
Abstract
In this work, an efficient scheme has been proposed for the computer-aided detection of the wide-spread disease diabetes. This scheme involves certain data mining techniques for the purpose of detecting the chances of diabetes by looking into a patient’s medical record. This work attempts to classify the nature of diabetes (Type-I and Type-II) as well. It also tries to determine the level of risk associated presently with the affected patient. Four different algorithms namely decision tree, Naive Bayes, support vector machine (SVM), and Adaboost-M1 have been used for the purpose of labeling the records as either diabetic or non-diabetic. A comparison strategy is then followed to adopt the best scheme among these through the voting expert. The proposed work gives satisfactory diagnosis result when compared to the ground-truth data. Overall accuracy rate of 95% is achieved through k-fold cross-validation (
Introduction
Diabetes is generally not a disease rather the inability of the human body through which it can not break the blood sugar into its constituents. The technical nomenclature for this is Diabetes Mellitus [1]. There may be mild to critical health condition pertaining to this inability. The person suffering from this medical condition has to take care of his/her blood sugar level with utmost care failing which it may lead to critical and sometimes fatal situations. There are several theories behind this medical conditions. It may be the pancreas which may not be able to produce the insulin which is solely responsible for dealing with the balance maintenance of the blood sugar. It may be the insulin strength which may not be strong enough able to do the task of balancing the blood sugar. Several other theories does exist as well. Based on the pre-conditions, diabetes mellitus is categorized into three different types. They are:
Type-1-diabetes mallitus (DM): A person suffering for this condition is unable to secret sufficient insulin through his/her pancreas. The reason behind this condition is still a research area in medical science and thus unknown. Type-2 DM: In this medical condition, the boy of the person becomes resistant to the insulin and thus can not break the blood sugar. Gestational DM: This type of medical condition occurs due to high blood pressure and hypertension over a long period of time. Generally, pregnant woman suffer from this type.
As per the survey report by national diabetic official forum approximately 10% among the US citizens are suffering from DM [2]. Worldwide, more than 420 millions of people (equally men and women) have got DM.
Data mining refers to the extraction of meaningful information from a large and vivid repository. It is treated as a KDD (knowledge data discovery) process (Fig. 1). The analysis pertains to known patterns and the challenge is to predict the nature of the unknown pattern. In this regard, data mining has been considered as a boon in the field of medical science. It is thus gaining importance day by day. By this, numerous disease and medical conditions can be predicated with accuracy and with least human interventions. Its applications in medical science includes analysis of several medical conditions like cancer, diabetes, heart problems, liver health condition, and brain related conditions. However diagnosis and analysis of DM is gaining importance world wide as this medical condition is spreading rapidly.
General overview of a KDD system [3].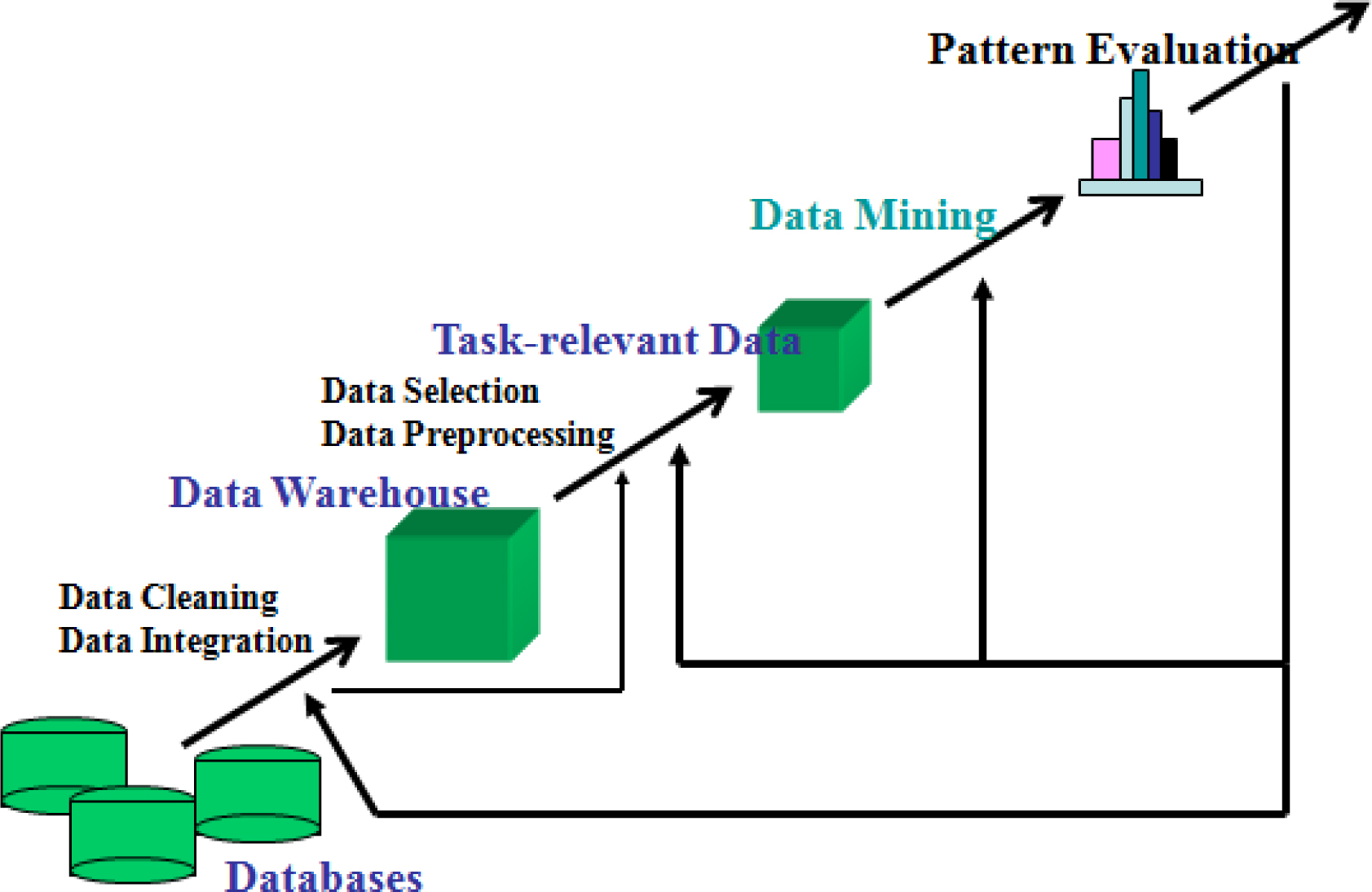
Numerous analytical tools and techniques have been proposed for the purpose. Several schemes have been proposed for the diagnosis and detection of DM. The schemes generally employ different concepts like Naive Bayes, Kernels, Support vector, Probabilistic models etc. [4, 5, 6].
In [7], the author have presented a scheme called CoLe that can predict ealy stage of diabetes. CoLe is an integrated framework. This can be trated as a pure KDD process. In [8], different types of classifiers have been individually implemented. These algorithms includes KNN (K nearest neighbor), Naive Bayes, LDA (linear discriminant analysis), C-4.5, and ID3. The C-4.5 algorithm has been proved to be a better classifier for prediction of DM with an accuracy rate of 91%. In [9], an expert clinical system has been proposed for the diagnosis of DM. It uses XCS (extended classification system) as the constituent classifier. In [10], the apriori scheme has been utilized for the intra-classification of type-2 DM. Association rule mining has been the key classifier in this context. Suitable pre-processing techniques have also been applied for the purpose. In [11], another framework called duo-mining tool is introduced for the diagnosis of diabetes. This also focuses on the intra-classification of type-2 DM. In [12], hierarchical clustering technique is used discover the different models for predicting the controlling mechanism for DM. In [13], the CART has been used for prediction of diabetes. It also predict the risk factor associated with the medical condition of the person. In [14], both the SVM and Naive Bayes are used for the purpose of predicting DM. This work focuses on diabetic retinopathy. It gives an overall accuracy rate of 84%. In [15], a database has been proposed for the purpose of diagnosis of DM through several data mining techniques. Disease correlation approach has been proposed in [16] using Naive Bayes method for diagnosis of heart related diseases occuring due to DM.
It is observed from the literature that none of the methods are focusing on an ensemble model for the purpose. An ensemble would help in taking the best algorithm always which can predict the medical condition with utmost accuracy at a particular instance. The proposed work here focuses on such an ensemble which enables it to take always the best among all accuracies providing algorithm and use it for the purpose of diagnosis and prediction.
Proposed work
A general overview of the proposed work has been shown in Fig. 2.
The proposed work employs an ensemble that uses the voting expert scheme. This scheme takes into account three different algorithms namely, decision tree, Naive Bayes, and SVM to generate the output. If only multiple algorithms give identical prediction label then only the output is considered as consistent and it is given as final output. Thus it eliminates the chance of misclassification. This is quit helpful in correct prediction which is most needful so far as medical conditions are concerned. All the three algorithms are discussed below in a sequence.
General overview of the proposed work.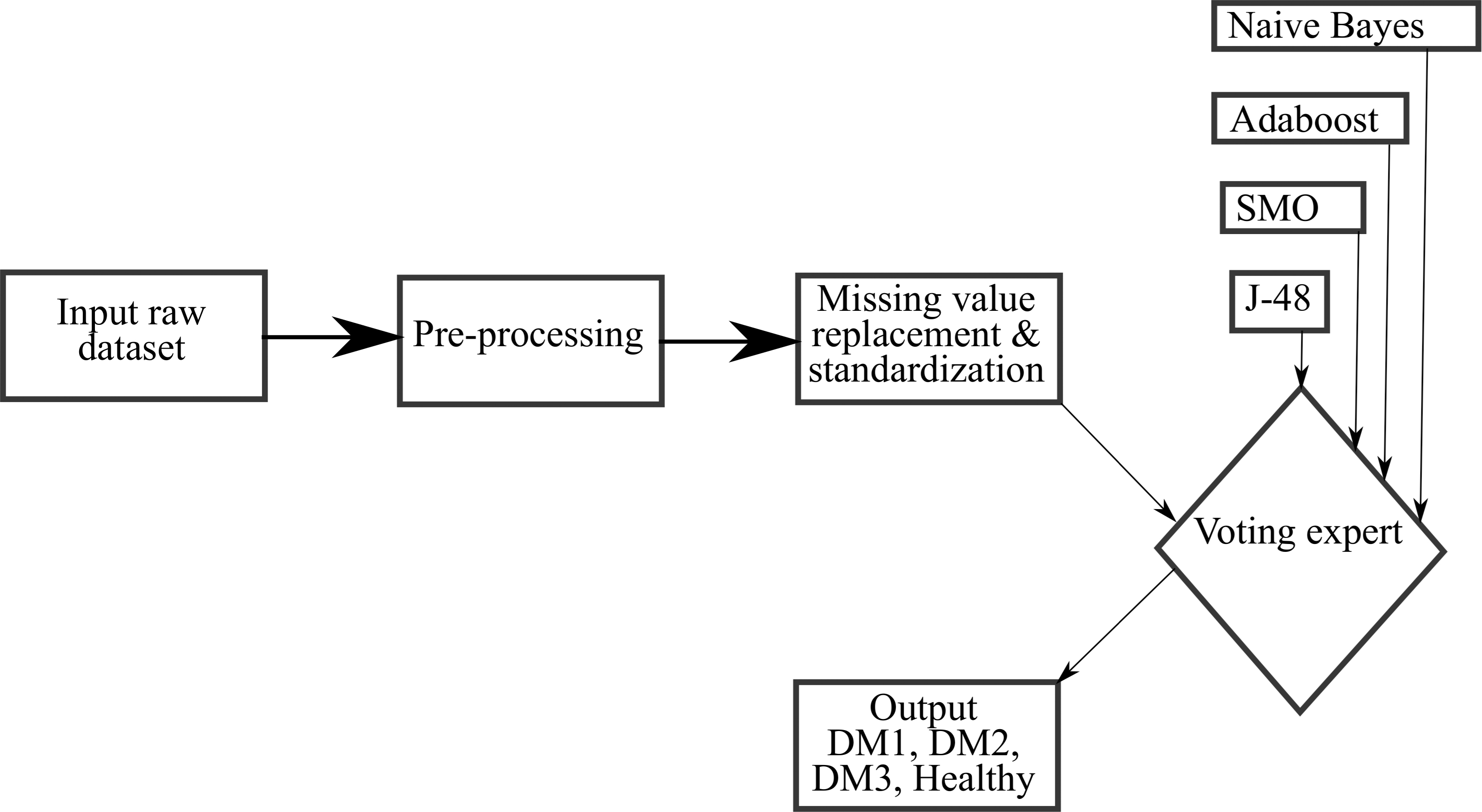
Sample representation of decision tree.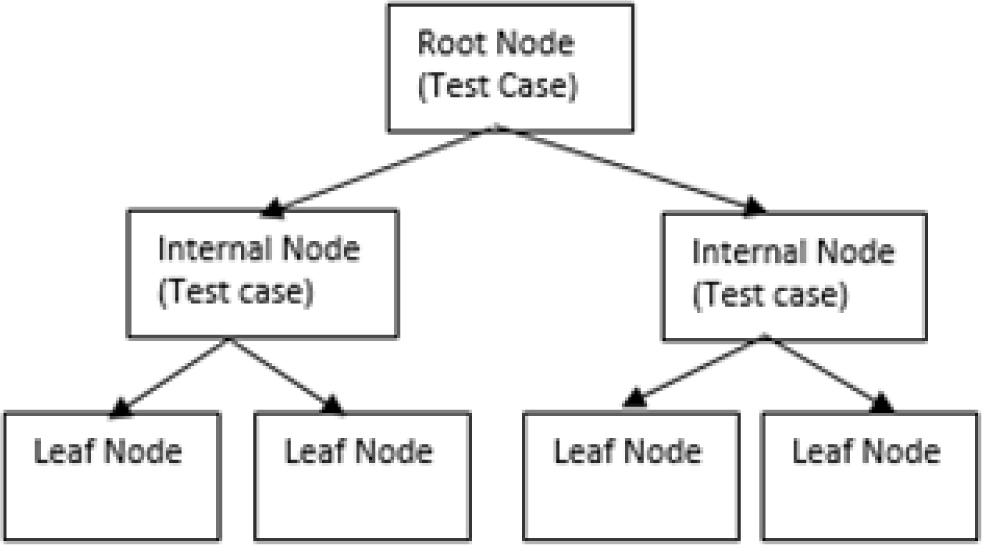
Decision tree (Fig. 3) has been successfully used for business decision analysis. However, it can also be used for prediction of DM as in our case. It is a tree with internal nodes pertaining to certain criteria and the external nodes or leaf nodes as the label for prediction. Based on the training data, the tree structure is designed. Each of the internal node is having an information gain value (
where, the sum is taken over the total number of classes involved in the training dataset,
The Bayes theorem for conditional probability has been adopted for this purpose. The features (attributes) are analyzed independently. This is because each of these features are considered equally important. Naive Bayes is powerful in the sense it can be applied to a vast dataset. For this case our data has been split into train/test samples in the ration 60/40.
SMO (sequential minimal optimization)
In general, the quadratic algorithmic problems are solved using this SMO. It uses quadratic kernel from the SVM. Thus, it is an analytical process and can be used in our case. It is robust as it can fill the missing values in a processed feature set. The core input to this process are the binarized values those are obtained by conversion from nominal values. The same ration of train/test samples (60/40) have considered in this case as well. A simple snapshot of the SMO flowchart has been shown in Fig. 4.
A simple snapshot of the SMO flowchart.
Adaboost stands for adaptive boosting. This is a meta-algorithm which supports pattern classification. It is generally combined with few other weak classifiers. A weighted sum strategy is considered for boosting the classifier. The term boosting here refers to the fact that the weak classifiers that are combined with this method are subjected to adaptation so that the misclassification can be reduced over a certain iteration of learning. Thus it is less prone to the over-fitting pro- blem. A symbolic representation of this theory has been shown in Fig. 5.
General theory for ada-boosting.
SVM has been successfully used as an efficient classifier for many a non-linear classification problems. The objective of a SVM classifier is to generate the hyperplane between two classes of objects among a distribution. Simultaneously, maximizing the width of the margin. The corresponding objective in terms of equation for the same is given below:
such that,
Define a margin with optimum width; Introduce a penalty value with respect to miss classification and thus subtend the margin width definition (Linearly non-separable cases); Perform mapping of the data points up to the level where which is suitable for classification with linear surface; Output the final optimized margin width.
The train and test samples used for the SVM set up are taken to be 400 and 300 samples respectively.
The Pima Indians Diabetes Database has been used for the experimental evaluation of the proposed work. The dataset is available at [17]. This dataset belongs to National Institute of Diabetes and Digestive and Kidney Diseases. It contains 768 number of instances and each instance contain at least 8 number of feature attributes. The feature values are depicted blow:
Number of times pregnant. Plasma glucose concentration a 2 hours in an oral glucose tolerance test. Diastolic blood pressure (mm Hg). Triceps skin fold thickness (mm). 2-Hour serum insulin (mu U/ml). Body mass index (weight in kg/(height in m) Diabetes pedigree function. Age (years).
Out of these data, a total of 700 samples have been considered for our case. Out of these again, different number of train/test samples are considered for all the classifiers separately. The detail of training samples are given below:
For J-48; For AdaBoost-M1; For Naive-Bayes; For SVM;
performance comparison (rates of accuracy)
Mentioned below is the list of working steps which are executed in sequence for implementing the proposed work.
indent=2em Proposed algorithm (Voting expert with the quad)[1] Load raw dataset Apply data pre-processing and filtering with target attribute as the last attribute (class-label); (Weka tools) Replace and standardize missing values to generate final dataset
Experimental evaluation
The algorithm is executed using the Weka tools which is an open source tools developed by the Waikato University. Satisfactory results are obtained pertaining to the proposed scheme. The performance measure of the proposed scheme has been generated using two different techniques separately. One is the k-fold cross validation method, where the value for k has been considered to be 10. The second method is using the precision and recall method that consider the TP (True positive), TN (True Negative), FP (False Positive), and FN (False Negative) parameters. Here the accuracy is computed as per the formula given below:
Comparison of the rate of recognition accuracy of constituent schemes individually.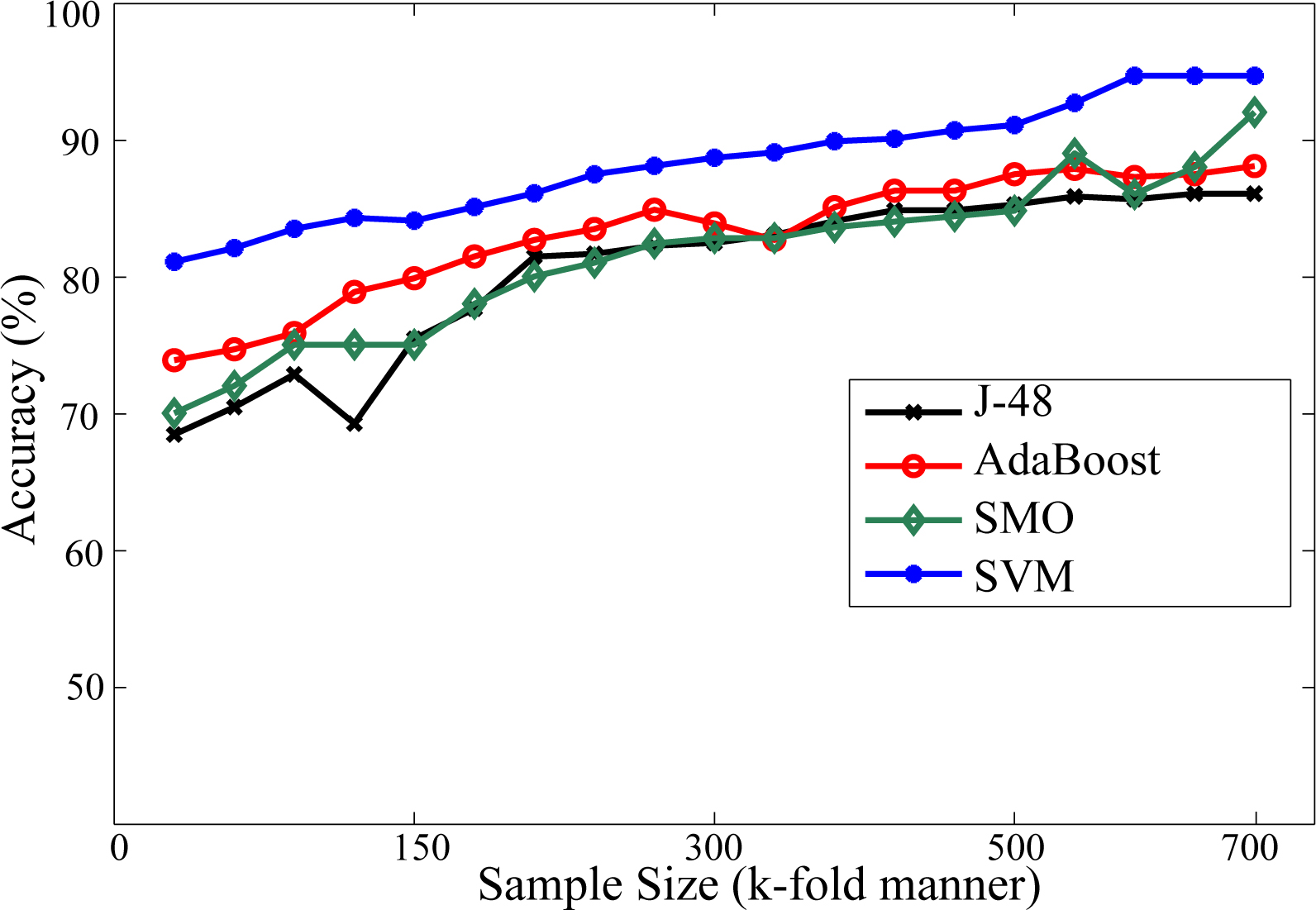
The results so obtained are depicted in Table 1. It can be observed that, for the particular dataset, the SMO scheme outperforms others with respect to the overall rate of accuracy.
Comparative analysis of the proposed scheme is also carried out with three other state-of-the-art schemes namely neural network, Cole, and RBF-NN (Radial basis) with the same dataset. The corresponding plot is shown in Fig. 6. It can be noted that the proposed scheme outperform others in terms of overall rate of accuracy. This validates te robustness and effectiveness of the proposed scheme.
A novel data mining approach has been proposed for the detection and classification of the medical condition diabetes mellitus. An ensemble of analytic algorithms is designed by taking four different algorithms (Quad). Voting expert strategy has been implemented to predict the correct label for the patients medical condition as such DM1, DM2, DM3, and healthy. The proposed work has been validated on benchmark dataset after proper pre-processing and missing value replacement. Satisfactory rate of accuracy (95%) has been achieved which validates the robustness of the proposed approach. The scheme has also been compared with three different state-of-the-art schemes for the related work and it outperforms others in terms of accuracy. Future works may include the disease correlation establishment between DM and other related medical conditions that arises mainly due to excess sugar component in human blood.