality of service parameters, with criteria of performance, power consumption, capacity, etc. [8]. Finally, Fig. 10 shows an ontology that characterizes the management of multimedia content in communication systems [12]. This ontology is based on the protocols of the IETF (Internet Engineering Task Force), and integrates the section control, the description of the section, and the transmission protocol.
Performance ontology.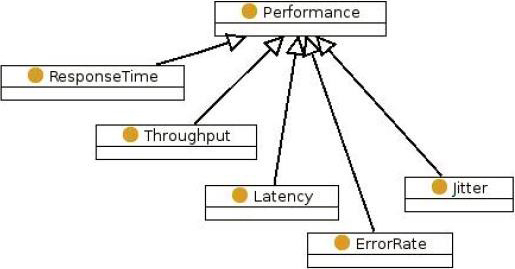
Proposed ontology.
Reduced ontology.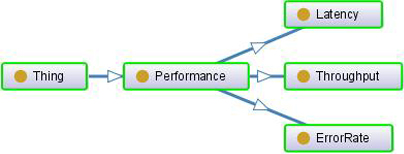
Primitives class.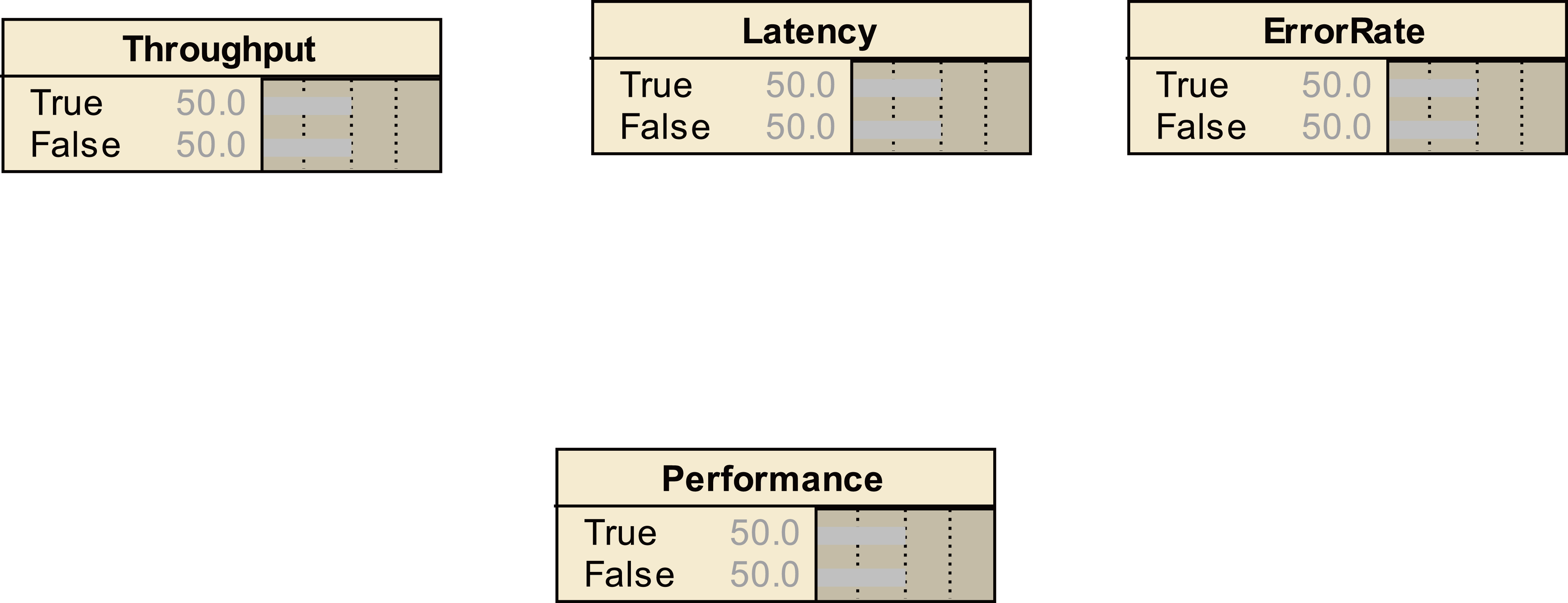
Subclasses.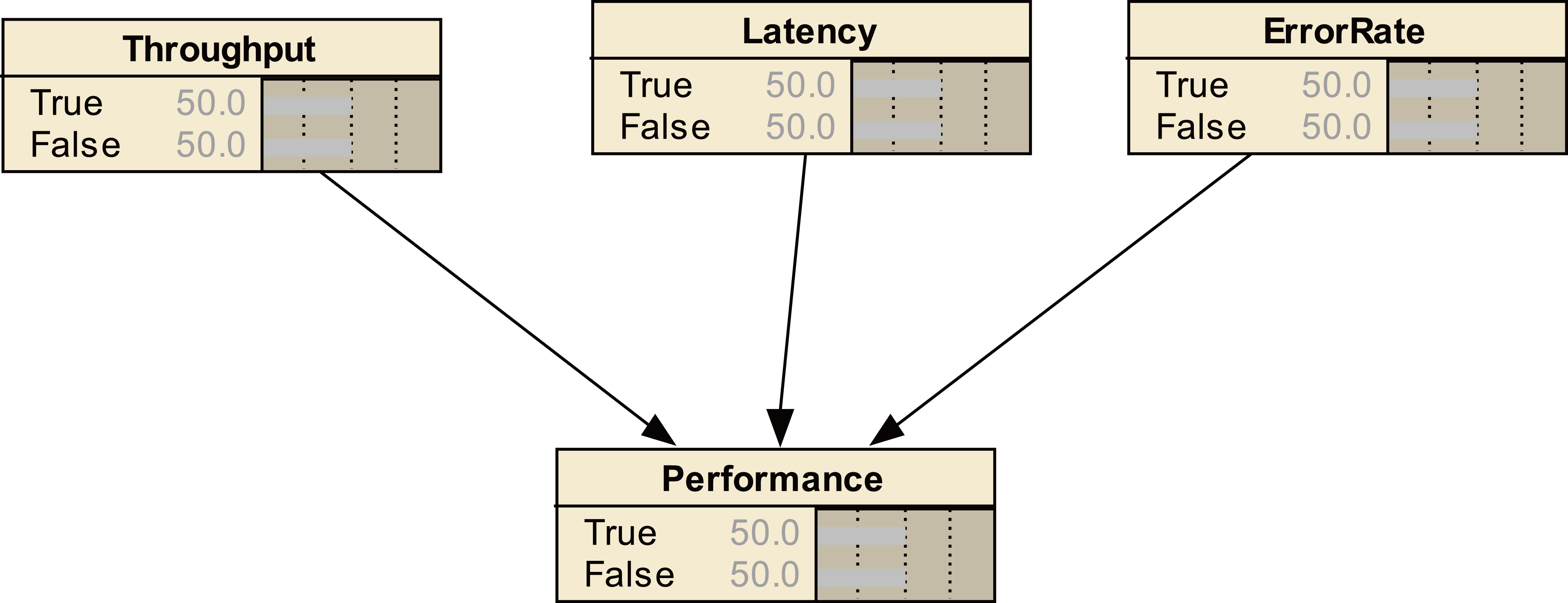
CPT Tables, with uniform values.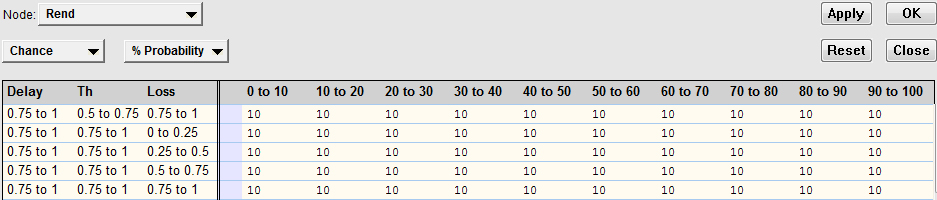
They are now used to form a single ontology that meets the following requirement: to characterize the autonomic communication system. To do this, we analyze each meta-ontology. The relevant elements of the meta-ontologies characterize the QoS parameters, and its ontological relationship with the performance in general of the communication (see Fig. 11). The QoS parameters describe (model) the basic characteristics of the channel of communication, as for example, the delay, the latency, the throughput, among other things.
Now, we need a general meta-ontology that describes the channel, shown in Fig. 7, to which is added the rests of the aspects described in the other ontologies to define the nature of the information to transmit, and the performance parameters. The merged ontology is shown in Fig. 12, and represents a compendium of all the elements used in the autonomous communication networks, taking account the elements involved in the decision-making process.
To use the previous ontology, we need to transform it into a Bayesian network. For this, the ontology must be described in OWL (BayesOWL structural 1.0) [21].
Transformation of the ontology proposed in Bayesian network
To show the process of transformation, it is considered a fragment of the ontology of Fig. 12 (see Fig. 13). Below are presented each Step of the algorithm:
Structural translation
Each primitive or class
The constructor “rdfs: subClassO” is modeled by a direct arc from the parent class (parent superclass) to each node of the subclass son. For this, we use the description in OWL (see Fig. 15):
CPT Tables, after of the learning process with EM.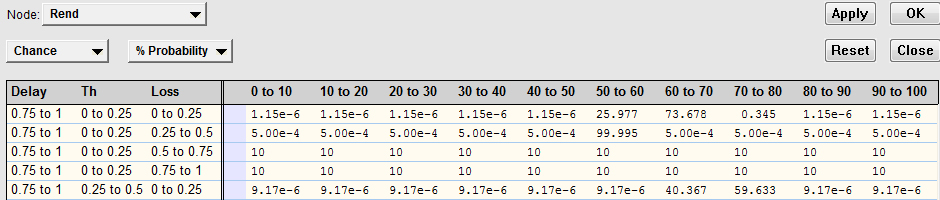
Ontology with decision node.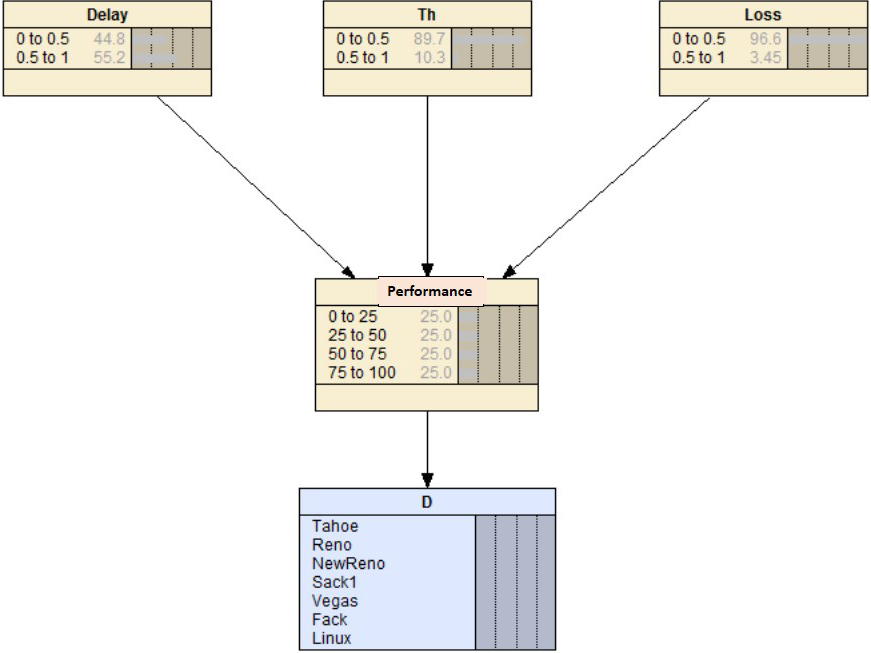
Ontology transformed into an influence diagram.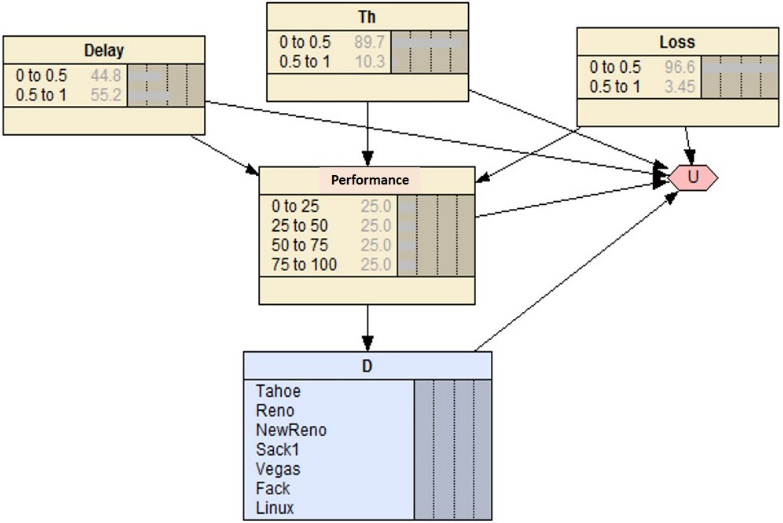
Influence diagram used for the simulations.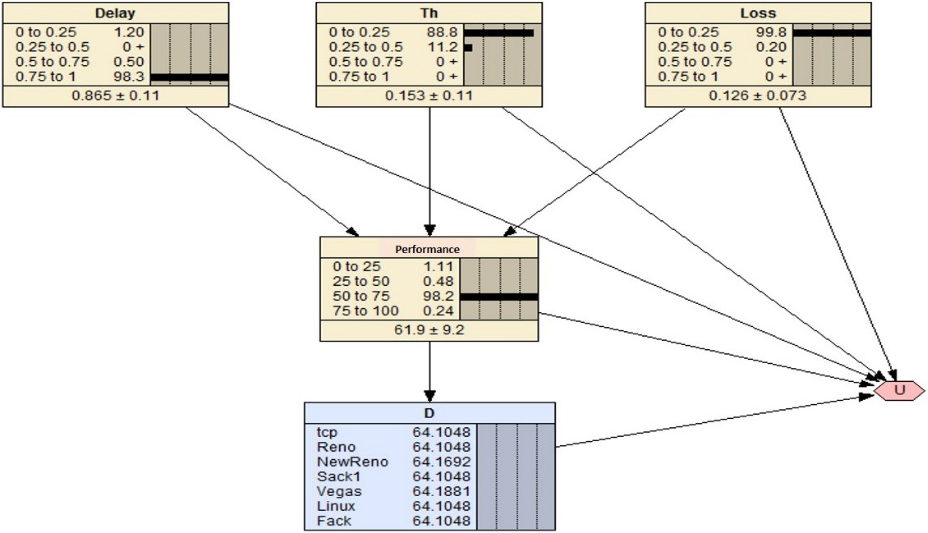
Utility table at the end of the learning process.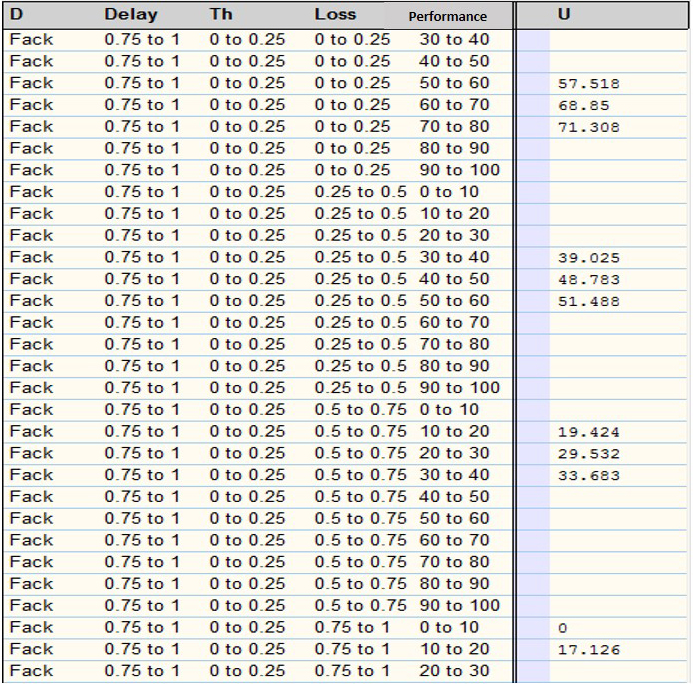
The Steps to create the nodes of operations “owl: intersectionO”, “owl: unionO”, “owl: complementO”, “owl: equivalent-clas”, “(owl: disjointWith)”, do not apply, because the ontology does not use these concepts. Once completed the transformation of the ontology (see Fig. 16), we define the tables CPTs. To build the initial CPTs, we follow the next Steps:
Step 1: According to the method of processing of BayesOWL, CPTs can be built from experimental data or ontological restrictions. In this case was calculated from experimental data. Step 2: Multiple experimental simulations are performed. Step 3: After obtaining the experimental data, they are used to calculate the CPTs through the EM learning method. To apply this method, the variables are initialized with random values. In the Fig. 16, we see the initialization of the conditional probability for the performance (Node: rend) variable with respect to different ranges of values of the throughput, error rate and latency variables (the number in each column represents the initial value of this probability in %, for a given number of simulations to be executed). Step 4: The experimental data were used as the current parameters
Now, the Bayesian Network must be transformed into a diagram of influence, in order to use the criterion of MUE, and thus facilitate the decision making in the system. In this paper, the idea is that the system decides what type of reconfiguration must be executed to maximize the performance of the communication. In the node of decision must be placed the alternatives of change that are presented. This process begins with the ontology of the Fig. 15, and adds the nodes of decision, as is shown in Fig. 18. In our case, there is a single node of decision, in this node of decision will be coded all possible changes that can be made according to the context in which it is going to use.
Once decision nodes are created, we proceed to create the utility function (table of utility). This table is displayed as a node (node of utility) with dependence with all nodes with which that table of utility has a relationship (see Fig. 19).
Learning process
With the diagram of influence obtained (Fig. 19), it is necessary to characterize the node of utility with the experimental data obtained from multiple simulations for different values of parameters (delay, capacity of the channel, and rate of loss). Figure 20 shows the influence diagram used for the simulations of the communication system with NS2. Figure 20 shows that the values for the variables delay (Delay), Flow (Th), performance and rate of losses (Loss) are divided into four ranges of values, this is due to the type of dispersion of the experimental data, which was not easily describable with less ranges. These ranges are assigned by means of a frequency distribution. This distribution of frequency depends on the simulations, and may change.
The table of utility has the following characteristics: it is defined by the node of utility
The initial learning process was conducted using the EM technique on the Bayesian network; after this initial learning, the system continues the learning process using the counting-learning method. This second learning process is carried out after each decision of reconfiguration. This process reinforces the Bayesian network, so that the decisions that increase the performance of the system also will help to improve the system of decision. This process consists in update the Bayesian network and the table of utility, so that the system can improve its performance.
In Fig. 21, we can see the table of utility after the process of learning. The utility is calculated using the Eq. (14), using the observed data in the system of the delay, flow (Th), loss variables, and in particular, the performance, which also depends on all of the above. The decision-making model seeks to optimize the maximum expected utility in the performance:
While the system learns in the initial stage, it does not take any decision. At the end of this stage, the system takes decisions on the basis of the table of utility, choosing the greatest possible utility in the table for a given input.
To verify the behavior of the decision system built from the ontology proposal, we use the NS2 simulation tool [20]. In addition to the NS2 simulator, we use APIs for networks of beliefs (Bayesian networks) and influence diagrams of the company NORSYS (in particular, the software netica) [19], to implement the decision system of our autonomic communication system.
Design of the experimental protocol
We have implemented a script, called parametric (simulation script), which changes online the parameters of the simulation in NS2, depending on the decisions taken by our decision system. The decision system uses as input, the analysis of traces of the simulation. Once obtained the traces of the simulation, are analyzed by using a script that determines the results of the Simulation: flow rate, rate of loss and delay. With these variables, the decision system determines the reconfigurations in the simulation to improve the communication performance. Then, the simulator runs again with the new reconfiguration.
Example of the results of a simulation
Example of the results of a simulation
Results of the simulations for different scenarios
Performance with and without autonomic system.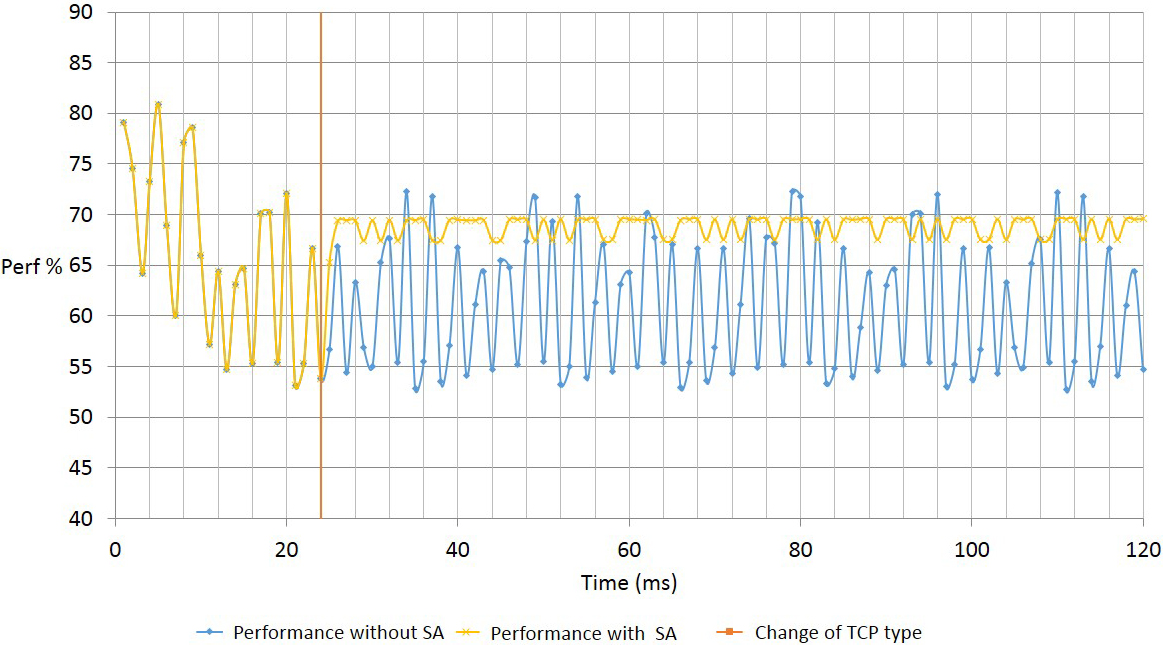
Throughput with and without autonomic system.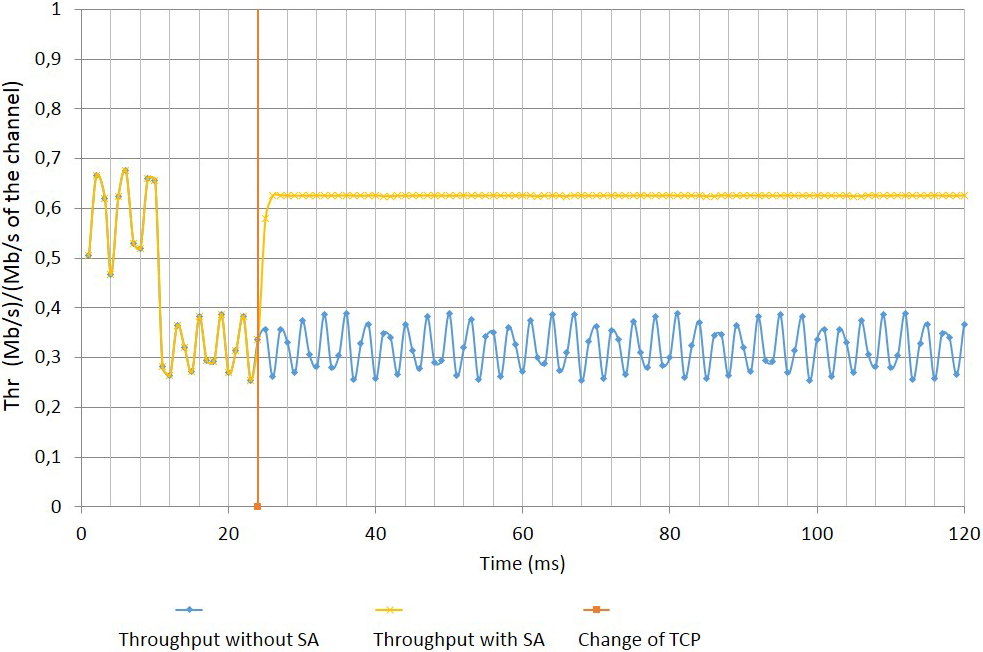
To calculate the flow rate, the rate of losses and the delay, we use a script that takes into consideration the amount of packets that are received successfully, that are sent, which are discarded, and the time in which they were sent and received. With these three parameters we use the following equation, based on a proposal in [26], inspired by the parameters of an ideal communication, to calculate the performance.
These variables have been defined in [26] as nominal values between 0 and 1, to indicate that a value of 100% of performance (1) means that the communication is ideal. The DelayR is the relative delay, normalized linearly with a theoretical delay (Rt), following the proposed in [26]. The FlowN is the Normalized Flow to the maximum that can be obtained in the simulation due to the minimum bandwidth on the path, which represents the maximum flow rate that can reach the desired communication. Tloss is the loss rate, is the ratio between the number of packets lost and the total number of packets sent.
The sub-system for the calculation of performance invokes the diagram of influence when it determines that a decision must be made, which is when there is a degradation in performance.
Due to the limitations in the form as is built the NS2 simulator, cannot be modified the parameters in real time. For this reason, in our experimental platform the decision system takes the decision to reconfigure offline. In addition, therefore, also it is launched a new simulation with the new configuration caused by the decision of our system, and it is compared with the initial simulation. In this way, we can determine if the decision taken by the decision system increase the performance. An example of comparison, for a scenario with a rate of loss of 25%, of the simulation with and without changes, can be seen in Table 1. In general, the performance and throughput averages of our approach are lower, once our decision system proposes changes; it decides to change at the time 24,001147 ms from TCP/Linux to TCP/Sack1. The graphics about the performance and throughput for the simulation of the Table 1, may be observed in the Figs 22 and 23, respectively.
In Fig. 22, we can see the result of two simulations: the first is the performance without autonomic system (SA), and the second is the performance with SA, when SA took the decision to reconfigure at the time 24.001147 ms (changes TCP/Linux to TCP/Sack1). We see an increase in the performance average of 38.26% to 43.92%. With respect to Fig. 23, the throughput is observed with and without SA, for the same simulation of Fig. 22. There, clearly shows that after 24 ms is better the throughput of the SA.
Experimental protocol
In this section, we define different scenarios. The scenarios used are:
Scenario with a variation of the packet loss: In this scenario will vary the rates of loss during the simulation.
Scenario with a variation of the Bandwidth: In this scenario will vary the bandwidth of the channel during the simulation.
Scenario with a variation of the delay: In this scenario will vary the delay during the simulation.
Scenario with a variation of the congestion: In this scenario will vary the type and rate of transmission of the packets during the simulation.
Improvements according to the Type of diagram of influence
Diagram of influences.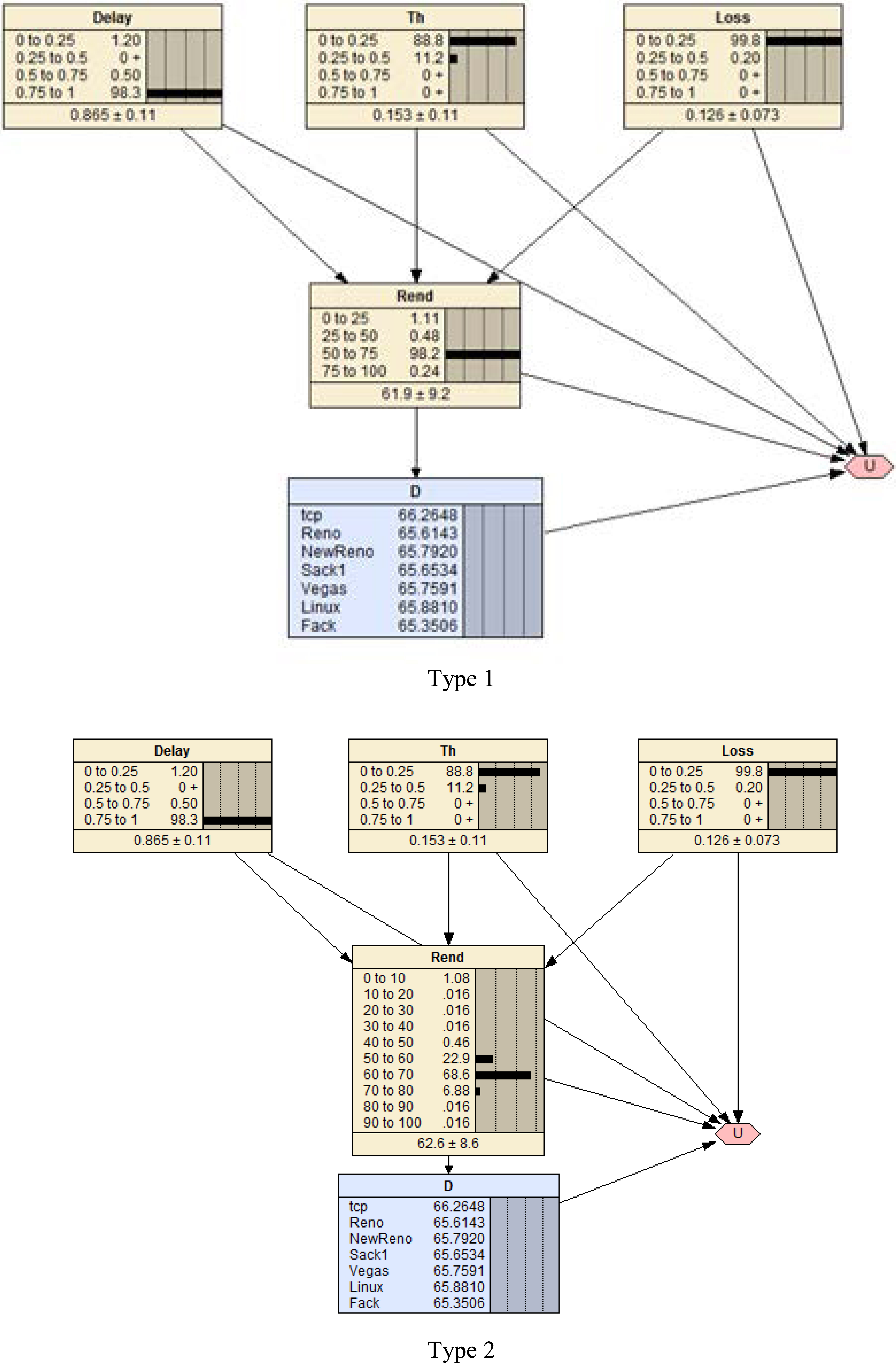
In each scenario, we have used an exponential distribution for the variation of each variable. Additionally, we define two influence diagrams, they differ in the number of ranges used to describe the performance variable (see Fig. 24). The main reason of these influence diagrams is to test if the number of performance states in the system can distinguish a greater number of situations, in order to take better actions.
Utility results due to the l
Comparison between different works
Scenario with different loss rates.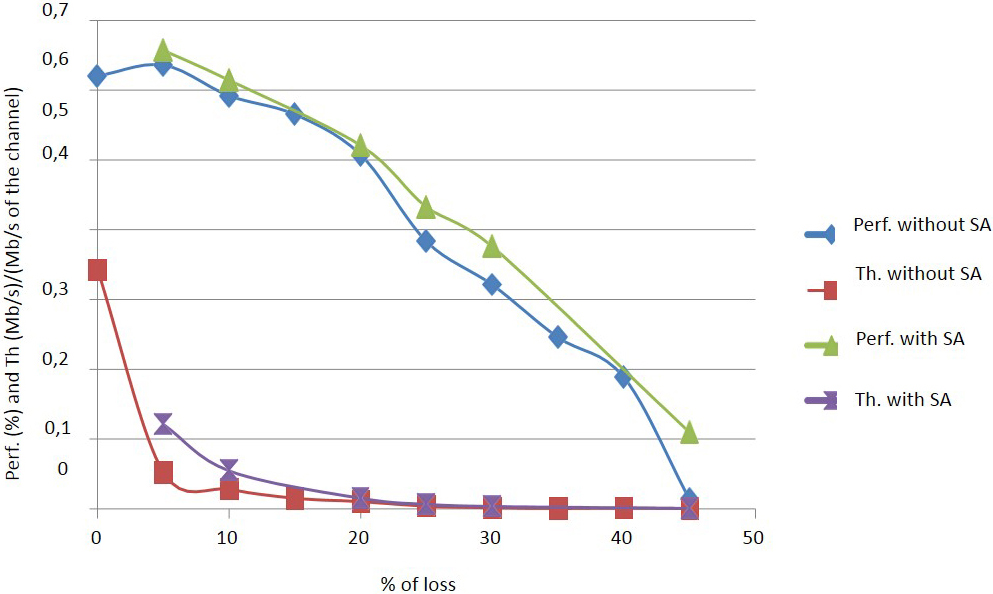
In each scenario, the system takes the decision based on the variable that is varying. The results are shown in Table 2. In the case of the diagram of influences Type 1, our autonomic system makes changes in the 55.3% of the cases. For these cases, the performance improved in the 92.3% of these cases, and the flow rate in the 84.6% of these cases. For the simulations with the diagram of influence Type 2, our autonomic system makes changes in the 51% of the cases. In the 95.8% of the cases where our autonomic system makes changes, the rate of flow and performance are increased. Our autonomic system always improves the results for the case of variation of the bandwidth and delays. In few cases, the changes of our autonomic system don’t improve the performance and flow rate. Sometimes, the system does not take decisions due to the current conditions of the communication system, which the autonomic system considers is ok.
Finally, Table 3 shows the average of the improvements in the two Types of influence diagrams. The average of improvement in performance is 1.95%, and in flow rate is 66.35%, for Type 2, which is better that for Type 1.
In general, the results of the diagram of influence Type 2 are better because the decision system has different levels of performance to characterize the context. That is, a larger number of states are effective, but the table of utility grows significantly (for this example, from 1792 to 4480 entries). Our autonomic system improves the communication due to the influence diagrams, which characterize the different communication protocols based on their performance characteristics (rate of loss, delay, etc.). In this way, our autonomic system takes decisions that improve effectively the communication.
Now, we carry out simulations in the scenario where is changed the rate of packet loss only for the influence diagram Type 2, using the autonomic system and without it. Figure 25 shows the results. The Fig. 25 in the Y axis shows two variables, performance (perf) and traffic flow (th), to compare our proposal (SA) with the fact of not using it for the management of the communication system. In addition, in the case of our proposal, we begin to show its results after the rate of loss begins to change, since at the beginning when there are not changes in it, it is not interesting its utilization (SA must not carry out any adaptation in the communication system). The curve of “with SA” is above to the curve of “without SA”. Due to the changes proposed by our system, the flow and the performance are improved considerably. The ability of the system to carry out several changes dynamically, demonstrates its flexibility.
A sample of the quality of learning on the utility (
Comparison
In this section, we compare our autonomous communications system with previous works. We carry out a qualitative comparison, based on the proposed design reported in the literature for each one of these works. The criteria were if they use a knowledge base for the decision making, if they have the ability to predict the future state of the communication system, how to evaluate its quality, which are the adaptive mechanisms and actions perform in the communication system, and if they propose an autonomic model (based on the MAPE paradigm) for the self-management [28]. Particularly, the MAPE paradigm establishes that all autonomic system has a closes loop composed by the next set of tasks: to monitor and to analysis the current situation in the system, to plan the next set of actions in the system according to the conclusions in the previous tasks, and finally, to execute these actions on the system [28]. In Table 5, we define this set of attributes, which are interesting for designing autonomic systems.
Our approach accomplishes all of them. In the case of [26], it does not present learning and MAPE mechanisms. In the case of [20], they have not MAPE mechanism, and the metrics used are very limited (we use an ontology that can be extended), and should be improved so that its decision-making process more efficient.
Conclusions and recommendations
We have proposed an autonomic communication system based on Bayesian Networks and ontologies, which is inspired by the DAISY architecture. The ontology defines the different standard used currently, which serves as basis for building the Bayesian network, which is the essential part of the decision-making system. The performance of our SA is satisfactory, improving the communication in general. We have tested the capabilities of the system in multiple scenarios, demonstrating its capabilities of adaptation and learning. The system developed has, among others, the capacity for self-optimization, which is mainly reflected in the learning process that is performed in the Bayesian network and the table of utility. Both components are modified according to the experience of the SA.
Our approach offers several improvements over previous works [26, 20]: all the parameters needed to analyze the current situation in the communication system (flow rate, loss rate, delay) can be determined by observing the communication from the emitter. Additionally, the system proposes an adaptive process of decision-making (Bayesian Network). Finally, the system is based on an ontology, which contains the basic standards used in this domain, by giving great conceptual robustness at the same. Another advantage of our system is the low computational cost, since none of the algorithms used has a computational cost greater than a linear function, which contributes positively in its future implementation.
Future works will carry out an exhaustive analysis of our SA approach for multi-variation cases, in different contexts of communication networks, such as wireless personal communication networks, local area networks, wide area networks, satellite networks and metropolitan area networks. Additionally, our SA approach will be extended with the concept of autonomic cycle of data analytical tasks [4], in order to include specific analysis tasks in our system linked to improving the quality of services, among other aspects, using the data.
Footnotes
Acknowledgments
Dr Aguilar has been partially supported by the Prometeo Project of the Ministry of Higher Education, Science, Technology and Innovation of the Republic of Ecuador.