
Abstract
Limestone mining is a significant economic activity in India, accounting for around 10% of the GDP however, it has certain negative environmental consequences. The objective of this study is to determine the spatial distribution area of captive limestone mines using remote sensing datasets, spectral index, and machine learning algorithms and compare their area estimation with industrial field survey reports for the financial year 2019. The study area includes a limestone resource area of 2226.16 ha with an excavation area of 487.10 ha in 2019. In the present research, we used a high-resolution Sentinel-2A satellite dataset to map and compute the active mining area by implementing the Normalised Vegetation Index (NDVI), Iterative Self-Organizing Data Analysis Technique (ISODATA), K-Nearest Neighbours (KNN), and Random Forest (RF) algorithms in the QGIS 3.18 software tool. The RF classifier estimated a limestone mine area of 379.57 ha with user accuracy (UA) of 97.25% and producer accuracy (PA) of 99.18% with a kappa coefficient value of 0.957. The mine area was estimated at 417.47 ha with a UA of 98.99% and PA of 99.10% and kappa value of 0.947 of the KNN method, The NDVI method estimated 469.92 ha with a UA of 93.63% and PA of 92.04% and kappa value 0.685. This research confirmed that the RF classifier well performed in classification with overall accuracy (OA) of 95.79% to KNN (OA of 94.78%), NDVI (OA of 79.84%) classifiers, and ISODATA poor in classification with OA of 64.16%. This research assists limestone mine owners and environmental engineers in making environmentally sustainable decisions, eco-friendly mine design, and monitoring.
Introduction
Limestone is a sedimentary rock mainly made of calcite (CaCO
The Yerraguntla cement industrial region is a prominent cement producer in the YSR Kadapa district of Andhra Pradesh, India. The region is endowed with extensive deposits of cement-grade limestone (calctufa) over an area of approximately 2226.16 ha with an excavation mining area of 487.10 ha in 2019 [2]. The amount of limestone produced in India during the 2019 fiscal year was close to 380 million metric tons [1]. The destruction of the environment brought on by limestone extraction in terms of dust and noise leads to geomorphological issues that have a significant impact on human civilization and existence at local levels [3].
Nowadays, machine learning applications in remote sensing are a trending topic that is gradually gaining attention from industry experts, scientists, and researchers [4] due to the availability of modern techniques in remote sensing, abundant data availability, and, when compared to traditional ground-based mapping techniques, spatial remote sensing has indisputable benefits in terms of covered area, speed, and cost [5]. Remote sensing technology benefits from machine learning techniques as they enable better resource management, more accurate environmental forecasts, and the discovery of novel insights from large data sets. While there are many benefits to using machine learning in remote sensing, there are some challenges as well. The availability of up-to-date data, the development and validation of training data, and algorithm design uncertainty are all barriers to machine learning being widely used [6]. The objectives of the research as follow (1). To map open-pit captive Limestone mining area in the study area using spectral index and machine learning algorithms; (2). To assess and compare the mining area with industrial field survey data; (3). Classifier performance evaluation in the mapping and appraisal of limestone mining areas;.
This article is organized as follows: Section 1 presents an overview and objectives of the research; Section 2 discusses a literature review of lithological mapping techniques; Section 3 presents materials and methods relevant to the limestone mining region, including data collection, preprocessing, and digital classification; Section 4 presents the findings and discussion; and Section 5 provides the conclusions of the study.
Literature review
Wang et al. [7] incorporated multi-sensor and multisource remote sensing images and used a hybrid classification method of Metric Learning (ML) and Random-Forest (RF) to differentiate major lithological units in the Himalayan orogenic belt, promoting computing efficiency and 85.75% overall classification accuracy [8]. Bachri et al. [9] used the RF method to map lithological characteristics utilizing Sentinel-2A (MSI) spectral, textural, and geomorphic information with the ALOS PALSAR. The results revealed that the RF approach is a good tool for creating new geological maps or updating existing ones, with a kappa hat of 0.88 and an overall accuracy of 91%. Shirmard et al. [4] explored high-capability RS datasets and machine-learning algorithms for mapping various geological features such as rock types, structures, and mineralized zones. Abdolmaleki et al. [10] used a support vector Machine (SVM) and combined remote sensing and geological data to generate a mineral prospectivity map. Davids and Rouyet [11] evaluated various remote sensing approaches that can be employed for mining-related applications such as surface mineralogy mapping for development, topographical changes used during mine design and operation, environmental consequences monitoring, and mapping surface motions of mine structures. El Atillah et al. [12] used ISODATA and Kinetic Monte Carlo (KMC) methods to perform lithological cartography. The integration of structural, lithological, and hydrothermal alteration data gathered from ASTER, Landsat (ETM
Materials and methods
Study area
Location of limestone mines in the cement industrial area at YSR Kadapa district.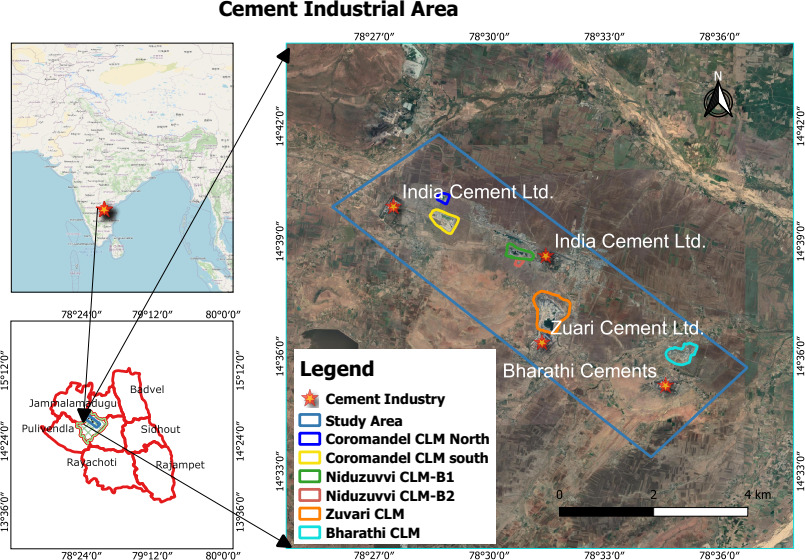
Classification and performance evaluation of classifiers in limestone mine mapping.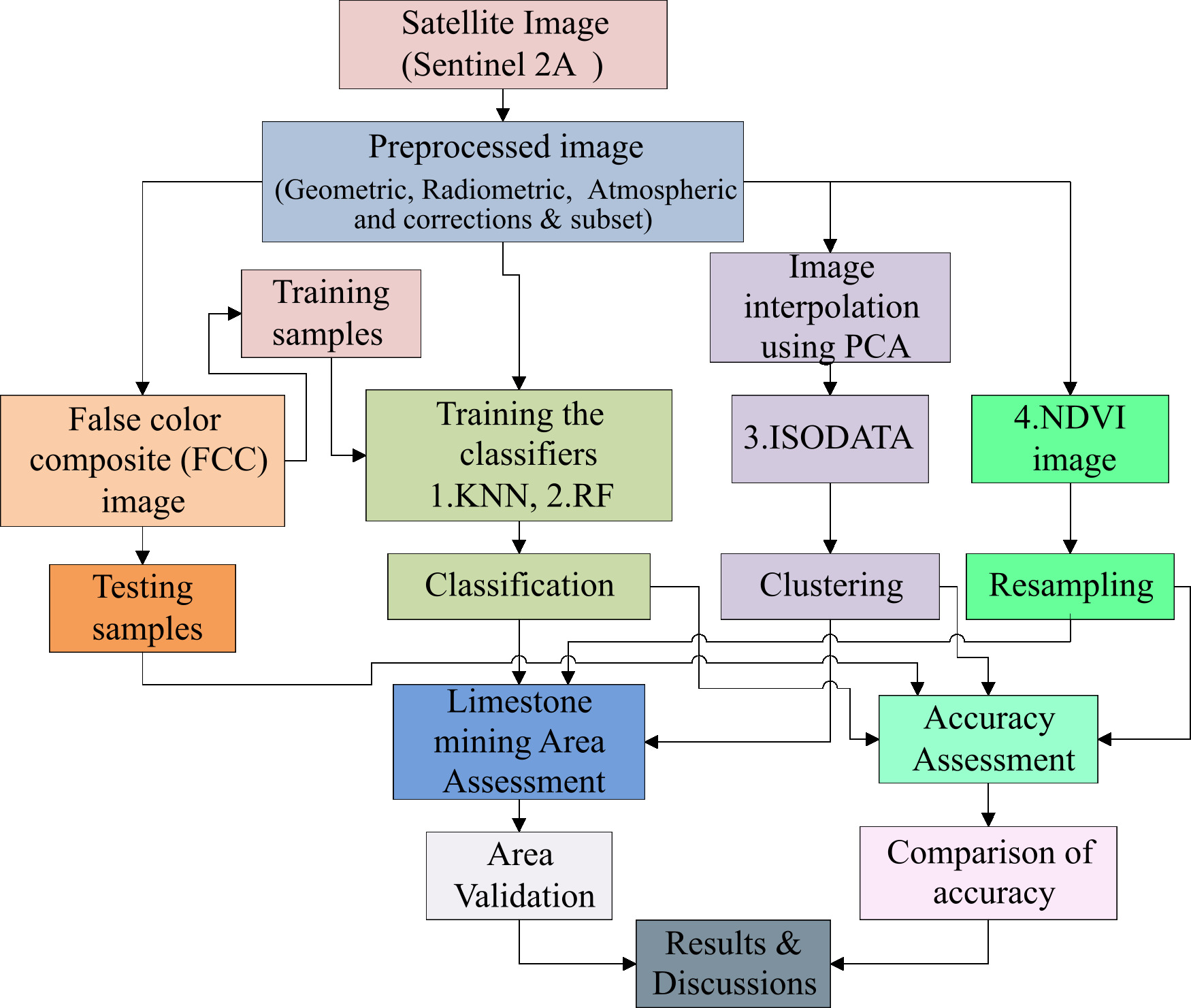
The study is conducted at the Yerraguntla cement industrial region, YSR Kadapa district, Andhra Pradesh, India as depicted in Fig. 1[14]. The study area has four cement industries and its captive limestone mines and Kadapa black stone slab mines in and around the Yerraguntla that was topographically lying 47 km west of YSR Kadapa district headquarters in the Rayalaseema region, Andhra Pradesh, India with Geographical Coordinates latitude 14.63
Sentinel-2A bands and its applications
Sentinel-2A bands and its applications
Classifier’s performance evaluation in the active Limestone mines mapping and area assessment was divided into three phases, the first phase included downloading, preprocessing, and clipping of the sentinel-2A imagery to the study area. The second phase includes spectral index (NDVI) calculation, training sample collection and training of the supervised machine learning model (KNN, RF), and dimensionality reduction using PCA for unsupervised learning (ISODATA). The third phase corresponds to the classification of the study area and mining area mapping. The fourth phase included classifier accuracy assessment followed by area calculation and validation. Figure 2 presents the workflow employed in the research.
In the present research, we used the open-access USGS-NASA EarthEexplorer (
Pre-processing
Preprocessed true color Sentinel-2A image.
To get the data ready for further processing and analysis 10 m and 20 m spatial resolution bands of Sentinel-2A (60 m resolution bands were not utilized for this study) were geo-referenced to coordinate reference system EPSG:32644-WGS84/UTM Zone 44N followed by an atmospheric correction, pixel value conversion from digital number to mirror reflection, resampling, creating layer stack of nine bands and clipping to the area of interest (AOI) using the Semi-Automatic Classification Plugin (SCP) in QGIS tool [17]. Figure 3 shows a preprocessed Sentinel-2A image, with white representing the limestone mines, blue representing barren lands, and dark brown representing the following lands.
False-color composite (FCC) of Sentinel-2A image.
To map the active limestone mining area, the selection of the ground control points (GCPs) was performed based on Sentinel-2A images False Color Composite (FCC) created using band combination 7-3-2 [18] shown in Fig. 4. A total of 140 points (1, 28,795 pixels) were randomly selected over the study area having a minimum of 20 points for each class. The points were divided into 6 classes (water body, Limestone mine, Barren land, Follow land Built-up, and vegetation) using the visual interpretation in the FCC Sentinel-2A image. The red color shows the vegetation region, the white color region shows the limestone mining area, the yellow color region shows barren land, the dark brown region shows Follow land and the red mixed white region shows the built-up. The points were distributed as follows: 80% for training and 20% for testing. The training points were used to train the model and then the classification model was applied to the preprocessed Sentinel-2A image. The accuracy of the classification over the Sentinel-2A image was performed by generating an error matrix utilizing, the testing points. However, the effectiveness of many supervised classifiers varies with the training set size and application domain.
NDVI threshold method
The NDVI has been one of the most extensively utilized vegetation indices in remote sensing since its inception in the 1970s. With the expanding availability of remotely sensed imagery, many people are using NDVI for applications of other than science. The NDVI is an efficient spectral index to locate vegetation cover, land cover (LC) changes caused by human activities, and water bodies [18]. The NDVI values are between
Figure 5 shows the NDVI map in the Limestone mining sites dated March 25, 2019, where water bodies are indicated by negative NDVI values (
NDVI threshold values for Land use/cover classes
NDVI map of sentinel-2A for the study area. 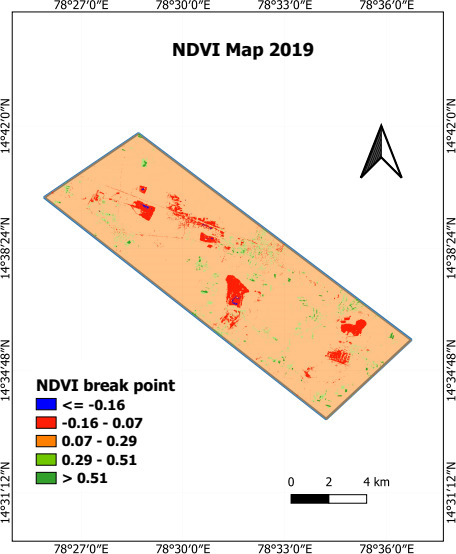
NDVI algorithm for classification
The algorithm is the hierarchy for a novel adaptive methodology for demarcating and assessing limestone mining areas based on the NDVI threshold method [20].
Satellite images are preprocessed and a layer stack is generated for data visualization using the Semi-Automatic Classification Plugin (SCP). The layer stack image is clipped to the study area utilizing the SCP ‘Clip multiple raster tool’ and the study area shapefile. The Red and Near-Infrared (NIR) bands of Sentinel-2A satellite imagery are used to generate NDVI values using the QGIS ‘raster calculator’. Using the ‘reclassify by table’ processing tool and the Nearest-Neighbor method, the NDVI image is classified (resampled) into six land use/cover classes with the help of NDVI threshold values shown in Table 2. The active mine area is determined using the ‘r.report’ processing tool. The accuracy analysis feature of the SCP ‘post-processing tool’ was utilized to detect mapping errors. The results obtained are compared to industrial report data.
For mineral mapping and lithological discrimination, the synergy of machine learning models and remote sensing data could be considered an efficient and economical solution. These methods are effectively data-driven methodologies and could be used to convert high-dimensional data into lower dimensions, forecast specific trends in the data, and identify particular traits in the data, among other things [21].
Eigenvector from principal component analysis
Eigenvector from principal component analysis
Selected ISODATA algorithm process parameters
PCA stacked image of Sentinel-2A.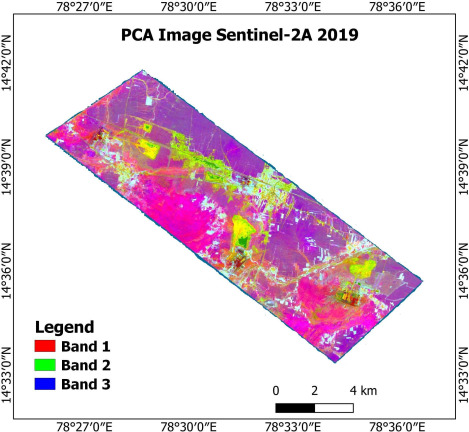
Machine learning models are classified into dimensionality reduction methods (e.g. Independent Component Analysis, Minimum Noise Fraction, and Principal Component Analysis(PCA)), Classification methods (e.g. Minimum distance, Support Vector Machines, Random Forest, simple Neural Networks), Clustering methods (e.g. K-means, ISODATA), Regression methods (e.g. Multi-Linear Regression, Multivariate Regression, Logistic Regression ), and deep learning methods (Convolutional Neural Network) [21, 22]. No algorithm is superior to another. The effectiveness of the algorithm is governed by the features of the landscape, training data, a complete comprehension of the classifier operations, and the user’s ability. There are several indices for evaluating an algorithm’s quality, including overall accuracy (OA), producer’s (PA), user’s (UA) accuracy, and kappa coefficient, These indicators values are greater the classification results are more accurate [23].
There are several Supervised and unsupervised learning methods to interpret remotely-sensed images. Ground truth data are initially required for supervised image classification. When there is no ground truth data, unsupervised (clustering) algorithms such as ISODATA and K-Means can be preferable and plausible.
Principal Component Analysis (PCA) in conjunction with ISODATA clustering is a powerful method for visualizing high-dimensional datasets. PCA is a multivariate statistical technique frequently used in image processing to reduce data dimension or data decorrelation. In the present study, data is reduced to three principal components (PCs), and redundancy between highly correlated bands is reduced. We computed the Covariance matrix, Correlation matrix, and eigenvectors using SCP in QGIS and then applied the ISODATA clustering method to the layer-stacked PCA image. Figure 6 shows the layer-stacked PCA bands image and Table 3 illustrates the eigenvectors of the PCA.
The ISODATA algorithm is an amendment of the k-means clustering. To avoid misclassification, the analyst (user) must normally set parameters such as the minimum and maximum size of the cluster, the minimum separation between clusters, the minimum and the maximum number of clusters, and the maximum number of iterations [20]. Figure 7 depicts the PCA – ISODATA classifier workflow, while Table 4 depicts the process parameter selection.
PCA – ISODATA classifier work flow.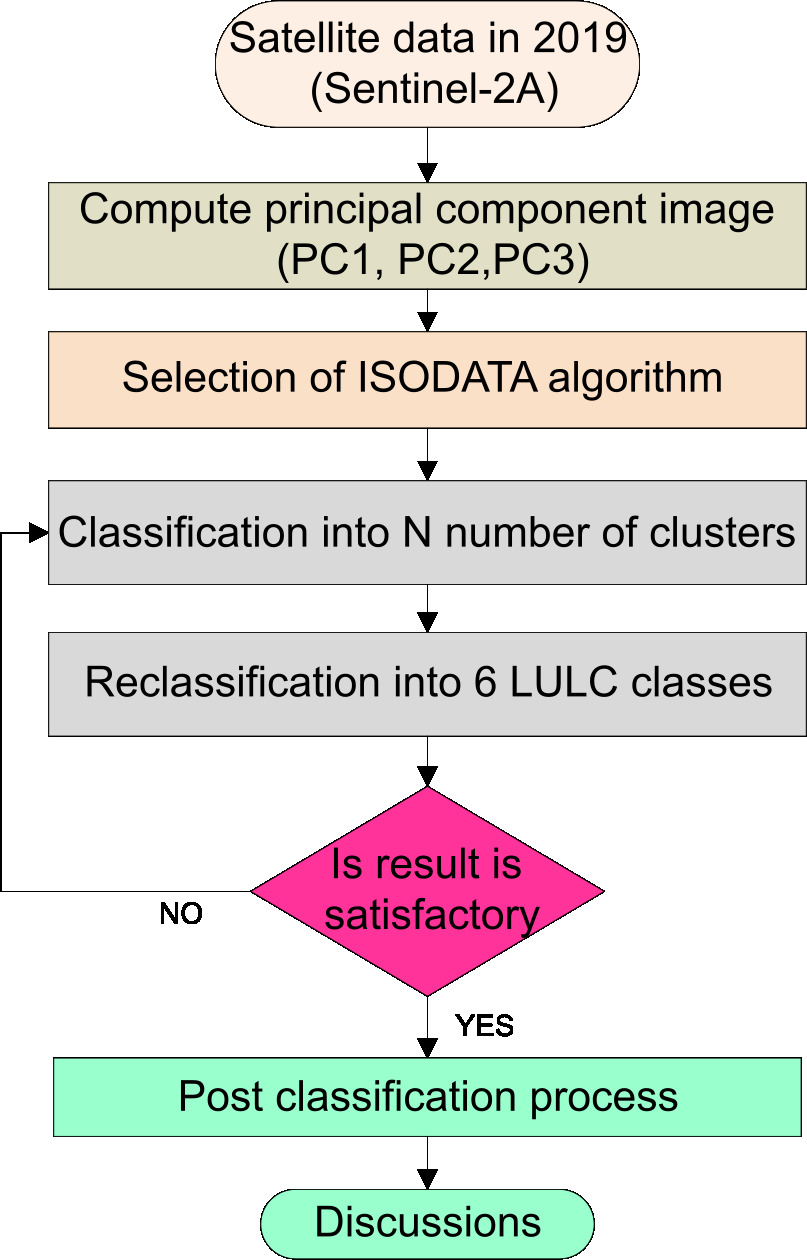
ISODATA algorithm for classification
Set the total number of spectral classes that will be grouped. Choose an optimal number of cluster centres at random. Assign each pixel to the nearest cluster based on the closest mean spectral Euclidean distance measure to the center mathematically expressed in Eq. (3). For each cluster, calculate the Sum of Squared Error (SSE) between cluster centers using Eq. (2).
where
Adjust the center of each cluster if SSE is high and update it until the SSE reaches the specified minimum value. Split the clusters if it contains a large number of pixels exceeding the predetermined threshold. Merge the clusters if the distance between the clusters is less than the predetermined threshold. Repeat the iterations with new cluster centers. Continue iterations until:
The average inter-center distance is less than the user-specified threshold. If the average changes in inter-center distance between iterations are less than a specific threshold. The maximum number of iterations has been reached. Image classification results for post-classification analysis.
KNN Classifier work flow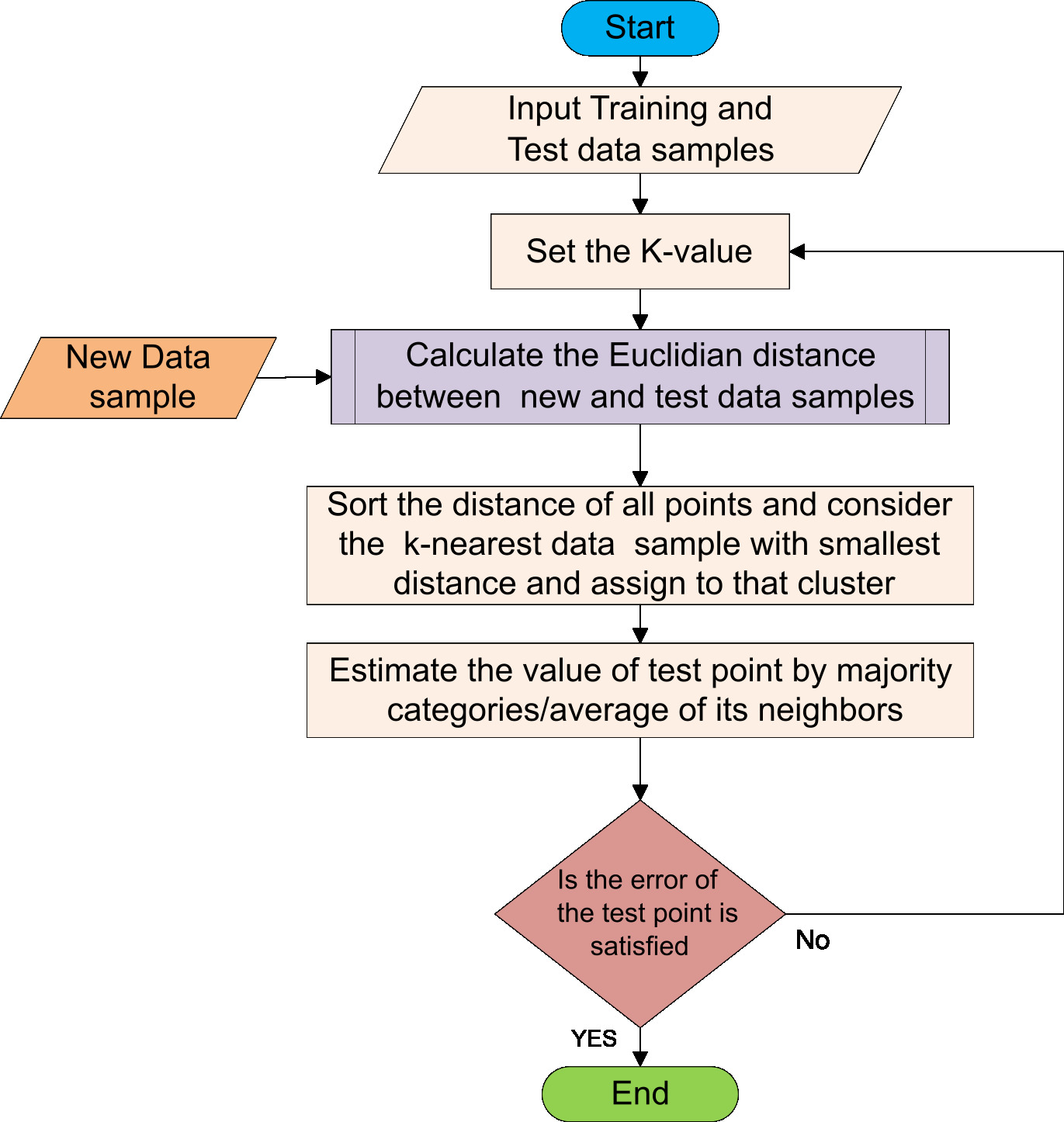
The KNN is a supervised machine learning classifier that is nonparametric memory-based. After determining the number of neighbors, the algorithm will classify the pixels based on the sample values of the (
KNN algorithm for classification
Data preprocessing. Fitting the K-NN classifier to the Training data (Training the model). Select the number Consider all points and the new points in an Calculate the Euclidean distance of new points from all points using Eq. (3).
Where
nb
Sort the distance of all points and select the Count how many data points there are in each group among these Allocate the new data points to the group that has the most neighbors. If the error of the test points is satisfactory, terminate the process; otherwise, repeat steps (c) to (h).
Selected RF algorithm process parameters
Selected RF algorithm process parameters
Hierarchy diagram of Random forest algorithm.
The RF classifier is an ensemble method using decision trees as classifiers [24]. It works on the feature aggregating (bagging) a huge number of decision trees using the bootstrap of the sample from training data. The decision of majority of the trees is chosen as the final output [25, 26, 27]. In this study, RF classification was applied to the Sentinel-2A image using QGIS’s “dzetsaka classification plugin” [22, 27, 28]. The Hierarchy structure of the RF algorithm is depicted in Fig. 9 in that the Root-Branch-Leaf node makes the decision trees. The decision tree’s root node reflects the most appropriate image feature. The branch nodes separate the data into groups with diverse rules. The image data categorization results are obtained via the leaf nodes. The classification error for each tree is estimated from out-of-bag (OOB) data. The RF algorithm process parameter listed in Table 5.
ISODATA and NDVI classification.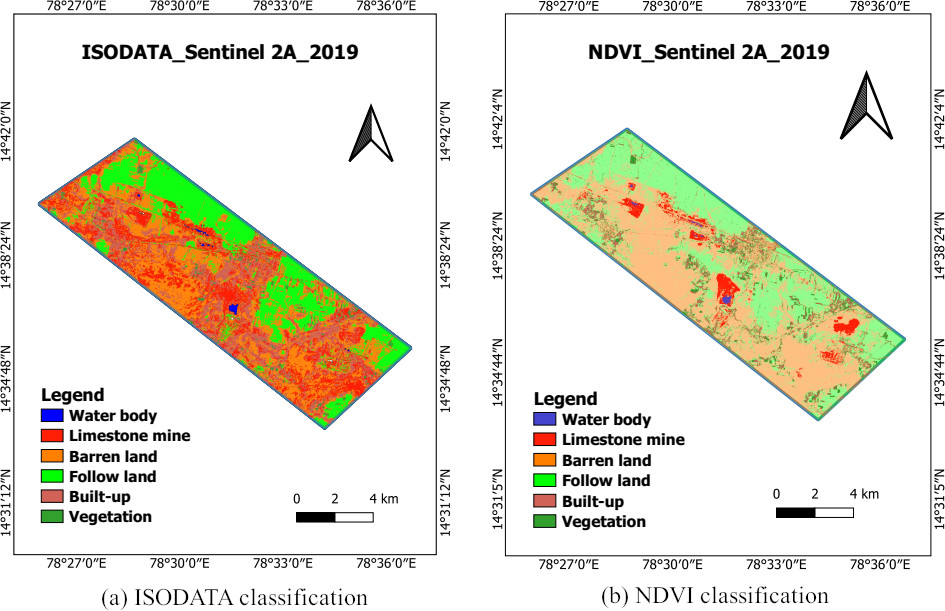
KNN and RF supervised classification.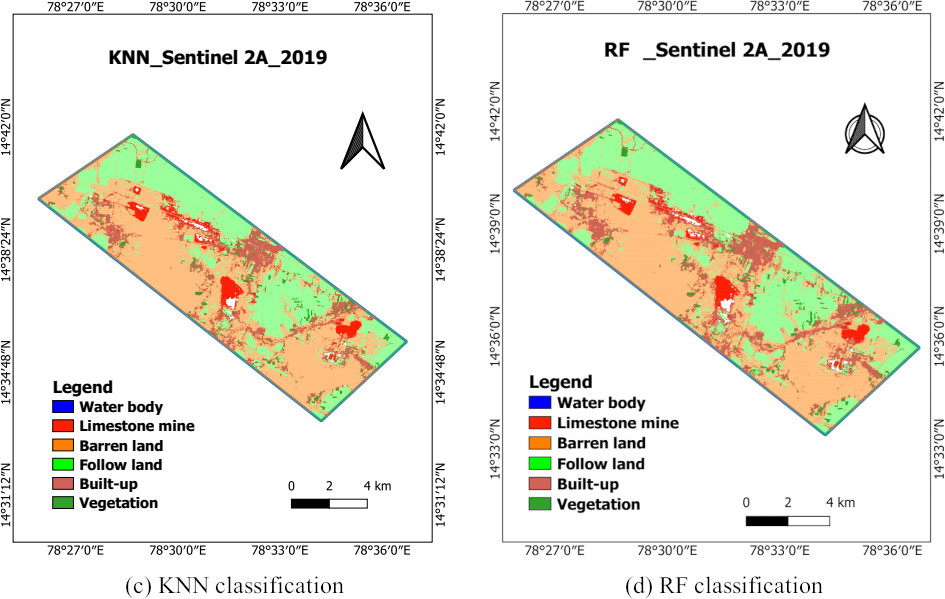
Random forest algorithm for classification
For sample
Take a bootstrapped sample Develop a tree using a random feature subset from the bootstrapped sample For a given node
Choose sample Compute the best-spilt features and cut points using the random feature subset. Split down the data using the finest split features and cut points. Repeat steps (i) to (iii) until the minimum node size Create trained classifiers
Using a simple majority vote, aggregate the B-Trained classifiers. The predicted class label from classifiers
Confusion matrix for the NDVI classifier
Confusion matrix for the NDVI classifier
Confusion matrix for the ISODATA classifier
Confusion matrix for the KNN classifier
Confusion matrix for the RF classifier
While identifying the limestone mines in the Yerraguntla cement industrial region, ISODATA was not able to identify the expected clusters. It can be concluded that the ISODATA clustering technique is not able to identify correct and one-label clusters. Due to similar spectral reflectance of land cover types (built-up and Limestone mines), two or more classes can be mixed and some clusters cannot be linked to the land cover (Fig. 10). Figure 11 shows the limestone mining area including barren lands, follow lands, built-up, and vegetation land cover classes’ mapped using supervised machine learning algorithms KNN and RF.
The major performance metrics for validating machine learning methods include the confusion matrix, AUC-ROC Curve, precision, accuracy, F1-score, recall, Log Loss, or Cross Entropy. The use of a confusion matrix to assess accuracy has become standard practice in the quality assessment of remote sensing products. Hence we used the confusion matrix to evaluate the accuracy of classifiers in this article [25]. The confusion matrix is a table that compares the categorized pixels (model predictions) to the Ground-Truth points (validation pixels). The rows of the confusion matrix represent an instance in a classified class, while columns represent an instance in the ground truth data. The diagonal elements show the accurately classified image pixels for each class.
In this study, we used the SCP post-processing tool in QGIS software to compute the confusion matrix, which we then used in Microsoft Excel to calculate statistical metrics such as Users Accuracy (UA), Producer’s Accuracy (PA), Overall Accuracy, and Kappa coefficient (K) [20] using the Eqs (4)–(7).
where
Tables 6–9 show the highest and lowest accuracy of classifiers for six different land classes. The Random Forest classifier outperformed the other classifiers in terms of accuracy because it is the best possible method for handling missing data and can handle large datasets with high dimensionality. It prevents overfitting issues.
LULC kappa coefficient and overall accuracy (OA) with Sentinel-2A image
LULC kappa coefficient and overall accuracy (OA) with Sentinel-2A image
Producer, User accuracy, and area of limestone mines with Sentinel-2A image
Classification of overall accuracy using different algorithms.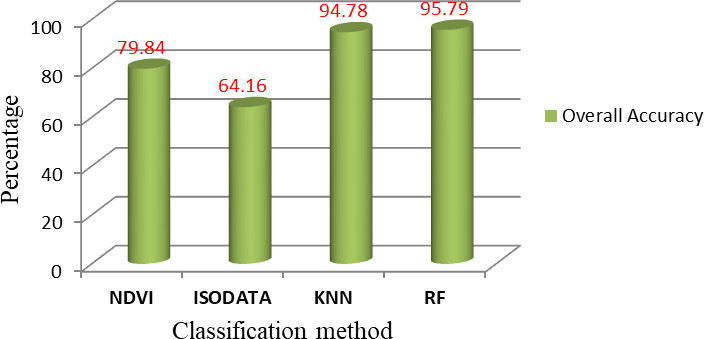
Active Mine area validation with industrial data.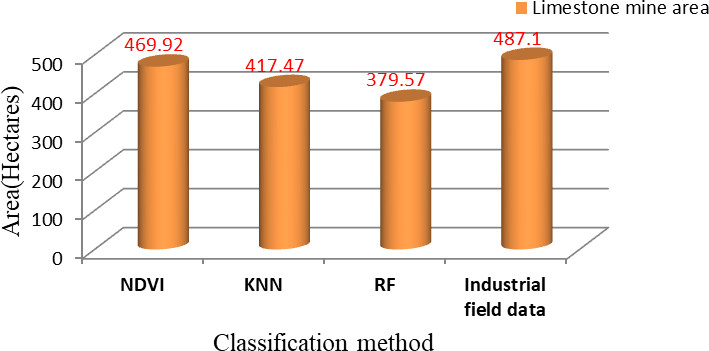
The mapped active limestone mine areas, as well as the comparison of overall accuracy and kappa coefficient for land use/cover (LULC) class to the four classifiers, are illustrated in Table 10 and Fig. 12. The accuracy assessment for the Limestone mine class was performed using an independent validation dataset, as shown in Table 10. The kappa coefficient ranges from 0 to 1, where 1 signifies perfect agreement and 0 signifies no agreement [29].
The classification algorithms estimated limestone mine area is compared with industrial field data illustrated in Fig. 13 and Table 11. According to the mapping results, in 2019 we observed an active mining area is 469.92 ha from the NDVI-classified Sentinel-2A image and 417.47 ha from KNN, and 379.57 ha from the RF classifier. These are compared with the original active mining area of industry (487.1 ha). The deviation in the area is due to the classified methods showing mine pit water bodies (of area 27.69 ha) as a separate class from the mining area. In this study, the area was computed using ‘r.report’ in the processing toolbox of the QGIS 3.18.
Conclusions
In this research paper, we explored the performance of the spectral index, unsupervised and supervised machine learning algorithms in the determination of limestone mine area and land use/cover classes. The Random Forest technique achieved the best results in terms of getting more accurate LULC maps, with an overall accuracy of 95.79% and a kappa coefficient of 0.957, although the limestone mine area was low (379.57 ha) compared to the industrial data area of 487.10 ha. With an overall accuracy of 94.78%, a kappa coefficient of 0.947, and a mine area of 417.47 ha, the KNN approach placed second. Following that, the spectral index (NDVI) method placed in the third category, with an overall accuracy of 79.84% and an estimated limestone mine area of 469.92 ha, which is extremely near to industrial field data. The lowest accuracy is occupied by the ISODATA method that’s 64.16%. When running the KNN and RF algorithms in QGIS using the “dzetsaka classification tool”, the default parameters were utilized. Improved results might be obtained by deep learning algorithms. This study gives a model for environmental impact assessment in industrial areas for limestone mine owners and environmental engineers with mining area mapping and monitoring.
Footnotes
Acknowledgments
The author is grateful to the management of the Limestone Mine and Cement Industries for allowing him to conduct fieldwork in the study area.
Funding
The authors also declare that there is no source of funding for this work.