
Abstract
This paper illustrates a two-stage approach for predicting customer profitability. The first stage is to build a dichotomous model to predict the customer’s likelihood of future purchase. The second stage is to build a model, with continuous target variable, to predict the conditional future profit generated by the customer given he would make a purchase. Both stages involve the utilization of the gradient boosting and neural network data-mining techniques. In each stage, various ensemble combinations are tried and the one resulting in the lowest validation average squared error is chosen to be the stage model winner. The two model winners are subsequently used jointly for the prediction of future profit. In this analysis, Base SAS
Keywords
Introduction
Customer value, or customer lifetime value (CLTV) in the longer-term perspective, has been a well-researched area in both academia and commercial domains (EsmaeiliGookeh & Tarokh, 2013; Damn & Monroy, 2011; Singh & Jain, 2010; Malthouse & Blattberg, 2005). It is an important topic in customer relationship management, and was defined by Kotler as the present value of the future profit stream expected given a time horizon of transacting with the customer (Kotler, 1974). One primary goal in the context of customer lifetime value is to understand how one customer differs from another. In fact, it is generally believed that a small percentage of customers account for a large percentage of revenue and profit (Mulhern, 1999), thus implying that the distribution of customer value is somewhat skewed. This phenomenon is also consistent to the Pareto Principle (Vilfredo Pareto 1848–1823) which states that for many phenomena, about 80% of the consequences are produced by 20% of the causes (Dunford et al., 2014). The same phenomenon can further be illustrated by considering Formula 1 – a formula commonly used (the interest rate factor is neglected) for calculating customer lifetime value (CLTV).
The formula assumes that the time horizon is divided into
The approach for estimating
This research focuses on non-contractual product purchases. Instead of considering the entire lifetime horizon, this analysis will focus on predicting the two quantities and the customer value in a shorter time-period (i.e.
In fact, Eq. (2) could be re-written as
Equation (3) essentially represents a two-part or two-stage model (Kapitula, 2015), including two components – the purchaser and non-purchaser population. The second term means that if a customer is predicted to be a non-purchaser (
A two-stage modeling framework for the prediction of future profit.
Profit is taken as a proxy of customer value. This study attempts to predict the future profit generated by existing customers. An existing customer is defined as someone who has prior purchase experience. He could be someone who made his first purchase yesterday; or someone who made his first purchase 3 years ago and thereafter placed a few orders in each subsequent year; or someone who bought 2 years ago but since then has made no more purchase as of today. The profit is defined as the gross profit margin (i.e. sales minus cost-of-good-sold), and we want to predict the profit an existing customer would generate for the company in the next 12 months. A period of 12-month is chosen simply because it covers all business seasons of a full financial year, and the model prediction as such derived would organically exempt from the influence of seasonality, in regardless of the starting month of any 12-month horizon.
The base and prediction period.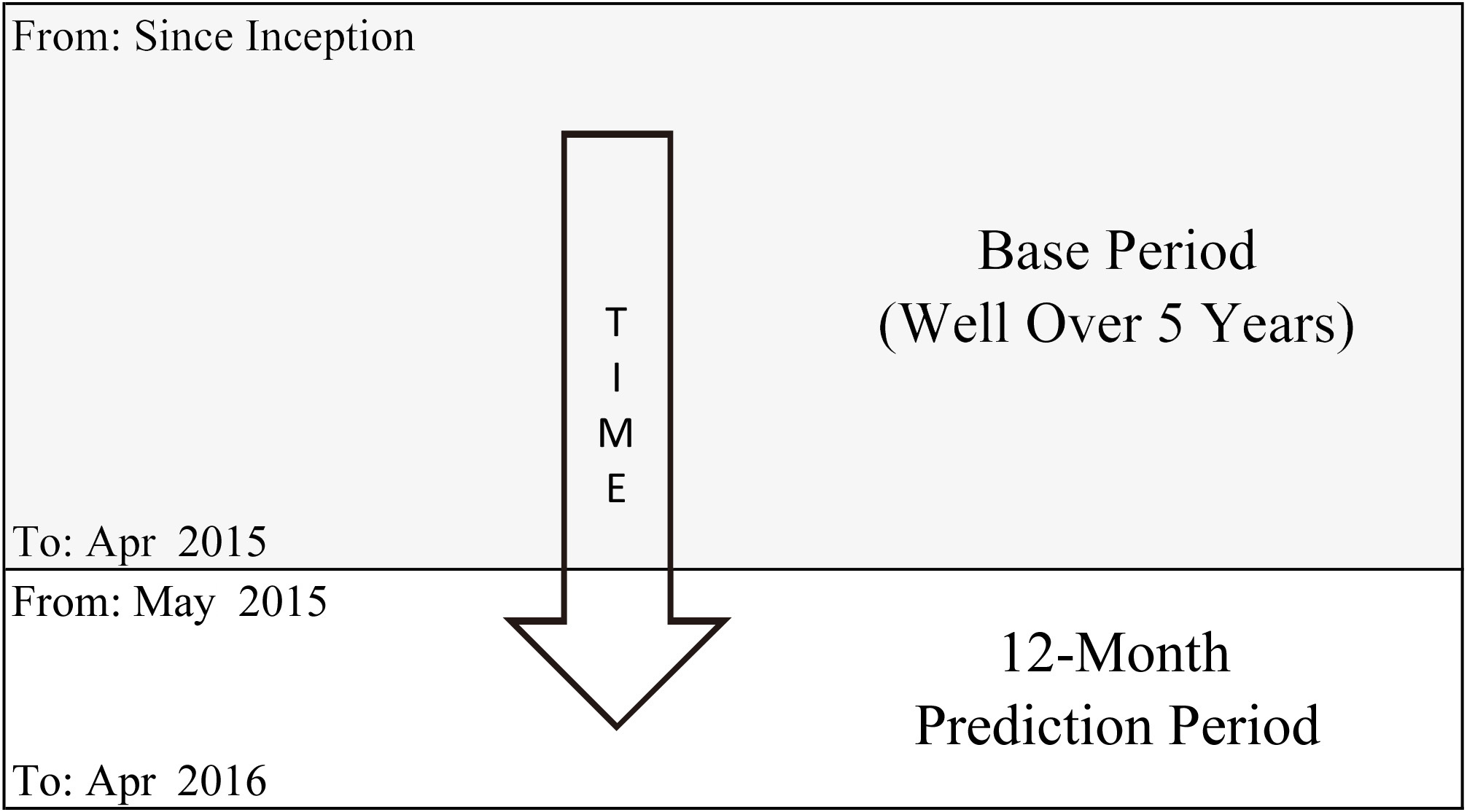
Refer to Fig. 1. Two models are built. Model 1 predicts how likely (i.e. probability
Sampling
The dataset utilized in this analysis is originated from an anonymous business operation which delivers consumable products to the general consumer market. For confidentiality reason, all the variable names, figures and profitability results are masked. We bookmark the status (e.g. prior usage behavior and loyalty membership status) of the existing customers as of the last day of April2015 (the reference date), and then predict as well as observe their actual purchase behavior (i.e. whether they purchase or not, and the associated profit margins) in the next 12 months (May 2015 to April 2016). A pictorial representation is shown in Fig. 2.
Sampling summary
Sampling summary
Variable descriptions
Remark: The status of all input variables is measured based on the reference date of 30 Apr 2015.
See Table 1, a total of 180,000 existing customers (who bought at least once during the base period) are randomly selected from the company database. This sample records a “Purchase” to “Not Purchase” ratio of 21.0% to 79.0% in the prediction period. A total of 22,500 customers are randomly drawn from the “Purchase” group without replacement. These 22,500 customers are combined with another 22,500 random observations drawn from the “Not Purchase” group (again without replacement) to form the modeling dataset for building Model 1, and the same 22,500 customers from the “Purchase” group is used to build Model 2. For the remaining 15,377 observations from the “Purchase” group, they are combined with 57,698 random observations drawn from the balance (i.e. 142,123 – 22,500
Profit distribution (full sample).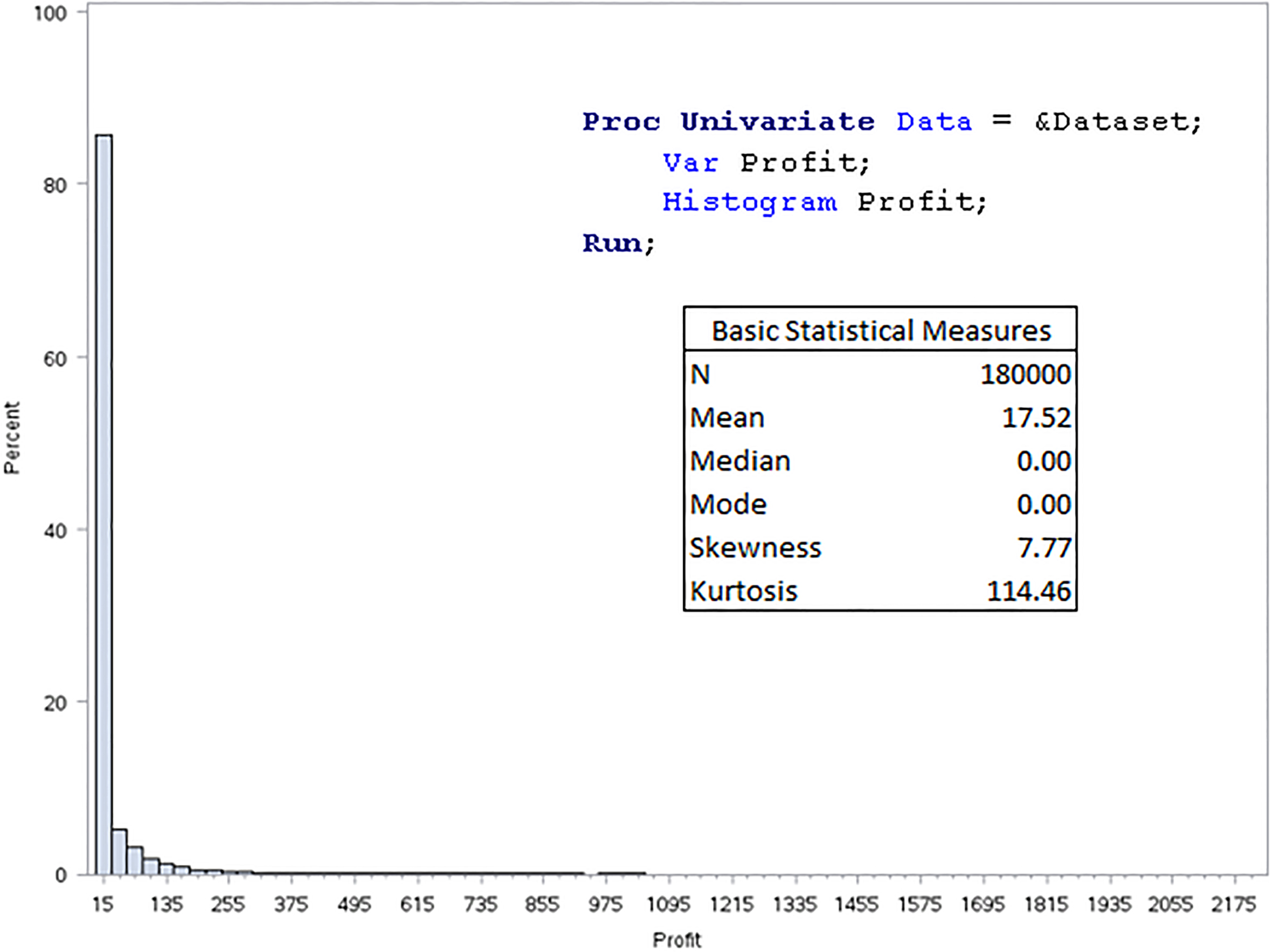
All the target and input variables used in this study are summarized in Table 2.
Model building
Exploratory analysis
One important practice in any predictive modeling project is to obtain an initial picture of the distribution of the target variable. This can be achieved through a Proc Univariate routine. The results of such routine reveal (see Fig. 3) that the target: Profit is highly skewed. Both the skewness and kurtosis are far from zero; and the location measure mean (17.5) and median (0.0) do not align. This is not unexpected since we know from Table 1 that 79.0% of the sampled customers have not made any purchase in the prediction period. Nevertheless, such highly skewed target distribution may pose difficulty in predictive modeling.
Profit distribution (purchaser only).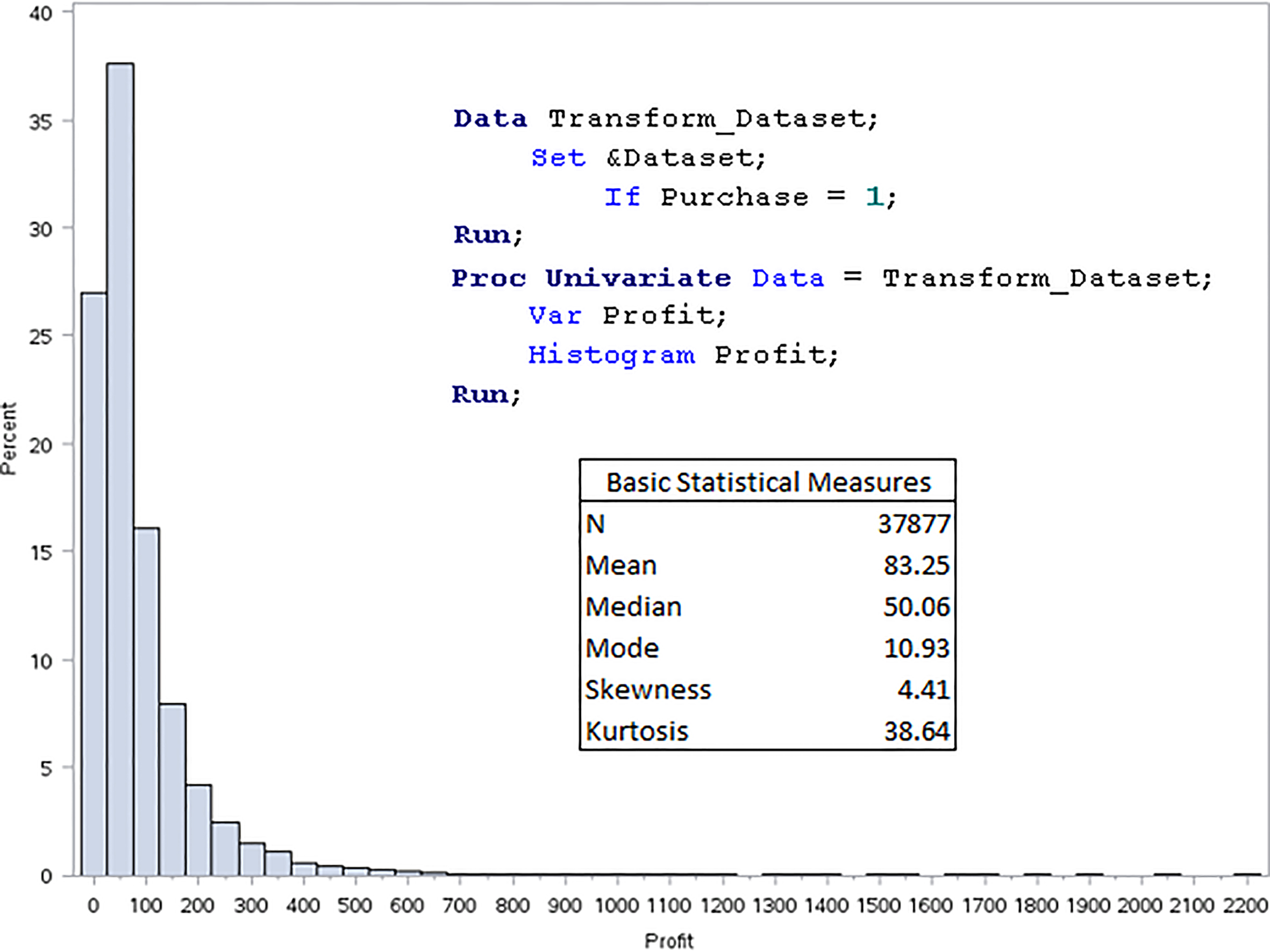
Log transformed profit distribution (purchaser only).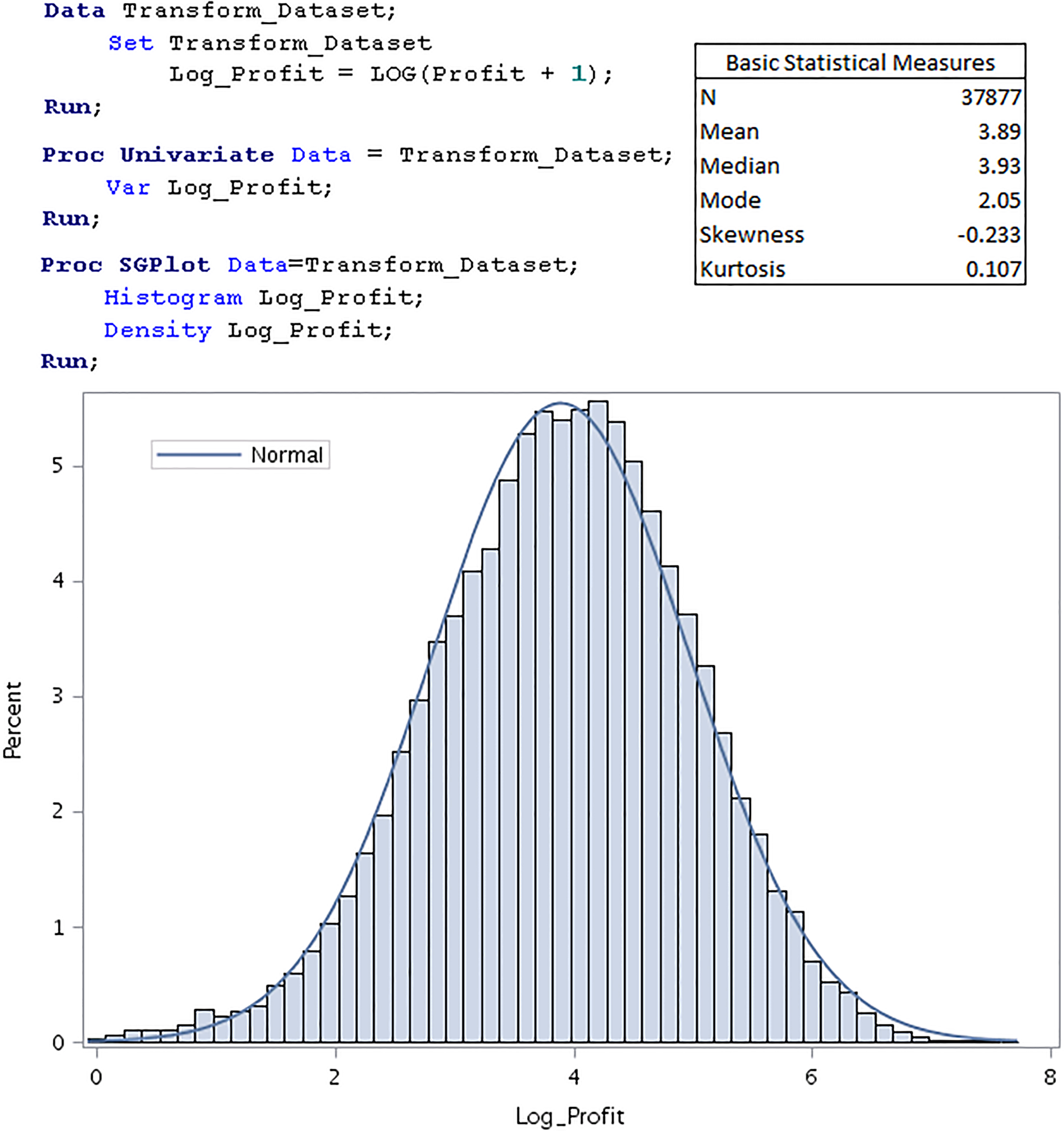
The data step and Proc Univariate routine in Fig. 4 serve to replicate the above but restrict the analysis to include only those customers who have made a purchase in the prediction period. The skewness and kurtosis figures have both come down but still not close to zero; the mean (83.3) and median (50.1) have even gone further apart. Again, such target distribution may still not be ideal for predictive modeling purposes.
To further mitigate the skewness problem, a logarithmic transformation: Log (Profit
One may want to understand that the logarithmic transformation also helps to restrict the predicted conditional future profit to be non-negative (see Step 4.2). On the other hand, the normality of the log-transformed Profit makes the un-logging process in Step 4.2 to be simpler (see Eq. (5) in Section 3.2.3.3).
This exploratory analysis together with Sections 2.1 and 2.2 suggests the following steps to be undertaken towards the prediction of future profit.
Build Model 1 using the modeling dataset (Purchase: Not Purchase Build Model 2 using the Purchase group (i.e. records with Purchase Use the confirmed Model 1 built to score (i.e. predict) the targeted audience of interest. Adjust (i.e. undo under-sampling) the scored probability, and this adjusted probability is the likelihood of future purchase Use the confirmed Model 2 built to score the same targeted audience. The scored profit, in log- transformed status, is then to be unlogged to obtain the desired conditional future profit, and this is the $ Profit as shown in Fig. 1. Calculate the expected future profit which equals
This section uses SAS
A process flow diagram for modeling the likelihood of future purchase and future profit.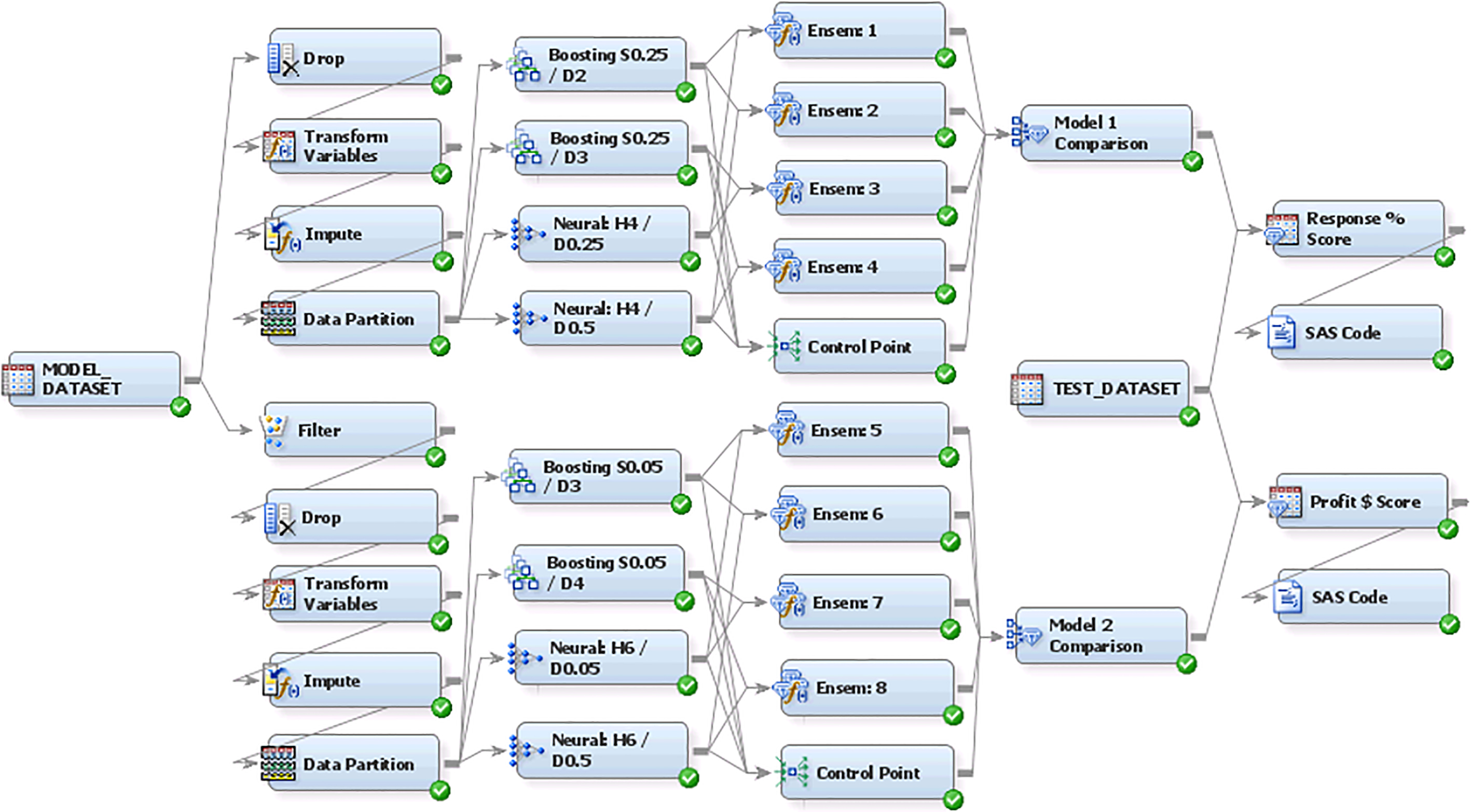
Data
For the first data node: Model_Dataset, the role of the data source is set as Raw. The variable: Purchase is set as a binary target (Role
Transform variables
In each of the two nodes, all interval input variables are set as “Best” for the method of transformation. This method tries all the available built-in alternatives (i.e. log, inverse, binning, etc.) and selects the one that the transformed input has the strongest R Squared relationship with the target. All binary input variables are set as “Default”, meaning no transformation. For the upper node, the binary target is set as “Default”; and the interval target in the lower node is set as “Log”.
Impute
In each of the two Impute nodes, all binary and interval input variables are set as “Tree” as the missing value imputation method.
Data partition
For each of the two nodes, the dataset is split into Training and Validation in the proportion of 50%–50%.
Gradient boosting
For all nodes, the assessment measure is set as “Average Squared Error”. Different combinations of the shrinkage constant (S) and maximum depth (D) have been experimented, and no vigorous attempt has been made for intensive hyper-parameter optimizations.
Neural network
For all nodes, the model selection criterion is set as “Average Squared Error”. Different combinations of the number of hidden units (H) and weight decay constant (D) have been tried, and again no attempt has been made for vigorous hyper-parameter optimizations.
Ensemble
The default “average” ensemble method is used for all ensemble nodes.
Model comparison
The model selection statistic is set as “Average Squared Error” for both Models 1 and 2.
This sub-section displays the final model comparative results. In both the Models 1 and 2 scenarios, Neural Network performs better than Gradient Boosting; and all ensemble models (Ensem: 1 to Ensem: 8) outperform individual Neural Network and Gradient Boosting models.
In determining Model 1, Ensem: 3 (Boosting S0.25/D3 and Neural H4/D0.25) gives the lowest validation average squared error (Table 3) and is therefore selected as the model winner for the prediction of likelihood of future purchase. For Model 2, Ensem: 8 (Boosting S0.05/D4 and Neural H6/D0.5) records the lowest validation average squared error and therefore becomes the model winner for the prediction of conditional profit.
Model performance comparison for determining Model 1 and 2
Model performance comparison for determining Model 1 and 2
Model 1 and Model 2 have been individually validated (e.g. via ROC chart, cumulative lift and mean predicted curve) with the validation datasets sampled in their corresponding Data Partition nodes (see Fig. 6). The details are not discussed in this paper. Alternatively, this section primarily attempts to use another holdout dataset (TEST_DATASET) to examine the joint validity of Model 1 and Model 2 in the prediction of future profit. This will involve scoring the TEST_DATASET (Step 3.1 and Step 4.1), adjusting the predicted probability (Step 3.2), re-engineering (un-logging) the conditional transformed future profit (Step 4.2), calculating the predicted future profit (Step 5.0), and building decile charts (to be illustrated).
3.2.3.1 Scoring
Each of the 73,075 observations in the TEST_DATASET is scored by Model 1 and Model 2 separately. Two data steps are written within their corresponding SAS Code nodes (Fig. 6), one for creating a data table (Scored_Purchase) to store the unadjusted purchase probability (i.e. “EM_EventProbability”) as predicted by Model 1, and the other one for creating another data table (Scored_Profit) to store the conditional transformed future profit (i.e. “EM_Prediction”) as predicted by Model 2.
3.2.3.2 Adjusting the scored probabilities
Since the majority group (Not Purchase) has been under sampled (see Table 1) to bring up the proportion of “Purchase” from 21.0% (a sample reflecting the entire population) to 50.0% (a biased sample) for modeling purposes, the scored probability needs to be adjusted. If the proportion of “Purchase” and “Not Purchase” in the representative sample are known to be
where
the adjusted probability of “Purchase”:
3.2.3.3 Un-logging the scored profits and predicting future profit
A new dataset (Model_Purchase_Profit) was compiled. The process merged the two scored datasets (ReScaled_ Purchase and Scored_Profit). It also calculated and stored the predicted future profit: “Predicted Future Profit”. Given
Those who are interested in Eq. (5) may refer to Malthouse (2013, p. 136) for more detailed explanation. In our scenario, the scored profit is an estimate of the mean, and the square of the standard error of the estimate
where SP is the scored profit (i.e. “EM_Prediction”), and the validation average squared error (or mean squared error “MSE”): 0.73944 from the Model 2 winner (Ensem: 8) has been taken as the
3.2.3.4 Construction of semi-decile charts
The table: Model_Purchase_Profit is then merged with the original TEST_DATASET to form a table: Model_Vs_Actual. This new table now stores the predicted probability of purchase: “ReScaled_Prob” and the “Predicted Future Profit”, as well as their corresponding sampled actuals (“Purchase” and “Profit”). One would naturally want to compare these predicted values versus actuals for the purposes of validation. This can be achieved by using some form of decile table. Since the sample size is large enough, semi-decile (i.e. 20 ranks) is used instead. The validation results are displayed in Tables 4 and 5.
Semi-decile table for the probability of purchase
Semi-decile table for the (unconditional) predicted future profit
In each semi-decile in Table 4, the average Model probability and the Actual proportion of purchase is very close (i.e. accurate). The Actuals give a monotonic decreasing pattern down the semi-decile. There is also a high differentiation in Actuals between the top and bottom semi-decile. All these are good signs, suggesting that Model 1 is of high validity for the prediction of probability of purchase.
Table 5 shows that the average Model profit (i.e. “Predicted Future Profit”) is also quite close to the average Actual profit in each semi-decile, albeit the fact that the accuracy does not visually appear to be as good as the case for the prediction of probability of purchase. The monotonic decreasing pattern down the semi-decile as well as the high differentiation in Actuals between the top and bottom semi-decile both also look very positive. Again, all these suggest that the combined effort of Models 1 and 2 has resulted in good validity for the prediction of future profit.
Each measure MAE (mean absolute error) is quite sizable and comparable to its corresponding Model and Actual values. The high variance reflects the fact that there is a high proportion (79.0%) of zero-value Actual observations whereas each Model value is always above zero. This may suggest that while the future profit can be individually predicted, it is better to be aggregately presented and interpreted in the segment level.
This paper has illustrated a methodological framework for predicting the future profit for customer purchases of non-contractual products. The skewness of the profit distribution has been demonstrated and a two-stage model was proposed. Stage 1 has produced an ensemble model: Model 1, which is consisted of a Gradient Boosting (with Shrinkage
Managerial and research implications
While the presented methodological framework in this paper is extendable to cover a longer lifetime horizon, management may find this first-period focused version to be applicable in their business planning.
It is not uncommon for any business to focus on a shorter time frame, especially during the annual budgeting period. The proposed one-year focus can help the business to estimate the aggregated one-year average predicted future profit for any customer segment of interest. It is not easy to evaluate the external validity of a lifetime value or longer-term prediction model in real life. In general, management is not in a position to wait for a few years (e.g. 5 years) to confirm the model accuracy, and some businesses may not even have a few years of customer history for a longer-term prediction. A one-year period is more affordable and feasible. Marketing may want to evaluate and compare the values of customers acquired from different channel sources (e.g. search engine, social media and affinity program) in order to better allocate marketing budgets. A business intelligence report showing the aggregated average one-year predicted future profit by acquisition sources would give appropriate direction.
Researchers and analysts may continue to extend the current methodology to suit their business applications.
A two-stage model was found to be appropriate in the current analysis. In fact, some businesses may involve an analysis universe that is better represented by more than two component populations (e.g. non-buyer vs seasonal buyer vs non-seasonal buyer), and this may call for fitting a more complex model. The author of this paper has prior understanding that neural network and gradient boosting work well with the customer base of the used business setting. In practice, researchers may need to experiment other data-mining techniques to work out a good ensemble model to suit their businesses. The final profit assessment of the ensemble model in this study is primarily based on the semi-decile table (an aggregate measurement method), and it was found that the MAE (an individual-level measurement method) is quite high (due to the excess zero profit). Researchers may continue exploring better ways to improve the prediction accuracy in the individual customer level.
Footnotes
Acknowledgments
The author is grateful to Professor Manoj Agarwal, Binghamton University, SUNY, for the review of this paper.
Operational definitions
Future profit – The profit that a customer (without prior knowledge as to whether he will make a purchase) would generate during a time-period in the future, and is the primary item for prediction in this analysis. Conditional future profit – The profit that a customer would generate during a time-period in the future given the customer would make a purchase. Expected future profit – This is a statistical quantity after the adjustment of non-purchaser bias, and this quantity is used as the prediction of the future profit in this study. Likelihood of future purchase – This refers to the probability of purchase in the future time-period. Customer lifetime value – This is a marketing term which refers to the total profit a customer generates during his entire lifetime. It is often loosely taken as the prediction of residual lifetime value counting from a particular point in time onwards, or defined as the profit generated during a longer period of time in the future. It is to be used interchangeably with customer value in this paper. Neural network – A predictive data-mining technique that emulates a biological neural network of the human brain. It is based on a collection of connected nodes (like neurons). The network is trained to perform a particular function by adjusting the values (weights) between connected nodes. Gradient boosting – A predictive data-mining technique based on a series of models developed in the sequential (vertical) manner. When confined to tree based models, the tree created in the sequence uses the residuals from the tree created in the previous step as the target. Ensemble – A method in combining different data-mining techniques to attempt to reach better predictive accuracy.