
Abstract
For emotion recognition, here the features extracted from prevalent speech samples of Berlin emotional database are pitch, intensity, log energy, formant, mel-frequency ceptral coefficients (MFCC) as base features and power spectral density as an added function of frequency. In these work seven emotions namely anger, neutral, happy, Boredom, disgust, fear and sadness are considered in our study. Temporal and Spectral features are considered for building AER(Automatic Emotion Recognition) model. The extracted features are analyzed using Support Vector Machine (SVM) and with multilayer perceptron (MLP) a class of feed-forward ANN classifiers is/are used to classify different emotional states. We observed 91% accuracy for Angry and Boredom emotional classes by using SVM and more than 96% accuracy using ANN and with an overall accuracy of 87.17% using SVM, 94% for ANN.
Introduction
Automatic Emotion Recognition is a challenging area in human-computer interaction acting a significant role in normal human interactions. However in the recent past emotion detection form speech signals gained much attention and a challenging task for intelligible decisions. A successful solution to tricky setback would facilitate a wide range of important applications. There have been many studies for emotional speech but it is observed that most of the studies are not in regional Languages. In a short time a researchers have been working on a wide variety of databases like., Emo-Db (a database of German emotional speech developed at Berlin Technical University for Department of acoustic technology) [2], IITKGP(SESC)-is a Telugu speech database built by IIT- Kharagpur developed at All India Radio(AIR), Vijayawada, India [3]. Surrey Audio-Visual Expressed Emotion (SAVEE) [4], DES-danish emotional speech database developed by Aalborg University [5, 6], Denmark. Many researchers have proposed important speech features which contain emotion information, such as energy, pitch [7], formant, Linear Prediction Coefficients (LPC) [8], Linear Prediction Cepstrum Coefficients (LPCC) [9], Mel-Frequency Cepstrum Coefficients (MFCC) [7] and its first derivative. Furthermore, many researchers explored several classification methods, such as Artificial Neural Networks (ANN)[5], Gaussian Mixture Model (GMM), Hidden Markov model (HMM) [10, 6], Maximum Likelihood Bayesian classifier (MLC), Kernel Regression and K-nearest Neighbors (KNN) [11] and Support vector machines (SVM) [12] . The analysis of both prosodies related features and spectral features for the evaluation of emotion recognition is necessary 5–50 LPC coefficients as spectral features, whereas mean value of pitch (F0), intensity, the pressure of the sound, Power Spectral Density (PSD), as prosody related features have been studied. The human competence to recognize the emotion from the speech was also studied and compared with machine classifiers. Initially, a listening test of sample Sentences was done to identify a speaker’s emotion based on auditory impressions and Mean opinion score was collected. Then speaker’s emotion Identification of sample sentences was done with SVM and ANN [9] using pitch and subsequently, PRAAT [13, 14, 15] software package was used to extract the Pattern of acoustic parameters for sample sentences. This paper comprises of the following sections: Section two review of speech database with a description followed by section three briefly describes the feature extraction of speech emotion recognition system, next to this section’s describes the architecture with an idea about feature extraction and feature selection followed by a short review of classifiers used for emotion recognition and in the sixth section we presented results with discussions and finally the last section concludes the paper.
Speech database
The database used in this paper is Berlin Emotional Database is a well known German corpus. It is an open access which is used in the field of SER. This database contains 535 speech files with seven emotional classes. The seven emotions are Happy, Neutral, Angry, sad, Fear, Boredom, Disgust and there are 71, 79, 127, 62, 69, 81, 46 speech utterances for each class of emotion. This has been developed with 10 professional actors of them 5 male, 5 female. Table 1 describes the number of samples for each category [16]. The length of each utterance ranges from 20 ms–30 ms where more than 1080 segments of 2 seconds each exists in our understanding.
Feature extraction
Here, we categorize the emotion of each speech utterance in the typical Berlin database. Each short-term utterance of (generally 20 ms–30 ms) 20 ms length. We separate each utterance into 60 ms segments with 20 ms time shifts. Contemporary research approach favors the long-time features for analysis of emotions, since the long-time features correlate emotions better than short time ones in our experiments long-time features are considered where the performance is degraded by short-time features, And by considering most basic features: Pitch, energy, formant (f0, f1, f2, f3) Since the change in acoustic features is also related to emotional states, we include the energy difference as additional features [17]. The acoustic features [18, 19, 16] employ are as follows.
Feature selection
The intuition behind using the acoustic and prosodic features is to summarize the intentional variations observed in humans. The acoustic features are 1. Maximum & Minimum counter ascent energy. 2. Mean and Median values of energy. 3. Mean and Median of energy decline in values. 4. Maximum of pitch frequency 5. Mean and Median of pitch frequency. 6. Maximum duration of pitch in terms of frequency. 7. Mean and Median of first format 8. Rate of change in formats. 9. Speed in voice frames.
Speech emotion recognition system.
Inverse
After extracting MFCC values and matrix is generated where each row represent the frame and each column represent the extracted coefficient where the matrix is fed to a Neural Network.
Involving with speaker’s emotion is one of the main challenging tasks in speech technology. The design of SER(Speech Emotion Recognition) system mostly contain three modules which relay in our discussions they are’, Speech acquisition, Feature extraction from signals, Training the machine with feature sets and classifying emotions through SVM and ANN. The input to the system will be given as a .wav file shown in Fig. 1 from any emotional database. Here Berlin emotion database which contains emotional speech utterances with different emotional states. From the given input, the temporal and spectral features like Pitch, intensity, MFCC, spectral density are extracted. In the next step “:data” file which consists class labels is fed into SVM and ANN classifiers. The machine is trained in such a way to classify all possible emotions.
After training the system with acted speakers the system is fed with a real-time speech signal given as input to the “.model” then the system will automatically predict the emotional states with an orientation to training sets. A continuous process of training is initiated iteratively in anticipation of accurate results.
Architecture
Figure 1 represents the architecture used for emotions recognition. It mainly comprises of two phases first one is used for training and second is left for testing, the training phase a model is built with the extracted feature of pitch, Intensity, MFCC from the utterances. The extracted MFCC features are fed to emotion recognition models like, SVM (Support Vector Machines) and ANN (Artificial Neural Network). The testing phase determines emotion class of the corresponding input utterances. It is done by the decision block by selecting the highest probability from the training model and they are classified. We propose a methodology rooted in our previous studies [2] for a confusion problem. Usually there are many such statements which will come with different emotions. In a supervised learning identifying different sources of ambiguity of different classes over regional languages within the state.
Classification model
SVM
A, powerful classifiers widely used in pattern recognition that uses linear and nonlinear hyper planes for classifying data, A binary nonlinear classifier efficient predicting input vector x belongs to class 1 or class 2. For a given set of separable data, the goal is to find the optimal decision function. This is done by choosing a maximum margin as the distance between the closest sample and the decision boundary. It performs classification methods by constructing hyper planes in a multidimensional space that separates different class labels based on statistical learning theory. SVMs applied in various fields for efficient in: High accuracy and flexibility, Capacity to accommodate large number of attributes, Ease of training and Ability to model complex and real-world problems.
Multilayer Perceptron with a hidden layer.
Artificial Neural Networks are fundamentally feed-forward neural network models and a derived class as Multi-Layer Perceptron, which utilizes a Backpropagation technique in supervised learning. Non-linear separable data can be distinguished by MLP. The Network contains at least three layers, one input layer, at least one hidden layer as a part, and an output layer. The network layers contain multiple neurons aka nodes. There is a connection or edges form each adjacent layer. Figure 2 describes the fully connected Neural Net, as each node is fully connected with the other nodes. The nodes at the input layer are represented as
All the connections are associated with weights as
The sequence
Experimental results and discussions
To evaluate the performance we selected Berlin Emotional Database a well known German corpus. It is an open access which is used in the field of SER. This database contains 535 speech files with seven emotional classes. The seven emotions are Happy, Neutral, Angry, sad, Fear, Boredom, Disgust and there are 71, 79, 127, 62, 69, 81, 46 speech utterances for each class of emotion. This has been developed with 10 professional actors of them 5 male, 5 female. Table 2 describes the number of samples for each category [16].
Parameter setting of MLP architecture
Parameter setting of MLP architecture
Sample size in Berlin-DB
Performance Index: The metric used to measure the accuracy, of the classifier is confusion matrix which is a commonly used visualization tool in supervised learning are easier to visualize the classifier errors while trying to predict from original classes instances. The representation of this tool is shown in Table 2. Each row of the matrix represents instances of original classes and each column represents predicted classes from original classes.
Confusion matrix by using ANN
In our first experiment, we used SVM for classification. In this, the network was trained several numbers of times where the extracted features are given as input for training and they are tested using open and closed testing [25]. Intact, the dataset is used in closed testing, the remainder dataset is used for open testing, here 90% is used for training and remaining for testing. Gender Recognition is 100%, Male as 233 and Female 302 in closed testing and 28, 26 in open testing. Table 3 shows results obtained by SVM classifier where emotions neutral and angry have a recognition accuracy of 89.87% and 91.38%.
Results obtained with SVM classifier
In the second Experiment Multilayer perceptron (MLP) a class of feedforward ANN [9] for classification with backpropagation algorithm is used. The formulation of the neural network can be
Where
Results obtained with ANN (MLP)
In these works, two classifiers SVM and ANN are used for pattern recognition. The recognition accuracy obtained for all seven emotions for Berlin dataset. The recognition accuracy is shown in Fig. 3. It is noticed that the ANN is slightly higher accuracy when compared with SVM over long-time features set without degrading the performance.
Recognition accuracy obtained with ANN and SVM.
In comparison with other state-of-art approaches we picked M.Ahamad [26] and T.M.Rajisha [16] as they low level descriptors of the speech signal as the input of the Neural Network. With comparison to their feature representation schemes: Pitch in Hz and its smooth contour, Energy, ZCR, Mel frequency coefficients, Formants, Jitter, Shimmer, SNR, for voice quality on the other hand only MFCC [16] features with an optional overlap of 50% is/are considered, moreover they have chosen various databases, although [26] has used the same database for their experiments but we have picked EMO-DB benchmark database for our experiments. The results revealed that they have obtained higher recognition accuracy when used Multi-layer Perceptron classifier, which is about 91.2%. The proposed method achieved 94% average accuracy on the same dataset by using deeper kernels.
Prediction accuracy of various methods with SVM, MLP.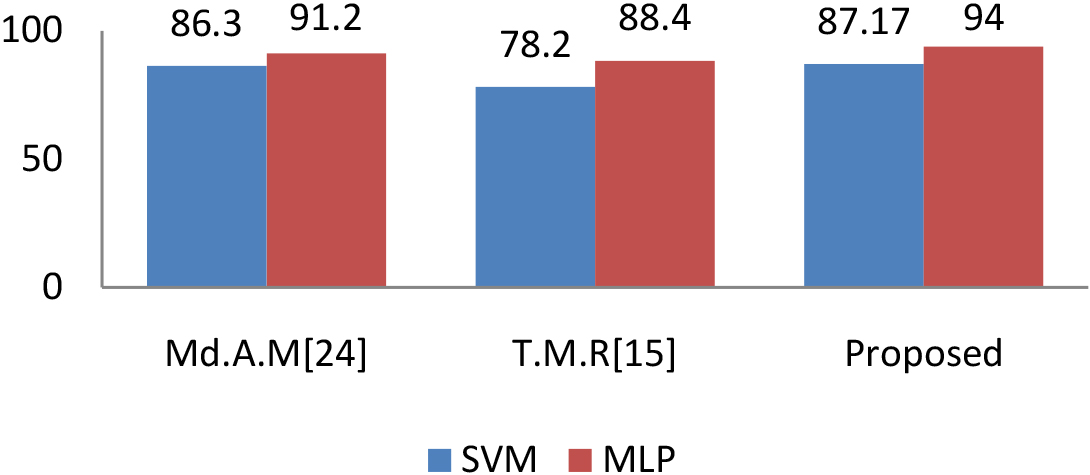
Figure 4 shows the prediction accuracy of various methods with two well known classifiers SVM and MLP. Results revealed that models with low level descriptors with recognition accuracy ranges from 78% to 91.2% and the proposed model achieved 87.17% with SVM classifier and 94% with MLP classifier.
The experiment presents us; the recognition rate of emotions by using spectral features is slightly improved when observed the prosodic features. We propose algorithm where at the outset we extract features based on prosodic and spectral features there is higher recognition accuracy in situations by combining prosodic and spectral features, the recognition rate with energy, pitch, MFCC is higher. We conclude that both prosodic and spectral features contain the combinations for better recognition of human speech emotion without degrading the performance. And from the experiments, it is observed that anger always has higher recognition accuracy. More work is needed to improve the system to extract more effective features even if the speech is a compressed one.