
Abstract
The growth in communication methods have motivated a good number of users to migrate the existing communication methods towards video-based communications. Thus, the use of video-based communications have become the basic communication method for various fields and domains as distance education, business, physical security monitoring and also in the field of news and media. The summarization process demands to extract key components from the video data in order to reduce the size of the data without compromising on any information loss. This processing is called key frame extraction process. Realizing the priority of the key frame extraction process, a few parallel research attempts were executed to match with the bottleneck of information loss and size reduction. Nevertheless, the processes were highly criticised for being time complex and sometimes for information loss. The issue with the standard or parallel methods for extraction of key frames is either high or low rate of key frame extractions, which in turn results into high size or high information loss respectively. Thus, this work aims to provide a novel key frame extraction process using the image meta data and further the adaptive thresholding method. The work demonstrates a nearly 50% reduction in time complexity with 100% accuracy of the key frame extraction process and finally a nearly 30% reduction in the key frame replication control.
Keywords
Introduction
Any key frame extracted from a video can represent a lot of information. As the key frames provides a suitable meta-data for indexing, browsing and retrievals. The review work by Aigrain et al. [12] presents a significant proof of concepts demonstrating the benefits of key frame extractions for various video processing and information extraction methods. The notable work by Zhang et al. [6] also proves that the key frame extraction and key frame-based indexing, searching and retrieving can be faster for any video datasets. The searching methods can quickly extract the desired key frames based on the analysis carried out for only key frames. None of the single research has predicted the accurate number of key frames to be extracted based on the length of the video. As the optimal number of key frames depend on the density of the information present in the video. The information density can be estimated based on the supported audio codec or the colour variations between the frames of the image. Thus it is natural to understand that the high density video will have more information available compared to the less denser video data. Thus, this becomes the most prominent method for key frame extraction. Zhang et al. [7] attempted first to extract the key frames based on the colour histogram difference between the first key frame and the sub sequent frames. This idea was widely accepted due to the nature of accumulating the effects of object motion or camera motion. This proposal was enhanced by Gunsel and Tekalp [2] by enhancing the threshold based key frame selection method and demonstrated significant improvements. Another direction of the same research is to cluster the frames based on the colour depth and further extract the significant frames from each cluster groups in order to formulate the key frame sequence. This proposal was first proposed by Hanjalic and Zhang [1]. Nevertheless, the selection of the significant frame for each cluster was criticised by various parallel researches and encountered with a modified approach of selecting the significant frame by trial methods. Zhuang et al. [21] proposes a method for selecting the significant frame for each cluster by first assuming the centroid frame and then adjust the frame by comparing the threshold values with other frames. The end result of this process is to generate the key frame with actual mid threshold value. Also, various other research attempts demonstrate the use of motion metric to detect the key frame based on the local minima of the time function on the optical key flow. The work by Wolf [17] demonstrates the key frame selection process by using motion analysis for the first time. This work was motivated by the work by Gresle and Huang [13]. The work by Gresle and Huang proposed a key frame selection algorithm by analysing the activities in each frame.
Conversely, the key frame extraction process is also presented from a different dimension by various researchers. The studies from these parallel researches are focused on the capture device specifications and benefits. The method demonstrated by Liu and Zhao [4] utilizes I frames, P frames and B frames for extracting the key frames. This method demonstrated higher robustness in the process. Another approach is to detect the key frames based on a provided predefined summery of similar images. This process is demonstrated by Sujatha [14]. The most recent outcome from the parallel research for extracting the key frames based on the perceived motion energy by Liu et al. [15]. The work by Liu and Zhao [4] and the work of Liu et al. [15] was analysed and an attempt to combine these two approaches was made by Gargi et al. [16]. Henceforth it is natural to understand that none of the single framework provides the optimal solution to the key frame extraction problem [18, 19, 20]. Thus, this work proposes a framework for video key frame extraction.
The result of the work is furnishing such as the outcomes from the parallel researches are been compared and analysed in Section 2. The statistics behind the motivation of the research is furnished in terms of consumer video statistics in the Section 3. The proposed framework for key frame extraction is elaborated in the Section 4 and the algorithm deployed for the key frame extraction on the framework is demonstrated in Section 5. In Section 6 the mathematical model is formulated; this work enhances a regular dataset for the establishing the proposed method. The analysis of the dataset is carried out and presented in the Section 7. The proposed method is compared with the existing framework based on architecture, time complexity, network load and data replication control analysis and the findings are furnished in the Section 8. The results obtained from this method is elaborated and analysed in the Section 9. The conclusion of the work is presented in the Section 10.
Parallel research outcomes
Many of the algorithms have been proposed for key frame extraction from videos. These traditional algorithms combine the functionalities of key frame identification and object detection to guarantee that the extracted key frames contain valid information about specified objects.
In general, the key frame extraction process is done in the following ways.
Sample frames
A sample frame is a frame which is considered as a reference frame to extract relevant key frames in a motion video. Identification of such sample frames is very easy and simple but the algorithms which use this technique will not effectively represent some significant contents and semantic patterns in a frame.
Curvature interpretation
Some image processing techniques represent each frame as a group of points in the feature space. These points are sequentially connected to form an arbitrary shaped curve. The traditional approaches use sequential information for curve simplification and key frame extraction. The main limitation of these approaches is that optimization of curve representation. Different metrics are also proposed for curve simplification by the discrete shape evolution algorithms.
Clustering
Clustering extracts the similar objects into a group. Clustering algorithms are used in image and video retrieval algorithms to identify key frames. The frames which are closest to the cluster centres are to be considered as the key frames. The main advantage of the clustering-based algorithms is that they can use global characteristics of a video can be inherited by the extracted key frames.
Even though clustering techniques performing better in key frame extraction, but there are certain limitations in attainment of semantically meaningful clusters, especially for high dimensional data and sequential nature of video frames.
This work performs
Sequential vs. global characteristic comparisons
Recent works on video processing, focusing more on sequential and global characteristics to distinguish key frames from the extracted frames from a video. Every key frame is sequentially compared with every extracted frame until a frame which is very different from the key frame is obtained. This new frame is selected as the next key frame.
The characteristics of the sequential comparison algorithms include their simplicity, perception, low computational complexity. However, these algorithms are less utilised because of the extracted key frames represent only local specifications of the video rather than the global specifications. So, there is a huge chance of data replication.
Other side, some algorithms use global characteristics of a key frame by minimizing a predefined objective function based on the application.
The characteristics of the global comparison algorithms include temporal variance, coverage, and correlation and reconstruction error.
Temporal variance
Variance is an important parameter to be considered while extracting a key frame from each video segment. There should be an equal temporal variance exist between the each extracted key frame. The objective function can be selected as the sum of differences between temporal variances of all the segments. The temporal variance in a video can be approximated by the cumulative change of contents across consecutive frames in the segment or by the difference between the first and last frames in the segment.
Maximum coverage
Capturing objects in a motion video is a complex task. To confine that key frame extraction is a best of representation for object identification. There is no fixed limitation for extraction of key frames. Traditional algorithms minimize the number of key frames subject to a predefined reliability criterion. These algorithms extract key frames by maximizing their representation coverage, which is the number of frames that the key frames can represent.
Minimum correlation
Few algorithms minimize the sum of correlations between key frames, making key frames as uncorrelated with each other as possible. For instance, represent frames their correlations using a directed weighted graph. The shortest path in the graph is found and the vertices in the shortest path which corresponds to minimum correlation between frames entitle as the key frames.
Minimum reconstruction error
Another set of algorithms extract key frames to minimize the sum of the differences between each frame and its corresponding predicted frame reconstructed from the set of key frames using interpolation. The set of key frames extracted by considering global characteristics are more concise and less redundant than that produced by the sequential comparison-based algorithms. The limitation of the global comparison-based algorithms is that they are more computationally expensive than the sequential comparison-based algorithms.
Further, the detailed analysis of the parallel research outcomes has contributed toward building a guardrail in this work demonstrating few key points to be done and not to be done while building a key frame extraction framework or an algorithm (Table 1).
Parallel research outcome review conclusion
Parallel research outcome review conclusion
The proposed framework can overcome the shortcomings identified and the detail analysis is provided further sections.
The video data is comprising of contents where sometimes the content is mixed with people’s expression and sometimes only with the objects. Henceforth, it is a prime task to understand the distribution of the content over these two categories. Also, the understanding of the content length and motion factors of the objects in the video and capture devices. This will certainly help in building a much robust algorithm for key frame extraction (Table 2).
Consumer video data analysis
Consumer video data analysis
Subsequently these learning are the plan rules for structure the system and the calculation, showed in the following stage.
The proposed structure is a mechanized system for extraction of the key edges. The oddity of the system is to extricate the diminished number of casings with least time unpredictability. Likewise, this system gives a work in video catching and video adjustment part. The accessible connection specialist is equipped for modifying limit amid correlation and can learn dependent on the video types. The parts of the proposed structure are expounded here (Fig. 1).
Capture library parameters
Capture library parameters
The proposed framework.
The capture code agent in the framework is responsible for capturing the video from various internet sources as programmed. Firstly, this component detects the native nature of the video and loads the appropriate library from the driver library associated with the capture module. Secondly, the frame size of the video after capturing is defined and the stream capture object is made ready. Further, the native socket connection is established and the video from the source URL is captured. Before writing the capture video from the source into the local machine, the header for the video with the metadata information in written in the local buffer then stored into the local video repository.
Capture library
This static component of the framework houses the library and recommendation system for the video stabilization and key frame extraction processes. The extracted metadata from the capture code agent is utilized by this agent and provides further recommendation in order to reduce the overall time complexity of the algorithm. The parameters in the video library are elaborated here (Table 3).
Video stabilization
After the capturing process and the library metadata analysis of the videos, the next agent in the framework performs the video stabilization process. During the video stabilization process, from the initial frames the reflexive points are extracted and compared with the subsequent frames. After the initial sets of points are extracted, then the relative points are measured. Based on the differences between the reflexive point and the relative point, the points are shifted to the relative average points. The result of this process is the stabilized video.
Key frame extraction agent
The one of major components of this framework is the key frame extraction agent. The agent calculates the total threshold of the video. The calculated threshold then compared with the per frame threshold and based on the compared result, the key frame is been selected.
Correlation analysis agent
The correlation agent controls the replications after the key frames are extracted. The correlation agent firstly converts the image into the binary images thus resulting into the two-dimensional images. Further the converted images are compared based on the correlation of the objects. The duplicated key frames are rejected, and the unique key frames are finally reported to the reporting agent.
Key frame reporting agent
The final UI agent of the framework is the visual representation of the images. The final key frames are presented to the end users.
Performance analyser
The internal framework agent called performance analyser calculates the CPU time for each phase of the algorithm and performs the overall time complexity analysis. This analysis helps the framework to identify the agents which are under performing, thus making the framework adaptive and continuously enhancing.
Proposed algorithm
The proposed algorithm is the prime component of the novel proposed framework and the algorithm is furnished here.
Mathematical model for the solution
In this section of the work, the mathematical model for the solution is formulated here.
Firstly, the video signal is considered to be the input for this process and represented as,
where,
Natural to understand, that the image collaboration function is a general representation of image sequences, thus
The improvement demonstrated in this work, compared to the existing key frame extraction method is the consideration of local and global thresholds for identification of key frames. This work proposes to calculate the global threshold by usual apprehension and calculate the local threshold for each class or the group or the clusters of the images.
In order to calculate the local threshold, it is important to extract frames from the video signal and classify the images or frames.
Here,
Further, the detection of objects in each frame based on the characteristics set is performed.
And
Here,
After the calculation of the objectsets for each image frame, this work calculates the number of objects and subsequently labels the objects for each class.
Hence, any image class for image
Once the clustering of the images are completed, this work calculates the local threshold for each class and the global threshold for the complete video.
The local threshold considered as
Here, it is prominent to understand that the median set of values for each parameter in the feature set is the realization factor of the threshold.
Thus, the global threshold considered as
Here, the natural combination of all the image classes and the natural distribution of the local thresholds are considered.
Finally, the key frame extraction process is relatively adaptive and based on the content, which separated the images into various clusters or classes.
For realizing the complete process, this work also furnishes the process here (Fig. 2).
This framework and the algorithm are rigorously tested on the following data (Table 4).
Analysis of the testing dataset
Analysis of the testing dataset
Schematic process of key frame extraction.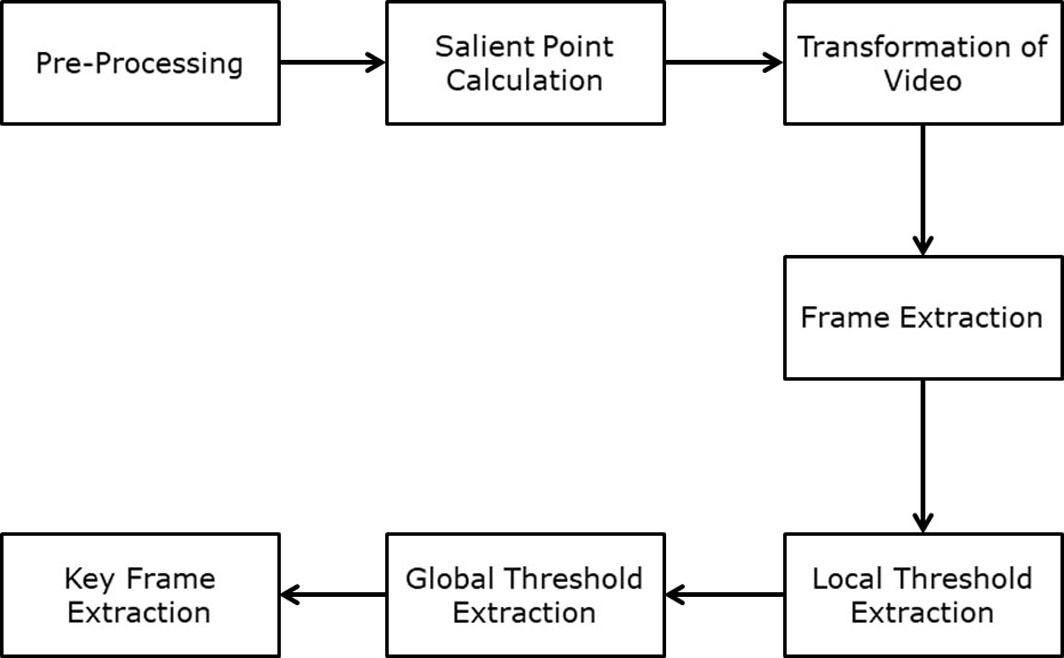
The dataset is comprised on three different categories and with multiple videos with different lengths. The videos are with 24 FPS.
The results of the algorithm and the framework execution on the mentioned dataset are furnished in the further section of this work.
In order to understand the performance of the proposed framework and advancements over the other parallel research outcomes, this work compares the proposed framework with the parallel outcomes on the basis of framework architecture, time complexity analysis, and network load analysis and data replication controls.
Framework comparison
Firstly, the analyses of the framework architecture in terms of the drawbacks identified are listed from the knowledge of parallel research outcome analysis. Further the shortcomings are been supplemented by the advantages of this framework (Table 5).
Deep analysis on the proposed framework for bottlenecks
Deep analysis on the proposed framework for bottlenecks
The time complexity is a key factor of evaluation for any key frame extraction process and the time complexities for each dataset is analysed here (Table 6).
Time comparison analysis
Time comparison analysis
Hence it is natural to understand that the proposed algorithm is faster than majority of the methods.
The re-enactment of the structure is completed on an independent framework without system segments. In any case, the number of key edges separated from the video is transmitted over the system and produces the system load. The created system burden will give the examination of the system burdens or exercises (Table 7).
Network load analysis
Network load analysis
The analysis demonstrates the higher load in case of the outdoor videos. Nevertheless, for the animated and indoor videos the network load is reduced significantly.
As expressed by the calculation in this work, the replication control is likewise been taken consideration amid the extraction of key edge process. This is considered one of the real results of the work. From this time forward, the similar investigation of the information or key edge replication control is outfitted here (Table 8).
Data replication analysis [16]
Data replication analysis [16]
The advantages of the proposed algorithm are discussed in the prior sections of this work.
In order to justify the correctness of the algorithms and the improvements obtained by the proposed framework, in this section of the work, the algorithm and the framework is tested on standard TREC Video Retrieval Test Collection, 2015 (Table 9).
Key frame extraction on standard dataset
Key frame extraction on standard dataset
Thus, with the awareness of the improvements specified in this section over the parallel researches, this work presents the results of this framework in the next section.
Firstly, the frame separation process outcomes are showcased (Table 10).
Frame separation process
Frame separation process
The results are analysed visually (Fig. 3). The result demonstrates that the nature of the video is significantly reflected in the number of frames separated from the video. This improvement is due to the availability of the capture library in the framework.
Secondly, the threshold analysis results are pictured (Table 11).
Mean, std. dev and threshold analysis
The result is analysed visually (Fig. 4).
Furthermore, the analysis of the number of key frame selection process is analysed (Table 12).
Key frame selection
The results are analysed graphically (Fig. 5).
Next, the accuracy in terms of key frame selection and rejection based on correlation analysis is been furnished here (Table 13).
Key frame accuracy
Frame separation process outcomes.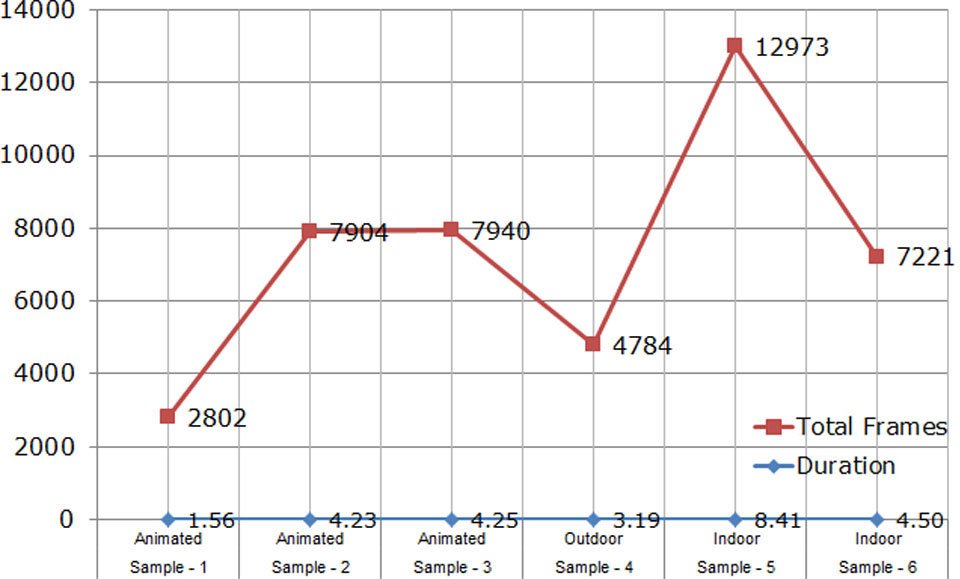
Threshold analysis of the video data.
Finally, the analysis of the time complexity results is furnished (Table 14).
Time complexity analysis
Key frame extraction (%).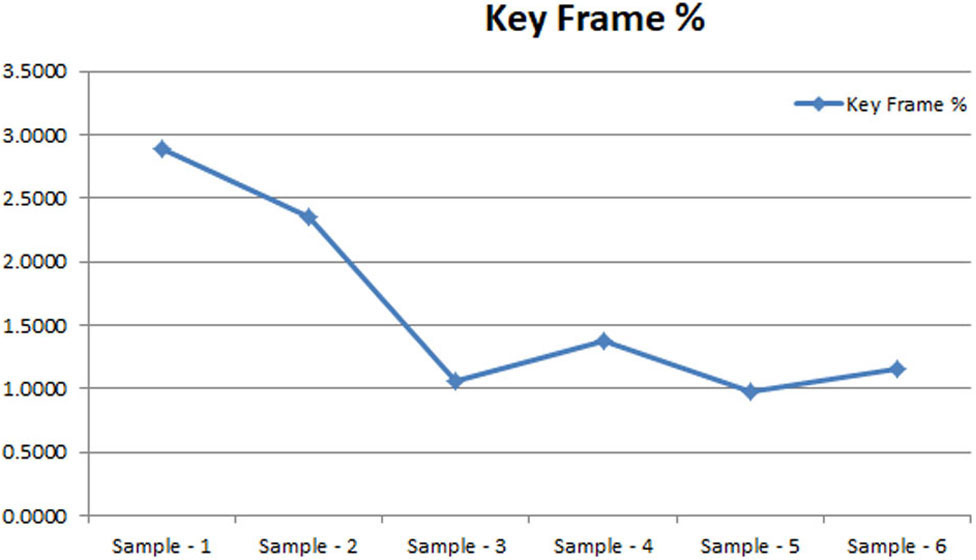
The comparative analysis demonstrates significant improvements over the parallel research outcomes by this work. Henceforth, with this improvement acknowledgement, in the next section of this work, the final research conclusion is presented.
The data extraction from the video information or the video outline is the most significant procedure. This work assesses the prevalent parallel results from the ongoing examines and builds up the enhancements in the proposed system. This work shows a 100% precision of the key casing extraction and lessens the time multifaceted nature. The decreases in the system burden and replication proportion of the key casings are likewise one of the striking results of this work. The proposition from the structure of including the extraction library is incorporated as recommender framework into the work and shows the huge enhancements for key casing extraction independent of the video length rather on the substance type. This is made conceivable because of another idea of consideration of metadata extraction process and joining that data amid the edge division process. With the essentially acceptable outcomes this work establishes the frameworks for further investigation of data extraction from the key casing and supports the video ordering and data recovery forms for improving the data portrayal for the science.