
Abstract
In this paper, we consider variance estimation of the sample mean when the missing data have been imputed with multivariate imputation methods. Modern multivariate imputation methods to missing data are complicated and computationally expensive. These multivariate imputation methods do not require the normality assumption to impute the missing values. Under this assumption free condition, we compare the performance of variance estimation of six modern multivariate imputation methods including copula imputation, random forest imputation, principal component analysis imputation, and k-nearest neighbors imputation methods in complex sampling designs such as stratified sampling, cluster sampling and resampling approach to variance estimation by jackknife and bootstrap methods in stratified sampling. We conducted simulation studies using National Health and Nutrition Survey data considering 5% and 15% missing completely at random (MCAR) rates. Based on our 500 times resampling simulation study of the mean squares errors of the sample mean in complex survey designs, the percent relative efficiency (RE(%)) of the random forest (RF) imputation method appears to outperform other imputation methods overall when the data has high skewness at the 5% missing rate and when the data has high excessive kurtosis at the 15% missing rate whereas the principal component analysis (PCA) imputation method appears to outperform other imputation methods when the data has high skewness at the 5% and 15% missing rates. Especially, the RE(%) of the multivariate imputation methods appears to be efficient in the cluster sampling design when the data has high skewness or excessive kurtosis at the 15% missing rate.
Introduction
Estimation of population variance is of significant importance in the theory of estimation in presence of nonresponse. Efficient variance estimation under auxiliary information has been widely discussed by various authors such as Singh (2003), Arnab and Singh (2006), Kim et al. (2007) and Singh et al. (2015).
A common significant issue in survey research is nonresponse at both the unit and the item level. Unit nonresponse (weight adjustment) refers to the complete absence of an interview from an eligible sample member whereas item nonresponse (missing data) refers to the absence of answers to a particular item or items in the interview after the eligible sampled member agrees to participate in the survey. Survey statisticians have dealt with unit and item nonresponse as two different problems with separate impacts on data quality, different statistical analysis results which lead to the misleading conclusions, and different underlying causes (Kim & Anderson, 2004; Groves, 2004; Groves et al. 2004; Groves et al. 2000).
Missing data make the statistical analysis of the study more complicated and less efficient. Missing values may reduce the representativeness of the samples, induce bias in estimation of parameters, and lead to a loss of power in hypothesis tests. The statistical method of replacing missing item with plausible values from incomplete observations from the collected or available data is called imputation which enables construction of standard programs based on some probability sampling model, for substituting missing data with a point estimate. Missing data imputation is a statistical technique that replaces missing values with statistical predicted values so that imputation method has potential to reduce bias and improve precision to a significant extent. Singh (2003) and Kim and Shao (2013) have reviewed various imputation techniques.
Rubin (1976) introduced the term missing completely at random (MCAR) to describe data where the complete cases are a random sample of the originally identified set of cases, that is, the probability of a case having a missing value for a variable does not depend on either the known values or the missing data. Missing at random (MAR) is another missing mechanism in which the probability of a case having a missing value for a variable may depend on the known values but not on the value of the missing data itself. When the probability of a case having a missing value for a variable depends on the value of that variable, it is called missing not at random (MNAR). Heitjan and Basu (1996) have distinguished the meaning of MAR and missing completely at random (MCAR) in a very nice way. The clarification of these two methods includes the idea that the parameter spaces for models involving the data and the response mechanism are distinct.
In the last two decades an increasing interest has been observed in proposing many statistical methods for handling missing values. Survey researchers have commonly used simple methods such as complete case analysis (listwise deletion), available case analysis (pairwise deletion), or single-value imputation and multiple imputation methods which produce multiple imputed datasets to take into account the uncertainty of the imputation. Some of modern imputation approaches implement multivariate statistical techniques and machine learning algorithms such as principal component analysis, singular value decomposition, copulas, k-nearest neighbors, or random forest, etc. Most of published articles in this area deal with the development of new imputation methods. There are some recent work to compare and evaluate a variety of existing imputation techniques in order to provide practical guidelines for researchers to make an appropriate choice of imputation methods in different situations (Schmitt et al. 2015). Recently, Kowarik and Templ (2016) summarized a variety of imputation techniques available in the R packages, SPSS and SAS.
Though there are some comparison work on imputation methods (Schmitt et al., 2015; Celton et al. 2010; Saunders et al., 2006; De Brevern et al. 2004; Brock et al. 2008), none of them have evaluated performance of the imputation methods by connecting variance estimation in complex survey designs.
Imputation is commonly employed for item nonresponse in sample surveys and then compute the variance estimates using standard formulas. In this paper, we report the relative efficiency of variance estimations of the sample mean of some modern and traditional multivariate imputation techniques under complex survey designs such as stratified sampling, cluster sampling, bootstrap sampling, and jackknife sampling. To achieve that goal, taking the National Health and Nutrition Survey data, datasets were randomly simulated at rates 5% and 15% of missingness, imposing the MCAR mechanism in the original database.
The remainder of this paper is organized as follows: Section 2 describes the modern multivariate imputation methods for missing data and the variance estimation in complex survey designs. Section 3 shows the dataset description and empirical data simulation study. Finally, conclusions are presented in Section 4.
Method
We begin this section by summarizing multivariate imputation methods considered in this paper.
Modern multivariate imputation methods for missing data
Copula imputation: Käärik (2006) and E. Käärik and M. Käärik (2009) used Gaussian copulas to impute correlated incomplete data with repeated measurements. Since then, diverse copula-based imputation methods have been proposed. Di Lascio et al. (2015) emphasized the advantage of the copula based imputation is inherited from those of copula functions that make it possible to model parsimoniously complex multivariate dependence structures allowing to remove the assumption of normality for the data and to fit each margin through the most appropriate model. Zeisberger (2014) also proposed vine copula regression imputation, vine copula fitting imputation and vine copula expectation imputation based on vine dependence structure. Di Lascio and Giannerini (2016) developed an CoImp R package for an imputation method based on copulas. Suppose there are
where
is defined by Bayes’ rule. The conditional density of
It can be easily extended to the case of multivariate missing variables.
We can impute missing observations by means of the Hit or Miss Monte Carlo method. Random forest imputation (RF): Random forest (Breiman, 2001) is one of machine learning approaches. Random forest imputation is an iterative nonparametric imputation method based on random forest. For each variable, we fit a random forest on the observed data and then predict the missing values. This algorithm continues to repeat these two steps until a stopping criterion is met or the pre-specified maximum of iterations is reached. R package missForest (Stekhoven & Bühlmann, 2012) is running iteratively, continuously updating the imputed matrix variable-wise, and is assessing its performance between iterations. This assessment is done by considering the difference(s) between the previous imputation result and the new imputation result. As soon as this difference (in case of one type of variable) or differences (in case of mixed-type of variables) increase, the algorithm stops. Random forest offers advantages in terms of dealing with mixed-type data, it is relatively robust to outliers and noise, and does not assume normality, linearity, or homoscedasticity (Hill, 2012; Rieger et al. 2010). Predictive mean matching (PMM): PMM (Little, 1988; Rubin, 1986) is another way to do multiple imputation for missing data, particularly for imputing continuous variables that are not normally distributed. Suppose there is a single variable
For cases with no missing data, estimate a linear regression of Make a random draw from the “posterior predictive distribution” of Using For each case with missing From among those close cases, randomly choose one and assign its observed value to substitute for the missing value. Repeat steps b through e for each completed data set. Principal component analysis imputation (PCA): Alternative common approach dealing with missing values in PCA consists in ignoring the missing values by minimizing the least squares criterion over all non missing entries. This can be achieved by the introduction of a weighted matrix
There is no explicit solution to minimize the criterion Eq. (4) when missing values are present and it is necessary to use iterative algorithms. Many algorithms are available and (Gabriel & Zamir, 1979) proposed an iterative PCA algorithm that an imputation of the missing values is achieved during the estimation process. Their algorithm consists of the following steps:
Missing values are replaced by initial values PCA is performed on the completed data set to estimate the parameters and obtain Missing values are imputed with the fitted values Steps b and c of imputation are repeated until convergence. k-nearest neighbors (kNN) imputation: k-nearest neighbors algorithm can be used to estimate and substitute missing data. The kNN can predict both discrete variables by majority voting and continuous variables by averaging. For a continuous variable,
This kNN approach does not produce explicit prediction models. Thus, the k-nearest neighbor can be easily adapted to work with any attribute as class, by just modifying which attributes will be considered in the distance metric. Also, this approach can easily treat examples with multiple missing values. The main drawback of this approach is that whenever the k-nearest neighbor looks for the most similar instances, the algorithm searches through all the data set. This limitation can be very critical for the analysis of large databases. Singular value decomposition imputation (SVD): SVD can be used in a simple way to impute data to missing values (Krzanowski, 1988). The method is easy to compute and a description of the steps for one missing value
Omit the Omit the Impute for
In the case where there is more than one missing value, an iterative scheme can be conducted as follows: start with any initial imputed values such as the mean, and update each initial imputed value in turn using c. The process is then iterated until a specified stopping rule is satisfied.
Horvitz-Thompson (1952) introduced an unbiased estimator for
Where
and
where
The estimated variance of the Horvitz-Thompson estimator is given by:
Where
The unbiased estimator of the population mean of a variable
The variance of the Horvitz-Thompson estimator of
Cluster sampling can be used in a single-stage design where the whole population of a cluster is recruited. From Lumley (2010), it is common for large surveys to report only cluster and strata information for the first stage of sampling, or even to report pseudo PSU and strata information. In the single-stage approximation the PSUs are treated as strata and the second-stage sampling units are treated as PSUs. The replicate-weight approach to estimating standard errors computes the standard deviation of the estimated summary across many partially independent subsets of the one sample. Replicate weights for single-stage cluster sampling designs are produced by treating the clusters as units. The jackknife estimates set the weight to
The jackknife method, which was originally designed to estimate the bias of an estimator by deleting one datum from the original data set and recalculating the estimator based on the rest of the data, has become a valuable tool for the variance estimation since the work of Tukey (1958). In an infinite population context, Tukey suggested that each replicate estimate might be regarded as an independent and identically distributed random variable, which in turn suggests a very simple variance estimator. In the finite population sampling context, each jackknife replicate deletes one unit and modifies the weights of others. The general set up of the jackknife variance method is using the size of
Data set and simulation study
NHANES III data set
The National Center for Health Statistics (NCHS) of the Centers for Disease Control and Prevention (CDC) collects, analyzes, and disseminates data on the health status of U.S. residents. The National Health and Nutrition Examination Survey (NHANES) is a periodic survey conducted by NCHS. The third National Health and Nutrition Examination Survey (NHANES III), conducted from 1988 through 1994, was the seventh in a series of these surveys based on a complex, multi-stage sample plan.
Because each sample person in the sample design does not have the same probability of selection, several aspects of the NHANES design must be taken into account in data analysis, including the sample weights and the complex survey design. Appropriate sample weights are needed to estimate prevalence, means, medians, and other statistics. The sample weights incorporate the differential probabilities of selection and include adjustments for noncoverage and nonresponse. For the survey description in detail. We recommend the website
The first stage of the design consisted of selecting a sample of 81 primary sampling unit (PSU)’s that were mostly individual counties. The PSU’s were stratified and selected with probability proportional to size (PPS).
The 89 locations were randomly divided into two groups, one for each phase. The first group consisted of 44 and the other of 45 locations. One set of PSU’s was allocated to the first three-year survey period (1988–91) and the other set to the second three-year period (1991–94). Therefore, unbiased estimates of health and nutrition characteristics can be independently produced for both Phase 1 and Phase 2 as well as for both phases combined.
We downloaded the NHANES III data with 17,030 observations and 16 variables from Hosmer and Lemeshow (Hosmer & Lemeshow, 2000)’s Textbook. A subset of data from the National Health and Nutrition Examination Study (NHANES) III. Subjects age
NHANES III data set
NHANES III data set
Histograms of the five variables: BMPWTLBS, BMPHTIN, PEPMNK1R, PEPMNK5R, and TCP.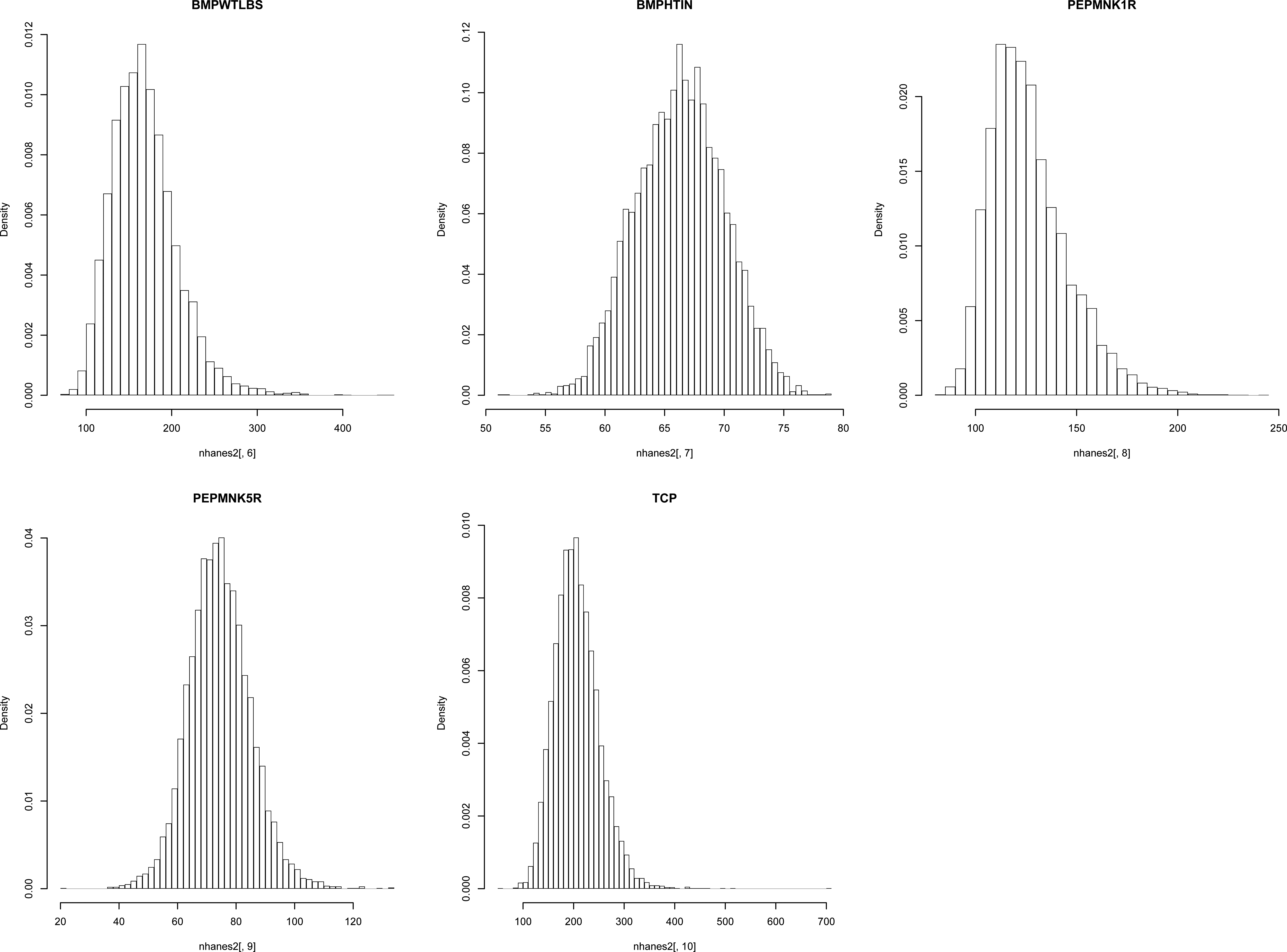
In our simulation study, we select five quantitative variables; BMPWTLBS, BMPHTIN, PEPMNK1R, PEPMNK5R, and TCP from the “nhanes3” data set that is available in survey package of the statistical software R. There are 7,927 individuals who do not have any missing on the five variables. We use these as the complete data during our simulation study. Figures 1 and 2 show that three variables BMPWTLBS, PEPMNK1R, and TCP are skewed to the right. Table 2 summarizes the sample variance, skewness and excessive kurtosis of the five variables. We generate missing observations from these three variables at 5% and 15% missing completely at random rates. With 5% and 15% missing rates, the proportions of the complete observations are approximately 85.74% and 61.41%, respectively. For each configuration of the missing rate, we generated 500 incomplete datasets to compare and evaluate the performances of the imputation methods. Figure 3 shows typical missing patterns of the simulated datasets at 5% and 15% missing rates, respectively. For computing the variance estimation in complex survey data, we used survey R package from Complex Surveys: A Guide to Analysis Using R (Lumley, 2010).
Sample variance, skewness and excessive kurtosis of the five variables
Sample variance, skewness and excessive kurtosis of the five variables
Average computing time of imputation methods in seconds
Q-Q plots of the five variables: BMPWTLBS, BMPHTIN, PEPMNK1R, PEPMNK5R, and TCP.
We summarize the results of the simulation studies in this section. Dong and Peng (2013) mentioned the proportion of missing data is directly related to the quality of statistical inferences. Yet, there is no established cutoff from the literature regarding an acceptable percentage of missing data in a data set for valid statistical inferences. For example, Schafer (1999) asserted that a missing rate of 5% or less is inconsequential. Bennett (2001) maintained that statistical analysis is likely to be biased when more than 10% of data are missing. Furthermore, the amount of missing data is not the sole criterion by which a researcher assesses the missing data problem. Tabachnick and Fidell (2001) posited that the missing data mechanisms and the missing data patterns have greater impact on research results than does the proportion of missing data.
The illustration of the multivariate imputation models using the NHANES III dataset, which are described by 16 variables classifies people described by a set of attributes as whether smoking influence people or not i.e whether the individual got high blood pressure or not caused by smoking. In this example the covariate variables are showing the health condition of the individuals. Three skewed distributed independent variables were taken to this analysis and these variables describe the status of the individuals in Table 1.
Simulation results: Standard errors of the sample mean at 5% missing rate
Simulation results: Standard errors of the sample mean at 5% missing rate
Missing patterns at 5% (Left) and 15% (Right) missing rates.
We conducted simulation studies using National Health and Nutrition Survey data considering 5% and 15% missing rates. Based on our 500 times resampling simulation study of standard errors of the sample mean in complex survey designs, we can conclude that the principal component analysis (PCA) imputation method appears to outperform other imputation methods overall in Tables 2 and 3. But the copula imputation method shows relatively good performance in clustering sampling design and 5% missing rate where the data are skewed to right because the standard error of each missing data design by using copula Imputation method is smaller than other imputation methods. For TCP variable when 5% missing rate, the distribution of TCP variable is heavily skewed to right. The SE value of the copula imputation is much smaller than the SEs of other imputation methods. In addition, the RF imputation method shows relatively good performance in bootstrap sampling design and 5% missing rate where the data are skewed to right.
The execution time of computing the SEs was related to the size of the dataset especially to the percentage of imputation rate. Especially, under the jackknife method under stratified sampling, it reaches around 300 mins on the largest dataset at the 15% rate of missing values.
The computation time of six imputation methods are quite different. For example, the kNN imputation method is almost immediate whereas the copula imputation method requires 8–10 minutes for completion of imputation. Table 3 summarizes the computing time of each imputation method.
Missing data are a part of almost all research, and there are several alternative ways to overcome the drawbacks they produced. It was previous observed that neutral and well-designed comparison studies in computational sciences are necessary to ensure that previously proposed methods work as expected in various situations and to establish standards and guidelines (Boulesteix et al. 2013).
Simulation results: Standard errors of the sample mean at 15% missing rate
RE(%): MSE of the sample mean at 5% missing rate
RE(%): MSE of the sample mean at 15% missing rate
However, only a few studies report an evaluation of existing imputation methods (Brock et al., 2008; Celton et al., 2010; Luengo et al. 2012). In the present study, we performed a neutral comparison of six imputation methods based on four real datasets of various sizes, under an MAR assumption. Validation of imputation results is an important step and we consequently considered two evaluation criteria: standard error (SE) and execution time. While much attention has been paid to the imputation accuracy measured by Root Mean Square Error (RMSE), some studies have examined the effect of imputation on high-level analyses such as unsupervised and supervised classification (Boulesteix et al., 2013; Wang et al., 2006), or the time of execution (Saunders et al., 2006). We found that the sample means by using all six multivariate imputation methods are slightly biased compared with the unbiased sample mean by the complete sample data. To see the magnitude of the gain in efficiency of using the multivariate imputation methods, we compute the percent relative efficiency (RE(%)) of the mean square error (MSE) of the sample mean by using one of six multivariate imputation methods introduced with respect to the MSE of sample mean by the complete sample data as follows
where
As shown in Table 6 at 5% missing rate, the values of RE(%) for BMPWTLBS are more than 100 for the RF and PCA imputation methods and the most of values of RE(%) for PEPMNK1R variable are more than 100 for the PCA imputation method. We can say that for 5% missing rate, the estimators by the RF and PCA imputation methods are more efficient than the estimator by the complete sample data when the data has high skewness. Similarly, Table 7 at 15% missing rate shows that the values of RE(%) for BMPWTLBS variable are more than 100 for the PCA imputation method, the values of RE(%) for TCP variables are more than 100 for the RF imputation method. We can say that for 15% missing rate and the estimators by the RF and PCA imputation methods are mostly more efficient than the estimator by the complete sample data. Especially, the multivariate imputation methods appears to be efficient in the cluster sampling design when the data has high skewness or excessive kurtosis at the 15% MAR rate.
We compared several multivariate imputation methods for missing data. This work revealed novel insights into the performance of variance estimation of the sample mean by a variety of modern multivariate imputation methods including copula imputation, random forest imputation, and k-nearest neighbors imputation methods in complex designs such as stratified sampling, cluster sampling and replication approach to variance estimation by using jackknife and bootstrap methods in stratified sampling. We conducted simulation studies using National Health and Nutrition Survey data considering 5% and 15% missing rates. Based on our 500 times resampling simulation study of MSE of the sample mean in complex survey designs, the PCA and RF imputation methods appear to outperform other imputation methods when the data has high skewness or excessive kurtosis at the 15% missing rate. In the clustering sampling design, most of the multivariate imputation methods performed well even if the estimators by the multivariate imputation methods have biased estimators. Our findings in this paper suggest that more research is necessary to understand the effects of the multivariate imputation methods in complex survey designs.