In this paper we propose a new cure rate survival model. Our approach enables different underlying activation mechanisms which lead to the event of interest. The number of competing causes which may be responsible for the occurrence of the event of interest is assumed to follow a geometric distribution while the time to event is assumed to follow a Birnbaum-Saunders distribution. As an advantage our approach may scan all underlying activation mechanisms from the first to last one based on order statistics. We explore the use of Markov chain Monte Carlo methods to develop a Bayesian analysis for the proposed model. Moreover, some discussions on the model selection to compare the fitted models are given. In particular, case deletion influence diagnostics are developed for the joint posterior distribution based on the -divergence, which includes the Kullback-Leibler (K-L), -distance, norm and -square divergence measures as particular cases. Simulation studies are performed for study frequentist properties of the Bayesian estimates. The methodology is illustrated on a real malignant melanoma data.
In many medical problems, such as chronic cardiac diseases and various different types of cancer, a cumulative individual damage may be caused by various unknown causes or risk factors. This degradation leads to a fatigue process, whose propagation lifetimes can be suitably modeled by a Birnbaum-Saunders (BS) distribution. The BS distribution was originated from a physical problem related to material fatigue, describing the total time that passes until the development and growth of a dominant crack, producing a type of cumulative damage that surpasses a threshold and causes a failure (Birnbaum & Saunders, 1969). Leiva et al. (2007) applied the classical version of the BS distribution (BS model generated from the normal law) for modeling lifetimes of patients with multiple myeloma.
A review of all developments on BS distribution and related distributions can be found in Balakrishnan and Kundu (2019).
The survival function of BS model is given by
where is the standard normal cumulative distribution function, and are respectively, shape and scale parameters. The corresponding probability density function (pdf) of the BS distribution is obtained from Eq. (1) as
The parameter is the median of the distribution: . The mean and the variance of the BS distribution are respectively and
Some proposals have been made in the literature by replacing the relationship between the BS and normal distributions by more general classes of distributions. For example, Díaz-García and Leiva-Sánchez (2005) introduce the generalized BS distribution by considering the elliptical family of distributions. The main motivation for considering the generalized BS distribution is to make the kurtosis flexible compared to the BS model. Sanhueza et al. (2008) presented a complete compilation of the results related to the generalized BS distribution and Gómez et al. (2009) proposed an extension of the generalized BS model based on the slash-elliptical distributions.
Moreover, from the practical point of view, due to significant progress and advancements in treatment therapies, it is common that we observe survival data where part of the population is not susceptible to the event of interest. For instance, in clinical studies a population can respond favorably to a treatment, being considered cured. The proportion of such fraction of the population which is not susceptible to the event of interest is usually termed as the cured fraction. In this context, in order to address such conceptual problem, cure rate models (also called survival models with a surviving fraction or long-term survival models) that incorporate a cure fraction have been proposed and are nowadays widely developed. Perhaps the most popular type of cure rate model is the mixture distribution introduced by Boag (1949) and Berkson and Gage (1952), where it is assumed that a certain proportion of the patients are cured, in the sense that they do not present the event of interest during a long period of time and can be seen as to be immune or cured to the cause of death under study. A key reference on mixture distributions is Maller and Zhou (1996).
Mixture models are based on the assumption that only a cause is responsible for the occurrence of the event of interest. However, in clinical studies, the patient’s death or recurrence of tumor, which is the event of interest, may happen due to different latent competing causes, in the sense that there is no information about which cause was responsible for disease manifestation through the occurrence of the event of interest. A tumor recurrence can be attributed to metastasis-component tumor cells left active after initial treatment. A metastasis-component tumor cell is a tumor cell with potential to metastasize (Yakovlev & Tsodikov, 1996). In the above context, the literature on distributions which accommodates different latent competing causes is rich and growing rapidly. The book by Ibrahim et al. (2001), the review paper by Tsodikov et al. (2003) and the works by Cooner et al. (2007), Rodrigues et al. (2009), Cancho et al. (2009) and Cancho et al. (2012a) can be regarded as key references. Another approach, by Cooner et al. (2006) and Cooner et al. (2007), forms an arranged stochastic sequence of latent causes, which induce the occurrence of the event of interest via an underlying activation mechanisms that lead to the event of interest. The cure rate models have been successfully applied to many real word problems. For example, Cancho et al. (2013), Suzuki et al. (2016) and Suzuki et al. (2017) assumed that unobservable number of causes of an event of interest follows the Negative Binomial, Poisson and Logarithmic distributions, respectively.
The main goal of this paper is to present a new distribution family, hereafter called the GBS cure rate (GBScr) model, conceived inside a scenario of latent competing causes with the presence of a cure fraction, where the occurrence of the event of interest may be activated by different kinds of mechanisms (Cooner et al., 2007).
The GBScr model includes a particular case of the model introduced by Cancho et al. (2012b) in presence of a first activation mechanism.
Bayesian analysis for the BS model has appeared in the literature. For instance we cite Tsionas (2001) and Xu and Tang (2011). In this paper, we propose a Bayesian approach for drawing inferences in GBScr models in the presence of covariates on the cure fraction. Also, we develop case deletion influence diagnostics for the joint posterior distributions of the parameters of the GBScr model based on the -divergence measure (Peng & Dey, 1995; Weiss, 1996). The -divergence measure includes several divergence measures as particular cases, such as the Kullback-Leibler (K–L), -distance, norm and -square divergence measures.
The paper is organized as follows. In Section 2 we formulate the model, providing its particular cases as well as a comparison among the activation mechanisms. The development of a Bayesian analysis is presented in Section 3, involving inference, Model comparison and case influence diagnostics. A simulation study with the different models is presented in Section 4, where we discuss the results of the evaluation of the frequentist properties as well as the influence of outlying observations. An application to a real data set is developed in Section 5. Finally, Section 6 ends up the paper with some general remarks.
Model formulation
The GBScr distribution is derived as follows. For an individual in the population, let denote the unobservable number of causes of the event of interest for this individual. Assume that follows a geometric distribution with parameter and probability mass function,
The time for the cause to produce the event of interest is denoted by , . We assume that, conditional on , the are independent identically distributed accordion to a BS distribution given in Eq. (1). Also, we assume that , are independent of . The observable time to event is defined by the random variable , where depends on , are the order statistics and if . In many biological processes can be interpreted as a resistance factor of the immune system of the individual. If the event of interest occurs (e.g., cancer relapse), then the random variable takes the value of the order statistics . In other words, as in Cooner et al. (2006) and Cooner et al. (2007), out of causes are required to produce the event of interest. Moreover, the activation mechanism may be seem as a system of hits generated by independent times to hit , where is the number of hits required to make the system fail. The resistance factor can be a fixed constant, a function of or a random variable specified through a conditional distribution on .
In this paper, using the terminology borrowed from Cooner et al. (2006) and Cooner et al. (2007), we deal with three specifications for , directing to a first activation mechanism, random directing to a random activation mechanism and directing to a last activation mechanism. Thus we scan all possible mechanisms of activation.
Although, one may have information beforehand about activation mechanism which should be considered for a particular application. For example, focusing in reliability, if a series system is considered to be analyzed than the first activation mechanism is the natural one, while the last activation mechanism is the natural one in presence of a parallel system. However, as in many situations we may have difficulties to view, in a simplistic way, which activation mechanism is the most adequate, our approach is, at least in principle, more intuitive, with ability to scan all the possibilities between the first and the last activation mechanisms. For instance, focusing in the medical area, it may be difficult to decide for a particular activation mechanism acting on the occurrence of a disease. Although a tumor recurrence can be attributed to metastasis-component tumor cells left active after initial treatment, which activation mechanism may represent the phenomenon? In this context, the GBScr with a scan type activation mechanism may be considered as its different particular cases. We then may decide for the best fitting in the light of the dataset via a model comparison criteria as it will be pointed out further in the text.
Activation mechanisms
We first assume that given , the conditional distribution of is uniform on (a random activation mechanism). Under this setup, the surviving function for the population is given by
where
Note that Eq. (5) gives the cumulative distribution function (cdf) of binomial distribution, with trials and success probability . If R=1, then, , which includes the models proposed by Tsodikov et al. (2003).
From Eq. (5), the survival function of in Eq. (4) under random activation mechanism is given by
where and . We observe that the in Eq. (6) is a mixture cure model with cured fraction . From Eq. (6), the density function is Furthermore, the corresponding hazard function is .
As a second setup, the so-called first activation mechanism, we suppose that the event of interest happens due to the possible cause with firstly happened. Therefore, for , the time to event is . From Eqs (4) and (5), the survival function of is given by
The cured fraction is given by . The density function associated to Eq. (7) is given by with hazard function . Note that the model Eq. (7) corresponding the model proposed by Cancho et al. (2012b).
In our third scenario, also known as the last activation mechanism, the event of interest only takes place after all the causes have been occurred, so that and the observed failure time is . From Eqs (4) and (5), we have that survival function of is given by
so that the cured fraction is . The surviving function in Eq. (8) leads to the density function with hazard function .
On the comparison of the activation mechanisms
We note that and are improper functions whichever the activation mechanism, since is not a proper survival function. But, the cured fraction is the same. The models differ by its surviving, density and hazard functions. The relationship between the survival functions in Eqs (4), (7) and (8) is described in next proposition. Figure 1 portrays distinct behaviors of the survival functions (left panel). These plots illustrate the flexibility built on our proposal. Moreover, the following proposition delimits the survival functions related to each activation mechanism presented in this paper.
Survival functions populational (left panel) and non-cured populational (right panel) for the GBScr models with 0.3, 5 and 5.0 under different activations (first: dashed, random: solid and last: dotted).
.
Under conditions of models in Eqs (6)–(8) and for the cdf given in Eq. (1), we have that: in Eq. (7) in Eq. (6) and in Eq. (8) in Eq. (6).
The proof of the Proposition 1 follows immediately from the Theorem 1 from Kim et al. (2011).
The (proper) surviving function for the non-cured population, denoted by is computed by For a random activation mechanism, is the same distribution of the latent random variable ’s, that is, . For the first activation mechanism, the survival function for the non-cured population is given by
We note that and , so that Eq. (9) is proper survival function. This survival function is same as the one given in Cancho et al. (2012b).
The survival function for the non-cured population under the last activation mechanism is given by
We note that and , so that Eq. (10) is proper survival function. From Proposition 1, we have in Eq. (9) in Eq. (10). This relation also, can be observed in Fig. 1 (right panel). Moreover, as pointed out by the referee, we made looked for different thetas which make equal models under different activation mechanisms. For instance, considering the GBS distribution under the first activation mechanism Eq. (9) with and the GBS distribution under the last activation mechanism Eq. (10) with . It is easy to show they are equal if .
The GBS pdf is given by
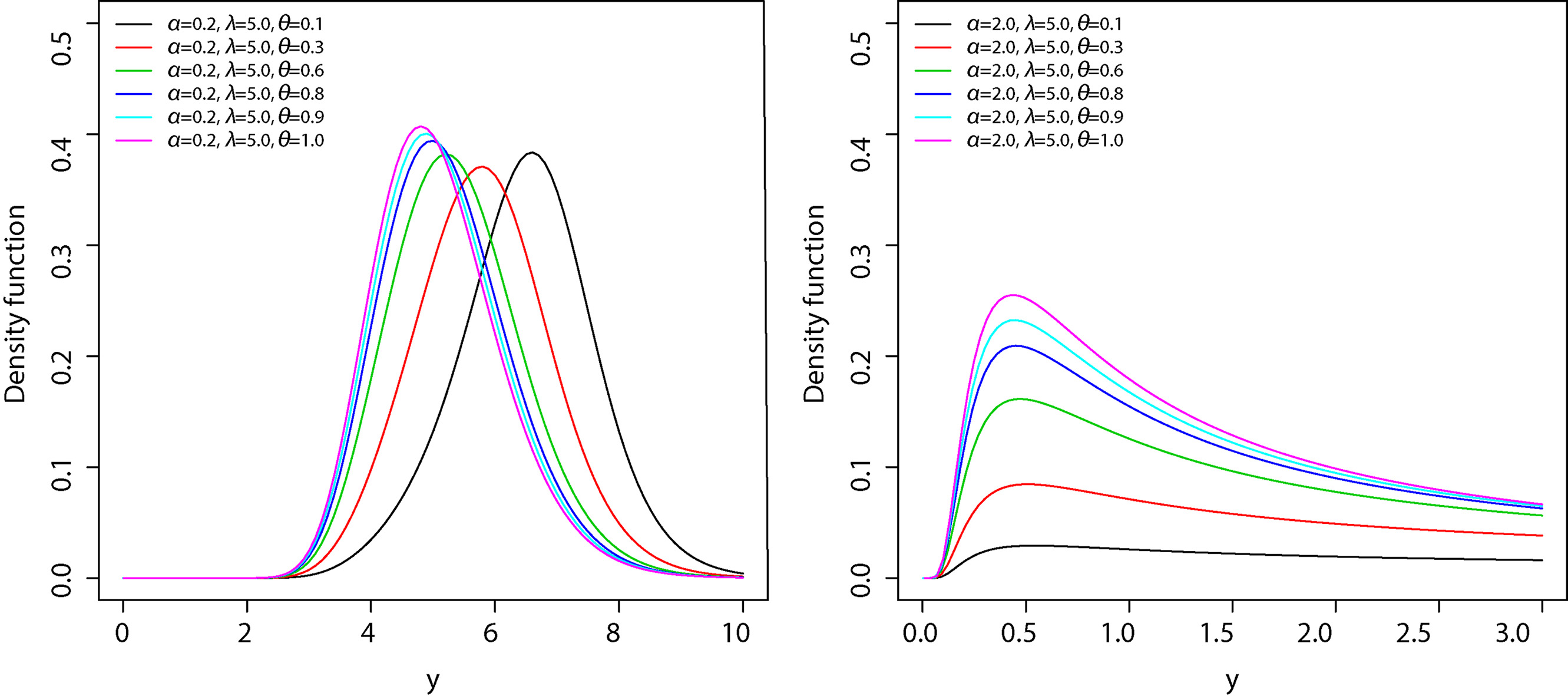
In Fig. 2, we plot the GBS last activation density functions for some fixed values of , and . These plots indicate that the GBS last activation distribution is very flexible and that the values of and have a substantial effect on its skewness and kurtosis.
Probability density function of the GBS distribution under last activation mechanism for some parameter values.
From Eq. (11) and Eq. (10) it is easy to verify that the corresponding GBS hazard function for the population of non-cured is given
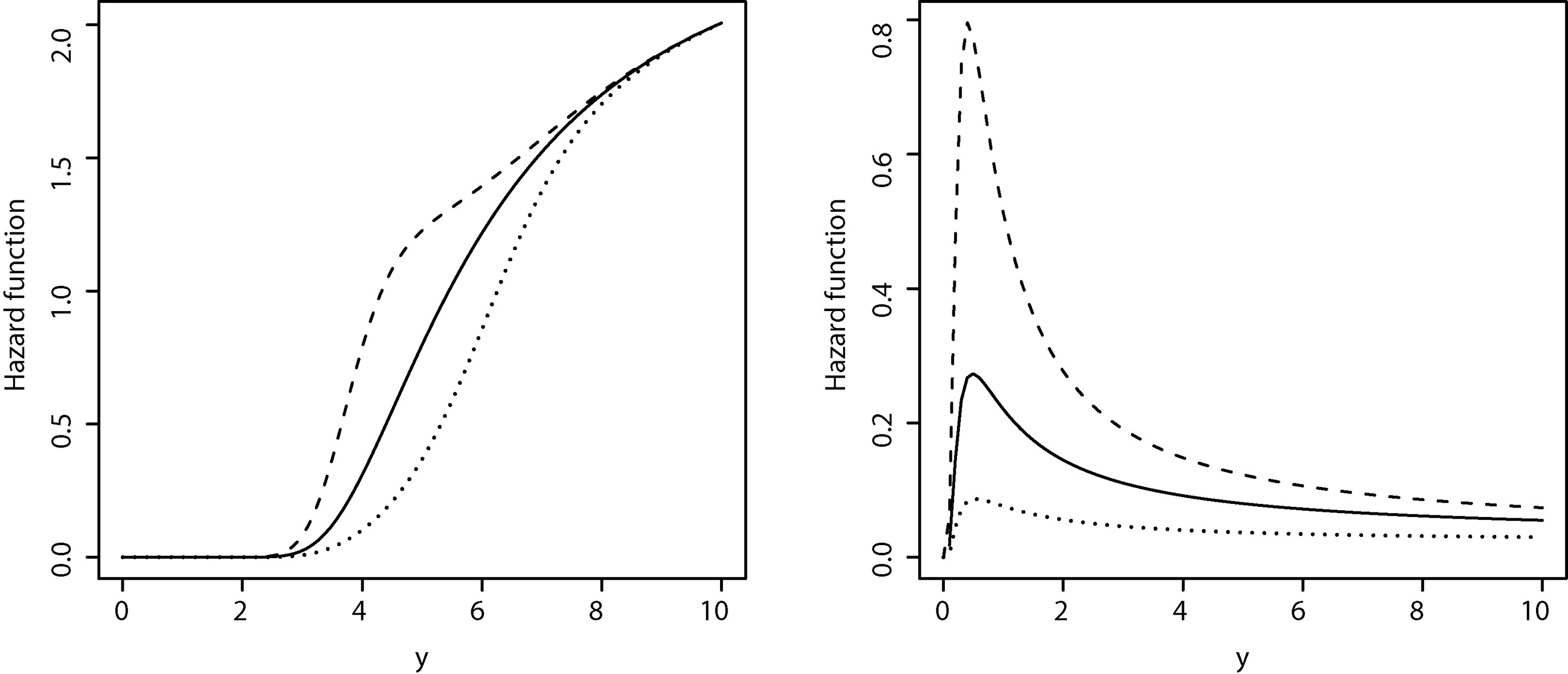
where and are hazard and survival functions of a BS distribution respectively. From Eq. (12), is decreasing in for . Beside, and and hence we have that the limit behavior of the hazard function of GBS distribution is the same as the behavior of the hazard function of the BS distribution. In the case of first activation mechanism, the limit behavior of the hazard function of the GBS distribution is the reversed of the behavior of the hazard function of the BS distribution. Figure 3 shows some GBS hazard function shapes for some fixed values of parameters.
Hazard function of the GBS distribution with , and under different activations (first: dashed, random: solid and last: dotted) for (left panel) and (right panel).
There is a mathematical relationship between the models Eqs (7) and (8) and the mixture cure rate model (Boag, 1949; Berkson & Gage, 1952) We can write
where is given by Eqs (9) or (10). Thus, is a mixture cure rate model with cure rate equal to and survival function for the non-cured population. This results implies that every mixture cure rate model corresponds to some model of the form Eq. (7) (first activation mechanism) or Eq. (8) (last activation mechanism) for any and . This result holds for any distribution function.
The moment of the GBS distribution under the last activation mechanism is given by
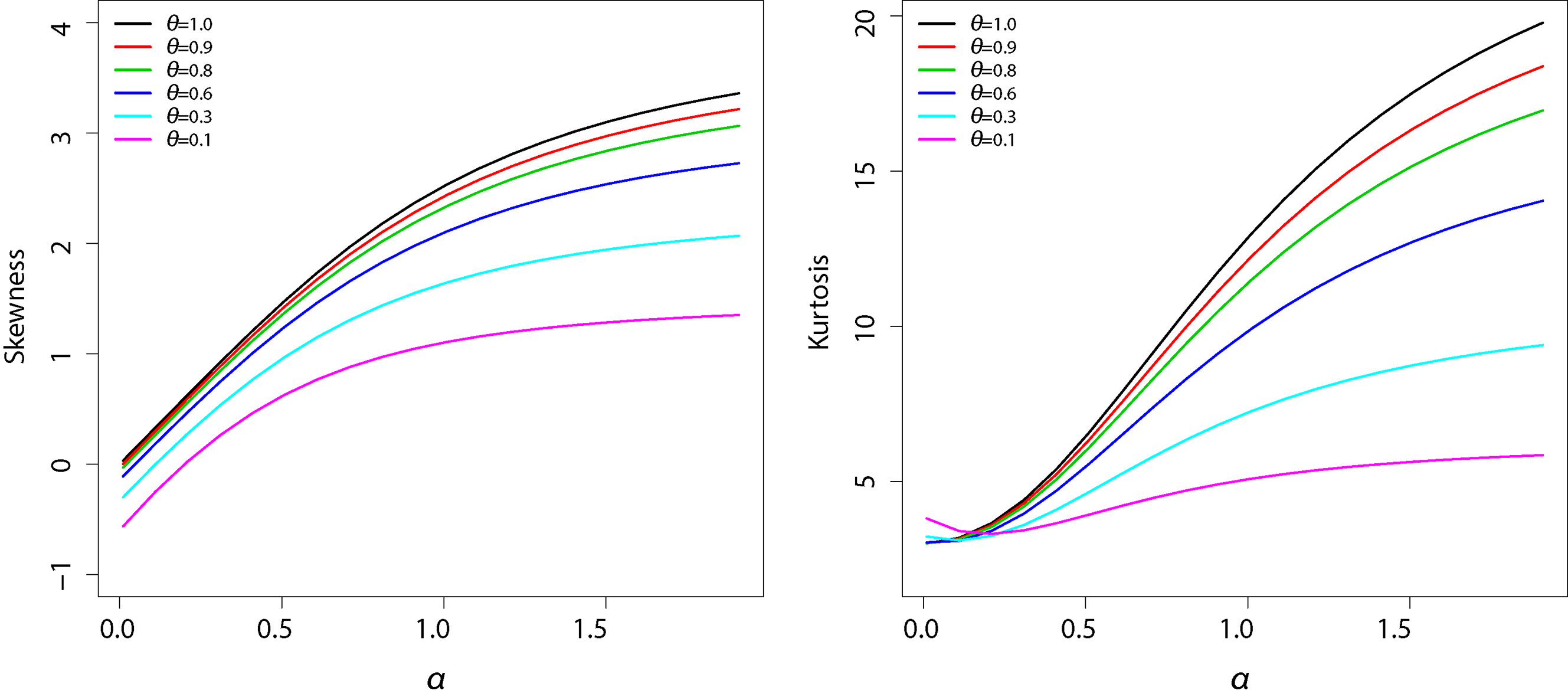
where is given in Eq. (10). Note that in Eq. (13) for , the moments agree with the respective moments of the BS distribution. The skewness and kurtosis measures can be calculated from the ordinary moments given in Eq. (13) using well-known relationships and they can be easily computed numerically in a statistical software such as R (R Development Core Team, 2010). Figure 4 shows a graphical representation of skewness and kurtosis for GBS last activation distribution. It is observed that both skewness and kurtosis are increasing functions of and . The moment of the GBS distribution under the first activation mechanism are calculated in the same manner. The results are similar to the ones obtained for the GBS distribution under the last activation mechanism and are therefore not shown.
Left panel: Skewness of the GBS distribution under the last activation mechanism. Right panel: Kurtosis of the GBS distribution under the last activation mechanism. The parameters were fixed and , for .
Overall, it seems to be a perfect complementarity between the mechanisms of activation, which can be observed confronting the behavior of the graphs shown in Fig. 1 (survival functions) and 3 (hazard functions).
Inference
Let us consider the situation when the failure time in Section 2 is not completely observed and is subject to right censoring. Let denote the censoring time. In a sample of size , we then observe and , where if is a failure time and if it is right censored, for . Let denote the vector of covariates for the individual.
Completing our model, we propose to relate the cured fraction to the covariates by considering the logistic link given by
where encapsulates the vector of regression coefficients, so that for each group of individuals represented by , we have a different cured fraction. With this link function the models are identifiable in the sense of Li et al. (2001). However, others link functions can be used such as probit one. We consider the logist link because the regression coefficients can be easily interpreted in terms odds ratios.
With the expression Eq. (14) we can write the likelihood of under non-informative censoring as
where , , and , whereas and are given in Section 2.
The maximum likelihood estimates (MLEs) of can be obtained by direct maximization of Eq. (15), while large sample inference for the parameters can be based on the asymptotic normality of the MLEs (Cox & Hinkley, 1979). However, they cannot be very accurate for small or moderate samples sizes. We now turn to the Bayesian approach for the model.
Prior and posterior
Now, some inferential tools are investigated under a Bayesian viewpoint. In this context we assume that , , and are a priori independent, that is, . Here all the hyper-parameters are specified in order to express non-informative priors.
Combining the prior distribution and the likelihood function in Eq. (15), the joint posterior distribution for is obtain as . This joint posterior density is analytically intractable. So, we based our inference on the Markov chain Monte Carlo (MCMC) simulation methods. In particular, the Gibbs sampler algorithm (see Gelfand & Smith, 1990) has proved to be a powerful alternative. In this direction, we observe that there is no closed form expression available for any of the full conditional distributions needed to implement Gibbs sampler. Thus we instead resort to the Metropolis-Hastings algorithm. We begin by making a change of variables to . This transforms the parameter space to (necessary to work with Gaussian proposal densities). Accounting for the Jacobian of this transformation, our joint posterior density (or target density) is now
To implement the Metropolis-Hastings algorithm, we proceed as follows:
start with any point , and stage indicator ;
generate a point according to the transitional kernel , where is covariance matrix of is same in any stage;
update to with probability , or keep with probability ;
repeat steps (2) and (3) by increasing the stage indicator until the process reaches a stationary distribution.
The computational program is available from the authors upon request.
Model comparison criteria
There exist a variety of methodologies to compare several competing models for a given data set and to select the one that best fits the data. Here we consider one of the most used in applied researches, which is derived from the conditional predictive ordinate statistic. For a detailed discussion on the CPO statistic and its applications to model selection see Gelfand et al. (1992) and Geisser & Eddy (1979). Let the full data and denote the data with the -th observation deleted. In our model, for an observed time to event we have from Section 3 that and, for a censored time, . We denote the posterior density of given by For the -th observation, can be written as
A Monte Carlo estimate of can be obtained by using a single MCMC sample from the posterior distribution . Let be a sample of size of after the burn-in. A Monte Carlo approximation of (Dey et al., 1997) is given by
For model comparison we use the log pseudo marginal likelihood (LPML) defined by . The larger is the value of LPML, the better is the fit of the model.
Other criteria as, the deviance information criterion proposed by Spiegelhalter et al. (2002), the expected Akaike information criterion (EAIC) – Brooks (2002), and the expected Bayesian (or Schwarz) information criterion (EBIC) – Carlin and Louis (2001) can also be used. These criteria are based on the posterior mean of the deviance, which can be approximated by , where . The DIC can be estimated using the MCMC output by , with is the effective number of parameters, which is defined as , where is the deviance evaluated at the posterior mean and is be estimated as
Similarly, the EAIC and EBIC criteria can be estimated by means of and , where is the number of model parameters.
Bayesian case influence diagnostics
Generally, when regression modeling is considered, a sensitivity analysis is strongly advisable since model it may be sensitive to the underlying model assumptions. Cook (1986) uses this idea to motivate his assessment of influence analysis. He suggests that more confidence can be put in a model which is relatively stable under small modifications. The best known perturbation schemes are based on case-deletion (Cook & Weisberg, 1982) in which the effects are studied of completely removing cases from the analysis. This reasoning will form the basis for our Bayesian global influence methodology and in doing so it will be possible to determine which subjects might be influential for the analysis.
Let denote the -divergence between and , where denotes the posterior distribution of for full data, and denotes the posterior distribution of without the th case. Specifically,
where is a convex function with . Several choices of are given in Dey & Birmiwal (1994). For example, defines Kullback-Leibler (K-L) divergence, gives -distance (or the symmetric version of K-L divergence), defines the variational distance or norm and defines the -square divergence.
The relationship between the CPO Eq. (16) and the -divergence measure is given by
where the expected value is taken with respect to the joint posterior distribution .
In particular, the K-L divergence can be expressed by
From Eq. (17), we can compute by sampling from the posterior distribution of via MCMC methods. Let be a sample of size from . Then, a Monte Carlo estimate of is given by
From Eq. (19) a Monte Carlo estimate of K-L divergence is given by
The can be interpreted as the -divergence of the effect of deleting of -th case from the full data on the joint posterior distribution of As pointed by Peng and Dey (1995) and Weiss (1996) (see, also Cancho et al., 2010, 2011), it may be difficult for a practitioner to judge the cutoff point of the divergence measure so as to determine whether a small subset of observations is influential or not. In this context, we will use the calibration proposal given by Peng and Dey (1995) and Weiss (1996).
Simulation study
A simulation study was performed with two objectives in mind, the first being to evaluate the frequentist properties of the parameter estimates for the proposed models as well as a misspecification study in order to verify if we can distinguish between the cure models in the light of a dataset based on the model selection criterion described in Section 3. The second being to examine the performance of the proposed diagnostics measures, by considering simulated datasets with one or more perturbed cases.
We considered the GBScr model under three (first, last and random) activation mechanisms with a BS distribution for the event times () with parameter and . Moreover, for each individual , , the number of causes of the event of interest for this individual, (), is generated from a geometric distribution with parameter . We assume as a binary covariate with values drawn from a Bernoulli distribution with parameter . We took and so that the cured fraction for the two levels of are and respectively. The censoring times are sampled from a uniform distribution on the interval , where controls the proportion of censoring of the uncured population, in this study the proportion of censored observation is taken approximately to be equal to 50%.
Frequentist properties
In order to evaluate the frequentist properties of the Bayesian estimates for the proposed models as well as to discovery if we can distinguish between the cure models in the light of a dataset based on the model selection criterion described in Section 3 we performed the following simulation study.
The following independent priors are considered to perform the Metropolis-Hasting algorithm, for , and . Thus, our choice is to assume weakly but informative prior. Because, our prior is still informative the posterior is always proper. After a burn-in, we considered 40,000 MCMC posterior samples. We monitored convergence of the Metropolis-Hasting algorithm using the method proposed by Geweke (1992), as well as trace plots. We considered jumps from ten to ten samples from the 40,000 MCMC posterior samples to reduce the autocorrelations and yield better convergence results.
We generated samples of size for each of the three different activation structures, namely first, random and last activations. For each one of them we generated 500 Monte Carlo datasets. Once the data were simulated we fitted the GBScr models based on the three activation structures and recorded the frequentist mean squared error (MSE) and the frequentist mean (Mean) of the parameters, and the DIC, EAIC, EBIC and LPML criteria. Table 1 shows the simulation summary statistics for the parameters assuming the models described in Eqs (4), (7) and (8), crossed with the three simulated mechanisms of activation. The MC Mean denotes the arithmetic average of the parameter estimates given by , the MC RMSE denotes the empirical mean squared error given by , where is the respective true value of the estimated parameter . Overall, the MC Mean are very close to the true value as well as the MC MSE are small, particularly when the fitted model matches the true model.
Simulation summary statistics for the cured fraction parameters assuming the models described in in Eqs (4), (7) and (8), crossed with the three mechanisms of activation simulated based on Monte Carlos datasets
Fitted model
True
Cured
First-activation
Last-activation
Random-activation
model
fraction
MC mean
MC MSE
MC mean
MC MSE
MC mean
MC MSE
First
0.635
0.054
0.641
0.068
0.603
0.075
0.170
0.061
0.154
0.077
0.164
0.079
Last
0.641
0.093
0.628
0.066
0.589
0.095
0.209
0.095
0.170
0.068
0.215
0.089
Random
0.596
0.064
0.602
0.068
0.627
0.047
0.152
0.070
0.172
0.066
0.175
0.045
Table 2 shows the percentage of samples in which the true model, from which the sample was generated, was indicated as the best one according to the DIC, EAIC, EBIC and LPML criteria. Overall, we observe that the true model is evidenced (the true model from which the sample was generated shows a higher percentage).
Percentages of samples in which the fitted model was indicated as the best one according to the DIC, EAIC, EBIC and LPML criteria
Fitted model
True model
First-activation
Last-activation
Random-activation
First
87.8
8.2
4.6
Last
5.7
85.2
7.8
Random
9.7
12.1
78.2
Influence of outlying observations
To examine the performance of the proposed Bayesian case influence diagnostics approach we considered simulated datasets with one or more of the generated perturbed cases. We consider a sample of size generated by the GBScr model under the first activation mechanism. In the simulated data, ranged to with median , mean and standard deviation . We selected cases , and for perturbation. To create influential observations in the dataset, we choose one, two or tree of these selected cases and perturbed the response variable as follows: , ; and , where is the standard deviations of the ’s. We then fitted the GBScr model under first activation mechanism. The MCMC computations were done similar to those in the Section 4.1. Further we used the methods recommended by Cowles and Carlin (1996) to monitor the convergence of the Gibbs samples.
Table 3 shows the posterior inference for the parameters , , and and the Monte Carlo estimates of the DIC, EAIC, EBIC and LPML for each perturbed version of the original dataset. In the Table 3, dataset (a) denotes the original simulated dataset with no perturbations while the datasets (b)–(f) denote datasets with perturbed cases. The estimates of , and are little sensitive to the perturbation of the selected case(s). However, the estimated of the parameter is very sensitive to them. According to all the criteria, the fitted the GBScr model with the original dataset stands out as the best one.
Mean, Standard Deviation(SD) and Bayesian criteria of the GBScr model parameters under a first activation mechanism for each datasets
Dataset
Perturbed
DIC
EAIC
EBIC
LPML
names
case
a
none
1.885
4.983
0.757
1.657
803.76
807.95
821.14
401.71
(0.211)
(1.264)
(0.219)
(0.270)
b
1
2.038
7.113
0.676
1.677
820.22
824.41
837.60
410.54
(0.331)
(2.796)
(0.233)
(0.280)
c
50
2.047
6.704
0.678
1.651
822.53
826.78
839.98
411.63
(0.294)
(2.255)
(0.222)
(0.284)
d
170
2.058
6.744
0.687
1.678
818.09
822.21
835.40
409.49
(0.290)
(2.268)
(0.228)
(0.280)
e
{1,50}
2.424
10.710
0.564
1.641
836.06
840.94
854.13
418.60
(0.552)
(6.826)
(0.249)
(0.283)
f
{1,50,170}
2.688
13.466
0.500
1.629
847.24
851.93
865.13
424.06
(0.684)
(11.204)
(0.251)
(0.281)
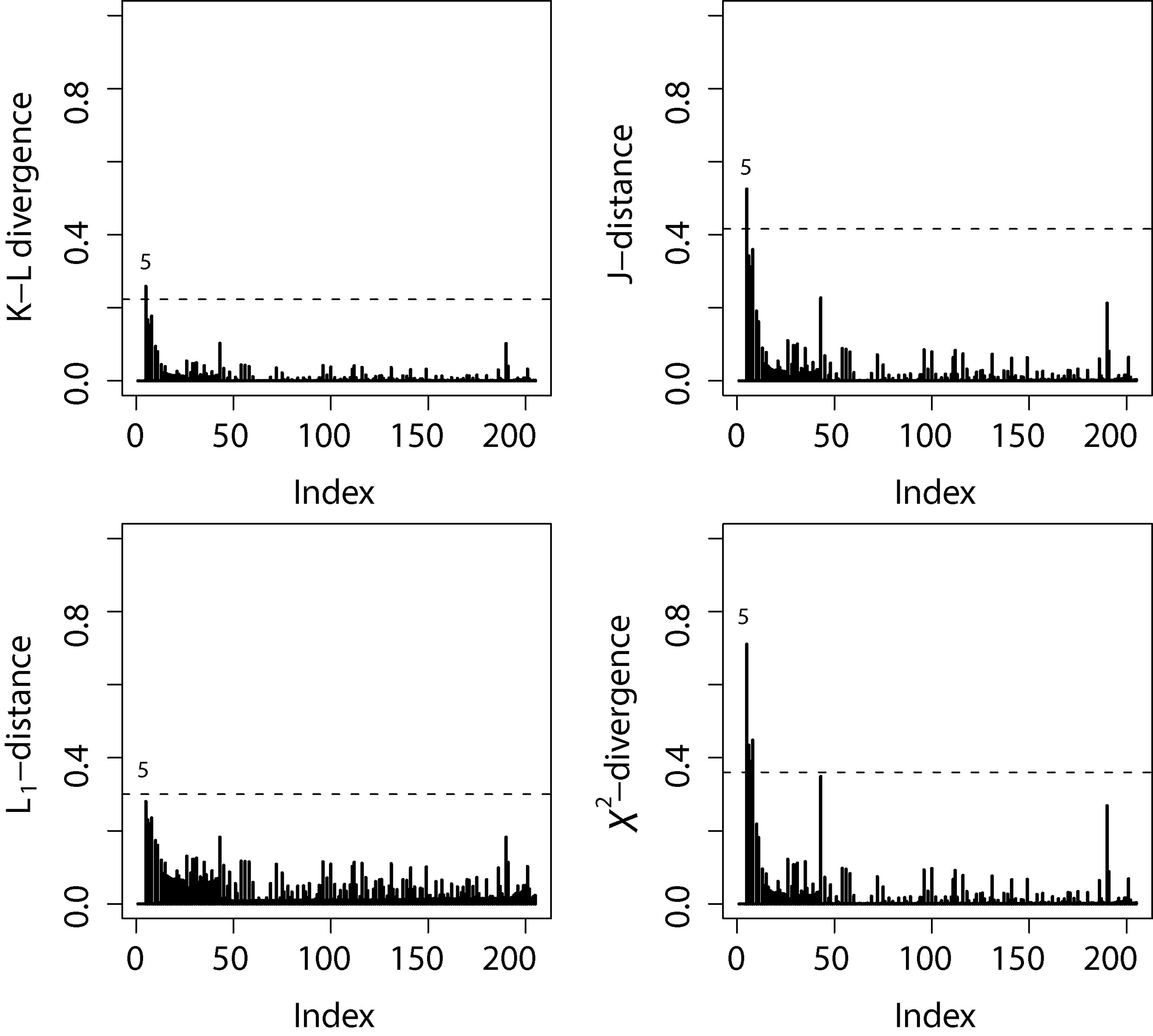
Now we consider the sample from the posterior distributions of the parameters of the GBScr model under the first activation mechanism to calculate the -divergence measures in Eq. (3.3) described in Section 3.3. The results in Table 4 show, before perturbation (dataset (a)), that all the selected cases are not influential according to all -divergence measures. However, after perturbation (datasets (b)–(f)), the measures increase indicating that the perturbed cases are influential. We use the calibration proposed by Peng and Dey (1995), for example, if we use K–L divergence, we can consider the th case as influential observation when . Similarly, using the J-distance or norm or s divergence, an observation which for or or can be considered respectively as influential.
-divergence measures for the simulated data fitting the logarithmic cure rate model under the first activation mechanism
Dataset names
Case number
a
13
0.134
0.277
0.208
0.349
50
0.006
0.013
0.045
0.013
170
0.003
0.005
0.028
0.005
b
1
0.657
1.477
0.465
4.775
c
50
0.567
1.220
0.430
2.730
d
170
0.694
1.615
0.467
6.485
e
1
0.249
0.579
0.291
1.327
50
0.268
0.626
0.302
1.495
f
1
0.273
0.561
0.389
0.818
50
0.304
0.673
0.340
0.983
170
0.311
0.715
0.284
1.011
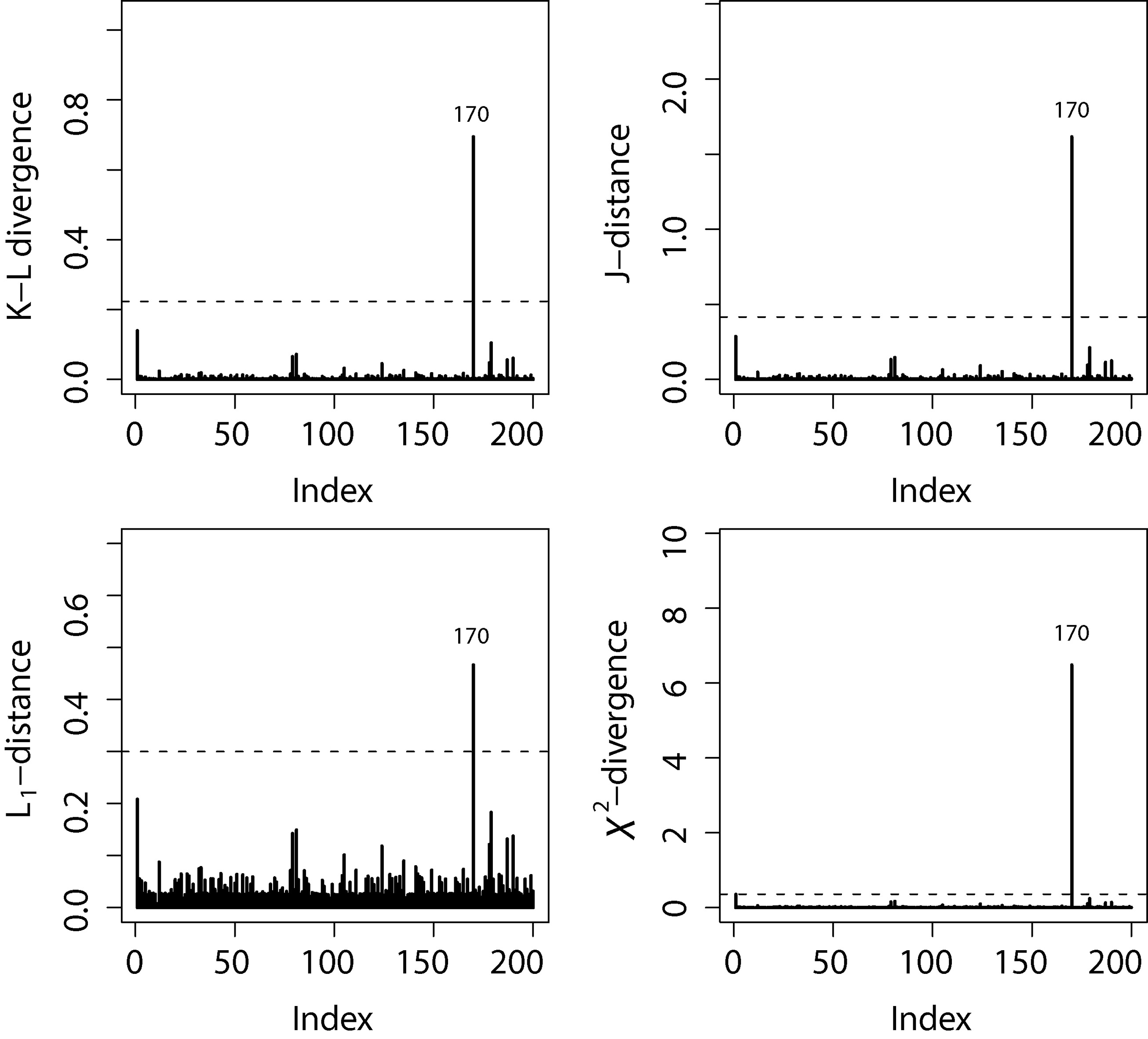
In the Fig. 5, we have depicted the four -divergence measures for the case (d). Clearly we can see that all measures performed well to identifying influential case(s), providing larger -divergence measures when compared to the other cases.
-divergence measures from dataset (d).
Application
In this section we work out an example employing the modeling presented in Section 2. The data set includes 205 patients observed after operation for removal of malignant melanoma in a period of follow up of 15 years. These data are available in the timereg package in R (Scheike, 2009). The observed time ranges from 10 to 5565 days (from 0.0274 to 15.25 years, with mean 5.9 and standard deviation 3.1 years) and refers to the time until the patient’s death or the censoring time. Patient dead from other causes, as well as patients still alive at the end of the study are assumed to be censored observations (72%). We take tumor thickness () (in mm, mean 2.92 and standard deviation 2.96), ulceration status () (absent, 115; present, 90) and sex () (female, 126; male 79) as covariates.
The malignant melanoma is a type of skin cancer which is common worldwide. Even though the exact causes are unknown, as pointed out in Section 2, we may speculate on some possible causes for the malignant melanoma patients data. Although the malignant melanoma seems to be predominantly associated with excessive exposure to sun, it may also arise for individuals who have a history of sunburns and chronic sun exposure. Moreover, various different genes have been identified as risks for developing malignant melanoma (Greene, 1998). In this context, malignant melanoma may also arises in some families with a recognized gene mutation. Besides, multiple genetic events have been related to the disease development (Halachmi & Gilchrest, 2001).
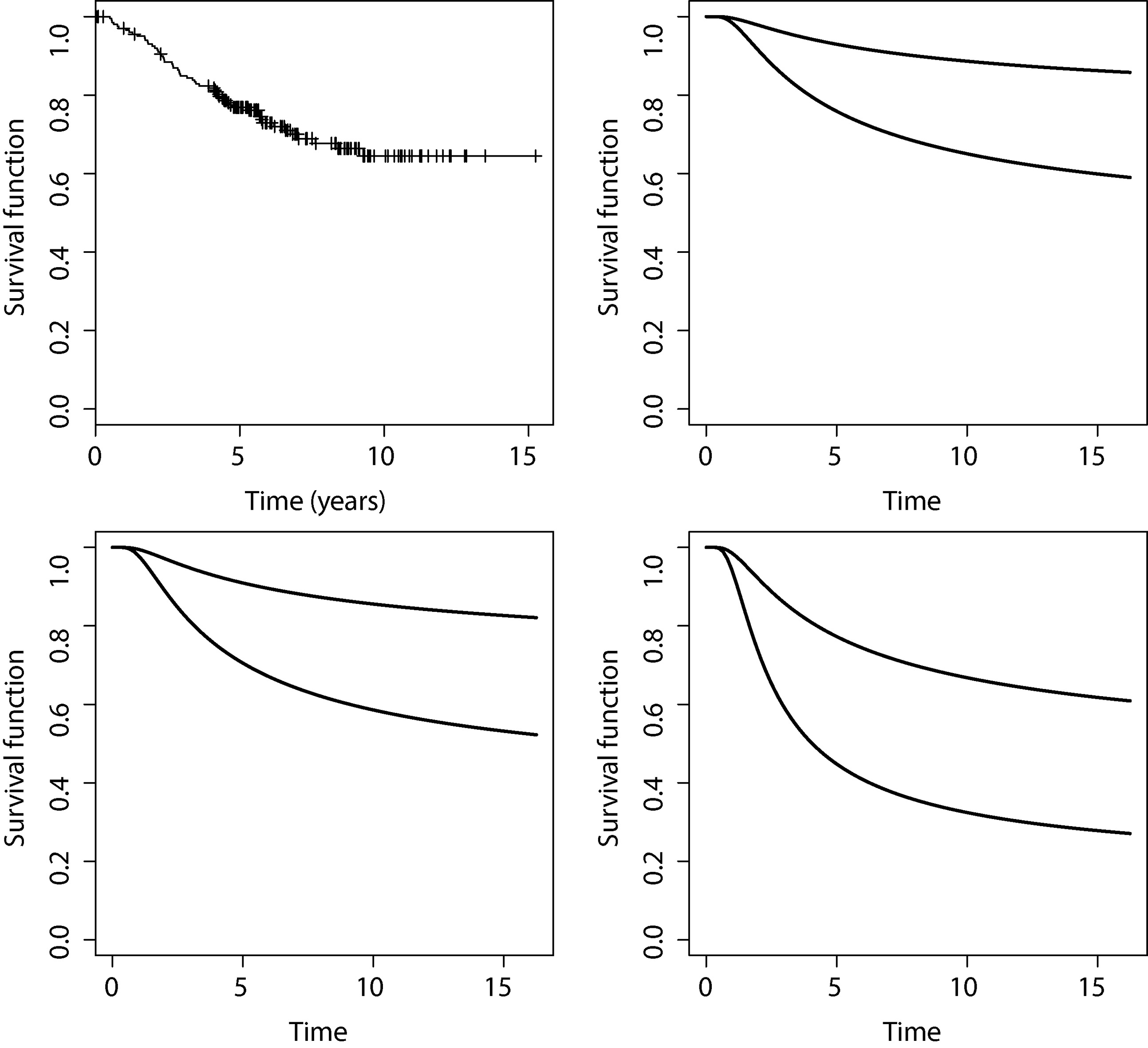
The question here is whether the malignant melanoma occurrence is activated by a first, random or last activation mechanism. That is, a minimum, random or maximum is responsible for the production of the event of interest? Moreover here, the cumulative damage in malignant melanoma patients, caused by various unknown causes, may leads to a fatigue process, which may be suitable modeled by a BS distribution (Leiva et al., 2007). In this context, the GBScr models seems to be aligned, offering the possibility of seeking for the more adequate activation mechanism in the light of the data. Furthermore, the Kaplan-Meier estimate of the surviving function is presented in Fig. 7 (upper left panel). The presence of a plateau above 0.6 indicates that models that ignore the possibility of a cure fraction will not be suitable for these data.
Then, we fitted the GBScr models described in Section 2 according to Eqs (4), (7) and (8), crossed with the three simulated mechanisms of activation. For all models the following independent priors were adopted in the Bayesian computations , and A quantity of 60,000 MCMC posterior samples were used in this analysis after burn-in. We used every twentieth sample from the 60,000 MCMC posterior samples to reduce the autocorrelations and yield better convergence results.
Bayesian criteria for the fitted models
Criterion
Activation
DIC
EAIC
EBIC
LPML
First
423.32
430.90
450.84
212.48
Last
434.11
440.31
460.25
221.21
Random
428.85
435.28
451.90
219.09
To compare the fits of the GBScr model with first, last and random activation mechanisms, we also obtained the values of DIC, EAIC, EBIC and LPML. These criteria of information provide the values presented in Table 5. According to all the criteria, the GBScr model under the first activation mechanism stands out as the best one, which we then select as our working model.
The posterior means, medians, standard deviations and 95% highest posterior density (HPD) intervals for the parameters of the GBScr model under the first activation mechanism are shown in Table 6. The covariates have a significant effect on the reduction of the cured fraction. The maximum likelihood estimates and the corresponding asymptotic 95% intervals in parentheses for the parameters of this models are given by 1.349 [0.613 , 2.966], 10.192 [2.066, 50.278] 1.475 [ 0.312 , 2.637], 0.160 [0.263, 0.057], 1.395 [2.091, 0.699] and 0.623 [1.272, 0.026]. Comparison between the results shows that the asymptotic 95% confidence intervals turned out to be more conservative than the the Bayesian intervals presented in Table 6. We recall that the Bayesian approach was implemented with minimum prior information.
Posterior summaries of the parameters for the Log-1 model
HPD Interval (95%)
Parameter
Mean
Median
Standard deviation
LI
LS
1.339
1.260
0.371
0.845
2.276
10.758
8.799
6.653
4.355
28.935
1.597
1.595
0.449
0.714
2.457
0.158
0.158
0.053
0.264
0.054
1.419
1.414
0.367
2.111
0.711
0.626
0.627
0.338
1.291
0.044
Considering the of the GBScr model under the first activation mechanism the -divergence measures in Eq. (3.3) described in Section 3.3 were computed. The Fig. 6 shows the index plot of the four -divergence measures. For all -divergence measures, the case 5 was identified as the most influential.
Index plots of -divergence measures for the melanoma data.
The relative changes (in percentage) of each parameter estimate, defined by , where denotes the posterior mean of , with , after the observations has been removed. The RC in posterior means and the corresponding 95% HPD intervals in parentheses for the parameters of the GBScr model under the first activation mechanism are given by 4.24 [0.815;2.128] for , 0.170 [4.331;29.362] for , 4.586 [0.605;2.400] for , 11.510 [-0.245;-0.0332] for 1.873 [-2.183;-0.759] for and 6.814 [-1.246;0.142] for . We notice that there are little in posterior mean with exception to after dropping the observation 5. However, there is no changes in the inferences for the coefficients. Thus, the final selected GBScr model in our analysis has cure rate given by
If follows that the posterior means(standard deviations) and 95% HPD intervals for , and are given by 1.343 (0.361) and [0.857;2.289] for , 10.384 (6.035) and [4.407;28.081] for , 1.391 (0.403) and [0.576;2.166] for , 0.169 (0.053) and [0.276; 0.057] for and 1.433(0.363) and [2.149; 0.749] for . The values of (DIC, LPML) are (423.85, 213.09), respectively.
Now we turn our attention to the role of the covariates on the cured fraction . Table 7 shows the posterior summaries for the cured fraction stratified by ulceration status with tumor thickness equal to 0.32, 1.94 and 8.32 mm, which correspond to the 5, 50 and 95 percentiles, under the GBScr model under the first activation mechanism. Fig. 7 displays the survival function stratified by ulceration status for patients with tumor thickness equal to 0.32, 1.94 and 8.32 mm. These plots highlight the combined impact of the covariates on the cured fraction. For each selected tumor thickness value the intervals do not overlap.
Upper left panel: Kaplan-Meier estimate of the surviving function. Surviving function under the GBScr model under the first activation mechanism stratified by ulceration status (upper: absent, lower: present) for patients with tumor thickness equal to 0.64 (upper right panel), 1.94 (lower left panel) and 8.32 mm(lower right panel).
Posterior summaries of the cured fraction stratified by ulceration status and selected tumor thickness under GBScr model
Tumor thickness
Ulceration
Mean
Median
Standard deviation
95% HPD interval
0.64
Absent
0.766
0.786
0.067
(0.626, 0.898)
Present
0.464
0.465
0.094
(0.286, 0.651)
1.94
Absent
0.737
0.748
0.073
(0.577, 0.855)
Present
0.411
0.412
0.086
(0.251, 0.583)
8.32
Absent
0.564
0.570
0.104
(0.363, 0.752)
Present
0.245
0.241
0.069
(0.124, 0.391)
We end up our application dealing with the estimation of the proportion of patients non cured who survived beyond a certain fixed time, which is the practical interest to practitioners. For sake of illustration we choose 5 years. This proportion is estimated from (model under the first activation mechanism) given in Eq. (9). Considering posterior samples of the parameters of the GBScr model, the estimated of Monte Carlo of stratified by ulceration status (absent, present) for non cured patients with tumor thickness equal to 0.32, 1.94 and 8.32 mm (joint with the posterior standard deviation) are given by (0.600 [0.095], 0.477 [0.085]), (0.585 [0.093], 0.441[0.078]) and (0.484 [0.0.091], 0.273 [0.066]).
Concluding remarks
In this paper we proposed the geometric Birnbaum-Saunders cure rate model under different activation mechanisms. Moreover, we propose an influence diagnostic approach from the Bayesian point of view, based on the -divergence (Peng & Dey, 1995; Weiss, 1996) between the posterior distributions of the parameters of the proposed model. Our simulation study indicates that it is possible to discriminate among its particular cases based on the DIC, EAIC, EBIC and LPML criteria. In the application to a melanoma dataset we discovered the GBScr model under the first activation mechanism provides the best fit. Moreover, we observed that the surviving probability decreases more rapidly for patients with thicker tumors, and that the cured fraction is lower for patients with ulceration.
There are some open questions which must be considered further. For instance, we only consider, as usual in the survival literature, that censored observations are subjects who either die of causes other than the disease of interest or are lost during the follow-up. However, as pointed out by a referee, we do not know that deaths from other causes are non informative and can be taken as censored observations. Moreover, the above issue together with the first activation mechanism standing out as an competing risk problem, in which the number of risks as well as the risk responsible for the occurrence of the event of interest are unknown. In this context, which influence could have the other deaths on the results if they were somehow related to T? How would the marginal estimation of would change and how much the coefficients would be affected? Those questions must be addressed elsewhere.
References
1.
Arellano-ValleR.Galea-RojasM., & ZuazolaP. I. (2000). Bayesian sensitivity analysis in elliptical linear regression models. Journal of Statistical Planning and Inference, 86(1),175-199.
2.
BalakrishnanN., & KunduD. (2019). Birnbaum-saunders distribution: A review of models, analysis, and applications. Appl Stochastic Models Bus Ind, 35, 4-49.
3.
BerksonJ., & GageR. P. (1952). Survival curve for cancer patients following treatment. Journal of the American Statistical Association, 47, 501-515.
4.
BirnbaumZ. W., & SaundersS. C. (1969). A new family of life distributions. Journal of Applied Probability, 6(2), 319-327.
5.
BoagJ. W. (1949). Maximum likelihood estimates of the proportion of patients cured by cancer therapy. Journal of the Royal Statistical Society B, 11, 15-53.
6.
BrooksS. P. (2002). Discussion on the paper by Spiegelhalter, Best, Carlin, and van der Linde (2002). Journal of the Royal Statistical Society B, 64, 616-618.
7.
CanchoV.OrtegaE., & BolfarineH. (2009). The log-exponentiated-weibull regression models with cure rate: Local influence and residual analysis. Journal of Data Science, 7, 433-458.
8.
CanchoV.OrtegaE., & PaulaG. (2010). On estimation and influence diagnostics for log-birnbaum-saunders student-t regression models: Full Bayesian analysis. Journal of Statistical Planning and Inference, 140(9), 2486-2496.
9.
CanchoV.DeyD.LachosV., & AndradeM. (2011). Bayesian nonlinear regression models with scale mixtures of skew-normal distributions: Estimation and case influence diagnostics. Computational Statistics & Data Analysis, 55(1), 588-602.
10.
CanchoV.de CastroM., & RodriguesJ. (2012a). A bayesian analysis of the conway-maxwell-poisson cure rate model. Statistical Papers, 53, 165-176.
11.
CanchoV.LouzadaF., & BarrigaG. (2012b). The geometric Birnbaum-Saunders regression model with cure rate. Journal of Statistical Planning and Inference, pp. 99-1000.
12.
CanchoV.BandyopadhyayD.LouzadaF., & YiqiB. (2013). The destructive negative binomial cure rate model with a latent activation scheme. Statistical Methodology, 13, 48-68.
13.
CarlinB. P., & LouisT. A. (2001). Bayes and Empirical Bayes Methods for Data Analysis. Chapman & Hall/CRC, Boca Raton, second edition.
14.
CarlinB. P., & PolsonN. G. (1991). An expected utility approach to influence diagnostics. Journal of the American Statistical Association, 86(416), 1013-1021.
15.
ChoH.IbrahimJ. G.SinhaD., & ZhuH. (2009). Bayesian case influence diagnostics for survival models. Biometrics, 65(1), 116-124.
16.
CookR. D. (1986). Assessment of local influence. Journal of the Royal Statistical Society, Series B, 48, 133-169.
17.
CookR. D., & WeisbergS. (1982). Residuals and Influence in Regression. Chapman & Hall/CRC, Boca Raton, FL.
18.
CoonerF.BanerjeeS., & McBeanA. M. (2006). Modelling geographically referenced survival data with a cure fraction. Statistical Methods in Medical Research, 15, 307-324.
19.
CoonerF.BanerjeeS.CarlinB. P., & SinhaD. (2007). Flexible cure rate modeling under latent activation schemes. Journal of the American Statistical Association, 102, 560-572.
20.
CowlesM. K., & CarlinB. P. (1996). Markov chain Monte Carlo convergence diagnostics: A comparative review. Journal of the American Statistical Association, 91, 883-904.
21.
CoxD. R., & HinkleyD. V. (1979). Theoretical statistics. Chapman & Hall/CRC.
22.
DeyD., & BirmiwalL. (1994). Robust bayesian analysis using divergence measures. Statistics & Probability Letters, 20(4), 287-294.
23.
DeyD.ChenM., & ChangH. (1997). Bayesian approach for nonlinear random effects models. Biometrics, pp. 1239-1252.
24.
Díaz-GarcíaJ. A., & Leiva-SánchezV. (2005). A new family of life distributions based on the elliptically contoured distributions. Journal of Statistical Planning and Inference, 128(2), 445-457.
25.
GeisserS., & EddyW. (1979). A predictive approach to model selection. Journal of the American Statistical Association, pp. 153-160.
26.
GelfandA.DeyD., & ChangH. (1992). Model determination using predictive distributions with implementation via sampling based methods (with discussion). bayesian statistics 4. eds: BernardoJ. et al. JMBernardoJOBergerAPDawidAFMSmith (editors). Oxford University Press, 1(4), 7-167.
27.
GelfandA. E., & SmithA. F. (1990). Sampling-based approaches to calculating marginal densities. Journal of the American Statistical Association, 85(410), 398-409.
28.
GewekeJ. (1992). Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. bayesian statistics 4. eds: J. bernardo et al. BernardoJ MBergerJ ODawidA PSmithAFM (editors). Oxford University Press, 1(4), 169-188.
29.
GómezH. W.Olivares-PachecoJ. F., & BolfarineH. (2009). An extension of the generalized Birnbaum-Saunders distribution. Statistics and Probability Letters, 79(3), 331-338.
30.
GreeneM. H. (1998). The genetics of hereditary melanoma and nevi. Cancer, 86(11), 2464-2477.
31.
HalachmiS., & GilchrestB. A. (2001). Update on genetic events in the pathogenesis of melanoma. Current Opinion in Oncology, 13(2), 129-136.
KimS.ChenM., & DeyD. (2011). A new threshold regression model for survival data with a cure fraction. Lifetime data analysis, 17(1), 101-122.
34.
LeivaV.BarrosM.PaulaG., & GaleaM. (2007). Influence diagnostics in log-birnbaum-saunders regression models with censored data. Computational Statistics & Data Analysis, 51(12), 5694-5707.
35.
LiC. S.TaylorJ. M., & SyJ. P. (2001). Identifiability of cure models. Statistics and Probability Letters, 54, 389-395.
36.
MallerR. A., & ZhouX. (1996). Survival Analysis with Long-Term Survivors. Wiley, New York.
37.
PengF., & DeyD. (1995). Bayesian analysis of outlier problems using divergence measures. Canadian Journal of Statistics, 23(2), 199-213.
38.
PettitL. (1986). Diagnostics in bayesian model choice. The Statistician, pages 183-190.
39.
R Development Core Team (2010). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria.
40.
RodriguesJ.CanchoV. G.de CastroM., & Louzada-NetoF. (2009). On the unification of the long-term survival models. Statistics & Probability Letters, 79, 753-759.
41.
SanhuezaA.LeivaV., & BalakrishnanN. (2008). The Generalized Birnbaum-Saunders Distribution and Its Theory, Methodology, and Application. Communications in Statistics-Theory and Methods, 37(5), 645-670.
42.
ScheikeT. (2009). timereg package. R package version 1.1-0. With contributions from T. Martinussen and J. Silver. R package version 1.1-6.
43.
SpiegelhalterD. J.BestN. G.CarlinB. P., & van der LindeA. (2002). Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society B, 64, 583-639.
44.
SuzukiA.CanchoV., & LouzadaF. (2016). The poisson-inverse-gaussian regression model with cure rate: a bayesian approach and its case influence diagnostics. Statistical Papers, 57, 133-159.
45.
SuzukiA.BarrigaG.LouzadaF., & CanchoV. (2017). A general long-term aging model with different underlying activation mechanisms: Modeling, bayesian estimation and case influence diagnostics. Communications in Statistics – Theory and Methods, 46, 3080-3098.
46.
TsionasE. G. (2001). Bayesian inference in Birnbaum-Saunders regression. Communications in Statistics-Theory and Methods, 30(1), 179-193.
47.
TsodikovA. D.IbrahimJ. G., & YakovlevA. Y. (2003). Estimating cure rates from survival data: An alternative to two-component mixture models. Journal of the American Statistical Association, 98, 1063-1078.
48.
WeissR. (1996). An approach to bayesian sensitivity analysis. Journal of the Royal Statistical Society. Series B (Methodological), pages 739-750.
49.
WeissR. E., & CookR. D. (1992). A graphical case statistic for assessing posterior influenceo. Biometrika, 79(1), 51-55.
50.
XuA., & TangY. (2011). Bayesian analysis of Birnbaum-Saunders distribution with partial information. Computational Statistics & Data Analysis, 55(7), 2324-2333.
51.
YakovlevA. Y., & TsodikovA. D. (1996). Stochastic Models of Tumor Latency and Their Biostatistical Applications. World Scientific, Singapore.