
Abstract
We use a simple machine learning model, logistically-weighted regularized linear least squares regression, in order to predict baseball, basketball, football, and hockey games. We do so using only the thirty-year record of which visiting teams played which home teams, on what date, and what the final score was. No real statistics are used, although a statistical method is used. The method works best in basketball, likely because it is high-scoring and has long seasons. It works better in football and hockey than in baseball, but in baseball the predictions are closer to a theoretical optimum. The football predictions, while good, can in principle be made much better, and the hockey predictions can be made somewhat better. These findings tells us that in basketball, most statistics are subsumed by the scores of the games, whereas in football, further study of game and player statistics is necessary to predict games as well as can be done. Baseball and hockey lie somewhere in between.
Introduction
There is a long tradition in statistics in predicting many aspects of athletic events, in particular which teams will win, which players are the best, and the propensity of players to become injured. The tradition began in baseball, and was glorified in Moneyball (Lewis, 2004), but it has now extended to almost all other major sports. With the growing popularity of sports gambling and fantasy sites, there is more demand than ever for statistical information about which players will succeed and which teams will win.
This paper uses a simple, weighted, and penalized regression model (see Rifkin et al., 2003) to predict the outcome of MLB, NBA, NFL, and NHL games, using data going back more than thirty years scraped from the websites. It is similar to the model in Fearnhead and Taylor (2011), except it measures the ability of teams over games instead of players over possessions, and it does not take into account which team is at home. We intentionally limit our data use to the date, home and visiting teams, and score of each game, and we compare our predictions to a theoretically near-optimal indicator. Doing so tells us what statistical information is contained just in the scores, and whether what are commonly referred to as statistics have real predictive power. In basketball, the statistics are largely made unnecessary by the record of game scores, whereas in football this is clearly not the case. Baseball and hockey lie somewhere in the middle. This is likely because basketball has long seasons and high-scoring games, whereas baseball and hockey have long seasons but low-scoring games. Football has short seasons and is effectively low-scoring, because what matters is the number of scores that take place, not the scores’ point values. The models are trained on even-numbered years and tested on odd-numbered years.
The theoretically near-optimal indicator (which we also call the “oracle”) works as follows: Since our data is historical, we can predict every game by looking at the eventual end-of-season rankings and always bet that the eventually higher-ranked team will win. This estimator does not adjust for schedule difficulty, but is nonetheless very hard to beat. We demonstrate the performance of our penalized regression compared to this estimator. Furthermore, we show how it can be computed quickly using the Woodbury Matrix Identity.
We additionally prove that our model beats a straw man. To compute the straw man prediction of a game, look at the previous season’s ranking and predict that the higher ranking team will win. Our model almost always beats the straw man.
Baseball predictions, MLB
Baseball predictions, MLB
Basketball predictions, NBA
Earnshaw Cook published the first major work on sabermetrics (baseball statistics) in 1964. Yang and Swartz (2004) use a Bayesian hierarchical model to predict Major League Baseball games, and Lyle (2007) does so using ensemble learning. Abuaf et al. (2006) and Moy (2006) predict baseball games using a number of statistics. Jang et al. (2014) uses a k-nearest-neighbor algorithm to predict Korean baseball games. Bukiet et al. (1997) model individual baseball games as Markov processes and studies many aspects of the game, including batting order, but does not post predictions. Sire and Redner (2009) study winning and losing streaks in baseball. Jensen et al. (2009) and Jiang and Zhang (2010) use Bayesian hierarchical models to study hitting performance in baseball. Houser (2005) believes the most important trait in a baseball player is his propensity to get on base. See Table 1.
The first model for predicting the outcome of professional basketball games appeared in Heit et al. (1994), which uses a formula to update a team’s strength after every game. Cervone et al. (2015) uses player position data to predict how likely an NBA team is to score on a given possession. Puranmalka (2013) uses a genetic algorithm, and achieves better results than we do in basketball prediction, but over a shorter time period, and only marginally so. Torres (2013) does about as well as we do at NBA prediction but also over a very short time span and using many statistics. These results do not contradict our thesis that the vast majority of the statistical power is contained simply in the scores of the games since their results are not that much better than ours. Beckler et al. (2013) and Yang (2015) use a simple models to predict NBA games, Poropudas (2011) uses a Kalman Filter, and Wei (2001) uses a Naive Bayes predictor. Cao (2012) surveys many NBA prediction methods. Cheng et al. (2013) predicts the betting line in NBA games. Clark et al. (2013) predict the likelihood of making a three-pointer using a logistic regression. Caruso and Epley (2004) and Vallone and Tversky (1985) study the hot hand effect, in which they do not believe. Summers (2013) studies how to win the playoffs. See Table 2.
Shi et al. (2013) use several machine learning methods, decision trees, rule learners, neural networks, naive Bayes, and random forests, and many statistics to predict NCAA basketball games. Brown and Sokol (2010), Carlin (1996), Caudill (2003), Stekler and Klein (2012) and Stoudt et al. use different methods to predict the NCAA men’s basketball. In fact, the Journal of Quantitative Analysis in Sports ran an entire issue on NCAA prediction in Glickman and Sonas (2015).
Football predictions, NFL
Hockey predictions, NHL
DeJong (1997) uses a probit regression to predict football games, and Kahn (2003) uses a neural network to predict football games. Glickman and Stern (1998) use a Bayesian hierarchical model to predict football games. Balreira et al. (2014) use numerous methods to predict NFL games. West and Lamsal (2008) predict college football games. Blaikie et al. (2011) use neural networks to predict both professional and college football games. Harville (1977) uses a stochastic process model to rate high school and college football teams.
Szalkowski and Nelson (2012) explain the extent to which casino betting lines predict NFL games, which raises interesting questions about the power of democracy in prediction. Warner (2010) predicts the betting lines. Sinha et al. (2013) predicts NFL games using Twitter, another democratic approach. McGee and Burkett (2003) study the NFL draft. See Table 3.
There is also some past work done on NHL hockey, including one paper on game prediction (Weissbock, 2014) using neural networks, and one paper on scoring rates (Buttrey et al., 2011). There are other papers using various factors to predict hockey games (Leard & Doyle, 2011; Weissbock & Inkpen, 2014). See Table 4.
Blundell (2009) and Haghighat et al. (2013) survey a group of machine learning methods used in sports prediction in general. There is also a wealth of research on the statistics of soccer games.
In the next section we describe a model that takes scores from historical games and predicts the winner of future games. We then evaluate its performance on historical data.
The general scheme is to put the scores of the games in a vector,
For
Model predictions compared
Model predictions compared
MLB: Our model (middle) vs. the oracle (top) and the straw man (bottom).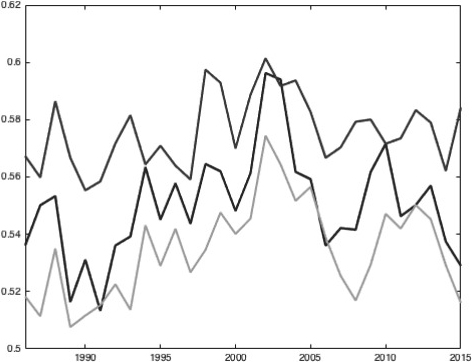
NBA: Our model (middle, darkest) vs. the oracle (top) and the straw man (bottom).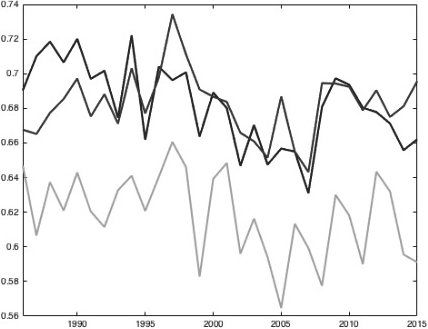
Let
where the
For matrices
with
and let
Typically there is a positive
The sign of
This process can be accelerated. First compute
Hypothesize that we know
NFL: Our model (middle) vs. the oracle (top) and the straw man (bottom).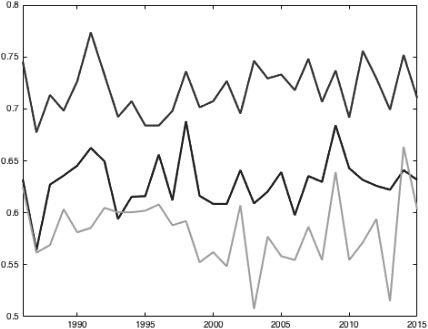
NHL: Our model (middle) vs. the oracle (top) and the straw man (bottom). Note that the 2005 season was unfinished due to a strike.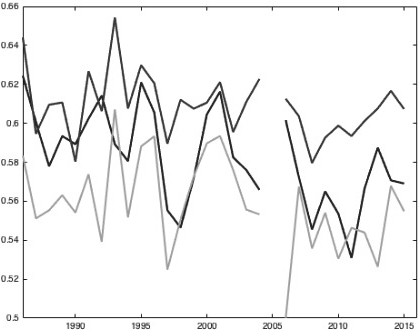
NBA: Teams are located on the x-axis (the best on a left); y-axis shows a percentage of the really won (descending) and predicted by our model (jagged) games in 2015 season.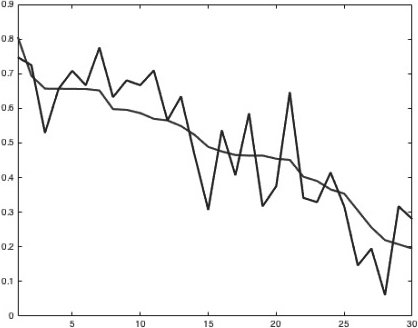
All computations were done using Matlab.
Table 5 shows the results of the model on all four sports, on the even years on which it was trained, on the odd years, and on all years. The form of the results is the probability of correctly predicting the winner of a game. The Model column denotes the performance of our model, whereas the Oracle column denotes the performance of the theoretically hard-to-beat model described in the introduction which uses information from the future to predict the past. The Straw Man was described in the introduction.
To reiterate, the theoretically near-optimal indicator works as follows: Since our data is historical, we can predict every game by looking at the eventual end-of-season rankings and always bet that the eventually higher-ranked team will win. This estimator does not adjust for schedule difficulty, but is nonetheless very hard to beat.
The even numbered years are our training set and the odd numbered years are our test set. Note that hte training and test set performance are similar.
The first four figures (Figs 1–4) show the performance of our model (in blue) vs. the oracle (in red) and the straw man (in green) in every year from 1986–2015. The performance is measured by the ratio of games predicted correctly. The figures are in the order MLB, NBA, NFL, NHL. They show that the model performs well in basketball, which has long seasons and high-scoring games. It performs passably in baseball and hockey and poorly in football. These results indicate that most basketball statistics are subsumed by the game scores. This is somewhat the case in baseball and hockey and not the case in football. The hockey graph jumps during the strike in the 2005 season.
Figure 5 compares actual and model-predicted wins for the NBA. Expectedly, the NBA graph shows the model to be accurate.
We see that the basketball predictor comes very close to and sometimes outperforms the oracle, even though it only uses game scores. The theoretically near-optimal indicator (which we also call the “oracle”) works as follows: Since our data is historical, we can predict every game by looking at the eventual end-of-season rankings and always bet that the eventually higher-ranked team will win. This fact suggests that adding more traditional statistics probably has limited value for predicting NBA matches. Furthermore, this fact is predictable. Basketball games are high scoring, so by the law of averages the better teams usually win. Furthermore, basketball has long seasons, so it is easy to identify which teams are better and best. Other sports are less like basketball because they do not have these properties. Baseball and hockey have long seasons but are low scoring. Football is higher-scoring but has short seasons. More work is necessary in predicting baseball, football, and hockey more optimally.
Footnotes
Acknowledgments
The author thanks the anonymous referees for their helpful comments.