In this paper, we introduce a multiple-inflated Poisson distribution that can handle count data with multiple inflated values. We explore a Bayes predictive distribution for future observation under Kullback Leibler loss function and a class of shrinkage priors, along with plug-in type pmf estimators. To illustrate how well the proposed pmf estimators perform, we provide both a simulated study and a real example analyzing a dataset of National Hockey League (NHL) shootout losses in 2017/18.
Often the times discrete frequency distributions involve counts of occurrences of events, such as the number of goals in a match, accident fatalities, suicides or insurance claims. The most commonly used model to analyze this kind of data is a Poisson distribution. However, in many practical situations, the Poisson distribution fails to model count data which exhibits over-dispersion (i.e., the variance exceeds the mean). Furthermore, another situation that makes the Poisson distribution less applicable is the excess number of zeros in a dataset (zero-inflation).
The zero-inflated model () is used where the observed number of zeros exceeds that which is expected by a Poisson distribution (see Mullahy, 1986; Lambert, 1992). There are many situations that the model is used; for example, in insurance (Yip & Yau, 2005), industry and manufacturing processes (Ghosh et al., 2006), health insurance (Mouatassim & Ezzahid, 2012) and public health data (Unhapipat, 2018).
In addition, some data sets may have multiple inflated counts of additional value rather than zero (multiple-inflation) and bulking of certain values can happen. For example, in datasets such as the number of red (or yellow) cards in the Premier League, penalties taken in certain season national hockey league (NHL), times a woman received a mammogram in the past two years, or days in week someone drinks alcohol, we would expect to see excess zeros and/or ones that we do not expect to see in the Poisson model. Lin and Tsai (2016) have discussed a model that can be applied to both excessive zeros and ones known as the zero-and-one-inflated Poisson, or (), model.
This paper considers predictive estimation of future probability mass function (pmf) in a multiple-inflated Poisson model, and, more specifically, a model that can be applied to a dataset with two inflated values, namely and . This model embraces all the inflated Poisson models and can be extended to inflated values, for .
The remainder of the article is organized as follows. In Section 2, we introduce the multiple-inflated Poisson models along with the corresponding likelihood function. Section 3 addresses the Bayesian setup and we discuss how to find the Bayesian predictive distribution under the Kullback Leibler loss function and the improper shrinkage prior. In Section 4, by simulating the inflated data, we compare the proposed Bayes predictive distribution with other kinds of pmf estimators called plug-in pmf estimators. In Section 5, we apply our obtained pmf estimators to real data from a hockey game. Finally, we make some concluding remarks in Section 6.
Problem set-up
One of the simplest methods for modeling count data is the Poisson distribution, denoted by , with the pmf
The pmf in Eq. (1) gives the probability of the event occurring over a large number of independent trials (in time or space), when the probability of that the event occurs on any one trial is small and constant. Therefore, the Poisson distribution is often used to model rare events such as highway accidents, earthquakes, incidents of terrorism, or the number of particles emitted from a small radioactive sample. The variance in the Poisson model Eq. (1) is identical to the mean (), thus making the variance equal one.
Another distribution that might be used in modelling of count data which permits the over-dispersion is a negative binomial distribution. A random variable has the pmf
The pmf in Eq. (2) shows the probability of a certain number of independent events occurring prior to a specific amount of failures. The mean and variance of the negative binomial distribution in Eq. (2) are and respectively, and the variance is greater than the mean.
The distribution in Eq. (2) can be considered a gamma mixture of Poisson distributions. If we let in Eq. (1) follows the gamma distribution , with the probability density function (pdf) , for and , then the resulting distribution is the negative binomial as in Eq. (2). Note that as , the pmf in Eq. (2) tends to Eq. (1).
In addition to over-dispersion, often datasets exhibit more zero or other observations than would be allowed for by the Poisson model or even the negative binomial.
A distribution is a two-component mixture model combining a point mass at zero with a Poisson distribution and it has the pmf
The extra parameter in Eq. (3) is called the inflation parameter (at 0) which, along with parameter , is unknown. The idea of the inflated probability at zero can be extended to another count value, such as . The –inflated Poisson, , arises when the probability is inflated at value . The pmf of is
The model in Eq. (4) reduces to the model in Eq. (3) whenever and the Poisson distribution corresponds to . The multiple-inflate model, is a generalization of the model, including two inflations, and , comparing to the Poisson distribution. The pmf of is given as follows:
where . An intuitive approach to obtain the pmf in Eq. (5) is to define a latent variable which is distributed as a multinomial with , for , where , and . This implies
Therefore, the joint pmf of and is given by
and the marginal pmf of is therefore modeled in Eq. (5).
Likelihood functions
Let us suppose that data points from the model, i.e., and , the number of and for , are quite large. If and , then the likelihood function is given by
Remark 1. The maximum likelihood estimator (mle) of unknown parameters , and in the model can be obtained numerically by considering the constraints , , and from Eq. (8). Similarly, one can use Eq. (9) to find the mle of parameter and in the model.
We need the following definition to set up a Bayesian framework.
Definition 1. Consider the bounded continuous variate , such that and . The Dirichlet distribution is given as
where and . Note that the beta distribution is equivalent to a bivariate Dirichlet distribution with and , and thus, .
Bayesian set-up
Prior and posterior densities
Komaki (2004) introduced a class of improper shrinkage prior for the mean of Poisson distributions as
Jeffreys prior corresponds to and . Let us assume that and ; , , with the pdf as in Eq. (11), be independent, respectively. The following Lemma provides the posterior density given .
Lemma 1. (i) Suppose that , and that prior densities and as in Eq. (11) are independent respectively. Then the posterior density, by assuming
is given by
for , , and .
(ii) Suppose that , and prior densities are and as in Eq. (11) are independent respectively. Then the posterior density by assuming
is given by
Proof Part (i). By replacing likelihood function Eq. (8) and priors in the posterior density formula, we can write
Remark 2. The Bayes estimator of , under the squared error loss function , where can be chosen as any of parameters , and is known to be . According to the posterior distribution Eq. (15), the corresponding estimators for the model are given as follows:
Also, for the model , we have
Bayes predictive distributions
We consider the problem of constructing the Bayes predictive distribution for the future observation , based on observable . We use the Kullback Leibler (KL) loss function (divergence)
where is the Bayes predictive distribution for estimating the pmf , and is a (n) (vector of) unknown parameter (s). The corresponding risk function given as follows
Previous studies (see Corcuera & Giummolè, 1999) indicate that under KL, the Bayes predictive distribution for , based on observed value , and posterior density , is given as
The following theorem provides the Bayes predictive distribution under KL loss function.
Theorem 1. The Bayes predictive distribution of future observation based on observable from
(i) the model, in Eq. (5), with priors defined in Lemma 1 (i), is given by
and for , we have
(ii) The model, in Eq. (5), with priors defined in Lemma 1 (ii), is given by
Proof In (i), using Eq. (21) and Lemma 1 for , we have
Applying Definition 1 the numerator in above, can be written as
The last integral in the above equation, is . This completes the proof of Eq. (24). In order to prove Eqs (23) and (23), respectively, we need to calculate the following equations in similar way to (i):
A similar proof can be done for (ii).
Comparison of bayes predictive distribution and plug-in pmf estimators
The plug-in pmf estimator is obtained by replacing by either the mle of (Remark 1) or by the Bayes estimator under a squared error loss function (Remark 2).
In order to compare the Bayes predictive distributions and the plug-in pmf estimators for future observation from models , and , as well as assessing their performance under KL loss function Eq. (19), a simulation study is carried out in this section. Table 1 represents the frequency table of a sample of size 200 from (a) , (b) with , and (c) , with and , respectively.
Frequency table based on a sample of size 200 from (a) , (b) with , and (c) , with and , respectively
0
1
2
3
4
5
6
7
8
9
10
11
12
(a)
56
7
13
21
29
18
17
16
9
9
4
0
1
(b)
2
6
75
28
26
19
17
11
7
4
3
2
0
(c)
60
2
50
12
18
19
14
8
8
5
2
2
0
Let us assume that and (corresponding to Jeffreys prior for in 11). In case (a), , , and . One can use Remarks 1 and 2 to obtain the mle’s and and Bayes estimators under a squared error loss function and , respectively. Table 2 shows the Bayes predictive distribution for future observation , applying Theorem 1 (ii) and plug-in predictive distributions (based on mle’s) along with corresponding the expected frequencies (rounded to the nearest integers).
The KL loss (divergence) in Eq. (19) for two pmf estimators are very close in this simulation study. Indeed, and , where is our actual underlying distribution .
The Bayes predictive distribution and the plug-in estimator for future observation from and related expected frequencies
0
1
2
3
4
5
6
7
8
9
10
11
12
0.286
0.023
0.060
0.100
0.125
0.126
0.1000
0.080
0.050
0.029
0.014
0.007
0.003
Frequency of
57
6
12
20
25
20
16
10
6
3
1
2
0
0.280
0.023
0.058
0.099
0.125
0.127
0.1072
0.077
0.049
0.027
0.014
0.006
0.004
Frequency of
56
5
12
20
25
25
21
16
10
6
3
1
0
In case (b), , , , and . Table 3 shows the pmf and the expected frequencies (rounded to nearest integers) of Bayes predictive distributions (corresponding to Theorem 1 [ii]) and the plug-in predictive distributions corresponding to mle’s and (Bayes and mle of parameters are equal, i.e., and ).
The Bayes and plug-in predictive distributions for future observation from , with and related expected frequencies
0
1
2
3
4
5
6
7
8
9
10
11
12
0.003
0.014
0.342
0.076
0.106
0.119
0.111
0.089
0.063
0.0390
0.022
0.011
0.005
Frequency of
1
3
68
15
21
24
22
18
13
8
4
2
1
0.015
0.060
0.252
0.166
0.169
0.138
0.094
0.055
0.029
0.0127
0.005
0.002
0.002
Frequency of
3
12
50
33
34
28
19
11
6
3
1
0
0
The KL loss (divergence) in Eq. (19) and , where , is our actual underlying distribution , with .
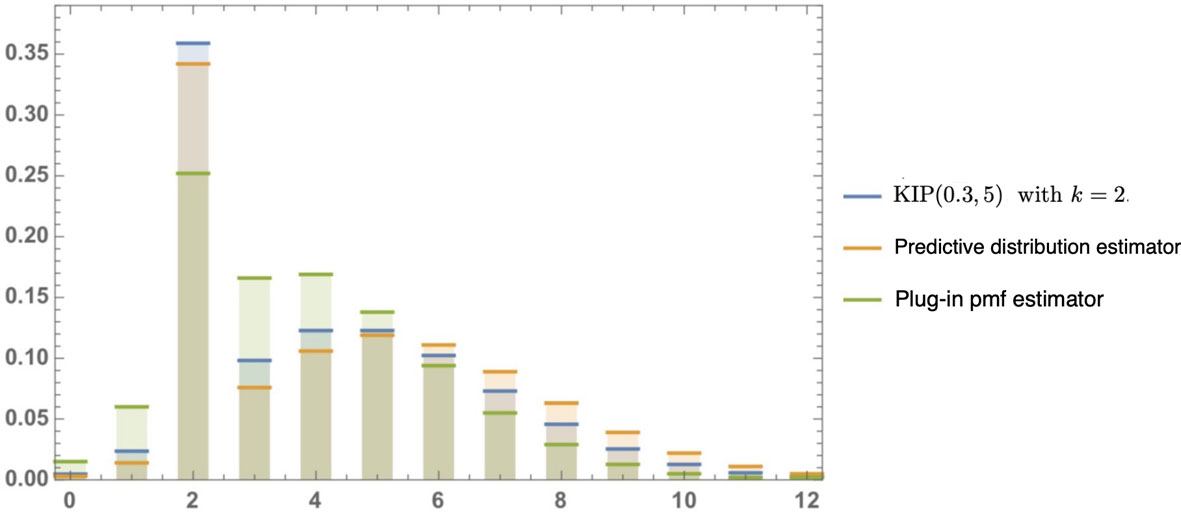
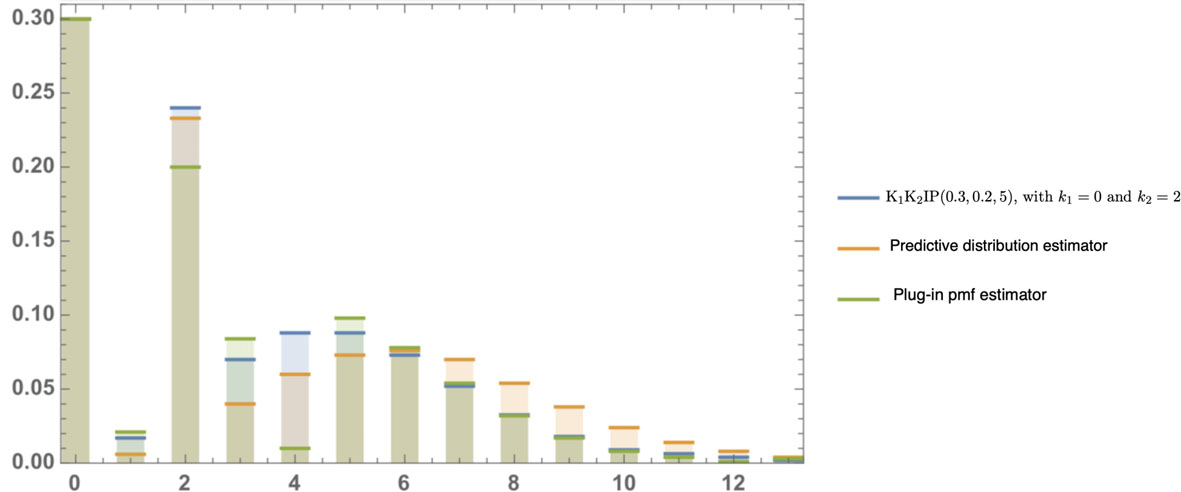
In case (c), , , , , , and . The mle’s of the parameters are , and , and the Bayes estimators under squared error loss are , and . Table 4 and Fig. 2 show the Bayes and plug-in pmf estimators based on the mle’s.
The Bayes and plug-in pmf estimators for future observation from and related expected frequencies
0
1
2
3
4
5
6
7
8
9
10
11
12
13
0.3
0.006
0.233
0.040
0.06
0.073
0.076
0.070
0.054
0.038
0.024
0.014
0.008
0.004
Frequency of
60
1
47
8
11
14
15
14
11
8
5
3
2
1
0.3
0.021
0.200
0.084
0.10
0.098
0.078
0.054
0.032
0.017
0.008
0.004
0.003
0.001
Frequency of
60
4
40
17
20
19
16
11
6
3
2
1
1
0
The pmf’s of the underlying distribution with , along with the Bayes and plug-in estimators related to Table 3.
The pmf’s of the underlying distribution with and , along with the Bayes and plug-in pmf estimators related to Table 4.
The KL loss (divergence) and , where , is our actual underlying distribution , with and .
Real examples
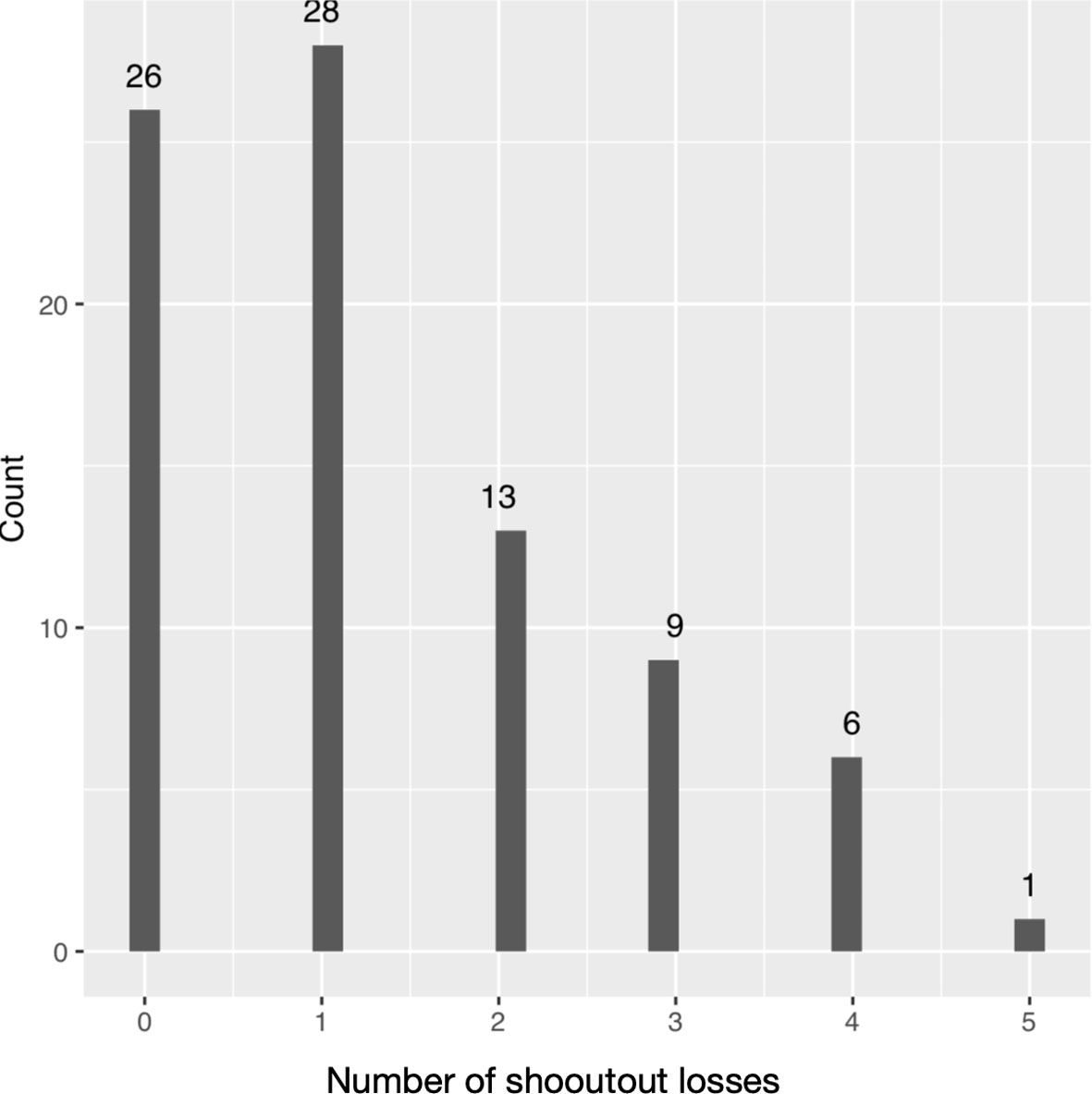
We use the number of shootout losses1 in the NHL for the season 2017/18 (see Fig. 3), and this data is available at http://www.hockeyabstract.com/testimonials/nhlgoalies2017-18www.hockeyabstract.com. The existence of excess zeros and ones in the dataset violate the Poisson assumption, thus making the model with and a perfect model.
Number of shootout losses in the NHL’s 2017/18 season.
Applying Remark 1 gives , and . Likewise, using Remark 2 gives , and .
Below, the pmf’s of the Bayes predictive distribution under KL loss function and Jeffreys prior, along with plug-in pmf estimators based on substituting the unknown parameters by mle and Bayes estimator of parameters (under squared error loss function) are given, respectively.
Table 5 shows the expected frequencies of the Bayes predictive distribution of future number of shootout losses based on Eqs (5) and (28).
The frequency of data as well as the corresponding frequencies of Bayes and plug-in pmf estimators, based on mle and the Bayes estimator of the parameters for future number of shootout losses
0
1
2
3
4
5
6
7
8
9
Data
26
28
13
9
6
1
0
0
0
0
Frequency of
25
28
7
7
6
4
2
2
1
1
Frequency of
27
26
14
8
5
2
1
0
0
0
Frequency of
26
28
7
8
6
4
3
1
0
0
In this example, in order to make a comparison and show the performance of Bayes predictive distribution and the pmf estimators, one can render the Pearson goodness-of-fit test which gives the corresponding -values of 0.940, 0.940 and 0.683, for the Bayes predictive distribution , the plug-in pmf estimator based on the mle and the plug-in pmf estimator based on the Bayes estimator of unknown parameters the , respectively.
One can conclude that the plug-in pmf estimators based on the mle demonstrate the best performance relative to Bayes predictive distributions. To the authors’ best knowledge, for the most of continuous distributions such as normal and gamma distributions under the KL loss function (see for instance L’Moudden et al., 2017; Marchand & Sadeghkhani, 2018), the Bayes predictive density estimators outperform to the plug-in density estimators under the KL loss function. But for the discrete distributions, more specifically , and models we do not have such dominance results. However, based on the obtained -values, the Bayes predictive distribution along with the plug-in pmf estimator fit perfectly to the data in the number if shootout losses’ example.
Conclusions
In summation, we have developed a model for analyzing count data with multiple inflated values that can not be modelled using typical Poisson distribution. Furthermore, we obtained the Bayes predictive distribution as well as plug-in pmf estimator for the future observation from the (a) model (Table 2), (b) model (Table 3) and (c) model (Table 4). We also illustrated the pmf’s of the Bayes predictive distributions along with the plug-in pmf estimators in order to make comparison to the actual frequencies based on simulations from a and models respectively in Figs 1 and 2.
We compared the performance of the obtained pmf estimators via simulation studies and as an application, we estimated the future pmf of the number of shootout losses using data from the NHL’s 2017/18 season. Our results confirm that the proposed pmf estimators fit perfectly to real pmfs based on the Pearson goodness-of-fit test.
Footnotes
Shootout is a method of determining a winner in hockey matches that would have otherwise been drawn or tied.
Acknowledgments
Abdolnasser Sadeghkhani acknowledges the ITAM and Asociación Mexicana de Cultura, A.C. for supporting this paper. S. Ejaz Ahmed acknowledges the Natural Sciences and the Engineering Research Council of Canada, and the Ontario Centre of Excellence for supporting this research. The authors are grateful to the editor and the anonymous reviewer for their valuable comments and helpful suggestions.
References
1.
CorcueraJ. M., & GiummolèF. (1999). A generalized Bayes rule for prediction. Scandinavian Journal of Statistics, 26(2), 265-279.
2.
GhoshS. K.MukhopadhyayP., & LuJ. C. J. (2006). Bayesian analysis of zero-inflated regression models. Journal of Statistical Planning and Inference, 136(4), 1360-1375.
3.
KomakiF. (2004). Simultaneous prediction of independent Poisson observables. The Annals of Statistics, 32(4), 1744-1769.
4.
LambertD. (1992). Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics, 34(1), 1-14.
5.
LinT. H., & TsaiM. H. (2013). Modeling health survey data with excessive zero and K responses. Statistics in Medicine, 32(9), 1572-1583.
6.
L’MouddenA.MarchandÉ.KortbiO., & StrawdermanW. E. (2017). On predictive density estimation for Gamma models with parametric constraints. Journal of Statistical Planning and Inference, 185, 56-68.
7.
MouatassimY., & EzzahidE. H. (2012). Poisson regression and zero-inflated Poisson regression: application to private health insurance data. European Actuarial Journal, 2(2), 187-204.
8.
MullahyJ. (1986). Specification and testing of some modified count data models. Journal of Econometrics, 33(3), 341-365.
9.
MarchandÉ., & SadeghkhaniA. (2018). On predictive density estimation with additional information. Electronic Journal of Statistics, 12(2), 4209-4238.
10.
UnhapipatS.TiensuwanM., & PalN. (2018). Bayesian predictive inference for zero-inflated Poisson (ZIP) distribution with applications. American Journal of Mathematical and Management Sciences, 37(1), 66-79.
11.
YipK. C., & YauK. K. (2005). On modeling claim frequency data in general insurance with extra zeros. Insurance: Mathematics and Economics, 36(2), 153-163.