
Abstract
A dynamic slicing algorithm is proposed in this paper along with its implementation which is dynamic for concurrent Component-oriented programs carrying multiple threads. As a part of representing the concurrent COP (CCOP) effectively, an intermediate graph is developed called Concurrent Component Dependency Graph (CCmDG). The system dependence graph (SDG) for individual components and interfaces are integrated to represent the above intermediate graph. It also consists of some new dependence edges which have been triggered for connecting the individual dependence graph of each component with the interface. Based on the graph created for the CCOP, a dynamic slicing algorithm is proposed, which sets the resultant by making the executed nodes marked during run time in Concurrent Components Dynamic Slicing (CCmDS) appropriately. For checking the competence of our algorithm, five case studies have been considered and also compared with an existing technique. From the study, we found that our algorithm results in smaller and precise size slice compared to the existing algorithm in less time.
Keywords
Introduction
The real and flawless digital world is made possible by a programming paradigm called the Component-Oriented program (COP) in which the integration of different components is carried out through component’s interface, such that internal structure is hidden from the outside world [25, 26]. Component-Oriented Program (COP) is based on the interoperability and connection between components through interfaces. This new programming paradigm enables to develop programs from existing software components, which are self-contained, executable blocks of code and can be reused. Again, to achieve multi-core architecture and faster execution speed of the program, the sequential COP is needed to be extended to concurrent COP (CCOP). The challenges that can be faced in the implementation of concurrency in COP are testing, debugging, and synchronization between components.
Program slicing [1, 2, 5, 6, 8, 14] is the process of finding out the subset of statements for a given program by discarding the irrelevant statements and only considering the related statements for a particular point of interest called slicing criterion [1, 2, 17, 23]. The semantics of the partial program called slice remains the same as there in the original program. Using this slicing process, we can determine a module’s significance for a particular computation. Program slicing is used for program comprehensibility, debugging, and testing [34]. The innovation or concept of program slicing was first introduced by Weiser [1, 2, 3]. Slicing can be carried on a program P, based on the point of interest and extracting only those portion of P which are relevant to the slicing criterion. A slicing criterion is considered as a pair
Dynamic slicing is much more preferable than static, since it gives the slice of a program, as per the input provided by the user [24]. This approach provides a smaller slice as compared to the other types since some statements in the program might not be executed due to the slicing criterion. Also, the slice that is computed should be checked for its preciseness and correctness. The computation of a precise slice for CCOP is a challenging concern. Concurrency can be achieved by multithreading which is embedded in different types of programs like OOP, AOP to have concurrent OOP, AOP [19, 21, 22, 35], and COP. Based on our literature survey, a clear outline can be drawn that no concurrency principle has been embedded in COP and found a gap in the slicing of concurrent component-oriented programs. A framework is developed in this paper for CCOP.
A dynamic slicing algorithm is proposed in this paper for CCOP. We have extended our existing intermediate representation CmDG [33] into Concurrent Component Dependency Graph (CCmDG) especially for CCOP. Based on the proposed graph, we have developed a slicing algorithm called Concurrent Component-Oriented Dynamic Slicing (CCmDS) to handle the concurrencies in CCOPs. The rest of the paper is organized as follows: Next Section deals with some basic concepts of component-oriented programming, web scrapping, and concurrent COP. In Section 3, the literature survey of the related works is presented. Section 4 deals with the designing of the concurrency model of COP through the case study, that is used in this paper. In Section 5, we have presented an intermediate program representation CCmDG and its use in our case study. Section 6 contains the overview of the working of our proposed algorithm i.e. Concurrent Components Dynamic Slicing (CCmDS). Section 7, explains the implementation of our proposed work CCmDS algorithm along with case studies. Section 8 concludes the paper.
Preliminary concepts
The current section gives us an idea of some of the basic concepts such as Component-Oriented programming, Web scrapping, and concurrent COP that are required for a better understanding of the approach proposed in this paper.
Component-oriented programming
Component-Oriented programs have brought a revolutionary change in the style of software development where modular programming was enlightened rather than line-by-line code and assembling components rather than syntax-based programming based on their interface. COP can be referred to as interface-based programming whereas OOP is object-based programming. While OOPs emphasizes on the concept of classes and objects [11], COP focuses on compositions, and interfaces [26]. Major advantages of using COP:
Abstraction: Only required functionality is mentioned, but the implementation of the components is not required. Complexity: The overall complexity of the program will decrease when well-designed components are integrated to form a new program. Reusability: In COP, we need to identify suitable components and they can be re-utilized many numbers of times.
COP helps in solving some issues and complexities of major software engineering industries such as frequent change of client requirements, software reusability, complexity in software development. Brown [28] presented the definition of a software component as “A component is a nontrivial, nearly independent, and replaceable part of a system that fulfills a clear function in the context of a well-defined architecture.” COP represents modular programming where each module is treated as a component whereas, in object-oriented programming, modules are treated as classes.
A program complying with the above definition and characteristics of COP can be achieved by using different component technologies like JavaBeans and Enterprise Java Beans (EJB), Distributed Component Object Model (DCOM), and .NET components.
Web scraping is also referred to as data scrapping which is used for extracting data from websites. COP can be implemented better in web services, which provided application-oriented services on the web and enabling it as a programmable web rather than just an interactive web [26]. Though features of COP can be achieved by many component technologies or frameworks such as NET, EJB, the web service is the only technology that provides cross-platform, cross-programming language, and internet-firewall solutions to the inter-operable distributed computing.
Web services provide a viewpoint to develop distributed software by composition rather than by developing in traditional form of programming. This is the biggest example of re-usability where new application builds from existing components. These are the core motives behind COP and Component-Based Software Development (CBSD). One of the key features of COP is the self-deployability of components, which is very difficult to acquire in case of other component technologies. Hence, the features of COP can be well implemented and acquired by web services.
Some of the web services development tools are Microsoft .NET web service based on IIS server, Java Web Service Development Pack (JWSDP) but, in this paper, we have considered XAMPP, which is a free and open-source cross-platform web server solution stack package developed by Apache.
Concurrent COP
Concurrency can provide an easier path for making a more efficient digitized world by performing multiple tasks simultaneously. Accessing data from web service concurrently can lead to generating the results in lesser time [12]. Concurrency can be put into picture by using threads in the component technology i.e. for this work we have used XAMPP. Multithreaded programs run faster than single-threaded programs giving a better throughput [22]. But to implement the multithreaded programs, some challenges need to be handled such as debugging, testing, and synchronization. Such challenges have been overcome using web service application for a testing client and server-side scripts. The component technology tools used here are XAMPP and the scripting language used is PHP. Below in Fig. 1, there is an example showing how concurrency is handled in web service applications (here PHP scripts) programming.
Concurrent web service.
The above example in Fig. 1 shows the creation and end of the series of threads. The threads are executing in parallel. All threads start at the same time and each finishes in a one-second gap between each thread. Given that the sleep time is being incremented on each new thread being spawned. It shows how concurrency could be handled in web service applications.
In this section, we have presented our literature survey of conventional slicing and due to the absence of any research work related to Concurrent COP, we have listed some of the works related to Concurrent OOP and AOP.
Slicing of procedure-oriented programs
Weiser has proposed program slicing for the first time in 1979 [1]. Weiser described program slicing, the process of extracting those lines of codes from a given program that may be affected by the point of interest. The point of interest is known as the “Slicing Criterion” at which the slice has to be estimated. The slicing criterion is considered as a pair
Ottenstein et al. [4] introduced a new form of computing program slicing, that is by traversing through the graph of a program rather than doing calculations by equations. They have developed an intermediate graph representation called Program Dependence Graph (PDG) which is confined to represent the program with one procedure. Hence, the intermediate graph PDG helps in providing effective resultant slice for the single-procedure program and not able to work out for inter-procedure programs with many procedures. In 1990, Horwitz et al. [5] developed another intermediate graph called System Dependence Graph (SDG), to model the dependencies among subprograms and developed a two-phase inter-procedural slicing algorithm to compute precise slices. To make the computation of interprocedural program slices more effective, they proposed a step-wise algorithm that traverses backward on the SDG.
Slicing of concurrent OOP
Many researchers have done intensive works in the slicing of the concurrent programming paradigm [30, 31, 32]. Zhao [18, 29] has proposed a slicing algorithm to compute slices of Java programs that are concurrent. He has proposed an intermediate graph representation called Multithreaded Dependence Graph (MTDG) for the multithreaded programs in Java which is the extension of System Dependency Graph (SDG). Though the paper has come up with the efficient computation of slices of multithreaded Java programs based on MTDG, still it is missing with the implementation issues of the same.
Krinke [30] proposed the context-sensitive approach for slicing concurrent programs correctly by taking time-sensitive information for computing slice. The author has proposed an intermediate graph namely threaded Interprocedural Dependency Graph (tIPDG) by introducing a new edge called interference edge. The problem of the shared variable in a different thread is solved in this approach. But, the slicing technique developed by the author is insufficient to find the slices where the serialization or inlining process is present.
Mohapatra et al. [19] developed an approach for computing slices of multithreaded object-oriented programs. In this technique, the intermediate representation graph developed was Concurrent System Dependence Graph (CSDG), and slices are computed based on this intermediate graph representation of the program. Basing on emerge and drop of dependencies during execution time, the edges of CSDG and are marked and unmarked. The new algorithm developed here is Marking-Based Dynamic Slicing (MBDS) which works efficiently by eliminating the use of trace files.
Slicing of concurrent AOP
Zhao et al. [20] presented the unique technique for computing a dynamic slice of Aspect-Oriented programs. For computing slice of Concurrent AOPs, Zhao proposed an intermediate graph called Aspect-Oriented System Dependence Graph (ASDG), which is constructed in three phases: an SDG for non-aspect code, an SDG for aspect code and several additional dependency edges for connectivity. This dependence graph is the extension of SDGs to represent aspect-oriented programs.
Ray et al. [21] improvised the existing dynamic slicing approach developed by Zhao et al. [20] to find the dynamic slices of concurrent aspect-oriented programs. The intermediate graph developed in this approach is named as Concurrent Aspect-Oriented System Dependence Graph (CASDG). The CASDG of a multithreaded AOP integrates dependence graphs for the non-aspect code, aspect code, and some new dependence edges used to connect the SDG and the dependence graph for aspect code. The slicing algorithm developed is the extension of the Node marking Dynamic Slicing (NMDS) algorithm [32] in which edges are marked or unmarked based on arising or ceasing during execution time.
Singh et al. [22] proposed a new context sensitivity approach for computing slices of concurrent AOP having multiple threads. The intermediate representation graph developed by the author is the Multithreaded Aspect-Oriented Dependence Graph (MAODG). A slicing algorithm is proposed which is based on the intermediate graph (MAODG) and a point of interest called slicing criterion as input to produce its slices. A slicing tool is implemented by designing a slicer and considering a sample example of an online auction system. They have computed the efficiency of their algorithm by comparing their approach with Ray et al. [21].
Concurrency model of sample COP.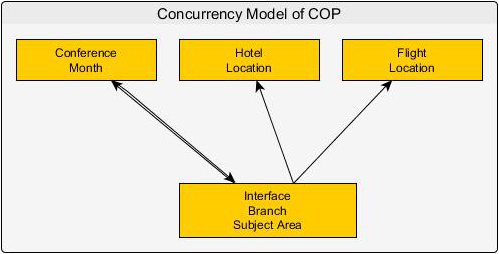
Looking at the literature survey, it has been found that the origin of slicing was introduced by Mark Weiser [1, 3]. Replacing mathematical calculation for the computation of slice through graphical representation was proposed by Otteinstein [4] and Hortitz [5] in the form of PDG and SDG. Zhao [18, 29] implemented slicing on other programming paradigms like an object-oriented program that is concurrent and proposed Multithreaded Dependency Graph (MTDG). However, the extension over it was proposed by Krinke [30], which takes time-sensitive information for computing slice. and most importantly, slicing through marking and un-marking of multithreaded object-oriented programs was created by Mohapatra et al. [19]. Zhao [20] also implemented slicing over Aspect-oriented programs by proposing Aspect-Oriented System Dependence Graph (ASDG). Ray et al. [21] improvised on the existing ASDG to be implemented on concurrent Aspect-Oriented Programs by proposing Node Marking Dynamic Slicing (NMDS) Algorithm. A slicing tool was developed by Singh et al. [22] for computation of slice of concurrent AOP by proposing a Multithreaded Aspect-Oriented Dependency Graph (MAODG). The gap found here is an implementation of slicing over Component-Oriented Programs (COP). This paper deals with the computation of slicing on COP that is concurrent by considering a case study that will be discussed in the next section.
This section puts a brief overview of the concurrency aspect of COP since, concurrency is a crucial attribute that has to be focused, to work on modern and real-time codes. It is achievable in OOP by the use of threads in procedures that can be run concurrently. Such programs are referred to as concurrent OOP. Similarly, it can be achieved in COP by the use of threads and called a Concurrent COP. The component-oriented programming approach has become a preferred approach that is used by developers as a vital technology for addressing a problem called “Software Crisis”. COP provides software that is built by assembling existing components. Concurrency plays a lead role in achieving better performance in throughput from web services (real-time example for component-oriented programs). But, putting concurrency into web codes (script code) is a challenging task. As per our literature survey and knowledge, none of the existing work or model is found in the field of slicing to address the concurrency aspect of COP. Hence, to cover the gap, a dynamic slicing algorithm is developed in this paper for computing slices of concurrent COP.
The model is explained by taking a simple real-time example, as shown in Fig. 2. The component used here is a web service component, in which web scrapper has been used for fetching and extracting the contents from the website. Web scraping can be done manually but the automated version of extraction which is used here is Web Crawler. Web crawling is the main component of web scraping for fetching the pages and data from websites for later processing. The content of the page may be parsed, searched, reformatted. Hence, concurrency is developed in web service applications with the help of web Crawler i.e. CURL. After data is fetched for one component, the other two web applications are fired concurrently based on fetched data, and the resultant is displayed. Query considered here is: To find out the Conferences held in India for the specified month and getting details of hotels available at low cost and direct Flight to the same conference location is available or not.
In Fig. 2, the model for Concurrent COP is shown, where we have created three APIs named as Conference, Flight, and Hotel. These three API’s are independent components, which perform independently to extract valuable information. The Conference component scraps the detail data from the ‘conferencealertsindia.com’ website about conferences held and results in only Scopus related conferences. Here, the other two web applications are considered as threads namely as Hotel and Flight are fired concurrently to scrap out only 5 starred hotels and direct flight communication based on the conference location. Interface collects the detailed data of conferences held by taking selection criteria based on topic and month by executing Conference API. Then two threads, hotels, and flights that are independent of each other are fired concurrently from the interface based on the location of conference details, making two processes to work simultaneously. Then, results from hotel and flight API along with conference details provide the desired output by the user.
In this paper, we have considered one example case study as shown in Fig. 2. Here, each web APIs are treated as components, and interface executes concurrent components. So, we have considered this case study for the implementation of our proposed slicing technique. The first component namely Conference extracts the data from the website Conferencealerts.com based on the month specified and uses CURL as a web scraper. Then the component generates all the conference details filtered based on the specified month and Scopus indexed. This API gives filtered out data from the website as per client requirement which is further reused by other components (here used by the interface) to build up new software.
The second component namely Hotels scraps the data from the hotel website and comes out with only 5 or above starred hotels based on the location of the conference extracted from the first component (i.e. conference) specified. This API is an individual component that further is accessed by any other component for reusability. The third component namely Flight gets the data regarding the availability of direct communication to the location of the conference by scrapping the data from the real site. This API is reusable by integrating it with components for getting the desired client requirement.
In the interface, we integrate the Scrapped data from three components: Conference, Hotels, and Flight. Interface accesses the result from conference API, all the conferences held in a specified month and particular branch. Subsequently, Hotel and Flight components are fired concurrently specifying the location of the conference. This concurrency is achieved by making both the component as thread. Since thread can enable two processes to execute independently improvising a decrease in response time. The resultant is a new component, where we can acquire the details of the conferences held on a particular month and belongs to a particular branch, along with its correlated parameters like showing the direct communication available to the location where the conference is held and all the hotels available in that location.
Proposed work
This section is carried with the work proposed and the method to handle concurrency in component-oriented programs. To portray the same, we have developed a graph known as the Concurrency Control Flow Graph (CCFG) in our earlier work [27], in which the flow of control in the program is shown. Then the extension of CCFG called Concurrent Component Dependency graph (CCmDG) is described along with the process of its construction.
Concurrent Control Flow Graph (CCFG)
In component-oriented programs, concurrency is handled by the use of threads. Control Flow Graph (CFG) can be constructed for each thread. Two components namely Hotel and Flight in the example case study shown in Fig. 2, are represented as a thread to execute independently and concurrently. However, the threads are independent but the interface scraps the data from three components to build up a new component. Hence, to represent the concurrent program, the collection of CFGs of each component will not suffice its requirement. So, additional edges are added into the CFG to represent communication among components referred to as Concurrent Component Flow Graph (CCFG). A CCFG is the integration of CFGs of all components along with new dependencies for connecting components with the interface. CFG for every single component is constructed from which two are represented as threads.
First, we construct the CFG [19] of each component and interface as in Fig. 2 shows the control flow/dependencies between components, threads, and interface. To interconnect the components and interfaces, a new dependency edge called Component Connect Edge (CCE) is developed. Another new edge called Thread Component Edge (TCE) is introduced, for connecting threads to more than one component simultaneously for more efficient results. To run the components concurrently, we need to execute two methods of a thread that is, start() method and the corresponding run() method. For all the components in the concurrent program, the process needs to be repeated.
CCFG of the concurrent COP.
Concurrent Component-Oriented programs are represented by extending the existing intermediate graph representation CmDG proposed by Pujari et al. [33] and named this intermediate representation as Concurrent Component-Oriented Dependency Graph (CCmDG). The CCmDG is constructed by the addition of data dependencies to the CCFG, as shown in Fig. 3. Concurrent Component-Oriented dynamic slicing is explained by considering a simple case study (example program) shown in Fig. 2 where an interface is designed to get connected with three components and access required data. Apart from that, two components are defined as thread, for concurrent execution of both. The CCmDG is a directed graph G
: Algorithm to generate CCmDG[] CCOP Codes A SDG G
Individual nodes are created for each statement of each component of the program. Add a Control Dependent edge, n1 Add Call edges between each node of type submit and the pages during runtime specified in the associated call in the graph. Add a Component Connect edge to interconnect the components and interface of the program.
Add a component-connect edge, n1 Add a Thread Connect edge to interconnect the multiple threads of the program for concurrent processing.
Add a thread connect edge, n1 Also, another dependency that can be found during runtime is thread dependency, which exists between the last statement of a thread and a statement of the interface once that thread is being called. Add a Call edge, n1
2. Construct CCmDG.Add a Data Dependent edge, n1
CCmDG of the concurrent COP.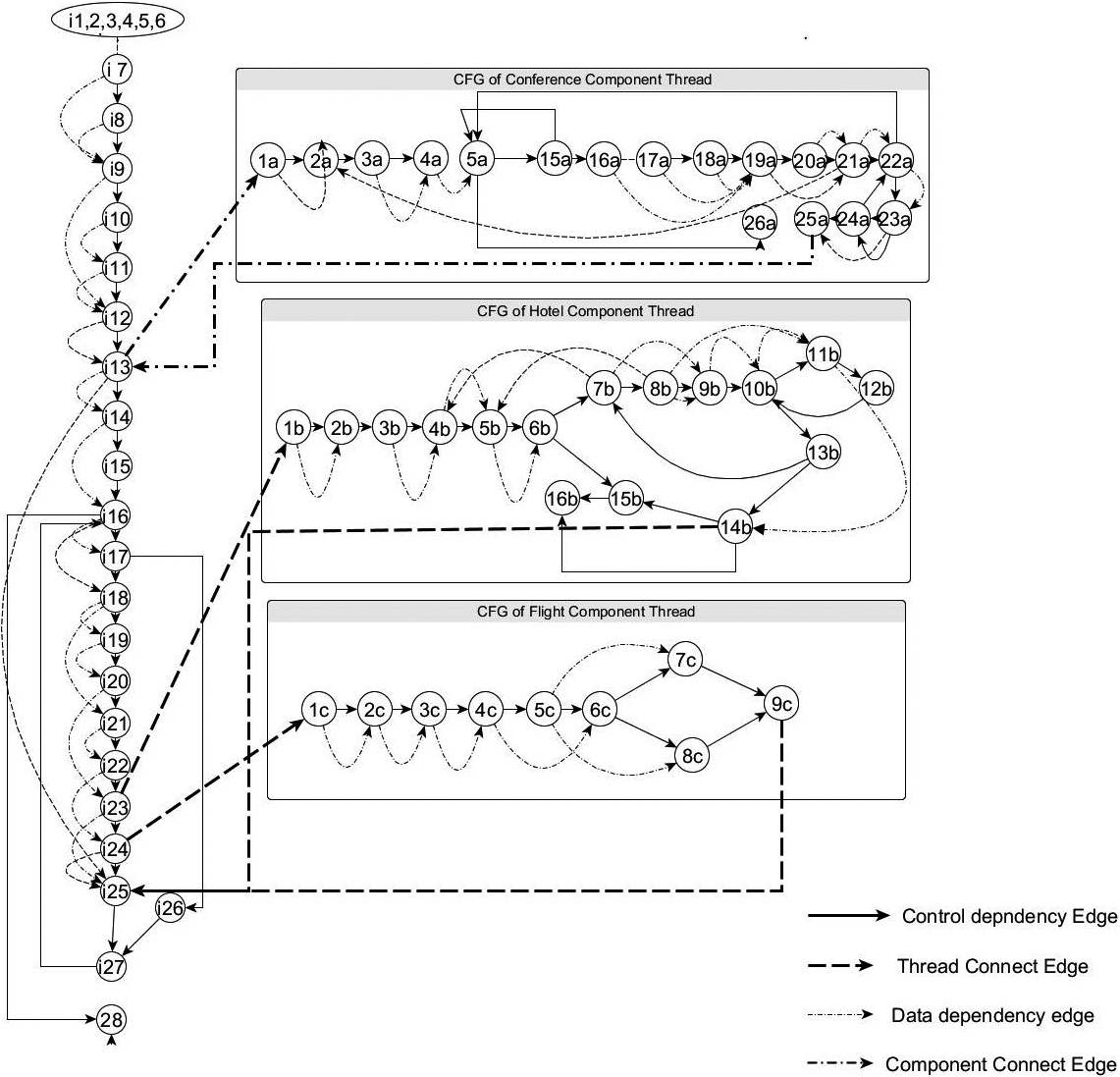
Example case study.
CCmDG is the extension of CmDG and a collection of CFGs, which gives the information regarding the flow of controls, component connects, thread dependencies in a CCOP. Data dependency edges are added to CCFG to capture the complete flow of data throughout the system and acquire CCmDG. So, for a given case study of a Component-Oriented program Q, CCFG is constructed first, then CCmDG of Q is constructed based on CCFG. The process of construction of CCmDG of a CCOP can be carried out as shown in Algorithm 1.
Figure 3 shows the CCFG of the example program (Fig. 2). This graph reflects only the control dependencies, Component connect edge, and thread connect edge between the components and interface. Node i13 invokes node in the first component and collects the data, hence the edge is called component connect edge while nodes i23 and i24 are nodes that invoked two threads concurrently and the edge called thread connect edge, Thread1-Hotel and Thread2-Flight. CCFG is added with an additional dependency called data dependency to form CCmDG. Figure 4 shows the CCmDG of the example program (Fig. 2). The step by step process of the generation of CCmDG is explained in Algorithm 1. Initially, CCFG of each component and interface is created. Then interface and components are connected by different edges as CCE, TCE depending on the interconnectivity. If there is a call to another page, then the call edge is added to CCFG. Lastly, CCmDG is constructed by an additional data dependency edge to CCFG.
Concurrent Components Dynamic Slicing (CCmDS)
We have improved the existing algorithm CmDS [33], which can handle component connectivity by traversing from the point of interest node in a backward manner. The proposed approach is efficient enough to handle self-deployable components but could not handle concurrency within components. Our proposed algorithm improvises by adding a new phase to enable the slicing of concurrent components using threads.
Proposed algorithm of concurrent COP slice
: Algorithm to find slice from CmDG[1] An CCmDG G
In Algorithm 2, we have extended a two-phase algorithm to three-phase to handle concurrency in COP. Here we have considered three transaction list TL1, TL2, TL3, for traversing interface edges, component edges, and thread edges respectively. Details of computing of slice are explained in the next section.
Slice computation
In our proposed intermediate graph CCmDG, the components and interface are interconnected by using new edges such as component connect edge (CCE) and thread connect edge (TCE). Working of our slicing algorithm is described by considering a case study as shown in Fig. 2. Considering the point of interest as node i25 and to reduce ambiguity in identifying nodes of different components and interface, alphabets a, b, c and i are attached with node numbers (alphabets a, b, c are for statement numbers in component 1, 2, 3 respectively and i for identifying statement in the interface). Hence, the list of nodes traversed in the initial state is given below:
S
In the first traverse, the algorithm restricts with slicing criterion and traverses backward along edges such as control flow, data flow, call edges except component connect edge (CCE), and thread connect edge. During this traversal, all vertices in CCmDG are being marked and added to slice and TL1, TL2, TL3 as per the type of edges that are being reached. Then in the second traversal, all the vertices in CCmDG stored in TL2 are traversed backward by the algorithm, along with the component connect edges (CCE) and pushed to the slice. Lastly, in the third traversal, the vertices present in TL3 have traversed backward along the thread connecting edges (TCE) and pushed to the slice. Hence, finally, we result in a slice which is having all the nodes encountered during the three traversals of CCmDG.
In the first step, the node that is reached in CCmDG are popped from TL1 and in case of its absence in S, it is added to the slice S. This is done by verifying all the incoming edges to the current node and the node is pushed to TL2 or TL3 depending on the type of edge encountered (CCE or TCE) and nevertheless, it is added to TL1 for further processing in Step 1. Hence, the list of vertices after the first step/traversal are:
TL1
In step 2, similarly, the vertices present in TL2 are traversed backward in CCmDG (which represents Component connect edge) and the node is popped from that list after traversal, added into slice S. The process could be carried out by verifying all incoming edges to the current node. The process is repeated until the list is empty. After the second traversal/step, the slice would contain such nodes:
TL1
In step 3, in the earlier process, all the vertices/nodes (which represent thread connect edge (TCE)) in TL3 are being encountered by verifying all incoming edges to the current node. The current node is popped out from the list after traversal and added to the slice S. Similar process is repeated until the list is empty. At last step/traversal the resultant slice is as such:
TL1
Hence for the given slicing criterion NDi25, the slice found is
S
Resultant slice
Resultant slice of CCmDG.
The resultant slice of the intermediate representation graph CCmDG of the concurrent COP is shown in Fig. 4. The marked nodes represent the resultant slice of the case study undertaken.
The current section deals with the designing, working, and implementation of the slicing tool developed called PHP-Slicer, which will be resulting in the automatic generation of CCmDG. Then, five case studies that are already discussed, has been considered in our implementation process and also described comparison with some closely related works. Lastly, the result of our experimental study has been presented.
Experimental setup
PHP-Slicer is a partial tool developed for the automatic generation of CCmDG and slice computation. To develop the slicing tool, we have used a personal computer with the specification of Intel(R) Core i5-7200U processor, x64 based processor, the clock speed of 2.50 GHz, with an internal memory of 8 GB, Windows 10 Home Basic (64 bit) operating system. The result may vary if any other computational environment is used to reproduce our findings.
Case study details
Case study details
Workflow diagram of PHP-Slicer tool.
Figure 7 shows a block diagram of our Slicing tool PHP-Slicer, in which six packages are being studied and each program of the web application is analyzed to generate CCmDG. After the PHP script is loaded, the initial PHPScript Interpreter studies all the PHP statements and stores all functions and variables in the respective tables. Here data internal to the system are stored in an internal storage system and edges are also read to computes data, control dependencies within the statements. Next,HTMLScript Engine package finds out all HTML tags like
As our work deals with remote sites, the Scrapper part takes care of all the external or remote server connectivity and extraction from the HTML engine. This part consists of the Remote Server analyzer (connectivity), the Request Action Engine (Extraction) acts as a crawler. And at last, the scrapped data is collected in an internal storage system in a localhost server. Lastly, the data from the 3 engines i.e local PHP script engine, remote action engine, and internal storage are input to CCmDG to generate the graph. The graph is provided as input to a web slicer tool, which results in generating slice based on a slicing criterion provided. The proposed tool enables us to generate the slice as per the point of interest.
Case study
Five case studies are observed to verify the competence of our proposed PHPSlicer tool. In each of the case studies, a CCmDG has been generated for each PHP page that we have taken and have computed slices according to slicing criteria. The case studies that are considered are presented in Table 1.
Findings
Table 2 shows the details of CCmDG generated for each PHP page. The table shows the size of each case study and the number of PHP pages content in it. The CCmDG generator has created the CCmDG for each case study project. In column number three of Table 2, we present the number of nodes created in the CCmDG followed by the number of edges and time taken by the tool to generate each CCmDG. From Table 2 we can observe that as the size of the component increases, the size of CCmDG is also increasing. And, hence the time taken by our tool to generate the CCmDG is also increasing with larger size components.
Details of all the CCmDGs generated for different case studies
Details of all the CCmDGs generated for different case studies
Comparison of our proposed work with the existing algorithm
In the literature, we cannot find any existing work in the field of slicing of COPs. To present the efficiency of our proposed work we have considered the trivial slicing technique proposed by Weiser [1], which is termed as Weiser’s algorithm. In Weiser’s algorithm for computing slices, no constraint or restriction is imposed while traversing backward from the slicing criterion and identifying the nodes of SDG to be present in a slice or not. It means that according to his slicing algorithm, the slices are computed by a blind backward traversal from the slicing criterion to all reachable nodes of the SDG. But, in our proposed slicing algorithm we check the context-sensitive nodes while finding the slice. The context-sensitive slicing [22] ensures that while backward traversal in a given SDG, we must consider only that function from where we have entered into the current function. It restricts the blind traversal into all functions.
Average Slice Size: Suppose there is n number of slices compute where
Average Slice Time: Suppose there is
In the experimental study, we have computed many slices by using both Weiser’s algorithm and our CCmDS algorithm taking different slicing criteria. For summarization of our findings, the average slice size and average slice time are calculated by dividing their summation in each slice by the number of the computed slice. All the observations for case studies are listed in Table 3.
Comparison of average slice size.
In this section, based on the average slice size, we have compared the result of our experiment. The case studies that have been considered in our experiment behaves similarly. We observed that the average slice size computed by the CCmDS algorithm is smaller than slices computer by Weiser’s algorithm for all case study projects, as shown in Fig. 8. To compile it, our proposed algorithm CCmDS generates 11% smaller slices compared to that of Weiser’s algorithm.
Then, by taking average slice computation time into account the two algorithms are compared and came to be observed that our algorithm computes slices much speedier than the Weiser’s algorithm, as shown in Fig. 9. From our five case studies, we found that our CCmDS algorithm generates slices of 31.91% speedier than the Weiser’s algorithm.
Comparison of average slice time in milliseconds.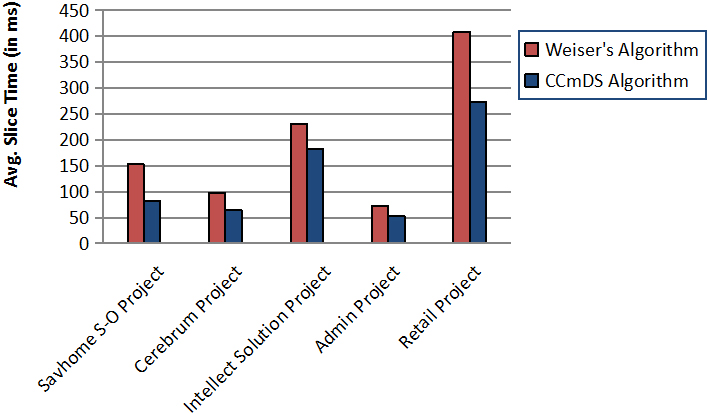
After the total observation we can deduce these points:
The slice produced by our proposed CCmDS algorithm is smaller in size compared to that of the slices produced by Weiser’s algorithm. Hence the slice is more precise. By using CCmDS algorithm the slice generation time is always found to be minimum. Hence it is faster/speeder than the Weiser’s algorithm.
In this paper, we have proposed an approach for slicing concurrent Component-Oriented Programs having multiple threads. First, we have developed an intermediate representation CCmDG and proposed a dynamic slicing algorithm called CCmDS to compute slices of a given CCOP. We have implemented our proposed CCmDS algorithm, and a closely related algorithm i.e. Weiser’s algorithm [1]. By considering five case studies, we have compared the preciseness of both approaches in terms of slice size and slicing time. We found that our CCmDS algorithm generates an average of 11% smaller slices than the approach of Weiser [1]. We have also compared the slice computation time of both algorithms and observed that our CCmDS algorithm runs 31.91% faster than the Weiser’s Algorithm. So, we conclude that our slicing technique enables us to find slices in less time and more precisely. Our future work is to develop a similar dynamic slicing technique to distribute component-oriented programs.