
Abstract
Manual creation of trail maps for hikers is time-consuming and can be inaccurate. This paper presents a new method to construct trail networks based on a growing self-organizing map (GSOM) using publicly available Global Positioning System (GPS) data. Unlike other network topology construction techniques, this approach is not dependent on sequential GPS traces. Fine-tuning multiple hyperparameters enables to customize this process based on unique features of datasets and networks. The generated maps, which are trained on public GPS data, are compared to a ground truth from Open Street Map (OSM). The performance evaluation is based on the accuracy, completeness, and topological correctness of the trail maps. The proposed approach outperforms, particularly on sparse networks without significant GPS noise.
Introduction
Trail maps are topological networks that are essential for navigation [1]. Trails are made up of various path segments that may intersect at certain points. The ability to navigate these paths successfully is crucial for the safety and enjoyment of both recreational hikers and those involved in search and rescue efforts.
Trail maps are typically created by cartographers and surveyors with specialized equipment. Although these techniques generate acceptable results, they are costly and time-consuming [1].
With the emergence of cost-effective GPS recording devices such as smartphones, smart watches, etc., the development of trail maps leveraging such data has become viable.
With the rise of collaborative crowd-sourced mapping, OpenStreetMap (OSM) has emerged as a popular platform. It allows users to make edits to streets, sidewalks, trail paths, and other cartography features. However, public GPS traces uploaded by users are prone to irregularities and noise, which could affect the quality of the data. Additionally, OSM trace datasets suffer from limited geographic representation, the use of low-cost and low-quality devices, and individuals who have wandered off the established trails. Ideally, a set of user-uploaded traces would be from a heterogeneous set of GPS recording devices; however, this may not always be true, which may introduce bias.
Much work has been done using both OSM as a model for ground truth comparison as well as utilizing its public GPS data for training [2].
As GPS data often suffer from signal attenuation problems as pedestrians walk under tree cover or near buildings, algorithms using this data must be resistant to high noise traces.
This paper introduces a novel approach for trail network construction, which involves utilizing a growing self-organizing map (GSOM) and applying connection and contraction rules. This methodology is motivated by previous research that has utilized GSOMs to approximate principal curves as well as SOMs to generate road networks [3, 4]. As a method of unsupervised learning, self-organizing maps have seen recent use in identifying fault modes and diagnosis [5]. Self-organizing maps have also been embedded in a more extensive neural architecture to improve quantization and topology in latent space; these are called deep-embedded self-organizing maps [6].
[2] establishes a set of benchmark metrics for evaluating different network construction methods. These metrics include precision, completeness, and topological correctness. To evaluate their proposed method, the authors constructed networks using Kernel Density Estimation from OSM traces and reported the results of the metric evaluation. Additionally, a section of the paper will focus on comparing the performance of their approach with our proposed methods using the same dataset and benchmark metrics.
Background
Preliminaries
.
A trajectory
Many existing works utilize trajectory-based traces where GPS points are sequentially ordered [8, 1, 9, 7]. We can anonymize a trace by removing the sequential ordering of nodes. OSM anonymizes many of their public GPS traces, so we primarily utilize anonymized traces, which adds a layer of complexity to the linking step of our algorithm and a difference to many existing works. Figure 1 illustrates the process of anonymizing a GPS trajectory.
We have formally defined an
.
An anonymized trace
Since our focus is the inclusion of hiking trails and due to the nature of our construction algorithm, we present slightly different definitions of networks or maps [7]. However, the underlying structure is the same.
.
A road or trail network or (map) is a graph
Trace anonymization.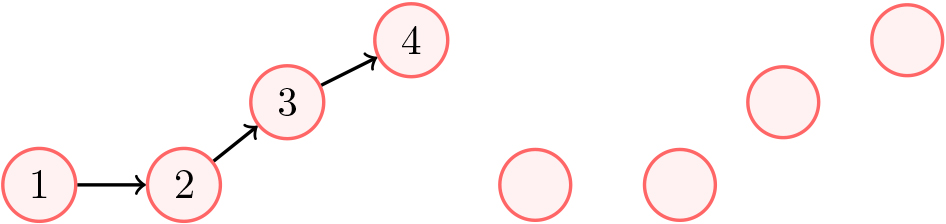
Two primary sources of data, namely GPS data or aerial imagery, are used to infer roads and trails. Although algorithms using imagery can be efficient, they often suffer from inconsistent or low-quality data sources due to high costs. Moreover, physical features such as visual obstruction and variable weather conditions can also introduce errors into the system. The authors have covered these issues in their work [10, 11]. Certain types of neural networks are used to analyze this aerial imagery for analysis of human activities [12].
However, some algorithms use GPS data recorded by mobile phones or smart watches to make road network inferences. This approach provides access to a wide range of data; however, GPS errors can lead to inaccuracies in network inference. This paper primarily focuses on this data inference source.
There are four method archetypes available for constructing road and pedestrian path networks from GPS data sources: 1. Point clustering, 2. Kernel Density Estimation, 3. Trace merging, and 4. Intersection Linking [7].
Point clustering
The main purpose of a clustering algorithm is to create a representative collection of data points from the input dataset that accurately describes the fundamental geometry. In order to determine the positions of these representative nodes, K-means was utilized. However, in this paper, a GSOM approach was adopted, which is analogous to K-means. Usually, Vincenty distances (for longitude and latitude coordinates) or Euclidean are employed to measure the distance. Once the set of representative nodes is established, a linking step is carried out to create the topology of the network [9]. The techniques used for creating edges between nodes differ depending on the approach. An approach that leverages trajectory-based GPS traces, that are not anonymized, involves utilizing information from these traces to establish connections between the nodes. For instance, the angle of the heading contained within the GPS trajectories can be utilized to establish edges [13].
The algorithm outlined in this paper is a type of point clustering approach that incorporates a novel component to use anonymized traces.
[4] employs a GSOM to generate a map of roads based on satellite imagery. The nodes of the map are created by neurons that adapt to the varying colors of a road in contrast to its background, while the edges are created through pattern matching. The final step matches the structure of the map to the templates.
Kernel density estimation (KDE)
In KDE approaches, it is common practice to create a function of traces based on probability density as the first step. To visualize the data, an image is created based on pixel value of each intersection of traces. In the next step, outliers and errors are discarded by using a threshold. Then the outlines of road line are calculated using various methods, such as Voronoi diagrams. Once the road outlines are computed, intersections are extracted from them. This process finalized the generated road network [9].
In [14], a KDE approach using point clustering algorithm was proposed to create walking paths using filtered trajectories.
In a typical KDE algorithm, trajectory information is used to create a histogram that is used to produce the discretized image. Though it is possible to adapt many of these algorithms for anonymized traces, performance may vary.
Trace merging
Trace merging approaches are a unique type of algorithms that aggregate trajectories into a network that grows continuously. The process involves aading new traces to the network incrementally. If there is no overlap between the new trace and the network, the added trace will be completely included in the net work. If any overlap exists, the edges’ weights will be adjusted in those parts of the network. In this process, the constraints of the existing network should be met to ensure that the system is actively learning [9].
Most known examples are variations on this fundamental idea. [15] instead of presenting trajectories one at a time, creates clusters of sub-trajectories, which are then iteratively presented to the existing network.
As these approaches require explicit traces, they cannot be applied to anonymized traces.
Intersection linking
This technique first identify intersections and then link these crossings based on trace data [7]. In [8], to determine the intersections, the turning changes are utilized.
The process involves extracting points from input traces that correlates with changes in the turning (heading) or speed. Then the created data points are clustered to form one intersection point for each cluster, link these cluster intersection points using trace data that crosses multiple intersections.
This process relies heavily on the proper identification of intersections. It also requires information from a trajectory, such as heading and speed, and could not be used for anonymized traces.
GSOM method
Our Growing Self-Organizing algorithm has a structure that is analogous to many point clustering techniques, consisting of a two step approach to identify points, followed by a linking process. However, what sets our algorithm apart from many common methods is the utilization of anonymized trajectories. This approach allows us to use public GPS data to be used in the analysis.
Methodology
The main component of this approach is the utilization of a GSOM, which is a type of self-organizing map (SOM) that functions as a neural network. For a given dataset, a data point is fed into the SOM, and one neuron is selected as the winner. The GSOM then employs a weight adjustment that includes the winning node and some neighboring nodes based on a threshold distance.
The GSOM has the ability to expand its number of neurons dynamically. This means that when a new data point is fed to the GSOM and it is not adequately represented by the existing neurons, the algorithm can create new neurons to better capture the characteristics of the data.
This process involves five major steps: initialization, growth and learning, connection rule, collapsing, and smoothing.
Methodology overview.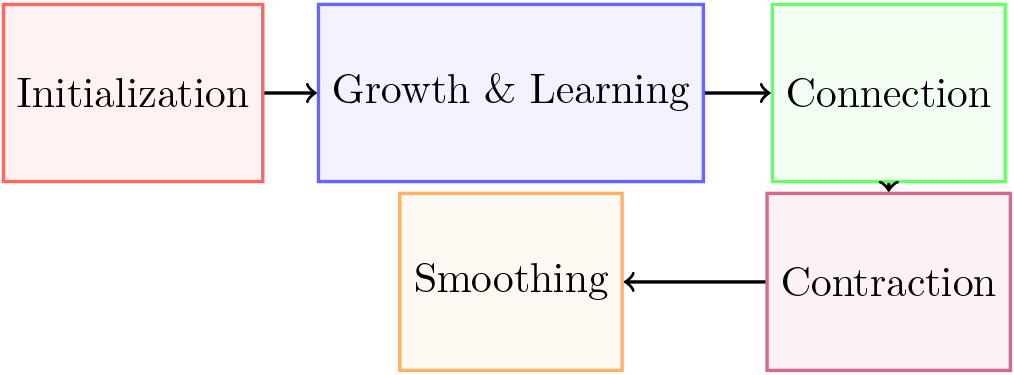
To initialize the GSOM, the weights of three nodes are randomly selected from the points in the dataset.
The spread factor
The following algorithm is performed on the dataset to remove points that do not have sufficient density. This was commonly caused by a single off-trail trace.
In this segment of the algorithm, the process involves learning, which includes adapting weights and generating new neurons. The network
Algorithm 3.2 describes the learning and growing phase in our approach. The terminal condition is reached when there are no changes in the weights.
Competitive learning is an essential aspect of all self-organizing maps. During this process, the system computes the distance to the datapoint Eq. (2), and then selects the neuron that has the smallest value as the winning node. In Fig. 3, the distances between datapoint
Finding winning neuron.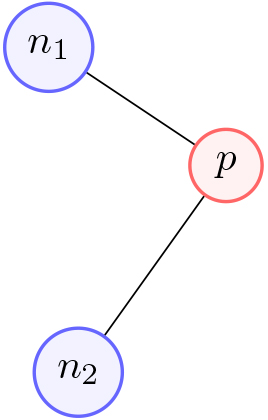
To find a winner using brute force, it requires
As we expand the map, additional neurons are incorporated into scale
Hence, this approach typically requires
Adapting weights is another essential characteristic of Self Organizing Maps. In this process, the weights are adjusted for all nodes within a certain distance from the winning node, which is determined using the weight adaptation rule outlined below. Figure 4 shows that neuron
Neighborhood.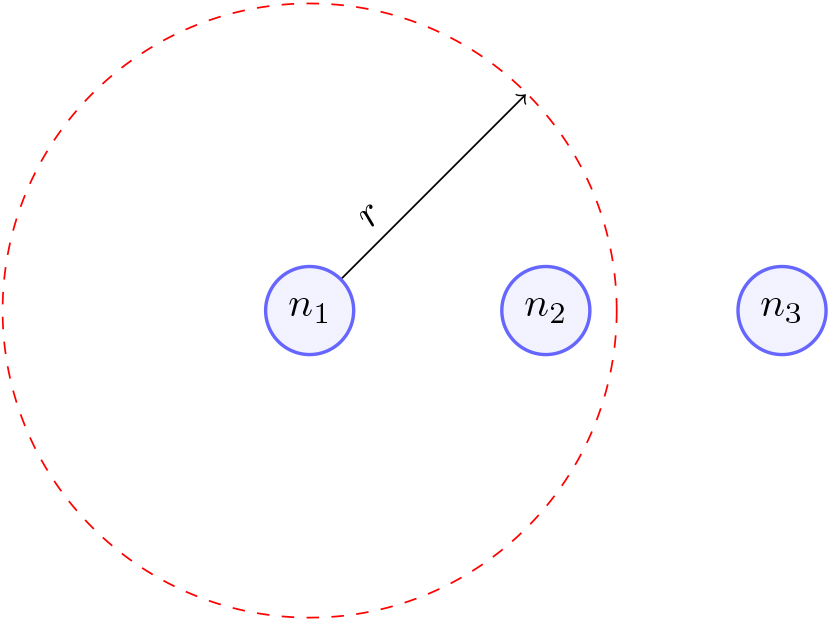
As can be seen in Algorithm 2, line 9, the iteration value
Where
Here,
If the error exceeds the growth threshold, it indicates that the data point is not adequately covered within a specific radius of a neuron. Thus, we generate a new neuron and assign its weights to the corresponding data point.
At first,
Once the node growth phase is completed and the terminal condition is reached, we apply the connection rule. We present each datapoint
As Fig. 5 shows, neurons
Connection rule.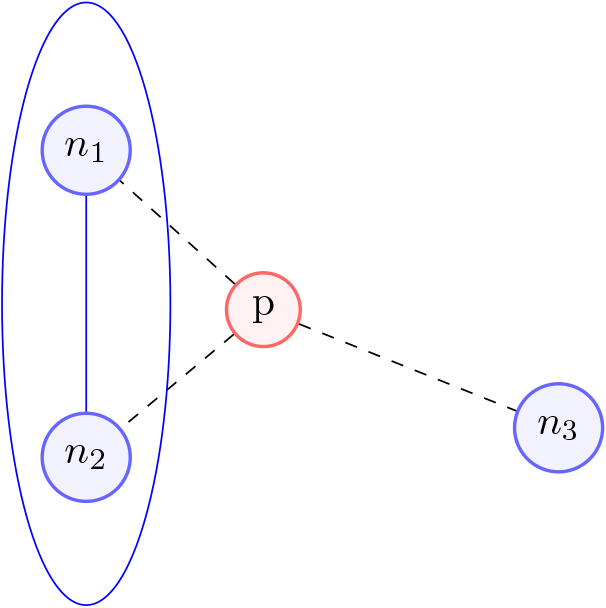
Node collapse.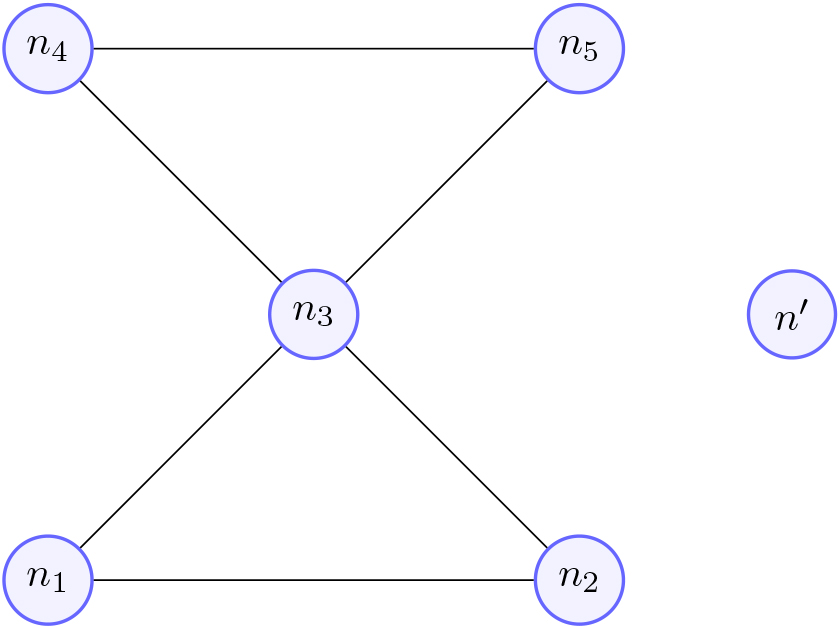
In order to determine the path connections between nodes, this rule utilizes the proximity of datapoints to nearby neurons. This guarantees a level of locality between two nodes with respect to other nodes. However, the rule does not take into account angle information, which could potentially enhance performance accuracy.
As this method tends to add an excess of edges, it can inadvertently lead to the creation of false triangular sub-graphs. To address this issue, the triangles are merged into a single point during this particular step.
To begin the process, we first list out all the nodes that form a triangle and then sort them based on their degree (i.e., number of edges). Then, the triangles that contain the node with the highest degree are collapsed iteratively. Assume there are neurons
Here,
Once the network has been contracted enough to eliminate triangular edges, it undergoes a weight adaptation phase. This phase is similar to the learning and growing step, but new growth is not permitted.
To accommodate newly contracted nodes in finding a general area they belong to, we increase the initial neighborhood size by two-fold. Following this, we apply the learning phase for a total of 50 iterations.
Subsequently, we reduce the neighborhood to half of the initial size to accurately position each node in its optimal location. This process is performed for each data point for a total of 20 iterations.
Results and comparison
When this method was created, it was meant for trail networks primarily. However, it is still important to compare its capabilities with existing approaches. Hence, we compared and evaluated our network with the Kernel Density Estimation (KDE) approach and the OSM datasets. These datasets are comprised of five different networks of GPS traces, as outlined in [2].
In order to evaluate different network construction techniques, benchmark metrics are designed by [2] including precision, completeness, and topological correctness. They have utilized Kernel Density Estimation from OSM traces for network construction and have reported the evaluation results. Our paper also includes a comparison of our method’s performance on these metrics using the same dataset.
To ensure the most accurate comparison of methods, we create and train a network for each GPS trace provided. Next, we calculate the precision, completeness (comp), and topological correctness (topo) metrics presented in Table 1, using the ground truth geometry as a reference.
Metrics
Segments
We utilize
Figure 7 presents us with a straightforward graph. The graph is divided into segments based on color, which is visible on the right. It is notable that when the orange nodes are connected to a segment, they are part of that segment. In total, this simple graph comprises six segments.
Moreover, it is essential to mention that every node in this graph is a shape point. The algorithms will denote it as
Segments.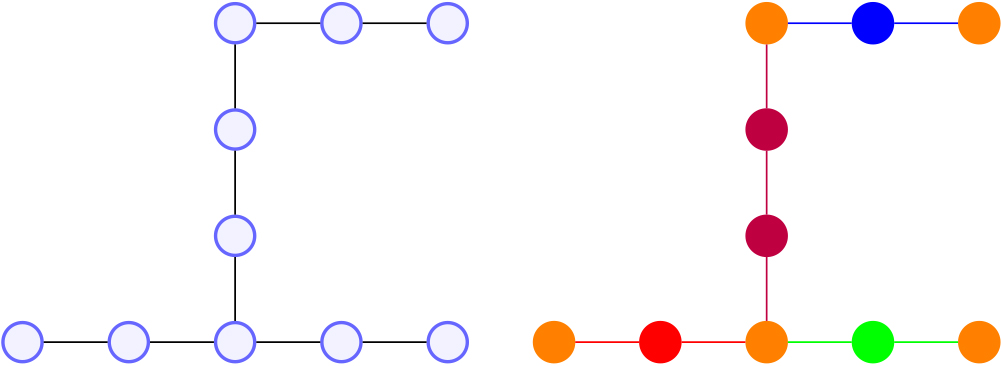
When the completeness function calculates the percentage of the segments that match the ground truth network, without taking into account the accuracy of the matched segments.
We briefly describe the pseudo-code in Alg. 4.1.2.
We work with two main parameters:
Precision
The precision function provides the mean distance of all matched segments, along with the standard deviation across all of the matched segments.
We describe a pseudo-code of this algorithm in Alg. 4.1.3. Similar to the completeness function, we iterate through each segment in the built network and search for the nearest segment in the ground truth network. At each shape point along the segments, we determine the distance and sum them up. This sum is then added to an overall precision array. Finally, we report the average distance across the entire array.
These scores give us an understanding of how erroneous the matched segments from the previous metric might be.
Topological correctness
To quantify the level of connection between the constructed and the ground truth networks, we use the topological correctness metric. We deploy the Floyd-Warshall algorithm to both the constructed network’s adjacency matrix
Floyd-warshall.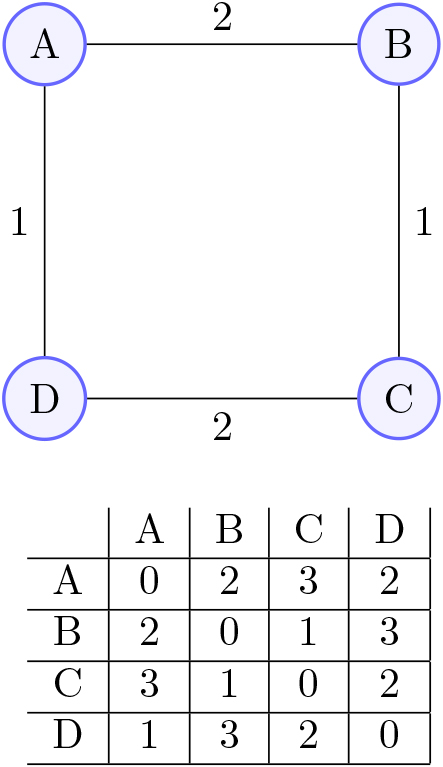
Metrics across various spread factor values.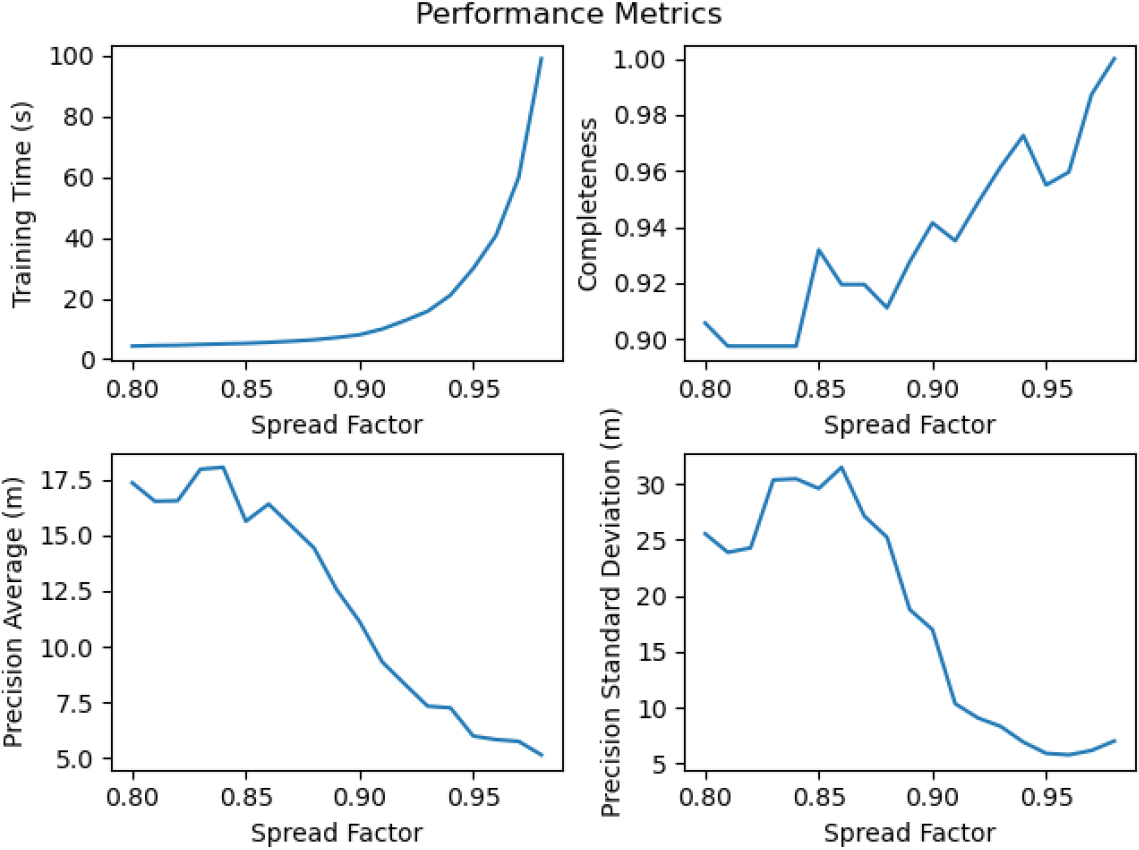
The Floyd-Warshall algorithm finds all pairs’ shortest path for a weighted graph [18]. In many implementations, this will be a matrix whose elements are the total path cost from one vertex to another. Then, we calculate the average of each returned matrix and generate the quotient. In Fig. 8, we demonstrate a simple example of the Floyd-Warshall algorithm on a graph with its result below.
A portion of a constructed network from trace 1 at SF 
In
An important consideration for the production of these networks is the choice of the SF. For a consistent way to choose a spread factor, we trained the network on each trace at spread factors from 0.80 to 0.99 at 0.01 intervals and analyzed the result graphs. Looking at Fig. 9, we see there is a time blow-up that occurs at SF
In Fig. 11, you can see the performance of our proposed approach based on the dataset from [2], comprising of different network traces. In Table 2, we see the individual metrics produced by our method and the difference to the reference data.
Considering the distinctive features of each network, we evaluate and compare the performance results across a network of traces. We can see some of the features in Table 1.
GPS traces networks
GPS traces networks
Performance comparison with [2] with different network traces. The error results indicates the precision of the evaluated approach.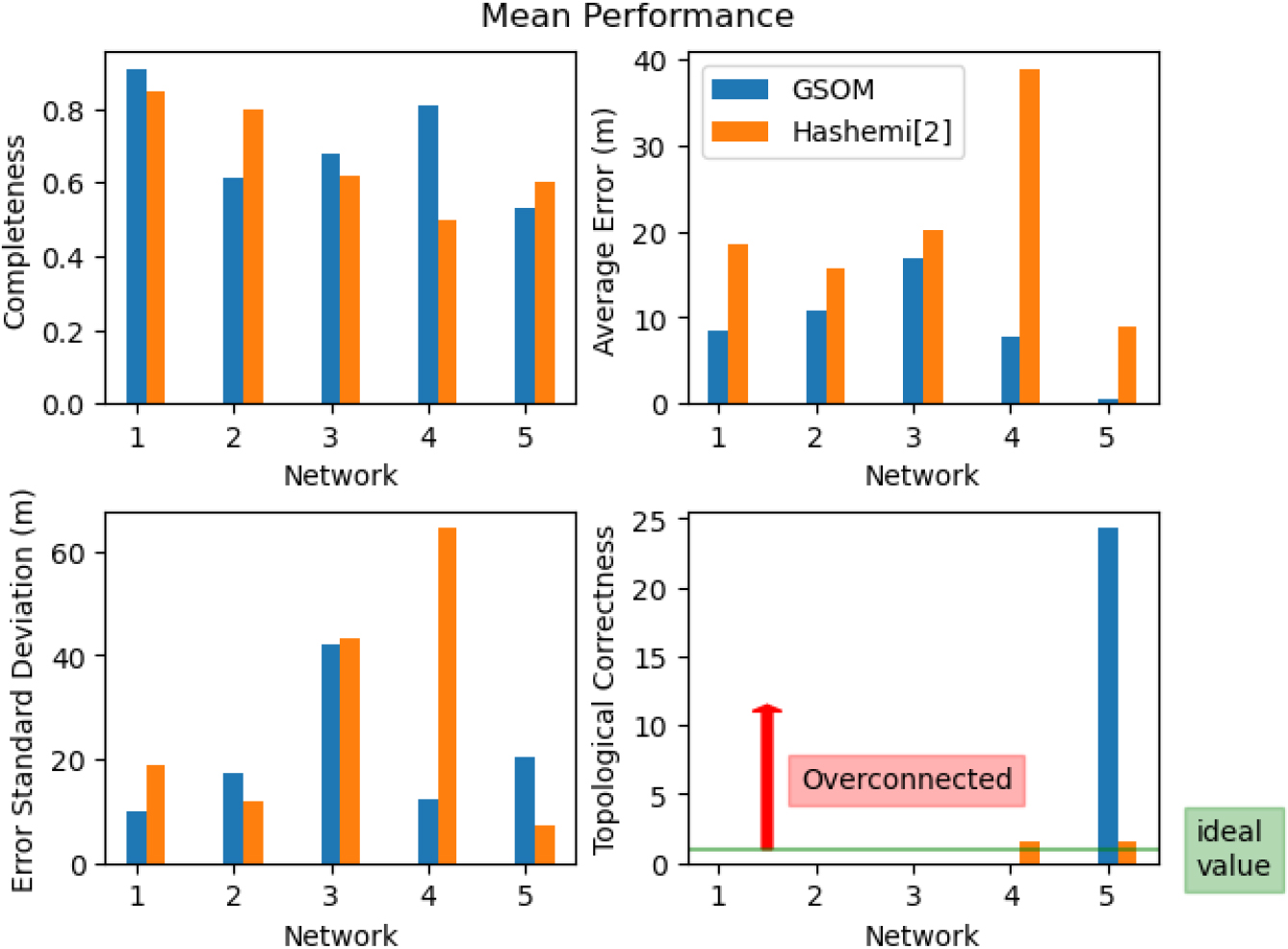
GPS traces networks
Network traces.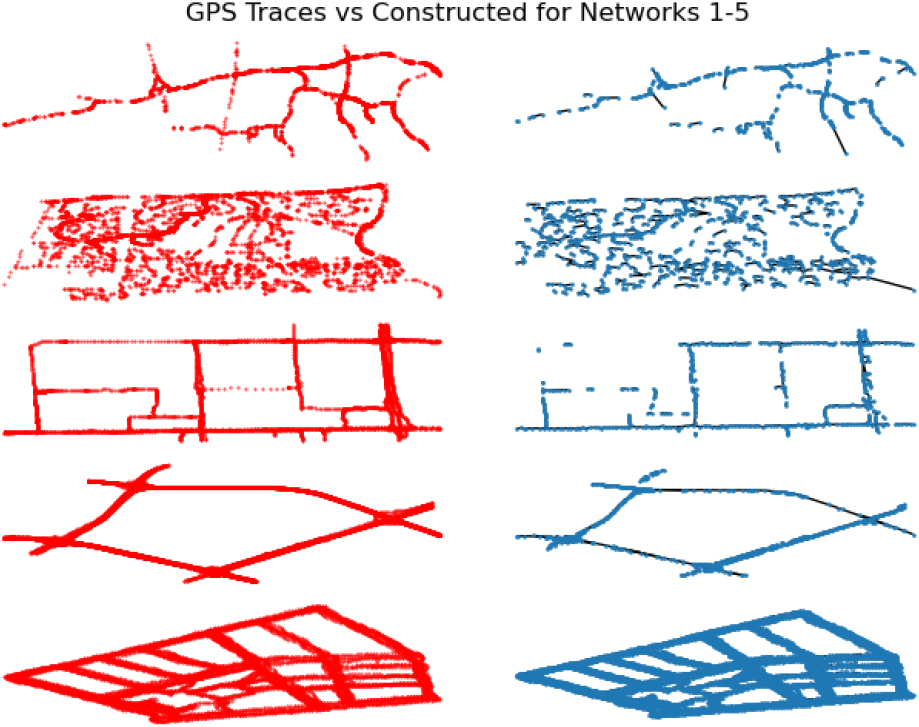
In comparison of our proposed GSOM approach to Hashemi’s KDE technique, we have observed superior overall performance for networks 1, 3, and 4. In addition, we have also improved some metrics of networks 2 and 5. In addition, Hashemi’s KDE approach could not for a network on multiple trajectories in the aforementioned networks, as indicated by NA (See Table 1). On the other hand, our approach constructs these networks, albeit with lower accuracy levels in many of the metrics, compared to the other traces from that network set. This contributes to a lower average performance for our approach.
In general, our approach demonstrate consistent superiority in terms of completeness, precision, and standard deviation precision. However, our GSOM method falls short in terms of topological correctness with 0 results for four of the networks, indicating at least one connection in the constructed network in missing.
Although the KDE technique shows three networks that have a topological correctness of zero, the other two have an acceptable score near one, which is the ideal value. On the other hand, our method has a non-zero score on one network, but the average score is 24.32, implying that it generates an excessive number of connections.
In network 1, we see an improvement in all metrics. Notably, this network features the lowest density at two nodes per km2 with a total length of 32,245 meters. The average times to perform our algorithm ranged from 2.34 seconds to 10.11 seconds.
In network 2, there is a moderate decrease in completeness but an improvement in average precision. However, with a worse standard deviation, a few segments were much more erroneous than most. Interestingly, this network has the second highest density, with 55 nodes per km2 and a total length of 56,669 meters.
Again, we see an improvement in every category for network 3, with slightly improved completeness and smaller errors in precision. With a density of 9 nodes per km2 this network is among the most sparse in these datasets. The total length is also similar to network 1 at 34,595 meters.
With network 4, there is an improvement in completeness and precision. However, our method fails to produce a non-zero value for topological correctness, while the KDE method does. Among the lowest densities at 3 nodes per km2, this network is the longest at a total length of 73,380 meters.
Lastly, for network 5, our method does produce slightly worse completeness values. Our average precision is much lower; however, the standard deviation is much higher, which indicates that a small percentage of our constructed segments were highly inaccurate, but most were more precise. This network has the most unique characteristic, with the highest density of 508 nodes per km2 and a total length of 11,695 meters. So this is a much smaller network in scale but with the highest total number of nodes at 151.
In sum, compared to the existing technique [2], our proposed method provides better average error and topological correction across all networks and better completeness and error standard deviation in most cases. However, the evaluation results indicate that our proposed approach works best in low-density networks and provides comparable and, in some cases, worse results in high-density networks.
Our paper introduced a new approach for building trail maps that performs similarly to the state-of-the-art methods. We evaluated the performance using various metrics that are now widely used as a standard in this field. It is worth noting that these standardized metrics are fairly new and in the past, many techniques were published using different testing methods, making it challenging to compare the results.
Based on the results, it is evident that this method has yielded encouraging outcomes. In comparison to previous techniques like KDE, we have observed improvements in trace analysis of several networks. Moreover, this method surpasses the current methodology in constructing trail maps, which was our original objective.
The main advantage of this work is the utilization of anonymized traces, allowing application to datasets that have been privatized. Reducing each iteration to scale linearly with input size is a major speed-up that allows the method to be used on even larger datasets. However, it faces challenges with edge prediction in densely geographic networks.
Future research may aim at enhancing edge prediction through more robust similarity metrics.