
Abstract
With the popularity of code search, it is an important problem how to make the retrieved source code change automatically based on the user needs. However, none of the existing code transformation methods could solve this problem. They either fix compile bugs or depend on the formal specifications which lack the practicality. In this paper, we propose a novel generative transformation based on code change: we generate the abstract change script from code changes and apply the script to transform the retrieved source code. To evaluate our method, we extract 7 topics and collect 5–6 code snippets per topic from Github, and perform 5 different experiments in which we even explore 2 sensitivity-related rules and use the rules for raising the accuracy gradually. The experimental results show that our method is feasible and practical with 73.84% accuracy.
Introduction
For the efficiency of program development, code reuse is important. It consists of code search and code transformation. The former comprise of the keyword-based [1], the signature-based [2], the specification-based [3] and the test case-based [4] searches. With more and more open source code available on the Internet [5, 6, 7, 8], many good code search methods are proposed, such as Satsy [9], Code Conjurer [8, 10], Strathcona [6] or Prospector [11]. However, users always manually change the source code which they retrieved by using the code search tools, because the retrieved source code cannot meet the user needs directly. Therefore, a meaningful problem to solve is how to make the retrieved source code changed automatically.
To solve the problem, we should have adopted the existing code transformation methods [12] but neither the compilation transformation nor the generative transformation works. The former (e.g., GenProg [13], Par [14] or BugModify [15]) is not suitable for solving the problem since it is just used for fixing compile bugs. By contrast, the latter seems to be suitable since it is always used for generating the new source code from the candidate source code based on the user needs. Unfortunately, the latter always makes source code conform to the user needs by using formal specifications. For example, Gopinath et al. [16] build a SAT formula that encodes the constraints imposed by the specification. If the SAT formula is satisfiable, the new source code could be derived from it. However, the formal specification is difficult to build, which limits the practicality in reality.
Fortunately, we observed an interesting phenomenon as shown in Fig. 1. We downloaded 3 pieces of source code from Github:
Similar changes to three pieces of source code.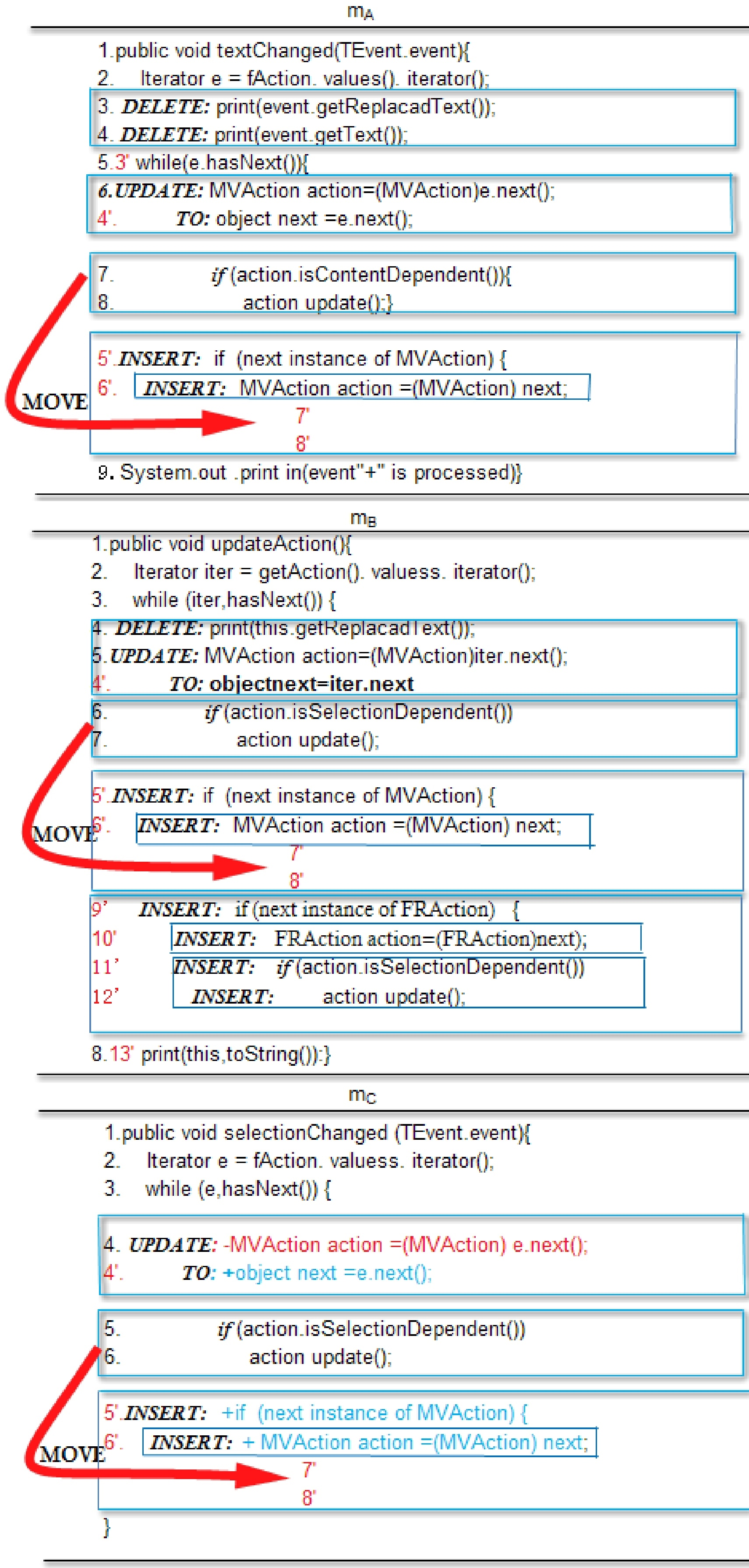
AST comparison between 
Suppose that Smith retrieved
Although
Inspired by the above hypothesis, we propose a generative transformation based on code changes. The method is based on the underlying idea: the common code changes that most users made could reflect their needs in some degree. The method contains the abstracting and the concretizing algorithms. The former identifies the similar changes from code changes and generates the abstract change script. The latter applies the script to transform the source code automatically.
To evaluate our method, we extract 7 topics and collect 5–6 code snippets per topic from the GitHub.1 Then we perform 5 different experiments, in which we explore 2 sensitivity-related rules and use the rules to raise accuracy gradually. All encouraging results indicate that our method is effective.
Main contributions are as follows:
As a new generative transformation, we transform the source code by using the abstract change script instead of the formal specifications. We propose the abstracting algorithm to generate the abstract change script, as well as the concretizing algorithm to transform the source code automatically by using the script.
We focus on the code changes collected from Github and propose the abstracting and the concretizing algorithms.
Abstracting algorithm
Algorithm 1 describes six steps about how to generate the abstract change script.
Step 1: Obtain changes
Let
Insert (node
Delete (node
Update (node
Move (node
Let
Figure 1 shows the original piece of source code
In this step, we obtain the code changes (
Step 2: Identify common changes
We identify the common changes
For the pieces of source code
i.e., {updates (
Step 3: Generalize abstract changes
After comparing the node operations in
For the pieces of source code
Step 4: Extract changes-relevant context
Let
Formally, the node
DataDepend (node
ControlDepend (node
ContainDepend (node
We extract the changes-relevant context
As shown in Fig. 2-
Step 5: Generalize abstract contexts
By using the LCEOS algorithm [17], we also identify the common contexts
For the pieces of source code
Analysis of the poor or good results.
We merge all common contexts
1. public void method declaration (…)
2. Iterator
3. While(
4. MVAction action
5. If (action.
6. Action.update()
Update
Move
Move
Insert
Insert
We think of
Concretizing algorithm
By using the abstract change script, the source code could be changed automatically. Algorithm 3 describes this process: produce mapping, customize the concrete changes and replicate the changes.
Step 1: Produce nodes/identifiers mapper
For the source code m and the abstract context
For the piece of source code
Step 2: Customize concrete change script
We replace all abstract identifiers in the abstract changes
For the piece of source code
Update
Move
Move
Insert
Insert
Setp 3: change source code
By using
For the piece of source code
Experiments
To evaluate our method, we (i) used a web spider to grab and organize code snippets from GitHub by topic, (ii) extracted 7 topics and collect 5–6 code snippets from each topic, (iii) and saved them as the testing set:
We used the accuracy as the metric that is the syntactic similarity between the output given by our method and the expected output. For each source code pair (
Accuracy of the five experimental results
We conducted 5 different experiments with this testing set: we (i) analyzed the reasons for decreasing accuracy, (ii) explored 2 sensitivity-related rules and (iii) used the rules to improve the accuracy gradually. The Table 1 lists the accuracy of the five experimental results, where “topic” represents 7 different topics, “num” represents the number of code snippets for generating the change pattern per topic, “A–E” represent the results of the five experiments respectively. For example, Table 1-A represents the accuracy results of experiment-A.
Experiment-A: We collected 7 topics, each topic had many different code snippets replied by users. From the code changes of these code snippets, we generated the abstract change script about this topic. Then we applied the script to transform other code snippets in the same topic. We used the accuracy for evaluating whether or not our method was effective.
Table 1-A showed the poor results with
We depicted the poor results (
We depicted the promising results (
In sum, if code snippets are different,
Effect of the representative code snippet
To improve the above poor results (
In experiment-A, let
Effect of the stable change pattern
In Table 1-B, the accuracy of
To improve it, we changed the experiment-B to the experiment-C. In experiment-C, let
To evaluate whether or not
Effect of the first modification
In Table 1-C, the accuracy of
To evaluate whether or not
Effect of the similar changes
To explore how sensitive our method is to the similarity of
Before and after heuristic strategy.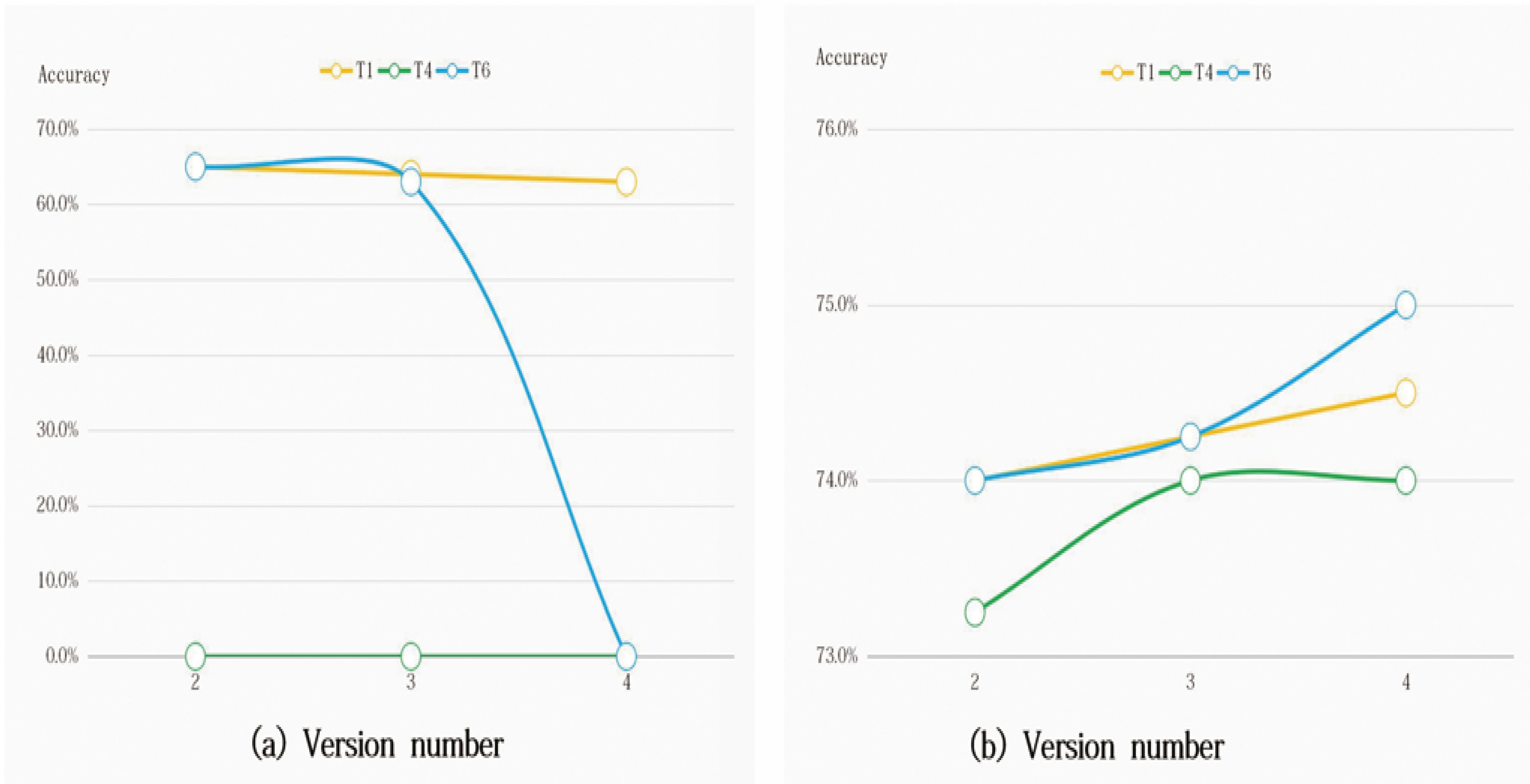
To avoid ill-effects of
We conducted the experiment-E with the default setting of 2 for
Besides in Table 1-E, we (i) depicted the results of
In this paper, we proposed the generative transformation based on code change. Instead of the formal specification, this method transforms the retrieved source code by using abstract change script. Through a series of experiments, we not only summarize the best practice for our method, but also confirm that it could assist users to reuse the source code on the Internet with 73.84% accuracy.
However, there are still the threats to validity. The first is human subjects. The limited number and the programming capabilities of the human subjects may bias the results. In the future, we plan to conduct more experiments and user studies. The second is a tiny sample of the available testing set with 7 topics and 5–6 pieces of source code per topic. In the future, we plan to investigate more queries over a much larger codebase.
Footnotes
Acknowledgments
This work was supported by the Key Scientific Research Projects of Henan Province High Talent Scientific Research Project no. 15A520022.