Markov regime switching models remain enormously popular in speech recognition, economics, finance, etc. Nonparametric segmentation in switching models without probability assignment of jump moments is in many papers by Brodsky and Darkhovsky. We model all regimes as long SCOT strings. Stochastic COntext Tree (abbreviated as SCOT) is -Markov Chain (-MC) with every state of a string independent of the symbols in its more remote past than the context of length determined by the preceding symbols of this state. A parallel super-fast fitting and asymptotically optimal inference in a sparse SCOT model including the nonparametric homogeneity test are described in our previous papers. Our segmentation method is a combination of preliminary online change point detection with its subsequent offline Maximal Likelihood update.
Approximability of mixing stationary sequences by -MC with large belongs to the mathematical folklore and is widely used without rigorous definitions in the Information Theory, see Cover (2006). In view of exponential complexity of general -MC, ARMA-models were their popular surrogates until sparse memory -MC named VLMC was introduced in Rissanen (1983) for compression aims. We discuss conditions for sparse -MC approximation of strong mixing stationary sequences called Stochastic Context Trees (SCOT) in Section 2. Parameter in sparse SCOT introduced in Section 2 depends in general on accuracy of the approximation and can be arbitrarily large, even infinite, making this process not Markov. Thus, this alternative name is appropriate to VLMC (which is much wider used for a video editor). An alternative apparently less powerful and flexible model is Markov Chain of Conditional Order, see Kharin and Maltsau (2014).
The ergodicity of Markov Chains (MC) and Asymptotic Normality (AN) of additive functions of their paths has been subject of numerous studies starting from the pioneering works of Markov and Bernstein in the beginning of 20th century. Among many popular surveys – Borovkov (1998); Meyn (1993); Tutubalin (1992); Veretennikov (2000). Statistical inference for MC has become popular after Billingsley (1961); Roussas (1972). The second of these references introduced the MC Local Asymptotic Normality (LAN) following the Le Cam-Hajek asymptotic locally minimax inference theory. An elementary exposition of this theory is in Veretennikov (2000). Our Section 5 outlines a simpler straightforward LAN derivation for finite MC following (with some revisions) Tutubalin (1992); Veretennikov (2000) rather than the popular much longer CLT reduction to the more general Martingale CLT. The latter approach involves a cumbersome Poisson-like inverse problem solution which is not straightforward (Meyn (1993); Veretennikov (2000)).
Ryabko (2016) and finally Zhang (2017) established the equivalence of a perfect memory sparse SCOT to 1-MC with state space consisting of the -MC contexts which we call new alphabet of cardinality . For not perfect memory sparse SCOT, its perfect memory sparse envelope also studied in Zhang (2017) plays this role, see an outline in Appendix 3. The perfect memory condition does not depend on prediction probabilities assigned to the leaves of SCOT.
A substantial part of the present paper deals with statistical properties of 1-MC. The statistical theory of SCOT cumbersome calculations requiring a sophisticated software is covered miraculously by the classical 1-MC theory with somewhat larger alphabet size under perfect memory.
Thus, by first applying UA--MC and conditions, we reduce a stationary sequence to an -MC with sparse memory structure, and reduce it further to a 1-MC with alphabet .
Our statistical SCOT modeling (Ryabko, 2016; Malyutov et al., 2013) of financial data discovered a small size of the context tree, while literary texts showed the adequate number of SCOT contexts around 2000.
This application suggests a modified asymptotics for deriving AN of additive SCOT functions for moderate sample sizes. An example in Appendix 1 illustrates this phenomenon by the spectral decomposition of cyclic random walks derived in Feller (1967), pp. 377–378 and 434–435.
The large asymptotics can be studied in future by the first order Edgeworth-type expansion for the additive functions developed for IID , observations. The principal multiplier of the residual term may grow with which worsens the precision of approximation. Here are the stationary third moment and standard deviation of respectively.
Section 8.1 justifies SCOT homogeneity testing (HT) results of Ryabko (2016) and Malyutov et al. (2013) and Section 9 HT applications in the framework of local (contiguous) alternatives theory under LAN. Testing very distant alternatives was exposed earlier in Ryabko (2016) and Malyutov et al. (2013) for an example of screening out active inputs of a multivariate regression model with colored noise using the large deviations probability results. Estimation and testing in Section 9 of transition probabilities in sliding windows is aimed at distinguishing abrupt changes in SCOT model from its small deviations.
The speed up of SCOT training of the sparse -MC with a large alphabet size or for multichannel online SCOT training prompted our novel development of a parallel implementation Malyutov and Grosu (2017) of the algorithms developed earlier in Rissanen (1983) and Mächler and Bühlmann (2004) et al., see a brief outline in Section 12.
HMM model for speech recognition
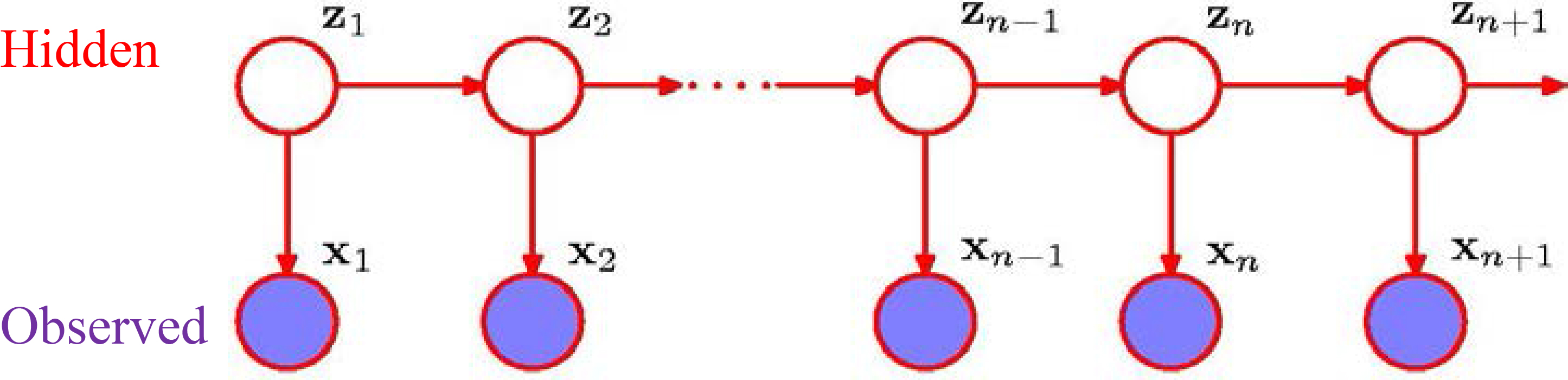
The Hidden Markov Model (HMM) is the simplest regime switching model with all regimes consisting of random strings called emissions. Emissions are INDEPENDENT (mutually and of HMM) with distribution depending on the current HMM state.
Speech is modeled (Baum et al.) as a sequence of emissions – phonems – random variables . Observed state depend only on current hidden letter of text which sequence is modeled as a Markov Chain.
We refer to as hidden states, see the Plot 1 below. Inference about the parameters of the model and hidden MC uses only the observed
The fast Baum-Welsh fitting HMM parameters has been successfully applied to speech recognition Rabiner (1989). Its application to Genome modeling Durbin (1998); Yoon (2009) by assigning IID emissions to the same part of Genome seems not justified. Markov switching models generalize HMM by considering parametric regimes (Hamilton, 2008; Cappe, 2005). Nonparametric segmentation in switching models without probability assignment of jump moments is in many works by Brodsky and Darkhovsky, see Brodsky (1993). We develop a model of slow HMM with SCOT emissions (SCOT-HMM) which seems a more realistic model for Genome, economics, analysis of combined authorship of literary works, or financial time series with piecewise volatility. We discuss in Malyutov (2017, 2012) approaches to SCOT-approximation of mixing sequences enabling consideration of mixing emissions.
Slow HMM-SCOT emissions model
We call HMM SLOW, if mean time that HMM keeps staying in the same state is proportional to a large parameter in all states, while the sample size is . Emissions shown in dark in the following Fig. are modeled as STRINGS of MC over the space of contexts with transition matrix depending on the current HMM state.
.
Our HMM-SCOT model has nothing in common with VLMCHMM which analyzes independent emissions under a SCOT model for HMM Dumont (2014).
The emissions MC over the alphabet of SCOT contexts are assumed ergodic, different for all states of HMM, expectations are taken everywhere under their stationary distributions.
Our segmentation method is a superposition of preliminary online change point detection with its subsequent offline Maximal Likelihood update. The online and offline parts are nontrivial modifications of IID case in Korostelev (2011) using alternative risk function to that in Shiryaev (1978).
HMM-SCOT scheme.
Appendices 2–4 outline respectively a parallel SCOT training algorithm Malyutov (2012), perfect memory and statistical simulation of the first Change Point (CP) detection.
Approximation by SCOT
Approximation of strong mixing sequences by -MC with large belongs to the mathematical folklore and is widely used without rigorous definitions in the Information Theory, see Cover (2006). We consider a strictly stationary process over an alphabet and discrete time: , with potentially infinite memory which can be approximated uniformly by an -Markov chain (UA--MC condition).
By this we mean that for any 0 there exists a positive integer 0 such that
for almost every and past sequences .
.
Apparently, a uniform version of exponential memory decay absolute mixing (attributed to A.N. Kolmogorov in Volkonskii (1959)) can guarantee a uniform approximation by an -MC.
Numerous conditions of strong mixing sequences are reviewed in Bradley (2005). Assume now the UA--MC condition of a stationary sequence and fix of the approximating -MC which is assumed ergodic. Sequences are called -grams. Let us introduce contexts for each of different realizations of -gram.
The context to is its final part of minimal length such that the conditional distributions , do not depend on prefix up to joint error probability . This statement is described by simultaneous validity of obvious double inequalities. Not occurring -grams are ignored.
To streamline introduction, we assume that there are no such -grams. Such a twice approximated stationary sequence will be called -SCOT with small abuse of notation.
Finally, the memory spectrum is the -vector of context lengths along all paths from the root to the past.
We combine all preceding developments into the following:
.
If a UA--MC has a memory spectrum , then is an -SCOT with the corresponding context length distribution.
We say that has a sparse -MC representation, if the average over steady state distribution of context lengths satisfies:
Widespread sparse processes in nature phenomenon are explained by the ‘Occam razor’ or ‘Bottleneck’ popular philosophical principles.
The median, or a quantile collection, or other functions of over the stationary distribution can be also used for defining sparsity.
Many examples of stationary distribution evaluation in various SCOT models are in Ryabko (2016).
We develop further asymptotic theory for fixed and large sample size and, therefore, for a finite ergodic MC assuming 0 in previously outlined more general approximations.
Thus, by first applying UA--MC and conditions, we have reduced a stationary sequence to an -MC with sparse memory structure, and finally reduce it further to a 1-MC with a larger alphabet .
An ergodic Hidden Markov Model (HMM) is the simplest regime switching model with all B regimes consisting of sequences of random variables called emissions. We call it SLOW, if all transition probabilities to stay in the same state are , where is a large parameter and the sample size is . Emissions are modeled as independent of HMM MC over the space of contexts with transition matrix depending on the current HMM state .
Introduce stationary log-likelihoods and entropy of SCOT():
The emissions MC over the alphabet of SCOT contexts are assumed ergodic for every state of HMM, expectations are taken under their stationary distributions which are assumed strictly different for all .
Given a long string with a vast collection of -grams, the probability distributions can be approximated with their corresponding consistent frequencies. This allows the sparse MC consistent training dealt with in Galves (2008); Bühlmann (2004); Rissanen (1983). A version of SCOT training on a cluster of computers valid for a large alphabet , is described in our Section 8. A fitting algorithm has been proved to be consistent for mixing sequences in Rissanen (1983) and used for compression. A somewhat confusing abbreviation VLMC (which is more widely used for a video editor) has been initially chosen for SCOT. For completeness, we display in Section 2 a sketch of the Context algorithm consistency from Galves (2008) admitting horizon and the sample size . A popular software Bühlmann (2004) implementing the Context algorithm of Rissanen (1983) assumes a fixed horizon as . We sketch simplifications in proving consistency under this assumption.
Consistency of SCOT training
is the joint empirical distribution of .
For a node is the conditional empirical distribution of given , where denotes the string .
The Empirical Shannon Information (ESI)
where of node in the string.
Test of Rissanen (1983) chooses as contexts such nodes that .
Consistency proofs of SCOT contexts estimation of Rissanen (1983) and his followers has admitted possibly growing as maximal context size (horizon) for sample size .
To prove that the estimate of the length of context is the true one, they upper bound the probability of the opposite event by
Rissanen proves that the first term is bounded by .
The second term goes to 0 due to the ergodicity of the time series concluding the proof.
Consistency under fixed horizon
To simplify the proof and sketch the rate of consistency and conditional accuracy of prediction distributions assignment in the contexts, we use more practical assumption of fixed maximal context size const as . We assume that the minimal cross entropy between the prediction distributions at nodes of the memory tree immediately preceding the context or following context exceed 0. Then, fulfilling inequality is a large deviation with exponentially small in probability. The Bonferroni bound means multiplication by a fixed under multiplier and does not affect the exponential decay of the error probability. Conditional to the correct decision about a context, the prediction distribution in the root given the context has a degenerate multivariate normal distribution estimated by .
.
Assuming a finite horizon can be interpreted as follows: we replace the original -MC with another one. Its conditional probabilities are replaced with averages of the original ones over their stationary distributions with respect to the tails of length exceeding . Due to exponential memory loss of regular stationary processes, this approximation seems appropriate.
Auxiliary material
Ergodic theorems for finite homogeneous MC
The Ergodic Theorem (ET) for finite homogeneous MC formulated below as Definition 1 is first proved in Markov (1906).
.
An MC over state space of cardinality is called ergodic if either of three equivalent sets of conditions hold:
Existence of such that all entries of are strictly positive (where , is MC transition matrix, -B-column of ones), or
MC is irreducible and aperiodic, see Feller (1967), or
The transition measures in jumps have a limit in total variation, which is a probability measure and this limiting measure does not depend on initial state .
Recall that the total variation distance between two probability measures is .
The following is apparently the shortest ET proof via the contraction principle:
The hyperplane is invariant w.r.t. multiplication by from the right: .
, and 0 due to item 1 of ET.
Namely: .
Taking first , we get .
This inequality holds for due to . Thus, exponential bound holds and proof is complete.
A better exponential inequality was derived by Doeblin.
Large Numbers Law (LLN) for additive state functions (Markov, 1906)
Under the assumptions of ET, for any and function on , LLN holds: converges -weakly to , see elementary proof e.g. in Veretennikov (2000).
stands for the expectation of with respect to the stationary measure, while denotes the measure, which refers to the initial value or distribution of .
The MGF derivation of exponential convergence rate in LLN for more general additive transition functions (ATF) and their asymptotic Normality (AN) use the powerful classical Theorem of Perron (PT). Any quadratic matrix with all entries positive has a positive simple eigenvalue called its spectral radius, which is strictly greater than the moduli of the rest of the spectrum, ’s corresponding eigenvector has all positive coordinates.
Exponential rate in LLN and asymptotic normality of ATF
MGF of ATF
Let be B-column consisting of ones. For a real number , introduce a new matrix with entries and start with an elegant expression of ’ moment generating function (MGF):
The proof with small gaps of insufficient for our aims particular case of depending only on its second argument (additive state function (ASF)) is displayed in Tutubalin (1992), pp. 230–232, and erroneously attributed there to Markov. The origin of this formula remains unclear to us. Markov actually used a cumbersome method of moments for deducing AN of . We omit the detailed derivation of this formula. It is straightforward via sequential conditioning: At first , then similar conditioning on , etc.
.
Another proof of Eq. (3) generalizes Veretennikov (2017) for ATF. Introduce operator family mapping real functions on into similar ones:
We have
Putting 1, we get Eq. (3) for 2 and arbitrary initial . Extension to arbitrary is by induction.
The Perron theorem implies that as .
is a convex function of as a linear combination of exponentials with nonnegative coefficients.
To simplify further exposition, we assume that all entries of (and therefore also of ) are positive. In view of ergodicity of , this is certainly valid for some power of , (see Feller, 1967), which is sufficient for proving our asymptotic results. Thus, is also strictly positive. The PT implies isolated maximal eigenvalue-spectral radius of existence. Due to analicity of and the theorem of implicit functions, this unique root of the equation
is an analytic function of in a neighborhood of 1. Attached to eigenvalue are row eigenvector and column eigenvector as 0 infinitely smoothly depending on , with unit scalar product. This follows from the fact that each of and are the solutions of non-degenerate linear system of equations with the same non-degenerate minor of . Then is such that is strictly smaller in matrix norm than for some 0 due to PT. Similarly, .
.
A standard Linear Algebra result implies existence of an invertible transformation such that admits the Jordan form decomposition with diagonal element and an additional term . Thus admits the Jordan form representation with diagonal and additional term . As a result, .
is shown to be negligible in our asymptotics derivation of .
Introduce .
Due to analycity of , which is the limiting mean of ATF. Indeed, it equals
The second summand is obviously bounded, while the third one is bounded from above by
Asymptotic normality
A normalized ATF shifted with time is obviously a stationary process converging to as . Tutubalin (1992, p. 234) , shows for ASF that at 0.
A similar result holds for a general ATF.
To prove the weak convergence to the limiting Normal approximation (possibly singular) under usual normalization for centered ATF, we evaluate the first and second derivative of its normalized ‘reduced’ MGF at 0.
The latter boils down to
Terms involving the first derivative of the centered normalized vanish at 0 due to centering, say, 0, , we assume that 0, see details in Tutubalin (1992). Only one term remains after neglecting as in the preceding proof exponentially small terms involving :
as . This finishes the proof according to the classical Probability approximation theorems since the limiting MGF is that of the centered Normal distribution with variance .
.
We use further a multivariate version of the above AN theorem which proof generalizes naturally the above univariate case. The principal multivariate example is the log-likelihood ratio vs. the vector of alternatives. The covariance matrix of the limiting Normal distribution replaces in the above statements.
.
The most popular derivation of the CLT for MC nowadays is based on a reduction to the more general Martingale CLT which requires rather cumbersome approximations to the Poisson inverse-problem-like solution which is not straightforward (see e.g. Meyn, 1993; Veretennikov, 2017). The proof (see Tutubalin, 1992, pp. 236–237) of the AN of normalized additive ASF functions via applying twice the L’hospital’s rule to its MGF is pretty standard given our representation of its MGF and rather similar to that in the IID case, see e.g. Snell (2006). Our proof for ATF based on Eq. (3) is essentially the same.
Of some interest is that the limiting distribution under standard normalization can be singular due to the null limiting variance.
As a consequence, in this case there is no need for normalization, and the residual distribution is bounded.
A simple example of such anomaly for additive state function is the symmetric cyclic RW with four states and equally likely transitions to each of two neighbors, and alternating function between neighboring states. Values 1 necessarily alternate also in time killing each other. Thus 0, while 1 for all and the standard normalization provides the limiting null variance.
Martingale lemmas for log-likelihood
Likelihoods , are martingales with respect to -algebras generated by MC observations , see Shiryaev (1978). Log-likelihoods are super-martingales as concave functions of martingales (see Shiryaev, 1978) and thus admit the Doob-Meyer decomposition with martingale , while compensators are -measurable (‘predictable’).
Further, as a convex function of is a submartingale for .
Exponential rate of ergodicity
Here we derive functional exponential bounds for both martingale and compensator parts of the log-likelihoods for application in Change Point detection.
1. The functional version of the ergodic theorem for the compensator is the following:
If we consider its latest of summands , then due to a long past of length the underlying distribution of can be taken as .
.
If , then absolute deviations of compensator from its mean exceed an arbitrarily chosen 0 only a finite number of times.
Proof..
. Thus, due to Eq. (3) and Taylor decomposition of the exponential function, MGF of is .
The exponential Markov inequality applied twice for and the Bonferroni bound yield that the maximal absolute deviation on the interval has exponentially small probability.
It remains to apply the Borel-Cantelli lemma to finish the proof. ∎
2. is a martingale. The Doob’s maximal inequality for submartingale implies:
for every . Now we find the appropriate and .
By the MGF formula, Section 5.1, , where .
The mean . Let us optimize an exponential bound for the maximal deviations of from its mean.
We have: .
Bound optimization over parameter .
Introduce , . Then under ET, it holds:
The convex smooth Legendre transform of function is semi-continuous and positive for sufficiently small if 0.
The above inequality and the same inequality for imply inequality for the absolute deviation.
Proof is obtained via the Doob maximal martingale deviations and standard optimization in exponential Markov inequality, see e.g. Veretennikov (2017) or Gallage (2013), p. 410.
We choose in application to the online Change Point detection in Sections 9.2 and 9.3. It follows from the preceding development that the maximal absolute deviation of on an interval of length is is chosen to guarantee only finite number of violations of the absolute deviation bound according to the Borel-Cantelli lemma.
The functional CLT (see e.g. Biscup, 2011, Theorem 2.11) states: if the conditional mean squared increments of square-integrable martingale satisfying Lindeberg condition converge to a const, then weakly converges to a Brownian motion under appropriate normalization. Conditions above are easily verifiable,
The local asymptotic normality of SCOT
Given the context tree, denote the set of SCOT root-prediction probabilities satisfying natural normalization conditions by . Their cardinality is with normalization conditions. We prove that the corresponding family of probability distributions id regular in the LAN-sense.
The principal role in the LAN proof is played by the multivariate AN of log-likelihood ratio as an example of multivariate ATF function (see Section 4). For simplicity we assume that all entries of are positive.
The Local Asymptotic Normality (or simply LAN) introduced in Le Cam (1960) is the following decomposition of the local log-likelihood ratio
where , is the limiting covariance matrix of ’s AN approximation assumed invertible, is called the Fisher information matrix. And converges in - probability to zero.
Proof..
Applying the Taylor expansion of the second order
where
Now, weakly by CLT, Section 5.2, by LLN, Section 5.3, since and again by LLN, Section 5.3. ∎
This expansion for a univariate parameter is proved in Veretennikov (2000) referring to a much more involved exposition in Roussas (1972) for the AN proof of the log-likelihood ratio in general case under standard regularity conditions.
The uniformity of the residual convergence in - probability to zero can be proved by the more elegant Lagrange-type integral representation of the second order residual in the Taylor expansion as in Malyutov (2002). Namely, for all 0, 0
The local asymptotic minimaxity of the likelihood-ratio-like tests
We introduce the Local Asymptotic Minimaxity (LAM) and the Locally Asymptotically Most Power (LAMP) of the likelihood based inference and of its certain approximations. It is implied by the LAN condition outlined in Section 6. Informally, the LAM in parameter estimation means that the deviation of the estimate from the true parameter value is asymptotically as minimal as possible in the local minimax sense.
Let the distribution family satisfy LAN condition in with the identity Fisher information matrix, be the Euclidean norm. A function is called bowl-shaped if are closed bounded symmetric convex sets for any . An increasing continuous bowl-shaped function , 0, is called a loss function.
The fundamental Hajek’s lower bound for the LAM-risk of any estimate for any loss function and 0:
holds. In general, the positively definite Fisher information determines the norm in the risk function definition.
The LAM property of the Maximum Likelihood (ML) estimate and of the Fisher score update to ML given a qualified consistent prior estimate for are exposed in Veretennikov (2000); Roussas (1972). Malyutov (2002) shows sufficiency of a usual consistent estimate for for LAM of the Fisher score update given the uniform LAN property.
The third Le Cam’s lemma (Chibisov, 2009; Roussas, 1972) proves that the AN of a statistic under the null hypothesis implies its AN under the alternative distribution provided contiguity and the LAN condition.
Locally asymptotically optimal tests
The most transparent overview of the Locally Asymptotically Most Powerful (LAMP) tests under LAN condition for I.I.D samples is in Chibisov (2009). Given LAN property, it differs insignificantly from the one for MC in Roussas (1972).
The main distinction of the LAMP approach originated in Le Cam’s works from the traditional one, is that the ‘close’ alternatives are considered for the sample size . This enables limiting positive significance level and power asymptotically and a transparent application of the familiar testing shift theory for multivariate Normal. We now give schematic simplified overview of this theory following Chibisov (2009) and shortening our notation for transparency in an obvious way.
The Neyman-Pearson lemma gives the most powerful test of significance level against alternative as
with parameter determined from equation .
The LAN condition converts this into the asymptotic equality which is equivalent to
The power of the test satisfies as implying
Thus, which means (see e.g. Chibisov, 2009, (8.1.19)) that the limiting asymptotic power of our test is asymptotically maximal for every given alternative in view of the Neyman-Pearson lemma. Thus, our test is LAMP.
Homogeneity testing
Let us apply the preceding theory to the homogeneity of multivariate distributions of the large strongly stationary ergodic training string and a query string . We use the nonparametric test of Malyutov (2013).
The first stage is estimation of the SCOT model of the string following the algorithm in Bühlmann (2004). We refer to this publications for the details.
We assume
The ’s and ’s are well-approximated by a sparse SCOT with Perfect Memory and
the LAN condition is fulfilled for the equivalent 1-MC over the space of contexts.
cut the query string into slices of the same length. Then, using the SCOT model of we find the log-likelihoods of query slices and of strings simulated from the training distribution of the same size as (for constructing simulated strings, see e.g. algorithm in Bühlmann, 2004).
We then find log-likelihoods of , of using the derived probability model of the training string and the average of their difference which approximates the likelihood ratio statistic discussed above. The averaging over slices is used for empirical evaluation of the log-likelihood variances since our testing homogeneity problem is completely nonparametric.
We assume though that the multivariate distributions of the training and the query strings are contiguous. In particular, for literary applications this assumption means that both texts are written in the same language, and admissibility of texts is the same for and .
Next, due to the asymptotic normality of log-likelihood increments both for the null hypothesis and alternative (third LeCam’s lemma), we can compute the usual empirical variance of and the t-statistic as the ratio with degrees of freedom (DF). We find from the empirical condition that is maximal. Then, the -value of homogeneity is evaluated for the -distribution with DF.
Comparison with GARCH on Apple log-returns
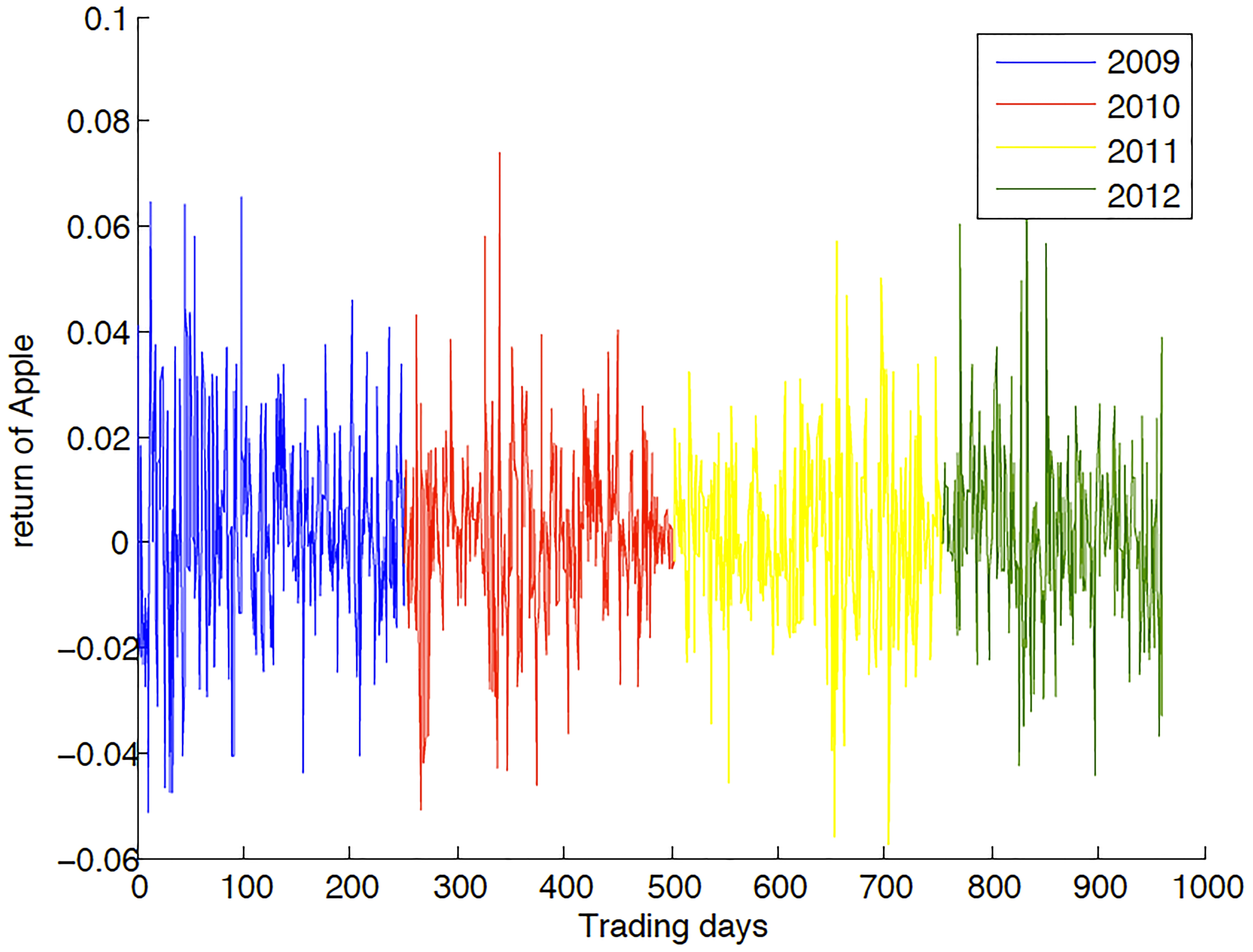
The first data set we use is the discretized in 27 bins daily log-return data of Apple Inc. starting from January 2, 2009.
Apple log-returns.
By observation, we pick the volatile region (the first 450 days returns) and the quiet region (the 500th to 600th days returns) to make a comparison. We first fit the data with the GARCH(1,1) modeled using the MATLAB(R2011a) GARCH toolbox. The -values obtained are 0.0311 and 0.0897.
We apply SCOTlr to the same data. The homogeneity -test between 1–450 and 500–600 (quiet and volatile regions) trained on 1–450 shows that the -value is 16.02058. Thus, the -value 0.00001. This -value by SCOT is dramatically smaller than the -score by GARCH.
Offline fitting Markov switching model
HMM model for speech recognition
Speech is modeled (Baum et al) as a sequence of emissions – phonems – random variables . Elements of observed sequence depend only on current hidden letters of text modeled as a Markov Chain. We refer to as hidden states, see the Figure above. Inference about the parameters of the model and hidden MC uses only the observed .
Slow HMM-SCOT emissions model
We call HMM SLOW, if HMM stays mean time proportional to a large parameter in all states, while the sample size is . Emissions shown in dark in the previous Fig. are modeled as STRINGS of MC over the space of contexts with transition matrix depending on the current HMM state.
Remark. Our HMM-SCOT model has nothing in common with VLMCHMM which analyzes independent emissions under a SCOT model for HMM Dumont (2014).
The emissions MC over the alphabet of SCOT contexts are assumed ergodic, different for all states of HMM, expectations are taken under their stationary distributions.
For notation simplicity we start with two-state ( 1) HMM.
Introduce stationary log-likelihoods and entropy of SCOT(( 1)): (( 1)) .
HMM-SCOT model fitting
As explained before, the SCOT emissions can be reduced to a MC on the alphabet of SCOT contexts.
We assume that diagonal elements of all hidden HMM transition probability matrices are and emission distributions are all different. Emission SCOT sequences are assumed transformable to ergodic MC over the same alphabet switching from a regime to alternative one at random CP time moments ; 0.
We estimate both emission regimes, all CPs and HMM parameters. Thus, the HMM jumps to an alternative state after spending asymptotically exponentially distributed time with mean in each state.
We modify the two settings of Change Point (CP) detection of IID sequences with changing mean 1 in Korostelev (2011). In their offline method, the quadratic risk of ML as a CP estimate does not exceed as the sample size due to certain exponential bounds. Their online method uses CP detection which is a point in the first -interval, such that the maximal absolute deviation of deviation in this interval becomes comparable with the absolute change of mean .
Our plan for online CP detection is to replace their IID-based inequalities with the Doob-Meyer decomposition-based bounds for the maximal absolute deviation of both the martingale and compensator parts separately. We use the exponential bounds obtained in Section 5.4. By implementing this program, we get the same order of quadratic risk as derived in Korostelev (2011) for IID case with changing mean.
.
A rougher estimates of the quadratic risk in online preliminary CP-detection can be obtained by a simpler quadratic maximum martingale deviation bound guarantying a larger window of order . It would require much larger risk and sample size, thus it is omitted.
Our algorithm uses repeatedly training (Section 12) the SCOT emissions in all regimes and homogeneity testing of Section 8.1.
To simplify notation, we first present our HMM-MC model with the two-state HMM ( 2).
Algorithm road map, two-state HMM
For notation simplicity we start with the two-state HMM ( 2, 1). Our algorithm includes:
Online estimation of the -transition matrix of 1-MC equivalent to SCOT-emission-regime, see Appendices 1 and 2.
After some initial period of online continuous improving the estimate, start online detection of the first CP in sequences of windows of size and find a preliminary first CP estimate. We show that its StD is .
The emissions from the time interval exceeding the CP estimate in , 0 are used for online continuous estimation of the alternative regime and next CP .
Using , estimates we update preliminary CP online estimates with the offline MLE. The offline MLE has StD .
Using the approach from the preceding item, we recurrently find estimates of all subsequent CPs and improve estimates of regimes 1.
Using all CP estimates, we get MLE of the HMM parameters.
Online CP detection
Given a 1-MC transition matrix in region 1, we carry on the CP online detection between regimes 1 and 1.
We choose such a window size that within window
where is the entropy difference between the current and alternative regime. A lower bound for is used if is unknown. This window size is evaluated using the maximal inequality for absolute value of martingale , Section 4.2. Our CP-detector is the first window when Eq. (5) occurs.
The Borel-Cantelli lemma implies that only finite number of events Eq. (5) occur under . As follows from section , the window size is which implies the same order of the standard deviation of our CP detector.
Offline CP detection
Our offline segmentation stage estimates time regions with constant HMM states using homogeneity test for SCOT emission strings and a preliminary online segmentation. This is made fast recurrently in parallel on a cluster of computers.
The offline CP detection follows after the online CP estimate is obtained. It starts with the SCOT training of the string after small delay of length . The homogeneity test verifies significance of new regime distinction from the previous one. The offline CP update of the preliminary online CP estimate is the location of the maximum of the log-likelihood function.
For simplicity of notation assume that the initial regime is and the time of the first CP is 0. Introduce a surrogate ‘log-likelihood function’ under ‘possibly false CP’ at time and show that is attained ata point .
Family is irregular and methods of Section 6 are inapplicable. First suppose 0 and is included into exactly two regimes 1; 0 belongs to the online CP interval estimate.
We have
where are regime transition probabilities and their logarithm.
Every summand in II has mean . Thus .
The case 0 is dealt with quite similarly resulting in equality . Both cross-entropies are positive.
The offline interval CP estimate can be updated in many ways including bification for iterative numerical finding .
It remains to bound its quadratic risk from above. The lower bound of the same order of magnitude follows from the IID case with changing mean in Korostelev (2011).
Lemma 1 implies that the compensators for are maximal at a point . Convergence of the normalized maximal absolute difference between the compensator and its mean to 0 follows from Lemma 1.
The functional CLT for the martingale component of log-likelihood Biscup (2011), Theorem 2.11, states that the normalized martingale sequence converges weakly to the Brownian motion. Our exponential bounds show that the maximal deviation converges to 0 also in .
The normalized left log-likelihood over negative times was proved in Section 5.2 to be asymptotically Normal with positive left slope and variance . Similarly, the normalized right log-likelihood of the reverted MC (which is also ergodic) over positive times has negative slope at 0 and variance . Thus, the quadratic risk of is in the weak convergence sense. The mean square convergence can be justified in a standard way.
The SCOT is proved to be LAN which implies that the same orders of quadratic risk remain valid when using the estimated SCOT parameters during search for CP.
HMM with finite number of states
Training SCOT for the general states slow HMM model such that all time means spent in states before jump are proportional to large parameter . Main steps of training are similar to the two HMM state case. Online change point detection is used before every jump to unknown state.
Main steps of training are similar to the two-states HMM case. Online change point detection is used before every jump to unknown state. It is followed by the SCOT training of the string using some delay after jump, where homogeneity is verified by homogeneity test and by the subsequent maximum likelihood offline change point update of the preliminary CP online estimate as above.
After all change points are safely estimated, parameters of HMM are ML-estimated based on their multivariate statistics.
HMM parameters estimation
If it is only known that all mean times spent in every state before jump are proportional to large parameter , we can estimate all HMM transition probabilities after detecting all jump times. The marginal HMM distribution is estimated via maximum likelihood applied to the joint CP estimates using obvious frequencies. Namely, denoting number of times is followed by 1, under the stationary initial distribution, the log-likelihood is (see e.g. Billingsley, 1961)
which yields the ML estimates
Thus, the average of empirical mean times before estimated jump from to any , serves as an estimate of mean time spent in , while transition probability from to any is estimated via the last formula or simply as the frequency of jumps from to out of all visits to .
Confidence band for HMM parameters
The above estimation of the HMM parameters is a regular statistical problem with non-degenerate Fisher Information matrix , the offline CP estimates are independent ‘observations’ with square risks of order not affecting asymptotics of the quadratic risk of ML-estimates. Thus asymptotically,
For large state space, iterative methods via Fisher scores are available.
Discussion and acknowledgments
Our display of modeling and asymptotic inference of strongly mixing stationary sequences differs drastically from the material presented in traditional courses on stationary processes and connects this discipline with the classical MC-theory. Our AN derivation for ATF, exponential bound for the martingale part of log-likelihood and its application for the online and offline CP detection seem new.
A challenging open problem is to prove accurate asymptotic results for MC alphabet rising simultaneously with the sample size.
Appendix 3 reviews results of Zhang (2017), several revised parts of Malyutov (2012) are used elsewhere in the text including a simulation prepared by Grosu. The author is deeply grateful to them for the long collaboration and help.
Footnotes
Appendix 1: Asymmetric cyclic RW
To illustrate what happens when both and sample size grow to infinity, let us consider the asymmetric cyclic random walk (RW).
The alphabet consists of equidistant circumference points , is the imaginary unit. The asymmetric cyclic random walk stays in the same state and jumps to the nearest left state with probabilities 1/2. Introduce . Equation (2.11) of Feller (1967) establishes the power of transition matrix spectral decomposition
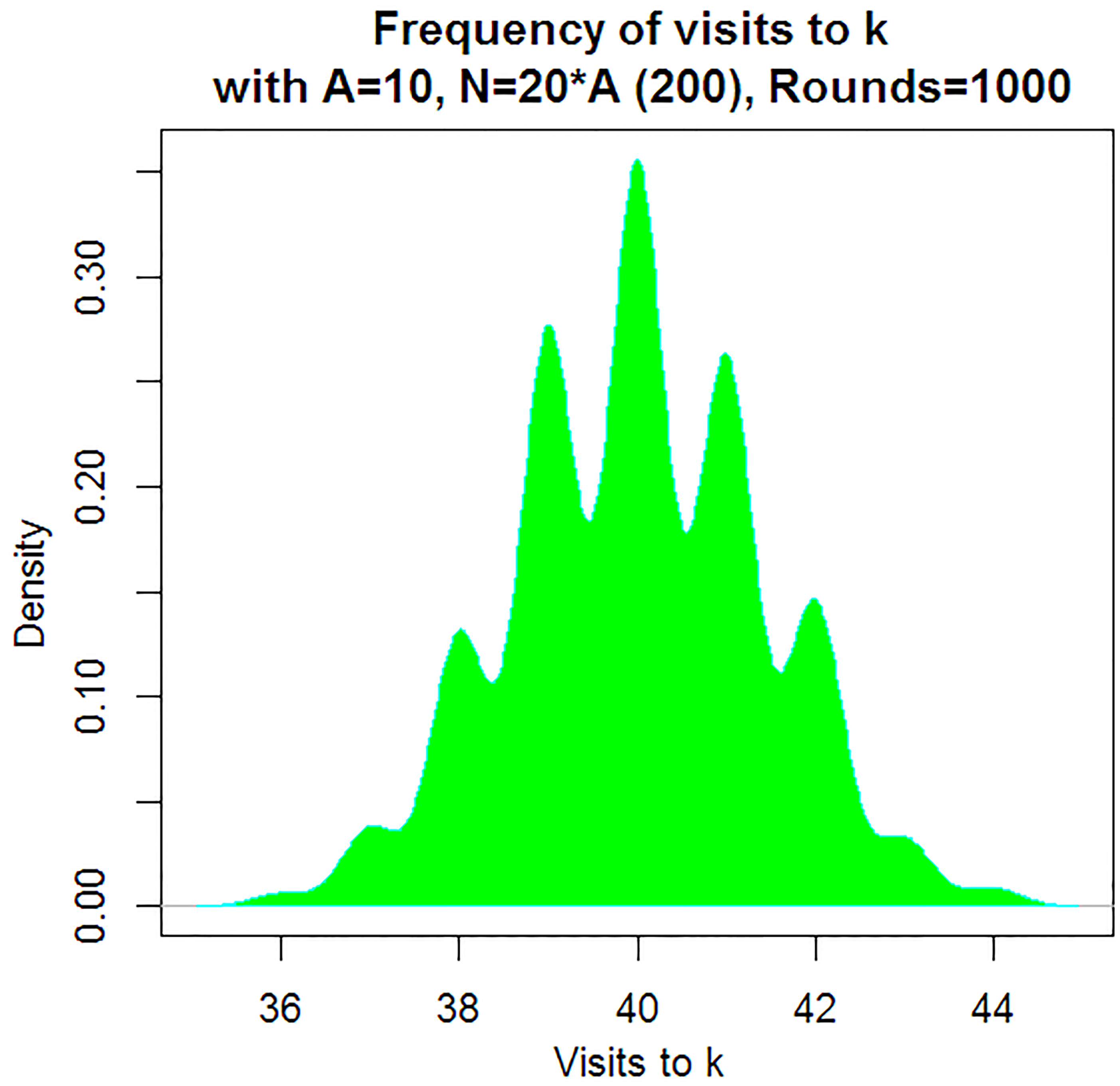
We see from Eq. (1) that eigenvalues of the transition matrix are apart as which means that we cannot separate the maximal of them from the rest and restrict spectral expansion to just one ‘maximal summand’. The term corresponds to the additive state function for the indicator function of state . Obviously, this function takes the value 0, if the initial state is 1 and number of summands less than . Distribution of the sum is far from Normal, if few more summands are involved.
This fact is displayed in empirical histogram of visits to the state (Fig. 1), where the sample size is 20 times more than prepared by Grosu as a result of 1000 simulations. It shows several slightly intersected clusters far from the overall Normal histogram.
A similar picture holds for symmetric cyclic RW starting from 0 since it takes at least steps to reach .
Histogram.
Appendix 2: Parallel SCOT training
This section outlines a novel parallel implementation of the algorithm similar to ‘Context’ which is created for fast processing more complex data sets including those with larger alphabet sizes.
The ESI-based criterion usually stops back-processing of the training string long before the chosen horizon. All directions backwards from the root are processed in parallel making the algorithm much faster. written using the Python programming language – builds the stochastic trees starting from stage 1 and proceeding to the horizon stage of interest. Potential contexts having an ESI value smaller than 0 become contexts, and would be omitted from processing in the following stages. Another improvement in parallelism is processing of a potential context by hashing, and determining if it should be processed on one node of many by taking the modulo of the hash with the total number of compute nodes. The assumption here is that there we have many (hundreds) of compute nodes available to process a corpus into a SCOT.
Appendix 3: Outline of the perfect memory theory,Zhang (2017)
Theory of perfect memory SCOT plays an important role in our constructions. It enables application of abundant theory for 1-MC justifying statistical properties of cumbersome calculations performed by a sophisticated software over SCOT. For completeness, we outline results of Zhang (2017) enabling this reduction.
If each node of a context tree is either a leaf or has exactly children then it is called complete
For two strings , denote the concatenation of and in the natural ordering by . We say that a string is a postfix of a string , denoted by , if there exists a string such that .
For a context tree let us denote by the sub-trees rooted at the children of ’s root. For two context trees let us write if is contained in such that they have the same root. The main result is the following.
The statement of the theorem can be reformulated as follows: has perfect-memory if and only if , either or , s.t. .
The partially ordered set of perfect-memory context trees is a lattice (namely, intersections and unions preserve perfect-memory), which in turn allows to talk about the perfect-memory closure of a context tree.
Since perfect-memory is closed under intersection, we can define the following.
Perfect-memory is preserved under intersection, so the perfect-memory closure of a context tree has perfect-memory. Thus, is the minimal context tree that contains and has perfect-memory.
Let denote the minimal complete context tree that contains .
An additional goal is to give a simple construction algorithm of the perfect-memory closure of an arbitrary context tree.
Appendix 4: Simulation of CP detection (Feng)
We simulate the first state transfer in HMM with states 0 and 1, starting from HMM state 0. The transition probability of this Hidden Markov Model is: 1, 0.001, 1, 0. Introduce CP as the least such that 1.
Then
In our simulation never goes back to state 0 again.
Emissions follow the SCOT model 2.ii from Ryabko (2016); Malyutov (2014).
ii) Define SCOT under state 0: Let
If where is the left boundary, then:
If where is the right boundary (we assume is large enough such that we will not reach the right boundary in simulation), then:
If for the greatest such that , we have and , then:
If for the greatest such that , we have and , then:
iii) Under state 1 we use model 2(ii) with probabilities 0.6, 0.2, 0.2 (the previous model is represented by 0.8,0.2,0.2)
Simulating HMM and SCOT models we generate data. Then the CP detection algorithm of Section 7 detects the CP in generated data . In our simulation displayed in Fig. 1 the sample size is 1000 (i.e. ) and the actual single change point is 662.
References
1.
AminikhanghahiS., & CookD.A. (2017). Survey of methods for time series change point detection. Knowl Inf Syst, 51(2), 339-367.
2.
BillingsleyP. (1961). Statistical Inference for Markov Chains. University of Chicago Press.
3.
BiscupM. (2011). Recent progress on the random conductance model. Probability Surveys, 8, 294-373.
4.
BorovkovA.A. (1998). Ergodicity and Stability Of Stochastic Processes. Wiley.
5.
BradleyR.C. (2005). Basic properties of strong mixing conditions. A survey and some open questions. Probability Surveys, 2, 107-144.
ChibisovD.M. (2009). Lectures on the asymptotic theory of rank tests. Lecture Notes NOTs 14. M: Matematicheskiy Institut im. V. A. Steklova, RAN, In Russian.
8.
CoverT.M., & ThomasJ.A. (2006). Elements of Information Theory, Second Edition. Wiley, Hoboken.
9.
CappeO.MoulinesE., & RydyenT. (2005). Inference in Hidden Markov Models, Springer.
10.
DumontT. (2014). Context tree estimation in variable length hidden markov models. IEEE Trans Inform Theory.
11.
DurbinR.EddyS.KroghA., & MitchisonG. (1998). Biological Sequence Analysis. Cambridge University Press.
12.
FellerW. (1967). An Introduction to Probability Theory and its Applications, Volume 1, Third edition, Wiley, NY.
13.
GallagerR. (2013). Stochastic Processes: Theory for Applications, Cambridge Uni.
14.
Galves, A. & LoecherbachE. (2008). Stochastic chains with memory of variable length. Festschrift in Honor of Jorma Rissanen on the Occasion of his 75th Birthday, Tampere, TICSP series No. 38, Tampere Tech Uni, 117-134.
15.
GrinsteadC., & SnellJ. (2006). Introduction to Probability, AMS.
16.
HamiltonsJ. (2008). Regime switching models. The New Palgrave Dictionary of Economics. Second EditionDurlaufS.N., & BlumeL.E., Palgrave Macmillan.
17.
KharinY., & MaltsauM. (2014). Markov chain of conditional order: Properties and statistical analysis. Austrian Journal of Statistics, 4(3-4), 205-216.
MächlerM., & BühlmannP. (2004). Variable length Markov Chains: Methodology, computing, and software. Journal of Computational and Graphical Statistics, 13(2), 435-455.
20.
MalyutovM., & ProtassovR. (2002). LAN and LAM, convergence of iterative estimates and optimal design in Gaussian one-way mixed model. Journal of Statistical Planning and Inference, 100(2), 249-279.
21.
MalyutovM., & GrosuP. (2017). SCOT approximation, modeling and training. Proceedings of Machine Learning Research, 60, 241-265.
22.
MalyutovM.B.ZhangT.LiX., & LiY. (2013). Time series homogeneity tests via VLMC training. Information Processes, 13(4), 401-414.
23.
MalyutovM.B.ZhangT., & GrosuP. (2014). SCOT stationary distribution evaluation for some examples. Information Processes, 14(3), 275-283.
24.
MarkovA.A. (1906). Extension of the limit theorems of probability theory to a sum of variables connected in a chain (in Russian). Appendix B of: Howard R (1971) Dynamic Probabilistic Systems, Volume 1: Markov Chains. John Wiley and Sons.
25.
MalyutovM. (2017). Retrospective training slow HMM-SCOT emissions model. Information Processes, 17(3), 199-205.
26.
MeynS.P., & TweedyR.L. (1993). Markov Chains and Stochastic Stability. Springer.
27.
RabinerL. (1989). A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of IEEE, 77(2), 257-286.
28.
RissanenJ. (1983). A universal data compression system. IEEE Trans Inform Theory, 29(5), 656-664.
29.
RoussasG. (1972). Contiguity of Probability Measures: Some Applications in Statistics. Cambridge University Press.
30.
RyabkoB.AstolaJ., & MalyutovM. (2016). Compression-Based Methods of Prediction and Statistical Analysis of Time Series: Theory and Appllications. Springer International.
31.
ShiryaevA.N. (1978). Optimal stopping rules. Applications of Mathematics, 8, Springer, New York.
32.
TutubalinV.N. (1992). Probability and Random Processes Theory. Mathematical Foundations and Applications. Moscow State University Press (In Russian).
33.
VeretennikovA.Yu. (2000). Parametric and Nonparametric Estimation for Markov Chains. Moscow State University Press (In Russian).