We propose point estimators for the three-parameter (location, scale, and the fractional parameter) variant distributions generated by a Wright function. We also provide uncertainty quantification procedures for the proposed point estimators under certain conditions. The class of densities includes the three-parameter one-sided and the three-parameter symmetric bimodal -Wright family of distributions. The one-sided family naturally generalizes the Airy and half-normal models. The symmetric class includes the symmetric Airy and normal or Gaussian densities. The proposed interval estimator for the scale parameter outperformed the estimator derived in Cahoy (2012) when the location parameter is zero. We obtain the asymptotic covariance structure for the scale and fractional parameter estimators, which allows estimation of the correlation. The coverage probabilities of the interval estimators slightly depend on the proposed location parameter estimators. For the symmetric case, the sample mean (or median) is favored than the median (or mean) when the fractional parameter is greater (or lesser) than 0.39106 in terms of their asymptotic relative efficiency. The estimation algorithms were tested using synthetic data and were compared with their bootstrap counterparts. The proposed inference procedures were demonstrated on age and height data.
The -Wright function has been increasingly gaining popularity from several areas of study particularly in mathematics, engineering and physics. It is often a probability density function in space which solves time-fractional diffusion processes (see Mura et al., 2008). As a solution, the -Wright density naturally models the increments or the ‘space’ component of the above processes at any given time. It is also used as a subordinator (as the operational time rather than the physical time) for time-fractional differential equations (Pagnini and Scalas, 2014), for a multi-point probability model of the generalized grey Brownian motion that includes the well-known standard and fractional Brownian motions, and for pure linear birth processes (see Beghin and Orsingher, 2010; Cahoy and Polito, 2012). The single-parameter positive-sided -Wright function takes the following form:
where , and is the fractional parameter. The last equality in the preceding equation follows from the reflection formula for the gamma function
and transformation We have the exponential density as a limiting case and the Airy () and half-normal () (see Mainardi et al., 2010) distributions as special cases where
Moreover,
where is the generalized Dirac function. The Laplace transform of Eq. (1) is
which is the Mittag-Leffler function. The positive-sided -Wright random variable has the structural representation
where follows an -stable distribution (Zolotarev, 1986) with . The th moment (see Piryatinska et al., 2005) is known to be
giving the mean and variance as
correspondingly. The coefficient of variation is straightforward to calculate as
The rest of the paper is organized as follows. The one-sided -Wright density, its properties, and test results are presented in Section 2. The extension to the symmetric case are in Section 3. The applications and concluding remarks are given in Sections 4 and 5, respectively.
One-sided M-Wright distribution
The three-parameter one-sided -Wright density function has the following form:
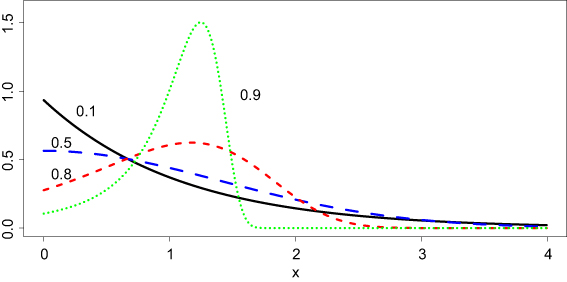
where and are the shift and scale parameters, respectively. Below are some forms of the densities in this family.
The one-sided -Wright density for .
Case 2.1:
If then
Given and applying the log transformation to the absolute value of the random variable given in Eq. (9), we obtain
where , and . From Cahoy (2012), the mean and variance are
respectively, where is the Euler’s constant. Moreover, the following point estimators of and are obtained:
Proposition 1. Let . Then
where
and is the Riemman zeta function.
Proof Recall the following key results in Cahoy (2012): Let Then the third and fourth central moments are
respectively. In addition, if and then it is widely known that
as , where the variance-covariance matrix is defined as
, and are given in Eqs (11) and (16). Using result Eq. (17) and the multivariate delta method,
where is a continuous mapping from given as
and is the gradient matrix given by
Note that the covariance structure of the scale and fractional parameter estimators given by above allows estimation of the correlation.
Corollary 1. Let . The 100% confidence intervals for and can be approximated as
and
correspondingly, where is the th quantile of the standard normal distribution, and .
Proof Immediately follows from Proposition 1 and is omitted. ∎
We tested our estimators by simulating the bias (), the median absolute deviation (MAD), and the 95% coverage probabilities for the proposed methods and the bootstrap percentile counterparts (with ‘*’) corresponding to several parameter combinations. Table 1 suggests that bias is as large as 5% and as little as 0.21% when . Reduction in variability is also apparent as the sample size goes large. It can be seen that the smaller the parameter , the slower the reduction in variability and bias regardless of the sample size. Nevertheless, we conclude that these point estimators are consistent and asymptotically unbiased. Table 2 reveals that the proposed interval estimator of the scale parameter quickly captured (e.g., 100 and ) the true nominal level than the one in Cahoy (2012) as the sample size goes large. Furthermore, Table 2 illustrates that the large-sample interval estimator outperformed the percentile bootstrap method for estimating especially when 1000. Note that the large-sample formula is faster to calculate than the resampling-based method especially for large sample sizes.
Mean estimates of and dispersions from the true parameters , and
% Bias
% MAD
% Bias
% MAD
% Bias
% MAD
(0.4, 150)
32.796
31.795
16.143
19.346
4.706
5.922
7.899
9.806
3.266
3.854
0.936
1.158
(0.6, 8.77)
17.443
19.959
5.852
7.176
1.887
2.325
6.437
7.648
1.955
2.435
0.641
0.809
(0.8, 375)
7.842
9.505
2.513
3.051
0.763
0.935
4.423
5.273
1.351
1.706
0.408
0.502
(0.95, 1000)
2.871
2.686
0.924
1.147
0.294
0.359
2.329
2.769
0.687
0.838
0.213
0.268
Coverage probabilities of 95% interval estimates for different values of , and
100
1000
10000
(0.4, 150)
0.917
0.952
0.956
0.941
0.957
0.949
0.884
0.928
0.950
0.942
0.941
0.947
(0.6, 8.77)
0.950
0.950
0.953
0.949
0.958
0.951
0.873
0.931
0.944
0.943
0.954
0.950
(0.8, 375)
0.964
0.950
0.954
0.942
0.958
0.952
0.831
0.925
0.948
0.935
0.954
0.948
(0.95, 1000)
0.960
0.922
0.952
0.902
0.948
0.950
0.724
0.888
0.931
0.922
0.948
0.947
Case 2.2:
Consider the location-scale structure
Proposition 2. Let in (23). A 100% confidence interval for the shift parameter is
where is the th quantile of and .
Proof Note that
which suggests that
For reproducibility, we estimate by generating random variates from and use the approximately median-unbiased (type 8 of the quantile function in R) estimator to calculate the th quantile as recommended by Hyndman and Fan (1996). Note also that we directly use the point estimators obtained in Case 2.1 after subtracting from the observed data.
Upon testing, Table 3 generally indicates similar observations and conclusions about the estimators of and as in Table 1. The mean and dispersion of seem to be large when . Overall, the proposed point estimators are consistent. In addition, Table 4 shows that the proposed interval estimator for seems to capture the true nominal rate even when the sample size is as small as 100 with . Comparing Tables 3 and 4 with Tables 1 and 2, correspondingly, reveals that the variability induced by the subtraction of the minimum from the data does not seem to seriously affect the performance of the proposed estimators.
Mean estimates of and dispersions from the parameters , , and
100
1000
10000
% Bias
% MAD
% Bias
% MAD
% Bias
% MAD
(0.4, 150, 78)
32.459
31.174
16.026
19.658
4.919
6.116
7.706
9.732
3.060
3.559
0.949
1.201
2.032
2.055
0.220
0.221
0.022
0.023
(0.6, 8.77, 25.2)
17.258
18.863
6.017
7.427
1.871
2.358
6.737
8.896
2.012
2.487
0.613
0.761
0.587
0.599
0.060
0.056
0.006
0.006
(0.8, 375, 375)
7.597
8.491
2.716
3.407
0.821
1.051
5.092
5.777
1.374
1.681
0.429
0.550
3.521
3.404
0.333
0.331
0.036
0.036
(0.95, 1000, 500)
2.971
2.926
0.940
1.147
0.309
0.397
13.693
11.921
1.946
1.710
0.297
0.317
6.936
6.890
2.764
2.690
0.296
0.278
Coverage probabilities of 95% interval estimates for different values of , , and
100
1000
10000
(0.4, 150, 78)
0.921
0.945
0.947
0.944
0.961
0.956
0.951
0.953
0.947
0.952
0.967
0.954
0.962
0.951
0.945
(0.6, 8.77, 25.2)
0.955
0.955
0.952
0.931
0.954
0.958
0.976
0.968
0.963
0.940
0.956
0.958
0.943
0.946
0.949
(0.8, 375, 375)
0.966
0.940
0.947
0.865
0.946
0.951
0.980
0.971
0.953
0.887
0.945
0.952
0.911
0.952
0.949
(0.95, 1000, 500)
0.963
0.947
0.949
0.945
0.957
0.951
0.996
0.963
0.966
0.931
0.959
0.934
0.907
0.941
0.947
Symmetric M-Wright distribution
Replacing by in Eq. (1) and dividing Eq. (1) by two, the three-parameter symmetric -Wright density can be written as
where and are the location and scale parameters, respectively. The Laplace or double exponential is a limiting case while the Gaussian or normal () (see Mainardi et al., 2010) distributions are special cases. Moreover,
where ‘’ means independent.
Case 3.1:
The -Wright function in two variables that is centered at zero satisfies the following transformation:
When , we get the Gaussian density
with mean zero and variance . It is easy to show that
The preceding result allows us to estimate the parameters of the two-sided symmetric -Wright distribution using the properties of its one-sided non-symmetric counterpart. Furthermore, the formula for the integer-order moments of the symmetric two-parameter -Wright distribution centered at zero can be deduced as
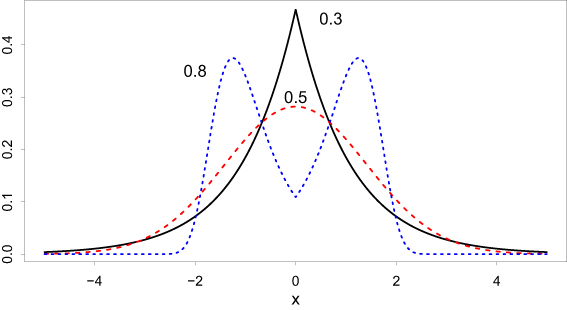
For completeness, we reproduce Fig. 3 from (Cahoy, 2012b) to emphasize the flexibility of the symmetric single-parameter -Wright density.
The symmetric -Wright density for 0.3, 0.5, 0.8; 1, 0.
The asymptotic relative efficiency of to as a function of .
Proof Directly follows from the standard large sample results for mean and median of random samples. ∎
Thus, the asymptotic relative efficiency of to is
Figure 3 displays the asymptotic relative efficiency of to as a function of .
The relative efficiency above equals unity if 0.39106. Thus, the sample mean is used for 0.39106. Otherwise, the sample median is preferred when 0.39106 for relatively large samples.
Corollary 2. Let in Eq. (31). From Proposition 3, the approximate mean-based % confidence interval for is
while the approximate median-based % confidence interval for is
Proof Directly follows from the central limit theorem and the asymptotic normality of the sample median. ∎
Subtracting from the data and getting the absolute values allow us to use the estimators of and from the preceding section.
For testing purposes, we used the sample mean as the location parameter estimator as values are chosen to be at least 0.4. Table 5 suggests negligible increase (due to the variability induced by subtracting the mean from the data) in both bias and MAD for the proposed point estimators of and in comparison with Table 1 () as .
Mean estimates of and dispersions from the true parameters , , and
100
1000
10000
% Bias
% MAD
% Bias
% MAD
% Bias
% MAD
(0.4, 150, 78)
33.282
31.708
15.402
16.742
4.841
6.076
7.821
9.771
2.928
3.365
0.958
1.233
21.865
26.410
6.842
8.610
2.237
2.868
(0.6, 8.77, 25.2)
17.082
20.509
6.114
7.422
1.959
2.536
6.272
7.587
1.895
2.311
0.620
0.792
3.691
4.536
1.136
1.389
0.387
0.494
(0.8, 375, 375)
8.427
9.125
2.551
3.186
0.837
1.027
4.479
5.532
1.328
1.636
0.435
0.559
9.361
11.389
2.980
3.818
1.000
1.306
(0.95, 1000, 500)
2.841
2.822
0.958
1.192
0.310
0.382
2.536
2.927
0.695
0.885
0.217
0.271
16.765
21.059
5.311
6.961
1.657
2.053
We also tested the proposed interval estimators and compared with their bootstrap counterparts (using percentile method). From Table 6, the large-sample interval estimator for outperformed its bootstrap counterpart especially when .
Coverage probabilities of 95% interval estimates for different values of , , and
(0.4, 150, 78)
0.906
0.956
0.951
0.958
0.960
0.957
0.940
0.955
0.955
0.859
0.929
0.943
0.939
0.957
0.947
0.946
0.955
0.958
(0.6, 8.77, 25.2)
0.956
0.955
0.953
0.942
0.947
0.955
0.952
0.956
0.952
0.887
0.938
0.939
0.962
0.948
0.955
0.95
0.949
0.954
(0.8, 375, 375)
0.969
0.959
0.945
0.924
0.954
0.958
0.940
0.953
0.945
0.862
0.941
0.944
0.944
0.949
0.954
0.939
0.948
0.943
(0.95, 1000, 500)
0.976
0.955
0.950
0.891
0.950
0.953
0.943
0.954
0.953
0.781
0.908
0.942
0.910
0.953
0.951
0.953
0.951
0.949
Applications
We apply our methods on two real datasets that are available online (used in some researches) using the statistical software R. R codes are also available upon request through dcahoy@latech.edu.
Ages of major league baseball players
We consider the ages (in years) of 826 Major League Baseball (MLB) players. The data was downloaded from the Statistics Online Computational Resource (SOCR) database (see http://wiki.stat.ucla.edu/socr/index.php/SOCR). The one-sided -Wright fit to the data yields the point and interval estimates in Table 7. The minimum age of these players tends to be around 25 years old. The confidence interval estimate of the fractional parameter excludes the exponential () and the Airy () distributions but includes the half-normal () model. Using the asymptotic bivariate results in Section 2, the correlation between and can be easily estimated as 0.989, which indicates a strong inverse linear relationship.
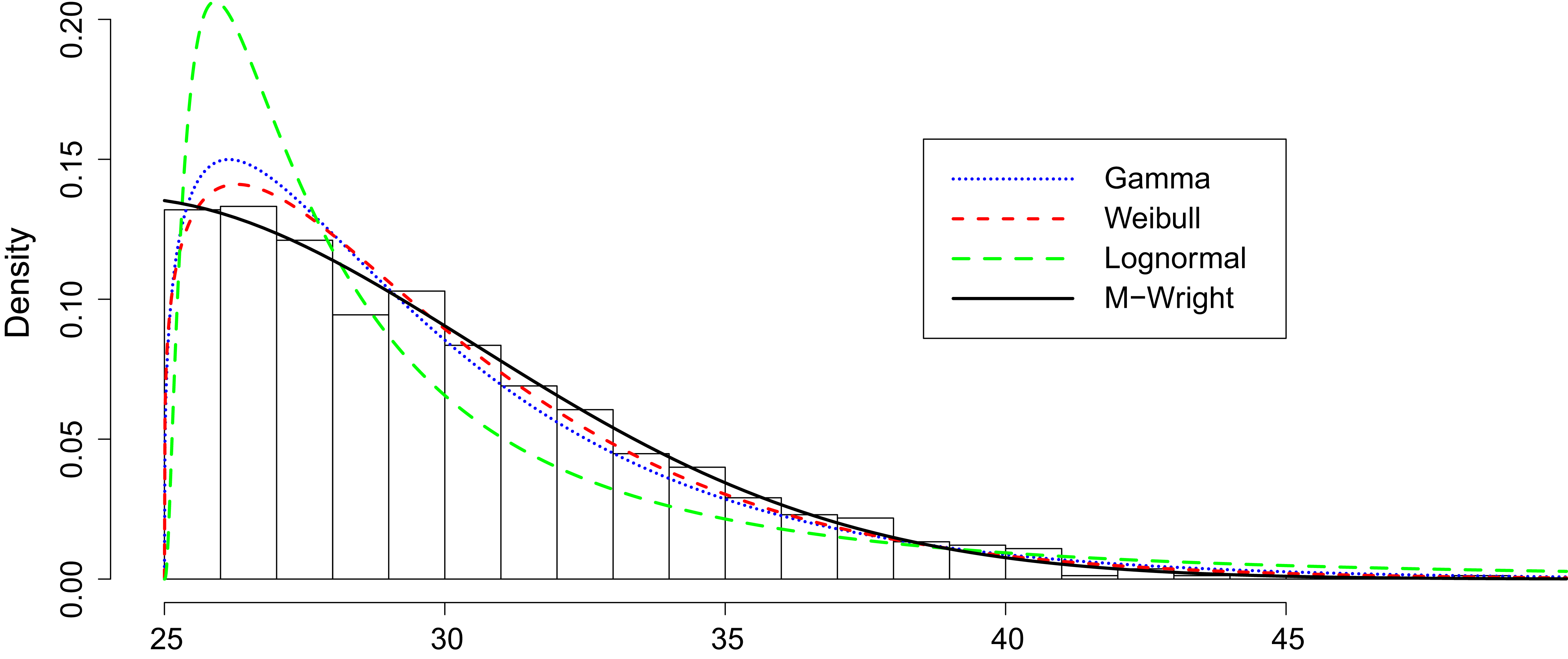
The two-sample Kolmogorov-Smirnov method (using R) was also used to test the fits of 100 simulated data sets (of same size with the observed data) using the parameter estimates. The average -value (0.841) indicated a reasonably good fit. The succeeding figure demonstrates the -Wright fit to the SOCR MLB age data with the maximum likelihood fits of gamma(shape=1.2994, rate=0.2605), Weibull(shape=1.2177, scale=5.3071) and lognormal(meanlog = 1.1752, sdlog=1.1292) distributions. By visual inspection, the one-sided -Wright distribution seems to provide the best fit. The picture also suggests that the one-sided -Wright had the flexibility to model data populations which have an inflection point (e.g., : half-normal) with mode at the origin or minimum and their variants corresponding to It can also be checked that at the origin, the height is
Human height and weight
The dataset contains 25000 records of human heights (in inches) and can be downloaded from the SOCR website. These data were obtained in 1993 by a Growth Survey of 25000 children from birth to 18 years of age recruited from Maternal and Child Health Centres (MCHC) and schools, and were used to develop Hong Kong’s current growth charts for weight, height, weight-for-age, weight-for-height and body mass index (BMI). Below are the corresponding point and 95% interval estimates for the three parameters. We used the sample mean as the point estimator as is greater than the cutoff value of 0.39106 above. The interval estimate seems not to favor the double-exponential and normal or Gaussian densities to likely model the distribution of the children’s heights. The estimate of the correlation between and is 0.613, which indicates moderate negative association.
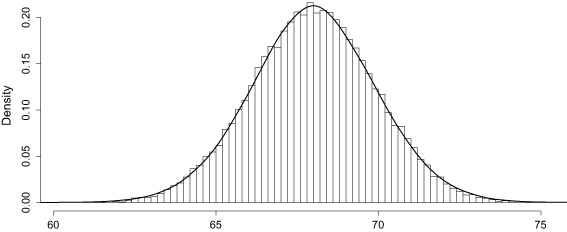
The two-sample Kolmogorov-Smirnov method (using R) was again used to test the fits of 100 simulated data sets (of same size with the observed data) using the parameter estimates above. The average -value (0.586) indicated a reasonably good fit to the data. The following figure demonstrated the fit of the model to the SOCR height data.
Estimates for , , and
Parameter
Point estimate
95% Confidence interval
25.020
(24.960, 25.020)
0.473
(0.338, 0.607)
4.390
(4.094, 4.686)
Estimates for , , and
Parameter
Point estimate
95% Confidence interval
67.993
(67.969, 68.017)
0.481
(0.457, 0.505)
1.352
(1.336, 1.369)
Model fits to ages of MLB players.
Symmetric -Wright fit to 25,000 heights of children from birth to 18 years of age.
Concluding remarks
Statistical inference procedures for the three-parameter -Wright family of distributions were proposed. The point estimators of the location, scale and fractional parameters were proven to be consistent and asymptotically unbiased. The large-sample results allowed quantification of the uncertainty associated with the proposed point estimators. The inference techniques were also demonstrated using real data sets, which indicated the ‘smoothing’ effect of the fractional parameter . The proposed location parameter estimators did not seriously affect the properties of the scale and fractional parameter estimates (point and interval). The random number generation algorithms were provided by the structural representations. Improvements of these procedures using robust or Bayesian perspectives and the derivation of the trivariate or joint asymptotic distribution of the location, scale, and fractional estimators would be worth exploring in the future.
Footnotes
Acknowledgments
The authors are grateful to the anonymous reviewers and co-editor-in-chief for their insightful comments and valuable suggestions that significantly improved the article.
References
1.
BeghinL., & OrsingherE. (2010). Poisson type processes governed by fractional and higher-order recursive diffferential equations. Electronic Journ Proby, (15), 684-709.
2.
CahoyD. O. (2012). Moment estimators for the two-parameter M-Wright distribution. Computational Statistics, 27(3), 487-497.
3.
CahoyD. O. (2012). Estimation and simulation for the M-Wright function. Communications in Statistics – Theory and Methods, 41(8), 1466-1477.
4.
CahoyD. O., & PolitoF. (2012). Simulation and estimation for the fractional Yule process. Methodology and Computing in Applied Probability, 14(2), 383-403.
5.
HyndmanR. J., & FanY. (1996). Sample quantiles in statistical packages. American Statistician, 50, 361-365.
6.
MainardiF.MuraA., & PagniniG. (2010). The M-Wright function in time-fractional diffusion processes: A tutorial survey. Int’l J of Diff’l Equations, 2010, 29. Article ID 104505, doi: 10.1155/2010/104505.
7.
MuraA.TaqquM. S., & MainardiF. (2008). Non-Markovian diffusion equations and processes: Analysis and simulations. Physica A, 387, 5033-5064.
8.
PagniniG., & ScalasE. (2014). Historical notes on the M-Wright/Mainardi function, 2014. Communications in Applied and Industrial Mathematics, 6(1), DOI: 10.1685/journal.caim.496.
9.
PiryatinskaA.SaichevA. I., & WoyczynskiW. A. (2005). Models of anomalous diffusion:the subdiffusive case. Physica A: Statistical Physics, 349, 375-424.
10.
ZolotarevV. M. (1986). One-dimensional stable distributions: translations of mathematical monographs. American Mathematical Society, 65, Printed in United States of America.