Computer security consists in protecting access and manipulating system data by several mechanisms. However, conventional protection technologies are ineffective against current attacks. Thus, new tools have appeared, such as the intrusion detection and prediction systems which are important defense elements for network security since they detect the ongoing intrusions and predict the upcoming attacks.
Besides, most of conventional protection technologies remain insufficient in terms of actions since they are all passive systems, unable to provide recommendations in order to block or stop the attacks.
In this paper, a distributed detection and prediction system, composed of three major parts, is proposed. The first part deals with the detection of intrusions based on the decision tree learning algorithm. The second part deals with intrusions prediction using the chronicle algorithm. The third part proposes an expert system for security recommendations in response to detected intrusions, able to provide appropriate recommendations to stop the attacks.
The proposed system gives good results in terms of accuracy and precision in detecting and predicting attacks, and efficiency in proposing the right recommendations to stop the attacks.
Nowadays, researchers and developers of intrusion detection and prediction systems are looking to improve the efficiency of attacks detection and prediction [14]. Indeed, intrusion detection and prediction systems are defined as a new generation of security products in comparison to other techniques. Prediction systems do not really exist as a well-defined technology, but as a concept that enables the implementation of different actors through security technologies. This concept aims to anticipate hacker attacks before it takes place.
In the literature, there are two main categories of intrusion detection and prediction systems: The first one is a host-based intrusion detection and prediction system (HIDPS) which allows monitoring the dynamic behavior and state of a computer system whereas the second one is a network-based intrusion detection and prediction system (NIDPS) that monitors network traffic for specific network segments or devices as well as analyzes network activity and application protocol to identify suspicious activity [8].
Detecting and predicting intrusions often involves Big Data analysis. In fact, conventional analytical techniques are not effective. Moreover, relational database technology is difficult, and the process of properties analysis is complex and time consuming [31]. In addition, the characteristics of Big Data include high volume and velocity as well as a variety of data representing a major challenge for intrusion detection and prediction systems [14, 31]. The use of Big Data technologies in association with Cloud Computing can solve such problems by solving the storage problem and speeding up the calculations.
Furthermore, another problem with the intrusion detection systems is that the majority of IDS are passive, that is to say, they do not ensure the correction of the intrusion in case of attack. Intrusion detection systems are used to secure computer systems, but they are not usually able to correct the errors caused by the attack established. Although there are IDS that provide recommendations, their recommendations for the intrusion are the most of time neither properly targeted to the attack established nor always the right solution defense for the user.
The objective of this paper is to propose an intrusion detection and prediction system based on Big Data technologies and Cloud computing. An ML pipeline model is used for training the decision tree model for intrusion detection and the chronicle model for intrusion prediction.
This paper also proposes an expert system for security recommendations in response to intrusions based on forward chaining algorithm. This expert system provides targeted and very specific recommendations to defend the system against intruders.
This paper is organized as follows. Section 2 deals with related work. Section 3 talks about Intrusion Detection and prediction Systems. Section 4 describes the current recommender systems and Section 5 describes the expert systems. Section 6 describes the Big Data platforms used in this research and in Section 7, the proposed approach is developed. The experimental results are presented in Section 8. Finally, Section 9 provides the conclusion of the research.
Related work
In this section, a brief state of the art is proposed by discussing the works already done in our domain. Cao Lai-Cheng [23] proposed a method for Markov Chain based intrusion prediction technology, which can avoid packet loss and false negatives in a high-performance network with the management of heavy traffic loads in real time. Zhang. Z and al. [35] proposed a hidden semi-Markov method (HsMM) which makes it possible to predict the events of anomalies and the intentions of possible intruders in a computer system; In fact, the method was developed on the basis of observing system call sequences so that it can find the attack attempt in advance to save the precious time of the active intrusion concern. The evaluation of the proposed method was carried out within the framework of DARPA1998. Hisham A. Kholidy and al. [22] proposed a Markov prediction model with hidden finite states (FSHMPM) tested on the DARPA 2000 dataset representing a sequence of events corresponding to signing attacks as a series of state transitions with some probabilities to predict cloud attacks at multiple levels [21]. Alireza Shameli Sendi and al. [32] proposed a framework to predict attacks in several stages before they constitute a serious security risk using the Hidden Markov Model (HMM) for the extraction of interactions between attackers and networks, as well as the use of Lincoln Laboratory 2000 dataset to evaluate the model. SHAOHUA LV and al. [25] proposed a sequence model with intrusion prediction sequence tested on the ADFA-LD dataset and which makes it possible predicting a system call sequence which will be executed in the future, which allows monitoring the system state and prediction of attack behavior.
Meera Gandhi [26] proposed an implementation of classification models for intrusion detection using data collected from the KDD99 database and four supervised learning algorithms KNN in the WEKA environment. Govind P. Gupta and Manish Kulariya [16] proposed a classification-based intrusion detection system using the SVM (Support Vector Machines) for learning and NSL-KDD as dataset to assess performance. The work of M. Elayni and F. Jemili [11] focused on merging and eliminating redundancies from the KDD99, DARPA 1998 and DARPA 1999 datasets using the Big Data MapReduce technique in MongoDB and the Bayesian network as an algorithm K2 implemented in WEKA to analyze the dataset. Suad Mohammed Othman and al. [31] proposed a Sparkchi-SVM intrusion detection model using ChiSqSelector for the selection of attributes, the SVM classifier for the model construction, the KDD’99 data set to evaluate the Apache Spark Big Data system and platform in order to improve performance and reduce training time. Xianwei Gao and al. [15] proposed a Multi-tree learning model using classification algorithms: decision tree, random forest, KNN, and DNN to improve the effect detection system as well as the NSL-KDD database which aims to improve detection accuracy. Osama Faker and Erdogan Dogdu proposed [14] a method for evaluating the performance of intrusion detection systems using Apache Spark as Big Data technology, and gradient stimulation tree (GBT) as classifiers and UNSW-NB15 as a data set to evaluate the system. Zina Chkirbene and al. [24] proposed an improved intrusion detection and classification system for a secure Cloud Computing (EIDC) environment using the “most frequent decision” combined technique to detect and classify the received traffic packets and the UNSW-NB15 dataset to generate the results; The purpose was to increase learning performance and system accuracy.
Mohammad Reza Ahmadi [6] proposed an intrusion detection and prediction system tested on the NSL-KDD7 dataset based on both genetic algorithm and co-evolving immune system where detectors can discriminate existing incidents and predict the new ones in a distributed environment. Farah Jemili [20] proposed a system for detecting and predicting intrusions on the basis of uncertain and imprecise influence networks using K2 Bayesian network and KDD’99 and DARPA 2000 datasets to manage uncertainty and imprecision and as well as use all available data. Jagtap S. et al. [42] proposed a review of using deep learning algorithms for intrusion detection and prevention, including artificial neural networks for Intrusion detection, and recurrent neural networks for Intrusion prevention.
Liu et al. in [43] proposed a recommender system for network intrusion detection based on decision trees. The system takes as input a set of network traffic features and generates recommendations for security analysts based on the severity of the threat. The authors evaluate the performance of the proposed system using KDD 99 dataset. This work demonstrates the potential of decision trees and recommender systems in intrusion detection.
Works [11, 15, 16, 26] and [14] have focused on intrusion detection but have not dealt with intrusion prediction, which consists of anticipating malicious actions before they take place. Whereas works [23, 35] and [32] have focused on intrusion prediction but have not dealt with intrusion detection. Some solutions are centralized using Weka platform, others use obsolete datasets, whereas the rest has not made the right choice of ML algorithm and the obtained results are not good, indeed.
Besides, all these proposed approaches are passive, except work [43] which has not dealt with intrusion prediction and just dealt with intrusion detection, not providing recommendations in case of detected attacks.
In this paper, a system which both detects and predicts as well as provides necessary recommendations is proposed. The proposed approach uses the decision tree algorithm for detection, the chronicle algorithm for prediction and an expert system for recommendations, and the obtained results are promising.
Intrusion detection and prediction system
An intrusion is any deliberate and unauthorized attempt to gain access to manipulate information or make a system unusable or inaccessible [16].
An intrusion detection system (IDS) is a complete ecosystem that allows to monitor a given environment activities and decide whether these activities are malicious or not based on system integrity, confidentiality and availability resources [12, 16]. A realistic cyber security intrusion detection system should be able to process large network traffic data as quickly as possible in order to detect malicious traffic as soon as possible [16]. The main purpose of this process is to protect the system and the network from intrusion [10]. There are two approaches of intrusion detection: detection based on anomaly and detection based on a signature.
Intrusion prediction systems (IPS) are network security software and hardware devices that monitor network or system activities to detect the malicious ones [7, 8]. The main function of intrusion prediction systems is to identify any malicious activity before it can begin [7, 8].
Intrusion detection and prediction systems (IDPS) are hardware and software devices that combine all the functionalities of intrusion prediction systems and intrusion detection systems. It does not only detect intrusions, but also predicts them.
An IDPS detects the intrusion by analyzing the data collected. The monitored environment can be network, host or application based:
HIDPS: A Host-Based intrusion detection and prediction system (HIDPS) monitors some or all of the dynamic behaviors and conditions of a computer system. It could detect the program accessed resources [24]. The types of characteristics that a host-based IDPS can monitor are network traffic, system logs, running processes, application activities, files access and system configuration [25].
NIDPS: A Network-Based Intrusion Prediction and Detection System (NIDPS) monitors network traffic for particular network segments or devices. It analyzes network and application protocol activities to identify suspicious activities [24]. It is primarily deployed at the boundary between networks, virtual private network servers, remote access servers, and wireless networks [25].
Hybrid IDPS: Consisting of Host-Based Intrusion Detection and Network-Based Intrusion Prediction [42].
There are some detection approaches in IDPS:
Knowledge-based approach (signatures): Signatures rely on the collection of malicious signature databases that must be updated regularly [26].
Behavior-based approach (anomalies): Anomalies rely on the prediction of the classification of behaviors, whether defined as baseline data (normal activities) or malicious behaviors collected from a specific host/network [26].
Specification-based approach: The specification base is similar to the anomaly-based one, created from generic profiles developed by the vendor and specific protocols, instead of developing a baseline by profiling day-to-day access behaviors [26].
In our contribution, we propose a Hybrid IDPS to take advantage of HIDPS and NIDPS, based on knowledge-based approach.
IDPS and machine learning
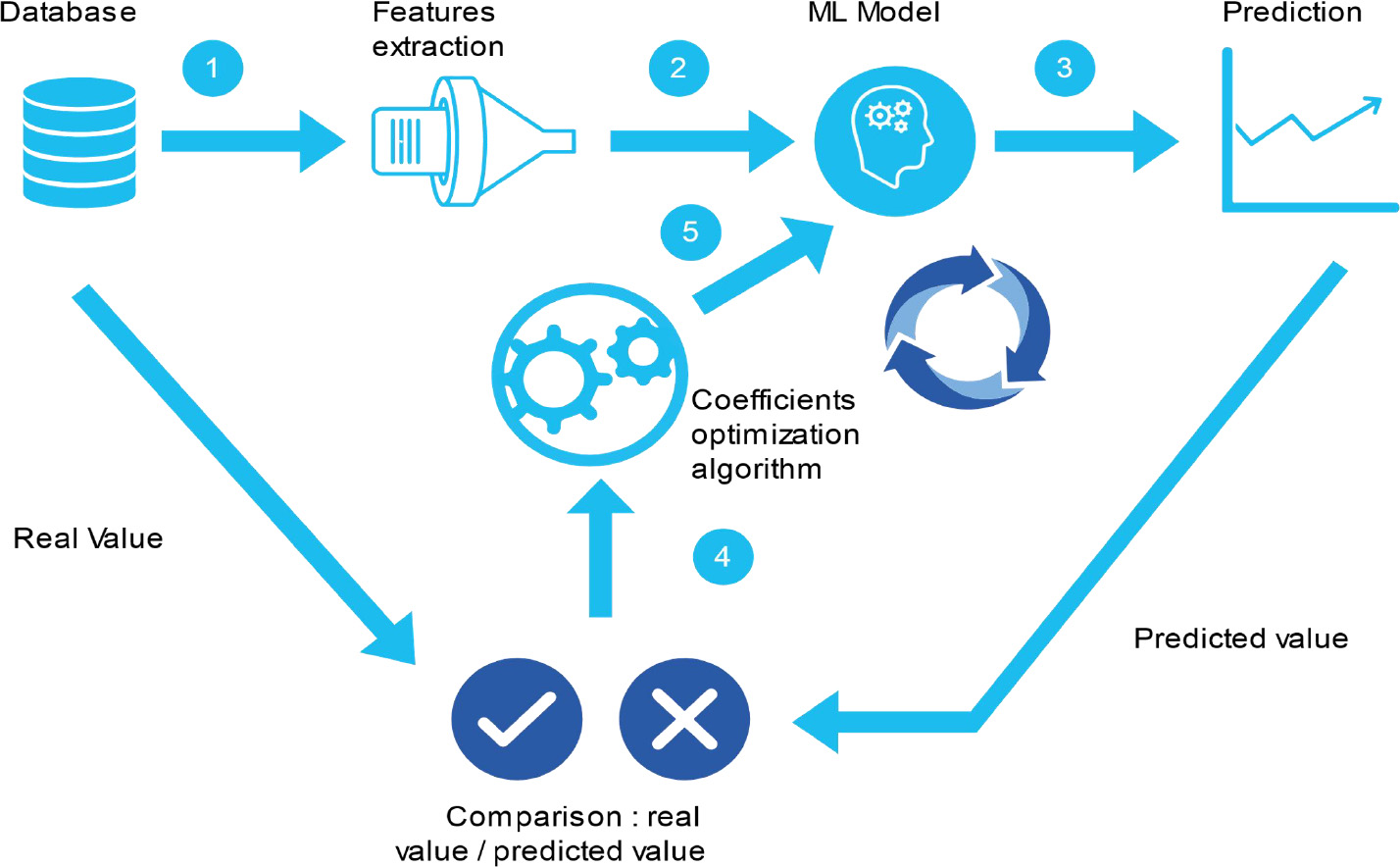
Machine Learning is a subfield of artificial intelligence that gives computers the ability to learn without being explicitly programmed [28] and to improve performance for certain tasks over time [12]. ML process is composed of many steps (see Fig. 1):
Data collection.
Data exploration and preparation: The data must be clean, precise and complete for ML models to be properly trained and provide good results. According to one research firm, more than 80% of the effort in an ML project is spent on data preparation [34].
Model construction: Choosing a good algorithm is a specific phase of ML to make it best fit the data. Several factors come into play to perform this task like number of features, amount of data, etc.
Evaluation of the model’s performance: It is important to evaluate the model used to see if it is working or not. This task is done by comparing the predictions on the assessment dataset to the actual values using various metrics.
Improved model performance: To obtain better predictions, optimizing the results is the solution. In addition, this task is performed so that the model can be generalized on data not yet seen by the algorithm during its learning phase.
Machine learning process.
In general, there are two types of machine learning techniques: supervised and unsupervised. Supervised learning is a common type of machine learning technique for creating a function from a set of data [29]. This type needs fully labeled class data [8]. Unsupervised learning is a method of machine learning where a model is fitted to the observations [29]. The purpose is to program the computer to do something without telling it how to do it [12]. Regarding this work, we have opted for supervised learning as we have labeled data.
Current recommender systems in response to intrusions
Intrusion detection systems analyze the activities on the computer and on the Internet, but how useful would be an IDS if it does not respond and does not prevent. The response of IDS differentiates between active and passive response. We will explain the difference in what follows.
The passive response: A passive response intrusion detection system detects and notifies all. When suspicious or malicious traffic is detected a warning is sent to the administrator or user taking precautions to block the activity or respond in some way [38]. Unlike the active response, the passive response has merely two reactions: The first one are warnings and advices, and the second one involves the generation of reports which monitor the systems and the production of reports. The passive intrusion detection system or IDS liability has a very special role in the field of computer systems protection. Indeed, instead of actively protecting computer components and systems, this type of intrusion detection system works passively and records network activity to trigger an alarm in case of any suspicious movement. The intrusion detection system can be an important tool to detect and identify threats and risks that IT systems are exposed to. The provision of an intrusion detection system is crucial to data collected effectiveness. However, the complexity of the network stream IDS can lead to false alarms called false positives.
The active response: An active response to intrusion detection system can not only discover malicious traffic and alert the administrator or user, but it also allows taking action and reacts to meet the threat and defends against intrusion [39]. According to the Linux Focus magazine, an active response means an automatic reaction in case the intrusion detection system identifies an attack or an attempted attack. Depending on the attack, the response options that can offer the IDS are various:
Action against the potential intruder.
Collect additional data only.
Change the configuration.
The first response is to trigger varieties of steps against the intruder as block access of the person or launch attacks against the illegal intruder. The second possible response is when an intrusion is detected, additional information about the user and his attack are being collected as its orders registration and when, how much time is left and also how often this creates the attacker profile, which later facilitates taking action against the attack. The last reaction is to make changes in system configurations. For example if the attacker uses a very specific IP addresses can prevent it from connecting with these IP addresses. Therefore, we can block all accesses to the network.
Below we briefly outline some examples of recommendation systems in response to the intrusions which have been recently developed.
OSSEC system: OSSEC is an active response to intrusion detection system based on the host, it is an open source system developed by the company Trend Micro. According to the official website of OSSEC, the system provides log analysis, integrity control files, rootkit detection and warning time with an active response that is most important because the system performs OSSEC immediate and automatic responses in case of attack without losing time and wait for the administrator to make the decision.
The OSSEC system can run on most operating systems such as Linux, Mac OS, Solaris, and Windows. OSSEC is a platform to control and monitor computer systems by providing the following main characteristics:
Integrity verification files
Rootkit detection
Active Response
The OSSEC system consists of various parts, it has a central manager monitoring. Moreover, it receives information from agents, syslog, databases and devices without agents.
Suricata system: Suricata is an open source-based intrusion detection system that monitors network security. The Suricata system is intrusion prevention system based on signatures that are distributed under GPL v2 which has been initiated in 2008 by Victor Julien. Then, this work is carried out by the Foundation Open Information Security (OSIF) with a beta version in December 2009 and a first standard in July 2010.
This system is a detection and prevention engine which is not intended to replace existing tools, but it brings new technologies and new ideas to the field. Suricata is a multi-threaded engine that contains native support IPv6. It also allows the extraction of files and many other features. Suricata The system has several characteristics: First, it is highly scalable, that is to say, it will balance an instance of processing load running on multiple processors. Second, this engine provides automatic recognition of the most common protocols, which makes it a great system Suricata malware hunter since it can stop them. Finally, Suricata can identify thousands of file types when crossing the network [41].
Snort system: Snort is a source network intrusion prevention system and open detector developed by Sourcefire (The community of security experts). It is also a free tool developed in 1998 by Martin Roesch of Sourcefire team [40]. Nowadays, it is worldwidely used by several companies, universities, and government agencies. IDS Snort uses the standard libcap library and tcpdump as a packet logging infrastructure. Its most famous feature is its flexible subsystem attack signatures. Snort has a constantly updated database of attacks across the internet which led it to become the strongest of the network intrusion detection systems. Snortsam is a plug-in for Snort enabling automatic blocking of IP addresses on multiple firewalls in an attack or intrusion. Guardian is a security program that works in conjunction with Snort to update the rules-based firewall on alerts generated by Snort, the rules allow you to block any incoming data from the IP address of the attacking machine.
By observing the previous section, we can see that the IPS are not miracle softwares that provide web browsing with peace of mind. Here are some disadvantages of intrusion prevention systems active response:
They block which is infectious in their eyes, so they are not reliable and may inadvertently block legitimate traffic and applications.
Sometimes they let some attacks without identifying them.
They are not very discreet and can be discovered by hackers.
Therefore, we need a system that defends against intrusions on precise and appropriate recommendations for each type of attack [39].
Expert systems
Expert systems are among the best systems used to help the user make decisions. These have evolved with the changing technology. According to the definition suggested by Jean Charles Pomerol, an expert system is a computer tool developed by artificial intelligence to simulate the expertise of an expert in a particular field, and well-defined, through the operation of a set of numbers knowledge provided in an explicit way by specialists.
Another definition of experts and the systems [40], which defines an expert system as intelligent software that uses the necessary knowledge and skills to solve problems that require human expertise.
Thus, an expert system is a software able to offer recommendations to a particular problem as a human expert.
In general, an expert system is an instrument that can reproduce the cognitive mechanisms of a specialist to solve a particular problem.
Its strengths are:
Cost reduction: the cost of an expert systems is very small.
Experience is permanent: the knowledge of an expert system is undefined.
Multiple experiences: different expertise can be combined.
Explanation: the expert system may explain his reasoning.
Speed of response: the expert system responds in a timely manner.
Easy Update: expert systems are easy to update.
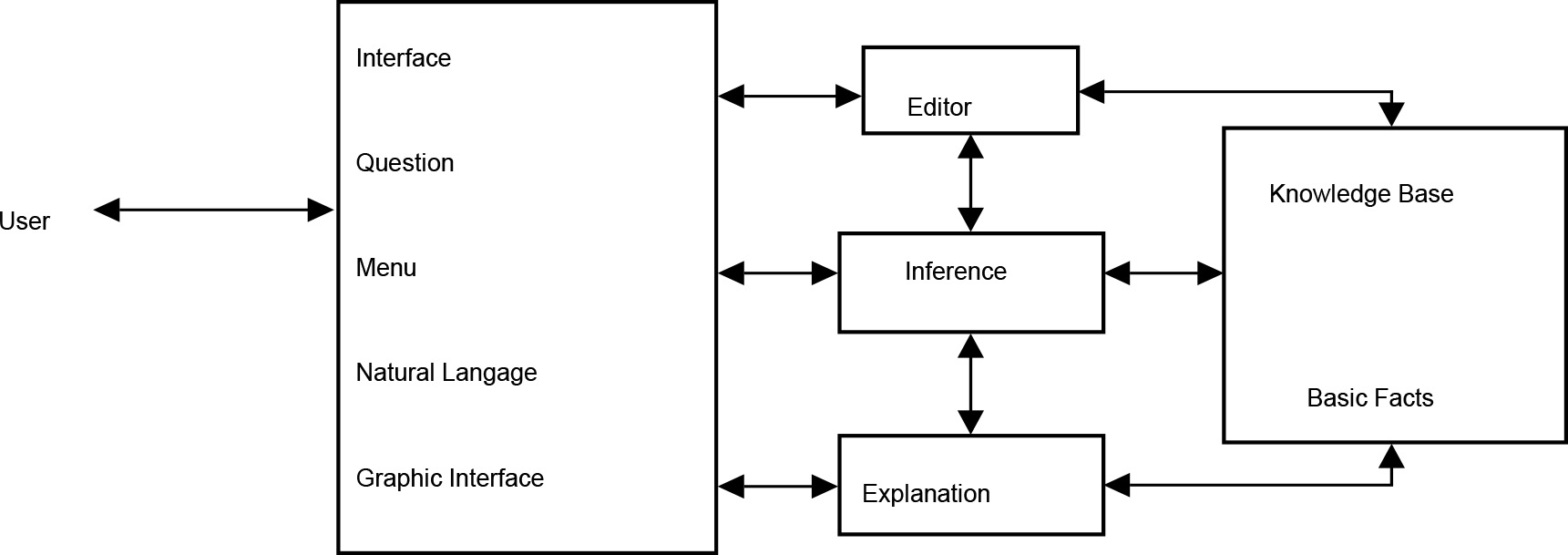
The structure of an expert system consists of several components that interact with each other, defined as:
User interface: It simplifies communication and facilitates interaction between the user and the system.
The knowledge base: this database contains all the knowledge about solving the problem.
The inference engine: Runs a problem solving plan using the knowledge of the database to produce new information.
The basic facts: contain the specific data related to the processed application.
The explanation module: provides the explanation of the expert system reasoning.
The editor: provides editing knowledge base.
Figure 2 shows the architecture of an expert system.
Architecture of an expert system.
The cycle of an expert system contains five stages [41]:
Engaging settings: This step is to gather and obtain the knowledge, whatever its type.
Application of inference rules: this phase is to apply the rules of proper inferences based on data from the lens.
Saving Results: This step is to store the results in the knowledge base and send potential solutions to the user for validation.
Commitment parameters: In this step, the facts are recalled stored by the meta-rules.
Making the result: in this phase, each solution found and then validated by the user is recorded in the basic facts as validated solution.
Expert systems are not perfect, the researchers noted drawbacks studies have shown the limits to their effectiveness as the large investment required in terms of cost and time, and the lack of machine learning. But the biggest drawback is that the development of this application is too heavy when exceeding a hundred inference rules, it becomes very hard and very difficult to understand how the system reasoning [40].
An expert system may use different calculation techniques, which are the basis of inference engine and associated decision rules [38]. Different calculation methods are depending on the type of expert system. We are going to present a summary table (see Table 2), which contains the advantages and limitations of Expert System algorithms to make a comparison between these methods. More specifically, comparison is made between the Forward chaining and Backward chaining algorithms.
Comparison of methods for expert system
Methods
Advantages
Disadvantages
Forward chaining algorithm
Receiving new data may trigger new inferences, which makes it more suitable for dynamic situations engine where conditions are subject to change.
Faster to execute if more rules lead to the conclusion sought.
Can operate with incomplete or uncertain data.
Natural representation of knowledge .
Raises all the rules without focusing on the goal when trying to prove a conclusion.
Meet memory consumption problems, especially in very large expert systems.
Inability to learn that is to say, the system cannot break the rules as humans.
Backward chaining algorithm
No rule triggered for nothing when trying to meet a goal.
Natural knowledge representation.
Separation of processing knowledge.
May be expensive (several rules) so many rules lead to the conclusion sought.
The need for substantial expertise to develop the application.
Complicated method for manual use.
Inefficient search strategy, the system goes through the several rules and can be very slow.
By observing the above table, we can see that the backward chaining algorithm may seem complicated and can be a little long and expensive when the system is complex. Thus, privilege is chosen to forward chaining algorithm which is more suitable to dynamic situations and has better speed of implementation.
Big data platforms
This section presents different tools used to build and evaluate our system:
Databricks
Databricks is a Spark service running on AWS. Amazon Web Services is a cloud platform that has infrastructure technologies and features such as compute, storage and databases, to emerging technologies such as machine learning and artificial intelligence [3]. The AWS Elastic MapReduce (EMR) platform is a solution for processing large amounts of data using tools such as Apache Spark.
Databricks [9] is a data analysis platform founded by the creators of Apache Spark, whose goal is to accelerate innovation in data science, analysis and engineering by:
Applying advanced analyzes for machine learning and large-scale graphics processing.
Using deep learning to harness the power of unstructured data like AI, image interpretation, machine translation, natural language processing, etc.
Making data warehousing, fast, simple and scalable.
Proactively detecting threats with data science and AI.
Performing a real-time analysis of the high-speed sensor and IoT data in time series.
Databricks Community Edition is a top-level platform that allows users to master Apache Spark and offers a variety of functionalities [3]:
It includes an interactive user interface (a workspace with notebooks).
It allows a cluster sharing where several users can connect to the same cluster.
It offers a security function (access control to the entire workspace).
It allows a good collaboration (access of several users to the same computer, a controlled revision history as well as an integration of IDE and Github).
It offers data management (support for connecting different data sources to spark, a caching service to speed up queries).
A free version provided by Databricks is called Databricks Community Edition. This platform is a Big Data solution based on Cloud and designed for developers and data engineers.
Apache Spark
Apache Spark [1] is an open source unified analysis engine developed at the University of California at Berkeley by AMP Lab for large-scale distributed data processing. The choice to develop with Apache Spark is because:
This Framework is capable of providing simple high level APIs in Java, Scala, Python and R.
It permits launching programs 100 times faster than Hadoop MapReduce in memory and 10 times faster on disk [2].
This Big Data analysis tool can be deployed as a standalone cluster or connected to Hadoop instead of MapReduce [4].
It allows access to several data sources like HDFS, Cassandra, Hbase and H3 [2].
It can easily combine libraries of MLlib algorithms for Machine Learning within the same application which allows developers to gain productivity [3].
It supports a set of top-level tools, including Spark SQL for SQL queries and structured data processing, MLlib for machine learning, GraphX for graphics processing and Spark Streaming for flow data processing.
In this Table 3 below, a comparison between the most popular Big Data frameworks is given:
Comparison between big data frameworks
Big data framework
Advantages
Apache flink
Open source, distributed and fault tolerant
Batch & stream processing
Low latency
Exactly once processing
Supported languages (Java, Python, Scala, R)
Apache storm
Open source, distributed and fault tolerant
Pure stream processing
At least one processing
Supported languages(Java, Clojure)
Apache spark
Open source, distributed and fault tolerant
Batch & stream processing
Low latency
Exactly once processing
Interactive queries
Streaming deduplication
Machine learning library: ML Spark
Supported languages (Java, Python, Scala, R)
ML pipeline
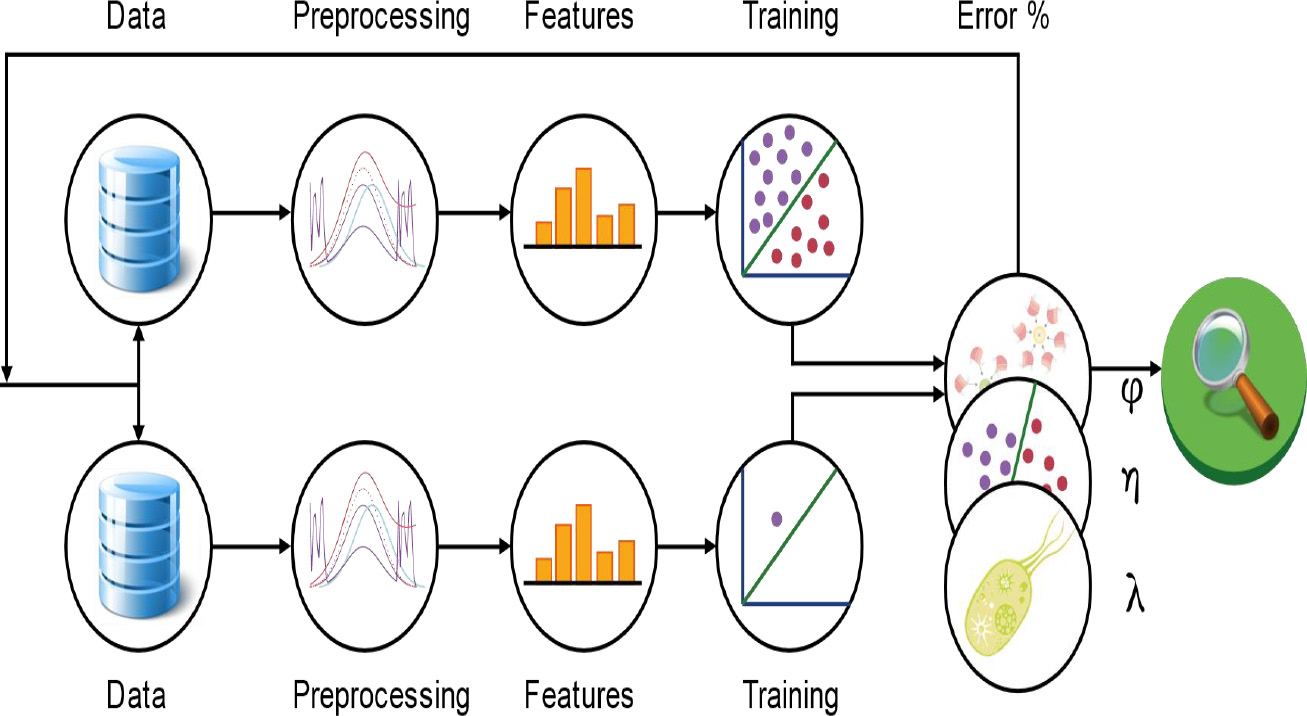
The concept of pipeline [5] is mainly inspired by sickitlearn where the concepts introduced by pipeline are:
Dataframe: a Spark SQL DataFrame used by the ML API as an ML data set, which can contain several types of data.
Transformer: A Transformer is an algorithm which can transform a DataFrame into another DataFrame. For example, an ML model is a transformer which transforms a DataFrame with functionalities into a DataFrame with predictions.
Estimator: An estimator is an algorithm which can be adjusted on a DataFrame to produce a transformer. For example, a learning algorithm is an estimator that trains on a Data Frame and produces a model.
Pipeline concept.
An ML pipeline [34] is a sequence of data preprocessing, feature extraction, model adjustment and validation steps (see Fig. 3).
In this work, an ML pipeline model is used. It contains a decision tree classifier to detect and classify intrusions.
Proposed approach
In this section, the proposed intrusion detection and prediction approach are presented as shown in Fig. 3. There are many alert databases and the most important ones are listed in the following Fig. 3.
To evaluate the proposed system, the UNSW-NB15 and CICIDS2017 datasets are used. The UNSW-NB15 and CICIDS2017 datasets are network traffic datasets that are widely used in the research community to develop and evaluate intrusion detection systems. These datasets are public and respectively available on [44] and [45]. On these pages, there are the datasets along with other resources such as documentation and publications related to the datasets.
The UNSW-NB15 [44] dataset was chosen for evaluation due to its widespread recognition and acceptance within the research community as a robust benchmark for intrusion detection systems. It has been extensively utilized in prior studies, providing a valuable basis for comparing our system’s performance against established results. Additionally, the dataset’s public availability, along with related documentation and publications, ensures transparency and facilitates the reproducibility of our research.
The selection of the CICIDS2017 [45] dataset was driven by its prominent role in the research community for assessing intrusion detection systems. This dataset has been widely employed in various studies, allowing us to benchmark our system’s performance against a well-established reference point. Furthermore, its accessibility through a public source and the availability of accompanying resources, such as documentation and publications, make it a suitable choice for our evaluation, enhancing the credibility and transparency of our research.
The UNSW-NB15 dataset
IN 2015, Mustafa and Slay [19, 28, 29] created a dataset called UNSW-NB15 using an IXIA tool to extract a hybrid of attack activities synthesized between modern normal and contemporary modern network traffic, within from the UNSW Cyber Security Laboratory. A tcpdump tool (tcpdump tool, 2014) was used to capture 100 GB of raw network traffic, the Argus tools (Argus tool, 2014) and Bro-IDS (Bro-IDS tool, 2014) were configured in a process parallel to extract attributes [30].
The UNSW-NB15 dataset includes 49 attributes and 2,540,044 records stored in four CSV files [19, 30]-which are classified into six groups: the first group is stream attributes (Srcip, Sport, dstip, dsport, Proto) including identifier attributes between hosts, the second group is basic attributes (state, dur, sbytes, dbytes, Sttl, Dttl, sloss, dloss, service, sload, dload, spkts, dpkts) which implies the attributes representing the protocol connections, the third group is the content attributes (Swin, Dwin, Stcpb, Dtcpb, smeansz, dmeansz, trans depth, res bdy len) which encapsulate the TCP/IP attributes, it also contains certain attributes of http services, the fourth group is time attributes (sjit, djit, stime, ltime, sintpkt, dinpkt, tcprtt, synack, ackdat) which contains time attributes, the fifth group is additional generated attributes which can be split into two groups: general purpose attributes (Is sm ips ports, Ct state ttl, Ct w http mthd, Is ftp login, Ct ftp cmd) where each attribute has its own function, in order to protect the protocol service and the connection attributes (Ct srv src, Ct srv dest, Ct dst ltm, Ct src ltm, Ct src dport ltm, Ct dst sport ltm, Ct dst src ltm) which are constructed from the stream of 100 record connections based on the sequential order of the last time function. And the sixth group is the category of labeled attributes (Attack cat, Label) which are provided to label this dataset [19, 30].
The UNSW-NB15 dataset includes nine types of attacks which are: Fuzzers, Analysis, Backdoor, Dos, Exploit, Generic, Recognition, Shellcode and Worm [19, 28] (see Fig. 4).
Fuzzers: an attack in which the attacker tries to discover security holes in a program, an operating system or a network by feeding it with the massive capture of random data to make it crash [27, 30].
Analysis: an attack method that violates Internet applications via ports (for example, port scans), email (for example, spam) and web scripts (for example, HTML_les) [27].
Backdoor: a technique in which a system security mechanism is bypassed by stealth to access a computer or its data [29].
Back: an attack that disrupts computer resources via memory in order to prevent authorized requests from accessing a device [27].
Exploit: a sequence of instructions which takes advantage of a security problem within an operating system or software and exploits this knowledge by exploiting the vulnerability [27, 29].
Generic: a technique which establishes against each block encryption using a collision hash function without regard to the configuration of the block encryption [30].
Attacks distribution in UNSW-NB15 database.
Recognition: an attack that gathers information on a computer network to escape its security controls [27, 30].
Shellcode: an attack in which the attacker enters a light piece of code from a shell to control the compromised machine [30].
Worm: a malicious program which requires user action to trigger and distribute it over a computer network by replicating itself according to the security failures of the target computer [27].
The CICIDS2017 dataset
The CICIDS2017 [45] dataset is a network intrusion detection dataset that was created by the Canadian Institute for Cybersecurity (CIC) at the University of New Brunswick. It was released in 2017 and is designed to be used for research purposes in the field of network security.
The dataset contains a total of 15 days’ worth of network traffic data, collected from a real-world network environment. The traffic was generated using a variety of network protocols, including HTTP, FTP, DNS, and SMTP, among others. The dataset includes both benign and malicious traffic, The CICIDS2017 dataset is a labeled network traffic dataset that contains various types of attacks as well as normal traffic. The dataset includes the following types of attacks:
Brute Force Attack: An attacker tries to guess a password by trying different combinations of usernames and passwords.
DoS Attack: An attacker floods a server or network with traffic to make it unavailable for legitimate users.
Web Attack: An attacker exploits vulnerabilities in web applications to gain unauthorized access or to perform other malicious activities.
Infiltration Attack: An attacker gains unauthorized access to a system or network by exploiting vulnerabilities or using social engineering techniques.
Botnet Attack: An attacker uses a network of compromised computers to perform malicious activities, such as sending spam or launching DDoS attacks.
DDoS Attack: An attacker uses a network of computers to flood a target system or network with traffic, making it unavailable for legitimate users.
PortScan Attack: An attacker scans a network for open ports and vulnerabilities that can be exploited.
Attacks distribution in CICIDS2017 database.
Fuzzing Attack: An attacker sends random or invalid data to a system or network to find vulnerabilities.
MITM Attack: An attacker intercepts communication between two parties to gain access to sensitive information.
SSH Brute Force Attack: An attacker tries to guess SSH login credentials by trying different combinations of usernames and passwords.
The dataset contains a total of 2.8 million network flow records, with each record consisting of 80 features, including network flow characteristics such as duration, number of packets, and bytes transferred, as well as transport layer and application layer protocol fields.
UNSW-NB15 and CICIDS2017 datasets must meet critical characteristics, including data integrity, security, concurrency control, data recovery, scalability, performance, data consistency, flexibility, and extensibility. In our contribution, we harness the power of Azure and Spark technologies to reinforce these characteristics. Azure offers scalable infrastructure and robust data recovery options, enhancing scalability and data recovery in our database solution. Additionally, Spark enables efficient processing, bolstering performance and data analysis capabilities.
In the proposed contribution, both UNSW-NB15 and CICIDS2017 datasets are stored in DBFS, the distributed file system available on spark cluster in Databricks. The UNSW-NB15 dataset contains approximately 2.5 million instances and is approximately 2.4 GB in size, and the CICIDS2017 dataset contains approximately 2.8 million instances and is approximately 5.5 GB in size. The proposed system based on Apache Spark has to reduce the time of data analysis.
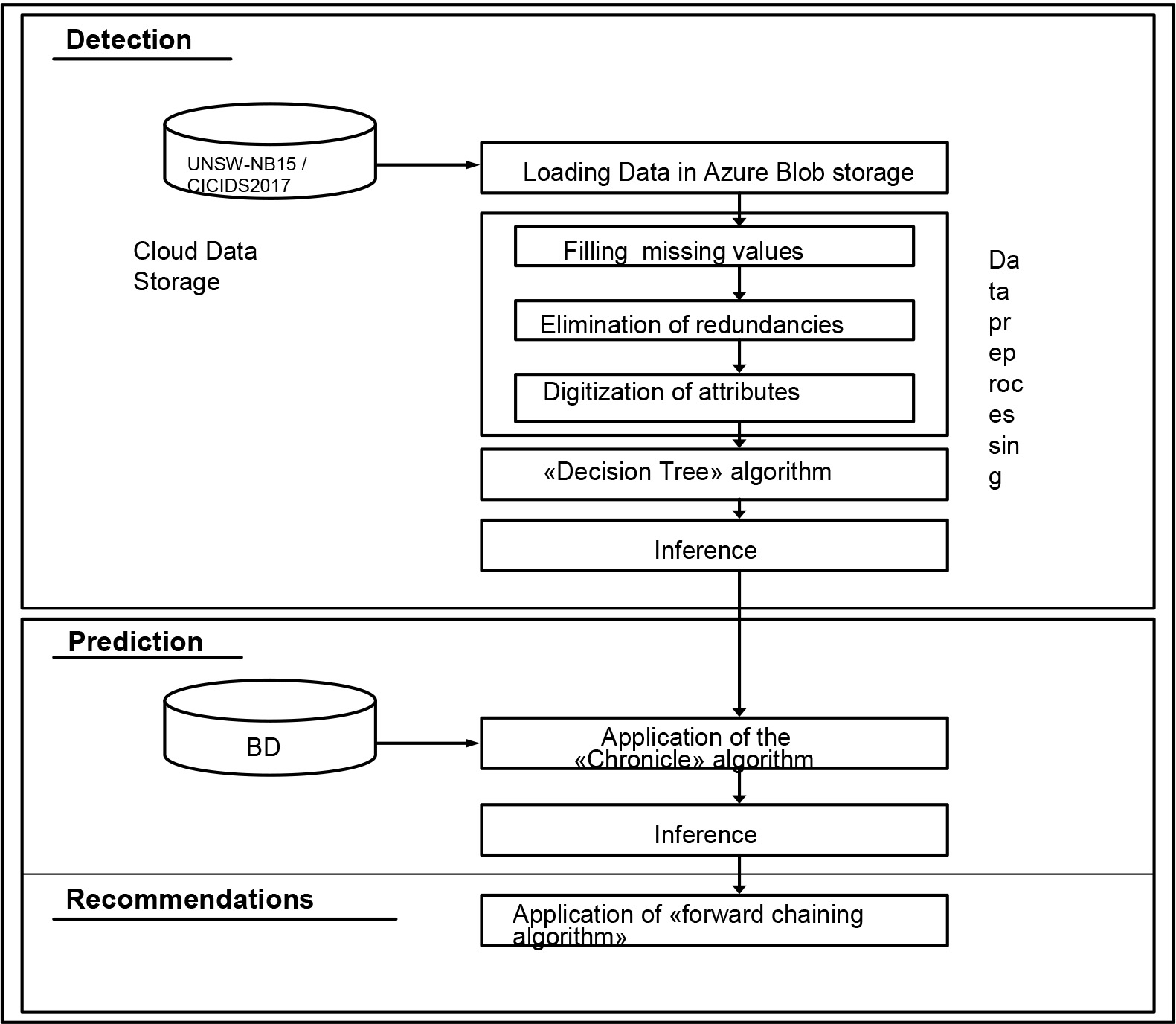
The proposed system has the following steps:
Collected files are uploaded directly to Azure Blob Storage.
A Spark job reads the data while it’s being placed in Azure Blob Storage.
Data is pre-processed and cleaned.
Data is classified using a Decision Tree pipeline.
Classifications are stored into Azure Data Lake Store.
This process involves collecting dataset files and loading them into Microsoft Azure Blob Storage. Blob Storage is built to meet HDFS standards and use global and local replication with Exabytes of capacity and massive scalability along with enterprise grade security. In order to obtain dataset files, we use the Microsoft Azure SDK for Python, which is a set of Python packages that make it easy to access components of Microsoft Azure.
The main steps of the proposed approach as shown in Fig. 6 can be summarized in these following steps:
Filling missing values.
Elimination of redundancies.
Digitization of attributes of type String.
Data classification based on Decision Tree model.
Prediction based on Chronicle algorithm.
Recommendations
Filling missing values
This step consists of filling in the missing values in the database records. Filling missing values involves replacing the missing values in a dataset with some appropriate values in order to improve the overall quality of the data and thus improve the accuracy of the analysis. To fill in the missing fields, the proposed solution is as follows: Each attribute of integer type will take 0 as a default value. On the other hand, attributes of type String will take “Unknown”. To perform this solution, we applied the na.fill() method. After applying this solution, the result obtained is a database with no missing values.
Proposed approach.
Elimination of redundancies
To address potential issues related to duplicate data in the dataset, a meticulous analysis was conducted. This analysis involved the utilization of the “dropDuplicates()” method, a technique that systematically identifies and removes redundant records [17]. By implementing this method, we achieved several essential outcomes. Firstly, it led to a substantial reduction in the dataset’s size, resulting in storage space savings and more efficient data processing. Secondly, the elimination of redundancies enhanced the accuracy and reliability of the data, which in turn reduced the time required for analysis and computations. Furthermore, this optimization step elevated the overall dataset quality, rendering it more suitable for subsequent data-driven tasks, including data analysis, modeling, and machine learning. Ultimately, these measures were instrumental in enhancing the overall detection rate performance of the system, ensuring its effectiveness in identifying and mitigating potential threats.
Digitization of attributes of type string
This step consists in digitizing the attributes of type String (converting them into digital or numerical format). This step Improves data analysis: By converting strings into digital format, it becomes possible to run queries and perform analysis on the data. It also allows efficient data storage since digital data takes up less storage space than text data. And allows faster processing, this means that digitized data can be processed in real-time, allowing for faster recommendations.
To perform this step, the StringIndexer () method is used.
After having stored and preprocessed, the data is hence ready to be used by the ML classification model. First of all, it is important to divide the data set in two parts: training data for model training and test data for performing the prediction.
The Machine Learning pipeline helps us bring together the stages of data transformation. After the creation of this class, a fit () method is called to start the transformation and learning from the training data, and a Transform () method to perform the prediction on the test data.
After classifying intrusions, comes the intrusion prediction part where the temporal analysis model is applied. Before applying this model, two columns are added to the database: the first one represents the difference between the two time attributes “Ltime” and “Stime” whereas the second one represents the time intervals noted t1, t2, …, tn.
After performing this preprocessing, the forecast model is applied to obtain an attack scenario in a time interval. Finally, to understand the quality of the predictions, we went through the evaluation stage where the calculation of the evaluation metrics is important.
Data classification based on decision tree model
There are many supervised machine learning algorithms, each with its own strengths and weaknesses. Here are some of the most common ones:
Linear regression: A simple algorithm used for predicting continuous values based on a linear relationship between input features and output variables.
Logistic regression: A classification algorithm that uses a logistic function to estimate the probability of belonging to a certain class.
K-nearest neighbors (KNN): A non-parametric algorithm that predicts the label of a sample based on the majority vote of its K-nearest neighbors in the training data.
Support vector machine (SVM): A binary classification algorithm that finds the hyperplane that maximizes the margin between the two classes in the feature space.
Naive Bayes: A probabilistic algorithm that uses Bayes’ theorem to estimate the conditional probability of belonging to a certain class, given the input features.
Gradient boosting: An ensemble algorithm that sequentially adds decision trees to the model, each one correcting the errors of the previous tree, to improve the model’s accuracy.
Decision tree: A tree-based algorithm that recursively partitions the data based on the values of input features, until the data is split into homogeneous subsets that are then assigned a label or class.
Random forest: An ensemble algorithm that combines multiple decision trees to improve the model’s accuracy and robustness.
In this contribution we opted for Decision trees as they have several advantages that make them popular for many applications. Here are some advantages of decision trees compared to the other machine learning algorithms:
Easy to understand and interpret: Decision trees are a highly interpretable model, making it easy for humans to understand how the model works and why it makes certain decisions.
Can handle both categorical and numerical data: Decision trees can handle both categorical and numerical data without the need for feature scaling, making it a versatile algorithm.
Can handle missing data: Decision trees can handle missing data by simply skipping over that feature when making a split, making it robust to missing data.
Can handle non-linear relationships: Decision trees can capture non-linear relationships between features and the target variable, making it a useful algorithm when dealing with complex datasets.
Fast to train and classify: Decision trees have a relatively fast training time and can quickly classify new data points once the tree has been built.
Can be used for feature selection: Decision trees can be used for feature selection by identifying the most important features for predicting the target variable.
Decision trees are a simple and effective supervised machine learning algorithm. In fact, a decision tree can be represented with nodes and edges. It is, also, composed of a root node which performs the first split nodes and leaves in which we can find the expected results [17].
Decision trees [36] are one type of supervised machine learning. They are defined by two entities: the nodes and the leaves where the decision nodes are where the data is divided and the leaves represent the final results.
The decision trees [37] are used to classify the examples according to the values of their attributes. Each attribute becomes a node in the constructed tree and their possible values determine the paths. The heuristics used to measure the purity of learning data are:
Entropy: Is the measure of the amount of uncertainty or chance in data. This metric provides information on the predictability of a certain event. The purpose of entropy is to measure the discriminating power of an attribute for the classification task. Here is the formula for entropy impurity:
With an attribute for the decision tree.
Information gain: Is the actual change in entropy after deciding on a particular attribute. It measures the relative change in entropy with respect to the independent variables. The purpose of this metric is to rank the filter attribute at the given node in the tree. Here is the formula for the Information gain measure:
With the probability of a classification .
Ranking in the decision tree is based on high information gain entropy in descending order.
After storing and preprocessing the data, our data is ready to be used by the “Decision Tree” classification model. First, it is important to divide the data set into two: training data for model training and test data for making the prediction. Then, we have a machine learning pipeline that helps us bring the stages of data transformation together. After this class is created, a Fit () method is called to start the transformation and training of training data, and a Transform () method to perform prediction on the test data.
Prediction based on chronicle temporal model
The tools for temporal analysis are very limited in the literature. We mainly cite:
ARIMA: (Autoregressive Integrated Moving Average) [16] is a prediction model based on linear functions; Its goal is to find a simple model that can provide a sufficient description of the observed data. This model is used to predict future values of the time series at time using past values.
ARIMA is a widely used statistical model for analyzing and forecasting time-series data. However, there are several drawbacks to the ARIMA model that should be considered:
Stationarity Assumption: ARIMA assumes that the time series is stationary, meaning that its statistical properties (mean, variance, etc.) do not change over time. In practice, many time series are non-stationary, meaning they have a trend, seasonality, or other patterns that change over time. ARIMA models can be extended to handle some types of non-stationary data, but it requires additional model components or transformations.
Lag Selection: The performance of ARIMA models depends on selecting the appropriate lags for the autoregressive (AR) and moving average (MA) components. Choosing the wrong lags can lead to poor model performance and inaccurate forecasts. The process of selecting lags can be time-consuming and requires domain expertise and statistical knowledge.
Data Requirements: ARIMA models require a minimum amount of data to estimate the model parameters accurately. The more complex the model, the more data it requires. If the time series is short or has missing data, ARIMA models may not be suitable.
Noisy Data: ARIMA models assume that the time series data is generated by a stochastic process with a specific mathematical structure. However, real-world time series data is often noisy, and it may not follow the assumptions of the ARIMA model. In such cases, the ARIMA model may not provide accurate forecasts.
Complexity: ARIMA models can become very complex when dealing with multiple AR and MA components, seasonal patterns, and other variations. This complexity can make it challenging to interpret the model results and communicate them effectively to stakeholders. Moreover, the model may be difficult to maintain and update as new data becomes available.
Recurrent Neural Networks (RNNs): A recurrent neural network [16] is a model that can model and predict complex nonlinear ones. Thanks to the cycles in its interconnection diagram, the model has internal memory. In theory, the network can memorize displayed information in an arbitrarily high order, but practically, in the long run, it will lose its efficiency in dynamic processes.
RNNs are a class of neural networks that are designed to handle sequential data such as time-series or natural language. While RNNs have been successful in various applications, they also have some drawbacks that should be considered:
Vanishing and Exploding Gradients: RNNs are prone to vanishing and exploding gradients, which can make it difficult to train the model. This happens when the gradient signal propagated through time becomes too small or too large, respectively. This problem can be addressed by using special types of RNNs, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), which can better handle long-term dependencies.
Memory Constraints: RNNs have a memory constraint, which means that they can only store a limited amount of information from the past. This can be a problem when dealing with long sequences, as the network may forget important information from earlier in the sequence.
Computational Complexity: RNNs can be computationally expensive to train and evaluate, especially when dealing with long sequences or large datasets. This can limit their applicability in some domains.
Input and Output Constraints: RNNs require that input and output sequences have a fixed length. This can be a problem when dealing with variable-length sequences, such as natural language sentences. Techniques such as padding or truncation can be used to overcome this problem, but they may introduce additional noise in the data.
Limited Parallelism: RNNs are inherently sequential models, which means that they cannot be easily parallelized. This can limit their speed and scalability, especially when dealing with large datasets.
Interpretability: RNNs can be difficult to interpret, as the network weights and activations do not have a direct interpretation in terms of the input data. This can make it challenging to understand how the model makes its predictions.
Chronicles: A chronicle is a set of events linked together by time constraints representing a scenario of attacks. This model takes the date event stream as input and identifies chronicle instances as events develop. One of its main advantages is that it is possible to make a complete forecast of the possible dates for each expected event [16].
The Chronicle temporal analysis model is used in this contribution as it is a powerful tool for identifying patterns and anomalies in large datasets. When applied to cybersecurity, it can be used to predict potential intrusions by analyzing historical data to identify patterns of behavior that could indicate an attack. It has several advantages:
Multi-granular Analysis: The Chronicle model allows for the analysis of time-series data at multiple levels of granularity, such as yearly, monthly, weekly, daily, or even hourly. This can help identify patterns and trends that may not be apparent at coarser time scales.
Temporal Context: The Chronicle model emphasizes the importance of temporal context, which means that the analysis takes into account the sequence of events and their timing. This can help identify the causal relationships between events and understand the impact of time on the data.
Event-centric Analysis: The Chronicle model focuses on events as the primary unit of analysis, rather than individual data points. This can help identify meaningful patterns and trends that are related to specific events or sequences of events.
Interactive Visualizations: The Chronicle model includes interactive visualizations that allow users to explore and analyze the data in real-time. This can help users gain insights and identify patterns quickly and efficiently.
Multiple Perspectives: The Chronicle model allows for the analysis of time-series data from multiple perspectives, such as statistical, spatial, or semantic. This can help identify patterns and trends that may not be apparent when analyzing the data from a single perspective.
Scalability: The Chronicle model is scalable, which means that it can be applied to large datasets without sacrificing performance. This can be particularly useful when dealing with high-frequency or streaming data.
The Chronicle temporal analysis model, Recurrent Neural Networks (RNNs), and Autoregressive Integrated Moving Average (ARIMA) are all useful tools for analyzing and forecasting time-series data, but they have different strengths and weaknesses.
The Chronicle model is particularly well-suited for analyzing complex, multi-dimensional time-series data, such as data from social media, sensor networks, or financial markets. It emphasizes the importance of temporal context, event-centric analysis, and interactive visualizations, which can help identify patterns and trends that may not be apparent using other methods. The Chronicle model can also handle missing or noisy data and is scalable to large datasets.
On the other hand, RNNs and ARIMA are more focused on forecasting future values based on past values of a single time series. RNNs are particularly well-suited for handling sequential data with long-term dependencies, such as natural language or financial data, and can handle variable-length inputs and outputs. ARIMA is a popular statistical method for modeling stationary time series, such as economic or financial data, and can be easily interpreted and explained.
Therefore, the choice between these models depends on the specific requirements of the analytical task. If the goal is to analyze complex, multi-dimensional time-series data and identify patterns and trends over time which is the case here, the Chronicle model may be the best choice. If the goal is to forecast future values of a single time series, RNNs or ARIMA may be more appropriate depending on the nature of the data [33].
In this proposed contribution, to predict intrusions, a Chronicle model, which is represented in the form of a constraint graph where the events are represented by nodes and the temporal constraints are the labels connecting the nodes, is used. A chronicle system is made up of three parts:
A set of predicates
A set of temporal constraints concerning these predicates
A set of actions to be applied when the chronicle is recognized (optional).
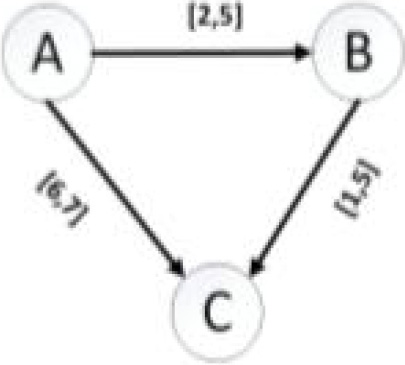
Chronicle example.
After classifying the intrusions, we move on to predicting them by applying the “Chronicle” algorithm after adding two columns to the database: the first column represents the difference between two time attributes “Ltime” and “Stime” and the second column represents the time intervals noted “t1, t2, …, tn”. After performing this preprocessing, the “Chronicle” algorithmis applied to obtain the attack scenarios in the time intervals.
Recommendations
Finally, to provide recommendations, we went through the forward chaining algorithm which calculates the recommendations that better fit the detected attacks.
In scenarios where a different approach is employed, such as backward chaining, the inference engine would start with a goal or conclusion and work backward to determine which rules or facts support that goal. The choice between forward and backward chaining often hinges on the nature of the problem, the availability of data, and the desired outcome.
The forward chaining is a mode of reasoning the inference engine of an expert system. This is a method of rules deduction starting from the premise to derive new conclusions. These findings enrich the working memory and can become the other rules premises. Forward chaining is a method of reasoning data driven, unlike the backward chaining who shares the findings to try to go back to the axioms. In the forward chaining mode, the inference engine share from facts to reach the goal, that is to say, it selects only the rules whose conditions of the left are checked (of the base facts), and then applies the first rule, which adds the conclusion to the base.
One of the advantages of the forward chaining algorithm on the backward chaining is that the receipt of new data may cause new inferences, making the inference engine best suited to dynamic situations in which the conditions are likely to change. The forward chaining is used in artificial intelligence, in a rule-based expert system, a rules engine, or in a production system.
To complete our presentation of forward chaining, the algorithm is presented in Fig. 8.
Forward chaining algorithm.
The forward chaining algorithm is a bottom-up approach that starts with a set of initial facts and uses the rules to infer additional facts until a goal is reached. Here are the general steps involved in the forward chaining algorithm:
Initialize the working memory with a set of initial facts.
Identify all the rules that can be fired based on the current set of facts in the working memory.
Apply the rules to the facts to infer new facts, and add these new facts to the working memory.
Repeat steps 2 and 3 until a goal is reached or there are no more rules to fire.
In summary, the forward chaining algorithm works by iteratively applying rules to infer new facts and adding them to the working memory until a goal is reached or there are no more rules to fire.
The decision to employ an Expert System, specifically utilizing the forward chaining algorithm, rather than alternative approaches like Intelligent Agents, in our intrusion detection and recommendation system stems from its compatibility with rule-based decision-making in the realm of cybersecurity. An Expert System with forward chaining is well-suited for making recommendations and decisions based on predefined rules and expert knowledge, crucial for handling potential cyber threats effectively. Furthermore, the forward chaining algorithm’s adaptability to changing conditions and its ability to build conclusions step by step as new data is received make it particularly suitable for dynamic and real-time intrusion scenarios. Its established utility in artificial intelligence and expert systems adds to its credibility, providing transparency and traceability in decision-making, essential for auditing and accountability in security-related applications.
Experimentation
To evaluate the performance of the proposed system, four performance metrics are used such as Precision, Recall, Accuracy and F-Measure.
Precision: this is the most important measure of any classification system. it provides information on the probability that a prediction of a given category is correct.
Precision TP/(TP FP)
Recall: the relationship between the number of correctly detected intrusions and the total number of intrusions.
Recall TP/(TP FN)
Accuracy: the relationship between correct detections and total detections obtained.
Accuracy TP N/TN TP FP FN
F-Measure: the harmonic mean which combines the recall and the precision.
F-Measure 2*(Recall*Precision)/(Recall Precision)
Where TP True Positive, FP False Positive, TN True Negative and FN False Negative.
True Positive (TP): Attack data that is correctly classified as an attack.
False Positive (FP): Normal data that is incorrectly classified as an attack.
True Negative (TN): Normal data that is correctly classified as normal.
False Negative (FN): Attack data that is incorrectly classified as normal.
In this approach, AWS Databricks is used as a cloud environment to load and store all data. Table 4 shows the Azure HDInsight cluster setup for experimentation:
Azure HDInsight cluster setup
Head node
Worker node
Name
D3 V2 optimized
D4 V2 optimized
Number
2
2
CPU
4 vCPUs
8 vCPUs
Memory (RAM)
14 GB
28 GB
Storage
200 GB SSD
400 GB SSD
Operating system (OS)
Linux (CentOS) x64bit.
Linux (CentOS) x64bit.
Cost
$0.229/hour
$0.458/hour
The training data is used to train the model and the test data to make predictions. In order to classify the intrusions, the decision tree model of ML is used. And to predict them, a temporal analysis model “the Chronicle” algorithm is used. The experimental results carried out by the proposed system in the intrusions detection part are presented in Table 5.
Intrusion detection rate
Connexion type (CICIDS2017)
Detection rate (%)
Connexion type (UNSW-NB15)
Detection rate (%)
Normal
98.94
Normal
98.54
Brute force
98.92
Reconnaissance
98.36
DoS
98.68
Backdoor
98.65
Web
98.97
Dos
98.79
Infiltration
98.93
Exploits
98.33
Botnet
98.97
Analysis
98.92
DDoS
98.92
Fuzzers
98.52
PortScan
98.96
Worms
98.46
Fuzzing
97.94
Shellcode
97.12
MITM
98.92
Generic
98.32
SSH brute force
98.32
We present the simulation results in Table 6 below.
Detection results
Dataset
Precision
Recall
Accuracy
F1-Mesure
UNSW-NB15
98.23
98.37
98.37
97.71
CICIDS2017
98.91
98.95
98.92
98.03
CICIDS2017 shows better results than UNSW-NB15. The CICIDS2017 dataset is a newer and more comprehensive dataset than UNSW-NB15 dataset. It contains a more diverse range of network traffic, including various types of attacks, normal traffic, and benign anomalies. It also includes new types of attacks that were not included in UNSW-NB15 dataset. Additionally, the CICIDS2017 dataset contains more detailed information about the network traffic, including packet header information, flow features, and statistical features, making it easier the training of the ML model and provides better results.
The difference between detection rates and a possible explanation of why some intrusions types are quite better detected than the others, is that the decision tree algorithm has to be trained on imbalanced class distributions of both datasets. Attacks distributions of both datasets are imbalanced as shown in Figs 4 and 5, meaning one attack class has significantly more examples than the others, the decision tree may be biased towards the majority class and perform poorly on the minority class.
In the next section, we compare the classification results of the proposed contribution based on decision tree with the results of other classifiers based on SVM and KNN. The results are shown in Table 7 and Table 8.
Comparison of the proposed model with other classifiers(UNSW-NB15)
Connexion type (UNSW-NB15)
Proposed detection model
SVM based detection model
KNN based detection model
Normal
98.54
96.24
96.04
Reconnaissance
98.36
96.16
96.26
Backdoor
98.65
97.26
97.06
Dos
98.79
96.72
96.07
Exploits
98.33
96.31
97.13
Analysis
98.92
96.21
97.02
Fuzzers
98.52
96.53
96.52
Worms
98.46
97.40
96.40
Shellcode
97.12
96.12
96.09
Generic
98.32
95.23
96.12
Comparison of the proposed model with other classifiers(CICIDS2017)
Connexion type (CICIDS2017)
Proposed detection model
SVM based detection model
KNN based detection model
Normal
98.94
97.36
97.32
Brute force
98.92
98.32
98.12
DoS
98.68
97.32
97.85
Web
98.97
97.52
97.36
Infiltration
98.93
97.25
97.12
Botnet
98.97
96.58
96.87
DDoS
98.92
96.78
96.47
PortScan
98.96
97.69
97.15
Fuzzing
97.94
96.25
96.12
MITM
98.92
96.25
96.11
SSH brute force
98.32
96.89
96.97
We notice that the proposed model based on decision tree gives better results than SVM and KNN classifiers. Decision trees are a type of supervised learning algorithm that are often used for classification tasks. They work by recursively splitting the data into subsets based on the values of the input features and making decisions based on the resulting structure. SVM and KNN are also commonly used for classification tasks, but they have different underlying mechanisms. SVM tries to find the best separating hyperplane between different classes, while KNN classifies data points based on the closest k neighbors.
In this case, decision tree has performed better than SVM and KNN because they can handle non-linear relationships between features, which is important in in both UNSW-NB15 and CICIDS2017 datasets. Decision trees also handles missing data in both datasets and outliers more effectively than SVM and KNN.
Since the types of attacks generated by intrusion detection participate in the intrusion prediction, the intrusion prediction process in the proposed system is closely related to the intrusion detection process. Table 9 represents the prediction rates.
We notice that the proposed prediction model based on the Chronicle algorithm gives good results in terms of Accuracy and Precision. By incorporating time-series data, the model is able to capture the cyclical nature of the alerts and make accurate predictions. It is designed to work with large-scale time series data. The algorithm is robust and handles missing data and outliers in both UNSW-NB15 and CICIDS2017 datasets. For these reasons, the chronicle algorithm is best suited for this contribution.
Intrusions prediction rates
Connexion type (CICIDS2017)
Prediction rate (%)
Connexion type (UNSW-NB15)
Prediction rate (%)
Normal
98.92
Normal
98.52
Brute Force
98.96
Reconnaissance
98.68
DoS
97.96
Backdoor
97.56
Web
98.97
Dos
98.37
Infiltration
98.97
Exploits
98.37
Botnet
98.96
Analysis
97.26
DDoS
97.96
Fuzzers
97.56
PortScan
98.93
Worms
98.43
Fuzzing
97.92
Shellcode
97.12
MITM
98.92
Generic
98.22
SSH Brute Force
98.82
Prediction results
Dataset
Precision
Recall
Accuracy
F1-mesure
UNSW-NB15
98.43
97.87
98.87
97.91
CICIDS2017
98.91
98.15
98.92
98.63
The chronicle algorithm uses a learning rate parameter to balance exploration and exploitation. If the learning rate is too high, the algorithm may explore too much and not exploit enough, leading to inaccurate predictions. If the learning rate is too low, the algorithm may not explore enough and may miss important information, also leading to inaccurate predictions. The choice of the learning rate in this contribution was correct.
We can say that the proposed intrusion detection and prediction system is a reliable system because of the good results of detection and prediction rates. In fact, in the context of intrusion detection, the ML decision tree model gave good classification results for normal and abnormal connections. As well as the process of intrusions prediction in the proposed system where the Chronicle algorithm is used and allowing well-formed and precise plans of attacks.
Table 11 above shows spark evaluation metrics and results.
Spark evaluation metrics and results
Description
Results
Input rate
Describes how many events were loaded per second.
560, 808 Event/Second
Processing rate
Describes how many events were processed per second.
55, 175 Event/Second
To test our recommendations expert system in response to intrusions, we consider 200000 alerts from UNSW-NB15 dataset and 250000 alerts from CICIDS2017 dataset.
In order to use forward chaining, we need to have apart from the alerts which represent the system entries, a set of production rules. The production rules consist of conditions and actions. The conditions describe the intrusion type, and the actions describe the recommendations to stop the intrusion.
For both UNSW-NB15 and CICIDS2017 datasets, here are the recommendations we used for rules production for each type of intrusion [43].
Reconnaissance
Use firewalls to block unauthorized traffic and limit the amount of information that can be gathered.
Implement strict access controls and limit the number of individuals who have access to sensitive information.
Monitor and log network activity to detect suspicious behavior.
Backdoor
Install and regularly update antivirus and anti-malware software to detect and remove backdoor software.
Ensure that all software and operating systems are updated with the latest security patches.
Use firewalls and network segmentation to limit the spread of malware.
DoS
Implement network and application level DoS protection mechanisms, such as rate limiting, filtering, and intrusion prevention systems.
Use redundancy and load balancing to distribute traffic and prevent single points of failure.
Monitor network traffic for anomalies and spikes in traffic volume.
Exploits
Use vulnerability scanners to identify potential vulnerabilities and apply security patches and updates promptly.
Use intrusion detection systems and intrusion prevention systems to detect and prevent exploitation attempts.
Implement network segmentation to limit the spread of malware and exploits.
Analysis
Implement network and system monitoring tools to detect unusual activity.
Use intrusion detection systems to alert security personnel of potential security breaches.
Conduct regular security audits to identify potential vulnerabilities and develop remediation plans.
Fuzzers
Implement security testing and code review processes to identify and remediate vulnerabilities.
Use firewalls and intrusion detection systems to detect and prevent malicious traffic.
Limit access to sensitive information and data.
Worms
Use antivirus and anti-malware software to detect and remove worm infections.
Implement network segmentation and access controls to limit the spread of malware.
Use intrusion detection systems to alert security personnel of potential security breaches.
Shellcode
Implement access controls and limit the number of individuals who have access to sensitive information.
Use firewalls and network segmentation to limit the spread of malware.
Use intrusion detection systems to alert security personnel of potential security breaches.
Generic
Implement a layered security approach with multiple security controls and technologies to protect against a variety of attacks.
Conduct regular security audits and vulnerability assessments to identify potential vulnerabilities and develop remediation plans.
Ensure that all software and operating systems are updated with the latest security patches.
Brute force
Implement account lockout policies and use strong passwords that are difficult to guess.
Limit the number of login attempts and implement CAPTCHA to prevent automated brute-force attacks.
Use multi-factor authentication to add an extra layer of security.
Web
Use web application firewalls (WAFs) to protect against common web application attacks, such as SQL injection and cross-site scripting (XSS).
Use secure coding practices and input validation to prevent injection attacks.
Regularly scan web applications for vulnerabilities and apply security patches and updates promptly.
Infiltration
Use access controls and limit the number of individuals who have access to sensitive information.
Use firewalls and network segmentation to limit the spread of malware.
Use intrusion detection systems to alert security personnel of potential security breaches.
Botnet
Use anti-malware software to detect and remove bot infections.
Implement network segmentation and access controls to limit the spread of malware.
Use intrusion detection systems to alert security personnel of potential security breaches.
DDoS
Implement DDoS protection mechanisms, such as rate limiting, filtering, and intrusion prevention systems.
Use redundancy and load balancing to distribute traffic and prevent single points of failure.
Monitor network traffic for anomalies and spikes in traffic volume.
PortScan
Use firewalls to block unauthorized traffic and limit the amount of information that can be gathered.
Monitor and log network activity to detect suspicious behavior.
Implement intrusion detection systems to alert security personnel of potential security breaches.
Fuzzing
Implement security testing and code review processes to identify and remediate vulnerabilities.
Use firewalls and intrusion detection systems to detect and prevent malicious traffic.
Limit access to sensitive information and data.
MITM
Use encryption and secure protocols, such as HTTPS, to protect against eavesdropping and interception attacks.
Implement certificate validation and revocation mechanisms to prevent man-in-the-middle attacks.
Use secure authentication methods, such as multi-factor authentication, to prevent unauthorized access.
SSH brute force
Use secure passwords and limit the number of login attempts.
Implement account lockout policies and use multi-factor authentication.
Use intrusion detection systems to alert security personnel of potential security breaches.
The alerts generated by the Intrusion Detection and Prediction System are the starting point for the forward chaining algorithm. They represent the information that is already known or assumed to be true. The algorithm applies the production rules to these facts to provide the necessary recommendations.
When we have tested the generated alerts of the test datasets one by one, we found a rate of about 98% for the UNSW-NB15 dataset and 99% for the CICIDS2017 dataset of successful recommendations.
Recommendations results
Dataset
Alertes
Recommandations rate
UNSW-NB15
200000 alertes
98.6%
CICIDS2017
250000
99.2%
Recommendations rate.
The forward chaining algorithm shows good efficiency because it only considers rules that are relevant to the available data. This means that the algorithm quickly filters out irrelevant rules and focuses on the ones that are most likely to produce useful recommendations. However, the recommendations non provided by the recommender system are essentially due to the missing or incomplete data: If the generated alert is incomplete or contains errors, the front chaining algorithm can not be able to derive accurate or complete recommendations.
Discussion
The proposed method presents several advantages. It significantly enhances the efficiency of intrusion detection and prediction systems by harnessing Big Data technologies and Cloud computing, enabling the handling of large data volumes and faster calculations. Utilizing machine learning models, such as decision trees and chronicles, leads to more accurate intrusion identification and prediction. Additionally, the incorporation of an expert system for security recommendations ensures targeted and specific responses to intrusions, ultimately improving system defense and security posture while adapting to emerging threats.
However, there are some disadvantages associated with this approach. The integration of Big Data technologies, Cloud computing, and machine learning introduces complexity, demanding specialized expertise for implementation and maintenance. Moreover, these technologies can be resource-intensive, potentially leading to increased operational costs. Machine learning models require substantial amounts of labeled training data for effectiveness and tuning them to minimize false positives and negatives can be challenging. Furthermore, the accuracy of the expert system’s recommendations hinges on the quality and currency of underlying expert knowledge, which must be consistently updated and verified to maintain effectiveness.
Conclusion
In conclusion, this article has introduced a distributed machine learning-based intrusion detection and prediction system, consisting of key components: the ML decision tree algorithm for detection, the chronicle algorithm for prediction, and an expert system-based recommender for responding to intrusions. However, it is essential to acknowledge the limitations of the proposed method and outline key directions for future research.
While the proposed system offers promising advancements in intrusion detection and prediction, it is not without limitations. Firstly, the system’s performance may be influenced by the quality and availability of training data, making it essential to address data-related challenges. Additionally, the reliance on decision trees for detection may result in overfitting issues, particularly when dealing with deep trees or noisy training data. Furthermore, the current system primarily focuses on providing recommendations rather than actively countering attacks in real time, leaving room for improvement in terms of rapid response and mitigation.
To build upon this work, future research should consider several key directions. Firstly, enhancing the system’s efficiency and effectiveness can be achieved by incorporating a broader range of alert datasets and embracing Big Data fusion techniques. Implementing real-time data processing capabilities will be essential for timely threat analysis and response. Moreover, developing mechanisms for real-time attack countermeasures, such as the ability to block malicious ports or suspicious traffic, should be a priority. Lastly, addressing the overfitting issue associated with decision trees can be tackled through the exploration of alternative algorithms like random forests and gradient boosting, which offer improved model accuracy and robustness. These research directions will contribute to advancing the capabilities and reliability of intrusion detection and prediction systems in the future.
Ethical approval
The authors declare that this manuscript is original, has not been published before and is not currently being considered for publication elsewhere.
Author contributions
Farah Jemili wrote the article, and Ouajdi Korbaa revised it.
Funding
The authors declare that they have no funding.
Availability of data and materials
The datasets generated during and/or analyzed during the current study are available from the authors.
Footnotes
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
1.
Apache Spark. https//spark.apache.org/.
2.
Apache Spark: Histoire et avantages du moteur big data. https//www.lebigdata.fr/apache-spark-tout-savoir.
Hadoop storm, samza, spark et ink. https//www.codeow.site/fr/article/hadoop-stormsamza-spark-and-ink-big-data-frameworks-compared.
5.
Main concepts in pipelines. https//spark.apache.org/docs/2.2.0/mlpipeline.html. main-concepts-in-pipelines.
6.
AhmadiMR. An intrusion prediction technique based on co-evolutionary immune system for network security (coco-idp). International Journal of Network Security. 2019.
7.
BaykaraMDasR. A novel honeypot based security approach for real-time intrusion detection and prevention systems. Journal of Information Security and Applications. 2018.
8.
BijoneM. A survey on secure network: Intrusion detection prevention approaches. American Journal of Information Systems. 2020.
DesaleKSKumathekarCNChavanAP. Efficient intrusion detection system using stream data mining classification technique. ICCUBEA’15: Proceedings of the 2019 International Conference on Computing Communication Control and Automation. 2019.
11.
ElayniMJemiliF. Using MongoDB databases for training and combining intrusion detection datasets. International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing. 2017.
12.
ElshoushHTOsmanIM. Alert correlation in collaborative intelligent intrusion detection systems: A survey. Applied Soft Computing. 2018.
13.
EssidMJemiliF. Combining intrusion detection datasets using MapReduce. The 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC 2016). 2016.
14.
FakreODogduE. Intrusion detection using big data and deep learning techniques. ACM SE’19: Proceedings of the 2019 ACM Southeast Conference. 2019.
15.
GaoXShanCHuCNiuZLiuZ. An adaptive ensemble machine learning model for intrusion detection. IEEE Access. 2021.
16.
GuptaGPKulariyaM. A framework for fast and efficient cyber security network intrusion detection using Apache Spark. Procedia Computer Science. 2021.
17.
HafsaMJemiliF. Comparative study between big data analysis techniques in intrusion detection. Big Data Cogn. Comput. 2019.
18.
HsuY-FHeZTarutaniYMatsuokaM. Toward an online network intrusion detection system based on ensemble learning. 2021 IEEE 12th International Conference on Cloud Computing (CLOUD). 2021.
19.
JanarthananTZargariS. Feature selection in UNSW-NB15 and KDDCUP’99 datasets. IEEE 26th International Symposium on Industrial Electronics (ISIE). 2020.
20.
JemiliF. Intelligent intrusion detection based on fuzzy Big Data classification. Cluster Comput. 2022. doi: 10.1007/s10586-022-03769-y.
21.
KholidyHA. Attack prediction models for cloud intrusion detection systems. Proceedings – 2nd International Conference on Artificial Intelligence, Modelling, and Simulation (AIMS). 2018.
22.
KholidyHAErradiAAbdelwahedSAzabA. A finite state hidden Markov model for predicting multistage attacks in cloud systems. 2019 IEEE 12th International Conference on Dependable, Autonomic and Secure Computing (DASC). 2019.
23.
Lai-ChengC. A high-efficiency intrusion prediction technology based on Markov chain. Computational Intelligence and Security Workshops. 2020. CISW 2020.
24.
TawalbehLDarwazehNSAl-QassasRSAl DosariF. A combined decision for secure cloud computing based on machine learning and past information. Procedia Computer Science. 2019.
25.
LvSLvSYangYLiuJ. Intrusion prediction with system-call sequence-to-sequence model. IEEE Access. 2021.
26.
GandhiGM. Machine learning approach for attack prediction and classification using supervised learning algorithms. Computer Science. 2021.
27.
MoustafaN. Designing an online and reliable statistical anomaly detection framework for dealing with large high-speed network traffic. Computer Science. 2020.
28.
MoustafaNSlayJ. A hybrid feature selection for network intrusion detection systems: Central points. The 16th Australian Information Warfare Conference. 2021.
29.
MoustafaNSlayJ. UNSW-NB15: A comprehensive dataset for network intrusion detection systems (UNSW-NB15 network dataset). Military Communications and Information Systems Conference (MilCIS). 2015.
30.
MoustafaNSlayJ. The evaluation of network anomaly detection systems: Statistical analysis of the UNSW-NB15 dataset and the comparison with the KDD99 dataset. Information Security Journal A Global Perspective. 2019.
31.
OthmanSMBa-AlwiFMAlsohybeNTAl-HashidaAY. Intrusion detection model using machine learning algorithm on big data environment. Journal of Big Data. 2019.
32.
SendiASDagenaisMJabbarifarMCoutureM. Real-time intrusion prediction based on optimized alerts with hidden Markov model. Journal of Networks. 2022.
33.
VásquezJTravé-MassuyèsLSubíasAJiménezF. Enhanced chronicle learning for process supervision. 20th IFAC WORLD CONGRESS. 2018.
34.
MengXBradleyJ. ML Pipelines: A new high-level API for MLlib. https//databricks.com/blog/2019/01/07/mlpipelines-a-new-high-level-api-for-mllib.html.
35.
ZhengdaoZZhumiaoPZhipingZ. The study of intrusion prediction based on HSMM. 2008 IEEE Asia-Pacific Services Computing Conference. 2019.
36.
VandewieleGSteenwinckelBDe TurckFOngenaeF. MINDWALC: Mining interpretable, discriminative walks for classification of nodes in a knowledge graph. BMC Med Inform Decis Mak. 2020; 20: 1-15.
37.
HwangSYeoHGHongJS. A new splitting criterion for better interpretable trees. IEEE Access. 2020; 8: 62762-62774.
38.
VayreJSCochoyF. L’intelligence artificielle des marchés: Comment les systèmes de recommandation modélisent et mobilisent les consommateurs. sur cairn.info. Les Études Sociales (n∘169). 177.
39.
BenouaretI. Un système de recommandation contextuel et composite pour la visite personnalisée de sites culturels. Thèse présentée pour l’obtention du grade de Docteur de l’UTC. 2021.
40.
Common Vulnerabilities and Exposures(CVE). Retrieved from https://cvemitre.org/. 2019.
41.
ChengWShenYHuangLZhuY. Dual-Embedding based Deep Latent Factor Models for Recommendation. ACM Transactions on Knowledge Discovery from Data. 202115(5):1-24.
42.
JagtapSSWankhadeAS. Intrusion Detection and Prevention using deep learning: A Review. International Journal of Computer Applications. 2020; 177(34): 13-19.
43.
LiuYShaoCZhangL. Recommender System for Network Intrusion Detection Based on Decision Tree. Proceedings of the 6th International Conference on Computational Intelligence and Communication Networks. 2020.
JemiliF. Intelligent intrusion detection based on fuzzy Big Data classification. Cluster Comput. 2022. doi: 10.1007/s10586-022-03769-y.
47.
AbidAJemiliFKorbaaO. Distributed architecture of an intrusion detection system in industrial control systems. ICCCI 2022 14th International Conference on Computational Collective Intelligence. 2022-09.