
Abstract
In Microarray Data, it is complicated to achieve more classification accuracy due to the presence of high dimensions, irrelevant and noisy data. And also It had more gene expression data and fewer samples. To increase the classification accuracy and the processing speed of the model, an optimal number of features need to extract, this can be achieved by applying the feature selection method. In this paper, we propose a hybrid ensemble feature selection method. The proposed method has two phases, filter and wrapper phase in filter phase ensemble technique is used for aggregating the feature ranks of the Relief, minimum redundancy Maximum Relevance (mRMR), and Feature Correlation (FC) filter feature selection methods. This paper uses the Fuzzy Gaussian membership function ordering for aggregating the ranks. In wrapper phase, Improved Binary Particle Swarm Optimization (IBPSO) is used for selecting the optimal features, and the RBF Kernel-based Support Vector Machine (SVM) classifier is used as an evaluator. The performance of the proposed model are compared with state of art feature selection methods using five benchmark datasets. For evaluation various performance metrics such as Accuracy, Recall, Precision, and F1-Score are used. Furthermore, the experimental results show that the performance of the proposed method outperforms the other feature selection methods.
Introduction
Microarray data with genes and gene expressions is one of the examples for High Dimensional Data. Analysis of expression of genes can provide valuable information to predict how certain diseases are formed and the countermeasures needed. DNA Microarray data contains data related to genes, gene annotations, gene expression level, observations, and observation annotations. To work with such a dataset, it is essential to have feature selection. If feature selection is not employed, the classification of genes may not yield accurate results in sub-optimal performance. Feature selection is necessary to improve the accuracy of any classification algorithm. By removal of irrelevant and redundant features, it also enhance the quality of input data for processing.
Feature selection methods are broadly classified into three types: Filter, Wrapper, and Embedded methods [34]. In the filter method, the feature subsets are selected using statistical methods before the learning model is applied. Whereas in the wrapper method [13] features are selected using the learning model as fitness function and feature subsets are selected by using search strategies. Finally, the embedded method [15] selects the features during the training phase itself and is specific for a learning model. In hybrid feature selection, it composes of two stages, in the first stage filter method is used to select the best features, and then as second stage wrapper method is applied for selecting the optimal feature selection. Some of the hybrid models includes Chi-square and GA [19], Multiple-Filter-Multiple-Wrapper (MFMW) [20], Mutual Information and PSO [33], Mutual Information (MI) and Recursive Feature Elimination (RFE) [35] and so on.
Many feature selection algorithms came into existence on microarray data such as [28, 16, 31] to mention few. Ding and Peng use the mRMR feature selection method for finding the optimal feature subsets for the microarray dataset [10]. Li et al. use a combination of GA (Genetic Algorithm) with kNN for the selection of feature subsets [21]. Wahde and Szallasi reviewed wrapper methods based on evolutionary algorithms; the selection of feature subsets is optimized using genetic operations [38]. Clustering-based feature selection is explored in [32]. A cuttlefish optimization approach is studied in [1]. Therefore, it is essential to have a more comprehensive approach for feature selection. In this paper, we proposed a hybrid feature selection method for Microarray data (high dimensional data). The proposed method uses ensemble approaches in the filter phase known as Relief, mRMR, and Feature correlation Filter methods besides IBPSO for optimization of features. In the wrapper phase, we use IBPSO instead of BPSO. Since BPSO has a drawback of getting stuck to local optima so to overcome this problem, IBPSO is used. So IBPSO overcomes the local optimum problem. Each particle uses two fitness values pBest and gBest. If the gBest value is trapped into local optimum, in IBPSO, the gBest value is reset to overcome being get trapped into local optimum [8]. By defining algorithms known as Ensemble Feature Selection (EFS) in the filter phase and Improved Binary Particle Swarm Optimization (IBPSO) in wrapper phase, the proposed method (EFS-IBPSO) achieves better performance when compared with the state-of-the-art feature selection methods. Our contributions in this paper are as follows.
A framework is proposed for performing feature selection for high dimensional data in a systematic way. For achieving better performance ensembling, three filter rank based feature selection methods are used, followed by IBPSO in the wrapper phase. To aggregate the ranks in the filter phase, the Fuzzy Gaussian method is proposed. Kernel SVM Classifier is used as an evaluator for the IBPSO in the wrapper phase. Experimental analysis of different dimensions of data is conducted to validate the EFS-IBPSO algorithm.
The remainder of the paper is structured as follows. Section 2 provides a review of literature pertaining to feature selection for microarray data (high dimensional data). Section 3 presents the proposed framework. Section 4 includes dataset details and result analysis. While section 5 provides conclusions and directions for future work.
This section provides a literature review on feature selection for microarray data (high dimensional data). Li et al. [22] uses linear support vector machines classifier to over the drawback of massive time consumption by SVM-RFE (Support Vector Machine based on Recursive Feature Elimination). Along with this re-sampling method to preprocessing the datasets for a balanced distribution of samples.
Wang et al. [39] proposed the BCO-MDP (Bacterial Colony Optimization with Multi-Dimensional Population) feature selection method to overcome the problem of local optimal. Generally, all population-based algorithms have the drawback of local optimal convergence to overcome this [39] uses the population with multiple dimensions and are represented by different subsets feature sizes. Ayyad et al. [2] proposed a new MKNN (Modified k-nearest neighbor) classification method for gene data. It has two scenarios LMKNN (largest modified KNN) and SMKNN (small modified KNN). It uses weighting strategies for employing neighbors.
Rani and Ramyachitra [29] uses the Spider Monkey Optimization (SMO) algorithm for the selection of optimal feature subset for Microarray gene datasets. The SVM classifier is used for classifying the cancer dataset using the optimal feature subsets selected by using the SMO optimization technique. The proposed methods have outperformed all existing techniques.
Mundra and Rajapakse [26] proposed a hybrid feature selection method by combing MRMR and support vector machine recursive feature elimination (SVM-RFE). MRMR feature selection method is used as a filter, and SVM-RFE is used as a wrapper method. First MRMR filter method is applied to the gene datasets, the best feature subset is selected. The feature chosen by the filter method is used as input for the wrapper method final feature subsets are selected using SVM-RFE.
El Akadi et al. [13] proposed a two-stage feature selection method by combining the mRMR filter method and the GA wrapper method. Candidate feature sets are selected in the first stage using MI-based mRMR, which filters irrelevant and redundant features, and also, the computational cost of the second stage is also reduced. These candidate features are applied as input for the second stage, and final optimal features are selected by using the GA wrapper method. SVM classifier for training the model.
Yuan et al. [41] uses partial maximum correlation information (PMCI) for Microarray data. For evaluating the importance of the feature, PCMI extracts several orthogonal components from the feature space. It uses the correlation between feature and class for extracting components. For evaluating the performance of the proposed method, it uses ten benchmark datasets over six already existing algorithms.
Bolón-Canedo et al. [5] proposed an ensemble of filters for feature selection. Five filter selection methods are used for selecting feature subsets. The feature subsets obtained from these five filter methods are forwarded to some specific classifiers. The output from these classifiers is ensemble by using the simple voting technique. Ten benchmark Microarray datasets are used for evaluating the performance of the proposed model.
Pashaei and Aydin [27] proposed Binary Black Hole Algorithm (BBHA) based on optimization problems. Existing methods have the drawback that they are computationally expensive and local optima. To overcome the local optima problem, BBHA uses an efficient global search. Eight benchmark datasets are used for evaluating the performance of the proposed methods. The performance is compared with Simulated Annealing (SA), Particle Swarm Optimization (PSO), Genetic Algorithm (GA).
Morovvat and Osareh [25] proposed an ensemble of filters and wrappers method for the Microarray dataset. The proposed method uses a set of filter and wrapper methods for selecting the feature subsets. First, a collection of filters is used to select candidate features, and these candidate features are used as inputs for the wrapper method to obtain optimal feature subsets. These optimal features are used by ensemble the performance of the classifiers J48, SMO (Sequential minimal optimization – SVM), and Naive Bayes classification methods.
Jain et al. [16] proposed a two-stage hybrid model for the classification of Microarray data. Correlation-based feature selection (CFS) and improved-Binary Particle Swarm Optimization (iBPSO) methods are integrated. Using iBPSO overcomes the drawback of the local optimum of traditional optimization algorithms. Eleven benchmark datasets are used for evaluating the performance of the proposed model. Naive Bayes classifier with 10-fold cross-validation is used for classification of the Microarray datasets.
Dash [9] proposed a bi-objective ranked based Pareto front technique by using two rank-based technique. The drawback with a single ranking technique is the same feature is ranked different ranks by different ranking methods. Due to this, there is the possibility of selecting irrelevant features and also may reject some of the relevant features. For ranking, the model grading method had been used.
Lu et al. [24] proposed a hybrid MIMAGA-feature selection method by combining the mutual information maximization (MIM) and adaptive genetic algorithm (AGA). By using MIMAGA – selection method, most of the redundant features are eliminated, and significantly reduced features are selected. To ensure the robustness of the MIMAGA method, Lu et al. use four classifications on reduced feature datasets for classification. MIM is used for finding the best dependency on all other features of the same class. AGA is used for finding the most suitable value for the crossover probability and the mutation probability values for finding the best optimal solutions.
Gao et al. [14] proposed a hybrid feature selection by combining Information Gain – Support Vector Machine (IG-SVM). IG is used for removing redundant and irrelevant features. For removing the noise in the dataset and further removal of redundant features, SVM is used.
Sharbaf et al. [31] proposed a hybrid feature selection method by combining the Fisher criterion as a filter method followed by a cellular learning automata (CLA) optimized with ant colony method (ACO) as wrapper approach. kNN, SVM, Naive Bayes classifiers are used for evaluating the selected features. CLA is used for solving the NP-complete problem during searching for feature subsets. ACO is used for selecting optimal features and also to overcome the local maxima problem.
From the literature, it is understood that hybrid feature selection approaches could provide better performance. In this paper, we proposed a hybrid feature selection approach for improving the accuracy of classification.
Proposed methodologies
In this section, we proposed a hybrid feature selection by combining the ensemble of filter feature selection methods and the IBPSO wrapper method for improving the performance of the classification model for microarray data.
Overview of the proposed framework.
When data has acquired a high dimension, it is difficult for machine learning algorithms to achieve high accuracy. The rationale behind this is that these data lead to the curse of the high-dimensionality problem, and that tends to either inefficiency of machine learning algorithms or even render them useless. From the literature, it is observed that the filter method alone can’t achieve the best feature subset because it doesn’t use any learning algorithm for subset selection. Whereas, in the case of the wrapper method, even though it uses a learning approach for feature subset selection, it has an NP-hard problem for subset selection. To overcome the problems of the filter and wrapper method, the hybrid feature selection method is proposed. Therefore, it is very challenging to have the best feature selection algorithms for high dimensional data analytics to enhance the performance of machine learning algorithms. This problem is to be addressed by defining a hybrid ensemble feature selection algorithm that produces a subset of features to meet an objective.
Overview of the proposed framework
This section provides a broad overview of the proposed hybrid ensemble feature selection method for selecting the optimal feature subsets. The proposed method has two phases, namely the filter phase followed by the wrapper phase. In the filter phase, three rank-based filter methods are aggregated by using a fuzzy Gaussian rank aggregator, and top n features are selected by using threshold value. These top n features are given as input for the wrapper method, and the optimal feature subset is selected. The three rank-based filter methods used in filter methods are Relief, minimum Redundancy Maximum Relevance (mRMR), and Feature Correlation (FC). Improved Binary Particle Swarm Optimization (IBPSO) wrapper method is used in the wrapper phase. The features selected with the ensemble method in the filter phase are used as input for IBPSO in the wrapper phase to find optimize features. Then the final feature subset is used to train the model using a kernel SVM classifier. Figure 1 represents the overview of the proposed framework. A ten-fold cross-validation technique is used to overcome the problem of over-fitting.
Ensemble feature selection process.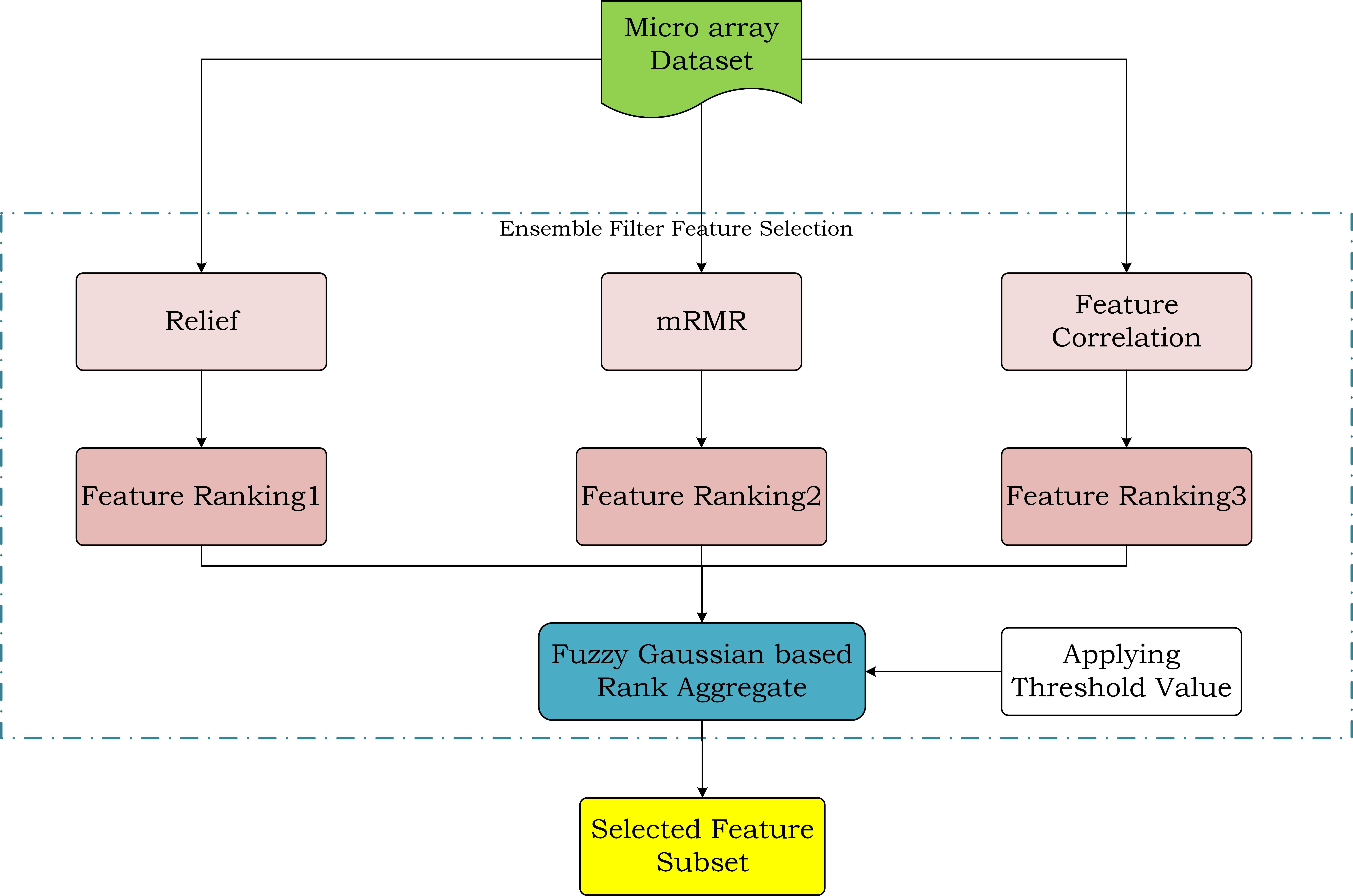
As presented in Fig. 2, the Microarray dataset is given as input for the ensemble feature selection method, which makes use of the combined benefits of multiple algorithms. Three rank based filter methods, namely Feature Correlation, mRMR, and Relief are used to rank the features according to their impact with the target features. The ensemble approach is used as it gets the combined benefits of multiple algorithms. From literature, some of the rank aggregation methods are Mean, Median, Highest Rank [40], Lowest Rank, Geomean, l2 norm, Borda, Robust Rank Aggregation [11] etc. There are some drawbacks to these methods. In the mean method, the mean rank may get affected due to very small or very large ranks And also, it is influenced by outliers and skewed distributions. Similarly, in the case of the median, it does not depends on all the values in the series that lead to less representative average and also is concerned with only middle value and so on. So to overcome the problems of existing methods, we use Fuzzy Gaussian Membership Function Ordering [4] for rank aggregation.
From the aggregate ranked features, we need to select top
where
where
In the following subsections we are going to explain in detail about each rank based filter feature selection methods.
Relief is one of the rank-based filter feature selection methods. Relief (RF) is used for assigning weights to the features based on instance-based learning [18]. Weights are assigned based on the nearest hit and nearest miss. The weights are updating based on how well the given instance is distinguished from its nearest miss and nearest hit. Higher the difference between the nearest miss and nearest hit, than the higher the weight of feature. If
where
Individual’s ranking and different rank aggregation methods
ARM
El Akadi et al. [13] uses mRMR feature selection method for selecting maximum relevant and minimum redundant set of feature for a given gene expression dataset. Mutual Information (MI) based mRMR method is employed to find minimum redundant and maximum relevant set of features. Let
The relevancy [26]
where
The gene ranking (
FC is another rank based filter feature selection method that is used as part of the proposed ensemble method in the filter phase. Here the correlation of feature values is given importance. Among the
where mean value is denoted by m. In the same fashion, the mean value of a feature for the
Here also the large value of
The above mentioned three filter feature selection methods are rank based methods that is they sort the features based on the ranks obtained by the respective FS methods. For obtaining greater diversity in the final subset, Feature Selection methods with different metrics are used.
From the literature, we came to know that there is a wide range of ensemble rank aggregation techniques available for combing the ranks obtained from different methods. The range varies from simple mathematical calculation measures such as minimum, maximum, mean, and so on to more advanced measures like SVM-Rank [30, 23]. Other rank aggregation methods are based on scores calculated using Borda algorithm [23] are Mean, Geometric Mean, Median, and
Table 1 represents the aggregate ranking of three feature ranking methods FS1, FS2 and FS3. The scores are computed for these methods using different rank aggregate methods ARM (arithmetic average), MED (median), GEM (geometric mean) and their rank aggregates are tabulated.
In Board’s methods mean position of the feature is used, with that inspiration we take the variance of the feature position also consider for calculating the membership values. Equation (10) is used for calculating the membership function of each feature obtained as a function of rank positions.
where
With this membership function value of each feature obtained as a function of position mean and variance. The membership value for each feature at each position is calculated. By using membership function ordering (MFO) [4] technique, the feature having the highest membership value at the given position is assigned the corresponding position of that particular feature. Thus the features are arranged in the aggregated ranking. Using this method the aggregate rank for example 1 is
Generally, in machine learning models, only one learning model is used for prediction. To improve further the performance of the model, the output of multiple prediction models is combined using ensemble learning, i.e., combine the output of various models is better than using one learning model. And it is successfully applied in machine learning classification models. Based on this concept to select the best feature subset, the feature subsets obtained from different feature selection methods are combined using an ensemble technique used for the classification model. In ensemble feature selection also the feature subsets from different feature selection methods are combined to form a single feature subset using some aggregation methods.
In this paper, Fuzzy Gaussian Membership function ordering is used for combing the ranking of the feature subsets to obtain an aggregate ranking. The number of features to select from the aggregate ranks is obtained by using the Fisher discriminant ratio value
Pseudo code of the ensemble feature selectionInputInputOutputOutput Microarray dataset D Selected Features F
Initialize feature rank vector V1,V2,V3feature selection method f V1 obtain feature ranking based on ReliefV2 obtain feature ranking based on mRMRV3 obtain feature ranking based on Feature CorrelationFeatures
Algorithm 3.7 explain about the proposed ensemble feature selection methods. The algorithm combines three filter ranking feature selection methods namely Relief, mRMR and Feature Correlation approaches. The feature ranking of these methods are aggregated by using Fuzzy Gaussian Membership function in the filter phase. The selected top
Improved binary particle swarm optimization (wrapper phase)
In 1995 [17] proposed a population-based stochastic optimization technique, called Particle swarm optimization (PSO). It is based on the behavior of birds in a flock. Best solutions are achieved by using their own memory of each particle and the knowledge gained by the swarm. For optimization, the fitness function is used, and each particle has fitness values. Every particle moves its position and velocity based on the best position obtained by each particle and its neighbors. It is estimated by two fitness values pbest and gbest. gbest is a global fitness value, whereas pbest is a local fitness value. To overcome the problem of local optimum, the weights are fine-tuning.
IBPSO proposed by [8] is used to overcome the problem of premature convergence of Binary Particle Swarm Optimization (BPSO) [7] and PSO. And also, IBPSO is used for achieving superior classification results and a reduced number of features. The kernel-based SVM classifier is used for evaluating the selected features and also used for calculating fitness value. In IBPSO, the position of each particle is represented by a binary bit. 1 represents feature being selected, and 0 represents the feature is not selected. The initial position of each particle is chosen by using a random function given in [36]. The velocity and position of the particles are updated iteratively based on the performance of the kernel SVM classifier and the selected number of features. pbest
where,
The
Table 2 represents the default parameters values used during the implementation of IBPSO and these parameters are evaluated by performing so many trails to get the best objective values and also based on many related work [17, 12].
IBPSO parameter values
[t] Pseudo code for proposed method load Microarray dataset DInitialize feature rank vector V1, V2, V3feature selection method f V1 obtain feature ranking based on ReliefV2 obtain feature ranking based on mRMRV3 obtain feature ranking based on Feature CorrelationFeatures
no of iteration or the stopping criterion is not met Evaluate fitness of particle swarm by kernel svm
Here in this work we use RBF kernel SVM for the evaluation of the IBPSO. In kernel svm there are so many kernel functions available that includes polynomial, radial basis function (RBF), and sigmoid kernel [6]. In this work as kernel function we are using RBF function because this kernel function is suitable to analyze higher-dimensional data [36] and also require only two parameters
Microarray datasets Colon, Breast, Prostate, Lymphoma and SRBCT which are publicly available and are collected from
Datasets used in the empirical study
Datasets used in the empirical study
Number of genes before and after feature selection method
Comparison of classification accuracy (%) obtained by the proposed method with other competing methods
* RBF kernel based SVM is used as fitness function.
Table 3 describes the dataset details such as the number of samples, no of genes, and the no of classes. The colon dataset contains 2000 genes having 60 observations with two class labels. Out of all the datasets, only SRBCT has four class labels, whereas remaining all datasets have only two class labels. For the implementation of the proposed method, MATLAB software is used.
The proposed method is implemented in two phases, in the first phase, the features are ranked using three ranking filter feature selection methods. The three rank based filter feature selection methods are Relief, mRMR, and Feature correlation. Ensemble rank aggregation technique is used to obtain the final ranks to features. In this paper, we use the Fuzzy Gaussian membership function ordering rank aggregation technique. Top
In the second phase of the proposed method, we use the Improved Binary Particle Swarm Optimization (IBPSO) method is used for further feature selection of the Microarray datasets and RBF kernel-based SVM classifier is used as the fitness function. Four Performance measures are used, namely Classification Accuracy, Recall, Precision, and F1-Score, to compare the performance of the proposed method over existing feature selection methods.
Table 4 represents the actual number of genes present in the given datasets and the number of genes selected by the feature selection methods. The no of genes is very less for proposed feature selection method when compared with other filter, wrapper and hybrid feature selection methods. For filter methods such as Relief and mRMR the no of feature selected is more when compared with wrapper, hybrid and proposed method. where as for IBPSO wrapper method the number of feature selected is very less when compared with filter method and little bit more when compared with wrapper and proposed method. Similarly in the case of Relief
As first experiment, we use RBF kernel SVM classifier on the five datasets without using any feature selection methods. In Table 5 Original represents classification is performed using all genes available in the datasets. It can be observed that the classification accuracy is very less.
In the second experiment, we perform Relief, mRMR, IBPSO filter, wrapper methods and Relief
Table 5 represents the comparison of classification accuracy (%) between proposed method over various feature selection methods such as filter methods (Relief, mRMR),Wrapper method (IBPSO) and hybrid feature selection (Relief
Shows experimental results with different data types compared with different feature selection methods
Shows experimental results with different data types compared with different feature selection methods
Table 6 represents the performance measure values such as Recall, Precision and F1-Score between proposed method and other competing methods like Original, Relief, mRMR, Improved Binary Particle Swarm Optimization (IBPSO), Relief
ROC (Receiver Operating Characteristic) Curve is used as performance measure in machine learning. ROC Curve is plotted as a function of true positive rate (sensitivity) to false positive rate (Specificity). The points on the ROC curve represents the ratio of sensitivity to specificity pair for a particular threshold value. The AUC (Area Under Curve) represents the measure of how good a parameter can able to vary between the classes. The more the AUC the best that particular model and vice versa.
ROC curve was drawn for each feature selection methods. To plot the ROC, Sensitivity and Specificity are calculated for each feature selection method. For evaluating which method is best Area Under Curve (AUC) is used, larger the area more accuracy and vice versa. The method with highest AUC is considered as the best feature selection methods.
Receiver operating characteristic curve for colon dataset.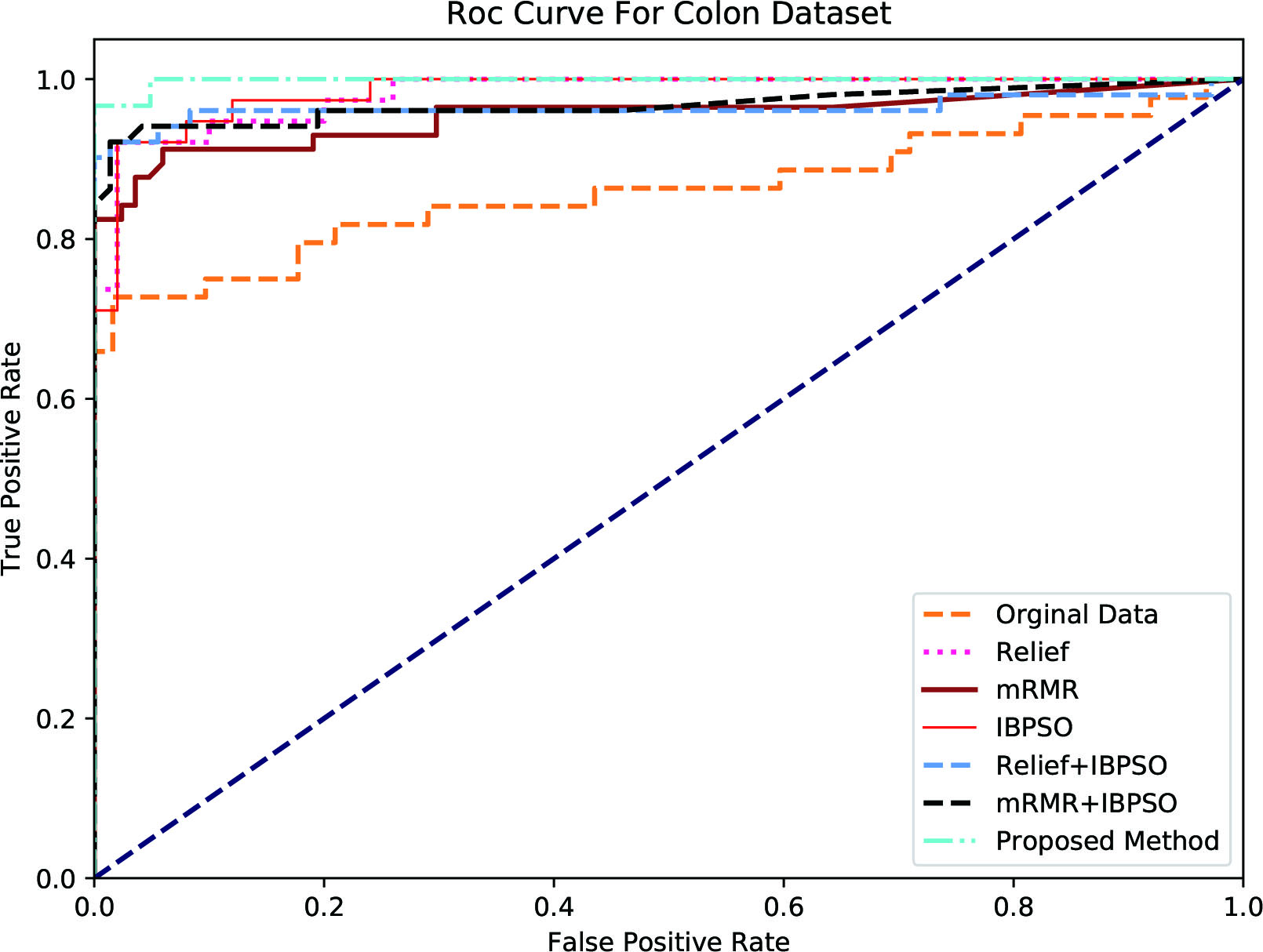
Receiver operating characteristic curve for breast dataset.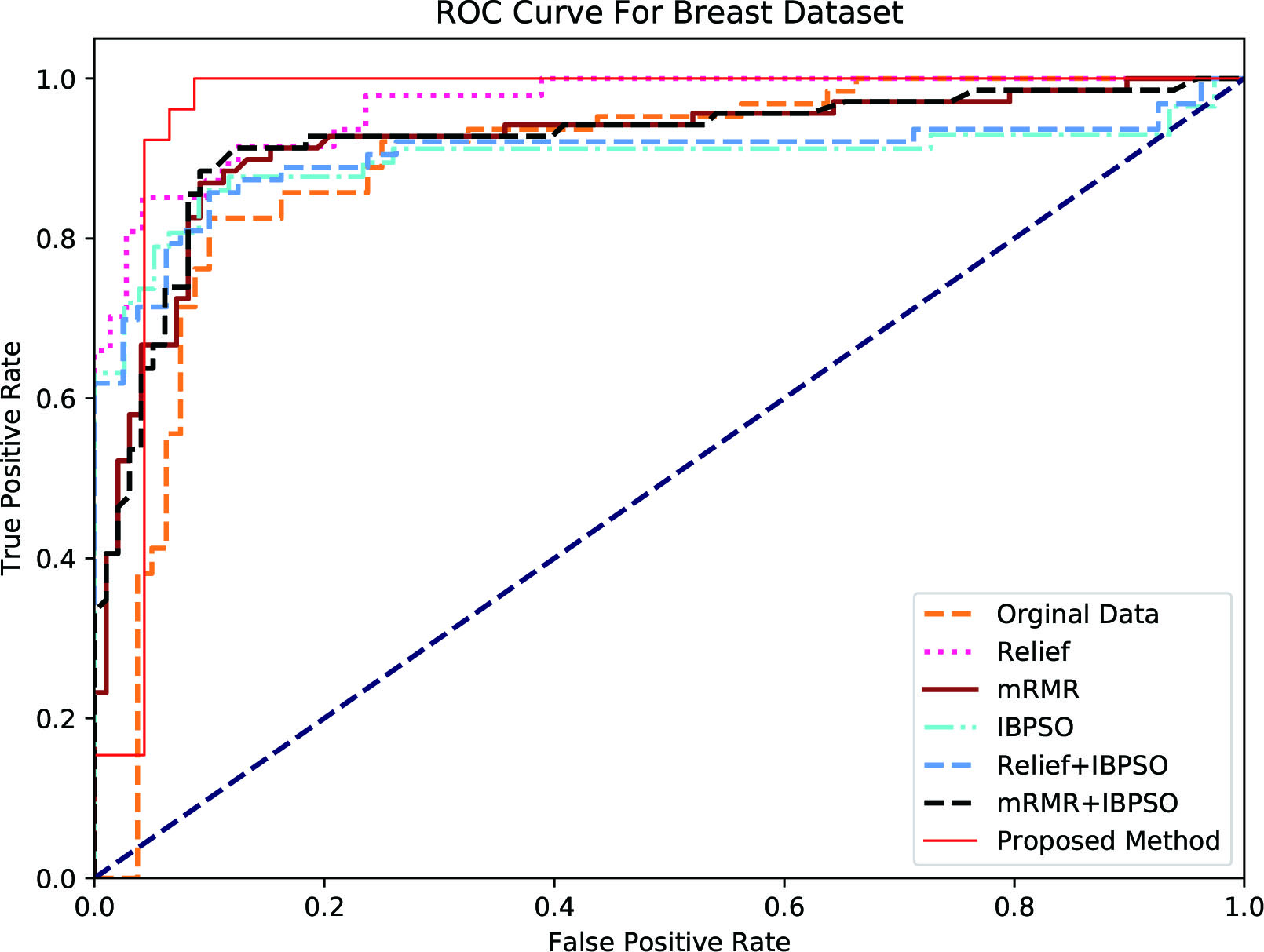
Figures 3–7 represent the ROC curves for the Colon, Breast, Prostate, Lymphoma and SRBCT datasets.
Receiver operating characteristic curve for prostate dataset.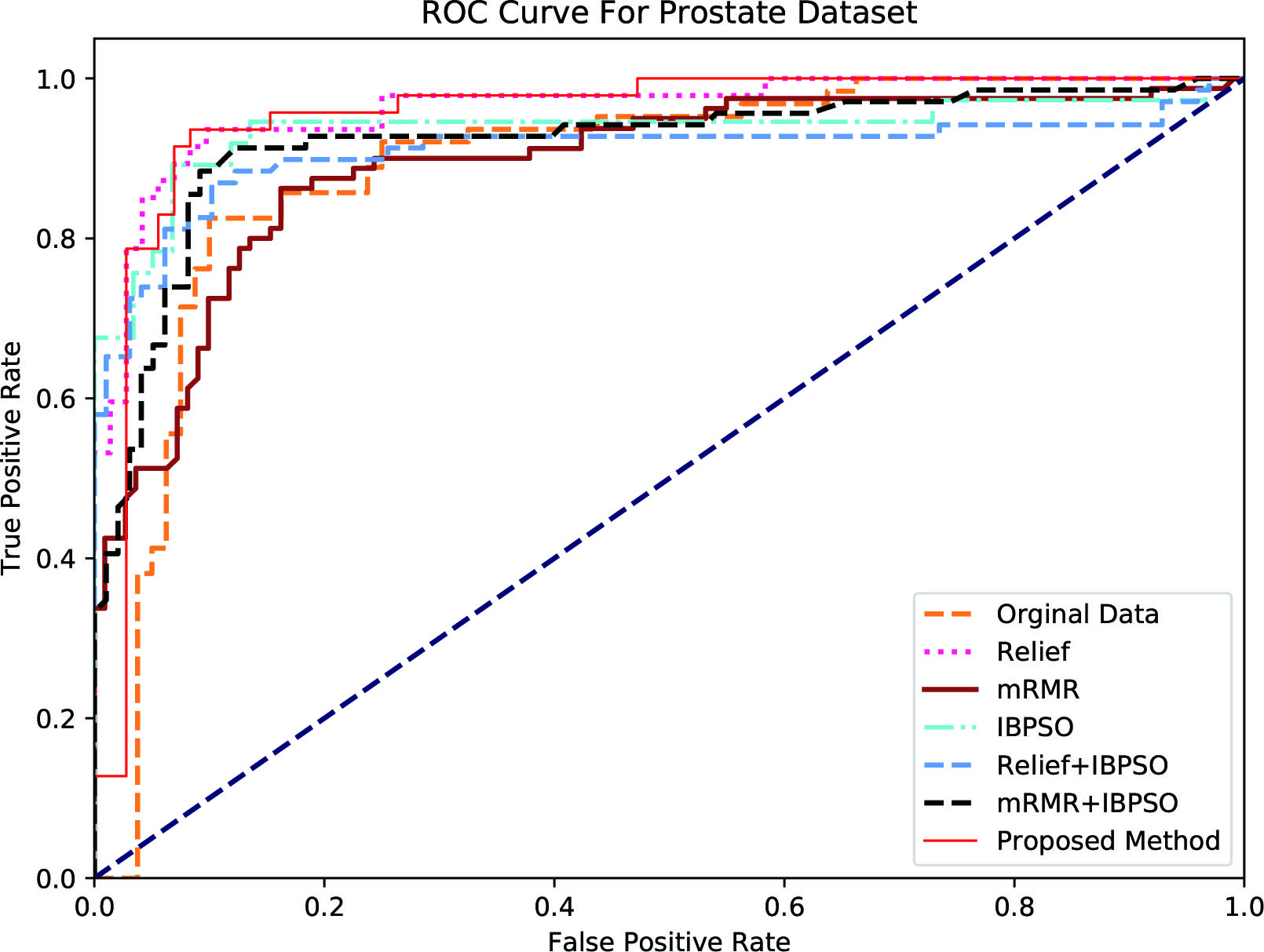
Receiver operating characteristic curve for lymphoma dataset.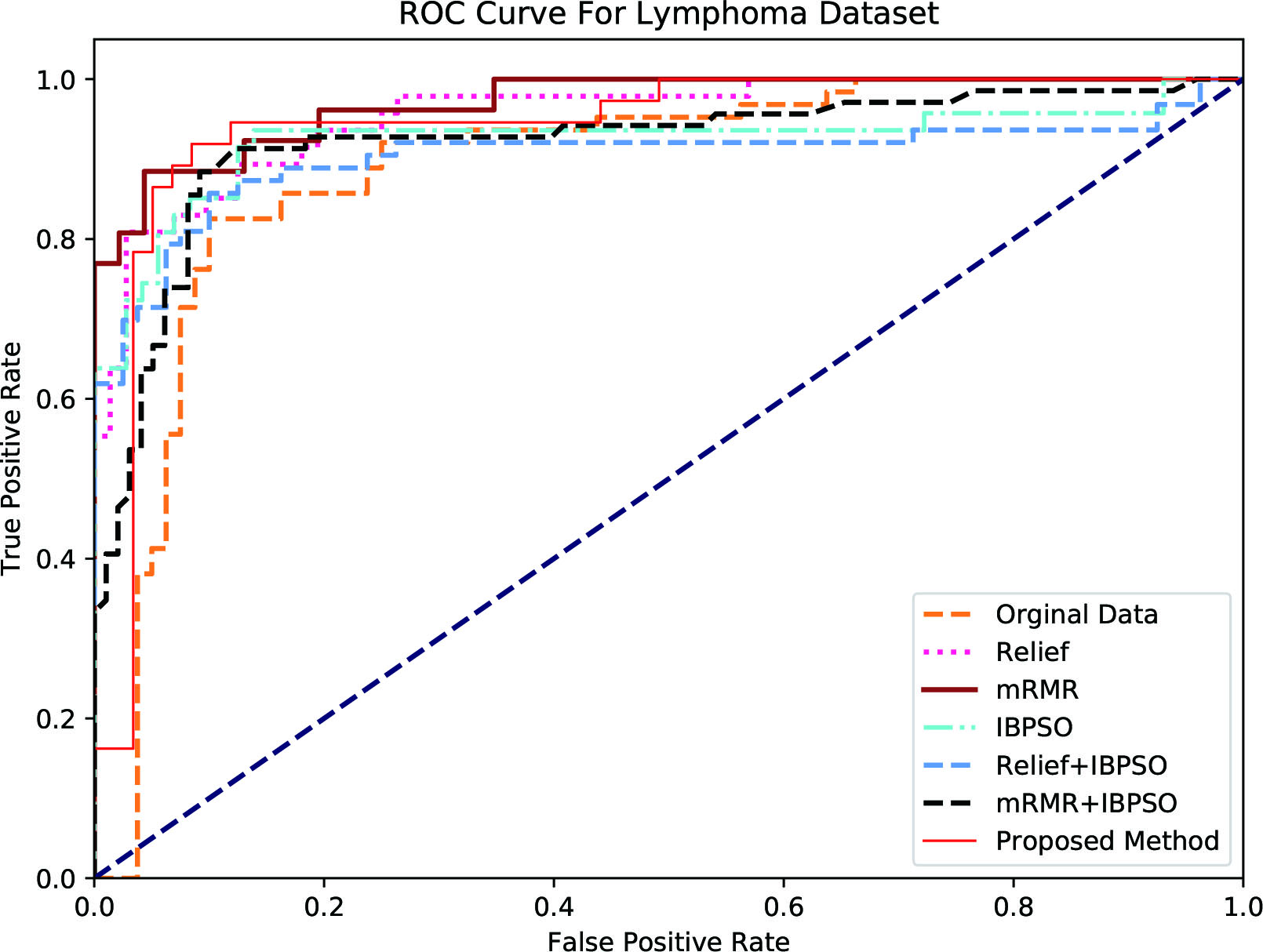
Receiver operating characteristic curve for srbct dataset.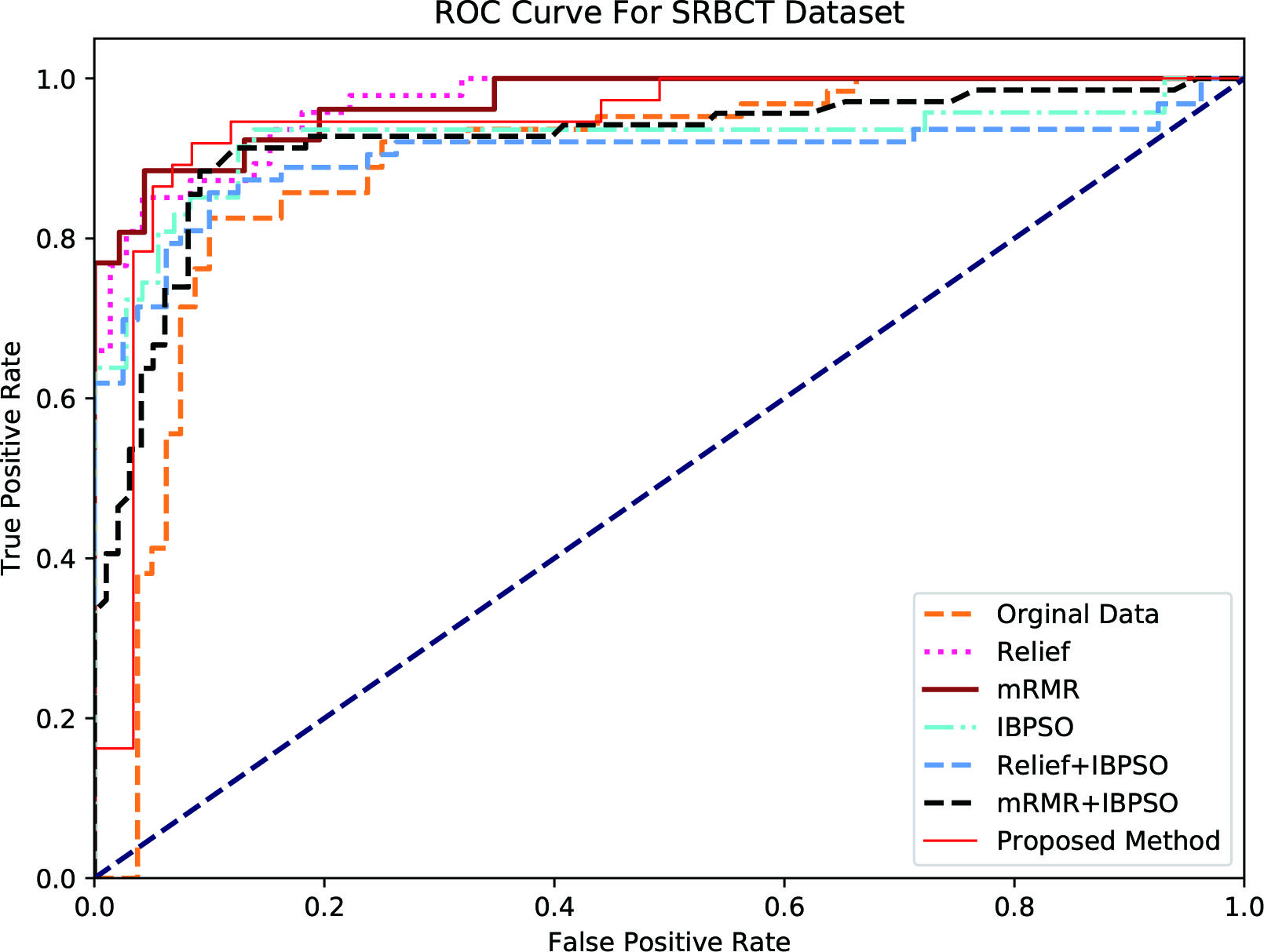
In this paper, feature selection from high dimensional data is proposed. The best classification methods may show sub-optimal performance when feature selection is not carried out. The rationale behind this is that the datasets, when used as it may cause many issues due to redundancy and irrelevant features. The efficiency of the classification algorithms will go down, and sometimes, they may be useless unless feature selection is carried out. In this paper, we proposed a feature selection method known as Hybrid ensemble Feature Selection (EFS), which combines approaches like Relief, mRMR, and Feature Correlation FS methods in the filter phase and IBPSO in wrapper phase. By using these three approaches as part of the ensemble method, the proposed method provides better results when applied to Microarray data (High Dimensional data). The performance of the ensemble method is improved by adapting to fuzzy Gaussian rank aggregation methods, which outperformed the mean, median, geomean methods used in the literature. The best-selected features are further applied to IBPSO (wrapper method) to obtain an optimal set of features. The overall performance of the proposed method is superior to other methods over the state of the art. Then the results are further optimized by IBPSO. The proposed framework reveals better performance over state of the art. In the future, the proposed ensemble method can be extended for feature selection in streaming data.