
Abstract
Targeted style transfer is the visual computing and deep learning problem where the input and target image sets are used to train the network by learning the mapping between those for conversion of the input image to the style of the target image. One of the popular methods for this task is Cycle-GANs (Cycle Consistent Generative Adversarial Networks), with Mean Squared Error, Binary Cross Entropy Error, and L1 loss functions. In this paper, our network is trained for image-to-image translation where the style or content of the Target image is changed by the network by modifying loss functions of Cycle GANs. Most accurate translation could be trained to the network through the use of paired images i.e. Supervised Learning where the input image and output images are known and thus, the network learns to minimize the gap between the expected output and observed output. However, this kind of paired data is not readily available and is strenuous to mass produce. Cycle GANs uses unpaired data, and our work is dedicated to finding the best possible loss function combination for making it even more efficient.
In Cycle GANs, there is a combination of 2 networks: Discriminators and Generators for each data set, which compete against each other to out-perform the other. Discriminator network uses Classification loss functions for distinguishing the images for the 2 datasets, while the Generator network uses Regression loss functions for determining Cycle loss and Identity loss. These loss functions play a vital role in the style transfer as they determine how much the images have been modified. We have worked on various loss functions like Mean Square Error loss, Binary Cross Entropy Error loss, Hinge loss, Huber loss, Log loss, Square loss and L1 loss for experimentation for the best losses combination to be used. We discuss the strengths and limitations of the loss functions already used and propose different combinations of loss functions for better accuracy. A separate classifier was trained extensively for performance evaluation purpose, which gives the most optimal combination of loss functions which is Binary Cross Entropy loss for Classification loss function and Huber loss for Regression loss function.
Keywords
An overview of system design.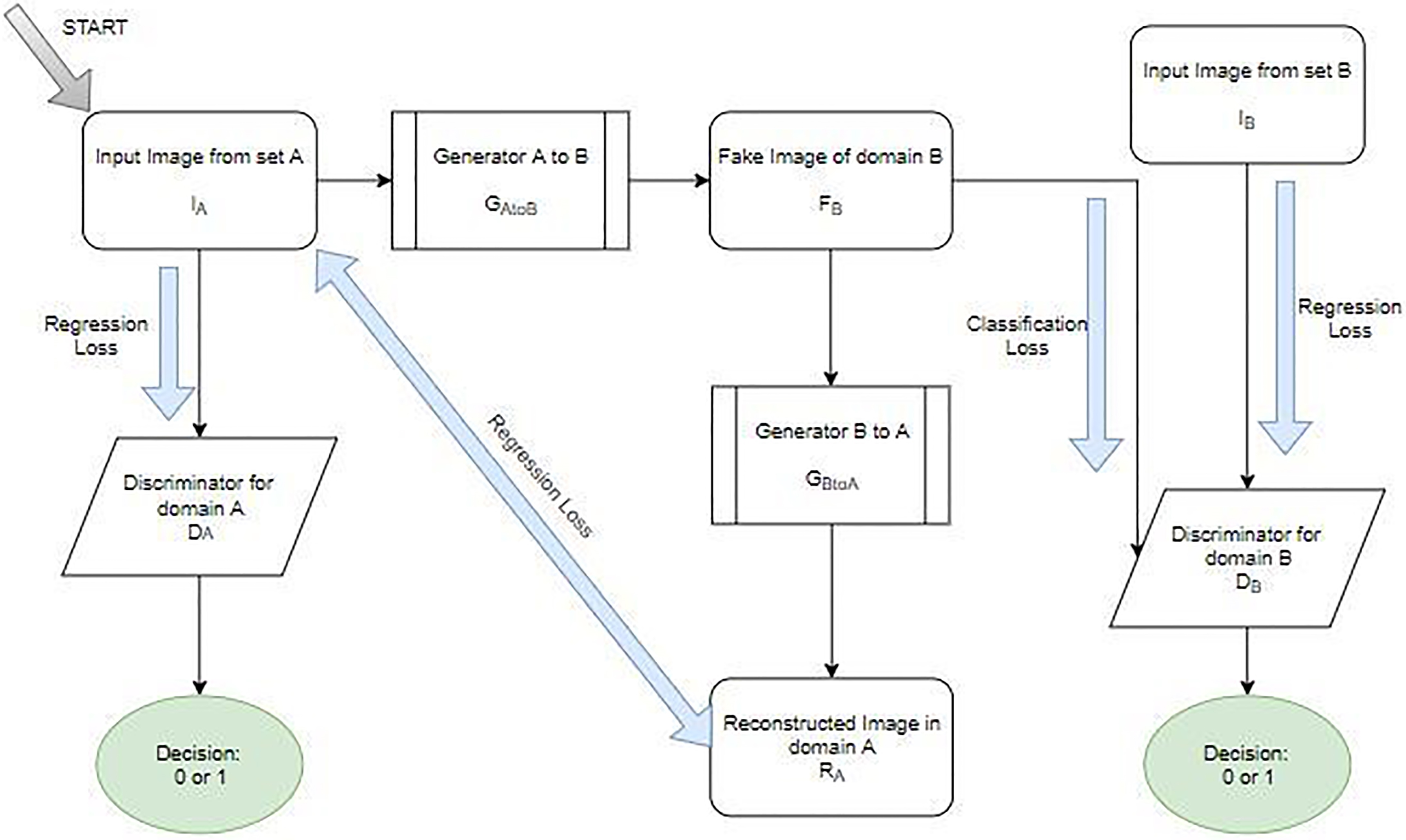
In the recent years, our day to day life deals with images on a grand scale. It’s not possible to manually generate or even modify all the required images, thus we need computer vision and its applications like image-to-image translation. Targeted style transfer is really beneficial for applications like visualization on different features in different backgrounds, for example: trying varying spectacles, hairstyles or clothes on humans, several flooring or furniture options for rooms, and movie editing. It can also be used for conjuring the older version of a face in an image or similarly, learning how a face might have looked like when it was younger. Simple doodles can be made into solid objects, as well as the network can be trained to convert different animals into one another.
This task was initially object identification and transformation [8], which was solved by just Convolutional Neural Networks, the most powerful class of Deep Learning for image processing. CNNs consist of small computational units which hierarchically process the feature information in the image. These layers can be represented as different filters, working their way up from low (points, edges) to higher (object outlines) amount of information. The style of an image and its content are separable entities, which the network learns through sets of input images, whose content has to be reproduced and sets of target images, whose style has to be produced into the output image.
Targeted style transfer requires only a part of the image to be altered, without changing its background information. For example, in the popular game Pokémon Go or in the Son of Zorn series, there are cartoons in real-world backgrounds. This work [2] is especially useful in augmented reality applications.
This image-to-image translation task is easier when there are paired datasets for the network to be trained from. However, creating paired training data is cumbersome and there are not a lot of repositories supplying the same. So, this challenge was overcome through Cycle GANs work [7], in which the approach deals with unaligned training data from a source domain to a target domain. The goal is to convert the images in source domain into target domain using an adversarial loss such that the converted image domain and target image domain are identical. Also, the inverse mapping of the converted image back to source domain is constrained through Cycle Consistency loss.
As a summary of our method, the Adversarial Networks framework is explained, in which there are 2 functions: Discriminators (D) and Generators (G). The Generators produce the fake images from one domain to the other while the Discriminators distinguish between the real or fake images for that domain. There are 3 losses in the networks: GAN loss used by Discriminator for Generated images, Cycle Consistency loss used for A to B to A converted images and identity loss used by discriminator for its own domain images.
Generator neural network architecture.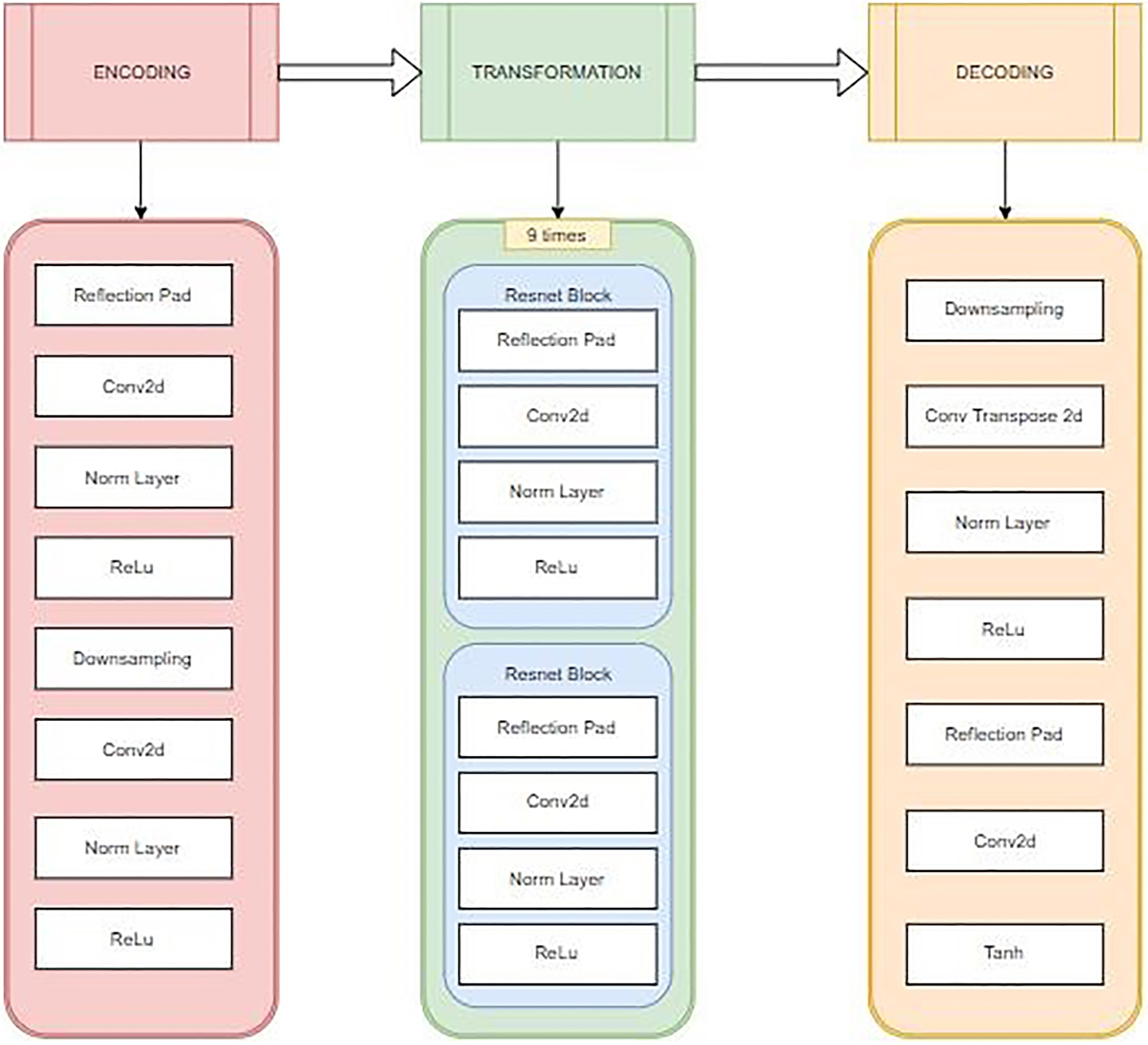
Advantages of the Cycle GANs are that they use unpaired datasets as a form of unsupervised learning to perform better and are more versatile than the previous methods. Our motivation for this particular work was that we wanted to make this method even more efficient. There are many loss functions; some are widely used while others are little known of. But there was a chance that some combination of loss functions might perform better than used techniques. Hence, we tried all the possible combinations with the appropriate loss functions that we thought would work. This led to the experimentation at the basic level of these neural networks.
In this work, we have experimented on various combinations for these losses. The losses [15, 1, 9] we have used are Binary cross entropy error loss, Huber loss, L1 loss, Mean Squared error loss, Hinge loss, Log loss and Square loss. Using a separate classifier trained on these datasets, we have then calculated the accuracy and cross entropy [10] for each of the combinations and discussed the conclusion.
The rest of the paper is organized as follows: Section 2 presents proposed system design. Section 3 demonstrates the experimental results of proposed system. Finally, the results of the experimentation are conveyed through concluding and future works are discussed.
The proposed system objective is to learn mapping function between the two domains
As can be observed from Fig. 1, when an image (
The fake image produced,
In Fig. 2, Generator neural network architecture is explained. This network contains two stride-2 convolutions, several residual blocks, and two fractionally strided convolutions with stride 1/2. Instance normalization is used instead of Batch normalization. The convolutional layers used are Conv2d, Norm Layer (Normalization), ReLu (Rectified Linear Unit) and Tanh Layer (for maintaining output from
In Fig. 3, the Discriminator neural network architecture is displayed. For this network, 70
From the Fig. 1 observed that the a loss function is a function that maps values or an event of one or more variables onto a real number intuitively representing the “cost” corresponding with the event. loss function is an important part in artificial neural networks, which is used to measure the inconsistency between predicted value (
Discriminator neural network architecture.
An optimization problem seeks to minimize a loss function.Generative Adversarial Networks pose a challenging optimization problem due to the multiple loss functions which must be optimized simultaneously. There are 2 major types of losses incorporated in this system
Regression loss Classification loss
In this work, we have dealt with the various types of loss functions and compared these to find out which of the combinations used is the best.
Absolute loss
Absolute loss function minimizes the absolute differences between the existing target values and the estimated values. It can be defined in the Eq. (1)
where
Mean Squared Error (MSE), or quadratic, loss function is widely used in linear regression as the performance measure, and the method of minimizing MSE is called Ordinary Least Squares (OSL), the basic principle of OSL is that the optimized fitting line should be a line which minimizes the sum of distance of each point to the regression line, i.e., minimizes the quadratic sum. The standard form of MSE loss function is defined in Eq. (2)
where (
In statistics, the Huber loss is a loss function used in robust regression that is less sensitive to outliers in data than the squared error loss.
where
GAN loss is the mapping function. It is used to map the
where
Binary cross entropy error loss
The cross entropy loss is ubiquitous in modern deep neural networks. This function is not naturally represented as a product of the true label and the predicted value, but is convex and can be minimized using stochastic gradient descent methods. Cross-entropy loss increases as the predicted probability diverges from the actual label. It can be defined in Eq. (6)
where
The hinge loss provides a relatively tight, convex upper bound on the 0–1 indicator function. However, for the purpose of labelling the output in the range of
where
The Logistic loss function does not assign zero penalty to any points. Instead, functions that correctly classify points with high confidence (i.e., with high values of
where
While more commonly used in regression, the square loss function can be re-written and utilized for classification. The square loss function is both convex and smooth and matches the 0–1 indicator function when
where
Cycle consistency loss is used to produce outputs identically distributed as target domain and it is defined in Eq. (10)
where
Dataset
To evaluate the performance of the proposed method the images collected from ImageNet database is used. The keywords searched in the ImageNet database for these datasets are wild horse and zebra [16]. The database contains 2 classes of 1973 images. The dimensions of the image are 256
Implementation
Network details
In this paper, we have used the architecture from Johnson et al. [6], which is contains two stride-2 convolutions, several residual blocks, and two fractionally strided convolutions with stride 1/2. For discriminator network, 70
Training details
The training set size of each class was horse (domain A): 500 images, zebra (domain B): 500 images and test size for evaluation was 973 images.
In our research, we worked on (5
Performance evaluation measures
Accuracy, cross entropy metrics [5, 11, 12] are used for performance evaluation. TP, TN, FP and FN indicate True Positives, True Negatives, False Positives and False Negatives respectively. Accuracy is the best measure for classification problem [3, 4]. It is given in Eq. (11).
Cross entropy calculates a network performance given targets and outputs, with optional performance weights and other parameters. The function returns a result that heavily penalizes outputs that are extremely inaccurate (
In special case (
Cross entropy is similar to Negative Log loss Likely-hood function.
The experimental results of the proposed targeted style transfer method is presented in this section. The experimental results are presented in two stages. In the first stage the training and test results are shown and in the second stage the results of the targeted style transfer method models are compared and the best one is chosen.
The sample real images, fake images, reconstructed images and identity images from various experiments.
The sample result of the proposed method with different loss functions.
For performance evaluation, a separate classifier: TensorFlow for Poets was trained over an extensive test set and accuracy of 97% was achieved. This classifier is used on the trained models of loss combinations, classifying the fake images produced and providing the relative accuracy and cross entropy for all of the models. All the combinations of loss functions models have been trained through sets of 500 images for both domains A and B. Each model was trained for 100 epochs, and then tested.
The models are trained and observed between the checkpoints of the iterations for which model performs better in minimum iterations which can be visualized. Then the model is tested on 973 images. For domains A and B, datasets of horses and zebras have been selected from [7]’s implementation.
These implementations can be compared to the system architecture, regarding which images are produced. Real_A, Fake_B, Rec_A, Real_B, Fake_A, Rec_B, Idt_A and Idt_B are the images associated in the system. The Real A and B images belong to the original images in domain A and B. Fake A and B are the translated images in the opposite domains. The fake images are then inserted into Discriminator for correct classification. Rec A and B are the reconstructed images from fake images back to original domains for checking the each classification losses. Idt A and B are the Identity images i.e. the images from the same domain, inserted into the discriminator for checking the Identity loss. The sample results of the real (input) images, generated (fake) images, the reconstructed images and identity images from various experiments is shown in Fig. 4.
Figure 5 displays the sample results of the proposed method with the various combination of the regression losses and classification losses. From the Fig. 5, it is observed that the Binary Cross Entropy loss is the best among all of the classification losses and Huber loss is the best among all of the regression losses.
Comparison of different loss function results
To evaluate the performance of the proposed method quantitatively accuracy and cross entropy measures are used. The performance comparison of proposed method with different loss functions using accuracy values is shown in Table 1. The value of the Binary Cross Entropy loss and Huber loss combination provided the better accuracy than the other loss functions combination. Similarly, the comparison of the proposed method with the different loss functions using cross entropy values is shown in Table 2. From Table 2, it can be noted that the value of the Binary Cross Entropy loss and Huber loss combination is lower than the other loss functions combination. It indicates that the Binary Cross Entropy loss and Huber loss combination are superior to the other combination loss functions.
Comparison of proposed method with the different loss functions using accuracy values
Comparison of proposed method with the different loss functions using accuracy values
Comparison of proposed method with the different loss functions using cross entropy values
In this paper, a new method for targeted style transfer using Cycle-GANs with different loss functions is proposed. The results can be visualized properly through the Fig. 5 and Tables 1 and 2. If the accuracy is high, then it means that the model has performed better. The accuracies are in the range of 0 to 1. Also, the cross entropy values being lower are supposed to be better for the model. The ideal value is 0, and if the calculated probability is further than the expected probability, then the cross entropy value increases. From the results, it is perceived that the Binary Cross Entropy loss is the best among all of the classification losses and Huber loss is better than each of the regression losses with 0.886 accuracy and 0.349 cross entropy value.
In future work, our endeavor to make this system even more efficient. For this at present working on replacing the CNNs used-ResNets (state-of-the-art) to more recent Deep learning frameworks being researched like Capsule networks. Also, the ideas for generating better activation functions are also being assessed for the future works.