
Abstract
High Utility Itemset Mining (HUIM) is playing an important role in extracting meaningful knowledge that is profitable itemsets rather than their occurrence frequency. HUIM result thrives into a huge number of utility itemsets that makes it difficult in decision policy. The alternative procedure is condensed representation of HUI’s that contains utility itemsets without any redundancy. Closed High Utility Itemsets (CHUI) and High Utility Generators (HUG) are lossless utility itemsets useful in recommendation systems. In this paper, we address how to extract Closed and Generator HUI’s from the given dataset. For faster accessing, it is proposed hash based technique that store itemsets with the frequency, utility value, closed flag, and generator flag. Experimental results shows that it outperforms other approaches in time and space.
Introduction
Frequent Itemset Mining (FIM) [5] and Association Rule Mining (ARM) [1, 2, 15] are playing an important role in deriving hidden and important knowledge. Traditional FIM’s considers the occurrence of itemsets in database, rather than its importance. It has been investigated extensively to Weighted Itemset Mining and Weighted Association Rule Mining. But such kind of knowledge is not exception to FIM limitations such are (i) value of the pattern is not considered due to frequency based framework (ii) relative importance of each item is not considered. Such kind of knowledge can cause of losing profitable itemsets due to insufficient frequency such are named as infrequent itemsets. To address and solve the above limitations, the outcome of the investigation led to the concept of High Utility Itemset Mining (HUIM) [2, 4, 18]. The goal of HUIM is a derive itemsets that have interested utility value or high utility value, where the utility value is determined from the utility function. The utility function is defined as a product of unique profit of the item and units or quantities that carry in that instance. HUIM is more difficult task than FIM, because it doesn’t follow monotonic and anti-monotonic property. Hence, the HUIM takes huge computation for a large number of utility itemsets. It is motivated for adopting condensed representation of itemsets to HUIM, the result with many techniques for extracting Maximal HUIM [21]. Further, it has been investigated for lossless condensed representation of utility itemsets, result with the concept of Closed HUIM and Generators [7]. It has been investigated to derive various kinds of knowledge such are incremental mining of HUIM [24]. Consider the sample database from Table 1, where each item is recorded with its units of quantity purchase in a particular instance. Table 2 shows the utility profit values of each item. For a given utility threshold value 25, the list of high utility itemsets with their frequency are shown in Table 2. It can be seen that Itemsets
Sample quantitative database
Sample quantitative database
Utility table
In this paper, we address the importance of Closed HUI’s and High Utility Generators, and approaches for deriving same thing from the quantitative databases. The main contributions of this paper are
Hash based data structure for keeping High Utility Itemsets of HUIM. Efficient approaches for deriving CHUI’s and HUG from the output of HUIM. Measuring the performance of the proposed approach.
The rest of the paper is organized as, we present the highlights and limitations of the techniques that are related to HUIM, CHUI, and generators in related works. We present basic definitions that are related to the problem statement in next chapter. We also describe the proposed method for CHUI’s and HUG. To examine the performance of the proposed approach, we present both theoretical results and practical result analysis.
Several approaches have been proposed for HUIM such are classified as (i) Apriori based approaches (ii) Tree based approaches (iii) Projection based approaches (iv) Hybrid approaches.
(i) Apriori based approaches
Liu et al. [13] proposed Two-phase algorithm, where all the possible high utility itemsets are explored in first step, and utility of the possible itemsets are calculated by scanning the database. One of the main contribution is Transaction Weighted Down-ward Closure (TWDC), is replica of Apriori property, to reduce the search space by reducing the maximum upper bound to its TWDC. To exhibit downward closure property, Yao and Hamilton [23] proposed UMining and UMining_H algorithms to discover HU itemsets.
(ii) Tree based approaches [14]
To address the limitations of Level-wise candidate generation based approaches of HUIM, Tree based and Pattern-growth approaches are introduced. Tseng et al. [11, 20] introduced more compressed tree UP-tree that can represent all the itemsets in structure format. He has proposed UP-Growth algorithm to mine High utililty itemset using UP-tree. To overcome the difficulties of UP-Growth [20], minimal node utility values are introduced in each path of UP-tree, is named as UP-Growth
(iii) Projection based approaches
To overcome the limitations of tree based approaches that is recursive visit of the same tree to derive all the high utility itemsets Lan et al. [9, 10, 19] proposed PBAU (Parojection-Based Average Utility) approach to mine high average utility itemsets. It uses a measure called average utility.
(iv) Hybrid approaches [12]
The above approaches derive HUIs either in K-passes or two passes. In real time applications, it is needed that running algorithm should meet the application data. Hence, it is motivated the researches to propose a Single Phase algorithms. One of the algorithm is HUI-miner [13]. It uses Utility-list structure to keep the item occurrence information and remaining utility information. Fournier-Viger et al. [6] proposed FHM algorithm. It uses estimated utility co-occurrence structure (EUCS) structure to avoid join operations. To discover HUIs more efficiently, EFIM algorithm is proposed [8]. To reduce the database scans, projection method HDP HTM (High Utility merging) is used in EFIM. Thus, it outperforms other approaches by reducing execution and space to linear.
High utility itemset mining
For a given data set
For example, the utility of item
HUIM is a defined as, it is process of discovering itemsets whose utility is not less than the minutil that is given by the user. HUIM process derives all High Utility Itemsets with the help of Definition 5, Definition 4 and others subsequently. It takes more search space to maintain all possible itemsets, because lack of downward closure property.
To reduce the memory space, the following Definition 5 is used to find the upper bound of the utility of item in a database QDB.
For example,
For example,
In other words, it can be defined it is high if the utility of an itemset in database is not less than minutil as mentioned in Definition 8 or Eq. (4).
For a large databases, HUIM delivers into huge itemsets. One of the goal of data mining that is it should not contain any redundancies. To tackle this issue, Definitions 9 and 10 are defined below.
Huge number of HUIM motivated researches to look at the size without any redundancy. It was the reason for Closed [3, 7, 10], Maximal [14] and Generator HUIM [3]. They tried to extract concise representation at the time of HUIM with additional time for visiting data structure. Mai et al. [8] proposed a post pruning technique to derive closed high utility itemsets. Lattice is used to represent HUI’s and Closed HUI’s which takes additional time for constructing lattice. In this paper, we assume that High utility itemsets are known, and try to determine Closed and Generators from the same single closure check.
Approaches for lossless condensed representations of HUIM
In this section, we discuss the approaches for CHUIM and Generators. At first, we discuss naïve approach for CHUIM and HUGM with its limitations, and then discuss the proposed approach.
Naïve approach for Closed Utility Itemsets
In this section, we discuss the general or Naïve approach for deriving Closed and Generator HUI’s. This approach takes High Utility Itemsets as input and discovers closed and generators high utility itemsets. The procedure is presented in steps as follows.
for each utility itemset, using Definition 9, check is there any itemset that is super set and having equal occurrence frequency. if there is any super set, then the current one is not considered as closed. If none of them are identified as superset, then the current itemset is considered as Closed.
Repeat Steps 1 and 2 for all the utility itemsets.
If there are
for each a utility itemset, using the Definition 10, check is there any utility itemset that is sub set and having equal occurrence frequency. if there is any sub set, then the current one is not considered as Generator. If none of them are identified as subset, then the current itemset is considered as Generator.
Repeat Steps 1 and 2 for all the utility itemsets.
If there are
It is observed from the above two approaches that, the time complexity towards double for both closures closed and generators. Hence it is motivated us to propose the following approach for deriving both in less time.
The idea for the proposed approach is to combine the above two approaches such that two operations are performed using a single condition that is either Superset or Subset check. In addition to that, we avoid some of the unnecessary computations during superset checking by checking only with one down its length.
In this section, we discuss the Hash Table based Data Structure, and then the proposed CG-Algorithm.
Hash Table Data Structure.
Basically each entry in hash table is associated with 5 fields such are Index Id, Utility value, Frequency, Closed Flag, and Generator Flag. The possible values in each entry are name of the itemset, utility value, frequency value,
Here, CG-Algorithm is proposed to find Closed High Utility Itemsets and Generators in integrated manner, such that only one closure is sufficient for both closed and generators. The input for CG-A is a list of High Utility Itemsets, and the output is Closed HUI’s and Generators. It arranges the input HUI’s are in the order of their length.
As a first step, using Definitions 9 and 10 it checks whether it is a superset of the hash contents or not. If it is found as superset, then it changes CF flag to T and GF flag to F, and subset itemset flags will be set to {F, T}. It repeats the same procedure for the rest of the utility itemsets. CG-Algorithm is presented in Algorithm 1. Lines 1 to 7 describes about inserting each utility itemset into hash data structure, changes in flags with respect to the superset closure. Line 3 inserts utility itemset into hash. Line 3 initializes 1-length utility itemsets CF, GF flags to T and T. Line 4 checks the holding UI is superset or not by calling IsSclosure() is same as Definition 9. If the holding UI is found to be superset of hash table contents and their frequency is same, then its CF is set to T and GF is set to F. lines 8 to 11 list the High Closed Utility Itemsets whose flag CF is T, and GF is set to T.
CG-Algorithm explanation for the input Table 3
List of Utility Itemsets when threshold utility value is 25
List of Utility Itemsets when threshold utility value is 25

Standard datasets with characteristics
Number of HUI, CHUI, HUG w.r.t various minimum utility, and memory usage of Naive, LHUI and CG-A
The proposed algorithm explanation for the given example Table 3 is presented in Fig. 2. For the given inputs {
For inserting an itemset into Hash Table takes O (1), for n itemsets takes O (N). Let K-itemset be the length of itemset K, N be the number of itemsets in Hash Table, and P be the number of (K-1) subsets of itemset K. For superset closure checking, CG-algorithm uses only
Therefore time complexity is O (N X P-L), which is feasible than O (N
Experimental results
In this section, we evaluate the performance of the proposed approaches Naïve and CG-Algorithm in terms of time complexity and space complexity. We have implemented CG-A in python with the configuration core I5. We carried out the performance analysis by considering various threshold values for various data sets visible in Table 5. We tested CHUI and HUIG on the standard data sets and the result is visualized in Table 5.
Chess dataset [16]: Chess dataset is recorded with 3196 instances, where 1669 instances describe that white can win and 1527 describe that white cannot win. Each instance is recorded with on average 37 attribute values which describe the board positions and class label name. Chess dataset characteristics are listed in Table 4. It can be seen that chess data set contains 6406 utility itemsets, whereas Closed and generators are 3550 and 4074. The variance in number of UIs, CHUIs, and HUIG for other datasets is visualized in Table 5. LHUI [9] lattice maintains high utility itemsets in lattice which is same as Naïve. CG-A integration approach maintains all HUI’s in Hash Table, are associated with flags that determines closed or generator. It reduces the search space when itemsets are exhibits properties of closed and generators. Hence it takes less space for both closed and generators. The runtime comparison of CG-A with other approaches are visualized in Figs 3 and 4.
Runtime comparison of Naive, LHUI and CG-A on chess.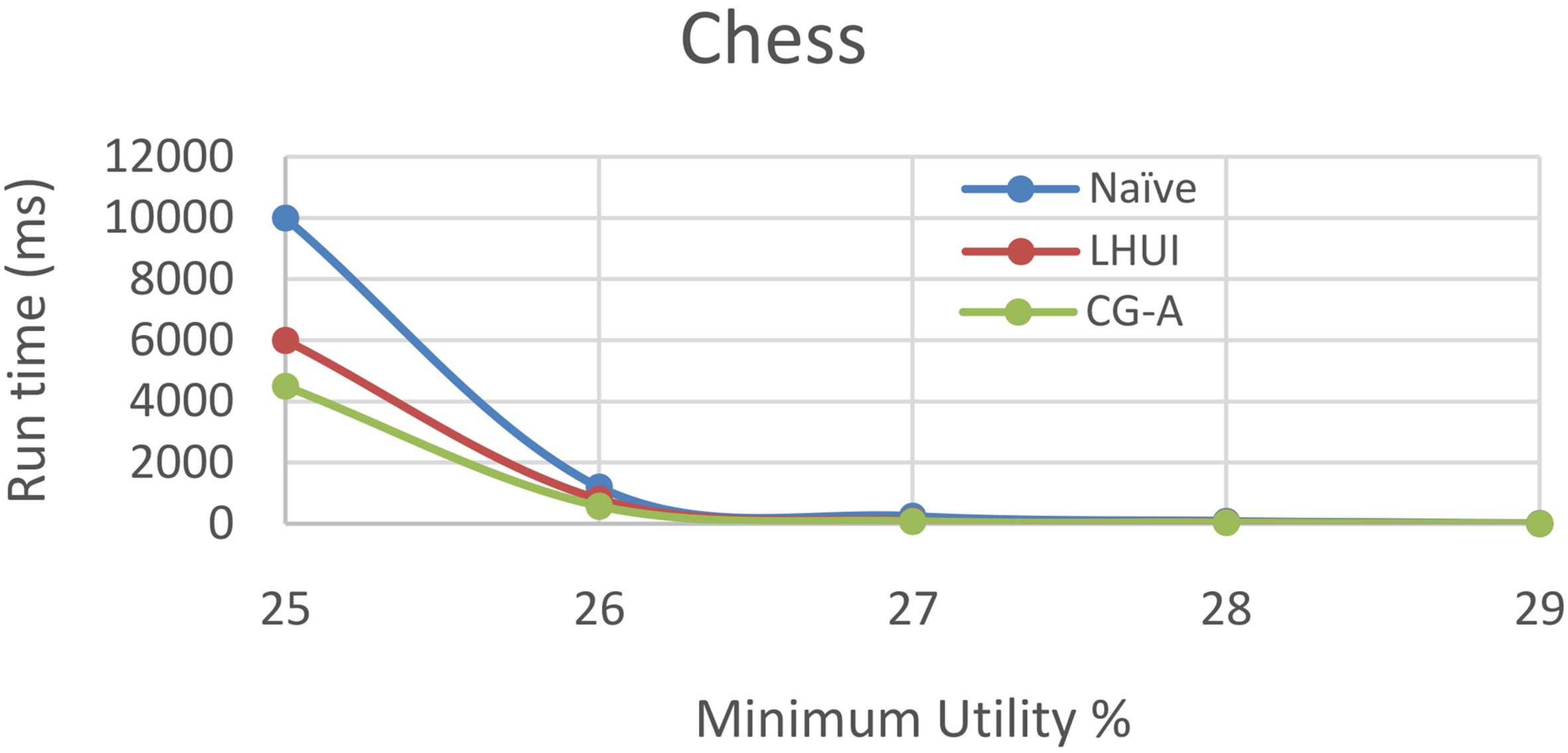
Runtime comparison of Naive, LHUI and CG-A on chain store.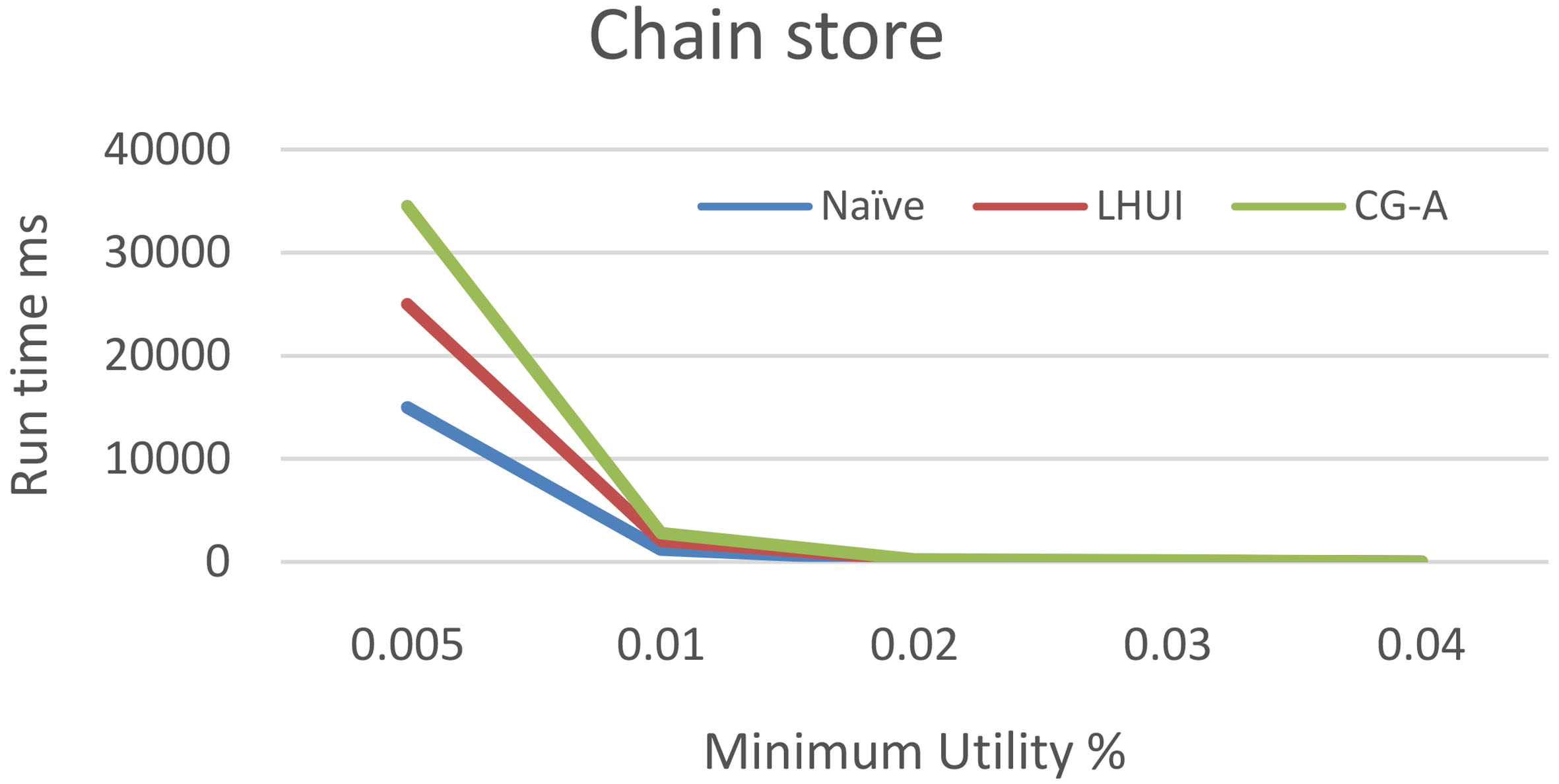
FoodMart [16]: Foodmart is recorded with 4141 instances, where each instance describe the behavior of customer transaction from a retail store. Each instance is recorded with on average 4.4 out of 1559 attributes. Hence it is registered as sparse database. The result of HUIM for the dataset of Table 4is visualized in Table 5. It can be seen that the growth in memory usage when utility threshold increases and CG-A uses less memory.
Mushroom [16]: Mushroom is recorded with 8124 instances, where each instance is a description of hypothetical samples of 23 species of gilled mushrooms in the Agaricus and Lepiota Family. It includes 4208 mushrooms are edible and 3916 are poisonous. Each instance is described an average with 15 attributes out of 119 with maximum length 25. Hence it is registered as Dense. The result of HUIM for the dataset of Table 4 is visualized in Table 5. It can be seen that the huge growth in memory usage when utility threshold increases and CG-A uses less memory.
Retail [16]: It describes the Belgian retail supermarket, which describes about the details about customer transactions. It is recorded with 88162 transactions, with 10.3 average length out of 76 maximum length. The participated products are 16470. Hence it is called as sparse database. Since the participated products are huge, it can result to a huge memory usage. It can be seen in Table 5, the change in memory usage when utility threshold increases, CG-A algorithm outperforms other approaches. The reason was the integration of closed and generators in Hash Table.
Accidents [16]: Accidents data set contains traffic accident data donated by Karolien Geurtsis, obtained from Belgian Traffic accidents. It contain information on the different circumstances in which accidents have occurred. It is recorded with 340,183 accidents as transactions, it consider 572 attributes, on average 45 attributes are considered for each accident. From the Table 4, Accident data set can be called as Dense. Because of dense property, techniques can cause huge memory usage which can be seen in Table 5.
Chainstore [16]: Chainstore dataset describe the customer transactions of retail store, which are obtained from NU-MU Bench. It is recorded with 1,112,949 sequences, having 46.086 products, with 7.2 average length. Hence it is recognized as sparse database. Figure 4 shows the running time performance of the proposed approach with other approaches when minimum utility threshold increases. Form the Fig. 4, it can be seen that CG-A outperforms other approaches.
We tested Naïve and CG-Algorithm on various datasets with various threshold values for mining closed and generators high utility itemsets. The results shown in Figs 3 and 4 tell that CG-Algorithm takes less time than Naïve approach which takes O (2 N
Conclusion
The proposed CG-Algorithm for mining CHUI and HUIG using utility confidence framework and flags that determines closure is closed or generator. The integration mechanism derives closed and generators for the same closure. Hash based data structure is used to maintain high utility itemsets. The result shows that it takes less time and less memory usage for deriving both kind of itemsets over the standard datasets. Basically it is post pruning technique of HUI’s. Further it can be improved deriving them while determining HUI’s.