
Abstract
Brain Computer Interface (BCI) – one of the recent advancements in the field of Bioinformatics which offers a real-time support for the people, who are affected by chronic neurological disorders. Owing to the rapid progression of Electroencephalogram (EEG) – based BCI system, the detection of epileptic seizures has become much simpler. However, accurate detection through visual inspection is tedious, time-consuming and prone to error. Thus, automation has become inevitable and for automating the epileptic seizure detection, entropies are appropriate as the nature of EEG signals are complex, arrhythmic, ephemeral, and non-stationary. Several renowned entropies are widely applied, nevertheless, the existing models fail to identify the optimal parameters of the entropies which greatly influences the performance of the Machine Learning models that could make better predictions. Hence to address the aforementioned issue, this paper presents a parallel machine learning based farmland fertility algorithm which optimizes the parameters of various entropies thereby detecting Epileptic Seizures in a systematic way. A novel weighted fitness function has been designed based on Kullback-Leibler Divergence (KLD). The extracted features are further classified using state-of-the-art classifiers. The overall performance of the proposed algorithm was evaluated using the EEG dataset obtained from University of Bonn, Germany, University of Bern and Indian EEG, New Delhi and the results show the supremacy of the proposed model in terms of sensitivity, specificity, precision, F1-score, G-mean and classification accuracy.
Keywords
Introduction
Epilepsy is a condition of the brain causing seizure, hence it is also known as seizure disorder that affects people of different ages, races, and backgrounds [1]. In seizure disorders, electrical activity of the Central Nervous System is intermittently disturbed, which results in a certain degree of momentary dysfunction [2]. Recently Bangalore Urban-Rural Neuro-epidemiological Survey conducted a population-based survey to estimate the prevalence of epilepsy and observed that an average of 8.8/1000 population are affected, with the prevalence rate in rural communities (11.9) being twice that of urban areas (5.7) [3]. This survey highlights the need to respond to the huge prevalence of epilepsy. Moreover, the occurrence and frequency of seizure is in-deterministic and people with epileptic seizures face challenges in their everyday life. Therefore, it is ineluctable to develop a robust epilepsy detection model which simplifies the diagnosis process and provides better treatment to the patients [4]. The treatment of epileptic seizures depend on its accurate diagnosis. In general, to diagnose the neurological disorders many brain imaging techniques are available to observe brain activity. Among the techniques, EEG is cost-effective than other brain imaging techniques and this can be a notable aspect in the diagnosis of epilepsy in rural communities. Further, EEG is a painless, non-invasive, and completely passive recording technique that captures neuron activity of brain through electrodes placed on the scalp [5]. However, EEG has proved to be an important means in diagnosing people with epileptic seizures because it directly measures the electrical activity of the brain. Unfortunately, the frequency and occurrence of seizures cannot be detected in advance; long recordings of EEG signals are obligatory. Nevertheless, epilepsy diagnosis from long recordings of EEG signals is usually done by visual inspection which is inefficient, time-consuming and error-prone process. Hence in recent years, several methods are proposed by researchers for automating epilepsy detection [6, 7, 8, 9].
To automate the diagnosis process of epilepsy, the entire process can be split into three main phases namely signal decomposition, feature extraction, and classification. For analysing the EEG signals in multiple resolutions, signal decomposition becomes inevitable. Similarly, feature extraction is an essential step that provides a solution to identify the hidden information regarding the signal’s time and frequency components effectively. However, the identification and extraction of significant features still remains a research challenge [10]. Literature reveals that the entropies have the capability to capture the complexity of non-stationary EEG signals, as entropy is a measure that quantifies randomness present in the signal [11]. While extracting the entropy based features, the parameters present in various entropies plays a vital role and they can be viewed as hyperparameters, as it has an impact in the discrimination power if they are altered. Thus, this research work focuses on setting the optimal parameters for various entropies. Though the parameters present in the entropies has an impact, manual selection of optimal parameters is time consuming. Therefore, this article proposes a parallel Farmland Fertility nature-inspired meta-heuristic optimization algorithm and a novel weighted fitness function is designed which has to satisfy the objective function. Finally, the entire process ends with the classification i.e., the extracted features are classified using state-of-the-art classifiers.
The major contributions of the proposed epileptic seizure detection model are
A parallel farmland fertility algorithm is proposed to optimize the parameters of entropies (Kraskov, Permutation, Renyi and Tsalli’s) with minimal computational time A novel fitness function is designed based on Kullback-Leibler divergence which helps to identify the optimal parameters of aforementioned entropies Based on the optimal parameters of each entropy, the features are extracted and classified using state-of-the-art (SOTA) classifiers (SVM, LDA, KNN, RF, ANN) The performance of optimal parameters obtained using PFFO is analysed. Three EEG benchmark datasets were used to evaluate the predominance of the proposed model.
The rest of the article is structured as follows: Section 2 discusses the research works which rely on entropy for designing an automated epileptic seizure detection system. Section 3 elucidates the need of the proposed work along with the intuition behind the selection of the entropy features. Section 4 discusses the fundamentals to provide the insight of the proposed work. Section 5 explains the proposed work. Section 6 articulates the experimental setup, brief description about the datasets considered followed by the discussions and Section 7 concludes the article.
Literature review
Literature reveals that various entropies contribute significantly during epileptic seizure detection and prediction as it measures the randomness of the physiological signals. In 2012, Nicoletta and Julius [12] proposed a model based on permutation entropy to characterize and classify epileptic EEG signals from the normal signals. In 2012 [13], Song and Zhang designed an automatic recognition system to diagnose epileptic EEG patterns using non-linear features: sample entropy, Hurst exponent and permutation entropy extracted after decomposing the signals using Discrete Wavelet Transform. In 2013, Guohun Zhu et al. [14] employed delay permutation entropy for the accurate detection of epileptogenic regions of the human brain. In 2014, Yatindra et al. [15] proposed fuzzy approximate entropy for epileptic seizure detection and obtained significant improvement in the results. In 2015, Rajendra Acharya et al. [11] compared the various entropies used for epileptic seizure detection and prediction along with its merits and limitations. In the same year, Rajeev Sharma et al. [16] proposed an entropy based model for the identification of focal EEG signals. In 2017, Lina Wang et al. [17] extracted spectrum and approximate entropies for the precise discrimination of brain abnormalities. In the same year, Tao Zhang et al. [18] introduced a novel entropy termed as fuzzy distribution entropy which combines wavelet packet decomposition for the classification of epileptic EEG signals. Also, Patidar and Panigrahi [19] developed a seizure detection model using tunable-Q wavelet transform from which kraskov entropy features are extracted and classified using LS-SVM. In 2019, Vipin Gupta et al. [20] employed FBSE-EWT and extracted entropies (Log-Entropy and Norm) for effective epileptic seizure detection. In 2020, Palani et al. [21] extracted entropy measures from Multivariate Empirical Mode Decomposition for Schizophrenia detection using multichannel EEG signals. Priscila et al. [22] employed discrete wavelet transforms for decomposing the EEG signal and extracted entropy measures for classifying interictal and ictal states in EEG signals. In 2021, Reem et al. [23] have analysed the relationship between spontaneous neural activity and psychiatric traits using EEG signals by extracting Multiscale entropy. Asghar and Babak [24] have implemented two signal decomposition methods: discrete wavelet transform and orthogonal matching pursuit and extracted entropy based features for epileptic seizure detection. Sukriti et al. [25] proposed an epileptic seizure detection system by applying a novel denoising technique based on multiscale principal component analysis and empirical mode decomposition. Further, refined composite multiscale entropies such as sample, fuzzy and permutation are extracted and the impact on epileptic seizure diagnosis is analysed. From the literature, it is evident that entropy measures are greatly contributing to the effective discrimination of normal and abnormal EEG signals, as it captures the randomness of the non-linear and non-stationary EEG signals and deliberates the distinct nature of the various brain states. However, most of the entropies have parameters that play a significant role in extracting useful information from the pre-processed signals and none of the researchers attempted to identify the patient-specific optimal parameters of the entropy measures yet they fail to utilize its complete thrust. Besides, Tomasz and Duch compared the performance of decision trees implemented based on three entropies: Renyi, Tsallis and Shannon entropy [26]. In which the performance of each entropy with respect to the probabilities was analysed by varying Further, the performance of the decision tree was improved while tuning as it nullifies the trade-off between the information gain and the probability among the different classes. Yin et al. [27] proposed a novel Multiscale Permutation Renyi entropy (MPEr) for effectively quantifying the complexity of EEG signals. The complexity of MPEr was analysed by varying the different parameters such as and Abhik and Basu [28] proposed a new logarithmic norm-entropy (LNE) which have two parameters & and viewed the proposed entropy measure & its corresponding cross-entropy measure as an optimization problem. The probability values of LNE were plotted by varying the & values ranging from 0 to 100. It was inferred that LNE decreases if any one of the values increases by keeping another as a constant value. Therefore, it is implicit from the literature that the parameters present in the entropy measures assuredly influence the performance. However, none of the research works viewed the parameters present in the entropy measures as hyperparameters that eventually extracts the significant patient-specific information from the raw EEG signals. Also, it is worthy to mention that, none of the researchers attempted automating the identification of optimal parameters of entropy measures which obviously improves the role discrimination power of the features in classification.
The reason behind
For identifying the seizure occurrence using EEG signals a diagnostic set of features have been extracted. The extracted features have to recognize intra-class relationships and reveal inter-class variances. For which in recent times entropy based features are highly preferred as it captures the degree of randomness of any physiological signal. However, each entropy based feature has its own benefits and limitations. Among them the entropies that better capture the characteristics of seizure activity have to be extracted. Thus, the entropies which are used to extract the prominent information from EEG signals are employed and the significance of each of them are given below,
Kraskov Entropy [29]: From the literature, it is observed that the value of Kraskov entropy is higher during the occurrence of seizure activity compared to normal EEG signals. Also, the features extracted from third level decomposition hold significant information compared to other decomposition levels. This inference necessitate the identification of optimal parameters for each level coefficients of decomposed EEG signals Permutation Entropy [30]: Recent studies reveal that, permutation entropy handles dynamical noise present in the chaotic non-stationary EEG signals effectively. Further, model assumption is not required and it is appropriate for analysing the nonlinear processes. Real-time EEG signals are noisy in nature, handling those using filters remove the required information at times. Thus, an entropy that extracts appropriate information from the noisy signal is suitable Renyi Entropy [31]: It is a smooth entropy and it remains unaffected over the diverse density functions. Thus the information extracted using Renyi entropy is independent of the learning model, it holds the information without loss Tsallis Entropy [32]: It measures the complex dynamics of bursts and estimates the gravity of brain impairment. Furthermore, it evaluates the diversified rhythms and bursts present in the EEG signals and extracts the required information out of it.
Why entropy parameter optimization
Entropy describes the characteristics of a signal in terms of randomness and the change in parameter influences the performance. Further, clear understanding and a proper conclusion of any entity can be arrived while changing its parameter. In machine learning perspective, the performance of the learning model is highly dependent on parameters involved in it. [26] confirms the role and influence of entropy parameters by varying and plotting the parameter values of different entropies. Also, in the diagnostic perspective the EEG signals are patient-specific. The default parameters fail to extract the patient-specific information. Further, while extracting the features from the decomposed signals, the features extracted from the different levels of decomposition gives significantly different inferences. These hypotheses and understandings paved the way for ideating and proposing this work and the results confirm that the proposed work yields better performance compared to the existing approaches.
Preliminaries
Farmland fertility optimization algorithm
Human et al. [33] proposed a nature inspired metaheuristic optimization algorithm based on the selection of fertile farmland to yield better cultivation. The basic idea behind this metaheuristic algorithm is, the algorithm splits the search space into several sections, and the global and local optimal solutions for each sections are computed which mimics the behaviour of farmers choosing the suitable farmland for cultivation. To improve the fertility of the soil green manures, organic and chemical fertilizers are used by the farmers. As a result the quality of the soil increases which yields better quality products. Based on the nature of soil, the farmers add appropriate fertilizers to make the soil a better one. By considering the previous observations the farmers decide whether to add fertilizers or to leave the farmland in its current form. After determining the quality of the soil in each section, the section with worst quality will be improved by adding the appropriate fertilizers to it. Thus, the section with worst fertility will have more changes compared to the other sections. The best part of the soil from all the sections will be stored in warehouses (global memory) and the best part of the soil from each individual section will be stored in local memory. To be clear, global memory holds the best solution that ever found in the entire search space and the local memory holds the best solution found in the each section. Algorithm consists of six mathematical stages which is depicted below.
Generation of Initial Population
The number of initial populations are generated based on the number of sections and its corresponding solutions (Eq. (1)).
Where Where Determining the fertility of the soil in each section of farmland Once the populations are generated, the fitness of the existing solutions are computed from which the fertility of the soil can be obtained. The solutions for each section is calculated using Eq. (3).
where Updating the memoriest Once the solutions and the mean value of each section of the farmland are computed, the local and global memory can be updated. The number of solutions to be stored in the local and global memory are determined using Eqs (5) and (6). Further, the best and worst sections of farmland are identified.
Altering the quality of the soil in each section of farmland In this stage, the section with worst soil quality has to be changed significantly. The solutions in the werst section of farmland has to be pooled with the solution available in the global memory using Eqs (7) and (8) [33].
In Eq. (9), Combining the soil To determine the amount of combination of solution with the global best solution In Eq. (11), Termination Condition Based on the fitness function, either the final condition or the maximum number of iterations is attained the algorithm ends else the algorithm continue to reach the termination condition.



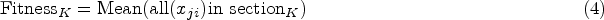







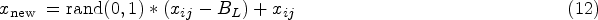

Entropy can simply be stated as the degree of randomness. Four Entropy based features are extracted in this study, namely Kraskox, Permutation, Renyi and Tsallis entropy.
Kraskov Entropy (KE) [19]
It measures the non-linear characteristics of finite length physical or physiological time series. KE has numerous applications and it is found to be a robust estimator where the nature of data is variance-nonstationary. Another significant advantage of KE is, it does not have constraint that the data should follow a specific distribution thus avoiding the necessity of performing Gaussian transformation. KE is calculated using Eq. (14).

In Eq. (14),
Permutation entropy introduced by Bandt and Pompe has been widely used in the analysis of data in various departments. The Permutation Entropy is the Shamnon Entropy of decomposed dynamic elements of the given time series and it estimates the complexity of physiological signals for a given time sequence. It takes 3 elements delay
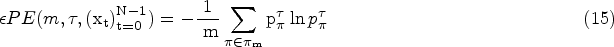
In Eq. (15) selection of
It quantifies the spectral complexity of the physiological signals. It relies mainly on the single parameter

In Eq. (16),
It characterizes the physical behaviour of the signal. It clarifies long range interactions, measures the unforeseen changes and helps to discriminate EEG spikes effectively. The parameters involved for estimating TE are

In Eq. (17), selection of is randomly chosen which can be viewed as a hyperparameter for automation.
This section provides insight into the proposed work of optimising the parameters of entropy measures using the parallel farmland fertility algorithm by designing a novel fitness function. Among the existing metaheuristic algorithms, farmland fertility algorithm is more effective as it divides the search space into many segments and freezes the optimal solution in each segment and aggregates them to attain the global optimal solution. Also, it effectively balances exploration and exploitation as it handles local minima traps and identifies the global optimal solution where many of the existing metaheuristic algorithms often fail to balance both. Besides, the parameters of several entropy measures are bounded between different boundary values, thus a single search space for identifying the optimal parameters of different entropy measures is not feasible. Hence, this article proposes a novel farmland fertility algorithm by parallelizing the search spaces with different boundaries of different entropies for locating their global optima respectively. Further, a real challenge lies while designing a fitness function as it quantitatively measures how good the identified solution is in solving the given problem. Designing a single fitness function for multiple search spaces bounded with different boundary values is challenging. In this work a new Kullback Leibler (KL) divergence based fitness function has been proposed to improve the optimization process and identify global optimal parameters set to improve performance of entropy-based classifications. As KL divergence measures the asymmetry of different probability distributions, the entropy features computed using optimal solution provide class-specific information and aggregates same class points closely for effective classification.
Signal decomposition
Before extracting the significant features, all you need is a suitable signal decomposition tool as EEG signals are non-stationary, aperiodic and complex in nature. Among the existing signal decomposition tools, Discrete Wavelet Transforms (DWT) is found to be a promising tool as it performs multi-resolution analysis by considering the unique thickness of EEG signals in different resolutions. Another notable advantage of DWT is it captures both time and frequency information of a signal simultaneously. Literature reveals that Daubechies (DB) wavelet is more appropriate for physiological signal processing as it has overlapping windows and therefore frequency spectrum coefficient apprehends all the changes in the frequency domain. There is a trade-off between the frequency and time resolution, it is observed that frequency resolution of the signal is enhanced as the order increases however, time resolution is deteriorated. For an effective compromise of both time and frequency information, in this work DB10 [35] is employed, after evaluating many families of DB using minimum entropy criterion. DB10 with four levels of decomposition yield four detailed coefficients (D1-D4) and one approximate coefficient (A4) which is mapped to the conventional frequency bands (D1 (
Parallel Farmland Fertility Optimization Algorithm (PFFO)
In Farmland Fertility Optimization algorithm (Fig. 2), the search space is divided into segments (
Let the sub-segment be denoted as
Generation of initial population
In general, metaheuristic algorithms begin with the population initialization and the population size is decided based on the expected solution. Let us consider a search space of d-dimension with
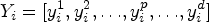
Where
Here, the generated population is the five-tuple Glimpse: Parallel farmland fertility optimization algorithm. Workflow: Parallel farmland fertility optimization algorithm.
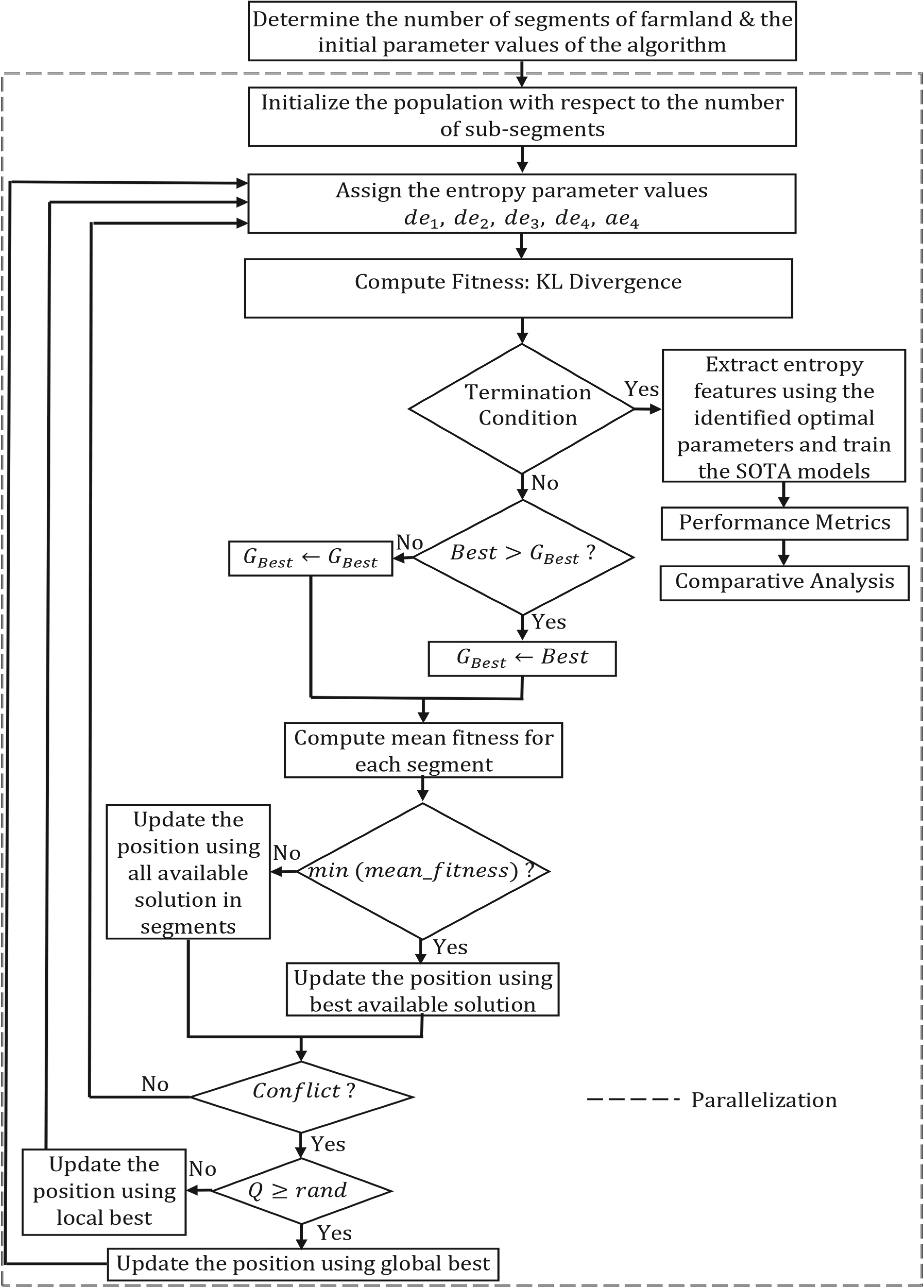
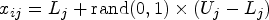
Designing a suitable objective function is highly inevitable as it quantitatively measures how pertinent the particular solution is while solving the given problem. If the identified objective function is inappropriate, it leads to a bottleneck. Since, the aim of the study is to maximize the performance of the learning model by identifying the optimal parameters of each entropy, the proposed work can be viewed as a Maximization problem. Keeping the performance of the learning model as an objective function is cumbersome. Thus, the difference between the data distributions can be extracted which eventually captures the information needed for maximizing the performance. To achieve this, Kullback-Leibler (KL) Divergence which is extensively employed in variational inference can be used to design an objective function, as it quantifies the difference among the data distributions. Since the problem considered here is a maximization problem, the fitness function based on KL Divergence can be formulated as follows,

Where
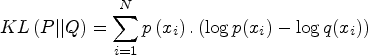
In general, KL divergence is used to measure the information loss while approximating the original distribution with the underlying distribution. Whereas, in this context in a new way KL divergence is employed to compute the difference between the distributions of two entities.
Segment-wise Parallelizatio
Identifying the optimal parameters of each entropy using farmland fertility algorithm in a single processor will leads to computational overhead. Also, it is worthy to mention that the entropy features to be extracted are independent of each other. Thus, to parallelise the farmland fertility algorithm, parallel processing has been employed through which each task (entropy parameter optimization) is executed simultaneously in multiple processors thereby reducing the overall processing time. Further the parallel processing is executed asynchronously as the parameters of each entropy do not influence each other thus, locking is not required. Thus, the parameters of each entropy are optimized and the entropy features are extracted asynchronously through parallel processing.
Termination condition
Once the optimal fitness value is reached or the algorithm attains the maximum number of iterations the proposed algorithm is terminated.
Population updat
If the termination condition is not attained, based on the obtained fitness value each population gets updated using Eqs (3)–(13). Once the termination condition is reached, the optimal solution from each segment of the farmland is gathered from its global memory, based on the optimal entropy parameters the level specific entropy features are extracted.
Epileptic seizure detection
The entropy based features extracted using the level specific optimal parameters are fed into the state-of-the-art classifiers for detecting the epileptic seizures. Background description of the renowned classifiers are as follows: Support Vector Machines (SVM), it forms potential hyperplanes and the best hyperplane is identified using the constraints, the kernel is configured with Radial Basis Function as the nature of input is non-linear and the learning process is carried out in a supervised way. Linear Discriminant Analysis (LDA), the classification is made by the probability estimation which is computed using Bayes theorem. It minimalizes the variance and maximizes the inter-class distance between the classes. K-Nearest Neighbors (KNN) is an instance-based learner which embeds high dimensional feature vector into a low-dimensional space. K is a hyperparameter which is fixed as 3. Ensemble of decision trees result in Random Forest (RF) which is a bagging method, the error in the individual tree does not propagate and it provides additional randomness and searches the optimal feature among the feature subsets which results in a better learning model. Artificial Neural Network (ANN) is inspired from the biological neuronal interactions which contains artificial neurons as nodes. It consists of input layer followed by hidden and output layers respectively. ReLU and Softmax are configured as an activation in the hidden and output layers respectively. Adam optimizer is used for training the neural network.
Results and discussions
This section provides the details of the experimental setup, EEG datasets used and validation procedure. The inferences from the recorded results were discussed.
Experimental setup
The proposed work was implemented in Python3 using Scikit-learn’s classifier functions to perform classification tasks. NumPy and Matplotlib were used for implementing mathematical operations and plotting respectively. In addition pyWavelets package was used to extract Discrete Wavelet Transform (DWT) coefficients from raw EEG signals. All the experimentations were carried out in Google Colaboratory.
Dataset description
In order to evaluate the performance of the proposed model without any bias towards the specific data, three different EEG benchmark datasets were used: University of Bern-Barcelona focal Epilepsy dataset, University of Bonn Epilepsy dataset and Indian EEG Dataset.
University of Bern-Barcelona [36]
It consists of two classes: Focal and Non-Focal EEG signals. Each class contains 3750 pairs of randomly picked EEG signals recorded simultaneously with a sampling rate of either 512 Hz or 1024 Hz. Each sample contains 10240 data points which corresponds to 20 second window [37].
University of Bonn [38]
It comprises of five different classes, with each class contains 100 samples, in a sampling rate of 173.61 Hz, healthy volunteers: Eyes closed (A), Eyes open (B), and epileptic patients: Inter-Ictal Focal (C), Inter-Ictal Non-Focal (D) and Ictal (E). Each sample contains 4097 data points which corresponds to 23.6 second window.
EEG Dataset New Delhi [39]
EEG signals collected from ten epilepsy patients of Neurology & Sleep Centre, Hauz Khas, New Delhi is used in this work. Each sample consists of 1024 data points recorded for the duration 5.12 seconds with a sampling rate of 200 Hz. Gold plated electrodes were positioned by following 10–20 electrode placement system. Recorded EEG signals were filtered between 0.5 Hz and 70 Hz and labelled into three different classes: ictal, inter-ictal and pre-ictal.
Data fine-tuning and validation
In order to improve the robustness of the learning model on the view of real-time applications, where influence of noise is indispensable, no separate filters were applied on EEG signals. The entropy features extracted using the optimal parameters obtained from the proposed work is normalised using zero-mean unit-variance normalisation. Stratified ten-fold cross validation was employed and the entire process was repeated for twenty times and the results were recorded to avoid biased results. The state-of-the-art classifiers: Support Vector Machines (SVM) with Radial Basis Function as kernel, Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Random Forest (RF) and Artificial Neural Network (ANN) were used to show the role of the optimal parameters in improving the overall performance of the learning model. The performance of the learning models were evaluated in terms of performance metrics given in Section 6.4.
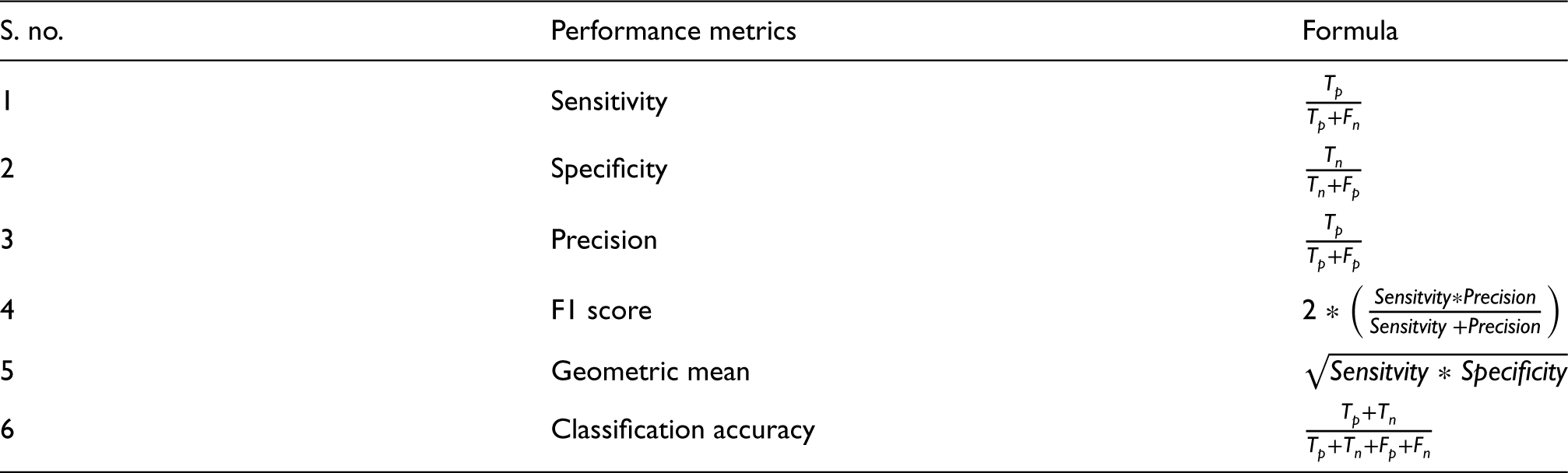
Performance metrics
Discussions
Optimal parameter values obtained from PFFO (Renyi & Tsallis Entropies)
Optimal parameter values obtained from PFFO (Renyi & Tsallis Entropies)
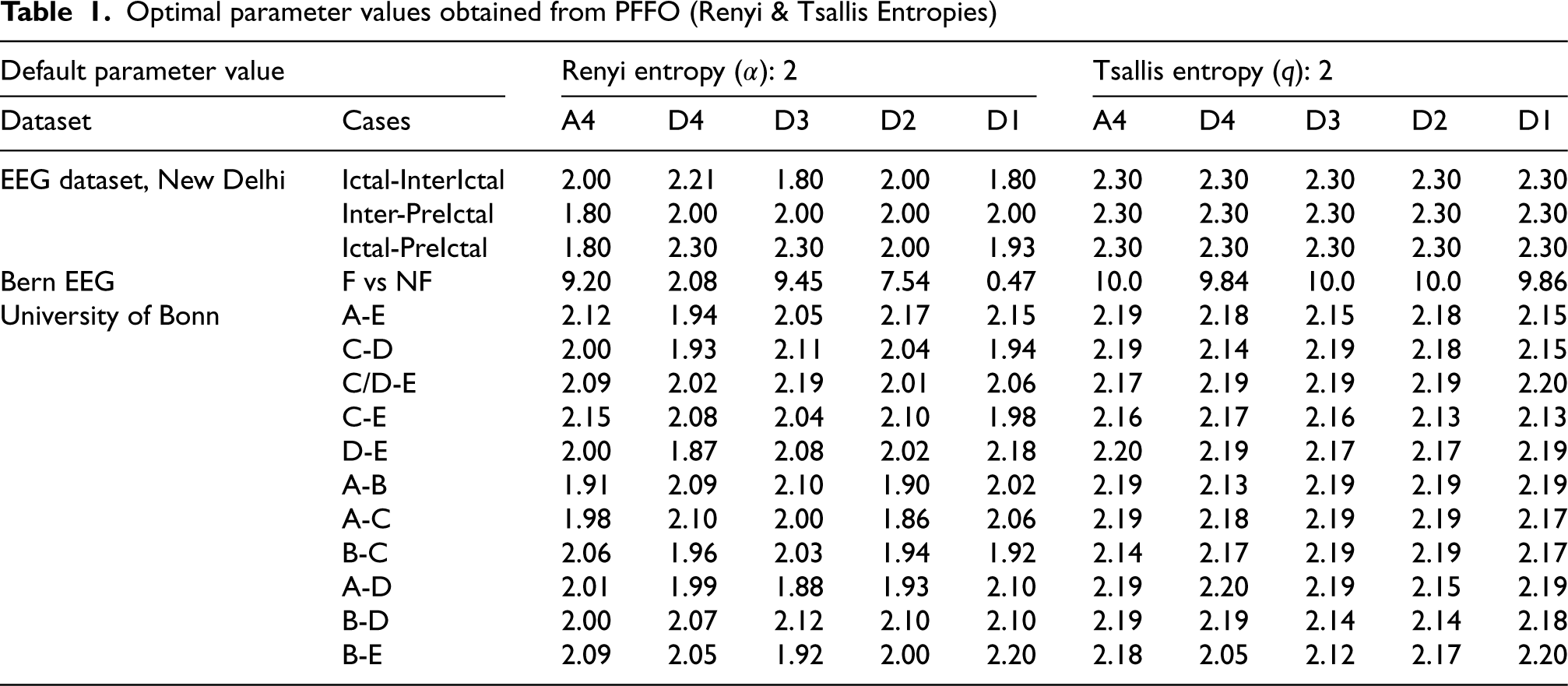
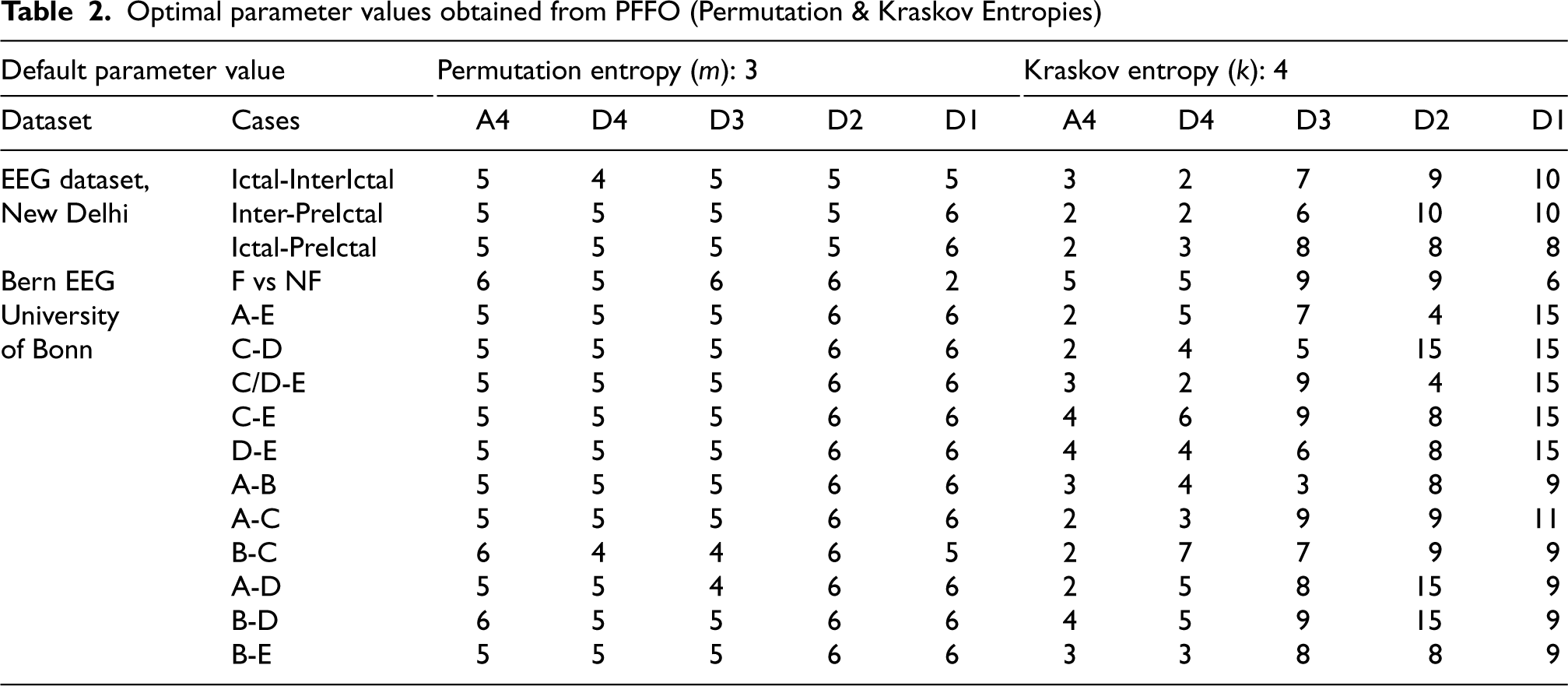
Optimal parameter values obtained from PFFO (Permutation & Kraskov Entropies)
Performance comparison in terms of sensitivity

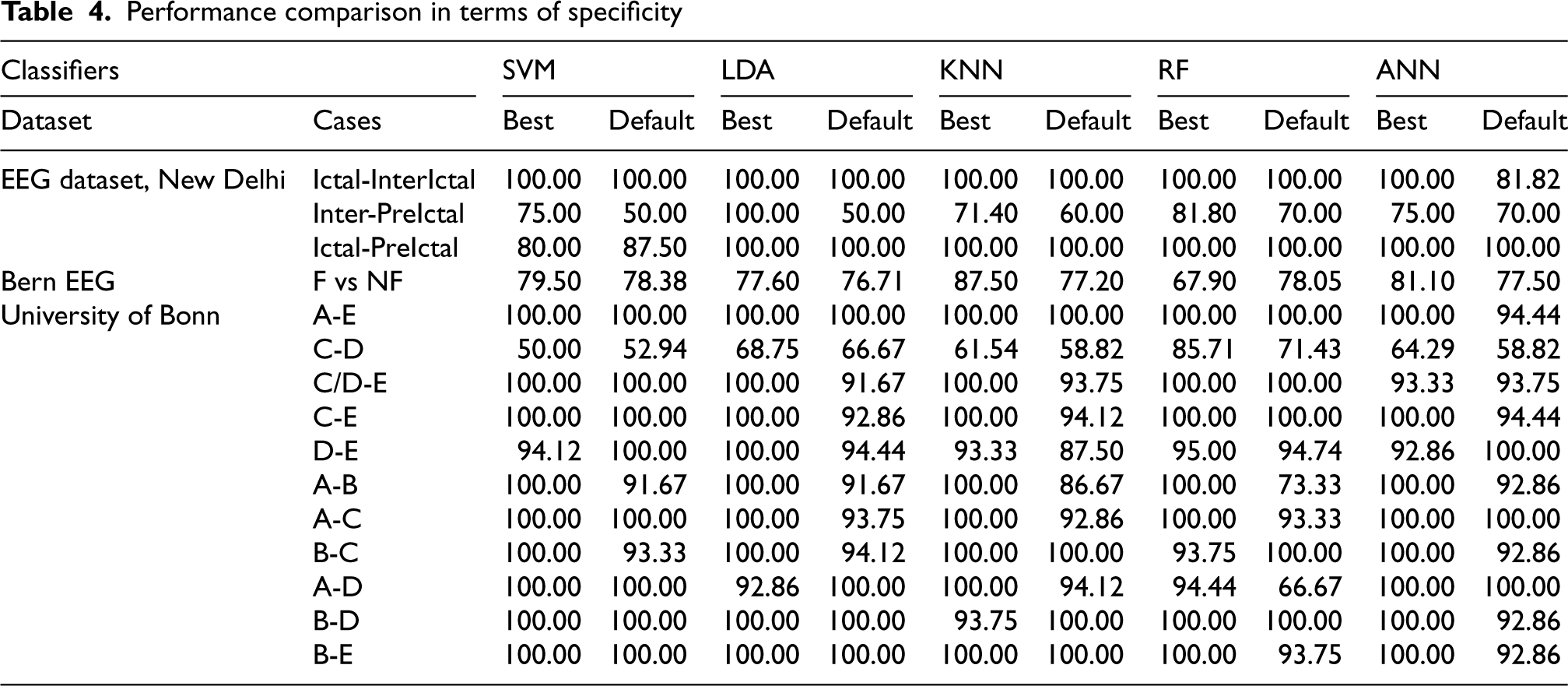
Performance comparison in terms of specificity
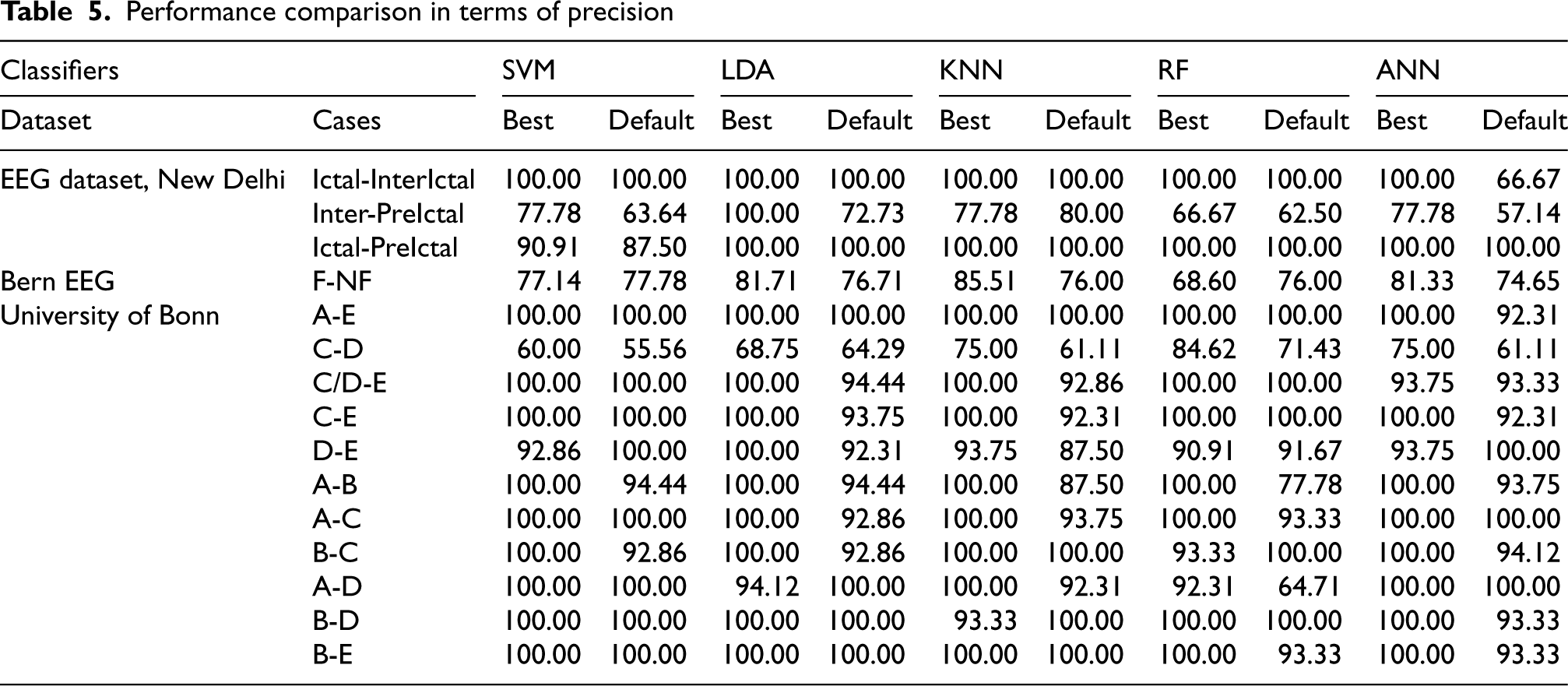
Performance comparison in terms of precision
Performance comparison in terms of classification accuracy

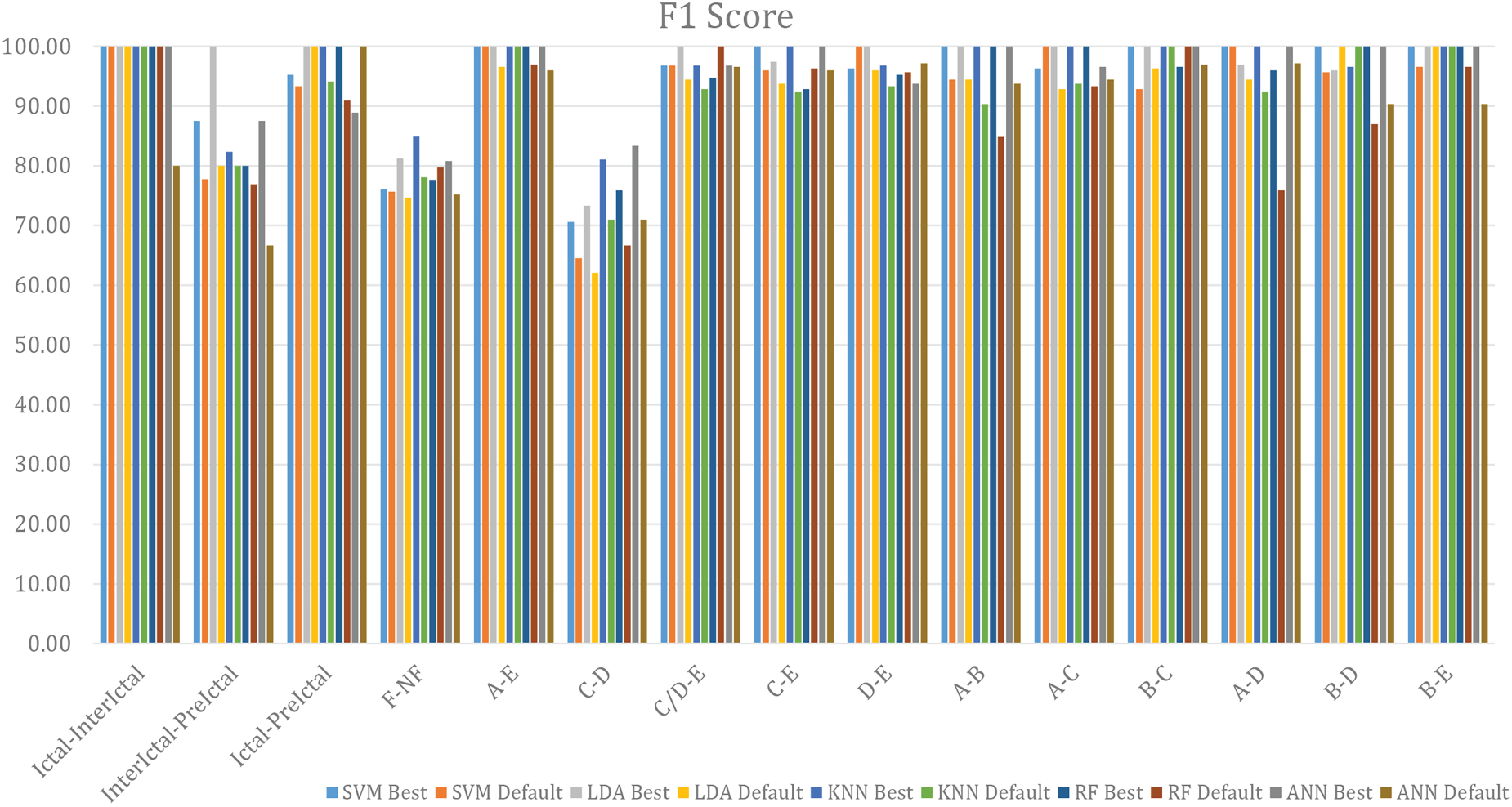
Performance comparison in terms of F1-score.
Similarly, bar graph is plotted in terms of F1-Score (Fig. 3) and G-Mean (Fig. 4). It is evident from the graphs (Figs 3 and 4) that the parameters optimized using the proposed model outperforms in most of the cases. In few cases, both the parameters attain similar results.
Statistical analysis: WTEST
Statistical analysis: WTEST

In order to have better clarity and to show the statistical dissimilarity between the performances of the learning models trained, validated and tested using the default and optimal parameters of the entropy features, the Wilcoxon rank-sum test (WTEST) is performed. WTEST, a non-parametric test in which the null hypothesis is rejected when the computed p-value is lesser than 0.05 i.e., less than 5% significance level. Table 7 confirms the Performance comparison in terms of G-mean Score.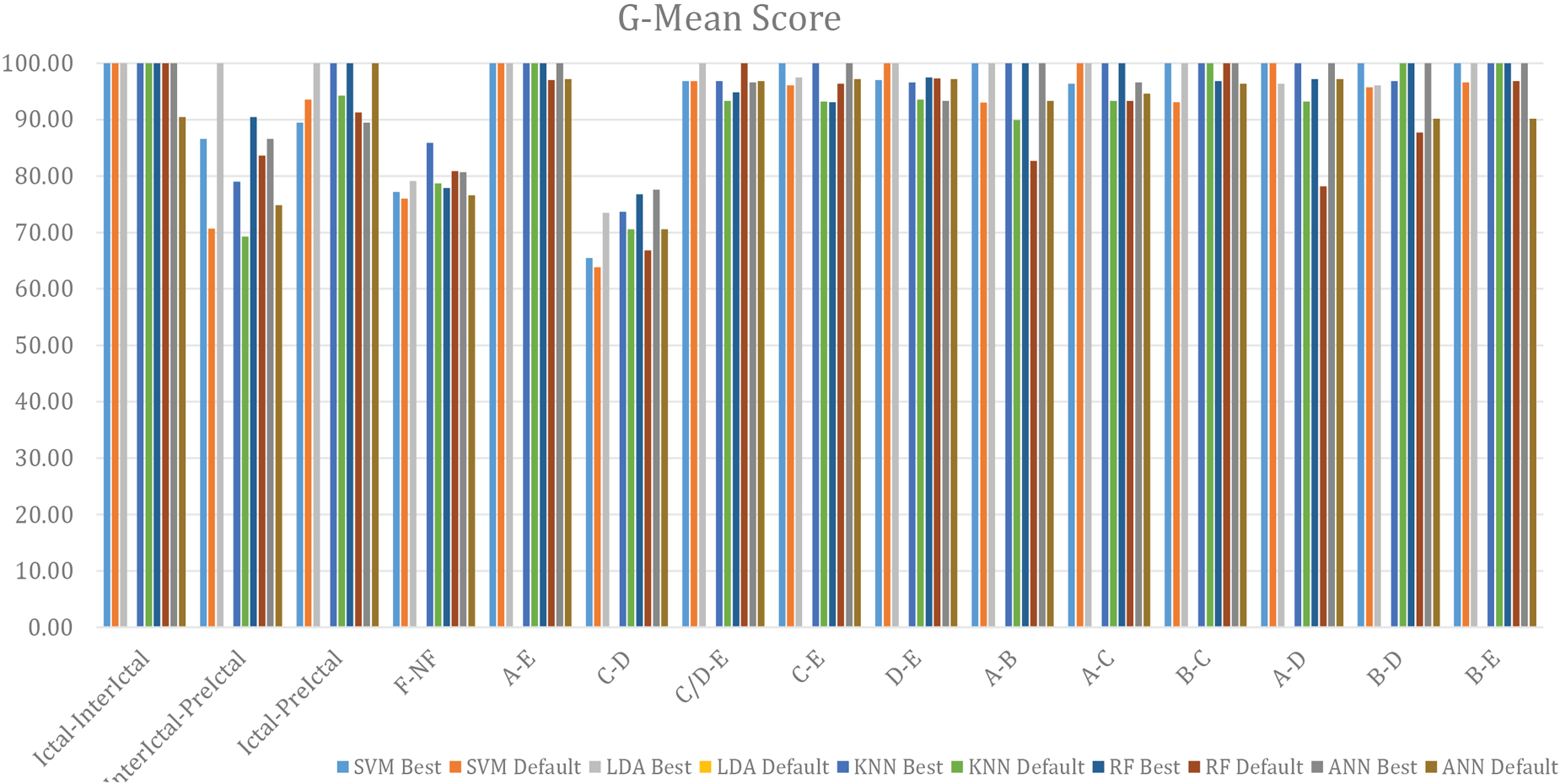
Owing to the combinatorial influence of the novel components employed in this work, the performance of the proposed model is prominent. Thus, the impact of each component is discussed in this section.
Influence of novel fitness function
In general, for identifying the optimal parameters with respect to the learning model, performance of the learning model is widely considered. However, the identified optimal parameters will become model dependent, it is obvious that for other learning models the optimal parameters identified could not yield better results. Also, if the performance of the learning model is kept as an objective function, superfluous computational overhead occurs. Thus, for extracting the difference among data distributions which ultimately holds the required information needed for maximizing the performance irrespective of the learning model’s novel objective function based on KL divergence is designed. Therefore, the optimal parameters obtained from PFFO is model independent and reliable.
Influence of segment-wise parallelization
As the parameters of each entropy is independent of the other entropies considered, novel parallelization component employed in this work is highly creditable. If the algorithm is executed in sequential fashion, the execution time will be higher compared to the segment-wise parallelization component designed in this work.
Influence of identification of optimal parameters
Optimal parameters obtained using the proposed model have certainly influences the performance of the SOTA classifiers considered which is quite evident from the results obtained (Tables 3–6). Though, for the Indian EEG dataset and University of Bonn dataset, the range of the identified optimal parameters of Renyi and Tsallis lies around the default parameters, significant improvement is inferred in the performance of the learning model. Also, for all the three datasets, substantial difference is noticed between the optimal and default parameters of Permutation & Kraskov entropies. The combinatorial impact of all the optimized entropies greatly impacts the performance of the SOTA classifiers taken into account.
On a concluding note, performance improvement is clearly inferred while optimising the parameters of the entropies. Due to the complex nature of EEG patterns, in some difficult cases, SOTA classifiers struggle to discriminate the samples accurately. Also, it is noticeable that level-specific parameter optimization directly influences the performance of the classifiers considered.
Conclusions
Epilepsy is characterized by recurrent seizures occur in different parts of the brain and usually assessed by EEG signals which are non-stationary, non-linear and transient in nature. Non-stationary implies signal’s statistical and spectral characteristics change with time. Entropy measures are proven to be a promising tool for characterizing the non-stationary property of EEG signals. However, while extracting features the parameters present in the various entropies plays a vital role and it influence the performance of the learning model. Hence this paper put forth a novel farmland fertility optimization algorithm to optimize entropy parameters based on Kullback-Leibler Divergence in a parallel fashion. Once the optimal parameters are identified, features are extracted and classified using state-of-the-art classifiers. The proposed model was validated using the EEG benchmark datasets obtained from University of Bonn, University of Bern and Indian EEG, New Delhi in terms of classification accuracy, sensitivity, specificity, precision, F1-score, and G-mean. The proposed algorithm can be used by the neurologists & technicians for the precise detection and prediction of epileptic seizures in advance and useful for other physiological signal specific biomedical applications.
Footnotes
Acknowledgments
This work was supported by The IBM Shared University Research Grant 2017. New York, USA.