In this paper, we have considered the exponentiated Pareto type I distribution. Various structural properties of the exponentiated Pareto type I distribution (such as quantile function, moments, incomplete moments, conditional moments, mean deviation about mean and median, stochastic ordering, Bonferroni and Lorenz curves, Renyi entropy and order statistics) are derived. We establish explicit expressions and recurrence relations for single and product moments of record values from exponentiated Pareto type I distribution. These recurrence relations enable computations of the means, variances and covariances of all record values for all sample sizes in a simple and effcient manner. By using these relations, we tabulate the first four moments and variances of record values. The maximum likelihood estimators of the unknown parameters cannot be obtained in explicit forms, and they have to be obtained by solving non-linear equations only. The asymptotic confidence intervals for the parameters are also obtained based on asymptotic variance covariance matrix. An application of the model to a real data sets is presented and compared with the fit attained by some other well-known two and three parameters distributions.
Record value finds extensive applications in many real life situations involving data relating to weather, sport, economics, life testing studies and so on. There are several situations like Guinness World Records where only record values are observed. News items like fastest time taken to recite the periodic table of the elements, shortest ever tennis matches both in terms of number of games and duration in terms of time, fastest indoor marathon, longest time to hop on one foot, etc are of immense interest to people. Several attempts are made to make a record and records are made only when attempts are successful. Usually, we don’t get the data on all of the attempts made to break the records around the world. The data that we have are the records.
Another example is the situation in the assessment of glucose level among diabetic patients, the researchers may be interested to study the behaviour of the ordered records of glocodine. Also, there are several situations where the lower record values are of special interest. For example, if various voltages of equipment are considered, only the voltages less than the previous one can be recorded. These recorded voltages are the lower record value sequence. There are hundreds of papers and several books published on record-breaking data and its distributional properties (see, for instance, Chandler, 1952; Resnick, 1973; Shorrock, 1973; Glick, 1978; Nevzorov, 1987; Ahsanullah, 1995; Balakrishnan & Ahsanullah, 1993, 1994; Grunzien & Szynal, 1997; Arnold et al., 1992, 1998; Kumar, 2015, 2016; and Kumar et al., 2015, 2017). Hence, it is pertinent that one has to study the properties based on records.
The Pareto distribution was first proposed as a model for the distribution of incomes. It is also used as a model for the distribution of city populations within a given area. The Pareto distribution is a skewed, heavy-tailed distribution that is sometimes used to model the distribution of incomes and other financial variables. For instance, they arise as tractable ‘life time models’ in actuarial science, economics, finance, life testing, survival analysis, and telecommunications. Many applications of the Pareto distribution in economics, biology and physics can be found throughout the literature. Burroughs and Tebbens (2001) discussed applications of the Pareto distribution in modeling earthquakes, forest fire areas and oil and gas field sizes, and Schroeder et al. (2010) presented an application of the Pareto distribution in modeling disk drive sector errors. To add flexibility to the Pareto distribution, various generalizations of the distribution have been derived, including: the generalized Pareto distribution (Pickands, 1975), the beta-Pareto distribution (Akinsete et al., 2008) and the beta generalized Pareto distribution (Mahmoudi, 2011). One of the important families of distributions in lifetime tests is the exponentiated Pareto distribution which has been introduced by Gupta et al. (1998). Khan and Kumar (2010) discussed the exponentiated Pareto distribution as an important model of life time models and derived the explicit expressions and some recurrence relations for single and product moments of lower generalized order statistics. The Pareto distribution has Probability density function
and the corresponding cumulative distribution function is
where is a scale parameter and is the shape parameter. Consider the transformation to get another form of the Pareto distribution
Mead (2014) introduced the six parameter generalized Beta exponentiated Pareto distribution. Note that the three-parameter exponentiated Pareto type I (EP I) distribution is a particular member of the generalized Beta exponentiated Pareto distribution.
Let be the first lower record values EP I distribution with pdf
and the corresponding is
where is a scale parameter and , is the shape parameters. It may be observed that several special cases can be obtained from Eq. (4). For example, if we set in Eq. (4) then we obtain the Pareto distribution given in Eq. (3). For and , we obtain Pareto distribution given in Eq. (1).
The remaining of the article is organized as follows. In Section 2, we first describe briefly the preliminaries of record values. Various mathematical and statistical properties of EP I distribution are presented in Section 3. In Section 4 we derive explicit expression and relations for single and product moments of record values. The maximum likelihood estimators and the asymptotic confidence intervals for the parameters based on asymptotic variance covariance matrix are provided in Section 5. In Section 6, the prediction of a future record value is discussed. The graphical representation of mean, variance, skewness and kurtosis of EP I distribution and further mean and variance of EP I distribution based on record values are given in Section 7. In Section 8, we present two real data applications. Finally, conclusions appear in Section 9.
Record values and preliminaries
Let be a sequence of identically independently distributed random variables with and . The th order statistic of a sample is denoted by . For a fixed we define the sequence of th lower record times of as follows:
The sequences with , are called the sequences of th lower record values of . For convenience, we shall also take Note that we have , i.e. record values of .
The joint of th lower record values can be given as the joint of th upper record values of ,
In view of above equation, the marginal of , is given by
and the joint of and , , is given by
Let be a random sample of the EP I distribution with and as in Eqs (4) and (5) respectively, and let be the first lower record values obtained from this sample. Let us denote the single moments by and and the product moments by for . For convenience, let us also use for .
Mathematical and statistical properties of EP I distribution
In this section, we give some important statistical and mathematical measures for the EP I distribution like quantiles, moments, incomplete moments, conditional moments, mean deviation about mean and median, stochastic ordering, Bonferroni and Lorenz curves, Rényi entropy and order statistics.
Quantile function
The quantile functions are in widely used in general statistics and often find representations in terms of lookup tables for key percentiles. The quantile function say , for denote the quantile function of the EP I distribution. Then
In particular, the first three, , and , can be obtain by setting , and in Eq. (8), respectively. Note that can be used to generate EP I random variates.
The effects of the parameters , and on the skewness and kurtosis can be considered based on quantile measures. The Bowley skewness (Kenney & Keeping, 1962) is one of the earliest skewness measures defined by
where , , . Since only the middle two quartiles are considered and the outer two quartiles are ignored, this adds robustness to the measure. The Moors kurtosis (Moors, 1988) is defined as
where , , and .
Clearly, and there is good concordance with the classical kurtosis measures for some distributions. These measures are less sensitive to outliers and they exist even for distributions without moments. For the standard normal distribution, these measures are 0 (Bowley) and 1.2331 (Moors).
Moments
We hardly need to emphasize the necessity and importance of the moments in any statistical analysis especially in applied work. Some of the most important features and characteristics of a distribution can be studied through moments (e.g., tendency, dispersion, skewness, and kurtosis).
Ordinary, central and factorial moments
Let the random variable follow the EP I distribution, then its th moment can be expressed as
where denotes the beta function defined by The expansion Eq. (3.2.1) can be readily computed numerically using standard statistical software. In numerical applications, a large natural number N can be used in the sums instead of infinity. Several quantities of (central moments, variance, skewness and kurtosis) can be derived using Eq. (3.2.1).
Similarly, the moment generating function of EP I distribution can be written as
The central moments and cumulants of can be determined from Eq. (3.2.1) as
and
where . Thus , , , etc. The skewness and kurtosis can be calculated from the third and fourth standardized cumulants.
The th descending factorial moment of is
where is the Stirling number of the first kind.
Incomplete moments
The answers to many important questions in economics require more than just knowing the mean of the distribution. Knowledge of the shape is required as well. This is not only obvious in the study of econometrics but in other areas as well. Incomplete moments of the income distribution form natural building blocks for measuring inequality: for example, the Lorenz and Bonferroni curves and the Pietra and Gini measures of inequality depend on the incomplete moments. The th incomplete moment of is defined by
Conditional moments
For the EP I distribution, it can be easily seen that the conditional moments, , can be written as
where
where denotes the ascending factorial and and defined in Eq. (5)
An application of the conditional moments is the mean residual life (MRL). MRL function is the expected remaining life, , given that the item has survived to time . Thus, in life testing situations, the expected additional lifetime given that a component has survived until time is called the (MRL). The MRL function in terms of the first conditional moment as
Another application of the conditional moments is the mean deviations about the mean and the median. They are used to measure the dispersion and the spread in a population from the center. If we denote the median by , then the mean deviations about the mean and the median can be calculated as
and
respectively. Where and can obtained from Eq. (3.4). Also, and are easily calculated from Eq. (5).
Stochastic ordering
Stochastic ordering is a tool used to study structural properties of complex stochastic systems. For example, it is useful for controlling congestion in information transfer over the internet, for deening treatment-related trends in clustered binary data, and ordering expected welfare income under differentent mechanisms of allocating rewards. There are different types of stochastic orderings which are useful in ordering random variables in terms of different properties. Here we consider four different stochastic orders, namely, the usual, the hazard rate, the mean residual life, and the likelihood ratio order for two independent EP I random variables under a restricted parameter space. If and are independent random variables with CDFs and respectively, then is said to be smaller than in the
Stochastic order if for all ;
Hazard rate order if for all ;
Mean residual life order if for all ;
Likelihood ratio order if decrease in .
The following results due to Shaked and Shanthikumar (1994) are well known for establishing stochastic ordering of distributions.
The EP I distribution is ordered with respect to the strongest “likelihood ratio” ordering as shown in the following theorem. It shows the flexibility of three parameter EP I distribution.
Theorem 1. Let and . If and , then , , and .
Proof The likelihood ratio is
thus,
Now if and then , which implies that and hence , , and .
Bonferroni and Lorenz curve
Boneferroni and Lorenz curves are proposed by Boneferroni (1930). These curves have applications not only in economics to study income and poverty, but also in other fields like reliability, demography, insurance and medicine. They are define as
and
respectively, where and . By using Eq. (4), one can reduce Eqs (14) and (15) to
and
respectively.
Reyi entropy
The entropy of a random variable with the density function is a measure of variation of the uncertainty. Reyi entropy is defined as , where , and . If a random variable has a EP I distribution, then, we have
see Gradshteyn and Ryzhik [(2014), p-325], where , denotes the beta function. Hence, Reyi entropy is given by
Order statistics
Moments of order statistics play an important role in quality control testing and reliability to predict the failure of future items based on the times of few early failures. We know that if denotes the order statistics of a random sample from a continuous population with cdf and pdf then the pdf of is given by
for . The and of the th order statistic for a EP I distribution is given by
and
The th moments of can be expressed
Joint distribution of the th and th order statistics
The joint distribution of the the th and th order statistics from EP I distribution is
If and we get the joint distribution of the minimum and maximum of order statistics
where .
Moments of record values for EP I distribution
In this section we derive explicit expressions and recurrence relations for single and product moments of th lower record values from EP I distribution.
Relations for single moments
We shall first establish explicit expressions for single moments of th lower record values, . Theorem 1 gives an explicit expression for single moments of th lower record values and .
Theorem 2. For the EP I distribution given in Eq. (4) with fixed parameters , , and , we have
If these reduce to the corresponding lower record values for the EP I distribution.
Relations for product moments
We shall first establish explicit expressions for the product moment of th and th lower record values, . Theorem 3 gives an explicit expression for and .
Theorem 4. For the EP I distribution given in Eq. (4) and for and ,
where , and . The result follows by using complete gamma function to calculate the integral in Eq. (22).
The proof is complete.
As a check, put in Eq. (21) and use Eq. (15), we have .
For simplicity, we denote the moment of and , which are also called the simple product moment of these records, by . The simple product moments are used for evaluating the covariances, in other words
Theorem 5 establishes a recurrence relation for . This result holds for positive as well as negative values of and .
By integrating by parts with respect to , we obtain
The result follows.
In particular, upon setting in Theorem 5, we deduce the following result.
Corollary 2. For the EP I distribution given in Eq. (4) and ,
Method of estimation
Maximum likelihood estimation
In this section, we obtain the maximum likelihood estimators of the parameters , and of EP I distribution when the available data are lower record values. Let be a sequence of random variables with and on positive support. Let for . The observation , is a lower record value of this sequence, if it is greater than all preceding observations, that is for .
Suppose we observe lower record values from a sequence of random variables following a EP I with Eq. (4). The likelihood function based on the random sample of size is obtained as:
Subsituting Eqs (4) and (5) in Eq. (30), we get the likelihood function
The maximum likelihood estimators are the values of , and that maximize this likelihood function. The log likelihood function , dropping terms that do not involve , and , is
We assume that the parameters , and are unknown. To obtain the normal equations for the unknown parameters, we differentiate Eq. (28) partially with respect to , and and equate to zero. The resulting equations are
and
The solutions of the above equations are the maximum likelihood estimators of the EP I parameters , and , denoted , and , respectively. As the equations expressed in Eqs (29), (30) and (31) cannot be solved analytically. Therefore, we propose the use of fixed point iteration method for solving these equations. For further details see Jain et al. (1984), Rao (2006) and Kumar (2017).
Approximate confidence intervals
Since the MLEs of the unknown parameters are not obtained in closed forms, it is not possible to derive the exact distributions of the MLEs. Therefore, the approximate confidence intervals of the parameters based on the asymptotic distributions of their MLE are derived. It is well established the MLEs are asymptotically normally distributed i.e. , where, is the sample size, , is the MLE of and is variance-covariance matrix, which is obtained as the inverse of the Fisher’s information matrix. The total observed information matrix is given by
whose elements are given in
Let . We construct asymptotic confidence intervals of the parameters by using variance covariance matrix as in the following forms:
where is the upper th percentile of the standard normal distribution.
Prediction of future record values
In this Section, we consider the problem of predicting future record values given a sample of observed record values.
Suppose that we observe the first lower record values from a population with . Our aim is to predict , , having observed records . The joint predictive likelihood function of , and the possibly vector-valued parameter can be written Basak and Balakrishnan (2003) as
where
and
The predictive likelihood function for the EP I distribution is
The log predictive likelihood is given by
To obtain the normal equations for the unknown parameters , , and , we differentiate Eq. (6) partially with respect to , , and and equate to zero. The resulting equations are
and
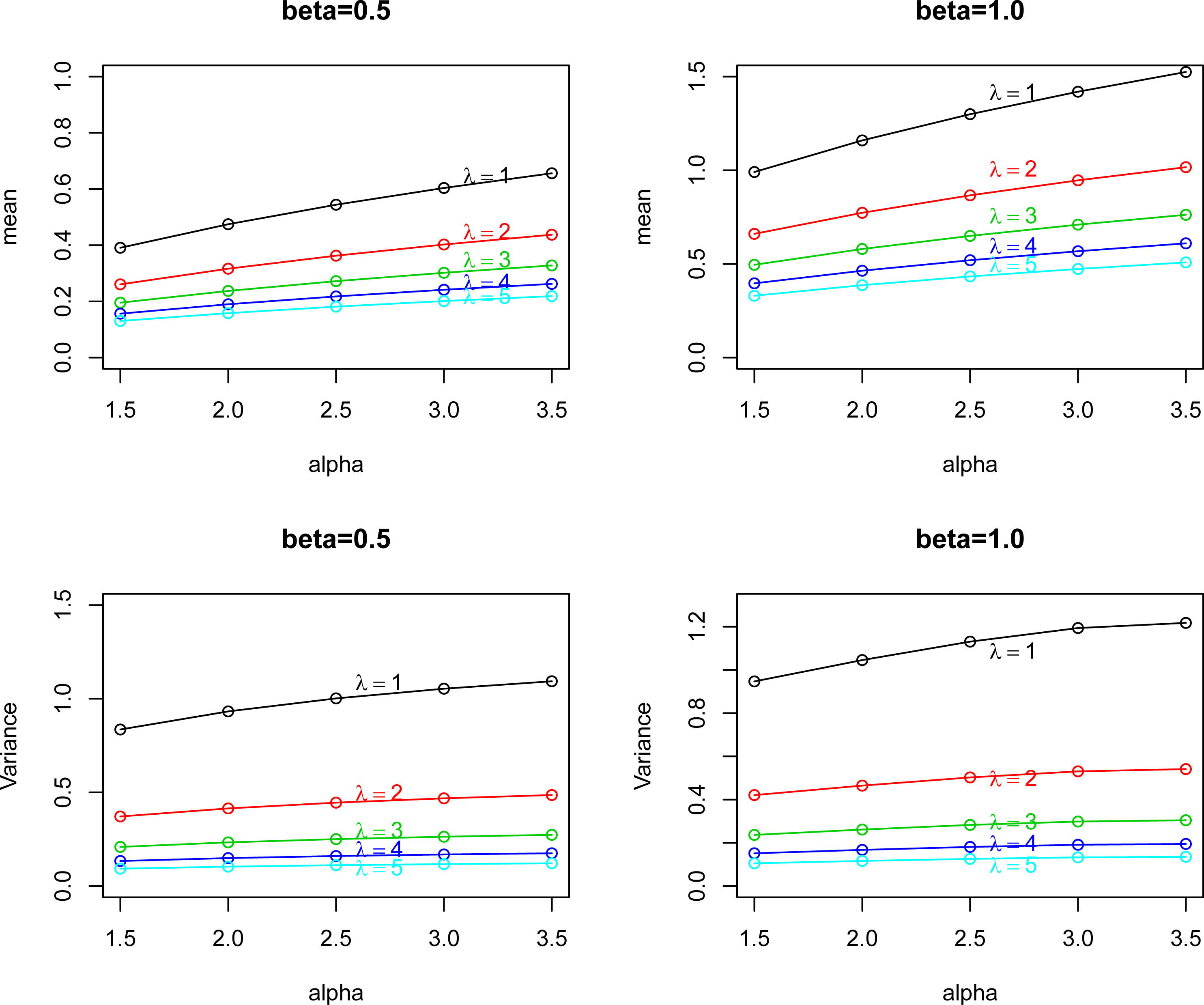
The mean of EP I distribution for (top left); (top right) and the variance of EP I distribution for (bottom left); (bottom right).
Numerical aspects
Here, we investigate how the moments of lower record values from the EP I distribution vary with respect to and . The recurrence relations obtained in the preceding sections allow us to evaluate the means, variances and covariances of all order statistics for all sample sizes in a simple recursive manner and can be used for various inferential purposes; for example, they are useful in determining BLUEs of location/scale parameters and best linear unbiased predictors (BLUPs) of censored failure times. More details on BLUEs and BLUPs based on order statistics can be seen in (Balakrishnan & Cohen, 1991; Arnold et al., 1992).
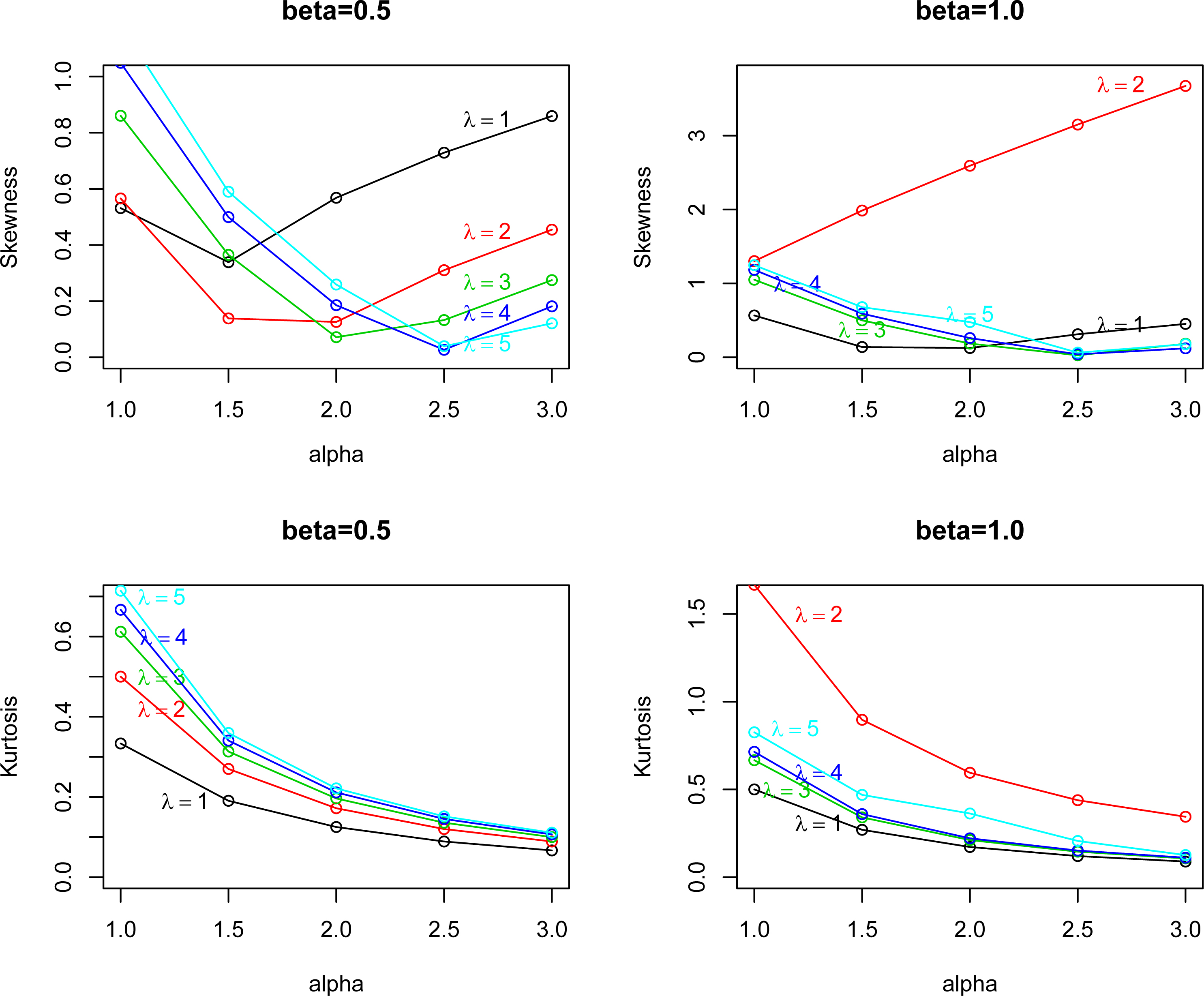
In this section, we plot the mean and variance versus for selected values of and . Figure 1 shows the mean and variance versus and for and . Figure 2 plots the skewness and kurtosis versus for selected values of and . Figure 2 shows the skewness and kurtosis and for and . We see from Fig. 1 that mean and variance of EP I distribution is increasing function of for selected values of and . Also we see from Fig. 2 that skewness and kurtosis of EP I distribution is decreasing function of for selected values of and .
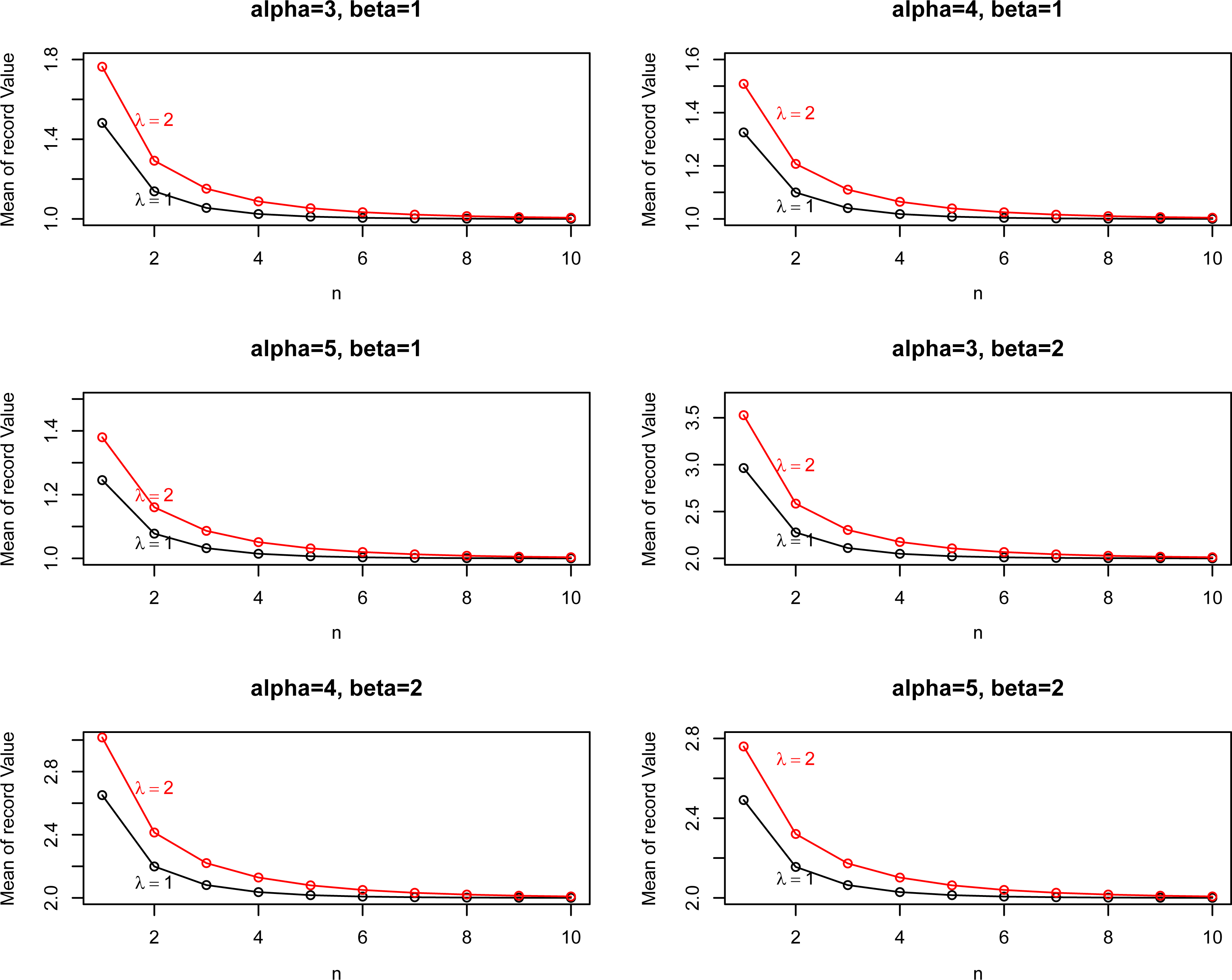
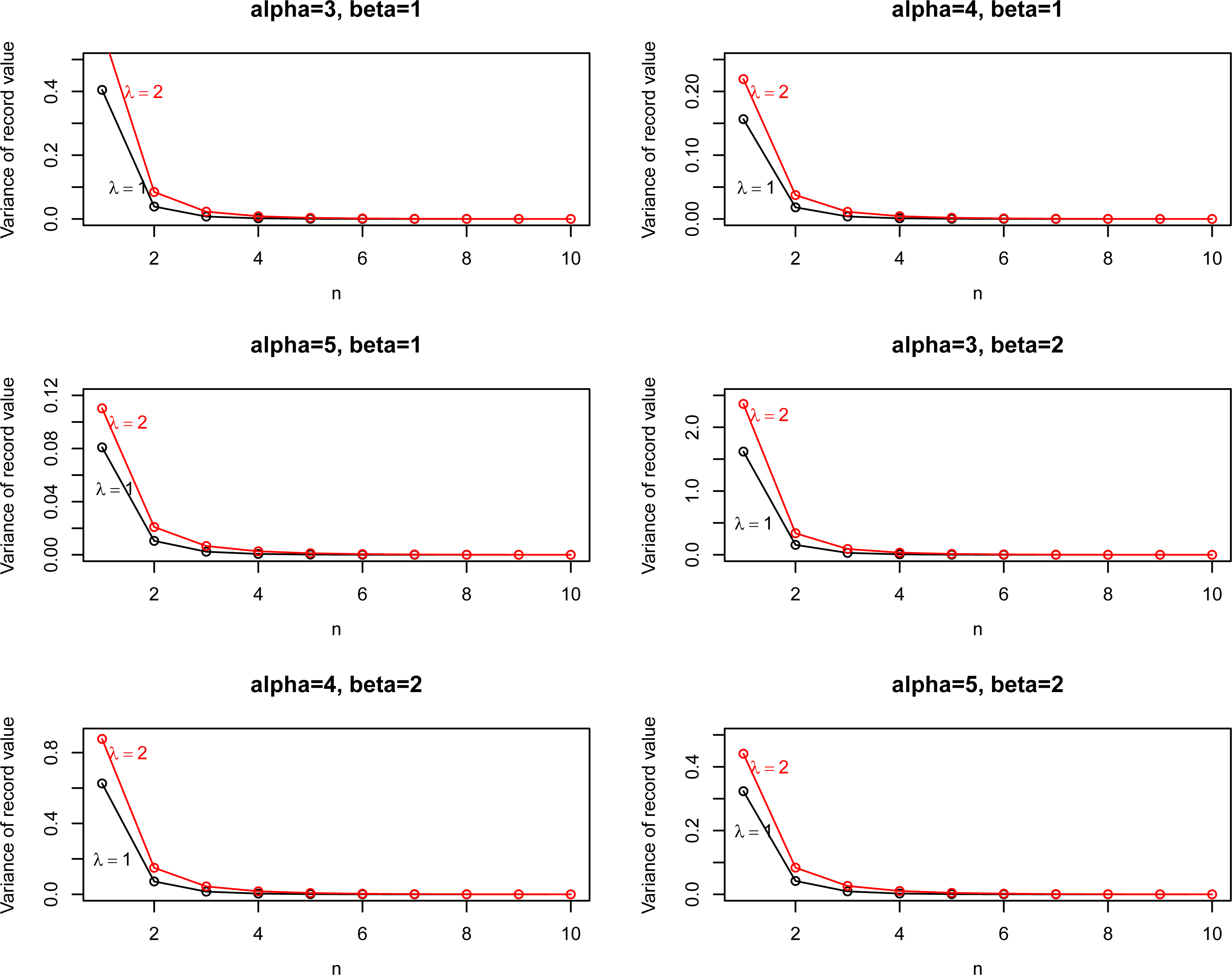
In the rest of the section, we plot the mean, and variance based on record values. From Fig. 3, one can see that the moments are decreasing function with . Figure 4 shows that the variance are decreasing with respect to and but increasing function with and .
Figures for the skewness, kurtosis, product moments and covariances of record values are not presented here but are available from the authors on request. All computations here were performed using R-Software. R-Software like other algebraic manipulation packages allows for arbitrary precision, so the accuracy of the given values is not an issue.
The skewness of EP I distribution for (top left); (top right) and the kurtosis of EP I distribution for (bottom left); (bottom right).
EP I model fitting to real data sets
In this section,we use two real data sets to illustrate the estimation and prediction procedures proposed in this work. For computation, we have used R package coda.
We compare the EP I distribution with exponentiated exponential Possion (EEP) distribution (Pogány, 2015), Weibull-Poisson (WP) distribution (Lu & Shi, 2012), complementry exponential geometrc (CEG) distribution (Louzada et al., 2011),
Descriptive statistics for data I
Mean
Median
Mode
SD
Skewness
Kurtosis
Min.
Max.
Data I
14.24
11.2
0
8.39
1.08
3.82
4.10
39.20
Prediction of 4-th lower record for data I
Estimation method
PMLE (data I)
12.6038
38.2501
402.04
417.03
95% predictive interval
(2.085, 21.432)
(11.270, 64.593)
(301.78, 415.03)
(55.021, 458.23)
List the MLEs of the models parameters and the approximate confidence intervals of the parameters of the EP I distribution for data I
Model
MLE
CIs
Data I
5.1437
1.6024
375.00
(0.6908, 10.9782)
(0.6224, 2.5824)
(374.02, 375.98)
Mean of EP I distribution based on record values for different values of parameters.
Lindley (LN) distribution (Lindley, 1958). Their density functions (for ) are given by
List the MLEs of the models parameters and the corresponding standard errors (in parentheses) and the approximate confidence intervals of the parameters of all the models for data I
Model
MLE
CIs
EP I
2.0858
0.5528
375.00
(1.6550, 2.5167)
(0.1330, 1.2388)
(374.02, 375.98)
EEP
2.0758
0.1111
0.0272
(0.0988, 4.0525)
(0.0001, 0.2431)
(0.0001, 7.0390)
WP
2.2757
0.0010
3.1550
(2.1719, 2.3796)
(0.0000, 0.9807)
(0.8495, 5.4605)
CEG
0.1952
0.0889
(0.1345, 0.2559)
(0.0039, 0.1724)
Goodness-of fit statistics for data I
Model
AIC
BIC
K-S
P-value
EP I
168.9992
343.9983
349.7938
0.06188
0.9880
EEP
174.5937
355.1874
360.9829
0.1450
0.5616
WP
170.9905
347.9810
353.7764
0.0988
0.8768
CEG
174.7967
353.5935
357.4571
0.1007
0.8858
Variance of EP I distribution based on record values for different values of parameters.
Descriptive statistics for data II
Mean
Median
Mode
SD
Skewness
Kurtosis
Min.
Max.
Data II
121.3
57.0
0
154.27
1.25
4.57
12.0
502
Prediction of 6-th lower record for data II
Estimation method
PMLE (data II)
1.5259
2.6201
398.52
420.12
95% predictive interval
(0.6701, 2.5807)
(0.8807, 4.3709)
(293.78, 408.13)
(67.052, 458.62)
List the MLEs of the models parameters and the approximate confidence intervals of the parameters of the EP I distribution for data II
Model
MLE
CIs
Data II
0.8823
0.0892
374.99
(0.1066, 1.6579)
(0.0001, 1.6920)
(374.01, 375.97)
List the MLEs of the models parameters and the corresponding standard errors (in parentheses) and the approximate confidence intervals of the parameters of all the models for data II
Model
MLE
CIs
EP I
1.1440
0.2616
299.99
(0.6807, 1.6072)
(0.0010, 0.9476)
(298.62, 301.36)
EEP
1.1905
0.0056
2.3448
(0.4917, 1.8892)
(0.0015, 0.0128)
(0.0021, 6.2172)
LN
0.0163
(0.0104, 0.0222)
Goodness-of fit statistics for data II
Model
AIC
BIC
K-S
P-value
EP I
84.0750
174.1501
176.2742
0.1476
0.9251
EEP
86.0423
178.0846
180.2088
0.2033
0.6604
CEG
86.1541
176.3082
177.7243
0.1909
0.9551
LN
90.6706
183.3412
184.0493
0.3863
0.1813
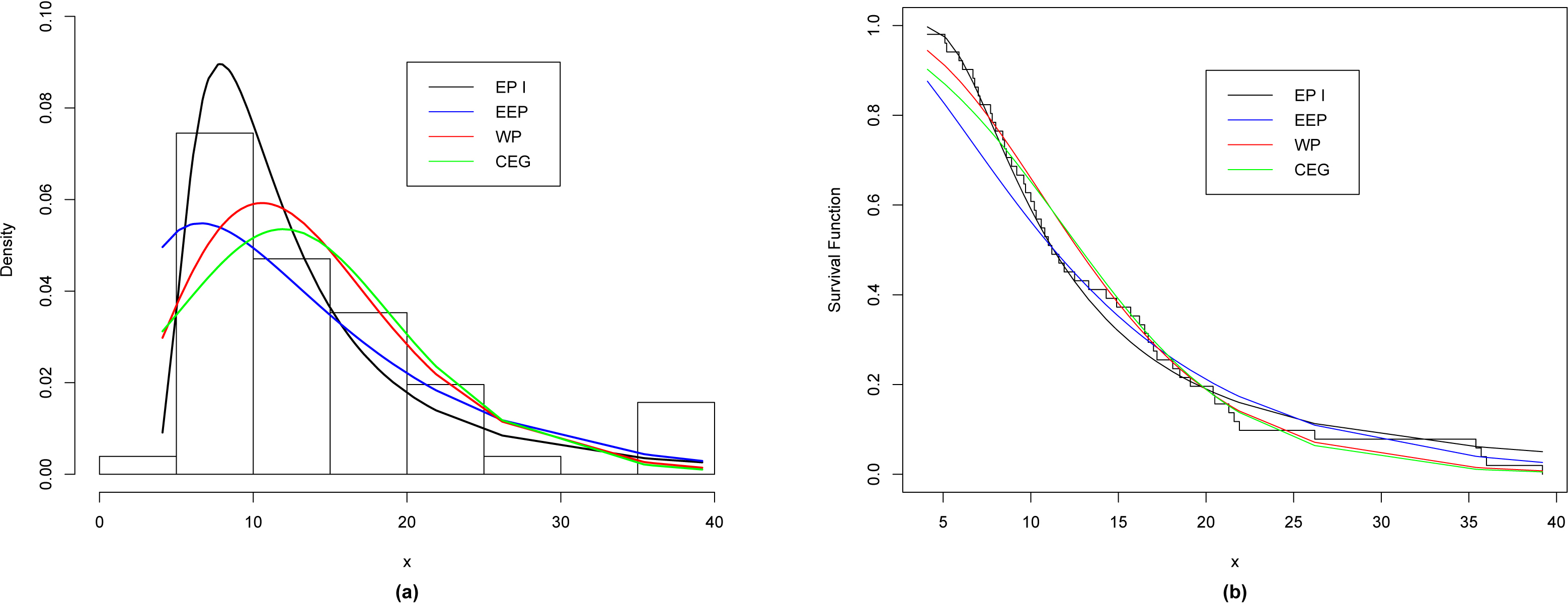
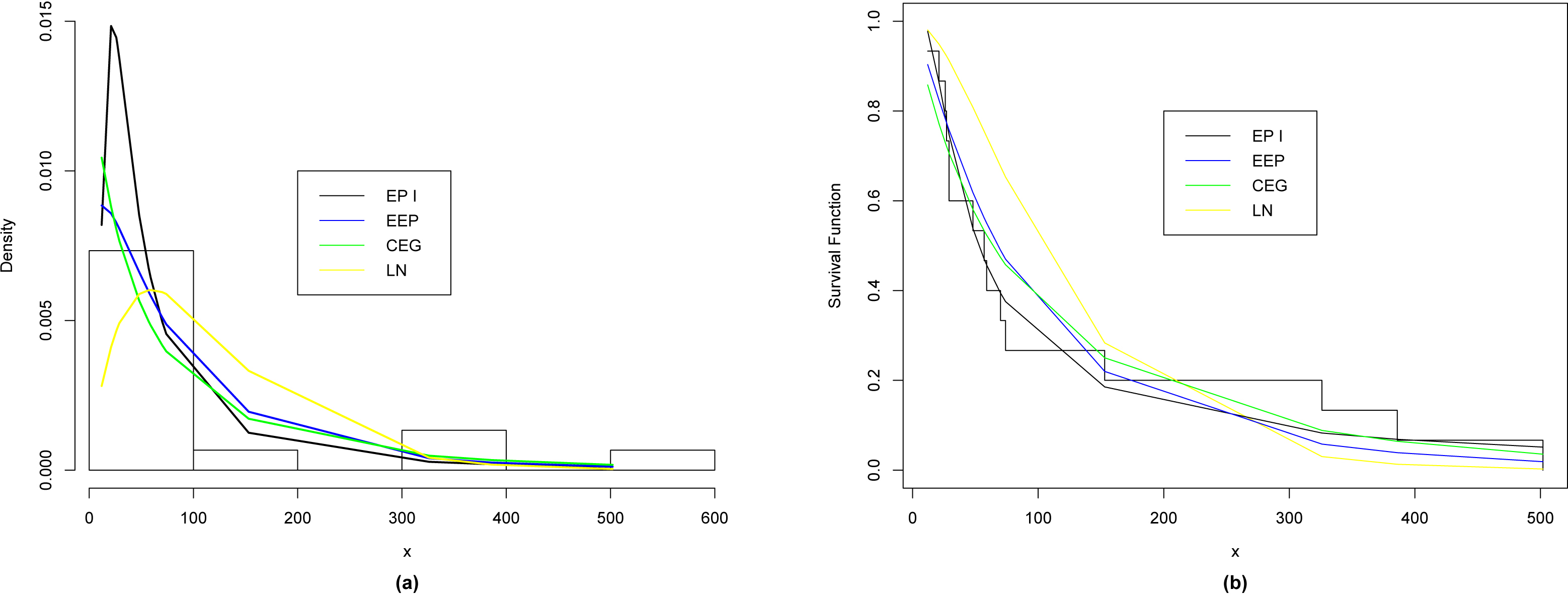
(a) The relative histogram with the fitted distributions for data I, (b) The empirical and fitted survival functions for various distributions for data I.
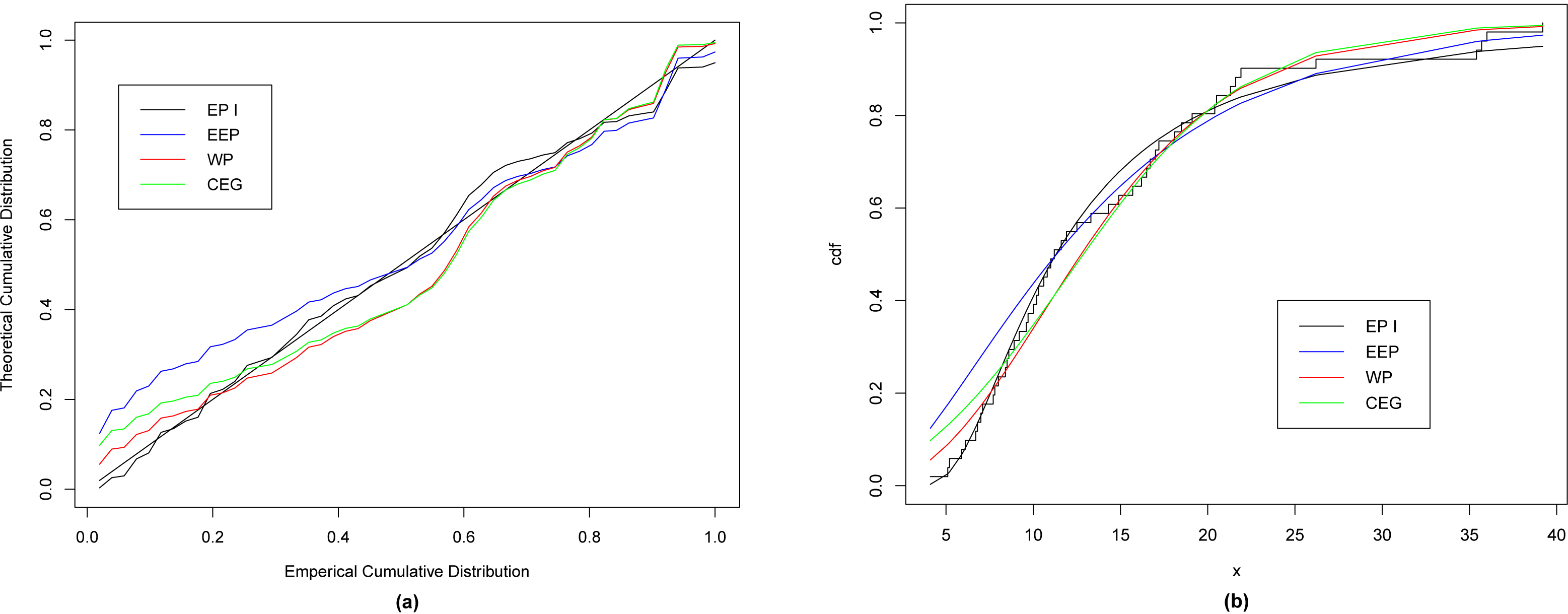
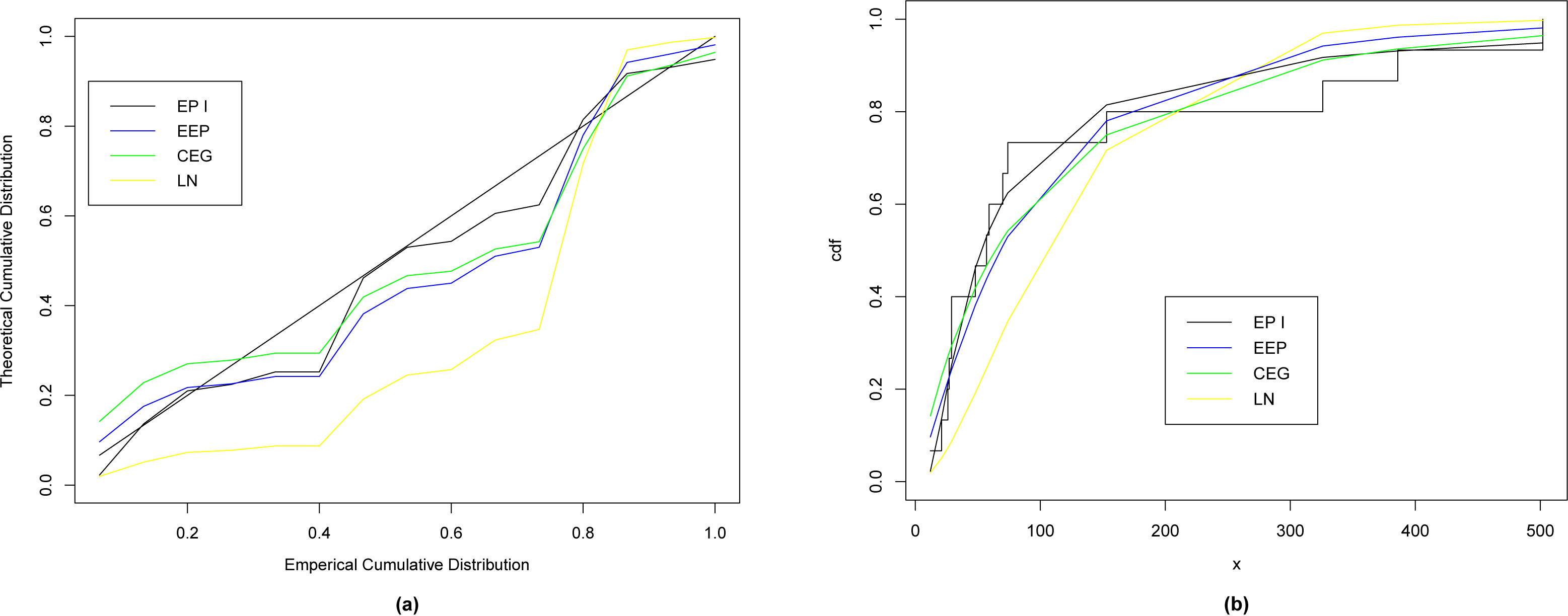
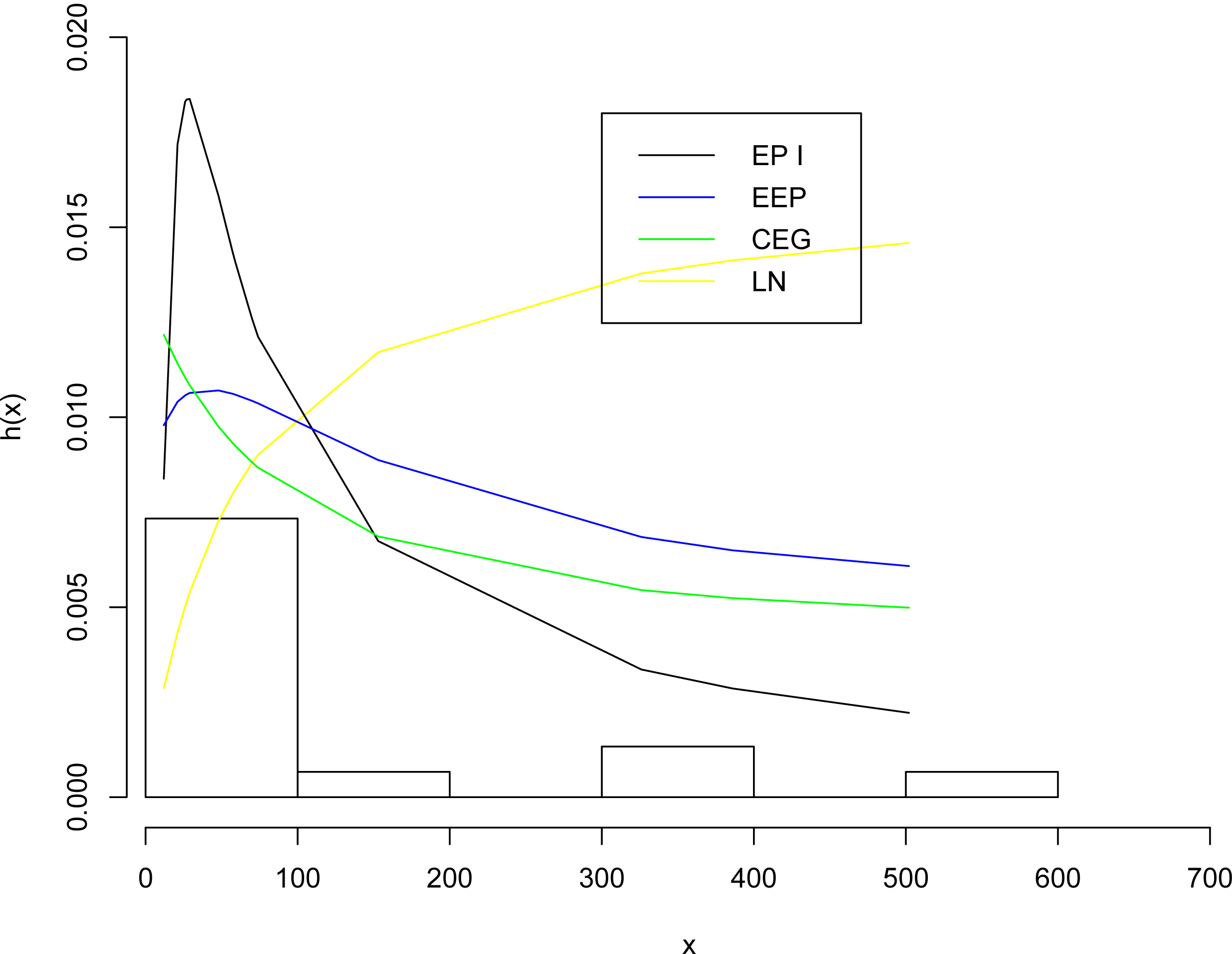
In order to compare the proposed distribution with the competitive distributions, we use the maximum likelihood method to obtain the values of the goodness of fit statistics where ( denotes the log-likelihood function evaluated at the maximum likelihood estimates), Kolmogorov-Smirnov (K-S) statistic and the corresponding p-value, Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) for data I and data II, respectively.
(a) The theoretical and emperical cumulative distribution with the various fitted distributions, (b) The fitted CDF for various distributions.
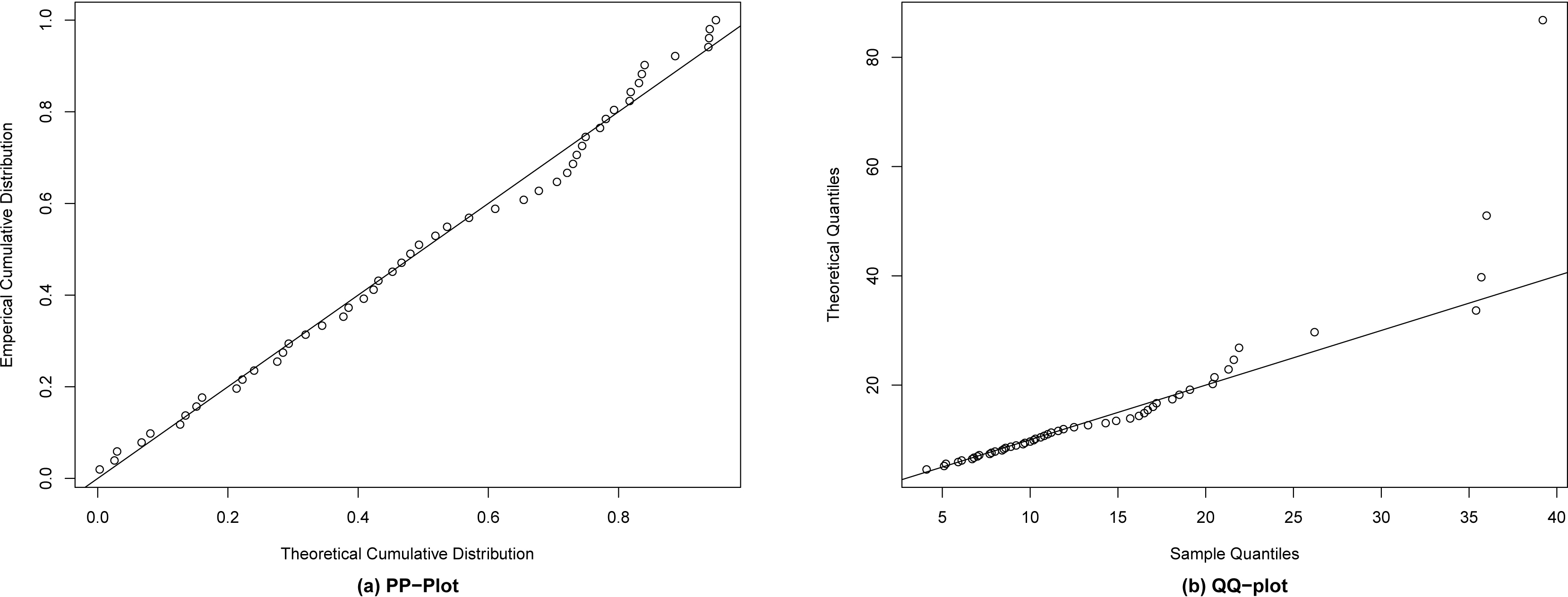
(a) P-P plot for the EP I distribution for data I. (b) Q-Q plot for the EP I distribution for data I.
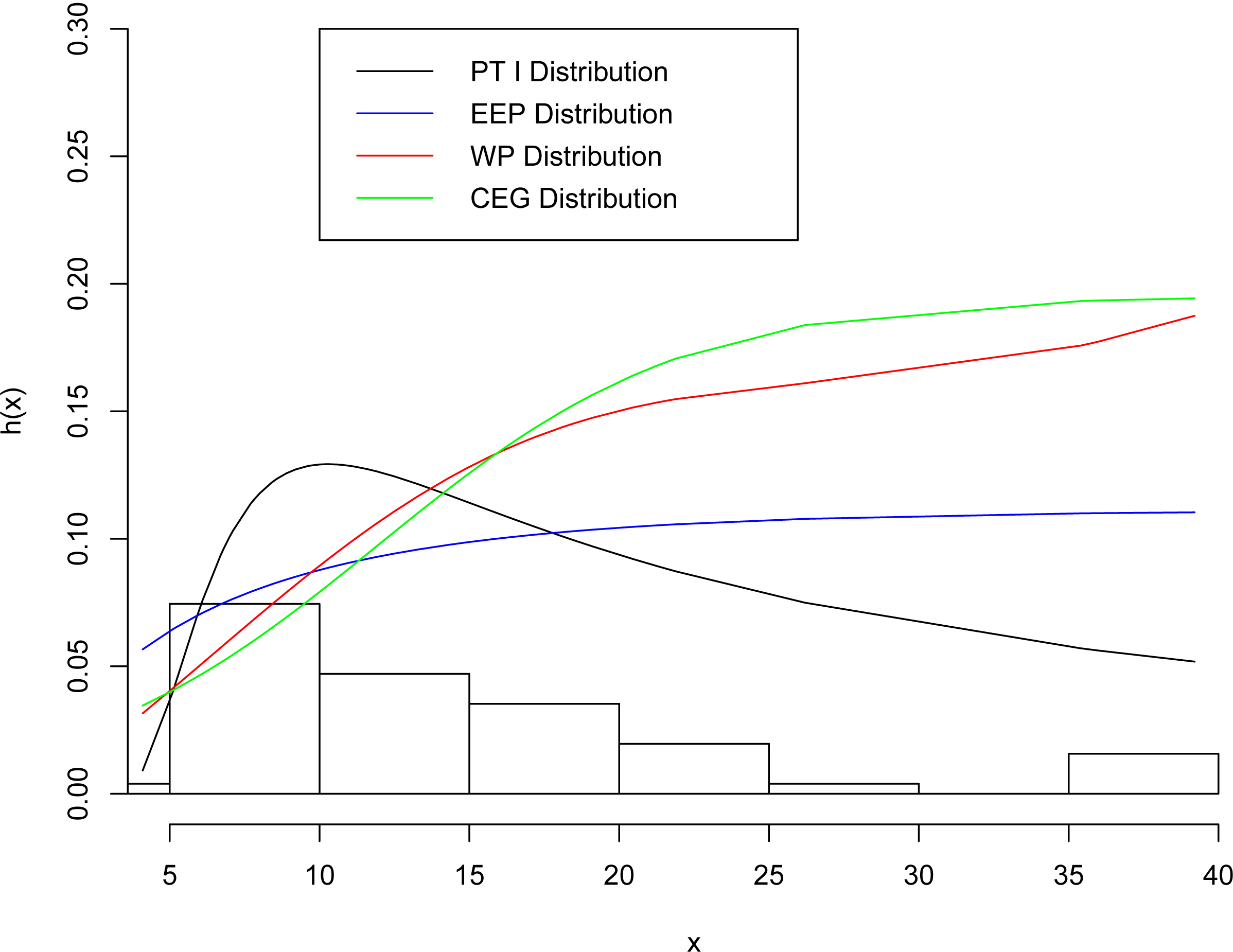
The fitted hazard function for various distributions for data I.
Example 1. The first data set (data I) represents the actual taxes data set. The revenue in Egypt is divided onto 5 chapters and although the taxes is only one chapter from these 5 chapters, but it records the majority of the income. The data consists of the monthly actual taxes revenue in Egypt from January 2006 to November 2010. The distribution is highly skewed to the right. The data (in 1000 million Egyptian pounds) are:
(a) The relative histogram with the fitted distributions for data II, (b) The empirical and fitted survival functions for various distributions for data II.
Table 1 gives a descriptive summary of the actual taxes in Egypt from January 2006 to November 2010.
These data were studied by Nassar and Nada (2011) using beta generalized Pareto distribution. But no one has discussed these data set in considered model under lower record values. From this data set we have extracted three lower records 5.9, 5.1, 4.1 for our data analysis. The parameter estimation results are summarized in Table 5. Besides parameter estimation, we have also implemented prediction procedures as mentioned the earlier section of the paper. Here our goal is to predict 4-th lower record value based on the three records considered in the parameter estimation. Table 2 represents our finding from the data analysis.
(a) The theoretical and emperical cumulative distribution with the various fitted distributions for data II, (b) The fitted CDF for various distributions for data II.
(a) P-P plot for the EP I distribution for data II, (b) Q-Q plot for the EP I distribution for data II.
The fitted hazard function for various distributions for data II.
Table 5 lists the values of , AIC, BIC, K-S and p-value, respectively. From Table 5, we observe that the EP I distribution gives the lowest values of , K-S (with largest p-value), AIC and BIC among all fitted models, so it could be chosen as the best model to fit the given data set.
Example 2. The second data set (data II) consist of the times between successive failures of air conditioning equipment in a Boeing 720 airplane. These data were analyzed by Proschan (2000), the data are:
Table 6 gives a descriptive summary of the times between successive failures of air conditioning equipment in a Boeing 720 airplane.
From this original data set we have extracted five lower records 74, 57, 48, 29, 12 for our data analysis. The parameter estimation results are summarized in Table 5. Besides parameter estimation, we have also implemented prediction procedures as mentioned the earlier section of the paper. Here our goal is to predict 6-th lower record value based on the three records considered in the parameter estimation. Table 7 represents our finding from the data analysis.
Table 10 lists the values of , AIC, BIC, K-S and p-value, respectively. From Table 5, we observe that the EP I distribution gives the lowest values of , K-S (with largest p-value), AIC and BIC among all fitted models, so it could be chosen as the best model to fit the given data set.
Conclusions
The exponentiated Pareto type I distribution provided excellent model for life time data for a variety of situations. Thus, it is important for the analyst to have reliable statistical methods to use for this distribution. We have provided in this study, a new explicit expressions and recurrence relations for single and product moments of lower record values from the EP I distribition. Further, we have provided frequentist methods of estimating the parameters based on samples of lower record values and methods of predicting future record values.
A future work may be to derive estimation procedures for the EP I distribution based on order statistics, generalized order statistics and dual generalized order statistics. Another future work may be to characterize the EP I distribution based on order statistics, generalized order statistics and dual generalized order statistics.
Footnotes
Acknowledgments
The authors are grateful for the comments and suggestions by the referees and the Co-Editor-in-Chief. Their comments and suggestions have greatly improved the paper.
References
1.
AhsanullahM. (1995). Record Statistics. Nova Science Publishers, New York.
2.
AkinseteA.FamoyeF., & LeeC. (2008). The beta-Pareto distribution. Statistics, 42, 547-563.
3.
ArnoldB. C.BalakrishnanN., & NagarajaH. N. (1992). A First course in order. John Wiley and Sons, New York.
4.
MeadM. E. (2014). An extended Pareto distribution. Pakistan Journal of Statistics and Operation Research, 10, 313-329.
5.
ArnoldB. C.BalakrishnanN., & NagarajaH. N. (1998). Record. John Wiley and Sons, New York.
6.
BalakrishnanN., & AhsanullahM. (1993). Relations for single and product moments of record values from exponential distribution. J Appl Statist Sci, 2, 73-87.
7.
BalakrishnanN., & AhsanullahM. (1994). Recurrence relations for single and product moments of record values from generalized Pareto distribution. Comm Statist Theory Methods, 23, 2841-2852.
8.
BalakrishnanN., & CohenA. C. (1991). Order statistics and inference: Estimation methods. Boston, MA:Academic Press.
9.
BasakP., & BalakrishnanN. (2003). Maximum likelihood prediction of future record statistic, in: LindquistB. H., & DoksumK. A. (eds), Mathematical and Statistical Methods in Reliability, in: Series on Quality, Reliability and Engineering Statistics, Vol. 7, World Scientific Publishing, Singapore, pp. 159-175.
10.
BonferroniC. E. (1930). Elmenti di statistica generale. Libreria Seber, Firenze.
11.
BurroughsS. M., & TebbensS. F. (2001). Upper-truncated power law distributions. Fractals, 9, 209-222.
12.
ChandlerK. N. (1952). The distribution and frequency of record values. J Roy Statist Soc, Ser B, 14, 220-228.
13.
GrunzienZ., & SzynalD. (1997). Characterization of uniform and exponential distributions via moments of the k-th record values with random indices. Appl Statist Sci, 5, 259-266.
14.
GlickN. (1978). Breaking records and breaking boards. Arner Math Monthly, 85, 2-26.
15.
GradshteynI. S., & RyzhikI. M. (2014). Tables of Integrals, Series of Products. Academic Press, New York.
16.
GuptaR. C.GuptaR. D., & GuptaP. L. (1998). Modeling failure time data by Lehman alternatives. Comm Statist Theory Methods, 27, 887-904.
17.
KenneyJ. F., & KeepingE. (1962). Mathematics of Statistics. D Van Nostrand Company.
18.
KhanR. U., & KumarD. (2010). On moments of lower generalized order statistics from exponentiated Pareto distribution and its characterization. Applied Mathematical Sciences, 4, 2711-2722.
19.
KumarD. (2015). Explicit expressions and statistical inference of generalized rayleigh distribution based on lower record values. Mathematical Methods of Statistics, 24, 225-241.
20.
KumarD.JainN., & GuptaS. (2015). The type I generalized half logistic distribution based on upper record values. Journal of Probability and Statistics, 2015, 1-11.
21.
KumarD. (2016). kth lower record values from of Dagum distribution. Discussiones Mathematicae Probability and Statistics, 36, 25-41.
22.
KumarD. (2017). The Singh-Maddala distribution: Properties and estimation. Int J Syst Assur Eng Manag, 8, 1297-1311.
23.
KumarD.KumarM.SaranM., & JainN. (2017). The Kumaraswamy-Burr III distribution based on upper record values. American Journal of Mathematical and Management Sciences, 36, 205-228.
24.
LindleyD. V. (1958). Fiducial distributions and Bayes’s theorem. Journal of the Royal Society, Series B, 20, 102-107.
25.
LouzadaaF.RomanaM., & CanchobV. G. (2011). The complementary exponential geometric distribution: Model, properties, and a comparison with its counterpart. Computational Statistics and Data Analysis, 55, 2516-2524.
26.
LuW., & ShiD. (2012). A new compounding life distribution: The Weibull-Poisson distribution. Journal of Applied Statistics, 39, 21-38.
27.
MoorsJ. J. A. (1988). A quantile alternative for kurtosis. Journal of the Royal Statistical Society, Series D (The Statistician), 37, 25-32.
28.
NassarM. M., & NadaN. K. (2011). The beta generalized Pareto distribution. Journal of Statistics: Advances in Theory and Applications, 6, 1-17.
29.
NevzorovV. B. (1987). Records. Theo Prob Appl, 32, 201-228.
30.
PogT. K. (2015). The exponentiated exponential Poisson distribution revisited. Statistics, 49, 918-929.
PickandsJ. (1975). Staistical inference using extreme order statistics. Ann Statist, 3, 119-131.
33.
ResnickS. I. (1973). Extreme values, regular variation and point processes. Springer-Verlag, New York.
34.
SchroederB.DamourasS., & GillP. (2010). Understanding latent sector error and how to protect against them. ACM Transactions on Storage (TOS), 6, Article 8.
35.
ShakedM., & ShanthikumarJ. G. (1994). Stochastic orders and their applications. Boston, MA: Academic Press.
36.
JainM. K.IyengarS. R. K., & JainR. K. (1984). Numerical Methods for Scientific and Engineering Computation. New Age International Pvt Limited, New Delhi.
37.
RaoG. S. (2006). Numerical Analysis. New Age International Pvt Limited, New Delhi.
38.
ShorrockR. W. (1973). Record values and inter-record times. J Appl Probab, 10, 543-555.