
Abstract
The prerequisite steps for summarizing, retrieval of video are detection of shot transitions and extraction of key frames. We hypothesized an advanced, ultra-modern Scale Invariant Feature Transform (SIFT). This SIFT method captures statistical modifications of various shot transitions, next the key frames or representative frames are extracted from those segmented shot with the calculation of entropy for each frame in the shot. We can amplify the performance of over proposed system by removing the repeated representative frames using the technique called edge matching rate. This intensified algorithm is applied to variable classes of videos to perceive shot transitions and getting of the key frame. Thus, the proposed algorithm proves its efficacy and accuracy in exhibiting its experimental results.
Keywords
Introduction
Presently, there’s been a fabulous expansion in the quantity of video database due to the accessibility of the number of video recording equipment’s, which are available at affordable expenses of storage memory devices and utilization of high speed communication services. So, a complex and effective video data base system is necessary for retrieving, browsing and searching [1, 2]. We retrieve videos in the current video database system by considering text or description. It engages a plenty of time of the user and requires man power. To cross this hurdle, an advanced video retrieval system is required based on its content [3]. Recognition of Shot transitions and getting representative frames are the crucial steps in video retrieval [4]. Shot is defined as the continuous frames that are captured in between the on and off button of the camera. A shot border differentiates two successive shots of a video. A border of a shot is classified as cut border and gradual border. The detection of shot transition is a significant step in indexing, classifying, summing up and retrieving videos [5, 16]. Therefore, a pattern change in shot border detection studies has occurred in research. There were many algorithms created to allow the objective above. These are block-based border detection, the process based on pixels and technique based on histograms. In pixel feature extraction process [6], correlating with pixels in order of the pictures is equated. Since it is arithmetically simple it saves time. Its disadvantage is if incase of any small shake in the camera or in the object also affects the result. Ultimately, it shows dissimilarity between two similar consecutive frames. Even in case of small illumination of the object also results in dissimilarity. Block based detection of shot transition [7]; each picture is split into multiple blocks. The respective successive frames of each adjacent block are compared and evaluated. Compared to pixel-based technique, this technique provides better outcomes. But the technique of identification of shot boundaries based on blocking is slow owing to computation or execution difficulties. This technique is also unable to define the items that move quickly. Detection of shot boundaries based on histogram [8, 17]; this method utilizes the statistical illustration of potency values. It overcomes the disturbances like translation, rotation and motion in the camera [18]. Its main drawback is it does not give accurate results when any two dissimilar frames represent similar color combination [29]. To prevail over the drawbacks of existing algorithms, in this paper we have hypothesized an unconventional methodology in detecting the shot boundaries using the technique SIFT i.e., Scale Invariant Feature Transform. It is vigorous, accurate and invariant to noise; picture scaling, picture rotation and changes in brightness [9, 28]. The shot border detection is the initial stage in video abstraction and followed by key frame extraction. Representative frame extraction reflects the shot’s notable data and abstracts the remainder of the frames features. It neglects or eliminates repeated information that in turn decreases data for video retrieval. The entropy value of all the pictures in every shot is computed in this suggested algorithm. As key frames, the frame that has distinct entropy value is subjected. This eliminates the redundant key frames by using the edge matching rate method yields the ultimate representative frames [10, 19]. Remaining paper is sectionalized below: Section 2 discusses shot boundary detection, Section 3 deals with key frame extraction, and Section 4 shows the framework of over proposed method. Section 5 covers the results of over experiment and lastly Section 6 leads to the conclusion.
Shot boundary detection
A shot is termed with the help of a single camera as the sequence of successive pictures of continually recorded video. Basing on the similarity and dissimilarity of the video, the shot boundary divided into two consecutive shots. Cut boundary and gradual boundary are the two classifications of a shot boundary [11, 20]. A cut boundary is defined as the quick transform from a shot to succeeding shot. There is a cut between the first shot’s end frame and the second shot’s start frame. There is a continuing transition between more frames [21]. To detect the shots, feature extraction has to be done to verify the similarity and dissimilarity between two frames of a video. We have proposed a technique called SIFT for the creation of feature vector in a video [12].
Scale Invariant Feature Transform
It is an efficient and powerful feature extraction algorithm for frame matching. It is a robust algorithm for object matching from a huge database. It is an accurate and reliable algorithm and it is in variant to changes in lighting, motion, object movement and picture scaling and also invariant to mixing of any unwanted noise. It comprises of 4 phases: ‘Recognition of Scale-Space Extreme’, ‘Exact Key Point Localization’, ‘Orientation Assignment’ and ‘Descriptor Illustration’ [22].
Recognition of Scale-Space Extreme
In this phase, we perceive attentiveness points or isolated points in the scale space of a picture or frame. These detected, isolated points are known as key points of the frame and these key points acts as a feature of that image. By smearing the local extreme of difference of Gaussian (DoG) space in the image, the key points are acquired. From Eq. (1), we can acquire DoG scale space.
In this phase, the place and scale of the main point candidate are determined. Be contingent on the stability measurement, key points are selected. By taking out small intensity and noise-influenced key points, exact key points are obtained.
Orientation assignment
Here, to build the descriptor invariant to rotation, we allocate an orientation to each of the main points. To calculate the orientation of a key point, the angle histogram of local gradients from the closest smoothed picture
The 360-degree orientation histogram of the main axis with thirty-six bins.
Each and every key point of a local image gives a gradient data which results a descriptor. Here we consider a 16
Generation of key point descriptors in 16 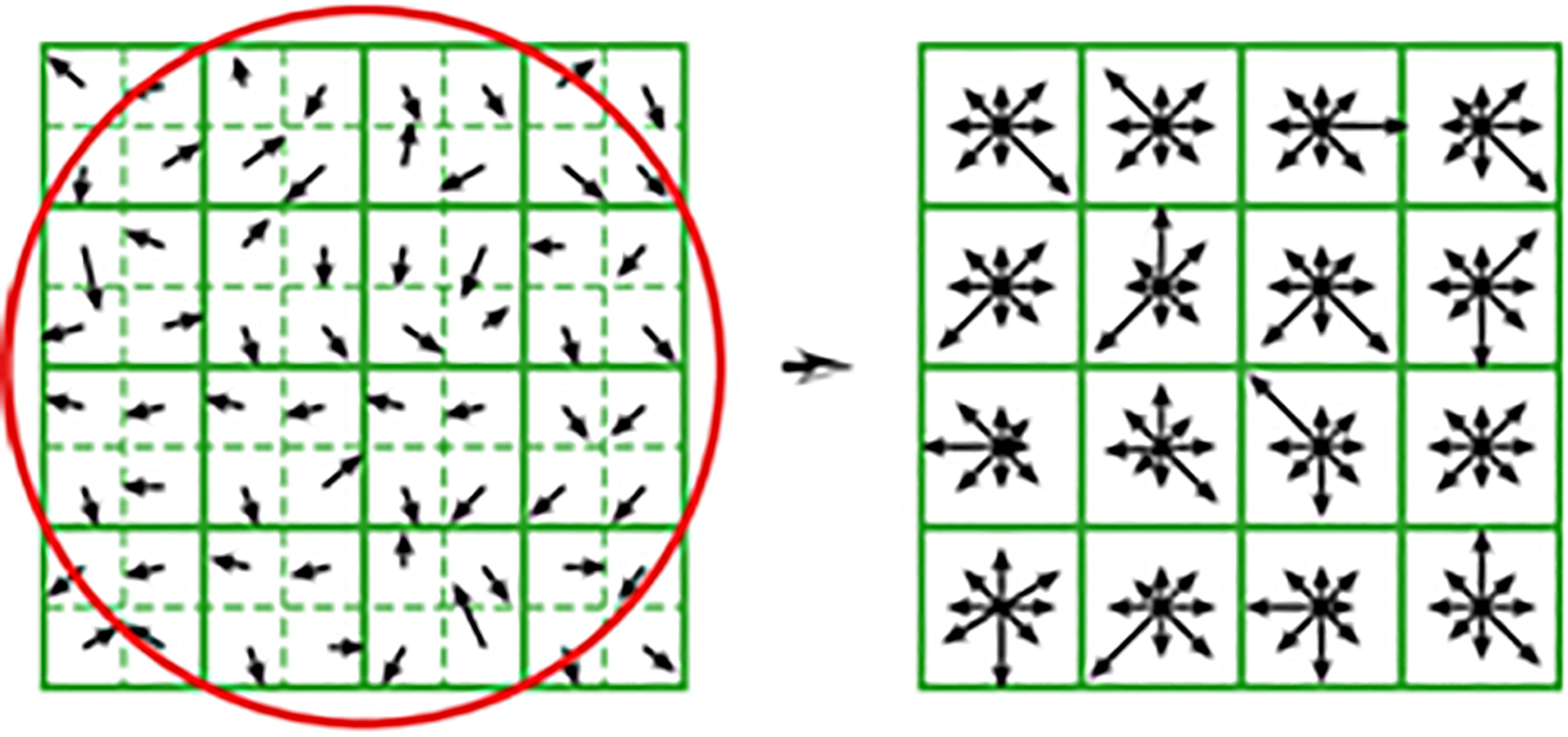
Matching of key points.
By using k-Nearest Neighbor (kNN) search, the main points in the present picture are correlated to that of the subsequent picture. If the main point has a smallest difference from Euclidean, it is said as closest neighbor. K-Nearest Neighbor exploration process is one of the easiest algorithms in machine learning. K-Nearest Neighbor relies on the range from Euclidean to determine if the main points of the present image match those of the following picture [14]. Euclidean distance is a method measuring the difference between two vectors of features [24].
When matching the main points in two frames, the lines between the corresponding main points are traced. If there is less than 0.6 in the detachment between any 2 key points, the match is accepted. Figure 2 shows a main point matching instance. If the quantity of coordinated key points is larger than the threshold value between any 2 images, these two images are correlated to the same region. Otherwise the boundary of the shot will be identified.
In the process of the video retrieval Representative frame extraction places a significant role. The other names for a key frame are selective or representative frame [25]. It consists of necessary data of the shot and synopsizes the physiognomies of the remaining frames. It removes duplication data and diminutions data quantities for indexing and video retrieval.
Computation of entropy
Entropy of picture data is a method that indicates the amount of data in a picture [15, 26]. To extract representative frames, each frame in the shot is evaluated with information entropy. The computations of information entropy for a picture are outlined in Eq. (7).
Here,
The frames with distinct entropy values are regarded as important frames [27]. The representative frames are not comparable in a particular shot in this phase. If the other shots are taken into account, comparable key frames can result. Entropy is dependent on the distribution of the gray level image. Both comparable frames may have distinct gray levels, which can lead to redundant representative frames.
The precision and recall values for various kinds of videos
The objective of this method is to remove the redundant, irrelevant, unnecessary key frames to avoid duplications. Method for removing the repeated selected frames is used in Edge Matching Rate. The final representative frames are eventually obtained. The quantity of false key frames depends on the nature of that particular video. The redundancy of false key frames is more in news videos when compared with movies, cartoons and animated videos. Here Prewitt operation is done to compare the edges of the key frames and eliminate the unnecessary key frames. The next step is to compare the top of the key frame candidate to the other key frame candidate. A threshold to control resemblance or dissimilarity shall be provided to the Edge matching rate. The representative frames are comparable if the correlation is higher than the matching rate. From the total key frames the redundant key frames are eliminated and the remaining are ultimate representative frames. The below points explains the mechanism.
Put on Prewitt operator on the candidate representative frames to detect edges. To compute the Edge Matching rate between 2 key frames with the use of Euclidean difference. A cut-off value is assigned for similarity corresponding. We compare edge matching rate between 2 candidate pictures, if matching is less than cut-off value then both are the ultimate key frames otherwise one of the key frames is treated as a redundant key frame. The previous step is repeated for all ultimate key frames. If we remove all the redundant key frames then the rest of the frames are the ultimate key frames.
Here we represent the step by step methodology to apply over hypothesized method as shown in Fig. 3.
Proposed algorithm
From video dataset, take a video as an input. From that video all the sequence of frames are being extracted. For each frame, feature vectors are obtained using a method called SIFT. To detect the shot transitions, the key points from the current frames are equated by the successive frame. To extract representative frames from each shot, we use the technique known as the Image Information Entropy method. Depending on the threshold values of each frame are obtained by using Edge Matching Rate, which helps in eliminating the false key frames.
Framework for the proposed method.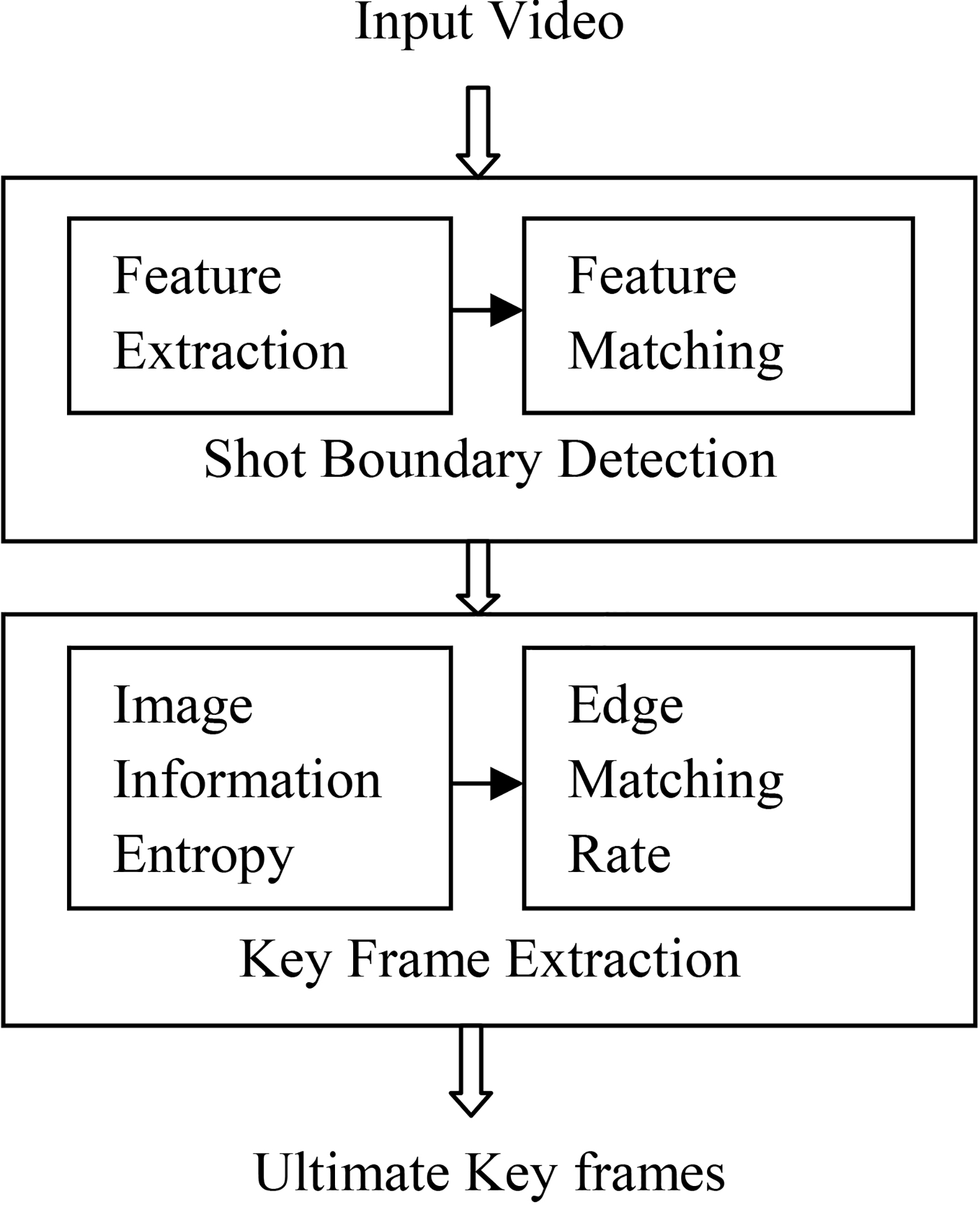
The extracted shot transitions, representative frames and ultimate key frames
Measurement of the performance of the suggested technique using current techniques.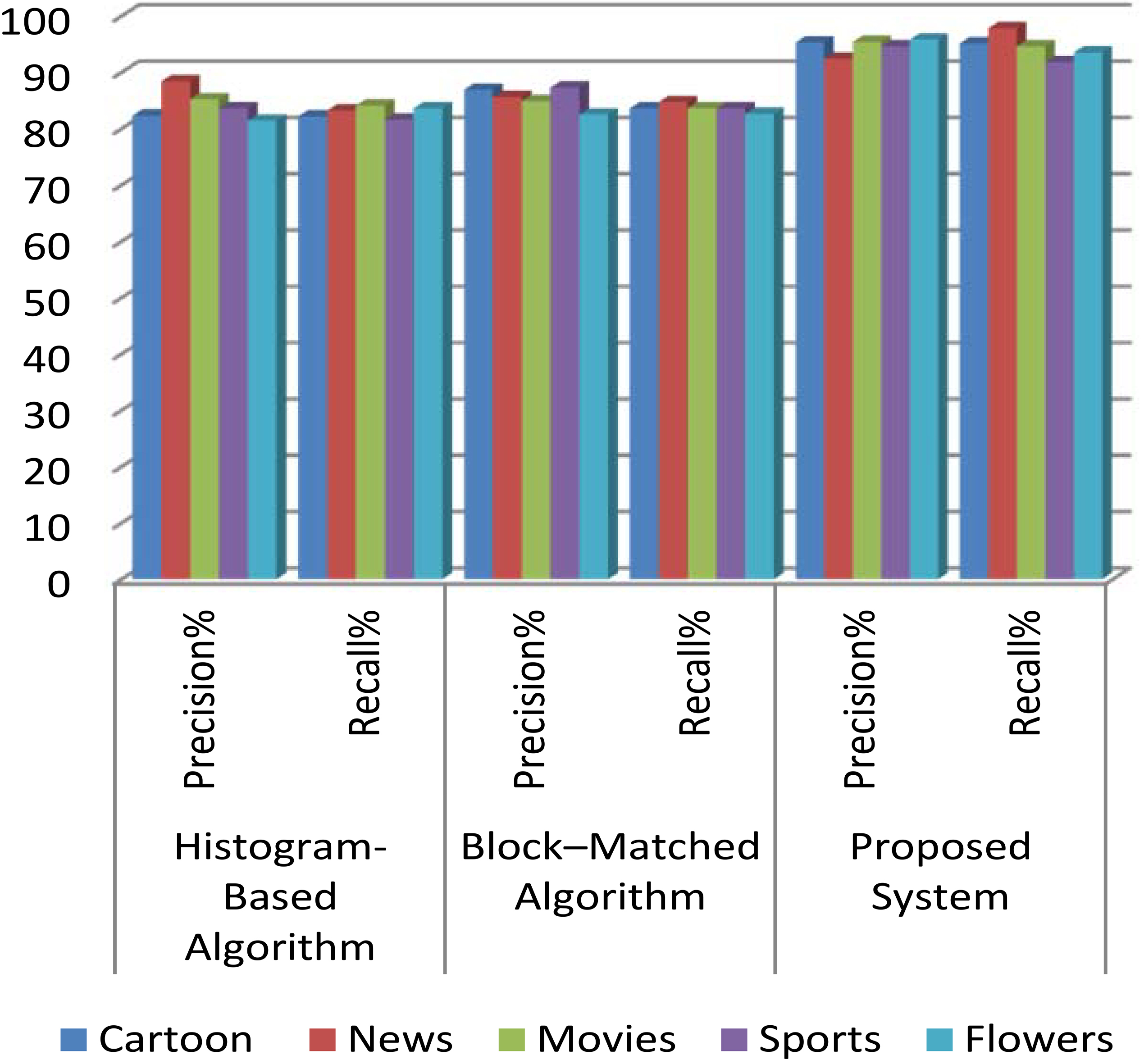
The key frames of the candidate obtained from the flower video.
Extracted the ultimate representative frames without false frames.
The proposed algorithm uses two essential techniques. Those are SIFT and Image information entropy for shot border detection and extraction of representative frames respectively. To examine the performance of this algorithm, 5 classes of videos from the video data set viz cartoon, news, movies, sports and floral videos are taken. By using SIFT algorithm the shot boundary detection is obtained and the performance is estimated by considering the value of precision and recall.
The experimental outcomes prove that the proposed technique gives well efficacy when equated with the existing method in Table 1.
The hypothesized shot transition detection method showing extraordinary recall and precision values. So, this shows that the hypothesized system yields the most accurate results when compared to the existing methods as shown in Fig. 4.
The below table shows the sort of videos that are regarded, the complete number of frames in each video, the amount of shot transitions identified, the amount of candidates, representative frames obtained and the amount of ultimate key frames shown in the Table 2 after eliminating the redundant videos.
The extracted candidate key frames from the flower category video are represented in Fig. 5. The quantity of ultimate key frames is represented in Fig. 6 which are obtained by excluding the repeated key frames by using edge matchng rate technique. This algorithm results in high efficacy and less redundancy from the proposed system.
In the proposed algorithm, SIFT technique is used for detection of shot transitions. It is invariant to picture scaling, variation in brightness, rotation and adding of noise. The main drawback in the existing algorithms is extraction of redundant representative frames. Here the repeated representative frames are removed by using the technique edge matching rate in over proposed algorithm. So, the proposed algorithm overcomes the above drawback by using these techniques and this algorithm gives a high value of precision and a high value of recall rate. Hence it is effective and strong.
In this paper, the major steps are shot boundary detection which is done by the SIFT technique followed by key frame extraction and it is done by using the technique called Image Information Entropy values. Next, repeated key frames are removed by using edge matching rate method and after eliminating the redundant videos we attain the ultimate representative frames. They strengthens the outcomes and improves the performance and shows robustness and accuracy of the hypothesized framework. The two steps detection of shot transition and keyframe extraction are obtained efficiently and allow the algorithm to function/perform properly in the process of retrieving the video.