
Abstract
In this paper it is introduced a new two-parameter discrete distribution derived from the continuous Sushila distribution (Shanker et al., 2013). Its mathematical properties and estimation procedures for the parameters of the proposed model are presented assuming complete and right-censored data. This new model, in the same way as the continuous Sushila distribution, has the discrete Lindley distribution as a special case. An extensive simulation study is carried out to examine the bias and the roots of the mean squared errors for the maximum likelihood estimators as well the moments and Bayesian estimators of the proposed model parameters. Some examples using simulated data and real datasets are considered to show that the new proposed model performs at least as good as its particular case and some other traditional discrete models as the Poisson and geometric distributions.
Keywords
Introduction
In the recent decades, the construction of new discrete distributions using discretization methods has been widely used in the literature. Basically, the main purpose of the discretization is to generate distributions that can be used for the analysis of strictly discrete data as alternatives to the traditional discrete distributions as the Poisson and geometric distributions. A field of study where the discretization process is widely needed is in the analysis of lifetime data where it is common the use of continuous distributions to model lifetime data, which could be discrete, usually in presence of censored data. Several applications where continuous distributions are used to model discrete data can be found in Klein and Moeschberger (1997), Meeker and Escobar (1998), Kalbfleisch and Prentice (2002), Lee and Wang (2003), Lawless (2003), Collett (2003), Hamada et al. (2008), among many others. A complete survey regarding all discretization methods introduced in the literature and some discretized distributions can be found in Chakraborty (2015).
One of the first proposed discretization methods presented in the literature is based on the definition of a probability mass function based on a infinite series. The first foundations of this method were presented by Good (1953), that proposed the discrete Good distribution to model population frequencies of species. Such approach was considered by other authors to define discrete analogues, for example: Haight (1957) proposed the discrete Pearson III distribution to model queues with baking; Siromoney (1964) introduced the Dirichlet’s Series distribution as an alternative to model the frequency of wet days (rain-spells); Kemp (1997) formally introduced the discrete normal distribution and derived its main mathematical properties; the discrete exponential distribution was proposed by Sato et al. (1999) to describe the defect count frequencies on wafers or chips; Bi et al. (2001) introduced the discrete log-normal distribution; Inusah and Kozubowski (2006) presented the discrete Laplace distribution also arguing that, in comparison to the discrete normal distribution, the proposed model has closed forms for the probability mass function, for the generating functions and for the central moments; the skewed version of the discrete Laplace distribution was proposed by Kozubowski and Inusah (2006); Doray and Luong (1997) presented efficient estimators for the parameters of the Good distribution family; Kemp (2008) introduced the discrete half-normal distribution also presenting its relation with other existing distributions and Nekoukhou et al. (2012, 2013) proposed the discrete generalized exponential distribution as an attempt to model rank frequencies of graphemes in the Slovene language. The method of discretization by infinite series is characterized by the following definition.
.
Let
being
One of the most recent examples of the use of this method is provided by the discrete analogue of the generalized exponential probability distribution introduced by Nekoukhou et al. (2012) having probability mass function given by,
for
The main goal of this paper is to use the infinite series method to propose a discrete analogue for the Sushila distribution which is a two-parameter lifetime model proposed by Shanker et al. (2013). In this way, it is expected that the proposed discrete Sushila distribution could be a suitable alternative for survival data, especially in the presence of right-censored data. The Sushila distribution has the one-parameter Lindley distribution (Ghitany et al., 2008) as a special particular case and can also be written as a mixture of probability distributions in the same way as the Lindley distribution.
Le
where
This paper is organized as follows: In Section 2, it is introduced the discrete Sushila distribution and derived the main mathematical properties. In Section 3, the estimation of the parameters and inference procedures under Classical and Bayesian approaches are presented. In Section 4, a Monte Carlo simulation study is carried out to evaluate the performance of the presented estimators. In Section 5, applications of the proposed model to real datasets are considered to illustrate its usefulness. Some concluding remarks are presented in Section 6.
A first approach of the discrete Sushila distribution was introduced in the literature by Borah and Saikia (2016). These authors used the discretization idea based on the survival function proposed by Nakagawa and Osaki (1975) in the discretization of the Weibull distribution to introduce a new discrete Sushila distribution. In this paper, it is introduced another approach to construct a discrete Sushila distribution based on the discretization method by infinite series previously described.
Let
where
The corresponding cumulative distribution function (cdf) and survival function (sf) of the DS distribution are given, respectively, by,
and,
The pmf Eq. (6) does not involves complicated expressions and therefore, the probabilities can be straightforwardly computed, as for example,
for
On other hand, the pmf Eq. (6) satisfies the the log-concave inequality
where
It follows from Eqs (6) and (8) that the hazard rate function (hf) of the DS distribution is concave and increasing in
where
Behavior of the pmf (left-panel: 
The quantile function of the DS distribution, say
where 0
The last property that will be discussed in this paper is related to the moments of the DS distribution. Let
from where, taking
It is important to point out that the mean of the DS distribution is always greater than the mode, that is, the DS distribution is positively skewed. The mean and the variance for the DS distribution are given, respectively, by,
where
Now, taking the ratio between the variance and the expected value, one can define the dispersion index and the coefficient of variation of the DS distribution, respectively, as,
The asymmetry degree and the flatness of a distribution are usually measured by their coefficients of skewness and kurtosis, respectively. The first one can be computed by the third central moment normalized by the variance raised to the power
In this section, it is estimated the unknown parameters of the DS distribution using the methods of moments, maximum likelihood method and the Bayesian method. For maximum likelihood and Bayesian methods, it is also presented the estimation procedure in presence of right-censored data.
Method of moments
The method of moments is the simplest technique commonly used in parameter estimation when the raw moments has a closed analytical form. For the DS distribution, first, let
where
For the MOM estimator of
Complete data
Considering
From Eq. (19), the log-likelihood can be written as,
which is maximized solving numerically, in
From Eq. (21), it is obtained that
On other hand, there is no closed analytical form for the maximum likelihood estimator (MLE) for
Now, under suitable regularity conditions (see, Lehmann & Casella, 1998, pp. 461–463), the asymptotic distribution of the maximum likelihood estimator
where,
On other hand, for the expected Fisher’s information matrix
where
Let us consider the situation when the lifetime,
where
where,
Different from complete data, for censored data, the expected Fisher’s information matrix
The Bayesian paradigm is based on specifying a probability distribution for the observed data
In order to determine the Bayes estimators for the unknown parameters of the DS model based on the squared error loss function,
Since the kernel of the likelihood function is proportional to a gamma distribution, the Bayes estimate of
Observe that since it is not possible to compute Eq. (27) analytically, it is used MCMC methods to get the posterior summaries of interest. In this way, without loss of generality, it is used the Gibbs sampling algorithm to generate samples from the posterior distribution of interest from which it is computed the Monte Carlo Bayes estimators under the squared error loss function. The Gibbs sampling algorithm steps are given by,
Step 1: Choose initial values, Step 2: Generate Step 3: Repeat step 2, Step 4: Calculate the Monte Carlo Bayes estimate of
The posterior summaries of interest are computed using the package
This section reports the results of a simulation study carried out to assess the performance of the MLEs, MOM and Bayesian estimators for the DS distribution assuming complete and censored data. The simulation study was performed in R software using the packages fitdistrplus for MLEs, nleqslv for MOM estimators and R2jags for Bayesian estimators. For the Bayesian estimators, independent approximately non-informative gamma prior distributions, Gamma(0.001, 0.001), were assumed for both parameters. The BFGS optimization method was considered as the optim.method. To simulate observations from DS model, the inverse transformation method for discrete case was used following the steps (Devroye, 1987):
Step 1: Generate Step 2: Define Step 3: While Step 4: Return
The simulation study was performed under six scenarios considering the assumed parameter values as the combination of (
where
Complete data
The biases and RMSEs for both parameters assuming the DS distribution for each considered scenario considering the MLE (upper-panels), MOM (middle-panels) and Bayesian (lower-panels) estimators assuming complete data.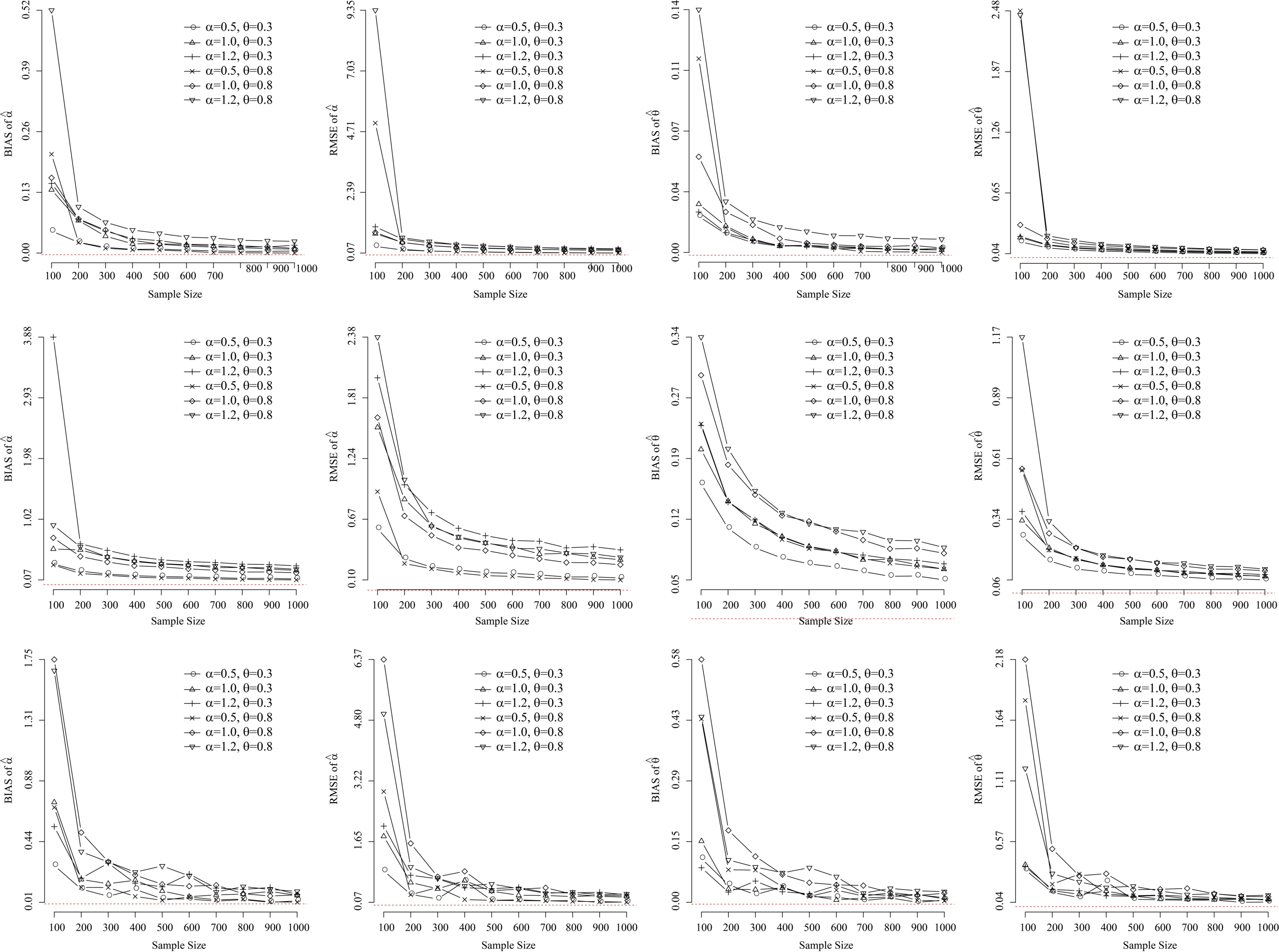
The obtained simulation results for each scenario assuming complete data are illustrated in Fig. 2 for MLE, MOM and Bayesian, respectively. From the simulation results illustrated in Fig. 2, it is possible to conclude that,
Assuming the MLE estimators, both parameters are asymptotically non-biased since Assuming the MOM estimators, both parameters are asymptotically non-biased since Assuming the Bayesian estimators, both parameters are asymptotically non-biased since The convergence of each estimation method was quite good even thought, for all considered samples, the parameters had been overestimated (that is, the parameters are positively biased). This result is expected since the Lindley distribution has the same property. In addition, based on these simulation results, it could be concluded that the DS distribution could be used as an alternative to other existing discrete univariate distributions to describe univariate lifetimes with good accuracy and computational aspects.
In this section, it is presented the simulation results assuming censored data. To perform the simulation study, it was considered the same data generated assuming complete data case and considering that the censored observations are determined by assuming a cut point equals to 10 to obtain simple right-censored observations. The simulation study was performed under four scenarios considering the assumed parameter values as the combination of (
The obtained simulation results for each scenario assuming simple right-censored data are illustrated in Fig. 3. From the results presented in Fig. 3, it is possible to conclude that both parameters are asymptotically non-biased since
Numerical experiments
Complete simulated dataset
For illustration purposes, let us consider
From the results of Table 2 and comparing to the true parameter values adopted in this simulated dataset, it is possible to conclude that the Monte Carlo Bayesian estimates are more accurate when compared to the MLE estimates by observing the standard errors and deviations as well the length of the confidence and credibility intervals. Despite the differences between both estimators, in general, the Bayesian estimators are more suitable in applications for the DS distribution.
Simulated lifetimes from a DS distribution with true arbitrary parameters values
0.7 and
0.3
Simulated lifetimes from a DS distribution with true arbitrary parameters values
Inference summaries for DS distribution with true arbitrary parameters values
The biases and RMSEs for both parameters assuming the DS distribution for each considered scenario considering the Bayesian estimators assuming simple right-censored data with cut point equals to 10.
As a second illustration, it was considered the same data generated for the numerical experiment assuming complete data from a DS distribution where the censored observations are determined by considering a cut point equals to 10 to obtain simple right-censored observations. Since the Bayesian estimators are more suitable for the DS distribution, in this illustration, they are only considered as the estimation approach assuming approximately non-informative uniform prior distributions for the parameters of the model with hyperparameter values equal to (0, 1). In Table 3, it is presented the posterior summaries of interest for the parameters of the DS distribution.
From the results of Table 3, it is observed that the lengths of the 95% credible intervals are relatively narrow and the standard deviations are estimated by small values, an indication that the DS distribution has a good performance for this right-censored simulated dataset under a Bayesian approach and could be used as an alternative to lifetime models.
Real data applications
Lung cancer data
To illustrate the usefulness of the proposed distribution, it is presented in this subsection, the analysis of a real medical dataset related to lung cancer assuming the DS distribution. The dataset is given by Ding et al. (2017) and corresponds to the lifetimes of Chinese patients pathologically confirmed lung cancer who received EGFR, KRAS, and BARF mutation tests at the Thoracic Cancer Institute, Tongji University from January 2012 to April 2016. The dataset consists of
Posterior summaries for DS distribution with true arbitrary parameters values
0.7 and
0.3 in presence of right-censoring
Posterior summaries for DS distribution with true arbitrary parameters values
Posterior summaries for the parameters and the mean (
For the statistical analysis, it is assumed two lifetimes: the overall survival times (calculated from the date of lung cancer diagnosis to death from any reason or censored at the last follow-up date), and the progression-free survival times (the times from the treatment start time until the date of systemic progression or death). It is important to point out that both times are measured in complete months (discrete data) and the possible dependence structure between both times is not considered here.
The parameters of the DS distribution were estimated under a Bayesian approach assuming approximately non-informative independent Uniform(0, 1) prior distributions for both parameters. The corresponding results are presented in Table 4 and the fit of DS distribution was compared to the fit of the Geometric (Geo) distribution and two discrete Lindley (DL
A measure that plays an important role in survival analysis is the comparison of the estimated lifetime mean assuming a parametric distribution with a nonparametric estimator for the mean. In this case, the non-parametric estimators for the means obtained from the Kaplan and Meier (1958) non-parametric estimators for the survival functions are given, respectively, by 16.57 months for the overall survival time and 5.71 months for the progression-free survival time. The estimated mean and the 95% credible intervals for each assumed model are presented in Table 4 from which it could be concluded that the estimated mean for DS distribution is very close to the empirical Kaplan-Meier estimator which is a great indication of a good fit and adequacy of the DS distribution to describe both survival times associated to the lung cancer data.
Now, considering count data, in this subsection, it is presented the analysis of a real dataset related to number of fires in Alberta assuming the DS distribution. The dataset is given by Tremblay et al. (2018) and corresponds of the number of fires recorded over a seven year period (1996–2002) within a 67,000 km
Forest fires are important events in many terrestrial ecosystems, including the boreal forests of North America. In many areas where they occur, fire management agencies attempt to control the growth and limit the size of these fires, to protect human lives, infrastructure, and natural resources (Tremblay et al., 2018). Thus, knowing the probability distribution of the number of fire is important for forecasting the number of fires that affects one area to draw a way to extinguish the fires.
Posterior summaries for the parameters and the mean (
) of DS, Geo, DL
, DL
, and P distributions for number of fires in northeastern of Alberta, Canada
Posterior summaries for the parameters and the mean (
For the statistical analysis considered here, it is assumed the response variable number of fires and the DS distribution do describe the response distribution. A Bayesian approach was assumed considering approximately non-informative independent Uniform(0, 10) prior distributions for both parameters of the DS distribution. The corresponding results are presented in Table 5 and the fit of the DS distribution was compared to the fit of the Geometric (Geo) distribution, the two discrete Lindley (DL
In this study, it was introduced a new univariate discrete distribution, named discrete Sushila (DS) distribution, obtained using the Good (1953) discretization method to generate a discrete analogue from the Sushila distribution proposed by Shanker et al. (2013) as an alternative to existing univariate discrete distributions like the popular Poisson, the geometric and the discrete Lindley distribution to analyze univariate discrete lifetime data in presence of right-censored data. The main mathematical properties of this new distribution were also discussed in this study from where it could be stated that the DS distribution can be used to model data with over/under/equi-dispersion. Moreover, an extensive simulation study was performed to verify the effectiveness of the maximum likelihood method, moments estimator and Bayesian method assuming different fixed values for the parameters of the model and different sample sizes. The results obtained from Monte Carlo studies showed that the parameters of the DS distribution are asymptotically non-biased and the biases as well the RMSEs tends to zero when the sample size increases for complete and simple right-censored data.
In the application with real data presented in this study, it was observed that, with the use of the DS distribution, it is possible to obtain in a simple way the inferences of interest for the dataset in presence or not of right-censored data with small computational costs and a good accuracy even using non-informative priors for the parameters of the DS model, under a Bayesian approach. As pointed out in the applications, the estimated mean using DS distribution is basically equal to the empirical mean of the data considered which is a great indication that the DS distribution is adequate and describes well the distribution of the data. In general, most of the existing models could be fitted to the dataset, however, only few of these models could describe the mean in a adequate way which, in some cases, is the main interest of the researcher. These results could be of great interest for the search of appropriate univariate lifetime distributions for the analysis of right-censored especially in medical and engineering studies.
Footnotes
Acknowledgments
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES) – Finance Code 001.