
Abstract
In the present scenario of educational technology inter-networking have provided a platform to access and share learning materials spread across various educational institutions. E-learning platforms provide an interface for accessing and sharing of heterogeneous educational resources (Learning Materials) to the various types of learners and content providers. These materials are created as the smallest digital imprints called as learning objects for the better usability. However, due to the variation in learner’s competence, providing a right content to the learner has become a cumbersome task. Consequently, a lot of personalization towards the creation and storage of the learning objects has become obligatory. Strategies involving learning style detections have provided a source of solution for the personalization. Yet, these methods are carried out with a limited number of learning styles and learning objects. And, most of these methods fail to upgrade the competency level of the learners as it provides less concentration to the learner’s capability. In order to personalize the system in consideration of the learner’s capability demands, there is a demand to understand the individual learner’s strength and weakness in the learning process. One of the features that decide the learner’s capability is the cognitive skill of the learners. It is desirable to maintain e-learning materials with respect to cognitive skill of the learners so the learning process becomes enjoyable. This paper focuses on the grouping of the e-materials with respect to the dominant cognitive content of learning objects. Hence, an organized storage mechanism is envisioned to aid the faster search and recovery of learning objects depending on the individual’s capabilities. The process is aimed to classify the materials that could be stored in a dedicated repository maintained in a distributed environment for a good usability.
Introduction
In the present scenario of the e-learning technology, a number of Learning Objects (LO) are created to help the different types of learners effectively. Different organization of learning objects is being widely adopted so that learners can access, share and use these resources easily and effectively. The maintenance of these learning objects encourages storing, indexing, sequencing, and retrieval of the objects. Organisation methodologies arrange different means of learning object grouping to help the learners in a personalized way. It is observed that these organizations attempt to provide a learning content at the learner’s desk in their desirable mode with the assurance of their convenience in learning. Usually, the contents are available in the form of learning objects and are stored in a centralized repository. This leads to the issues of storage, access and thereby affecting the reliability and maintainability of the system. Eventually, the challenge lies in storing and maintaining the assimilated learning objects in a standardized form to aid an easy access and retrieval. In order to deprive these issues, an appropriate storage mechanism is required. In view of this requirement, a dynamic reliable, maintainable storage mechanism is evolved. The idea emphasizes for distributed repositories that are strategized through a convenient arbitration mechanism, which boosts the organization of learning objects. Additionally, the organization is expected to help the individual’s convenience to reach the competency level. Hence, a Cognitive Skill (CS) based personalization is envisioned. Subsequently, cognitive skill-based classification strategy for storage of the learning object is aimed to be deployed over the grid structure for better personalization. This paper attempts to propose a novel standardizing mechanism to segregate the learning objects towards satisfying the cognitive skill of an individual, thereby improving the LO usability. Furthermore, the approach introduces a method that is powerful to guide a distributed storage mechanism that aids an easy and faster access of learning objects.
Related work
Learning object storage has been a highly puzzling process, as it instigates the learning as a meaningful and fruitful process for improving any one’s competency level. With the advent of technological facilities, E-learning has become prevalent across various domains of the education system. Irrespective of the type and level of education, Information and Communication Technology (ICT) based e-learning system has become essential to support learners for the personalization of the learning process. Mostly, this personalization is carried out to cater to the need for learner’s learning style. Hence, to suit the learning style of the learners, learning objects are needed to be deployed. As the number of learning objects proliferates, it becomes highly indispensable to increase the memory requirements of the system accordingly. Consequently, an appropriate storage and cataloging mechanism need to be adapted to assist faster, relevant retrieval of learning objects. One of the strategies adopted to resolve these issues is the distribution of course contents across variety of platforms. Several attempts have been carried out in the last decade for the effective storage of learning objects thereby to develop a prudent system for content management. Considerable research work has been carried out by various authors focusing the above aspect with different approaches. The contents are organized as a set of learning objects that span from text to multimedia contents, which included tutorials, scenarios, simulations, lesson modules, case studies, and assessments [30]. These learning material composed of different objects are usually stored in a central repository [32]. However, these repositories are to be properly indexed and maintained using an appropriate strategy. A Knowledge-tree model maintained as a component had reusable learning objects and services for learners as well as tutors. The model operated through the distributed environment for better storage and maintainability. Yet, the model suffered from an efficient protocol for the communication and retrieval [5].
Proposed architecture.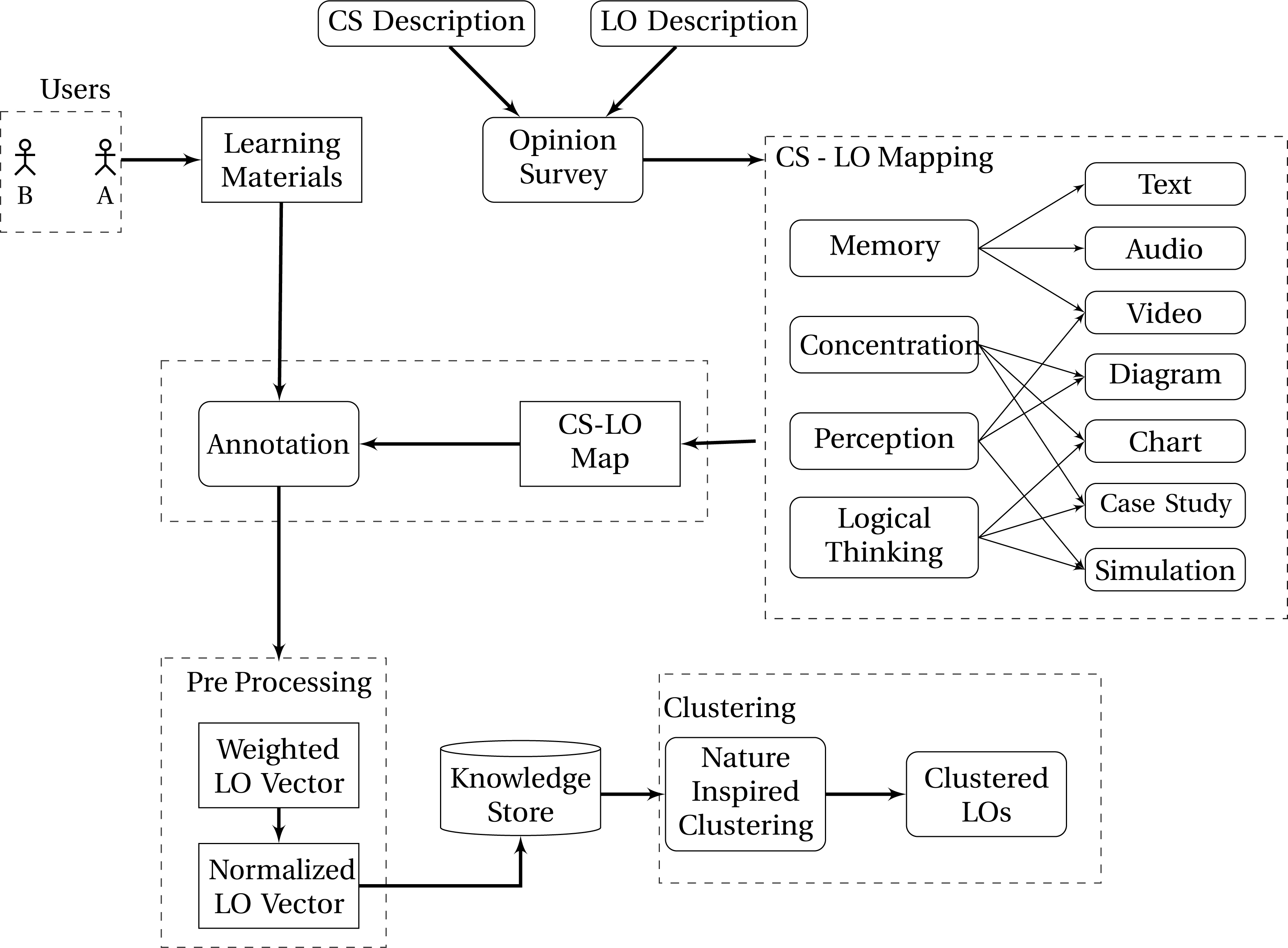
Similarly, [36] tried with geographically spread e-learning services based on the subjects as a strategy for storage. The strategy was worked out to reduce complexity and time. Meanwhile, [23] adapted a storage strategy based on the profile and experience of the learners. However, the method had limited inferring mechanisms. Also, it is noted that these storage repositories contain contents from different sources and needs standardization for better maintainability. An open source e-learning taxonomy is attempted to resolve the issue of standardization [10]. But, the model restricted the number of category of Learning Objects [28] arrived a metrics to understand the size and growth rate of the learning object to decide on the storage requirements for an e-learning system. Meanwhile, [31] proposed an efficient system using P2P architecture and Semantic Overlay Network. This method suffered from clustering similar LO’s from the perspective of different degrees of aggregation. In the meantime, [17] adopted a learning grid to identify appropriate LOs based on learner’s context and preferences. This has led to the trials on content creation and management [31, 29, 15]. Ulimately, the e-learning system discovered the use of social networks as a platform for sharing knowledge base of databases with different scheme designs [3, 11, 2], proposed to use learning object repository that was stored with a classification of Learning Objects using Felder-Silverman Learning Style Model (FSLSM) model. Additionally, [26, 27, 20] have expressed the significance of distributed database, query optimization and data replication in the e-learning technology. The idea of distributed database explored the possibility of information access and rapid data collection for high-performance data processing in e-learning content management. Subsequently, a micro context based positioning process was evolved to support distribution of LO [24]. On the other hand, the concept of data replication boomed to be an effective technique for distributed storage of e-learning content [35, 25]. In a similar way, [34] have developed sharable web fragment to distribute course contents across different e-learning system and a federated, unified and an interoperable scheme had been attempted by [22, 6] has proposed flexible and distributed framework that included tasks to capture, process and store data. An Apache Hadoop Framework has been used to collect live data, organize data traffic, stream data, and for storing data. Hence, a scope of distributed storage is expanded to fulfil the requirement of faster access.
From the study, it is inferred that the storage of e-learning materials is as important as the content authoring for better usage of LO’s. The approaches followed in the literature mostly rely on the FSLSM and subject-based model, where a centralized repository was emphasized. The repository is observed to be deployed over distributed environment for an effective maintenance of LO’s. Yet, the arbitration allowed to distribute LO’s concerned only on the storage and the consideration of learner’s learning style and their capability was not either addressed or handled in minimum. Hence, to help in the easy access of LO’s with respect to their learning capability, a system is demanded. To address this issue, a distributed model policy including the cognitive capability of the learner’s is proposed. The model claims to distribute the heterogeneous LO’s into an appropriate cluster so that the learners can easily access their choice of LO’s that improves the competency level without any difficulties. The following section depicts the distributed model proposed for the issue.
Considering the gap identified a distributed model for LO storage is envisioned and designed. The design model for the LO storage system is provided in Fig. 1. The model enclosed three major processes such as CS-LO mapping, LO-Automation and pre-processing and LO Clustering for storage as shown in Fig. 2.
Pre-processing.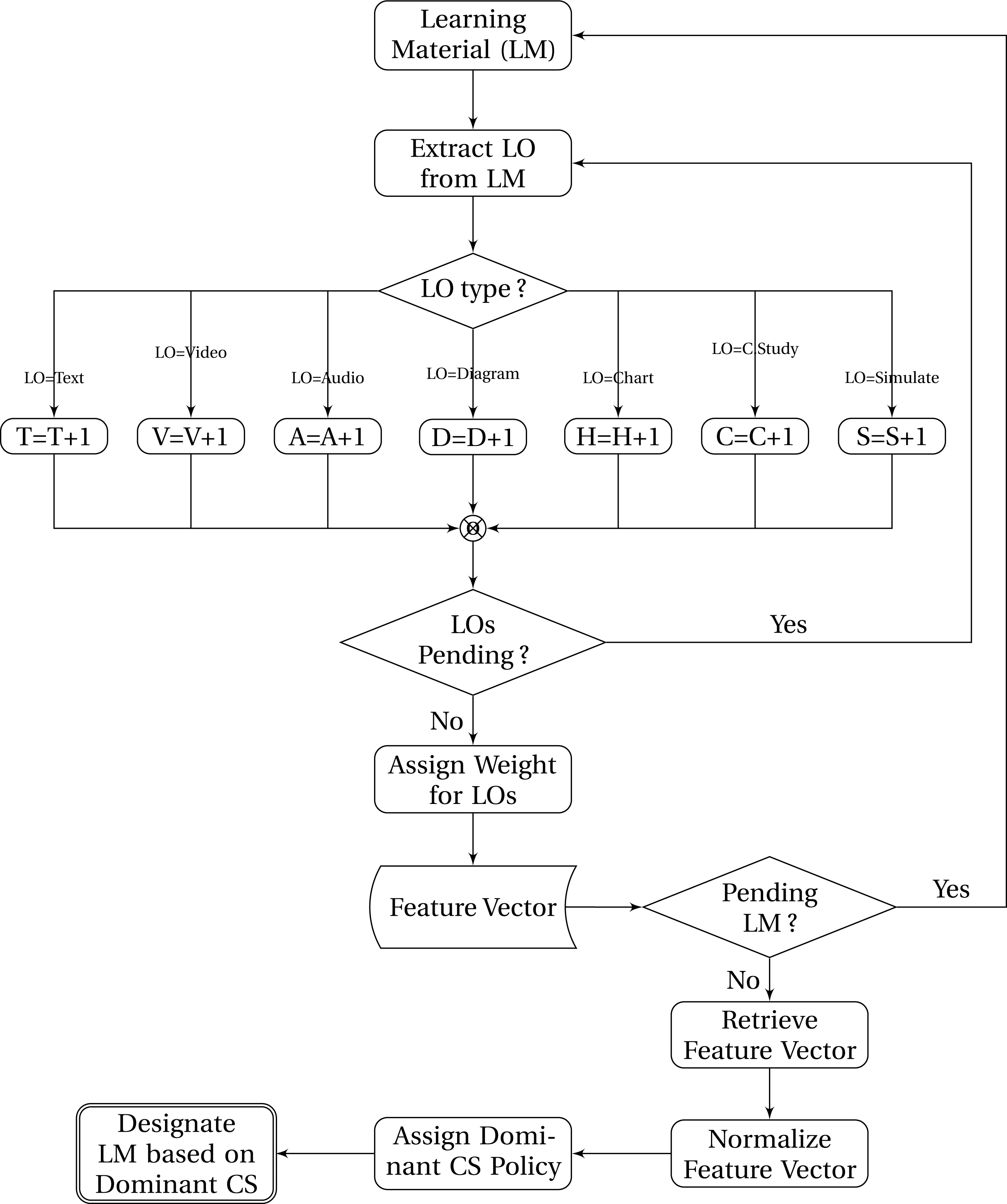
Due to the advent of ICT in learning, a lot of research commenced to bloom towards building a learning network for bringing up global knowledge sharing. In order to provide, a good and flexible encompassing different LO’s are suggested. According to [21], each of these LO’s are entitled to be a knowledge objects enclosing a set of predefined self-describable elements such as text, video, audio, graphics or any other illustrations issuing contents. However, for effective strategizing, these objects need to be properly designated and indexed and hence the storage and access to these objects become easy.
To commence with the process, initially, an appropriate organization of LO’s has to be carried out. As the focus of the work is storage strategizing, an additional feature for LO’s segregation is to be defined. The method attempts to favor the learning style of the learner’s, which is ultimately defined by the cognitive skill of the individuals. Hence, a demand for subscribing LO’s with respect to cognitive skill is foreseen. In support of this spirit, [4] proposed a model that aids in adding learning objects that are in accordance with the cognitive skill of a learner. The cognitive skill is broadly classified as memory, concentration, perception and logical thinking. According to [4], a mapping between the CS and LO is evolved. The mapping projected a combination description of LO with CS. Using this idea, an opinion survey is conducted among the educationalists. The survey outcome is synthesized and verified with the outcome obtained [4]. It was observed, that the mapping was the same. Hence a confident move towards LO-CS mapping is performed. The individual mapping thus obtained as,
Having obtained the mapping, the selected documents are subjected to annotation. Presently with the consensus of the experts, a manual annotation process was suggested.
Annotation and pre-processing of learning materials
The process that is time-consuming in the whole model is in preparing the learning objects suitable for clustering. Initially, the raw course material as obtained from different authors is annotated manually with the help of experts. The present form of the system obtains the input from the experts and using the mapping evolved, the annotation is performed. Therefore, each Learning Material (LM) is assumed to be set of LO’s (indeed, it represents only the available LO in the material). However, the annotation material cannot be taken forward as such as the different types of objects have varied influence on the cognitive skill. Hence, an appropriate pre-processing scheme is designed. According to the scheme, the weights are assigned randomly based on the importance as well as the influence of the LO towards the CS. To make the computation simple, the weights are distributed among the LO’s such that it sums up to 1.
Preprocessing
Using the weight decided, the procedure as mentioned in the Fig. 2 is carried out. Finally, each LM is designated as LO vector. By finding the weight of each LO-CS pair the dominant CS of the LM is obtained. Hence, the LM-LO vector with designated CS is stored in the knowledge store for further processing. As each of the LO has different weights, a normalization process is applied on the feature vector to convert the feature values between 0 and 1 to reduce the effect of biases. This normalization is carried out through Min-Max Normalization using the expression,
Hence, the feature vector value is normalized between 0 and 1 and is made suitable for uniform processing. Thus, the knowledge store contains the annotated LM, as well the LM’s significance towards the cognitive skill. Finally an appropriate clustering is employed to categorize the LM’s based on the CS and subsequently, a schema for distributed storage and cataloging may be arrived. To determine the dominance, the appropriate values of LO’s are aggregated for each CS respectively. The CS that culminates to a maximum value is considered to be a dominant CS for the document. Finally, the document is associated with the dominant cognitive skill. Once the annotation is completed, the documents are subjected to clustering process.
Clustering for distributed storage
Clustering is a process of collecting similar objects. The process is usually performed with respect to certain characteristics of the object that make the object unique. Traditionally, the clustering is carried out using either supervised mode or in an unsupervised mode. The supervised clustering is performed with respect to known classes. Hence it may provide an illusion of classification, with high probability density to a single class. An unsupervised clustering is a process that finds groups that are inherent to data with specific object functions and keep the group tight. Semi-supervised clustering, in turn, enhances the process with additional input along with objects characteristics so that the clustering becomes tighter with minimum distance.
To carry out the process of LM clustering, an appropriate clustering mechanism is to be decided. As the domain has different dimension of perspective such as CS, LO and learning style for clustering obviously the unsupervised mode is ruled out. A supervised model may be a suitable one but obtaining the additional information for the clustering may be challenging. Therefore a semi-supervised mode of clustering is suggested.
Nature inspired clustering of learning objects
As stated in the previous section, a clustering process is designed to segregate the learning objects, which may be subsequently dispersed in to a distributed environment for a better storage organization. According to the literature, it is found that some of the clustering algorithms are traditionally adopted for its popularity, flexibility, applicability and handling high dimensionality [1]. K-Means algorithm is one of the most important and widely used algorithms in clustering issue and is known due to the simplicity and rapid implementation for large test data set [16]. Though it is simple, in these kinds of clustering it is not possible to have full search, as challenges remain with the definition of clustering in a large search space. Hence, to have good quality clusters having optimal or near-optimal solutions in a domain of learning object discovery with respect to the learning style of individuals, nature-inspired clustering is preferred. According to [12, 14], out of several nature-inspired clustering, Particle Swarm Optimization (PSO) based clustering is found to be more appropriate for recommendation systems of larger search space. Indeed, the learning materials will have larger search space as the number of learning objects increases. Therefore, the clustering of learning objects is attempted by a Hybrid PSO technique which would be performing the clustering process based on the characteristics of cognitive skill.
Particle swarm optimization for LO clustering
Generally, PSO is a meta-heuristic algorithm which relies on a population, referred to as a swarm of particles [13], each representing a solution within the problem space. Each particle owns some information like its location, its velocity, the memory of its own best position and the best position found by the whole population up to the current search round. Fitness function calculates the fitness value for each particle, which is used to adjust the particle for a better location. Each particle has a position and velocity, denoted by the following vectors:
The solution is evaluated for each particle iteratively. The former best position of the
where
According to the attempted scenario, each vector represents the consolidation of learning objects available in each of the learning materials. Ideally, seven learning objects are considered as mentioned in section. Though the vector contains seven parameters, for any learning materials there would be a few influencing parameters that contribute for the dominancy of cognitive skills in the material source. Hence, uniformly three parameters for each cognitive skill are identified. As per the investigations carried out by [4], it is inferred that each cognitive skill is contributed by the LOs significantly as shown in the Table 1.
Influential learning objects
Considering these significant influencing parameters, the objective function is formulated as,
where ILO is the Influencing Learning Objects and
where
Particle swarm optimizationInitialize the particle and their velocities Stopping criterion is reached
(
The optimum value obtained for each of the cognitive skill is henceforth considered as the centroid for the cognitive skills around which the clustering needs to be performed. Having found out the centroid that is optimum for each cognitive skill, traditional clustering process is carried out through K-Means(KM) and Fuzzy C-Means(FCM) clustering techniques.
Consider a given data set
is minimized. where
Centroids of c clusters are chosen from Distances between data points and cluster centroids are calculated. Each data point is assigned to the cluster whose centroid is closest to it. Cluster centroids are updated by using the expression: Distances from the updated cluster centroids are recalculated. If no data point is assigned to a new cluster the run of algorithm is stopped, otherwise the steps from 3 to 5 are repeated for probable movements of data points between the clusters.
Similarly, Fuzzy C-Means focuses on the minimization of the objective function,
This function differs from classical K-Means with the use of weighted squared errors instead of using squared errors only. ‘
FCM is an iterative process and stops when the number of iterations is reached to maximum, or when the difference between two consecutive values of objective function is less than a predefined convergence value (
Initialize Calculate prototype vectors:
Calculate membership values with:
Compare If
According to the process carried out the feature vectors are subjected for clustering by applying these standard clustering techniques. The optimum value as obtained from the PSO for each of the cognitive skill is provided as centroids for further processing. The hard clustering process through K-means assigns each CS designated LM to exactly one cluster while FCM tries to accommodate LM to clusters with varying degrees of membership. Hence, when dataset is accumulated with noises or outliers, the soft clustering FCM performs differently as it provides overlapping clusters and K-means is appearing to be good for exclusive clustering.
With the identified credentials of hard and soft clustering, the process is carried out to cluster the LMs in accordance with the dominant cognitive skill exhibited through the LOs embedded in the LM. The evaluation of the clustering process performed is done through precision and recall measures.
In order to evaluate the effectiveness of the clustering methods towards categorizing the Learning Objects based on cognitive criteria, experiments were carried out. The experiments were restricted to Learning Objects of one specific course namely operating system. Two different topics such as process management and memory management were initially considered. Around 238 materials for process management and 156 materials for memory management has been collected for experimentation. Presently, learning materials were limited to presentation slides due to its adequate availability. Each of the documents is subjected to an expert guided, manual annotation process. Subsequently, the annotated learning objects are assigned with a prescribed weightages. Earlier, the influence of these LOs towards the cognitive skill was established through ANOVA process. Accordingly, the learning objects influencing the cognitive skill memory are assigned with the lesser weightages while the LOs associated with the logical thinking is given greater weightages as shown in Table 2. Once the annotation process is completed for a document, the aggregated values for each LOs is analyzed and the dominant CS is determined accordingly.
Weights for influencing LO’s
Weights for influencing LO’s
In addition to the dominant cognitive skill of each document, a feature vector is also constructed to echo the impact of each of these learning objects in a document. Thus, ‘
In the case of fuzzy C-means, it relies more on the wide clusters than the narrow clusters and hence, the real grouping is envisioned properly. Thus, to ensure that the grouping obtained on global goal, it is decided to integrate these methods with nature inspired techniques, as these methods ensure the best solution. To demonstrate the same, the particle swarm optimization is performed to find the optimum centroid around which the clusters could be formed. Having applied K-means, Fuzzy C-means with and without PSO, it is noted that the accuracy rate is significantly improved in the method that used PSO for centroid determination. As the task objective is to group the documents based on the dominant cognitive skill exposed through document, the measures such as precision, recall, and accuracy are considered for evaluation. Considering the process management course contents of operating systems, the performance is evaluated. The outcome for the performance of the K-means clustering with and without PSO is shown in the Table 3.
Process management – K-means clustering
From the outcome obtained, it is noted that the average performance of the K-Means method was found to have a precision of 0.57 and recall of 0.53 with an accuracy of 0.77. While K-means integrated with PSO turned out to have 0.76 of precision, 0.72 of recall with an improved accuracy of 0.87. From this result it is evident that K-Means with PSO performs better, similarly FCM clustering is also attempted.
Process management – fuzzy C-means clustering
It is found from the Table 4, the average performance of FCM is found to be 0.35, 0.34 and 0.67 in terms of precision, recall and accuracy. On the other hand FCM with PSO showed some improvements in the measures with values of 0.64, 0.69 and 0.81 respectively.
It is found that the average performance of FCM with PSO is observed to be higher than the FCM. However, the outcome does not show a convincing result as the FCM calculates the likelihood of a document in to the class. Hence, it is seen that the result is very much oriented towards the cognitive skill – concentration for precision, accuracy and the clustering with respect to other CS does not seem to be uniform. Yet, the performance of FCM with PSO has shown significant improvement. The performance is depicted through the graph shown in Table 5.
Process management precision values


Comparison of recall values.
Memory management – performance measures
Comparison of accuracy values.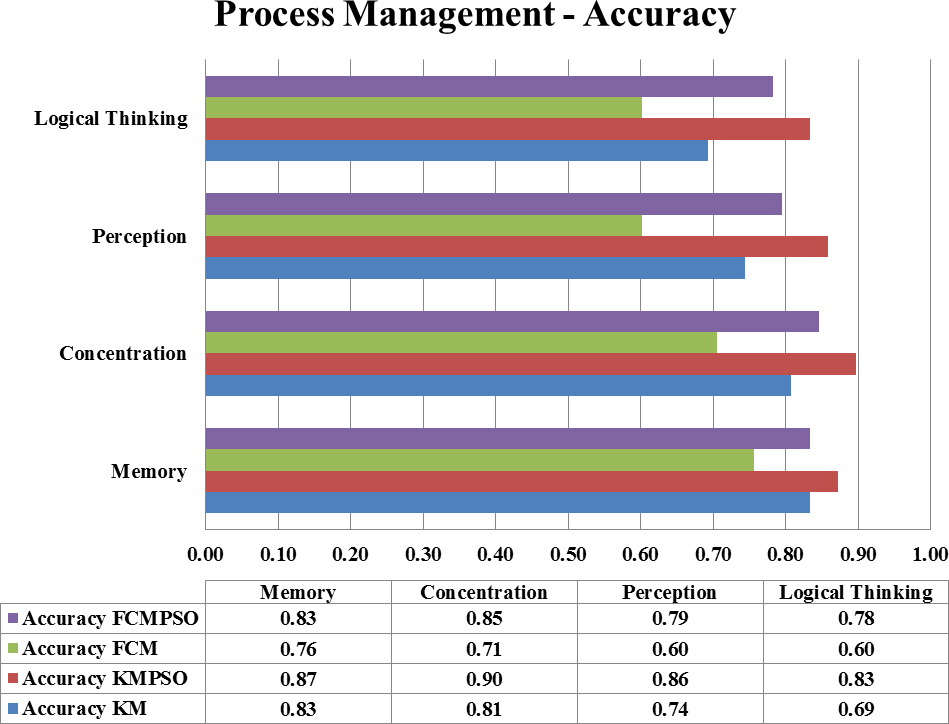
Comparison of average accuracy values.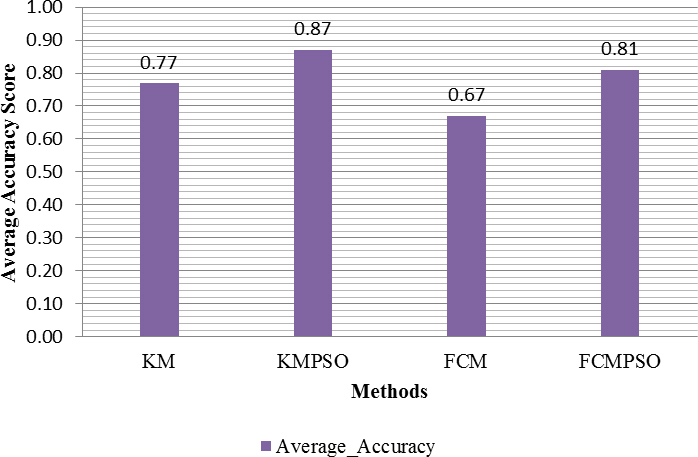
Memory management performance values

Comparison of F1-score.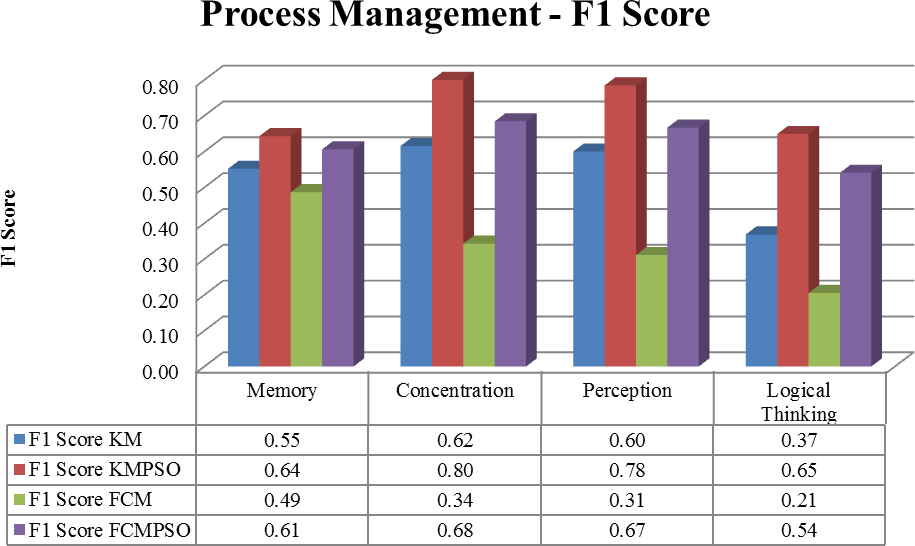
Comparison of F1-score.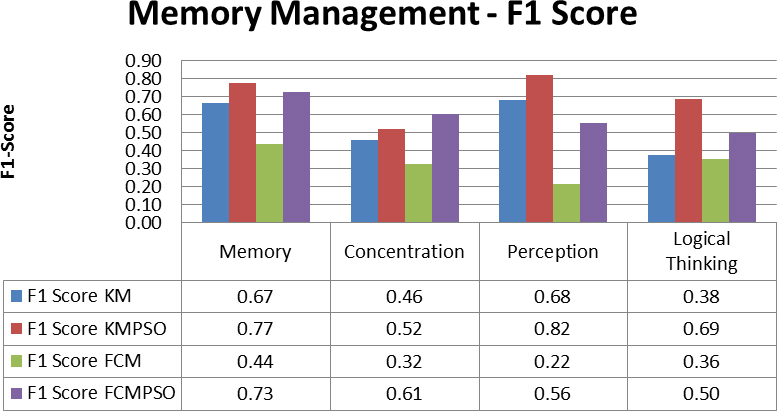
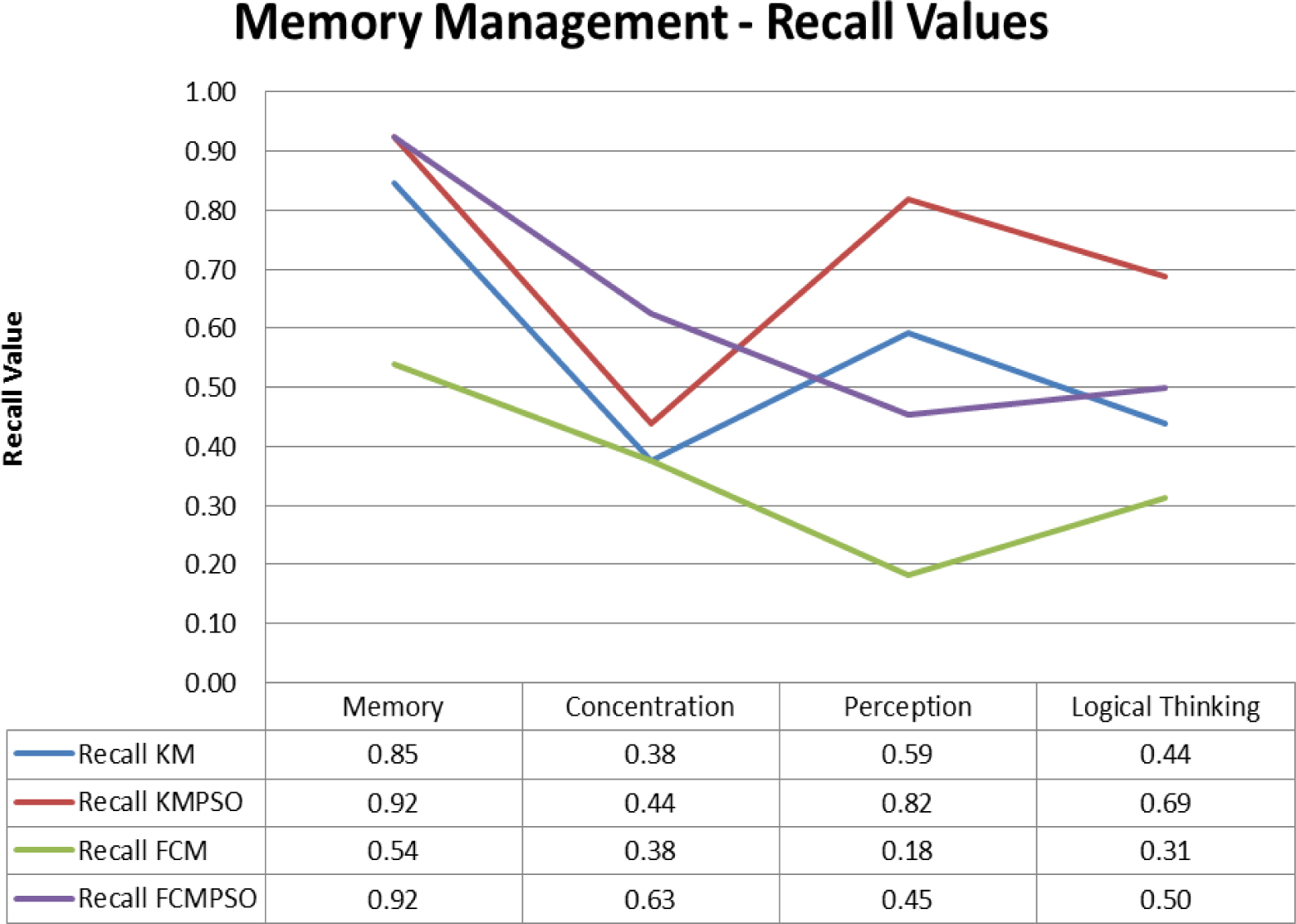
Considering the Recall rate as depicted in Fig. 3, it appears, the methodology performs well with PSO (on an average of 0.72 for K-Means and 0.695 for FCM) than without PSO (average of 0.525 for K-Means and 0.335 for FCM). Hence it is concluded that the inclusion of PSO for centroid identification does make significant improvement in the performance. To substantiate the claim, the accuracy of all the four methods has been shown in Fig. 4. By comparing the average performance, it is observed that the method integrated with PSO performs in a better way as shown in the Fig. 5.
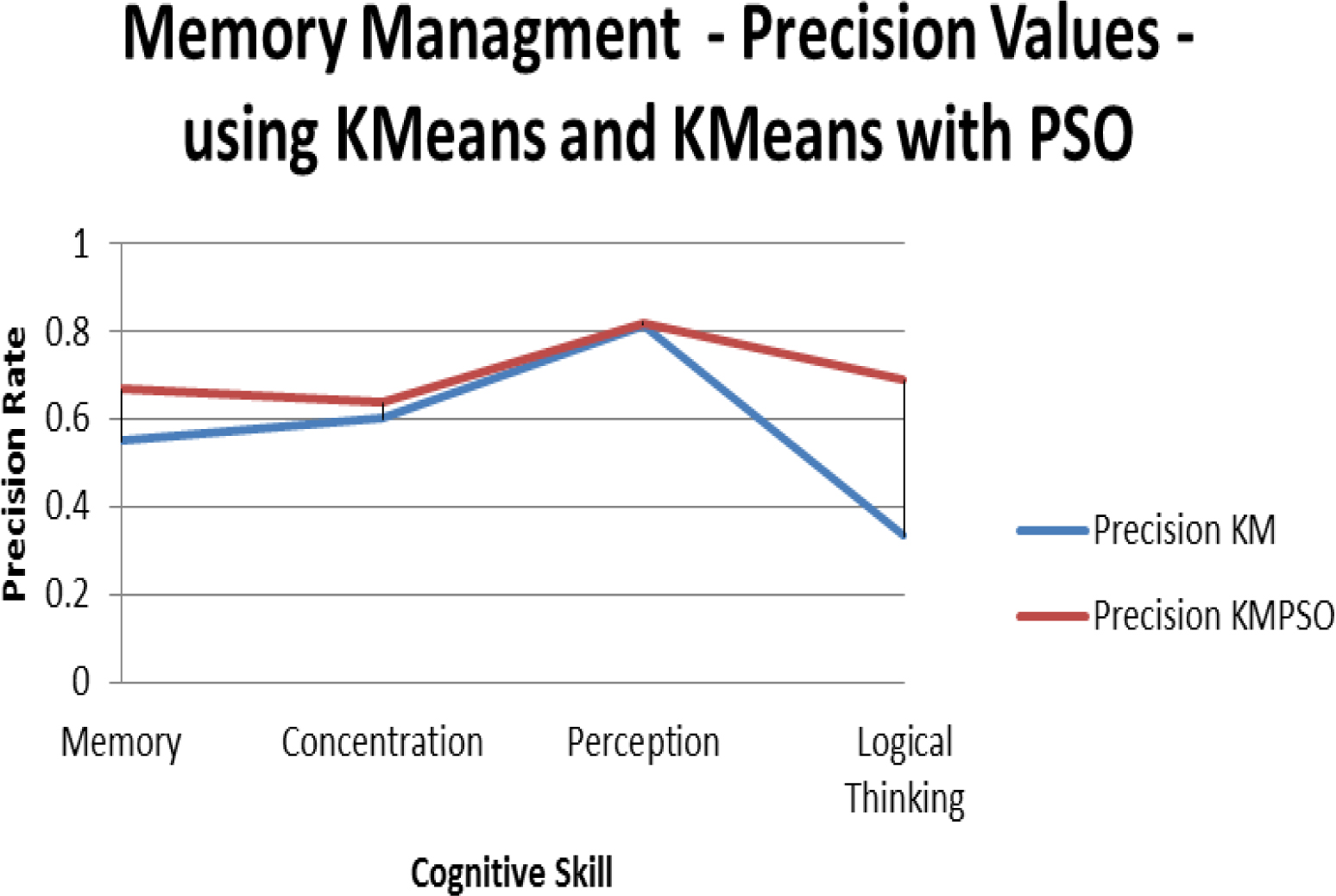
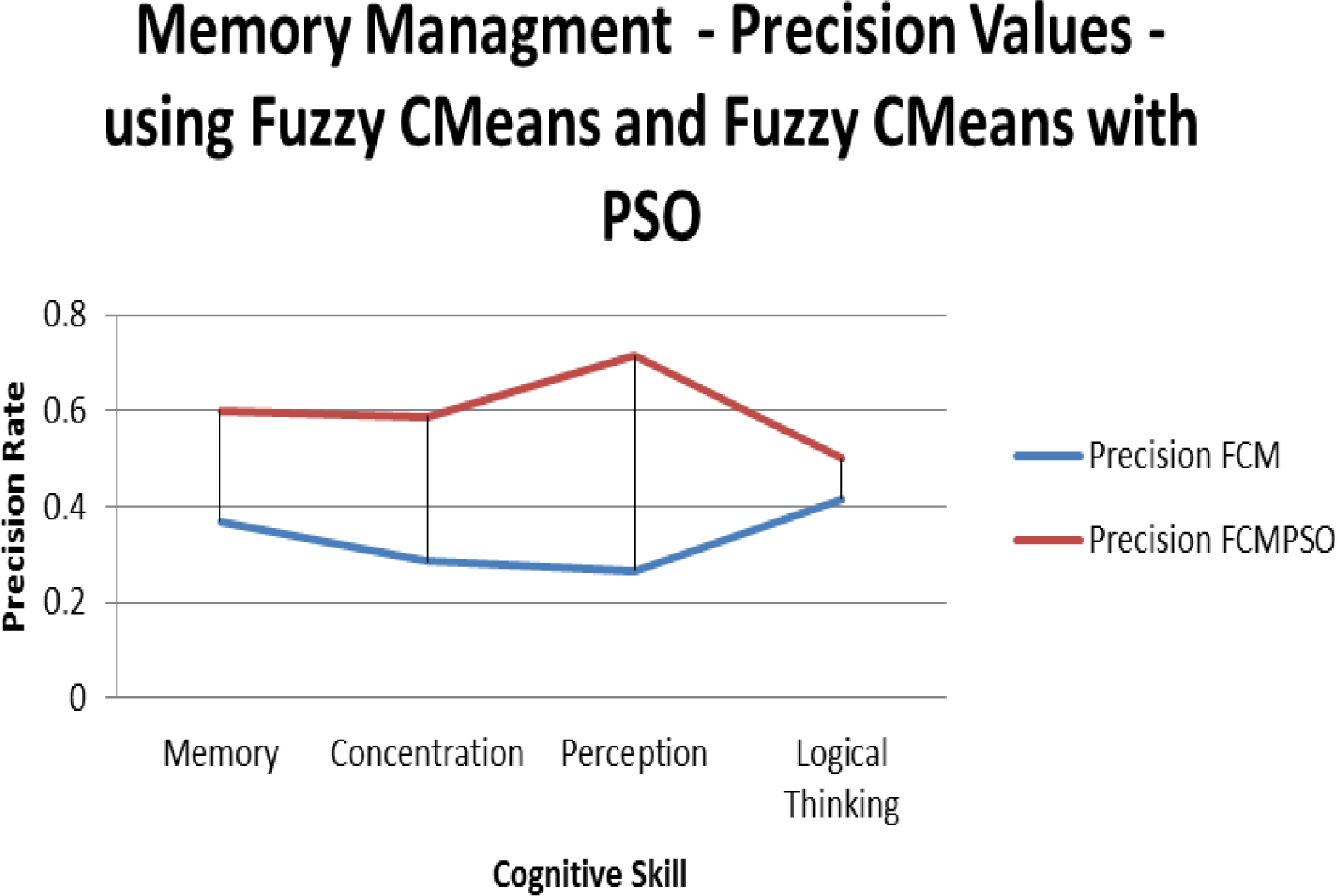
Similarly, for memory management documents of operating system, the process is repeated. The outcome obtained is as shown in the Table 6 and the performance graphs are shown in the Table 7. It is observed that using K-Means approach has a precision of 0.57 and recall of 0.56 with an accuracy of 0.78, while K-means integrated with PSO turned out to have 0.70 of precision, 0.72 of recall and with an accuracy of 0.86. It is also found that for FCM the precision, recall and accuracy values were 0.33, 0.35 and 0.6 respectively, while FCM with PSO had the measures with values 0.60, 0.63 and 0.80.
According to the outcome obtained, the average performance with respect to the learning material titled memory management is observed to be better for the method integrated with PSO as shown in the graph. From the results it is clear that the method with PSO performs better irrespective of KM and FCM. Within the two methods KM and FCM, KM with PSO has shown better performance for the considered dataset. The reason for the better performance is that each subset share a significant proportion of common traits which becomes a favorable fact for the LO clustering towards dominant CS. On the other hand, FCM has an advantage of fast convergence, yet it expects low membership degree for outlier. In this case, as most of the LOs have significant contributions at different levels towards CS, it is likelihood that the presence of an LO would contribute for more than one CS. Hence, there is a chance for the increased misclassification rate, due to which the accuracy of the clustering is affected. Additionally, according to the F1 score of these methods, it is seen that the K-means with PSO demonstrates substantially.
From the graph, it is observed that the F1 score which is obtained as a balance between precision and recall is greater in the KM-PSO than the other options. Only in the case of concentration of memory management CM, there is a minor deviation where FCM-PSO showed a better performance. The deviation could be due to the lack of learning objects in the sample course materials. However, as the difference between KM-PSO and FCM-PSO is trivial, the deviation can be ignored. Therefore, from the experimentation, it is concluded that for the clustering of learning objects having considerable amount of heterogeneity, K-means with PSO would be very much preferable.
The study was aimed to design a methodology that would help in the process of segregating bulk course materials in the order of cognitive skills. The process attributes for two different aspects such as effective storage and learner centric course materials. Towards this objective, experimentations were carried out by considering around 400 documents containing LOs for process and memory management of Operating system course. Popular methods such as KM and FCM were attempted. As the performance was not resounding, a hybrid methodology including PSO as means of finding centroid for clustering is attempted. The endeavored approach demonstrated an owing performance when compared to the methods without PSO. Also it is noted that the KM clustering was found to be effective than FCM. However the approach may have deviated functionalities when all the Learning Objects are not be present in the Learning Material and sufficient document for all types of Learning Objects are not trained adequately. With these findings, a storage strategy for distributed E-learning is framed. The clustering of the course materials with respect to the dominant cognitive skill intended to streamline the distributed storage strategy which is expected to yield improved throughput. Additionally, the approach ensures the availability of course materials in accordance with the learning capability of the individuals. On the whole, the suggested approach demonstrates a decent performance towards distributed e-learning system.