
Abstract
We consider a panel model with a binary response variable that is a product of two unobservable factors, each determined by a separate binary choice equation. One of these factors is assumed to be time-invariant and may be interpreted as a latent class indicator. A simulation study shows that maximum likelihood estimates from even the shortest panel are much more reliable than those obtained from a cross-section. As an illustrative example, the model is applied to Russian Longitudinal Monitoring Survey data to estimate a proportion of the non-employed population who are participating in job search.
Introduction
Event history analysts and survival statisticians are familiar with problems that require treating data as a sample drawn from a heterogeneous population split into two latent classes. The first class consists of objects that are going to face a certain event of interest sooner or later, while the second class includes those objects that never face the event. Models that allow for such heterogeneity are known as cure models in medicine (Boag, 1949) and split-population or mover-stayer models in event-history analysis (Schmidt & Witte, 1989; Blumen et al., 1955; Yamaguchi, 2003). Poirier (1980) used a similar approach when introducing a partial observability model for binary choice.
In this paper, we propose a panel version of a partial observability model and show that panel data allow the identification of parameters that are unidentified in the cross-section case. The paper is organized as follows. Section 2 contains a brief review of research concerning partial observability models and their applications. Section 3 describes in detail the model with partially observable bivariate binary response for cross-sectional data. Section 4 presents the extended version of the model for use with panel data. Section 5 contains the results of a simulation study. Section 6 gives an example of the model’s application to the job search analysis. Section 7 concludes the article.
Literature review
Binary choice models with partial observability were introduced by Poirier (1980) who gives an example from a study on the retention of trainees (Gunderson, 1974): a researcher knows whether a trainee continues working after the completion of training, but this choice is not just an individual decision. The trainee cannot continue working if the employer decides not to retain him. Therefore, we may consider a latent class of individuals who are able both to continue working and to quit and another latent class for those who have no choice except to quit the job because the employer is not interested in retaining them. Poirier uses the term “partial observability” because in this situation, a researcher does not observe the individual decisions of the trainee and the employer but only the result determined by both decisions. Poirier considers a model that consists of two probit equations for unobserved factors (decisions of the trainee and the employer) and the only observed dependent variable which is the product of these factors. Although the paper starts with demonstrative example from labor economics, it is purely theoretical and deals mostly with identifiability issues.
Applications of partial observability models include the study of political interactions by Nieman (2015), where a civil war onset is explained by unobserved decisions of rebels and the government, similar studies on international relations and conflicts (Signorino, 1999, 2002) and works on misreporting in survey data (Beger et al., 2011; Rainey & Jackson, 2013).
Identifiability of models’ parameters and reliability of estimates in presence of partial observability have always been the issue of concern. Simulation studies were conducted to examine statistical properties of estimators but these studies led to substantially different conclusions. The results presented in Beger et al. (2011) show that the estimates agree with true values, while Rainey and Jackson (2017) found the inference from partial observability models to be seriously misleading. Nieman (2015) investigates the consequences of misspecification and concludes that the estimates from misspecified models are biased but nonetheless useful. Rainey and Jackson (2017) state that even a slight specification error leads to substantial bias and distorts results of significance tests.
Bivariate binary model with partial observability: Cross-sectional data
For the sake of convenience, let us return to the example with the retention of trainees and consider a sample that consists of
The probabilities of the agents’ decisions are
Here,
In this case, the decisions of both the trainee and employer are determined by probit equations. The split-population logit model presented in Beger et al. (2011) is similar but uses a logistic function for
If variables
The specification used by Poirier allows for correlation between the agents’ decisions, but we do not consider that case, nor do Beger et al. (2011); Nieman (2015); Rainey and Jackson (2013, 2017).
Coefficient vectors
One problem that arises when dealing with such a model is possible nonidentifiability. The simplest example of the unidentified model is obtained by omitting all the explanatory variables so that
Rainey and Jackson (2017) note another weak point: estimates obtained from partial observability models are highly sensitive to misspecification. Choosing wrong functions
Most researchers, however, are interested not in predictions but in explanatory ability or theoretical inference, and switching the coefficient sign means providing the opposite explanation of a phenomenon under study. It seems that the results of Rainey and Jackson simply remind us that there can be empirically almost-equivalent models that contradict each other. This phenomenon is not just a drawback of partial observability models but a problem of science as a whole. Such a discussion is beyond the scope of our paper, although we consider it highly important. At the moment, however, let us conclude that consequences of misspecification are not as clear as they may seem.
Now, we turn to a case where a sample consists of repeated observations of
We assume that all latent variables
The response probabilities in a separate observation are determined by the following equation:
The probability of observing values
The log-likelihood function is obtained by summing the logs of these probabilities over all objects:
Maximizing the log-likelihood with respect to coefficient vectors
It is rather weird to assume that the decision of one agent is time-invariant while another agent may change his mind, so this interpretation seems to be of little use. It is more appropriate to consider
One may also think of time-invariant factors as individual effects. A common formulation for a binary choice model with individual effects
If we assume that
We have conducted several simulation experiments to examine the properties of the estimators obtained by fitting the panel model with partial observability and its version for cross-sectional data. The results of one such experiment are presented below.
Data are generated according to the following system of equations:
Both equations are specified as logit models:
Values of random variables
Log-likelihood is maximized via the Newton-Raphson algorithm, and derivatives are calculated numerically (method d0 in Stata).
We generate 10,000 random samples for each pair
Results of the simulation study
The maximization procedure fails to converge on some samples. This failure is quite common in a cross-section case, although the proportion of failures declines with sample size increasing. The panel data almost guarantee convergence. There were no failures in the described case, but in some other experiments with the same sample sizes, we observed a very small proportion of nonconvergences (less than 0.1%) when dealing with short panels,
Nonconvergence takes place when the value of a parameter that maximizes the log-likelihood function is infinite. Such cases may appear even when estimating univariate binary choice models (“perfect separation”; see Hilbe (2009)). They also take place when a simple logit model fits the data better than a model with partial observability, so that a maximization procedure tries to set
The large MSEs in certain cells of Table 1 indicate that there might be some proportion of false convergences when the maximization procedure stopped at very large coefficient values because of numerical inaccuracy. In such cases, we also observe substantial bias and a proportion of correct confidence intervals that differ from the nominal confidence level.
We have tried to correct the simulation results by omitting estimates with implausibly high absolute values for at least one coefficient (for example, more than 100). Nevertheless, evidence for bias and incorrect inference does not disappear even after excluding all the cases with estimates greater than 10 in absolute value. Figure 1 presents a histogram with a kernel density plot for the remaining values of
Estimated density function for 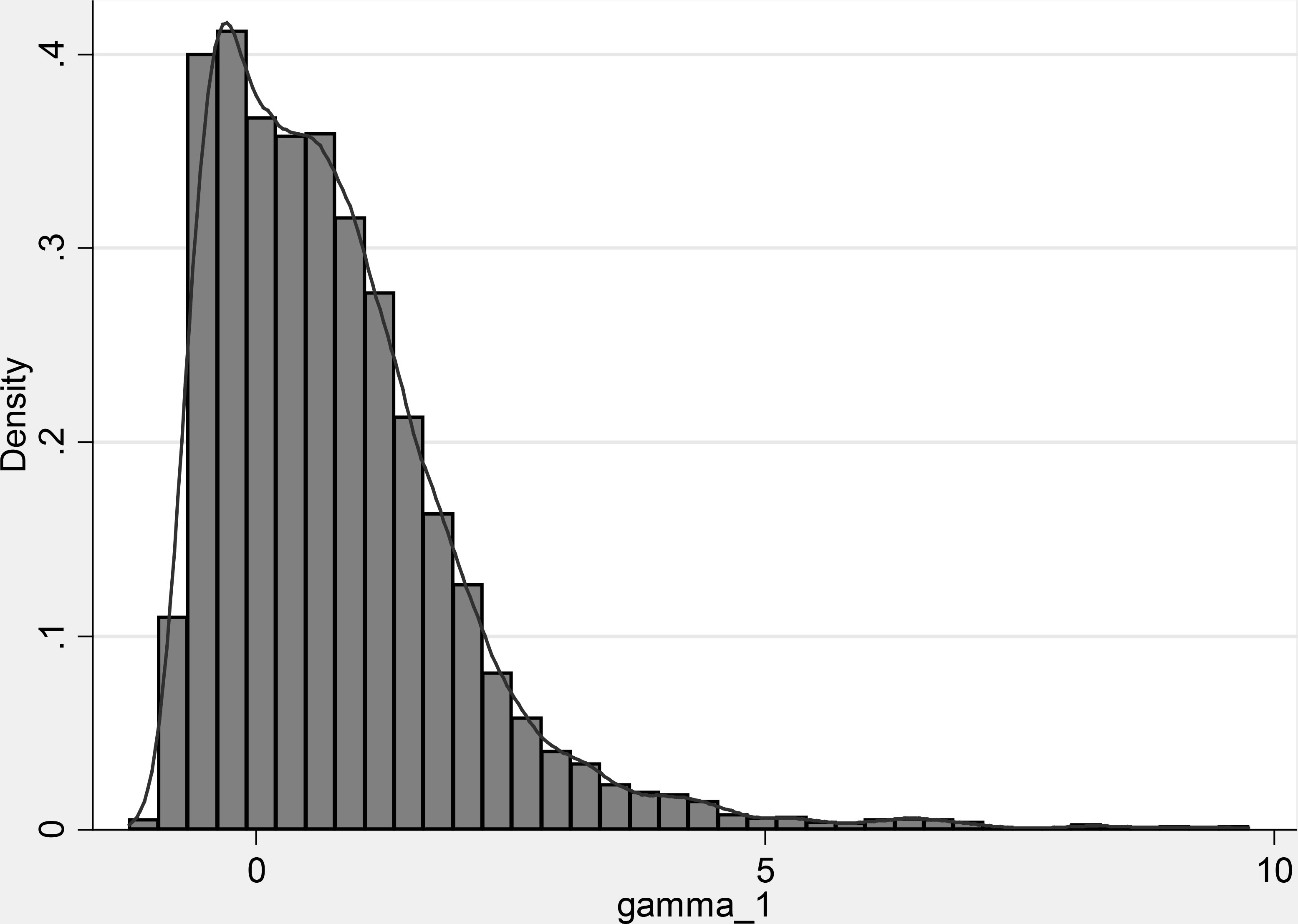
It is worth describing other experiments in brief. They accounted for:
Correlation between explanatory variables with coefficient of correlation varying from 0 to 0.97; Same covariates appearing in both equations; No explanatory variables for time-invariant factor (only intercept term); Covariates with normal and Bernoulli distribution with probabilities of values 0 and 1 ranging from 0.1 to 0.9; Unbalanced panels with random number of observations per object.
We did not study the properties of estimators with almost perfectly correlated covariates or Bernoulli distributed explanatory variables with probabilities close to 0 or 1, so the caution should be taken when fitting the model in presence of multicollinearity.
All our experiments show that the use of panel data greatly reduces the proportion of nonconvergences, allowing for the estimation of parameters that would be unidentified in the cross-section case, and secures more reliable inferences.
Consider a simple job search model described in Kiefer (1988). An agent is seeking a job and receives offers that he or she can either accept or reject. Once the agent accepts an offer, the job search ends, and the agent becomes employed. If acceptable offers arrive according to a Poisson process with intensity rate
Now let us introduce heterogeneity among the non-employed individuals: agents are involved in a job search with probability
Let
The problem is to estimate probabilities of job search participation and of finding a job within a given period of time. It can be considered as a kind of classification problem for binary data (Aivazian et al., 2016).
We use the following parameterization (here,
This is the panel model with partial observability from Section 3 with no covariates, where the first equation is the same as in a logit regression, and the second equation is the same as in a cloglog regression. Of course, other parameterizations lead to the same point estimates, although confidence intervals slightly differ.
The model is estimated from RLMS HSE data for the period from 2000 to 2015. The sample includes observations on non-employed men aged 18 to 59 years and women aged 18 to 54 years. We fit the model to two-year subpanels of men and women separately. Estimated probabilities of job search participation and proportions of job seekers are presented in Table 2. The table also presents pooled estimate for the probability of finding a job that is obtained under homogeneity assumption (all individuals are looking for job). Columns with observation numbers contain odd values because of attrition: some individuals were not observed for the full period. Untransformed estimates of
The proportion of job seekers among both sexes mostly ranges between 50% and 65%, and men stably have a higher probability of successful search than women. We have also found that the estimated proportion of seekers increases when fitting the model to longer panels, which is quite natural. For example, using data from the 2000–2008 period, we obtain practically equal values of 89.4% and 89.5% for the proportion of seekers among men and women, respectively.
Proportion of job seekers (
These results are presented here purely for illustrative purposes, not for discussion of Russian labor market, interested reader is referred to Grogan and van den Berg (2001); Batalova and Furmanov (2018). They demonstrate the advantage of using panel data when dealing with partial observability. It is noted in Section 2 that a model without covariates is unidentified, but here we present estimates of such a model. Panel data make this possible.
It is worth considering identification problems not as a purely mathematical issue but as something that reflects the conceptual drawback of a model. The functional form is, in fact, the only thing that distinguishes the partial observability model for cross-sectional data from its simple, single-equation counterparts such as probit and logit models. Latent classes and agents’ decisions are simply arbitrary interpretations.
In the panel case, partial observability means not only a different functional form but also a special kind of dependence between repeated observations of the same object. Of course, this meaning does not ensure that a model becomes closer to reality (which is not our aim, anyway). It just deepens latent factor interpretation and perhaps makes the model more useful.
Footnotes
Appendix
Job search model: untransformed estimates. Standard errors in parentheses.
Period
Men
Women
Obs
Obs
2000–2002
1625
0.002 (0.094)
0.460 (0.127)
2156
0.491 (0.164)
2001–2003
1775
0.476 (0.127)
2237
0.700 (0.190)
2002–2004
1882
0.120 (0.082)
0.265 (0.095)
2207
0.435 (0.141)
2003–2005
1907
0.061 (0.090)
0.212 (0.102)
2225
0.266 (0.133)
2004–2006
1888
0.285 (0.115)
2256
0.296 (0.127)
2005–2007
2033
0.414 (0.114)
2422
0.402 (0.149)
2006–2008
2127
0.658 (0.144)
2472
0.734 (0.210)
2007–2009
1989
0.025 (0.084)
0.263 (0.101)
2309
0.106 (0.096)
2008–2010
1977
0.211 (0.078)
0.109 (0.082)
2224
0.271 (0.135)
2009–2011
2464
0.006 (0.086)
0.177 (0.102)
2833
0.308 (0.168)
2010–2012
2927
0.315 (0.111)
3467
0.288 (0.126)
2011–2013
2921
0.326 (0.108)
3484
0.259 (0.126)
2012–2014
2809
0.066 (0.076)
0.005 (0.080)
3345
2013–2015
2558
2909