
Abstract
Autonomous vehicle platoons have become an increasingly popular solution to enhance driving system performance and facilitate the safe integration of these vehicles on the roads. To ensure efficient platoon traffic, it is essential to effectively manage both speed and direction within this group of vehicles.
It is in this context that this research is situated. Our primary objective is to enhance the performance of speed and direction controllers, as the ability of vehicles to adjust these parameters in a coordinated manner is crucial for the success of platoon traffic. To achieve this, we have developed a novel speed control approach based on neural networks and fuzzy logic, utilizing V2X communication. By incorporating environmental parameters through vehicle-to-vehicle communication and considering the specific goals of the platoon, our neuro-fuzzy system can accurately calculate optimal speeds and directions for the vehicles.
Our experiments have demonstrated the effectiveness of this approach compared to traditional and advanced methods, improving both energy efficiency and temporal coordination of autonomous vehicles within the platoon.
Keywords
Introduction
The emergence of autonomous driving systems [1, 2] has brought significant changes to the automotive industry. These systems, based on technologies such as perception [3], artificial intelligence, and advanced sensors [4], enable vehicles to operate without direct human intervention.
Real-time road data access is crucial for autonomous driving systems, as it enables them to have up-to-date information about road conditions in order to plan and navigate safe and efficient routes [5]. Autonomous vehicles (AVs) [6] are equipped with advanced sensors such as cameras, lidars, and radars, which gather information about the road environment, including traffic, signage, and potential obstacles. Through Vehicle-to-Infrastructure (V2I) [7] communication, autonomous driving systems can connect to intelligent transportation infrastructures to retrieve real-time road information, such as traffic conditions and incidents. Similarly, Vehicle-to-Vehicle (V2V) [8] communication allows vehicles to exchange information with each other to acquire real-time data about road conditions and events. By combining onboard sensors with V2V and V2I communications, AVs can obtain an extended view of the road environment.
In addition to exchanging road information, AVs can also collaborate with each other through V2V communication to share information about their position, speed, and driving intentions. By using this data, vehicles can work together in a coordinated manner, adopting consistent and predictable driving behaviors.
We’re discussing cooperative autonomous driving systems, specifically referring to platoon [1, 9, 10] traffic, which involves a group of AVs moving in close and coordinated formation on the road. These vehicles operate cooperatively, communicating with each other and coordinating their actions to optimize their movement and maximize the efficiency of the system.
Autonomous driving can be modeled in numerous ways. However, the crucial factor to consider is the practical implementation of the driving model with reduced complexity and execution time. The goal is to design an intelligent speed controller that is both accurate enough to replace human driving and efficient. In this context, fuzzy logic emerges as a promising approach for modeling the speed control of AVs.
Based on cooperation with other vehicles on the road, an AV can collect the necessary traffic data for its operation. In a cooperative autonomous driving system, to achieve a high level of autonomy, an AV must be capable of automatically adjusting its speed and direction within a platoon.
The stability of platoons in autonomous driving systems refers to the ability of AVs to follow the speed and/or acceleration profile while maintaining a bounded spacing and/or velocity error. In other words, this means that each AV must be capable of adhering to the platoon instructions by maintaining a predefined minimum distance and similar speed and acceleration, all while avoiding collisions or platoon disintegration.
The stability of platoons in autonomous driving systems depends on many factors, including coordination and communication between vehicles, regular updates of road data, the precision of the control system, and the characteristics of the AVs forming the platoon. These factors must be considered to ensure the safety and efficiency of platoons on the road. Therefore, a good platoon movement controller is a stable controller that allows for the minimization of speed deviations and closely tracks the reference speed with minimal error.
The primary contributions of our work lie in the design and implementation of an intelligent speed controller aimed at enhancing the management of AV platoons. This contribution is based on the integration of V2X communication to foster effective cooperation between AVs within the platoon and roadside units. Our controller leverages kinematic traffic data collected and exchanged among the platoon vehicles, relying on a supervised neuro-fuzzy architecture. This innovative approach optimizes the speed and direction of AVs within the platoon, thereby improving road safety and operational efficiency. By highlighting the advantages of our controller through a detailed performance evaluation, our work makes a significant contribution to the advancement of autonomous driving systems and the realization of safer and smarter roads.
In this paper, we propose a cooperative distributed system for autonomous platoon speed and direction management, combining neural networks with fuzzy logic. Divided into three sections, we start with a review of the state-of-the-art, highlighting recent advancements and identifying gaps in the field. Next, we present our distributed autonomous driving system, based on a supervised neuro-fuzzy controller, providing improved accuracy and responsiveness. The third section validates our approach through simulations. In conclusion, we summarize our contributions and emphasize potential future research avenues to enhance autonomous driving technology for platoons.
Related work
Conventional cooperative speed controllers are often based on physical kinematic models. These models are mathematical representations of vehicle dynamics, taking into account variables such as speed, position, acceleration, mass and other physical factors. Model selection is therefore an important phase in the design of this type of controller. A good model ensures stability, robustness and tracking of leader position and speed, while maintaining a constant inter-vehicle safety distance. To achieve this, we need to bear in mind that vehicles are dynamic and non-linear systems, as they are dependent on many external environmental factors such as gradient, road quality, etc.
In autonomous cooperative systems, conventional controllers fall into two categories: non-cooperative controllers and cooperative controllers. In the first category, as shown in Fig. 1, there are two types of controller:
Classic cruise controllers.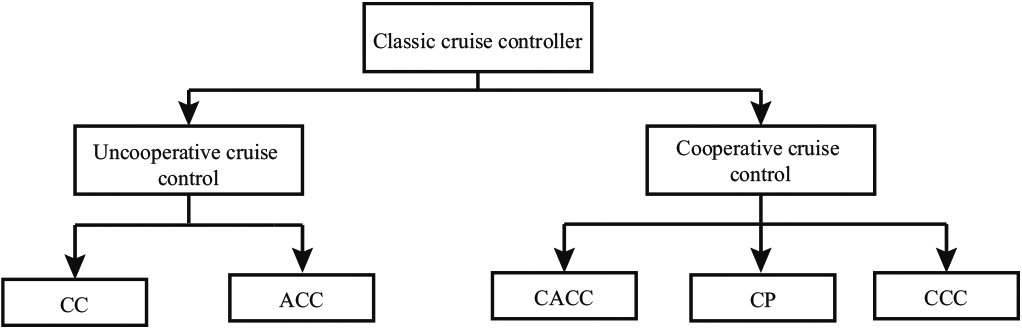
Cruise Control (CC) [11, 12]: This controller is implemented in a standard vehicle with zero range. It allows manual adjustment of the vehicle’s driving speed. Adaptive Cruise Control (ACC) [13, 14]: This controller can be implemented in vehicles grouped together in a static, homogeneous Platoon (all vehicles have the same level of autonomy). ACC equipped vehicles are fitted with a front radar. This radar can detect a preceding vehicle and is able to measure its distance and speed. This information enables ACC to react to changes in speed and control the vehicle’s time difference to the preceding vehicle.
The second category represents the following cooperative controllers:
Cooperative Adaptive Cruise Control (CACC) [15, 16, 17, 18, 19, 20, 21, 22]: CACC enhances ACC with wireless communication, new control logic and GPS. Thanks to intra/inter-Peloton communication technologies, this controller can be seen as an extension of the ACC controller based on V2V communication. Through this communication, the exchange of information between vehicles enables the CACC controller to improve the management performance of vehicles in a Platoon. Using CACC, the vehicles in a Platoon travel at harmonized speeds with reduced safety distance. Connectivity problems and sensor visibility failures limit CACC performance by degrading Platoons’ stability. connected cruise control (CCC): This controller can be used in real-life scenarios where Platoons may be formed by vehicles with heterogeneous levels of autonomy. Based on the CCC controller, the tail vehicle monitors the movement of vehicles in front of the Platoons using V2V communication. Predictive Controller (CP): the Predictive Controller is a cooperative controller for speed control of homogeneous Platoons, based on the use of speed prediction models. Unlike adaptive technologies, CP ensures speed stability between vehicles forming a Platoon. This type of controller is well suited to slow-moving systems, given its high computational cost. Consequently, the increase in response time caused by the CP controller degrades the performance of AVs, which are real-time dynamic systems.
In conclusion, the accuracy of speed controllers depends on the quality of the kinematic models used to describe vehicle behavior. Accurate kinematic models enable speed controllers to predict vehicle behavior with a high degree of accuracy, which can improve the safety and efficiency of autonomous driving systems. However, kinematic models are only an approximation to reality and can be affected by factors such as weather conditions, terrain variations and road defects. Errors in kinematic models can lead to prediction errors and inconsistent results in speed controllers.
The main problem with conventional speed controllers lies in their physical modeling. In this context, intelligent speed controllers have been proposed to regulate vehicle speed by integrating machine learning. The use of machine learning makes it possible to design advanced autonomous automatic driving systems that can adapt to a variety of driving situations, improving the safety and fluidity of road traffic. As shown in Fig. 2, three machine learning techniques are used to create intelligent cooperative speed controllers [23, 24, 25].
Intelligent cruise controllers.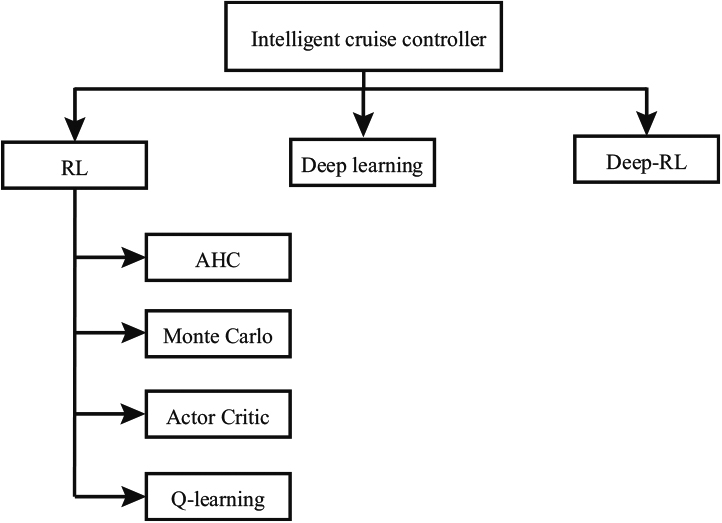
Reinforcement learning [23, 24, 25, 26, 27, 28, 29, 30] is a method that enables an agent to learn how to make decisions that maximize a reward (or minimize a penalty) by interacting with an environment. In the context of speed control in a Platoon, each AV in the Platoon is considered as an agent that adjusts its speed according to the state of its environment (e.g. distance between vehicles, Platoon speed, traffic speed, etc.). To make these decisions, RL algorithms can be trained using simulation data or data collected in real time on the road. They can also be trained to make decisions based on sensory inputs such as distance from other vehicles, speed, weather conditions, etc. RL speed controllers are able to make decisions based on the current state of the environment and the expected long-term reward. Supervised learning using deep-learning algorithms [31, 32] which use raw data as input, the extraction of useful input data is the responsibility of the deep-learning algorithm, since the task of data extraction is a little difficult in some cases. The deep-learning algorithm is based on deep artificial neural networks (a high number of hidden layers), which requires a powerful computer. Deep learning is a learning method that uses artificial neural networks to estimate the optimum speed to follow while minimizing the error rate. This technique requires large quantities of data to obtain accurate and reliable results. So, for speed controllers, it is necessary to collect data under a variety of road and traffic conditions. Once collected, the road data is prepared and processed to adapt it to the neural network input. This data pre-processing stage includes data normalization, filtering, sampling and segmentation. Deep reinforcement learning [33, 34, 35, 36, 37] combines these two techniques (RL and deep-learning). This technique involves training a deep neural network to make speed control decisions in real time, while maximizing a long-term reward defined by the desired goal. The training process then involves the use of reinforcement learning, where the neural network learns through trial and error by adjusting the weights of the neurons to maximize the long-term reward. Deep reinforcement learning enables more complex and sophisticated decisions to be made using deep neural networks that can learn hierarchical representations of the environment and the behaviors of other vehicles on the road.
However, machine learning algorithms can have several disadvantages in the speed control of autonomous driving systems. Firstly, as with any method based on machine learning, it is possible for decision errors to occur. Knowing that speed control decisions will be shared between the leader and his followers, it is possible that these errors will be amplified. This can lead to road safety risks. Indeed, these algorithms are highly sensitive to the data used to train them. If the data is not representative of all possible driving situations, the algorithm may misbehave in certain situations.
There are many ways to model autonomous driving. However, it is essential to consider first and foremost the practical feasibility of implementing the model, minimizing both complexity and execution time. With this in mind, the use of fuzzy logic is proving to be a promising approach for modeling the speed control of autonomous vehicles.
Indeed, designers consider fuzzy logic to be the simplest solution for designing complex processes [38, 39]. This gives fuzzy logic advantages over traditional solutions based on physical modeling. On the other hand, thanks to fuzzy rules expressed in natural language, fuzzy logic enables calculators to perform human-like reasoning. This kind of reasoning enables them to respond effectively to complex inputs (from sensors or cooperative communications) in order to deal with notions such as “obstacle too close” or “obstacle too far”. Since the mathematical model of the autonomous driving process is too costly in terms of computer processing power and memory consumption, a system based on rules of thumb is more efficient. In addition, fuzzy logic is well suited to low-cost implementations that reward the large uncertainties of sensors embedded in CAVs, as well as the limitations of cooperative communications [40]. This approach improves the understanding of human driving for autonomous cooperative driving systems by adding rules. Consequently, in these systems a fuzzy controller can be used to enhance existing traditional controllers by adding an extra layer of intelligence.
Thanks to its aforementioned advantages, fuzzy logic has been used in various applications in the field of autonomous driving, namely trajectory tracking [41], lane change control [42] and Platoons speed management [43, 44].
However, this work proposes a partial speed control in the whole Platoon control process. In addition, the fuzzy controller’s decision is taken following a sequential traversal of the rule base. This can slow down decision making at the CAV level. Expressing the knowledge of a fuzzy controller in the form of natural language rules does not prove that the system has optimal behavior. Since fuzzy controllers are completely dependent on human knowledge and expertise, the rule base needs to be manually updated on a regular basis. What this type of controller lacks is machine learning capability. To this end, thanks to their learning and adaptation capabilities, neural networks have been used in the design of Platoons speed management controllers [38, 39, 40, 41]. This technique is limited by the absence of interpretation of the generated decision. The “black box” aspect of the proposed neural networks is at the root of the difficulty in choosing their architecture.
Therefore, combining fuzzy logic with neural networks could improve the performance of speed controllers in Platoons with a reduction in computation time. On the one hand, direction and speed decisions in Platoons will be justified in natural language through the use of fuzzy logic. These decisions are made on the basis of traffic data shared between CAVs, even in the presence of uncertainties, thus mimicking human driving behavior. On the other hand, automatic rule learning is provided by neural networks.
The neuro-fuzzy approach offers several distinct advantages over alternative methods. Its adaptability to changing conditions and ability to learn from data make it a versatile choice. Moreover, its precision in modeling complex relationships, robustness in handling uncertainty, and real-time adaptation capabilities contribute to improved performance and safety in autonomous driving systems. Additionally, the reduced rule complexity and generalization capabilities enhance the comprehensibility and applicability of neuro-fuzzy models, making them a compelling choice for optimizing the speed and direction control of autonomous vehicle platoons.
The Platoon motion control process is a complex system used to facilitate autonomous driving. Autonomous driving is a real-time system, requiring a low execution time. The implementation of the neuro-fuzzy controller makes it possible to exploit the computational capacity of a neural network, which is likened to a massively parallel computer, enabling a decision to be made with a reduced computation time. This solution consists in building the different parts of a fuzzy inference system using neural networks which are assembled to provide a global neural structure in which the different operations performed in a fuzzy inference system can be identified.
General architecture
Figure 3 shows the overall architecture of the autonomous driving system composed of five layers:
Cooperative control system architecture for platoons.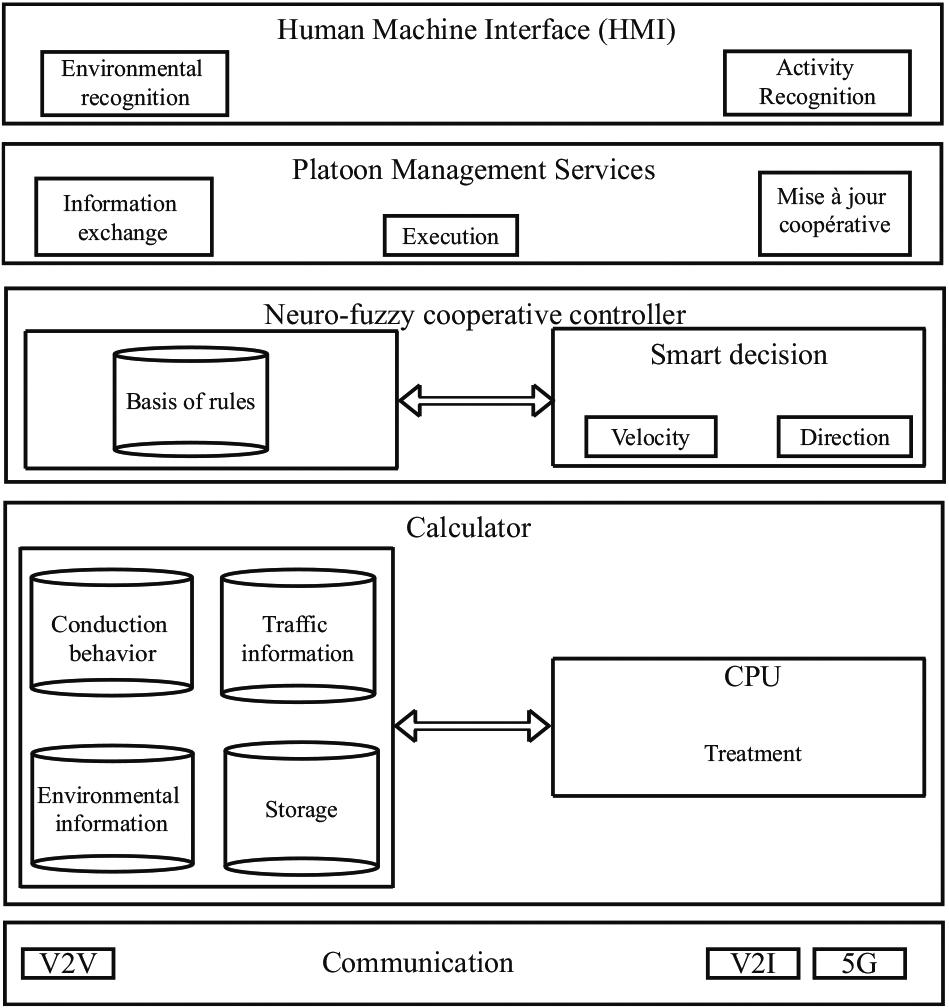
The first layer of this architecture is called the “communication layer”. It includes three modules:
V2V module: which ensures communication between leader and followers via DSRC, V2I modules: ensures communication between leader and RSUs, 5G-V2x module: provides cellular communication between leader vehicles and the external environment such as HD-map [45] servers and neighboring leaders. Each vehicle adopts the communication module that corresponds to its role. The second layer, called the “computer” layer, is designed for the leading Platoon vehicles. It is the road environment information processing layer. The third layer named “fuzzy neuro cooperative controller” exploits the data processed at the previous layer for the management decision of the Platoon movements. The fourth layer named “Platoon Management Services” allows the exchange of updated speed and direction information between the leaders and each leader with his followers. The exchange of information and the cooperative update take place following the execution of the cooperative controller’s decision by all vehicles in the Platoon. The fifth layer represents the scoreboard and allows you to visualize and check the execution status of decisions already made.
Control system operating principle for platoons: leader vehicle case.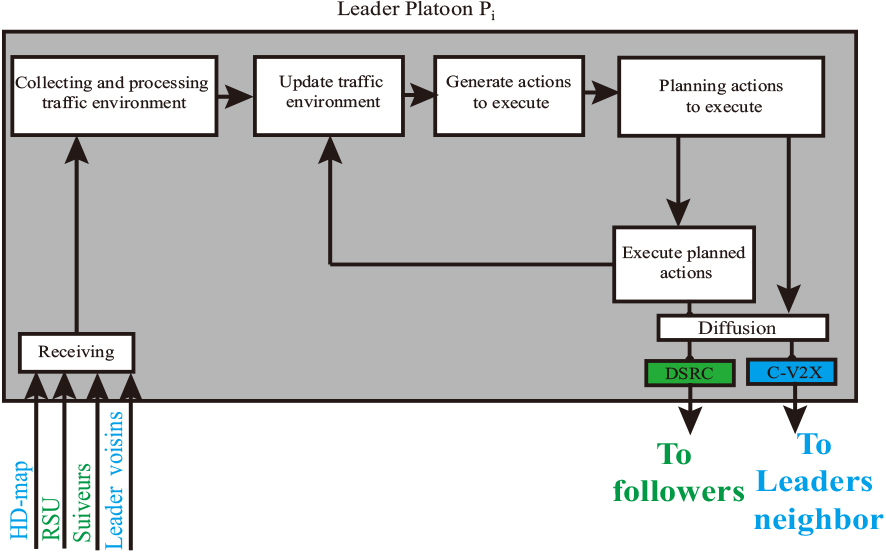
We have proposed a Platoon movement control system based on cooperative information exchange between vehicles. The operating diagrams of our solution at the level of a leader vehicle (respectively a follower vehicle) are shown in Fig. 4 (respectively Fig. 7). For a leader, as shown in Fig. 4, the neuro-fuzzy controller is based on five steps:
In this step, the vehicle collects the information it needs to make a decision. Information is gathered by observing the traffic environment, the status of following vehicles, and environmental information retrieved from (RSU, HD map, etc.). Based on the information collected, the leading vehicle updates information about its traffic environment. The leading vehicle then uses the information collected to generate the appropriate road actions. Two types of actions are considered: (i) steering actions (turn left, turn right or stay), (ii) speed actions (maintain speed, accelerate, decelerate or brake). Depending on the road information, the leader plans the actions generated in chronological order of time and position of the realization. Action planning will be shared with its followers and the leaders of neighboring Platoons via the V2V and C-V2X connectivity types, respectively. Each time an action is executed, the leader updates the traffic environment information stored in its ECU.
As soon as actions are received from the leader, each follower launches the fuzzy controller process shown in Fig. 7. This process has three main phases:
Each follower executes the action plan received from the leader. It must also update the traffic environment information after each action execution. Each follower notifies the leader of the execution of actions and shares with him his new state of the traffic environment. These notifications enable the leader to supervise the ability of his followers to apply the actions generated.
Control system operating principle for platoons: Follower vehicle case.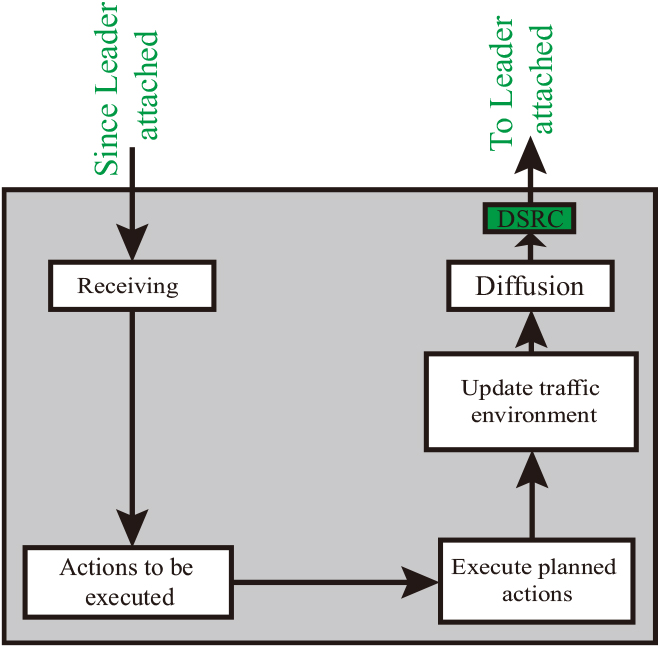
The neuro-fuzzy network, allowing the control of the direction and speed of the Platoon, consists of five layers as illustrated in Fig. 6. The first layer, receiving its data from the sensors and V2X communication, communicates the input data (Position, safety distance and obstacle states) to the second layer (fuzzification) which, in turn, calculates the degrees of membership of the input variables to the various classes of situations. Each input has either seven classes or five classes as shown in Table 1. The fuzzy set of the deviation allowing the management of direction (Table 2)
Input classes
Input classes
Output classes
Neuro-fuzzy network.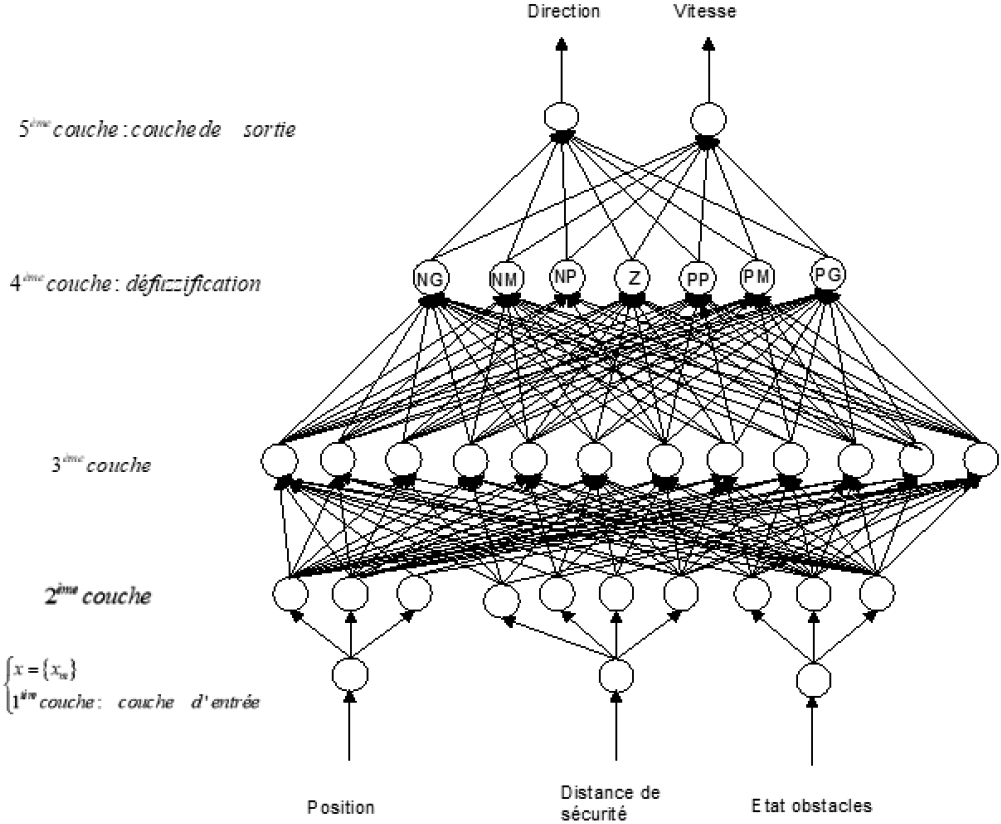
The third layer calculates the degree of membership of the premise part, by the realization of the logical AND operator, by taking the minimum of the memberships having activated the
The weights linking the third layer to the fourth layer are equal to one. The fourth layer calculates the degrees of membership of the conclusion parts whose classes are defined by the activation functions of the neurons of the layer in question. It performs the logical OR function. The
with:
The fifth layer of the neural network performs the defuzzification of the values provided by the activated rule set.
The neuro-fuzzy controller used to manage Platoon movements is shown in Fig. 7. It is implemented in all vehicles. Each vehicle that starts moving periodically sends a message to announce its existence in the vehicular network. Following this network message, it either joins a Platoon that has not reached its maximum capacity, if one exists, or becomes the leader of a new Platoon. Vehicles that follow each other and are connected via DSRC communication form a Platoon. Each leader vehicle collects traffic and environmental information from several types of sources (i) internal: followers and RSUs. (ii) external: neighboring leaders, external servers, etc. The leader uses the DSRC and cellular communication protocols for internal and external sources respectively. Subsequently, during the fuzzification phase, each piece of data collected is represented by a class of the fuzzy set E. Once the membership classes of the road and environmental data have been obtained, they are used to evaluate the fuzzy rules. A fuzzy rule combines input variables using the logical operator “AND”. For example, if “Safety distance is very large” AND “No obstacles” then “High acceleration”. The result of this evaluation is the set of rules that could be applied to the final decision. Each rule returns a unique conclusion representing the result of the evaluation of the membership classes given as input. In order to obtain the final conclusion to be applied, the adjustment phase is used to adjust the outputs of the returned rules. The final stage in the neuro-fuzzy process of managing Platoon movements is defuzzification. As the name suggests, this is the reverse of fuzzification. Defuzzification consists in determining numerical values from the fuzzy outputs adjusted in the previous step. These values then represent the final decisions (speed and direction) for controlling a Platoon’s motion management system.
The decisions generated will be broadcast via DSRC to its attached followers and via cellular communication to other nearby leaders. After receiving the decisions, each follower updates its speed and direction, then shares its new environmental data with its leader. In turn, the leader updates the Platoon’s overall status.
We obtain two cases to treat:
Neuro-fuzzy controller algorithm.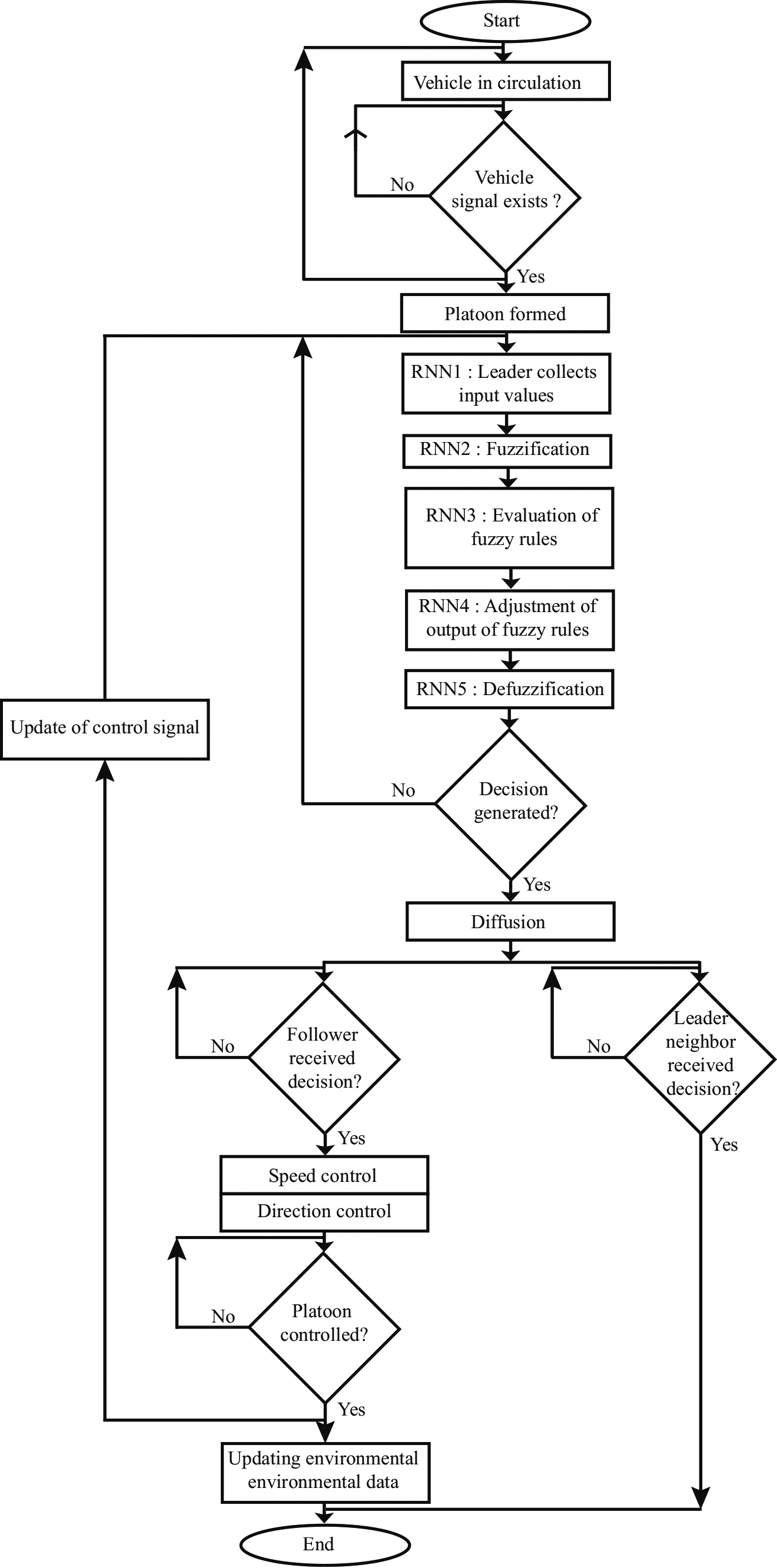
Direction management case (Table 3): (i) When the command accuracy is high, the Platoon’s command signals are executed and the degree of the automatic decision is increased. For example, if the automatic decision is slight left deviation (NP), and the Platoon’s command is to turn left, which is judged correct after supervision (
Membership functions of input and output variables: case of management of direction
Traffic speed processing case (Table 4): (i) When the accuracy of the control signal is high, the speed management command of Platoon is executed and the confidence level of the automatic decision is increased. If the automatic decision is a small acceleration (PA), and the Platoon’s command is to accelerate, which is judged correct after supervision (
Membership functions of input and output variables: case speed management
The simulation is performed on a network of several centralized Platoons, each of which consists of eight vehicles, as shown in Fig. 4. Each Platoon contains a leader vehicle, and seven self-driving follower vehicles in an urban environment. It is assumed that all vehicles in the Platoon are equipped with a DSRC communication module and a cellular communication module.
We take into account the presence of obstacles that are scattered in the road. We have considered this scenario to detect the different critical situations of speed change. For example, Platoon 5 or Platoon 4 can improve the visibility of Platoon 1 in case of a change of direction (right or left turn). This allows the leader of the latter to better predict the new speed to be adopted. Within the Platoon, the leader vehicle manages all the following vehicles by broadcasting a periodic CAM message, every 100 ms, to inform them of the traffic speed to be respected. For real-time decision making, each following vehicle periodically sends its updated status.
Performance metrics
The neuro-fuzzy approach is essentially based on a speed and direction prediction algorithm in Platoons. It is then necessary to study the accuracy level of the algorithm as well as its time complexity. In addition, it is necessary to evaluate the error rate that can occur after the application of the decision. Then, we consider the following three performance metrics:
The accuracy of the prediction algorithm: this is the percentage of true predictions given by the following equation:
With
Convergence time: this time depends on the execution time of the three phases of the prediction algorithm: collection of traffic information, prediction and diffusion. The convergence time is given by the following equation:
with Decision tracking error: after the execution of the neuro-fuzzy algorithm, each vehicle in the Platoon changes its speed according to the decision made by the leader. However, we can have errors during the application of the decision since this maneuver depends on the state of the vehicle actuators. The error of
With
Test environment.
Figure 9, shows the evolution of the percentage accuracy of autonomous driving system as a function of the number of Platoons. The accuracy of the proposed neuro-fuzzy approach increases rapidly and reaches an accuracy of 90% from 5 Platoons, and stabilizes at an accuracy that exceeds 95% from 8 Platoons. This is justified by the fact that if our controller has a global view on the traffic environment its accuracy improves.
Comparison of the accuracy according to the number of Platoon between the proposed approach (neuro-fuzzy), CPFCC and RL.
Inter-platoon propagation delay depending on the Platoons.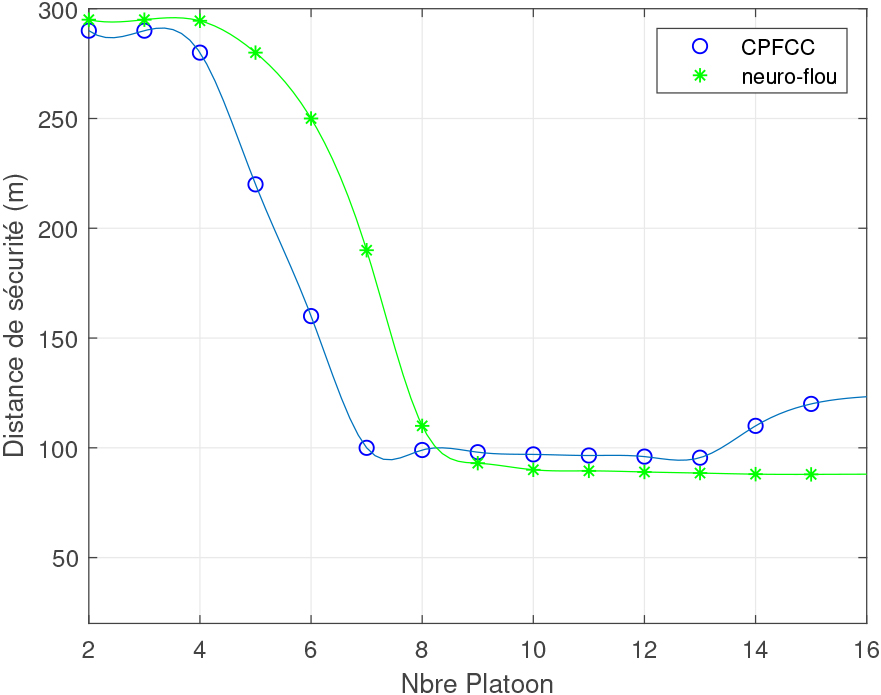
Safety distance according to the number of vehicles.
Safety delay according to the number of vehicles.
Safety distance according to the number of Platoon.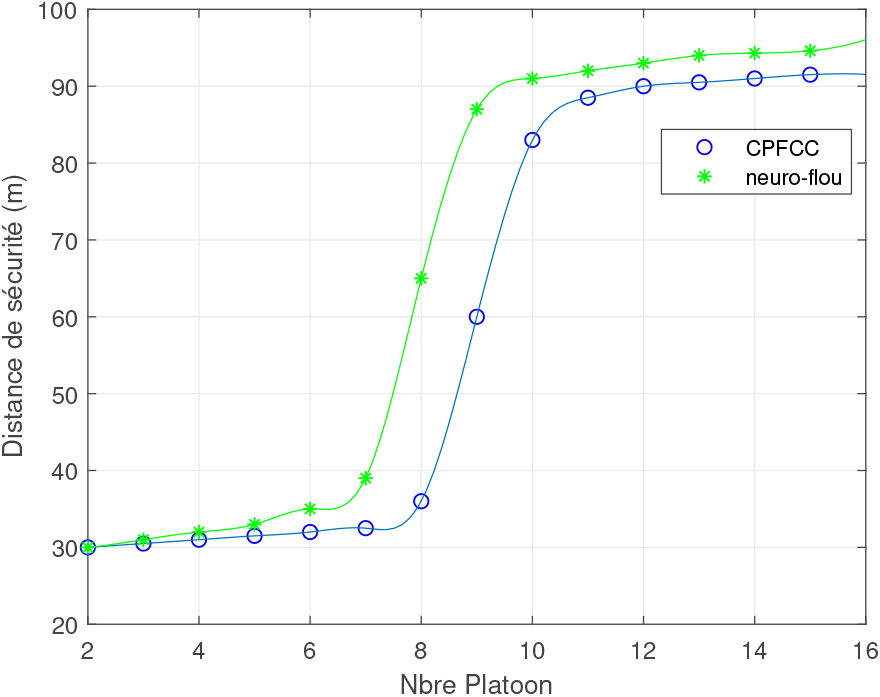
Security delay depending on the number of Platoons.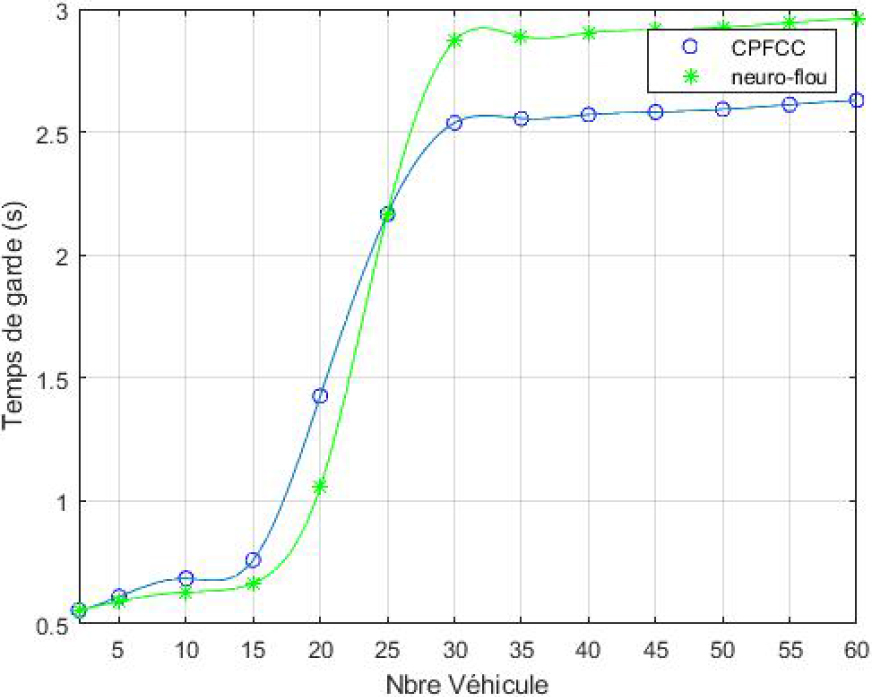
Safety distance according to numbers RSUs.
Security delay depending on the number of RSUs.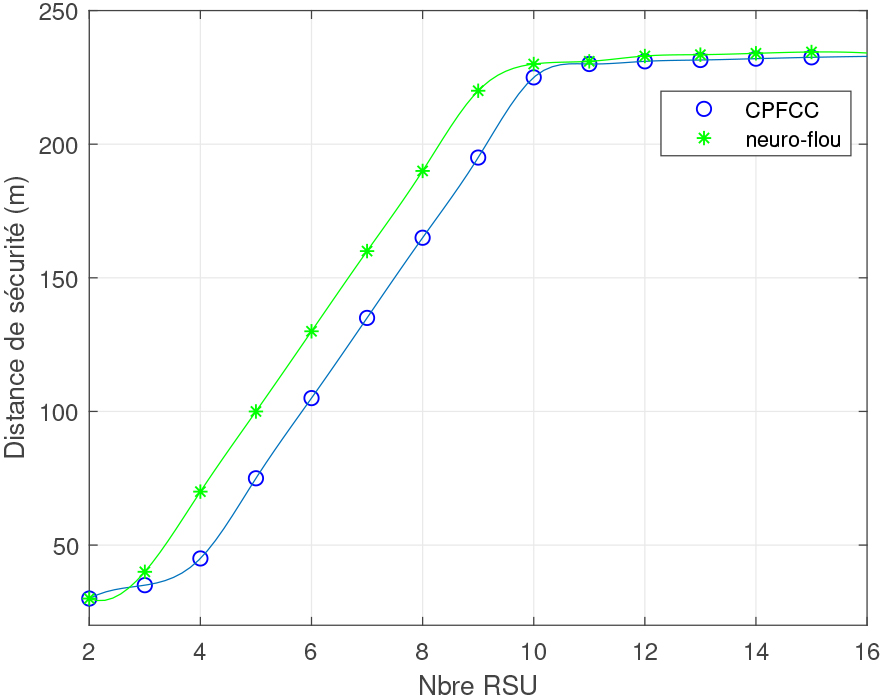
Convergence of optimization criteria as a function of time.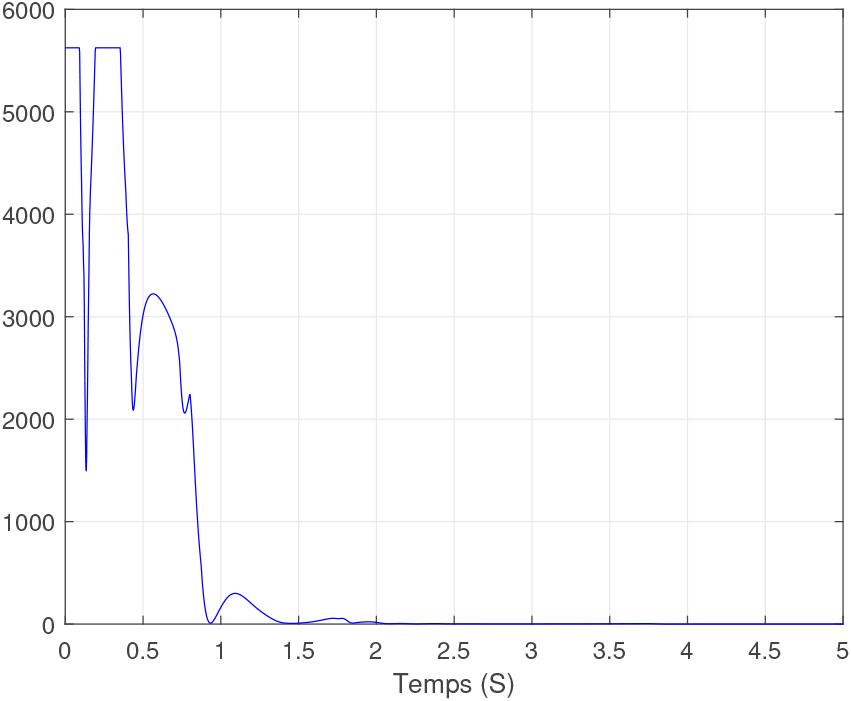
The tracking error of the action provided by the leading vehicle as a function of time.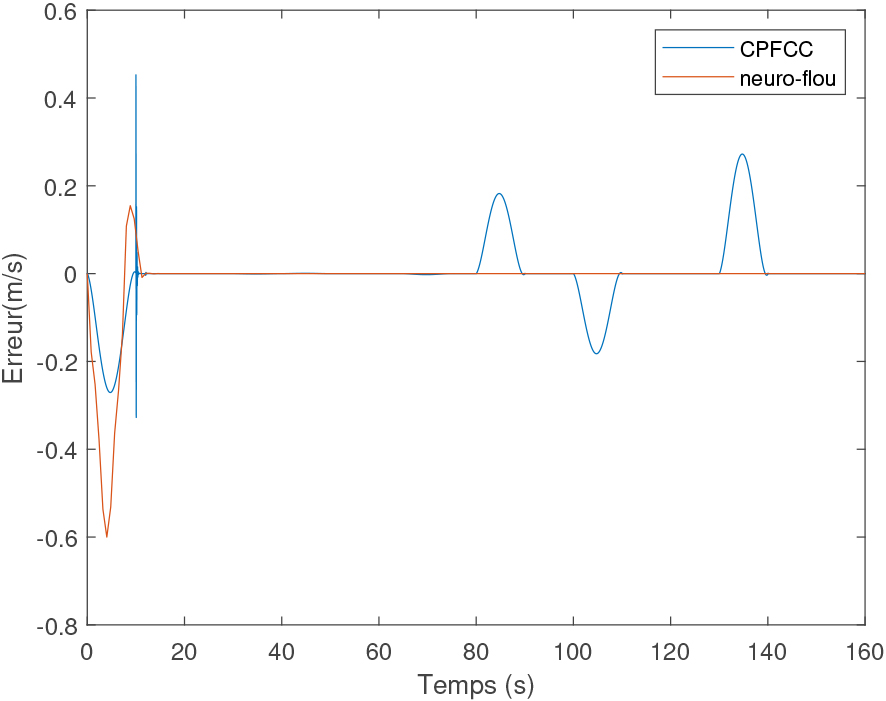
For a number of Platoon less than 6 the accuracy of CPFCC is better than that of our proposed approach, since the neuro-fuzzy controller requires a learning phase that gives good results only when all the necessary traffic data are collected. If the number of vehicles increases, the modeling phase becomes more and more difficult, but the machine learning becomes more efficient. For this reason, beyond 6 Platoons the accuracy of CPFCC degrades and stabilizes at about 85%, while that of our approach improves and exceeds 95%.
It’s interesting to observe that the neuro-fuzzy-based approach exhibits higher accuracy compared to reinforcement learning (RL). This superiority can be attributed to the inherent ability of neuro-fuzzy systems to integrate expert rules and prior domain knowledge. Fuzzy rules provide the means to model intricate relationships between input and output variables in an interpretable manner, thereby offering more precise guidance to the control system. By mitigating the issue of misguided exploration often encountered in the complex environments of reinforcement learning, this approach reduces the risk of errors. Additionally, the design of neuro-fuzzy systems for resilience against environmental variations and uncertainties enhances their capability to maintain high accuracy in real-world scenarios. However, it’s worth noting that the comparison between these two approaches hinges on the specific task characteristics, the quality of their respective implementations, and other influencing factors.
In conclusion, autonomous driving systems based on physical models are dedicated to a reduced number of vehicles. On the other hand, if the number of vehicles on the road increases, the methods based on machine learning are more adapted, and reward the limits of the methods based on physical models.
The main objective of autonomous driving system is to reduce dangerous situations, as we described before the key to improve the accuracy of our approach is the collection of traffic data (speed, obstacle, direction, position, …) for that the propagation time of traffic data between Platoons is a very important metric.
Figure 10 represents the propagation time of the inter-platoon data as a function of the number of platoons. The propagation time of CPFCC is better than that of Neuro-flou for a number of platoons lower than 6, beyond this number the propagation time degrades and becomes increasing from 12 platoons onwards, this is due to the saturation of the computer. On the other hand, the propagation time of the neuro-fuzzy approach is higher than that of the CPFCC approach, which is due to the learning and supervision phase, but once the controller collects the data necessary for traffic, the propagation time improves and becomes invariant to the number of Platoons, which justifies the fact that the neuro-fuzzy approach considerably improves the performance of autonomous driving systems.
The improvement of the propagation time will serve to inform the Platoons, in advance, about dangerous situations that may occur.
Figure 11 (respectively 12), shows that the safety distance as a function of the number of vehicles (respectively guard time as a function of the number of vehicles) increases and saturates at about 80 m (3 s) from 30 vehicles. The same is true for the safety distance (time) as a function of the number of Platoons Figs 13 and 14 (RSU).
In an area of 2.5 Km2 with 2 Platoon that circulates we vary the number of RSUs installed at the roadside, we notice that the safety distance (guard time) saturates from 10 RSUs (as shown in Figs 15 and 16). It can also be seen that from 5 RSUs onwards, the maximum safety distance obtained without RSUs is exceeded.
Since the cost of installing RSUs is very high, in order to guarantee maximum security, it is suggested to use a maximum of 2 RSUs in areas with high traffic and to install half the number of RSUs to reach saturation.
In conclusion, using the neuro-fuzzy approach we have a gain of about 15% compared to the CPFCC approach from saturation. I.e. we have 3.5 seconds to act in front of a dangerous situation, which is largely sufficient, thereafter the accuracy of the neuro-fuzzy controller increases compared to that of CPFCC.
Figure 17, shows the convergence of our algorithm which converges at about 1.5 s. During these first 1.5 s the vehicles are in the process of starting the traffic speeds are reduced, thereafter this time of convergence does not pose problems from a safety point of view.
Figure 18, shows the tracking error of the action provided by the leader vehicle as a function of time. The error of the neuro-fuzzy approach is larger than that of CPFCC which is due to the convergence time. Once our algorithm converges the tracking error becomes almost zero, which proves the improved performance of the neuro-fuzzy approach compared to approaches based on physical modeling.
In conclusion, for light traffic with one, cooperative autonomous driving systems based on physical models are recommended. However, as the number of vehicles on the road increases, methods based on machine learning become more suitable. Since the installation costs of RSUs are high, we recommend limiting their use to a maximum of 2 in high-traffic areas containing several platoons. For low-traffic areas, the installation of 3 RSUs representing half the number of RSUs needed to achieve stabilization is generally sufficient to guarantee maximum safety. Using the neuro-flou approach, we observed a gain of around 20% over the CPFCC approach from stabilization onwards. In other words, we have around 3.5 seconds to react to a dangerous situation. This guard time is considered to be more than sufficient, helping to increase the accuracy of the neuro-fuzzy controller over that of CPFCC.
The objective of the penetration of AVs on the roads, is for the minimization of accidents in addition to the comfort of the drivers. To ensure these objectives in this chapter we have presented a cooperative autonomous driving strategy based on artificial neural network learning. As the modeling of AVs is very complicated we proposed the fuzzy logic which allowed us to ignore the modeling phase and our proposed algorithm is implemented by simulation, which gives good results for the speed management of AVs. As the Platoons are built in a natural way from where all the followers have to follow the speed of leader which sometimes can’t reach the maximum speed of the road which can cause traffic jams. Therefore, a reorganization in the formation of the Platoons is necessary to improve the traffic flow. However, the neuro-fuzzy approach may encounter challenges in handling extreme situations or rare events that are not adequately represented in the training data.
We should therefore concentrate on the actual validation of the neuro-fuzzy controller. This essential step will enable us to confront the controller with real traffic situations, in order to assess its responsiveness, stability and ability to make informed decisions in real time. Field validation will also enable us to gather relevant data to refine the controller and make it perform better in a variety of road environments. In addition, optimization efforts could be undertaken to improve the neuro-fuzzy controller by taking into account various factors, such as fluctuating traffic management and variable weather conditions.