
Abstract
Object detection and recognition is a computer vision technology and is considered as one of the challenging tasks in the field of computer vision. Many approaches for detection have been proposed in the past.
AIM:
This paper is mainly aiming to discuss the existing detection and classification techniques of Deep Convolutional Neural Networks (CNN) with an importance placed on highlighting the training and accuracy of the different CNN models.
METHODS:
In the proposed work, Faster RCNN, YOLO and SSD are used to detect helmets.
OUTCOME:
The survey says MobileNets has higher accuracy when compared to VGG16, VGG19 and Inception V3 and is therefore chosen to be used with SSD. The impact of the differences in the amount of training of each algorithm is highlighted which helps understand the advantages and disadvantages of each algorithm and deduce the most suitable.
Introduction
According to a survey in 2019, the vehicle population of Bengaluru, India is about 80 lakhs with a trend of increase by six lakhs every year [1]. Out of this, around 55.9 lakhs constitute two-wheeler vehicles, with more than one thousand new two-wheeler vehicles hitting the road every day [2]. A large population like this will lead to a lot of inconveniences like traffic jams, air and noise pollution, accidents etc. with the major hindrance being violation of traffic rules. Skipping red lights, not wearing seatbelts, not wearing helmets, over speeding etc. are few violations that are found very often. The most common offence is overseeing the usage of helmets and seatbelts. Traffic rules such as wearing helmets are set to avoid serious losses during accidents, but many riders do not wear them [3]. This plays a pivotal role in safety and is the prime reason for losing lives during accidents [4]. Along with the traffic police on road, staff at the traffic control help in recognising the credentials of the violators in order to fine them using CCTV devices. This process includes large manual labour and is naturally prone to error. The inclusion of Machine Learning (ML) into such tasks increases its efficiency as well as reduces workload. For the hope of a future with intelligent technology, detection of motorcyclist’s helmet is a step towards it.
Artificial Intelligence (AI) is now closer to us than before. Nowadays, it is almost a part of everything we use. Machine Learning is a technology that gives the systems the ability to learn on its own through real-world interactions and generalizing from examples without being explicitly programmed. With the advancement in the fields of AI and Image Processing, exposure to image and video datasets has increased. Object Detection is a common application in the field of Computer Vision also [5]. Deep Learning alone or along with other domains can be applied in such use-cases to solve problems. Object Detection in Motion is a step ahead, where the object that is to be recognised is in motion in the dataset. In a traffic scene, detecting the presence of the helmet of a motorcycle rider, is a situation where Object Detection in Motion can be applied [6]. To address the problem of rule-breaking without wearing a helmet, we seek help from Deep Learning. Here, methodologies like Neural Networks are applied in order to detect the presence of a helmet on a motorcycle rider in a traffic scene.
Neural Networks are inter-connections of neurons which can be connected fully or not. Every network contains an input layer, one or several hidden layers and an output layer. The nodes in the output layer corresponds to the number of classes during a classification problem. Every neuron has its own weight and bias. Neural Networks extract features on its own, from the dataset, in contrast to ML algorithms. Thus, it makes the implementation easier. The most used Neural Network is the Convolutional Neural Network (CNN). The CNN includes several fully connected layers along with a kernel or a filter [7]. The filter is a matrix of dimensions height, width and depth holding a certain value. The function of the filter is to propagate throughout the input image, as a sliding window, and apply transformations to all the pixel values.
Literature survey
For detection of objects in videos and images Sandeep et al. [8] proposed the Easynet model. The detection process initiated with pre-processing followed with feature extraction through edge detection, also the concept of bounding boxes along with the confidence score is used to represent the certainty of an object within the box. The proposed model is tested using the PASCAL VOC 2007 dataset. Li et al. [9] developed a safety helmet wearing detection system to identify and ensure the safety of workers at a power station. The model used ViBe background modeling and C4 algorithm to classify the motion object as a human or not. Further the detection of safety helmet was performed by considering only the head region of the classified human image along with Hue-Saturation-Value (HSV) transformations and adaptive threshold selection methods.
Abhishika et al. [10] used the SSD approach to detect and classify objects in an image or video. The system used HOGDescriptor(), setSVMDetector() function to pre-train the detector and detectMultiScale() function to achieve multi scale window. On comparing the traditional and neural network model, it is proven that HOG feature extraction and Support Vector Machine [11] classifier shows less accuracy than Multibox Single Shot Detector (SSD) model. Long et al. [12] proposed an effective safety helmet wearing detecting system based on SSD and a novel safety helmet precise detecting model. On comparing You Only Look Once (YOLO) and SSD, it proved that SSD has a better detection performance with its ability to detect objects with different sizes and uses the anchor strategy to detect dense objects.
Boonsirisumpun et al. [13], presented the experiment on applying few deep learning techniques to solve the issues of detecting and classifying motorcyclists wearing a helmet and not wearing a helmet. The authors used four Convolutional Neural Networks (CNN) in these experiments-VGG16, VGG19, GoogLeNet or Inception V3, and MobileNets for image classification along with the SSD technique to perform image detection. MobileNets with SSD gave better results closely followed by Inception V3 with SSD.
Babayan et al. [14], compares three artificial neural networks YOLOv3, Faster R-CNN, SSD based in their precision, recall, speed etc. The results show that Faster-RCNN has better accuracy, but the average image processing time is lengthier, SSD performs image processing but it does not guarantee a good accuracy and YOLOv3 produces mean accuracy and performance. Anisha et al. [15], uses Automatic Number Plate Recognition process that uses the optical character recognition [16] for detection of the vehicle’s number plates. The procedure is a step-by-step process that starts with conversion of image to gray scale, applying morphological and segmentation processes, localization of the number plate and character recognition and segmentation to recognize and detect the number in the number plate.
Dahiya et al. [17], proposed different variations in representations of features, that includes Scale-Invariant Feature Transformation (SIFT) [18], Local Binary Patterns (LBP) [19] and Histogram of Oriented Gradients (HOG). This paper produces implementation in two phases: The rider of the bike is detected in the first phase. The detection of the location of the head of the rider and helmet presence in the second phase. After the execution of both the phases, the results states that, for phase-1 HOG performs better than any other all the other algorithms. From both phase-1 and phase-2 the paper gives an accuracy of 95%.
Several models based on CNN have been developed since its inception. RCNN, Faster RCNN, YOLO, VGG, MobileNet etc. are a few to name. RCNN refers to Region CNN. In this algorithm, the image is divided into several regions [20]. For each region, the CNN is applied. A faster RCNN algorithm is used for detecting the object along with its location in the entire image. In RCNN, the frame is broken down into several regions to find the location of the object. Then the image again goes through the network for the object to be detected [21]. In faster RCNN, a convolutional feature map of the image is given as output. Another network is used to predict these proposals. Another algorithm is YOLO [22] or You Only Look Once. When compared to RCNN, YOLO is a much better option in terms of speed. This is due to the fact that the CNN is applied only once in this architecture, as the name suggests, and the bounding boxes are drawn simultaneously. Thus, the detection of objects and the classification is done together. Due to this YOLO is a better option to use on general datasets that include real-time object detection in external environments like traffic scenes, when compared to RCNN. MobileNet SSD on the other hand is more accurate than YOLO. MobileNet is an architecture [23] that has been condensed in such a way that it is light enough to run even on mobile phones. SSD [24] stands for Single Shot multibox Detector. SSD is used to obtain multiple bounding boxes in a single frame or to detect multiple objects in a single shot. MobileNet along with SSD is used for object detection as it is a more feasible option than models like AlexNet or ResNet as it is a network smaller in size and of a simpler architecture. MobileNet SSD is preferred over YOLO due to its better accuracy. In RCNN, the detection is done in two shots, whereas with MobileNet SSD in one shot [26, 27].
In order to implement this application, video of a traffic scene is captured using a camera. This video dataset is then processed and converted into frames. These images are passed onto a CNN. The algorithm tries to detect the object in the frame. This object is then classified and labelled. After passing through several layers of the neural network, vehicles such as cars, motorcycles etc. are detected. Here, only the objects in the class motorcycle are considered [28]. Similarly, the presence of a helmet is detected. A bounding box is drawn to the region containing the object and is given as output along with confidence score. The different sections in this paper throw light onto different aspects of the use-case. Section 1 introduces the problem and the approach taken to solve it, briefly. The next section, Section 2 describes the path taken for the implementation along with more knowledge about the algorithms used. Section 3 presents the results obtained graphically as well as in a tabulated way, along with its justification. Finally, in the last section, the paper is concluded with the key outcome.
Methodology
Dataset description
Total of 701 images, obtained from Open Images v4 open-source dataset, consisting of motorcycles and helmets are used for training the model. 300 images are used for testing.
In order to build an In-House dataset of operational environment, two videos were shot with a DSLR camera. The top angle video was shot from a skywalk to make a dipping inclination possible. The front angle was shot at eye-level. To obtain optimal illumination, the videos were shot around noon. One shot from the front angle and another from a higher angle, each of 5121 and 6326 frames respectively are used to obtain the results from the trained models. There is a motorcycle and helmet count of 56 and 44 in the front angle video. Top angle video captures 75 motorcycles and 69 helmets. The detection process is applied for each frame and the result is saved as an output video.
Flowchart of the model.
Comparison of various object detection algorithms available is done by performance evaluation on the COCO dataset, a benchmark dataset for object detection using accuracy and training time as metrics. Out of Faster R-CNN (Faster Region-based Convolutional Neural Network), Fast R-CNN (Fast Region-based Convolutional Neural Network) and R-CNN (Region-based Convolutional Neural Network), Faster R-CNN performed better. SSD (Single Shot Detector) outperformed Faster R-CNN with respect to inference time but compromised with accuracy. In real-time situations, YOLO (You Only Look Once) outperformed the other models. Therefore, Faster R-CNN, SSD and YOLO are the algorithms used, in this paper, for object detection over other available algorithms.
Faster R-CNN was developed to overcome the limitations of R-CNN and Fast R-CNN. In R-CNN and Fast R-CNN, Selective Search is used for the extraction of region of the image, whereas Faster R-CNN uses Region Proposal Network (RPN) instead. A Region Proposal Network is a fully convolutional network that simultaneously predicts the object bounds as well as objectness scores at each position of the object and is trained end-to-end to generate high-quality region proposals, which are then used for detection of objects. In Faster R-CNN, feature maps of the image given to ConvNet are first obtained. Then object proposals of the input image are attained by applying RPN is applied on the feature maps. The proposals are changed to the same size and passed onto the fully-connected convolution layer for classification of bounding boxes of the image.
A convolution network, run by the SSD, computes the feature map of an input image. After this, a small 3
Faster RCNN & MobileNet SSD detection over steps for motorcycle
Faster RCNN & MobileNet SSD detection over steps for motorcycle
Faster RCNN & MobileNet SSD detection over steps for helmet
Execution time of YOLO over epochs
YOLO detection over epochs for motorcycle
YOLO detection over epochs for helmet
Graphical results of YOLO. (a) Training loss of YOLO, (b) Precision of YOLO, (c) Recall of YOLO.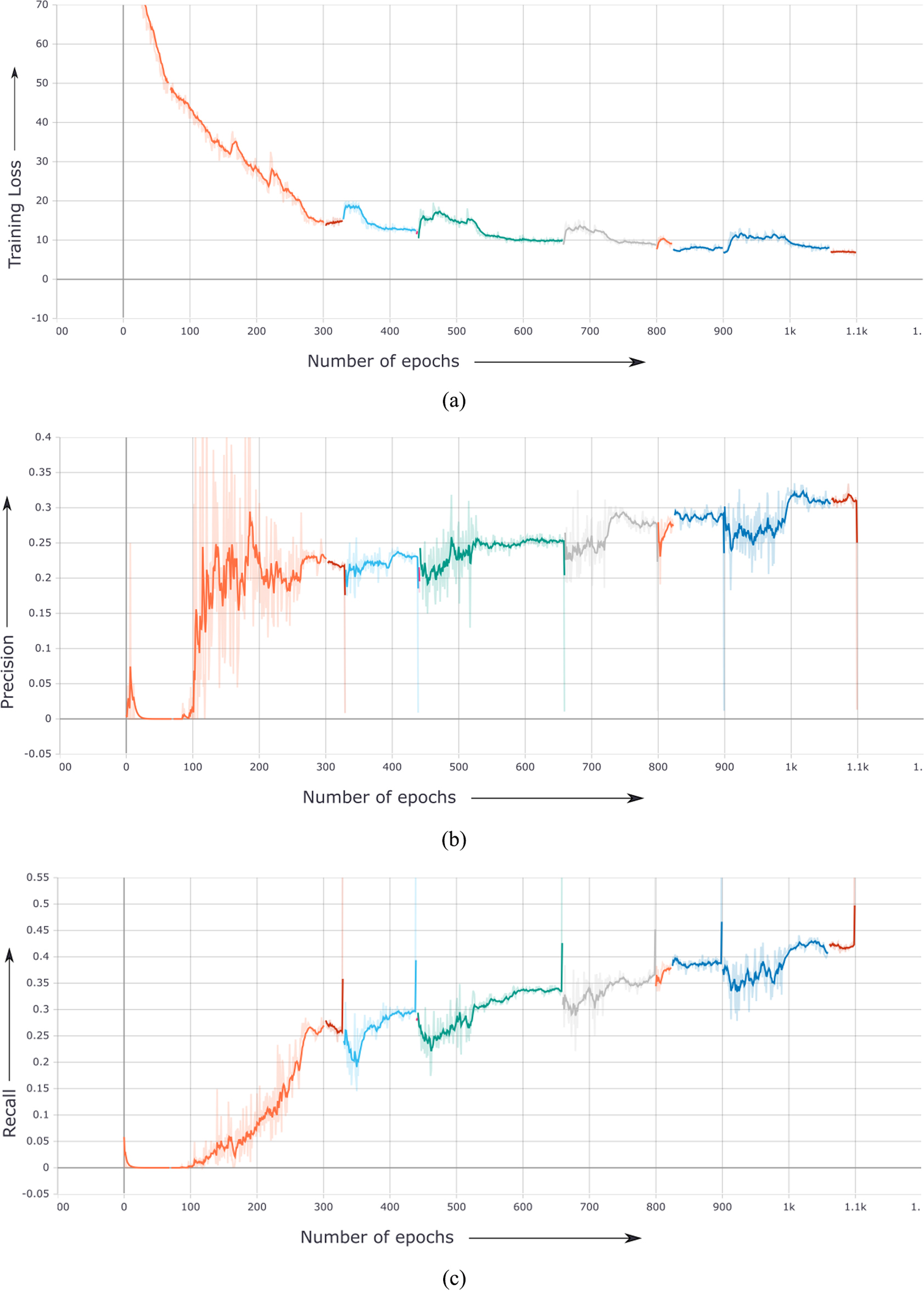
In the proposed system, as shown in Fig. 1, video is first recorded using a camera and then processed into frames using suitable time delay that can be chosen based on factors like angles, traffic density, computing power of the machine used etc. Firstly, necessary packages and models have to be installed while making sure the dependencies are all satisfied and necessary computing power is available. In case the system is not capable, cloud services like Google Colaboratory are leveraged. Then, the open-source dataset that is used to train the model is first acquired. If an annotated dataset is not available, LabelImg can be used to annotate the images which will be of XML form. The annotations are processed into acceptable form, such as CSV files, that the code requires. These are then converted into TFRecords which are given to the algorithms for training after which trained models are obtained. In the prediction module, the generated frames from the video input is given as input to the model which recognizes motorcycle and helmet and draws a bounding box over the recognized object along with the confidence score. The objects other than motorcycles are discarded.
Results
The dataset of 700 imaging was used to train the models by leveraging Google Colab. With a GPU allocation of 11.5 Gb, Faster RCNN took the longest amount of time to train with each step taking longer than a second while SSD steps took milliseconds. In order to compare the algorithms, they were trained with similar configuration values, resources and equal steps. The elements of a confusion matrix [25] are used as metrics. They are true positive (TP), false negative (FN), false positive (FP) and true negative (TN). Consider two classes, namely positive and negative. If the prediction and the actual observation both hold the same value as positive, it is called a true positive. If the predicted value is negative but the observation is positive, it is a case of false negative. Whereas, if the prediction is positive and the observation is negative then; it is a false positive case. Finally, when the predicted and the observed value are both negative then it is said to be a true negative.
As mentioned in Table 1ba and b, Faster RCNN, at 15,000 steps gave no FN values but the highest number of FP values. With more training, it is clear that the FP values are reduced. SSD, at approximately 15,000 steps, gave less TP values and even lesser false positive values compared to Faster RCNN. Although at approximately 30,000 steps SSD detected a higher number of helmets and gave very reduced FP value, approximately 45,000 steps it gives less accurate values when compared to the model trained on 30,000 steps. It can be deduced that with 45,000 steps, Faster RCNN model was better trained whereas the SSD model was overfitted. The SSD model had less to no improvement from 35,000 steps.
The YOLO model trained with a total for 1100 epochs and is compared with models trained with 660 and 800 epochs. A batch size of 24 required 11.5 Gb GPU capacity while a batch size of 32 required 14–15 Gb GPU capacity. The training loss, precision and recall of YOLO is shown in Fig. 2a–c respectively
Evaluation metrics (comparison of EasyNet with RCNN and Faster RCNN)
Evaluation metrics (comparison of EasyNet with RCNN and Faster RCNN)
Testing experimental results
As shown in Table 3b the pretrained YOLO model has 100% accuracy in detection motorcycles. At 660 epochs, 2 helmets are recognised and there are less FP cases. At 800 epochs, helmets are detected but there is also an increase in FP cases. As the epoch number goes higher, the recognition gets slightly better and FP cases reduce more significantly. Detection of helmets in the higher angle video, is very low regardless of increase in number of epochs.
Irrespective of the number of detections, the training process can be clearly observed with higher steps and epoch levels when farther and less significant objects are recognised accurately, and the bounding boxes are more precise. In the front angle video, at least training levels, only the objects the front lines were detected and with more trained models, FN values were of objects with less visibility among other vehicles. At higher training levels, less visible objects were better detected, and confidence score improved.
Object detection can be done using a variety of methods. Real time applications are being focused on and implemented extensively in recent times. One such application is automatic detection of motorcycles and helmets. The methods have evolved from using traditional image processing techniques to using machine learning and deep learning models, especially due to the availability of many pre-trained models.
As stated in [4], the proposed model is tested using the PASCAL VOC 2007 dataset in comparison with RCNN and FASTER_RCNN the Easynet model is proven efficient.
The RCNN models generate nearly 1800–1900 bounding boxes which are larger in number compared to the Easynet model which produces around 100 boxes. The FASTER-RCNN lacks real time performance which the CNN model overcomes. The Easynet model also outperformed the drawback of the FASTER_RCNN models which use ROIPOOL. On comparing the Easynet model with other models using the mAP the results as shown in Table 4, were obtained and it is hence proved that the proposed model is efficient. The model can further be extended for detecting moving objects.
Curves for all classifiers in helmet detection. (a) ROC Curve, (b) PR Curve.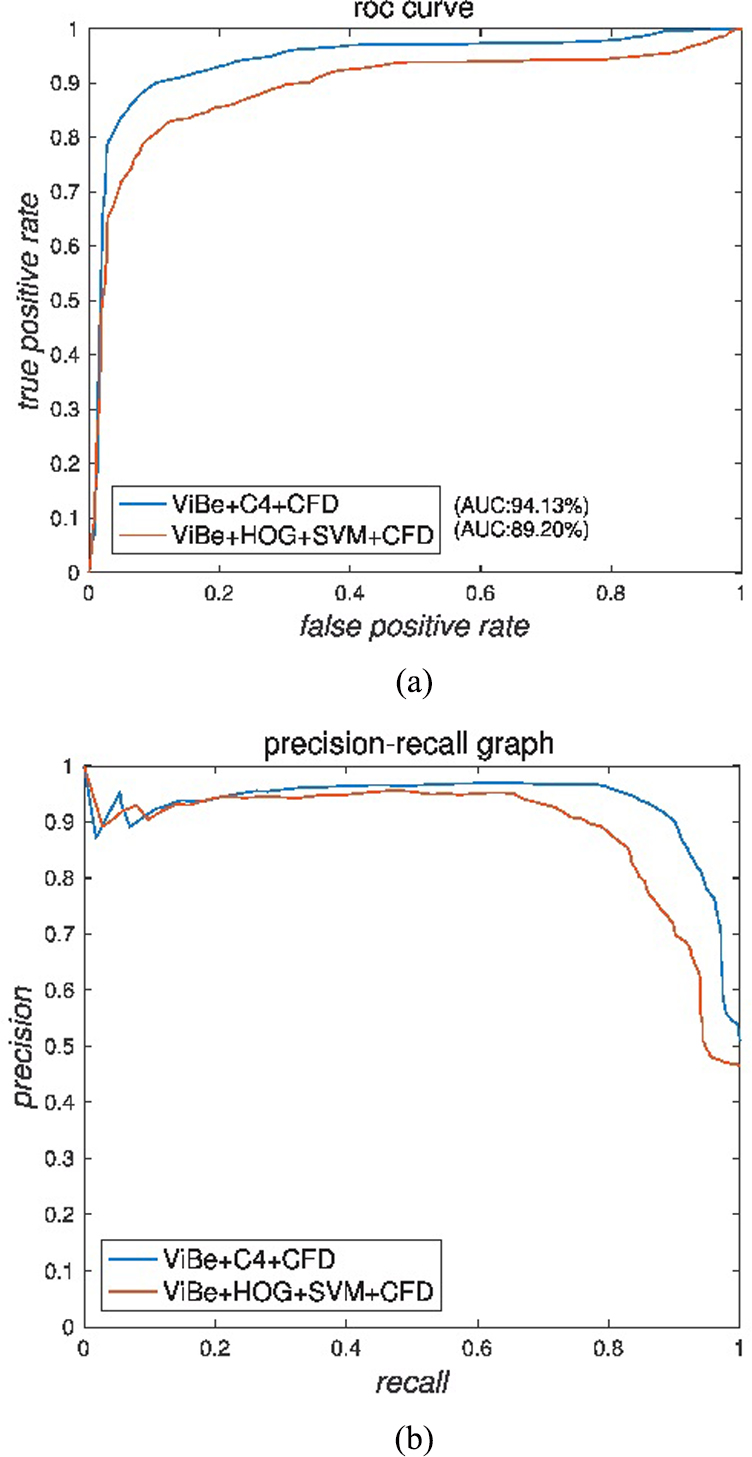
It is proven, in [5], that the C4 classifier has limits in the description capability. The Receiver Operating Characteristic (ROC) curve and Precision Recall (PR) curve is plotted to illustrate the efficient performance of the proposed model. The Receiver Operating Characteristic (ROC) curve and Precision Recall (PR) curve is plotted to illustrate the efficient performance of the proposed model as shown in Fig. 3a and b respectively.
Comparing the processing speed
Comparison of different algorithm using different metrics
Testing experimental results
In the proposed model in [7], using regression, the classifier identifies the safety helmet and then calculates the exact location. With the help of these results, the proposed method has outperformed the SSD detector with higher AP during testing phase. This is significant in Table 5. The experimental results, tabulated in Table 6, says both models perform faster than 20 FPS. Real time detecting is achieved in the proposed system. Safety helmets are detected much better in the proposed system when compared with the SSD detector.
The literature [8] found Inception V3 and MobileNets to have better accuracy. MobileNets are more accurate than the VGG models, as shown in Table 7, and were therefore chosen. Single Shot Multibox Detector (SSD) was used with Inception V3 and MobileNets for image detection. MobileNets with SSD gave better results closely followed by Inception V3 with SSD. The arguably more desirable aspect of this approach is that it requires a single runtime and no other image pre-processing algorithms.
KITTI and Cityscapes datasets are used for the experiment by [9]. Different algorithms such as YOLO, MobileNet with SSD, Faster RCNN with ResNet and with Inception, used are compared using different metrics used are shown in Table 8. The experiment included images containing classes with its objects. The classes are “pedestrian” and “car”. The processed images are shown in Fig. 4.
Examples of vehicle and pedestrian detection.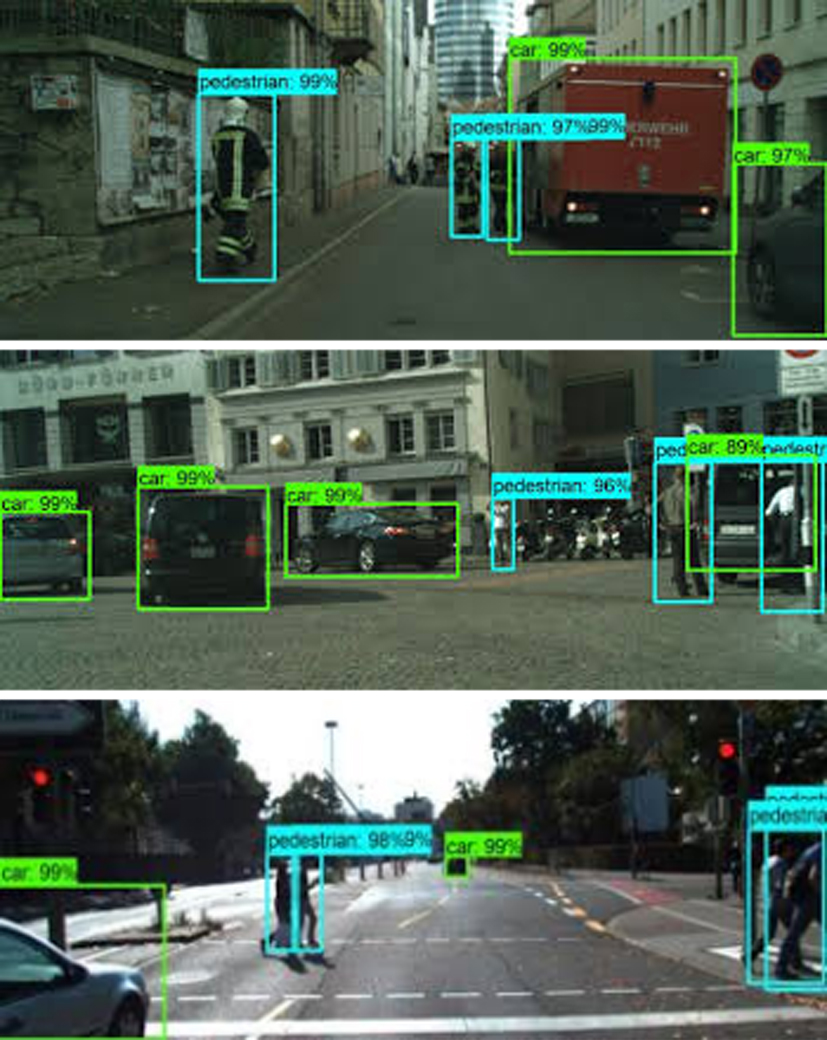
This research tries to shed some light on how it is necessary to know which model is more suitable to the problem statement which can be have a considerable impact in applications.
In this paper, irrespective of the number of detections, the training process can be clearly observed with higher steps and epoch levels when farther and less significant objects are recognized accurately, and the bounding boxes are closer and more precise. In front angle video, at least training levels, only the objects the front lines were detected and with more trained models, FN values were of objects with less visibility among other vehicles. At higher training levels, less visible objects were better detected, and confidence score improved. In the higher angle video, detection of helmets is very low despite having a considerably better motorcycle detection accuracy with lesser epochs. Since this is also observed in SSD but not in Faster RCNN, it is probably not only due to training data distribution and is also due to the build of the algorithms.
The implementation of the different algorithms on the same dataset highlights the advantages and disadvantages in each. If the most important factor is time and delays cannot be afforded, YOLO is the most suitable algorithm. If precision is the most important factor and time to train and obtain results is not a concern, Faster RCNN is more promising. SSD offers middle ground between these two algorithms. Also, it is important to notice that if FNs are to be vehemently avoided and FPs can be tolerated, Faster RCNN is the most suitable. It can be concluded that the problem statement has to be thoroughly understood and the objectives analyzed before choosing the algorithm to implement.